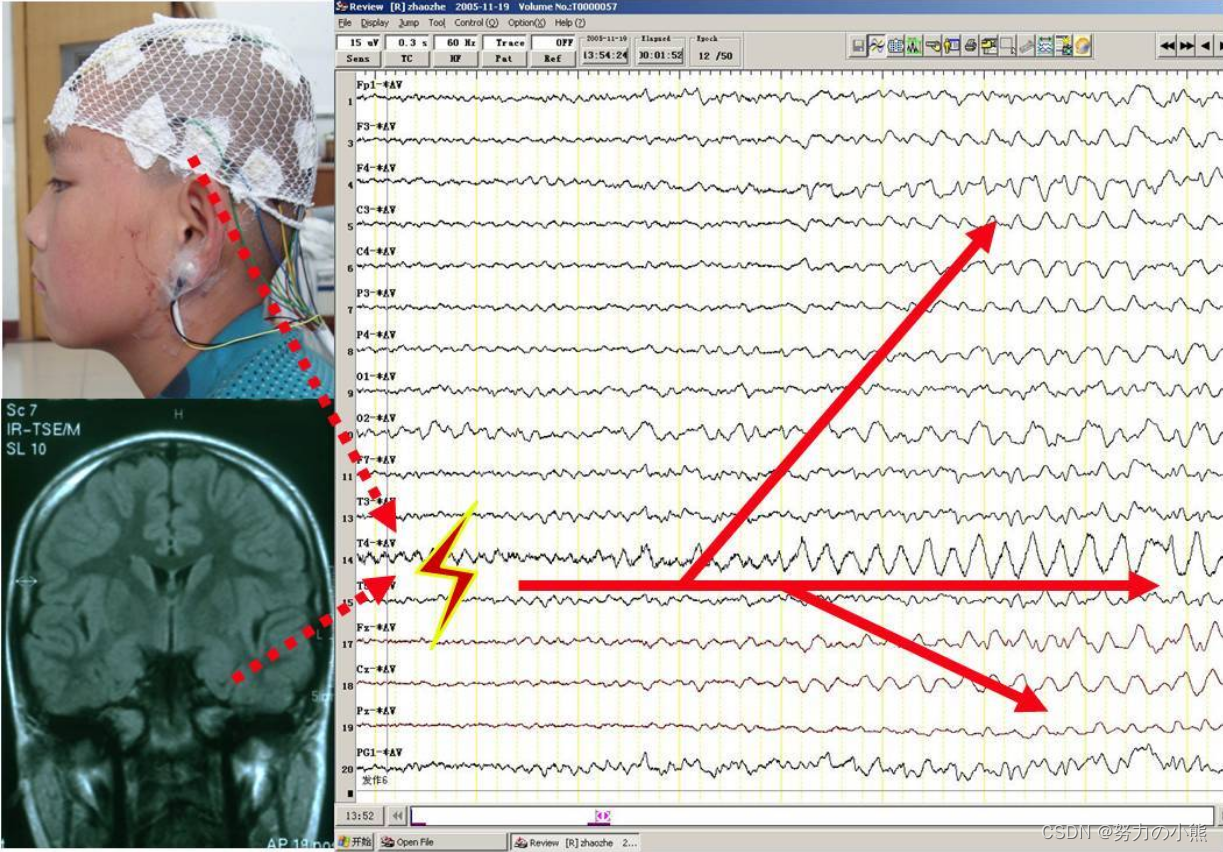
是个脑电信号研究小白,今年3月下旬临时换了研究方向,到现在也看了不少论文,试过一些特征提取的代码还有分类的代码。现在也想总结一下这段时间所学的东西,算是做个中期回顾吧。
Ps:里面的特征提取的代码以及分类的代码均不是我所写的,后面会附上链接,可以直接去找链接,还有一些工具包,等会上传上去,应该是可以免费拿的,第一次弄,我还没怎么搞清楚。
Pps:这篇主要是汇总一些方法,还有代码链接等等。均适用于Matlab
No.1 脑电信号分析的大致流程
大致流程是:脑电信号采集,预处理,特征提取,特征筛选(我看有的文章并没有这一块,所以主要看自己吧),分类,得出结果进行分析。
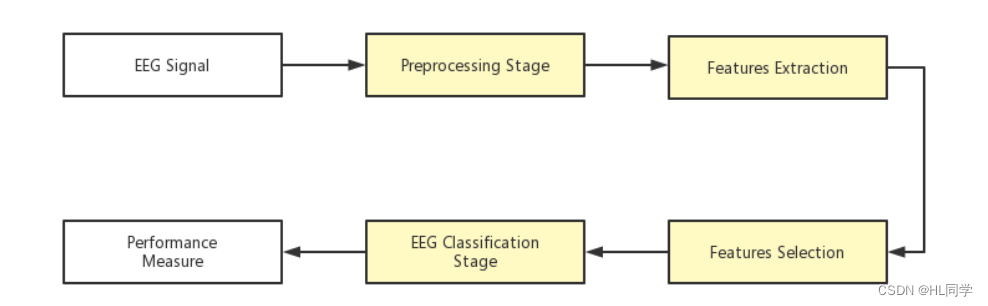
流程这一块大同小异,在脑电信号这一块大部分都是这个流程。
No.2 预处理
预处理这一块我就不做过多的详解了,我接触的不多,只是尝试过使用EMD以及EEMD做噪声剔除。
在预处理这一块,主要是剔除噪声和伪影,伪影包括眼动,肌动,心动等伪影,可以采用一些方法进行剔除,如我前面所讲的EMD和EEMD,还有PCA,ICA,ANOVA等也可以进行剔除,稍后我把EMD和EEMD的工具包上传,应该可以免费获取。
Ps:EEMD是EMD的进化,里面可以尽量避免模态混叠,但是感觉好像两者没啥太大的区别,但也有可能是我研究的这一块看起来没啥太大的区别。
我目前在网上以及文献里看到采用EMD和EEMD进行去噪去伪影的方法是,采用这些方法将原始信号分解成多个imf,随后对分解的imf进行相关性分析,得出相关系数,然后对所有的imf的相关系数求取std,随后将其设置为阈值进行筛选,大于阈值的留下,小于阈值的剔除。最后将筛选出来的imf进行重构(相加)得出一个新的信号,这个新的信号就是剔除噪声和伪影的信号。
附上链接:EEMD算法原理及应用_Zhi Zhao的博客-CSDN博客_eemd算法
No.3 特征提取
特征提取主要分为时域,频域,时频域,非线性动力学等。时域的特征有SSA(奇异值),ERP(事件相关电位)等,频域有PSD等,时频有小波变换,小波包变换等,非线性动力学特征有各种熵,比如模糊熵FuzzyEn,样本熵SaEn,近似熵ApEn,排列熵PEn等等。
附上链接1:非线性动力学特征的代码
关于熵的一个总结_人间不想清醒的博客-CSDN博客_matlab多尺度熵
【熵与特征提取】从近似熵,到样本熵,到模糊熵,再到排列熵,究竟实现了什么?(第一篇)——“近似熵”及其MATLAB实现 - 知乎 (zhihu.com)
附上链接2:PSD的代码
数字信号中功率谱估计相关方法简介及MATLAB实现_cqfdcw的博客-CSDN博客_信号功率谱matlab
Ps: 可以直接用Welch法来计算功率谱密度
No.4 特征筛选
特征筛选就是将求取的特征进行相关性分析,将P<0.05的特征提取出来进行下一步分类的分析。因为统计学上认为P<0.05具有显著性差异,否则没有。相关性分析可以直接调用Matlab的函数corr。调用格式为
[R,p_value] = corr(data,'Type','spearman') %spearman可以替代为pearson或者Kendall,默认类型为pearson型附上链接:matlab相关性分析(皮尔逊,肯德尔,斯皮尔曼) - 知乎 (zhihu.com)
No.5 分类
分类是我接触脑电信号研究的第一个模块,最先接触的分类器是SVM。目前感觉最好用的SVM是Libsvm,是一个工具包,稍后附上Libsvm下载的官网地址以及如何激活等。
当然分类器还有DT(决策树),RF(随机森林),KNN等。
分类主要分为机器学习和深度学习两大类
| 种类 | 分类器 |
|---|---|
| 机器学习 | DT(决策树) |
| RF(随机森林) | |
| SVM(支持向量机) | |
| KNN(K近邻) | |
| LDA(线性判别分析) | |
| 深度学习 | 多层感知机 |
| LSTM(长短期记忆网络) | |
| 各种神经网络 (卷积神经网络,循环神经网络等) |
分类器就是首先将每个样本打上标签,标签自行定义。
随后将样本随机打乱分为test测试集和train训练集。分类器对训练集进行训练,得出一个模型,然后将test测试集放入到模型里进行测试,得出准确率。
分类一般分为二分类和多分类。二分类可以直接调用Matlab自带的函数。多分类则需要进行一定的更改,当然也可以不更改,比如RF,就可以直接调用Treebagger进行多分类。格式如下
%% all 随机森林模型
a_randomforest = TreeBagger(100, Traindata, Traindata_label,'Method','classification');
[a_randomforest_pred, outcome] = predict(a_randomforest, Testdata); % outcome 是概率输出% a_randomforest,a_randomforest_pred, Traindata, Traindata_label,Testdata为自行定义的名称,可根据自己喜好进行更改。
% a_randomforest:训练的模型
% a_randomforest_pred:预测的结果
% Traindata:训练的数据
% Traindata_label:训练数据的标签
% Testdata:测试的数据
附上链接:Libsvm的多分类代码示例以及Libsvm安装包如何安装的案例
SVM多分类问题 libsvm在matlab中的应用_lwwangfang的博客-CSDN博客_matlab svm多分类
LIBSVM在Matlab下的使用_xiaopihaierletian的博客-CSDN博客_libsvmread
Over!
先讲这些,后面又找到一些,学习完后,再进行归纳总结。
欢迎提问!