Yarn安装及配置一件启停
数据、程序、运算资源(内存、CPU)三者组在一起,才能完成数据的计算处理过程。在单机环境下,三者之间协调配合不是太大问题。为了应对海量数据的处理场景,Hadoop软件出现并提供了分布式处理思想。但是在分布式环境下的三者如何协调好将成为关键。在Hadoop1.x的时候 MapReduce既负责数据的运算,又负责资源的管理.在Hadoop2.x的版本拆分MapReduce,剥离出资源管理成为单独框架,YARN闪亮登场,MapReduce专注于数据处理,两者解耦合。YARN被设计用以解决以往架构的需求和缺陷的**资源管理**和**调度软件**。
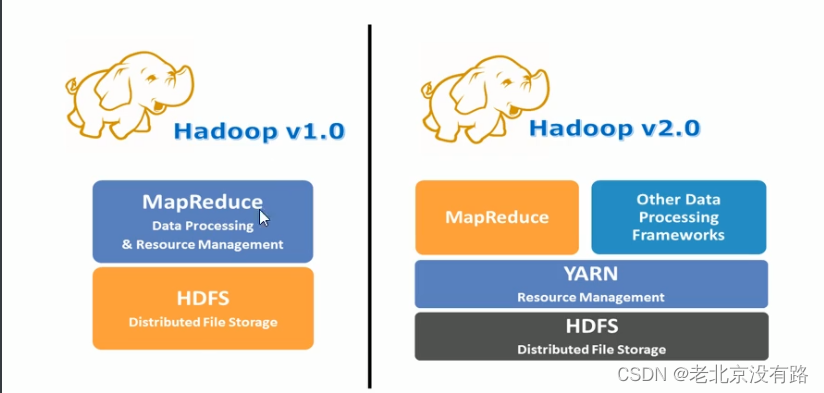
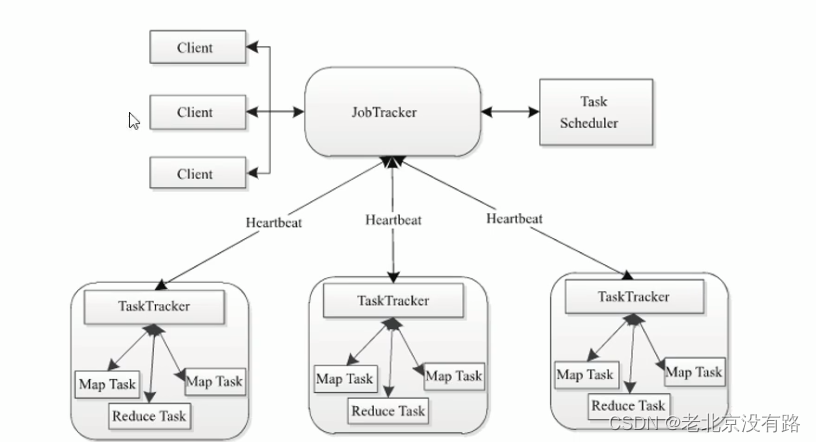
Hadoop 1.x 版本主要架构模型
JobTracker :一个中央守护进程,负责运行集群上的所有作业。
TaskTracker:系统里的从进程,根据JobTracker的指令来执行任务
JobTracker身兼多职、压力大(作业数据管理、作业状态记录、作业调度)、可靠性和可用性欠缺(JobTracker单点故障)、计算模型单一。MapReduce框架本身需要迭代优化。但是计算和资源管理绑定在了一起,使得MapReduce的演变比较困难。
什么是Yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
资源管理系统:集群的硬件资源,和程序运行相关,比如内存,CPU等
调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
通用∶不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、CPU等)。
Hadoop能有今天这个地位,YARN可以说是功不可没。因为有了YARN,更多计算框架可以接入到 HDFS中,而不单单是MapReduce,正式因为YARN的包容,使得其他计算框架能专注于计算性能的提升。
HDFS可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,YARN功不可没。
Yarn架构体系
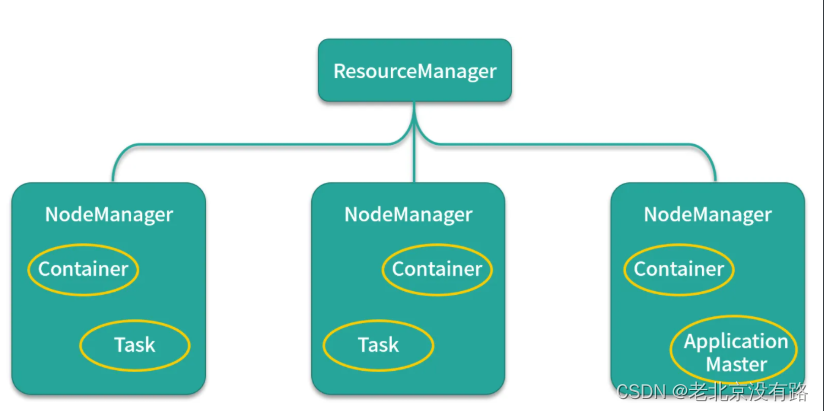
主从架构
也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。
1、 每个节点上可以负责该节点上的资源管理以及任务调度,Node Manager 会定时向Resource Manager汇报本节点上 的资源使用情况和任务运行状态,
2、 Resource Manager会通过心跳应答的机制向Node Manager下达命令或者分发新的任务,
3、 Yarn 将某一资源分配给该应用程序后,应用程序会启动一个Application Master,
4、 Application Master为应用程序负责向Resource Manager申请资源,申请资源之后,再和申请到的节点进行通信,运行内部任务。
Resource Manager
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
Schedule 资源调度器是一个可插拔的组件,用户可根据自己需要设计资新的源调度器,YARN提供多个可直接使用的资源调度器。资源调度器将系统中的资源分配给正在运行的程序,不负责监控或跟踪应用的执行状态,不负责重启失败的任务。
Applications Manager 应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
Node Manager
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
ApplicationMaster
用户提交的每个应用程序均包含一个AM,主要功能包括:
1.与RM调度器协商以获取资源(用Container表示);
2.将得到的任务进一步分配给内部的任务
3.与NM通信以启动/停止任务;
4.监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。yarn的container容器是yarn虚拟出来的一个东西,属于虚拟化的,它是由memory+vcore组成,是专门用来运行任务的
Yarn的安装
etc/hadoop/目录下 yarn-site.xml文件
vi yarn-site.xml
<!-- resource,manager主节点所在机器 -->
<property><name>yarn.resourcemanager.hostname</name><value>linux01</value>
</property><!-- 为mr程序提供shuffle服务 -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property><!-- 一台NodeManager的总可用内存资源 -->
<property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value>
</property>
<!-- 一台NodeManager的总可用(逻辑)cpu核数 -->
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value>
</property><!-- 是否检查容器的虚拟内存使用超标情况vmem为true 指的是默认检查虚拟内存,容器使用的虚拟内存不能超过我们设置的虚拟内存大小
-->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 容器的虚拟内存使用上限:与物理内存的比率 -->
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>将 yarn-site.xml 同步给其他Linux
scp yarn-site.xml linux02:$PWD
scp yarn-site.xml linux03:$PWD
配置一键启停
cd /opt/apps/hadoop-3.1.1/sbin
vi start-yarn.sh
vi stop-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=rootstart-yarn.sh 一键启动 启动后可以访问 http://linux01:8088 查看页面解决linux连接部上 网卡出现问题
systemctl stop NetworkManager
systemctl diable NetworkManager
systemctl restart network