文章目录
- Overview
- BEiT
- 1.0. Summary
- 1.1. BEiT VS BERT
- 2.1. Two Views: visual tokens
- 2.1. Two Views: image patches
- 3. Results
- BEiT V2
- 1.0. Summary
- 1.1. Motivation
- 2.1. Methods -- VQ-KD
- 2.2. Methods -- patch aggregation
- 3.1. Results -- image classification & semantic segmentation
- 3.2. Results -- Ablation studies about VQ-KD
- 3.3. Results -- Ablation studies about patch aggregation
- 3.4. Results -- Visualization
- VLMO
- 1.0. Summary
- 2.1. Contribution 1: MoME
- 2.1. Contribution 2: Stagewise Pre-Training
- BEiT V3
- 1.0. Summary
- 1.1. Motivations & Contributions
- 2.1. Method -- Multiway Transformers
- 2.2. Method -- Masked Data Modeling
- 2.3. Method -- Scaling up
- 2.4. Method -- Transfer to downstream tasks
- 3. Experiments
Overview

BEiT
1.0. Summary
题目: BEiT: BERT Pre-Training of Image Transformers
机构:微软
论文: https://arxiv.org/abs/2106.08254
代码:https://github.com/microsoft/unilm/tree/master/beit
任务: CV的BERT,图像单模态预训练
特点:
方法:
前置相关工作:BERT
1.1. BEiT VS BERT
BEiT: Bidirectional Encoder representation from Image Transformer
BERT: Bidirectional Encoder Representation from Transformer
| Model | Pretraining Task | Mask Method | Special Tokens |
|---|---|---|---|
| BERT | masked language modeling | masking 15% tokens 80% [MASK], 10% random, 10% origin | [CLS], [SEP] |
| BEiT | masked image modeling | blockwise masking | [CLS] |
2.1. Two Views: visual tokens
tokenizer需要在pretrain之前先训练好,或者使用网上开源项目的权重(比如DALLE)
作用:为pretrain阶段提供监督信息。类比于NLP中的tokenizer

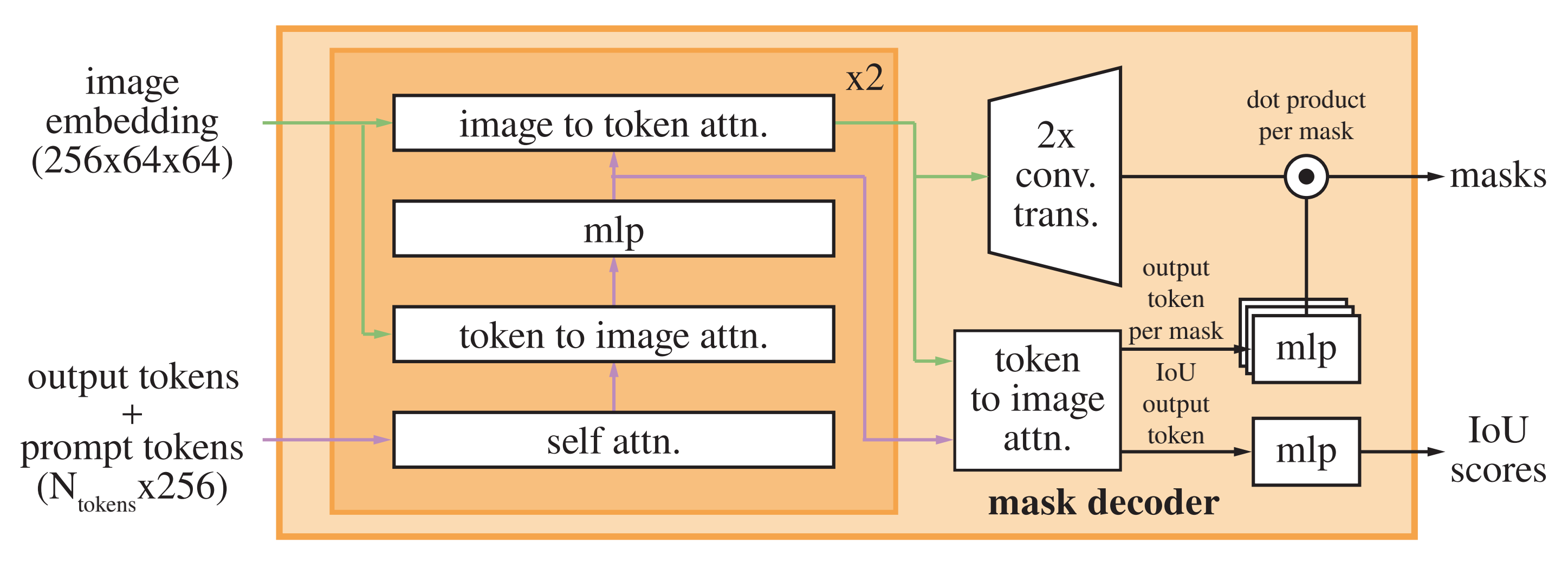
2.1. Two Views: image patches
- 将图片分成patches
- blockwise masking一些patches
- 拼接[CLS],+ position embedding
- 经过transformer encoder预测masked patches对应的visual tokens

3. Results
image classification和semantic segmentation任务上效果好于
(1) training from scratch(ViT, DeiT)
(2) Supervised Pre-Training on ImageNet-22K(ViT)
(3) Self-Supervised Pre-Training on ImageNet-1K(ViT, iGPT, MoCo v3, DINO)

BEiT V2
1.0. Summary
题目: BEIT V2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
机构:微软
论文: https://arxiv.org/pdf/2208.06366.pdf
代码:https://github.com/microsoft/unilm/tree/master/beit2
任务:
特点:
方法:
前置相关工作:
1.1. Motivation
(1) 当前MIM任务更多关注低层图片元素(像素值),较少考虑高层图片元素(语义信息) NLP中都是挖掘高层的语义信息,所以需要挖掘MIM探索语义信息的能力
(2) MIM任务重视patch的重构,而较少关注对图片全局表征的学习
2.1. Methods – VQ-KD

- 使用其他已有模型的feature map作为重构对象,teather模型有CLIP和DINO
- Encoder输出和Codebook Embedding都用L2-norm
2.2. Methods – patch aggregation

- 增加一个MIM的损失函数,使用第l层的patch tokens和第L层的CLS token,浅层网络
- 促进CLS学习到图片全局的信息
3.1. Results – image classification & semantic segmentation

3.2. Results – Ablation studies about VQ-KD
 decoder越复杂,重构loss越小,codebook的利用率越小,下游任务上表现变差 codebook维度越大,利用率越小
decoder越复杂,重构loss越小,codebook的利用率越小,下游任务上表现变差 codebook维度越大,利用率越小
3.3. Results – Ablation studies about patch aggregation

3.4. Results – Visualization

VLMO
1.0. Summary
题目: VLMO: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
机构:微软
论文: http://export.arxiv.org/pdf/2111.02358
代码:https://github.com/microsoft/unilm/tree/master/vlmo
任务:
特点:
方法:
前置相关工作:
2.1. Contribution 1: MoME
motivation
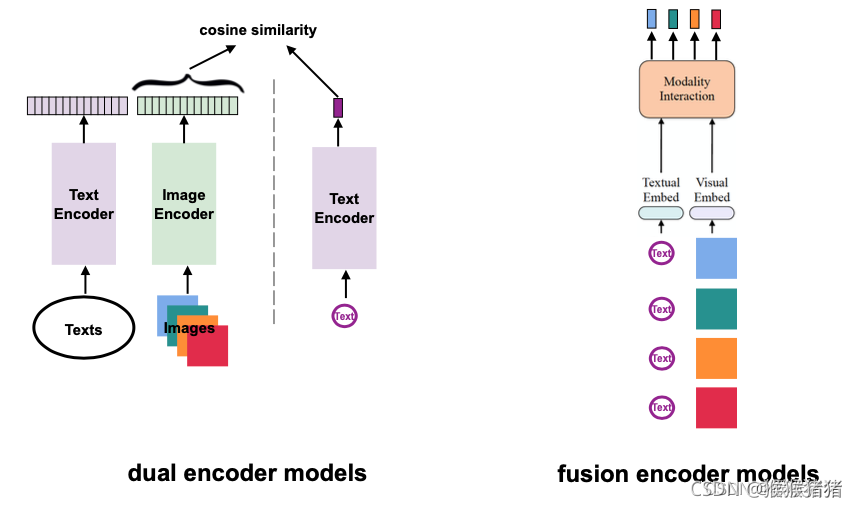
(1) dual encoder models
比如:CLIP,ALIGN
优势:检索任务上高效 (T2I、I2T)
不足:信息融合简单(cosine similarity或linear proj), 在VR和VQA等任务表现不好
(2) fusion encoder models
比如:ViLT,ALBEF 优势:在推理任务上表现较好,VR和VQA 不足:检索任务上速度较慢

检索任务上性能比较
MoME:Mixture-of-Modality-Experts Transformer
pretraining
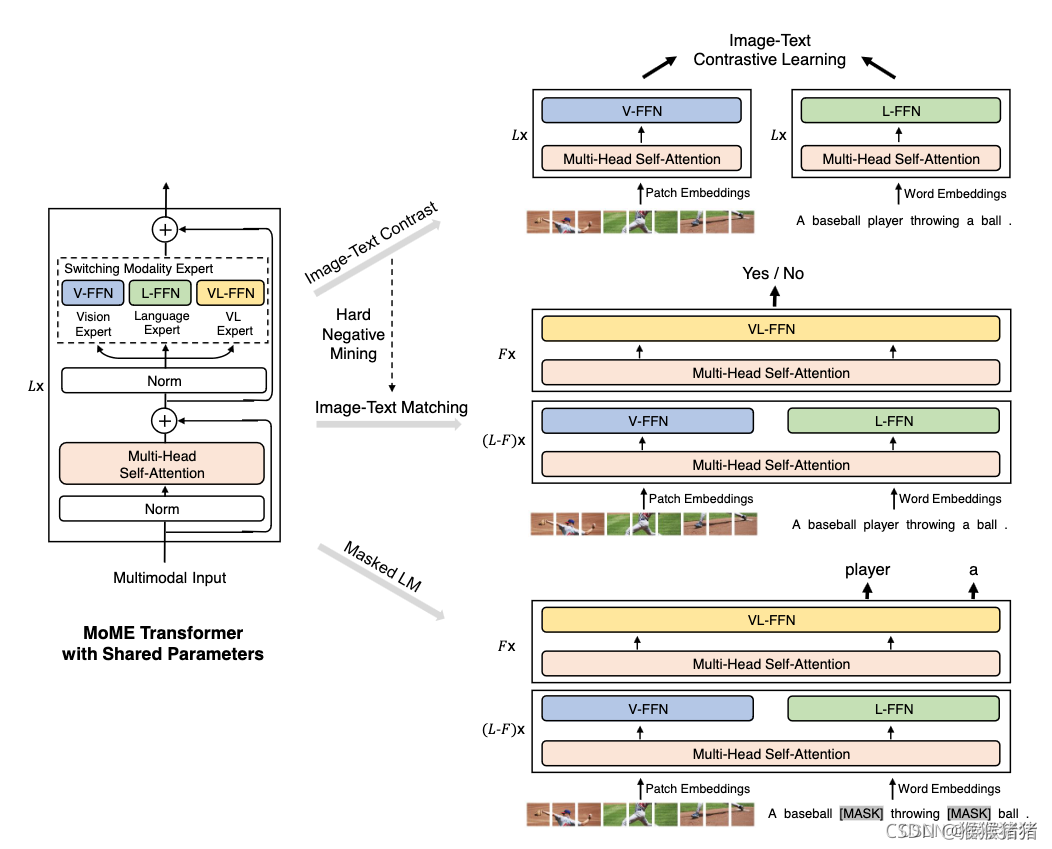
fine-tuning

2.1. Contribution 2: Stagewise Pre-Training
motivation
(1) image-text pairs较少,而且文本大多简短
(2) image-only或text-only的数据较多
提出Stagewise Pre-Training策略,为多模态预训练获得较好的初始化权重

BEiT V3
1.0. Summary
题目: Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
机构:微软
论文: https://arxiv.org/pdf/2208.10442v1.pdf
代码:https://github.com/microsoft/unilm/tree/master/beit3
任务:
特点:
方法:
前置相关工作:
1.1. Motivations & Contributions
vision,language and multimodal pretraining相关研究逐渐增多,并且效果不错,本文提出一个general-purpose foundation model,可以做多种模态的任务
Contributions:
- backbone:Multiway Transformers
- pretext task:mask-then-predict
- scaling up the model size and data size
2.1. Method – Multiway Transformers

对于不同模态的输入,使用共享的Multi-Head Self-Attention提取特征
modality experts pool:根据输入模态的不同,选择不同的FFN
所有层都包含V-FFN和L-FFN,只有顶层的3层额外包含VL-FFN
2.2. Method – Masked Data Modeling
在不同的模态上使用统一的pretext task
monomodal:images or texts
multimodal:image-text pairs
不仅能学习到不同模态输入的表征,还能学习到不同模态输入的对⻬关系
text data使用SentencePiece tokenizer
image data使用BEiT v2里的tokenizer
mask 15% tokens in monomodal texts
mask 40% block-wise patches in monomodal images
mask 50% tokens of texts from image-text pairs
2.3. Method – Scaling up
结构简单的backbone和统一的pretrain task使得BEiTv3易于扩展到大规模

2.4. Method – Transfer to downstream tasks

3. Experiments