限流
- 为什么要限流
- 限流算法
- 单机限流
- 计数器算法
- 滑动窗口算法
- 漏桶算法
- 令牌桶算法
- 分布式限流
- 配额算法
- 限流策略
- 限流位置
为什么要限流
作为有追求的程序员,我们都希望自己的系统跑的飞快,但是速度再快,系统处理请求耗时也不可能为0,这样我们的系统也就无法做到处理能力无上限。此外,机器CPU、磁盘IO、内存、网络带宽也都有自己的处理上限的,这也进一步限制系统处理能力上限。
当请求超过了系统上限,系统的某处节点必然存在瓶颈:
- CPU使用率100%:没有空闲CPU只能排队等调度
- 内存满了:无法申请新的内存,频繁发生内存置换影响处理速度
- 磁盘IO满了:后续读写请求只能排队等调度
- 网络带宽满了:后续收发网络包只能排队进出
如果不采取任何措施,新请求源源不断的进来,旧请求依旧排队等待处理,但往往请求都有超时时间,当超时后用户可能会发起重试,这样就会进一步使情况恶化。当系统复杂时,各个节点都可能出现超时,最终导致大量请求超时,系统成功处理数急剧下降,从而导致系统雪崩,所有用户无法使用。
为了避免以上情况出现,我们必须想法来保护我们的系统,避免出现雪崩。降级和限流是经常采用的两种手段:
- 限流-事前预防:保证请求量在系统处理的安全范围内
- 降级-事中应对:保证核心系统可用
下面我们主要围绕限流来进行讲述。
限流算法
单机限流
在微服务兴起之前,主要是单机限流,也叫本地限流,其对应的主要算法有 计数器、滑动窗口算法、漏桶算法、令牌桶算法。
计数器算法
这个是最容易想到的算法,思想:在指定的时间窗内,如果请求数超过预期数,则认为流量过大,需要限流。
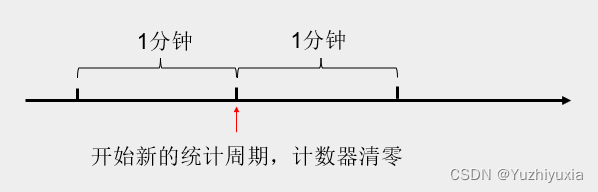
实现思路:
统计单位时间内(比如1分钟内)的请求数,如果超过阈值,则拒绝请求,否则累加计数器。下个单位时间(下1分钟)开始时,重新开始计数。
#include <chrono>typedef std::chrono::duration<long, std::milli> MilliTimeUnit;class CounterLimit {
public:CounterLimit(int max_limit, MilliTimeUnit interval) {this->max_limit = max_limit;this->interval = interval;base_time = std::chrono::steady_clock::now();counter = 0;}bool canPass(int num) {std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();MilliTimeUnit time_span = std::chrono::duration_cast<MilliTimeUnit>(now - base_time);//当前时间跟基准时间超过指定时间窗时,重置计数器和基准时间//这里没必要精确控制时间窗的起始和截止时间if (time_span.count() > interval.count()) {counter = 0;base_time = now;}counter += num;return counter < max_limit;}private:int max_limit;MilliTimeUnit interval;unsigned long counter;std::chrono::steady_clock::time_point base_time;
};
优点:实现简单
缺点:无法应对时间窗口临界的突发请求场景
时间窗口临界的突发请求是指在当前周期和下一周期的交界处瞬间有大量请求过来,比如设定1分钟1000个请求,用户在当前周期的最后1秒和下个周期第1秒突然发起大量请求。
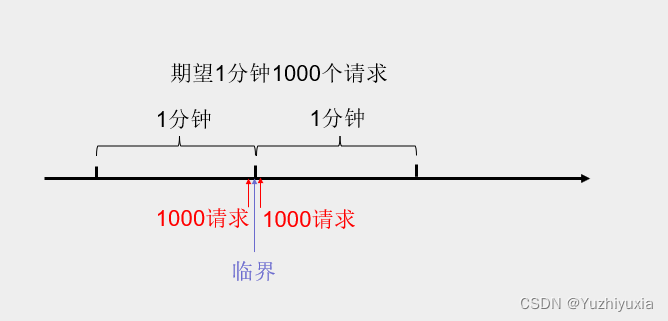
期望并发流量是1000/分钟,但在临界处的瞬时流量就达到2000/分钟,超过我们系统的处理上限,可能导致系统雪崩。
也许有人会说1分钟粒度太粗了,我们可以将时间窗口设置为1秒,但是即使将时间窗口设置为1秒也会有类似问题,对坏坏的高手而言,他们可以在最后10毫秒发来大量请求。
滑动窗口算法
计数器算法的窗口前移是整个窗口往前移动,此时就会存在窗口边界。为了消除窗口边界,我们可以将窗口缓慢向前滑动,类似TCP的滑动窗口,这样就解决了计算器算法的临界处突发请求的问题。
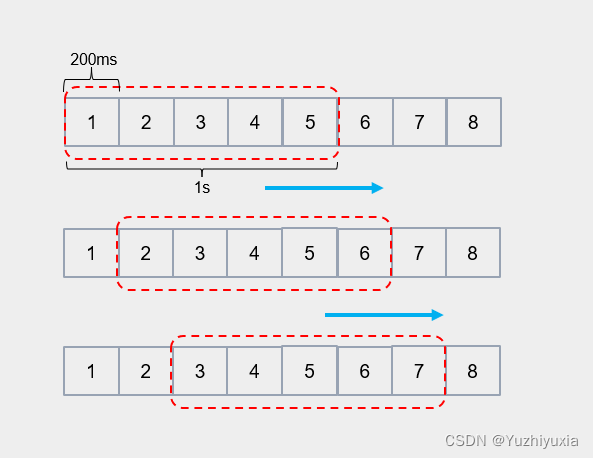
思想:将单位时间窗等分n份,比如1s等分5格(每格代表200ms),每隔200ms窗口向前移动一格,每格都有一个计数器记录该窗格时间内的请求数。当所有窗格的请求数之和大于阈值时,则需要限流。
#include <chrono>
#include <vector>typedef std::chrono::duration<long, std::milli> MilliTimeUnit;
class SlidingTimeWindow {
public:SlidingTimeWindow(int max_limit, int window_size, MilliTimeUnit window_interval) {this->max_limit = max_limit;this->window_interval = window_interval;base_time = std::chrono::steady_clock::now();window_idx = 0;total = 0;}bool canPass(int num) {int window_size = window.size();std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();MilliTimeUnit time_span = std::chrono::duration_cast<MilliTimeUnit>(now - base_time);//最新请求所处的窗格编号int new_window_idx = time_span / window_interval;if (new_window_idx - window_idx >= window_size) {//当最新请求时间和最近请求时间的时间间隔超过整个时间窗时,直接重置窗口for (int idx = 0; idx < window_size; ++idx) {window[idx] = 0;}total = 0;window_idx = 0;base_time = now;} else if (new_window_idx > window_idx) {//当最新请求时间和最近请求时间的时间间隔不超过整个时间窗时,将最近窗格和最新请求窗格之间的窗格重置for (int idx = window_idx + 1; idx <= new_window_idx; ++idx) {int wIdx = idx % window_size;total -= window[wIdx];window[wIdx] = 0;}window_idx = new_window_idx;}total += num;window[window_idx % window_size] += num;return total < max_limit;}private:int max_limit;MilliTimeUnit window_interval;//基准时间,用于计算当前时间对应的时间窗窗格std::chrono::steady_clock::time_point base_time;//时间窗的起始窗格long window_idx;std::vector<int> window;long total;
};
优点:解决了临界处的突发流量
缺点:实现相对复杂,每个窗格都需要记录请求数;无法平滑的处理请求流量
由于滑动窗口每次往前滑动一格,当时间窗内请求数达到上限后就拒绝新请求,因此可以解决临界处的突发流量问题。
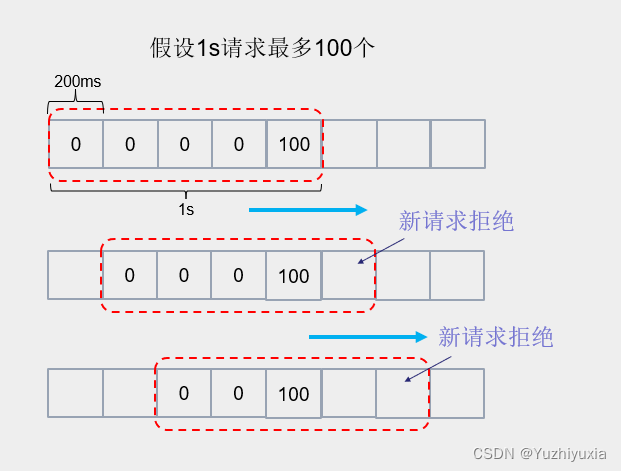
以上图为例,当最后一个窗格达到阈值后,后续4个窗格时间内的新请求都将会被拒绝。理想情况下,我们希望请求均匀的进来,这样系统就可以平滑的处理所有请求。但现实是我们没法控制请求的频率,这样就导致滑动窗口面对突发流量时,没法做到平滑处理。
要做到请求平滑处理,要么控制请求进来的速度,要么控制请求出去的速度。因此,也就有了以下两种算法:
- 漏桶算法:限制请求出去的速度
- 令牌桶算法:限制请求进来的速度
漏桶算法
思想:请求随机进来,先放入一个桶里,但桶下方有个洞,该洞可以匀速流出请求。
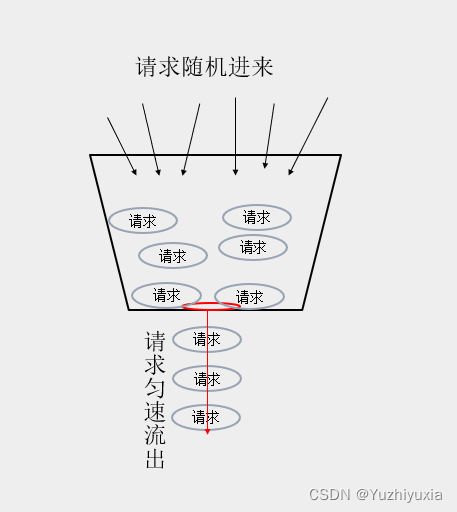
常规实现:有个计数器记录当前桶中剩余请求数,开启一个线程定期扣减桶中的请求数,当新请求来临时,检查请求数是否超过桶的最大限制,如果超过则判定限流。
上述实现需要开启一个线程来专门扣减桶中的请求数,这种方式将浪费一个线程资源,可以通过请求时间计算来实现桶中请求数的扣减:
桶中剩余请求数 = Max(0, 桶中当前请求数 - ((请求时间 - 基准时间)/ 频率 - 上次流逝请求数))
#include <chrono>typedef std::chrono::duration<long, std::milli> MilliTimeUnit;class LeakyBucket {
public:LeakyBucket(int max_limit, MilliTimeUnit interval) {this->max_limit = max_limit;this->interval = interval;counter = 0;base_time = std::chrono::steady_clock::now();last_output = 0;}bool canPass(int num) {std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();MilliTimeUnit time_span = std::chrono::duration_cast<MilliTimeUnit>(now - base_time);//基于基准时间计算桶的总流出量,减去上次的总流出量last_output 即为上次请求时间到当前时间的请求流出量long new_output = time_span.count() / interval.count();//需要保证桶中剩余请求数一定不小于0counter = std::max(0L, counter - (new_output - last_output));//更新上次流出的请求数last_output = new_output;if (counter + num <= max_limit) {counter += num;return true;}return false;}private:int max_limit;MilliTimeUnit interval;long counter;std::chrono::steady_clock::time_point base_time;long last_output;
};
优点:保证了系统处理速度恒定,避免了瞬间峰值的压力
缺点:当系统资源充足时,无法应对突发流量;当依赖消息队列时,则存在请求处理时延
在具体使用场景中,有以下方式:
- canPass通过后,直接调用后端请求
这里要求请求处理速度要跟桶流出速率保持一致,当桶流速大于请求处理速度,将可能导致限流逻辑失效,即桶未满但系统已高负载。 - canPass通过后,请求放入消息队列
这种场景将会导致请求的处理有时延,不适合时延敏感的场景。如果引入了消息队列,感觉没必要在用漏桶了,直接在收到请求后就将请求放入消息队列中,后端慢慢处理。
令牌桶算法
思想:匀速往桶中放令牌,后端在处理请求前先获取令牌,如果取到令牌则可以处理,否则限流
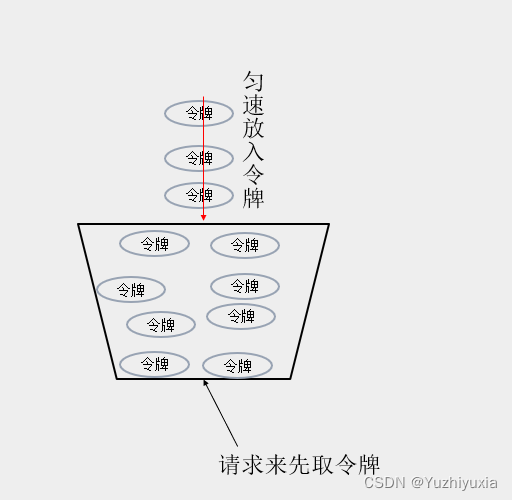
常规实现:有个计数器记录当前桶中剩余令牌数,开启一个线程定期往桶中放入令牌,即增加计数器的值。当新请求来临时,需要从桶中取令牌,即减少计数器的值,当取到令牌,则继续处理请求,否则判定限流。
上述实现需要开启一个线程来专门往桶中放如令牌,这种方式将浪费一个线程资源,可以通过请求时间计算来实现往桶中放入令牌数:
桶中剩余令牌数 = Min(桶限额, 桶中剩余令牌数 + ((请求时间 - 基准时间)/ 频率 - 上次放入令牌数))
#include <chrono>typedef std::chrono::duration<long, std::milli> MilliTimeUnit;class TokenBucket {
public:TokenBucket(int max_limit, MilliTimeUnit interval) {this->max_limit = max_limit;this->interval = interval;counter = 0;base_time = std::chrono::steady_clock::now();last_output = 0;}bool canPass(int num) {std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();MilliTimeUnit time_span = std::chrono::duration_cast<MilliTimeUnit>(now - base_time);//基于基准时间计算总放入令牌数,减去上次放入令牌数last_output 即为上次请求时间到当前时间的新增令牌数long new_output = time_span.count() / interval.count();counter = std::min((long) max_limit, counter + (new_output - last_output));last_output = new_output;if (counter >= num) {counter -= num;return true;}return false;}private:int max_limit;MilliTimeUnit interval;long counter;std::chrono::steady_clock::time_point base_time;long last_output;
};
优点:支持一定的突发流量
缺点:系统需要预热,刚启动时没有令牌,初始请求都会失败
分布式限流
在微服务兴起之后,通过每台机器的单机限流来达到分布式限流目的,可能存在着以下问题:
- 配置维护复杂:当机器处理能力不一样时,需要单独维护每台机器的限流配置
- 无法准确反映全局情况:当请求分布不均时,可能会出现某台机器限流了,其他机器没请求
限流的思想是固定的,但分布式限流需要在单机限流的基础上解决限流统计信息如何在不同机器间共享的问题。对于该问题,第一反应就是将内存中的统计信息移到第三方组件中存储,比如Redis缓存。
如果每次请求都去访问第三方组件,这将会带来严重的性能问题。为了解决这里的性能问题,我们可以减少访问第三方组件的次数,比如一次拉取多个配额存储在本地,当请求来临时消耗本地配额,当本地配额不足时再去远端拉取新配额。
配额算法
思想:客户端在启动时从服务端拉取配额存到本地内存中,当请求来时,先扣减本地配额,如果扣减成功,则继续处理请求;如果扣减失败,则尝试从服务端拉取配额存储到本地,如果拉取后本地配额扣减成功,则继续处理请求,否则提示限流。
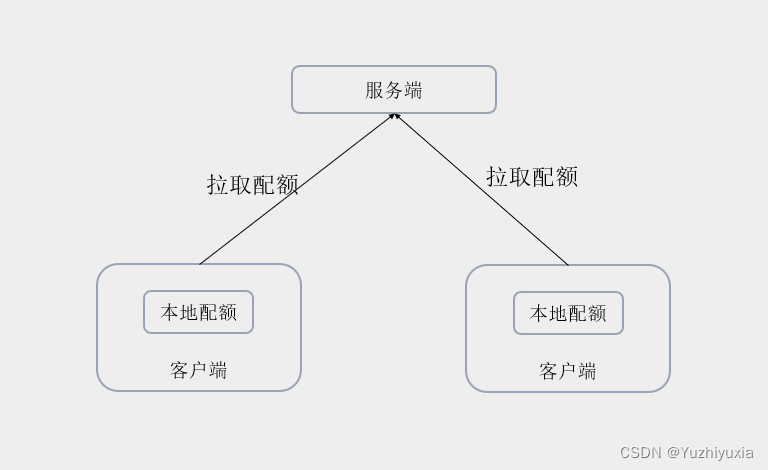
实现过程中需要注意的点:
- 配额具有时效性:每个时间段都应该有专门的配额计数器,需要定时从服务端拉取当前时间段内的配额信息,可以通过当前时间计算所对应的配额信息
- 何时拉取配额:最好能做到预拉取,比如本地配额剩余5%时就异步拉取配额
- 注意配额大小设置以及请求负载的均衡性,当请求负载不均时,可能会导致某台机器限流,其他机器无请求
限流策略
- 拒绝请求
当达到请求阈值时,直接拒绝请求。
主要适用于实时性交互的场景、敏感的写操作等,比如交易下单等。 - 缓存请求
当被限流后,将请求放入消息队列或者缓存队列中,等服务空闲后,继续处理这些请求。
主要适用于非实时性交互的场景,非敏感操作等,比如发送触达。
限流位置
- 接入层限流:依赖全链路压测性能,可以按照请求接口限流,实施更简单
- 应用层限流:依赖应用接口的压测性能,不同应用有不同的接口,这些接口有不同的性能,实施更复杂
- 基础层限流:依赖底层服务(如数据库)的性能