在 Kubernetes 中,各种各样的控制器实现了 Deployment、StatefulSet、Job 等功能强大的 Workload。控制器的核心思想是监听、比较资源实际状态与期望状态是否一致,若不一致则进行协调工作,使其最终一致。
那么当你修改一个 Deployment 的镜像时,Deployment 控制器是如何高效的感知到期望状态发生了变化呢?
要回答这个问题,我们需要从etcd的Watch特性说起,他是Kubernetes控制器的工作基础。
那么实际上我们有4个核心问题:
- client获取事件的机制,etcd是使用轮询模式还是推送模式呢?两者有什么优缺点?
- 事件是如何存储的?会保留多久?watch命令中的版本号有什么作用?
- 当client和server端出现短暂网络波动等异常因素后,导致事件堆积时,server端会丢弃事件吗?如果你监听的历史版本号server端不存在了,你的代码怎么处理?
- 如果你创建了上万个 watcher 监听 key 变化,当 server 端收到一个写请求后,etcd 是如何根据变化的 key 快速找到监听它的 watcher 呢?
接下来我就和你分别详细聊聊 etcd Watch 特性是如何解决这四大问题的。搞懂这四个问题,你就明白 etcd 甚至各类分布式存储 Watch 特性的核心实现原理了。
轮询 VS 流式推送
首先第一个问题是client获取事件机制,etcd是使用轮询还是推送模式呢?答案是etcd两者都使用过。
在etcd v2 Watch机制实现中,使用的是HTTP/1.x协议,实现简单,每一个watcher对应一个TCP连接。client通过HTTP/1.1协议长连接定时轮询server获取最新的数据变化事件。
但是当你的watcher成千上万的时候,即使集群空负载,大量轮询也会产生一定的QPS,server端会消耗大量的socket,内存等资源,导致etcd的稳定性无法满足Kubernetes的要求。
etcd v3 的 Watch 机制的设计实现并非凭空出现,它正是吸取了 etcd v2 的经验、教训而重构诞生的。
在 etcd v3 中,为了解决 etcd v2 的以上缺陷,使用的是基于 HTTP/2 的 gRPC 协议,双向流的 Watch API 设计,实现了连接多路复用。
HTTP/2 协议为什么能实现多路复用呢?
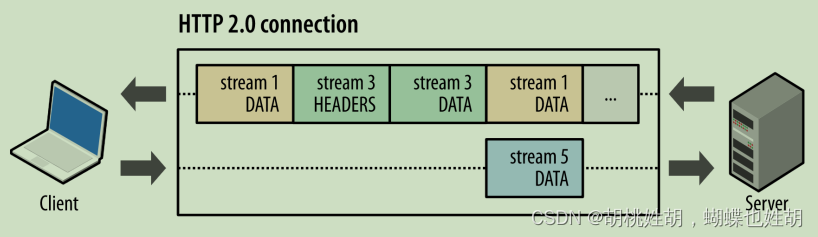
在 HTTP/2 协议中,HTTP 消息被分解独立的帧(Frame),交错发送,帧是最小的数据单位。每个帧会标识属于哪个流(Stream),流由多个数据帧组成,每个流拥有一个唯一的 ID,一个数据流对应一个请求或响应包。
如上图所示,client 正在向 server 发送数据流 5 的帧,同时 server 也正在向 client 发送数据流 1 和数据流 3 的一系列帧。一个连接上有并行的三个数据流,HTTP/2 可基于帧的流 ID 将并行、交错发送的帧重新组装成完整的消息。
通过以上机制,HTTP/2 就解决了 HTTP/1 的请求阻塞、连接无法复用的问题,实现了多路复用、乱序发送。
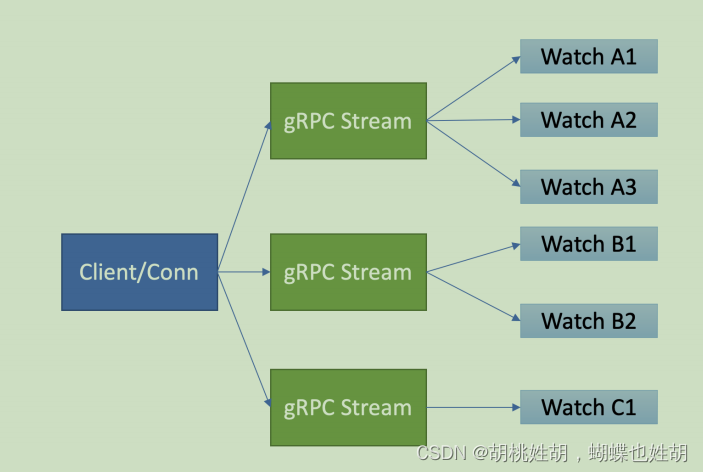
etcd 基于以上介绍的 HTTP/2 协议的多路复用等机制,实现了一个 client/TCP 连接支持多 gRPC Stream, 一个 gRPC Stream 又支持多个 watcher,如下图所示。同时事件通知模式也从 client 轮询优化成 server 流式推送,极大降低了 server 端 socket、内存等资源。
HTTP2.0的详细知识请看《小林coding》
当然在 etcd v3 watch 性能优化的背后,也带来了 Watch API 复杂度上升, 不过你不用担心,etcd 的 clientv3 库已经帮助你搞定这些棘手的工作了。
在 clientv3 库中,Watch 特性被抽象成 Watch、Close、RequestProgress 三个简单API 提供给开发者使用,屏蔽了 client 与 gRPC WatchServer 交互的复杂细节,实现了一个 client 支持多个 gRPC Stream,一个 gRPC Stream 支持多个 watcher,显著降低了你的开发复杂度。
同时当 watch 连接的节点故障,clientv3 库支持自动重连到健康节点,并使用之前已接收的最大版本号创建新的 watcher,避免旧事件回放等。
滑动窗口 VS MVCC
介绍完 etcd v2 的轮询机制和 etcd v3 的流式推送机制后,再看第二个问题,事件是如何存储的? 会保留多久呢?watch 命令中的版本号具有什么作用?
第二个问题的本质是历史版本存储,etcd 经历了从滑动窗口到 MVCC 机制的演变,滑动窗口是仅保存有限的最近历史版本到内存中,而 MVCC 机制则将历史版本保存在磁盘中,避免了历史版本的丢失,极大的提升了 Watch 机制的可靠性。
etcd v2 滑动窗口是如何实现的?它有什么缺点呢?
它使用的是如下一个简单的环形数组来存储历史事件版本,当 key 被修改后,相关事件就会被添加到数组中来。若超过 eventQueue 的容量,则淘汰最旧的事件。在 etcd v2 中,eventQueue 的容量是固定的 1000,因此它最多只会保存 1000 条事件记录,不会占用大量 etcd 内存导致 etcd OOM。
type EventHistory struct {Queue eventQueueStartIndex uint64LastIndex uint64rwl sync.RWMutex
}
但是它的缺陷显而易见的,固定的事件窗口只能保存有限的历史事件版本,是不可靠的。当写请求较多的时候、client 与 server 网络出现波动等异常时,很容易导致事件丢失,client 不得不触发大量的 expensive 查询操作,以获取最新的数据及版本号,才能持续监听数据。
特别是对于重度依赖 Watch 机制的 Kubernetes 来说,显然是无法接受的。因为这会导致控制器等组件频繁的发起 expensive List Pod 等资源操作,导致 APIServer/etcd 出现高负载、OOM 等,对稳定性造成极大的伤害。
etcd v3 的 MVCC 机制,正如上一节课所介绍的,就是为解决 etcd v2 Watch 机制不可靠而诞生。相比 etcd v2 直接保存事件到内存的环形数组中,etcd v3 则是将一个 key 的历史修改版本保存在 boltdb 里面。boltdb 是一个基于磁盘文件的持久化存储,因此它重启后历史事件不像 etcd v2 一样会丢失,同时你可通过配置压缩策略,来控制保存的历史版本数,在压缩篇我会和你详细讨论它。
最后 watch 命令中的版本号具有什么作用呢?
版本号是 etcd 逻辑时钟,当 client 因网络等异常出现连接闪断后,通过版本号,它就可从 server 端的 boltdb 中获取错过的历史事件,而无需全量同步,它是 etcd Watch 机制数据增量同步的核心。
可靠的事件推送机制
再看第三个问题,当 client 和 server 端出现短暂网络波动等异常因素后,导致事件堆积时,server 端会丢弃事件吗?若你监听的历史版本号 server 端不存在了,你的代码该如何处理?
第三个问题的本质是可靠事件推送机制,要搞懂它,我们就得弄懂 etcd Watch 特性的整体架构、核心流程,下图是 Watch 特性整体架构图。
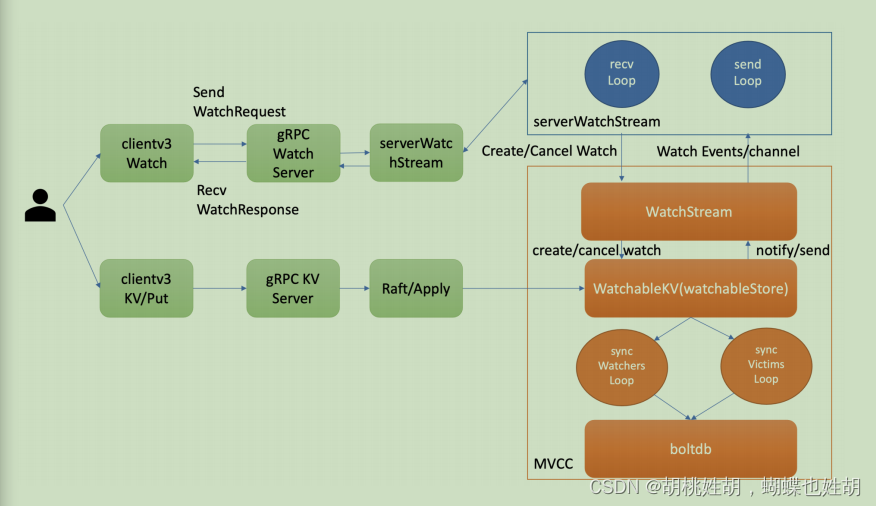
当你通过 etcdctl 或 API 发起一个 watch key 请求的时候,etcd 的 gRPCWatchServer收到 watch 请求后,会创建一个 serverWatchStream, 它负责接收 client 的 gRPC Stream 的 create/cancel watcher 请求 (recvLoop goroutine),并将从 MVCC 模块接收的 Watch 事件转发给 client(sendLoop goroutine)。
当 serverWatchStream 收到 create watcher 请求后,serverWatchStream 会调用MVCC 模块的 WatchStream 子模块分配一个 watcher id,并将 watcher 注册到 MVCC的 WatchableKV 模块。
在 etcd 启动的时候,WatchableKV 模块会运行 syncWatchersLoop 和syncVictimsLoop goroutine,分别负责不同场景下的事件推送,它们也是 Watch 特性可靠性的核心之一。
从架构图中你可以看到 Watch 特性的核心实现是 WatchableKV 模块,下面我就为你抽丝剥茧,看看"etcdctl watch hello -w=json --rev=1"命令在 WatchableKV 模块是如何处理的?面对各类异常,它如何实现可靠事件推送?
etcd核心解决方案是复杂度管理,问题拆分
它通过将 watcher 划分为synced/unsynced/victim 三类,将问题进行了分解,并通过多个后台异步循环goroutine 负责不同场景下的事件推送,提供了各类异常等场景下的 Watch 事件重试机制,尽力确保变更事件不丢失、按逻辑时钟版本号顺序推送给 client。
高效事件匹配机制
介绍完可靠的事件推送机制后,最后我们再看第四个问题,如果你创建了上万个 watcher监听 key 变化,当 server 端收到一个写请求后,etcd 是如何根据变化的 key 快速找到监听它的 watcher 呢?一个个遍历 watcher 吗?
显然一个个遍历 watcher 是最简单的方法,但是它的时间复杂度是 O(N),在 watcher 数较多的场景下,会导致性能出现瓶颈。更何况 etcd 是在执行一个写事务结束时,同步触发事件通知流程的,若匹配 watcher 开销较大,将严重影响 etcd 性能。
那使用什么数据结构来快速查找哪些 watcher 监听了一个事件中的 key 呢?
也许你会说使用 map 记录下哪些 watcher 监听了什么 key 不就可以了吗? etcd 的确使用 map 记录了监听单个 key 的 watcher,但是你要注意的是 Watch 特性不仅仅可以监听单 key,它还可以指定监听 key 范围、key 前缀,因此 etcd 还使用了如下的区间树。
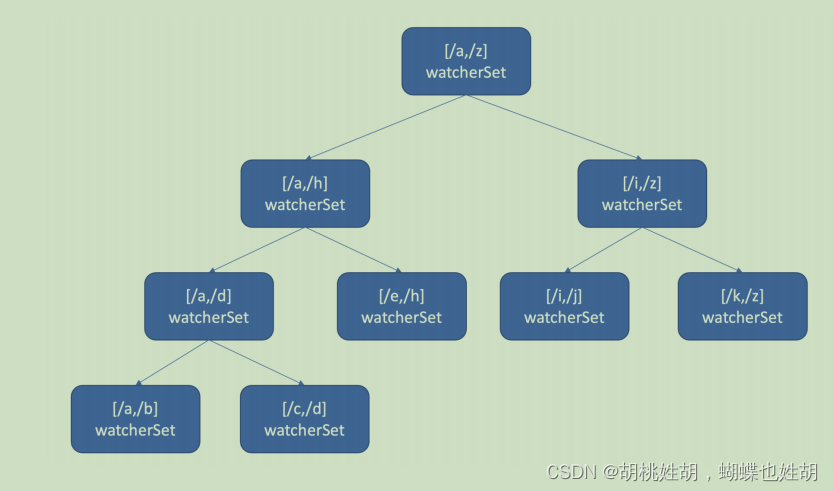
当收到创建 watcher 请求的时候,它会把 watcher 监听的 key 范围插入到上面的区间树中,区间的值保存了监听同样 key 范围的 watcher 集合 /watcherSet。
当产生一个事件时,etcd 首先需要从 map 查找是否有 watcher 监听了单 key,其次它还需要从区间树找出与此 key 相交的所有区间,然后从区间的值获取监听的 watcher 集合。
区间树支持快速查找一个 key 是否在某个区间内,时间复杂度 O(LogN),因此 etcd 基于map 和区间树实现了 watcher 与事件快速匹配,具备良好的扩展性。