Apache Doris 在京东搜索实时 OLAP 探索与实践
https://doris.apache.org/zh-CN/blog/JD_OLAP/
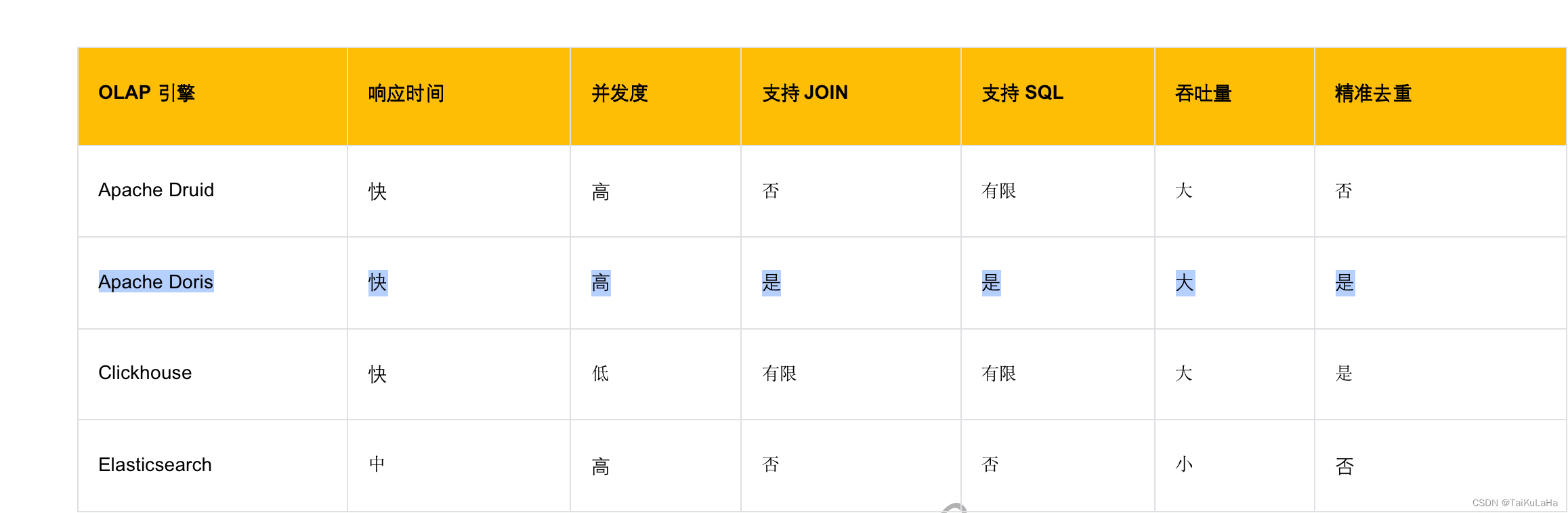
通过对比开源的几款实时OLAP引擎,我们发现doris和clickhouse能够满足我们的需求,但是clickhouse的并发度太低是个潜在的风险,而且clickhouse的数据导入没有事务支持,无法实现exactly once语义,对标准sql的支持也是有限的。 最终,我们选定doris作为聚合层,用于实时OLAP分析。对于流量数据,使用聚合模型建表;对于订单行,我们使用Uniq模型,保证同一个订单最终只会存储一条记录,从而达到订单行精准去重的目的。在flink处理时,我们也将之前的任务拆解,将反复加工的逻辑封装,每一次处理都生成新的topic流,明细层细分了不同粒度的实时流。
从 ClickHouse 到 Apache Doris,腾讯音乐内容库数据平台架构演进实践
升级前存在的问题:
- 数仓层:不支持部分列更新,当上游任一来源表产生延迟,均会造成大宽表延迟,进而导致数据时效性下降。
- 加速层:不同的标签跟指标特性不同、更新频率也各不相同。由于 ClickHouse 目前更擅长处理宽表场景,无区别将所有数据导入大宽表生成天的分区将造成存储资源的浪费,维护成本也将随之升高。
- 应用层:ClickHouse 采用的是计算和存储节点强耦合的架构,架构复杂,组件依赖严重,牵一发而动全身,容易出现集群稳定性问题,对于我们来说,同时维护 ClickHouse 和 Elasticsearch 两套引擎的连接与查询,成本和难度都比较高。
ClickHouse 由国外开源,交流具有一定的语言学习成本,遇到问题无法准确反馈、无法快速获得解决,与社区沟通上的阻塞也是促进我们进行架构升级的因素之一。
Apache Doris 的优势:
- Doris 架构极简易用,部署只需两个进程,不依赖其他系统,运维简单;兼容 MySQL 协议,并且使用标准 SQL。
- 支持丰富的数据模型,可满足多种数据更新方式,支持部分列更新。
- 支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析。
- 导入方式多样,支持从 HDFS/S3 等远端存储批量导入,也支持读取 MySQL Binlog 以及订阅消息队列 Kafka 中的数据,还可以通过 Flink Connector 实时/批次同步数据源(MySQL,Oracle,PostgreSQL 等)到 Doris。
- 社区目前 Apache Doris 社区活跃、技术交流更多,SelectDB 针对社区有专职的技术支持团队,在使用过程中遇到问题均能快速得到响应解决。
同时我们也利用 Doris 的特性,解决了架构 1.0 中较为突出的问题。
- 数仓层:Apache Doris 的 Aggregate 数据模型可支持部分列实时更新,因此我们去掉了 DWM 集市层的构建,直接增量到 Doris / ES 中构建宽表,解决了架构 1.0 中上游数据更新延迟导致整个宽表延迟的问题,进而提升了数据的时效性。数据(指标、标签等)通过 Spark 统一离线加载到 Kafka 中,使用 Flink 将数据增量更新到 Doris 和 ES 中(利用 Flink 实现进一步的聚合,减轻了 Doris 和 ES 的更新压力)。
- 加速层:该层主要将大宽表拆为小宽表,根据更新频率配置不同的分区策略,减小数据冗余带来的存储压力,提高查询吞吐量。Doris 具备多表查询和联邦查询性能特性,可以利用多表关联特性实现组合查询。
- 应用层:DataSet 统一指向 Doris,Doris 支持外表查询,利用该特性可对 ES 引擎直接查询。
从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台
在同样实现倒排索引的情况下,相较于 ES, Apache Doris 怎么做到更高的性能表现呢?或者说现有倒排索引的优化空间有哪些呢?
- ES 基于 Apache Lucene 构建倒排索引,Apache Lucene 自 2000 年开源至今已有超过 20 年的历史,设计之初主要面向信息检索领域、功能丰富且复杂,而日志和大多数 OLAP 场景只需要其核心功能,包括分词、倒排表等,而相关度排序等并非强需求,因此存在进一步功能简化和性能提升的空间;
- ES 和 Apache Lucene 均采用 Java 实现,而 Apache Doris 存储引擎和执行引擎采用 C++ 开发并且实现了全面向量化,相对于 Java 实现具有更好的性能;
- 倒排索引并不能决定性能表现的全部,作为一个高性能、实时的 OLAP 数据库,Apache Doris 的列式存储引擎、MPP 分布式查询框架、向量化执行引擎以及智能 CBO 查询优化器,相较于 ES 更为高效。
通过在 Apache Doris 2.0.0 最新版本的探索与持续优化,在相同硬件配置和数据集的测试表现上,Apache Doris 在数据库内核实现高性能倒排索引后,相对于 ES 实现了日志数据写入速度提升 4 倍、存储空间降低 80%、查询性能提升 2 倍,再结合 Apache Doris 2.0.0 版本引入的冷热数据分离特性,整体性价比提升 10 倍以上!
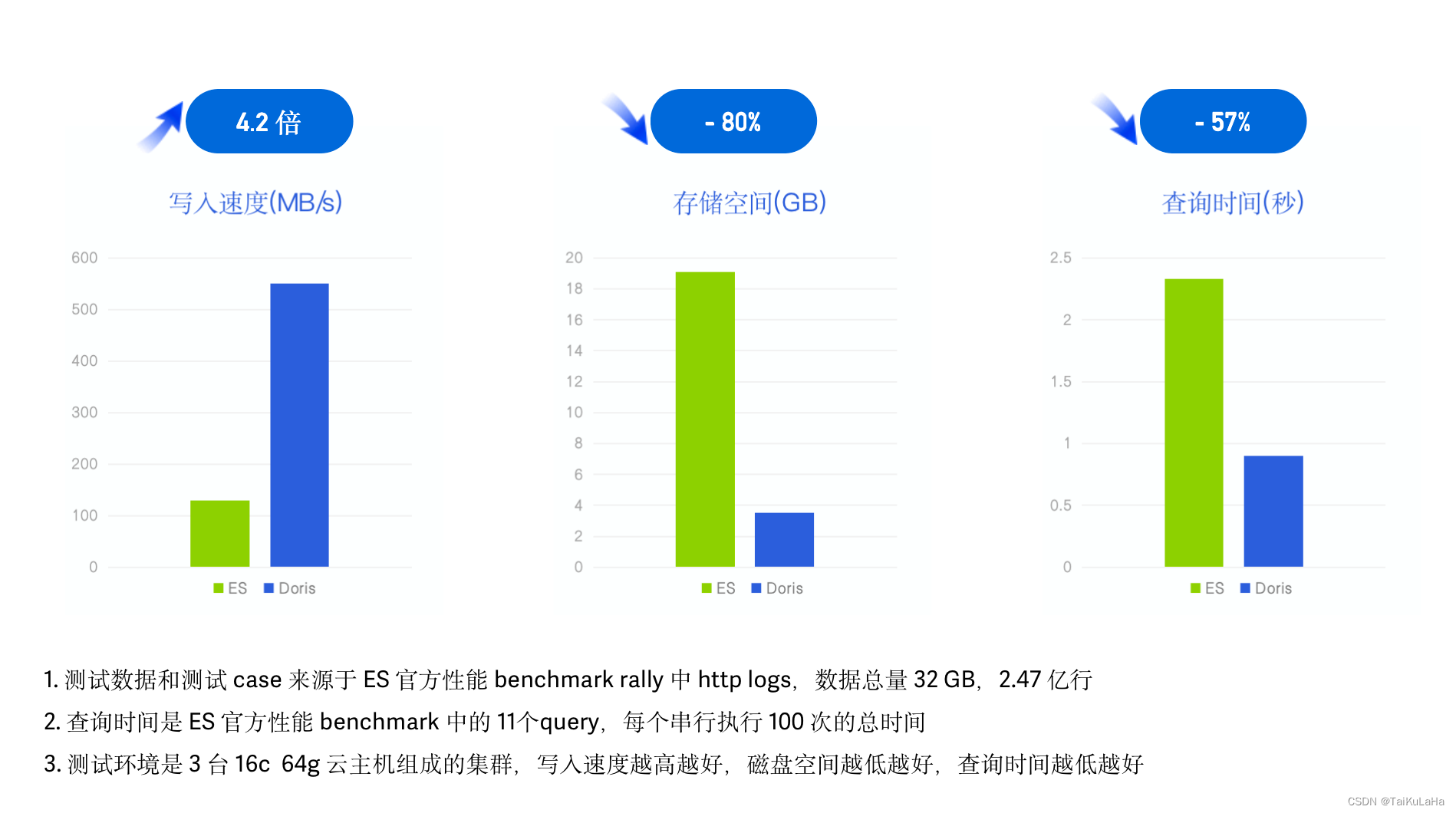
doris vs es
Doris 写入速度是 ES 的 4.2 倍、达到 550 MB/s,写入后的数据压缩比接近 1:10、存储空间 节省 超 80% ,查询耗时下降 57%、查询性能是 ES 的 2.3 倍。加上冷热数据分离降低冷数据存储成本,整体相较 ES 实现 10倍以上的性价比提升。
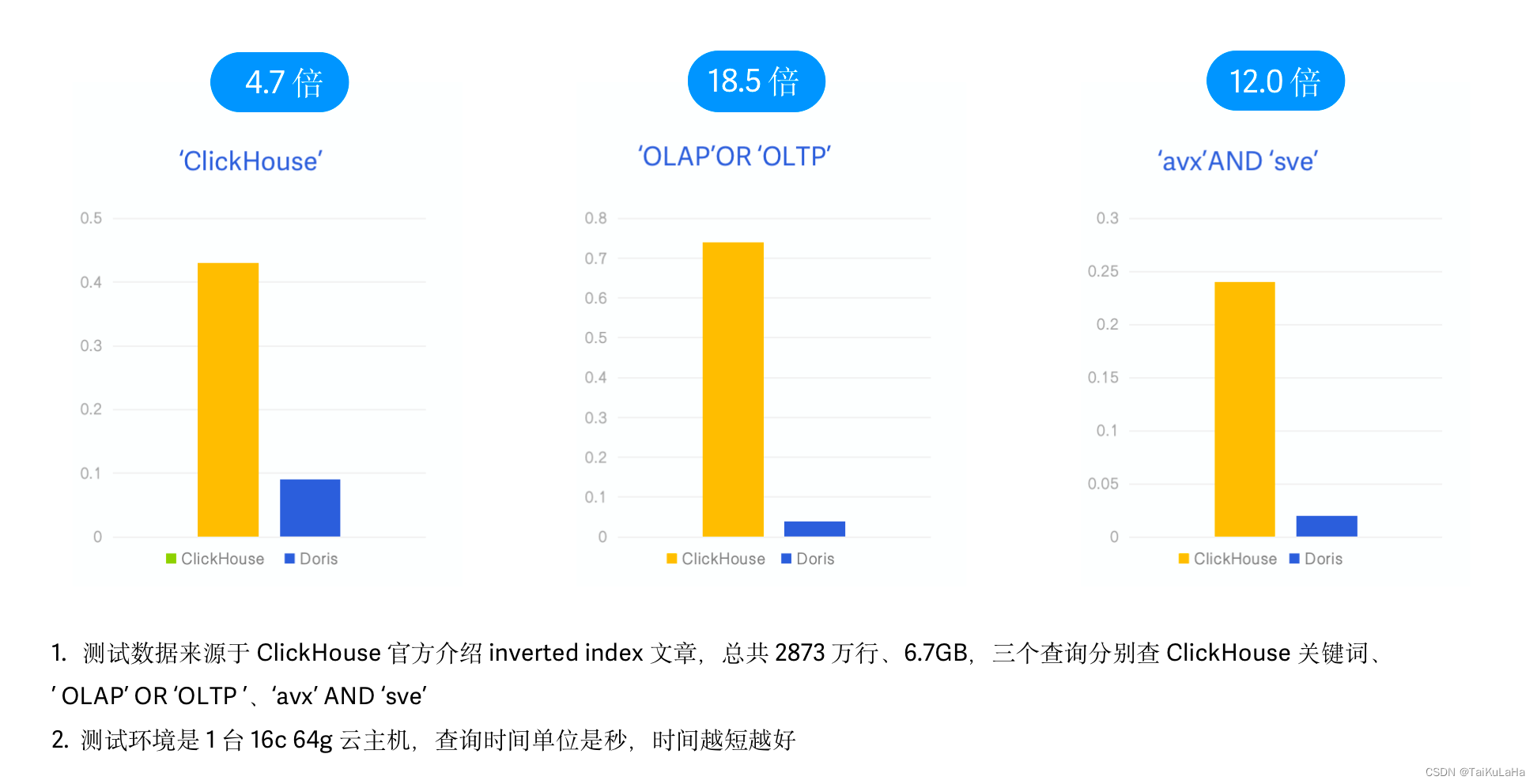
doris vs Clickhouse
在最终的测试结果中,3 个 SQL Apache Doris 的查询性能分别是 Clickhouse 的 4.7 倍、12.0 倍以及 18.5 倍,有明显的性能优势。
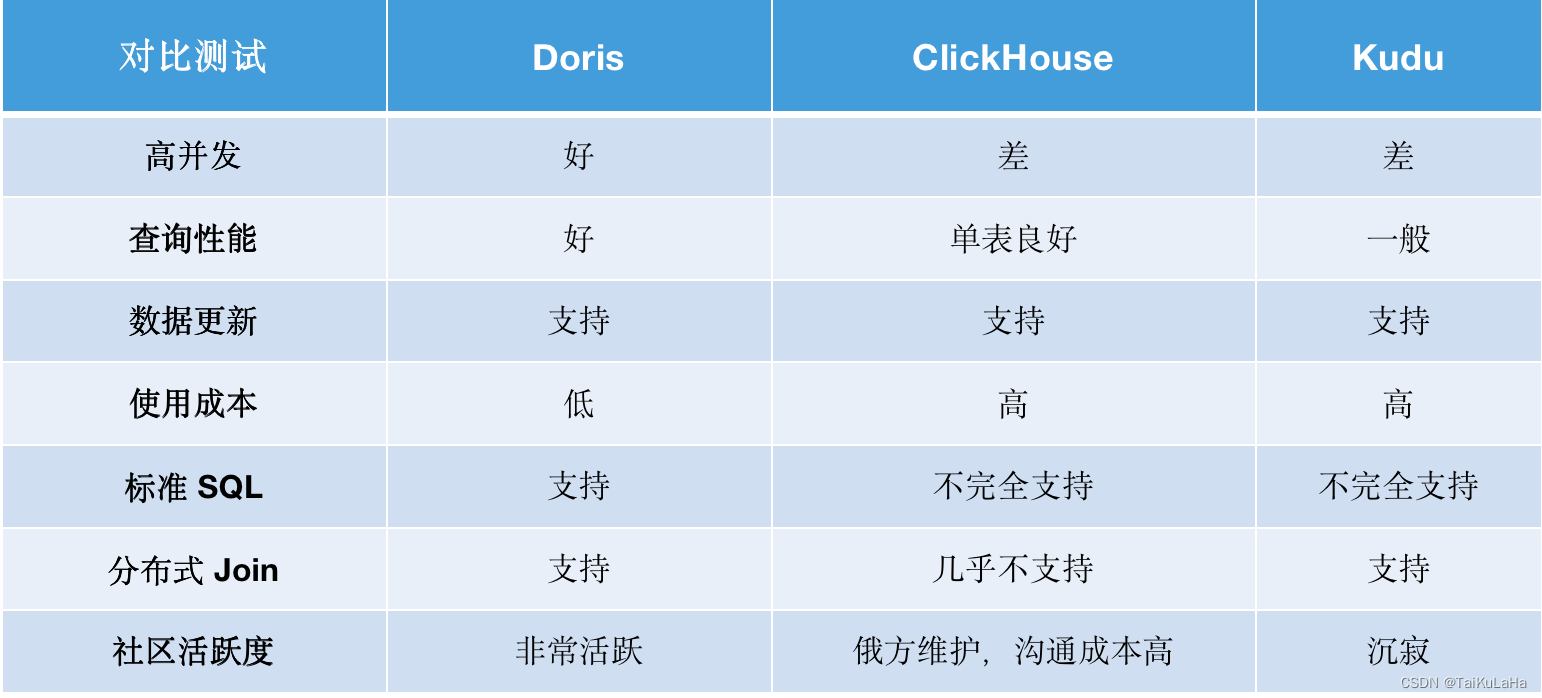
并发提升 10 倍,运算延时降低 70%,领健从 ClickHouse 和 Kudu 到 Apache Doris 数仓升级实践
https://doris.apache.org/zh-CN/blog/linkedcare/
Clickhouse并发问题
ClickHouse 遭遇并发宕机,最初项目选用 ClickHouse 来提供数据查询服务,但在运行过程中 ClickHouse 遭遇了严重的并发问题,即 10 个并发就会导致 ClickHouse 宕机,这使其无法正常为客户提供服务,这是迫使我们寻找可以替代 ClickHouse 产品的关键因素。
业务诉求
- 支持复杂查询:客户进行自助拖拽设计图表时,将生成一段复杂的 SQL 查询语句直查数据库,且语句复杂度未知,这将对数据库带来不小的压力,从而影响查询性能。
- 高并发低延时:至少可以支撑 100 个并发,并在1 秒内得到查询结果;
- 数据实时同步: 报表数据源自于 SaaS 系统,当客户对系统中的历史数据进行修改后,报表数据也要进行同步更改,保持一致,这就要求报表数据要与系统实现实时同步。
- 低成本易部署:SaaS 业务存在私有云客户,为降低私有化部署的人员及成本投入,这要求架构部署及运维要足够简单。