文章目录
- 一、多表查询
- 二、自连接
- 三、子查询
- 1.单行子查询
- 2.多行子查询
- 3.多列子查询
- 4.在from子句中使用子查询
- 四、合并查询
一、多表查询
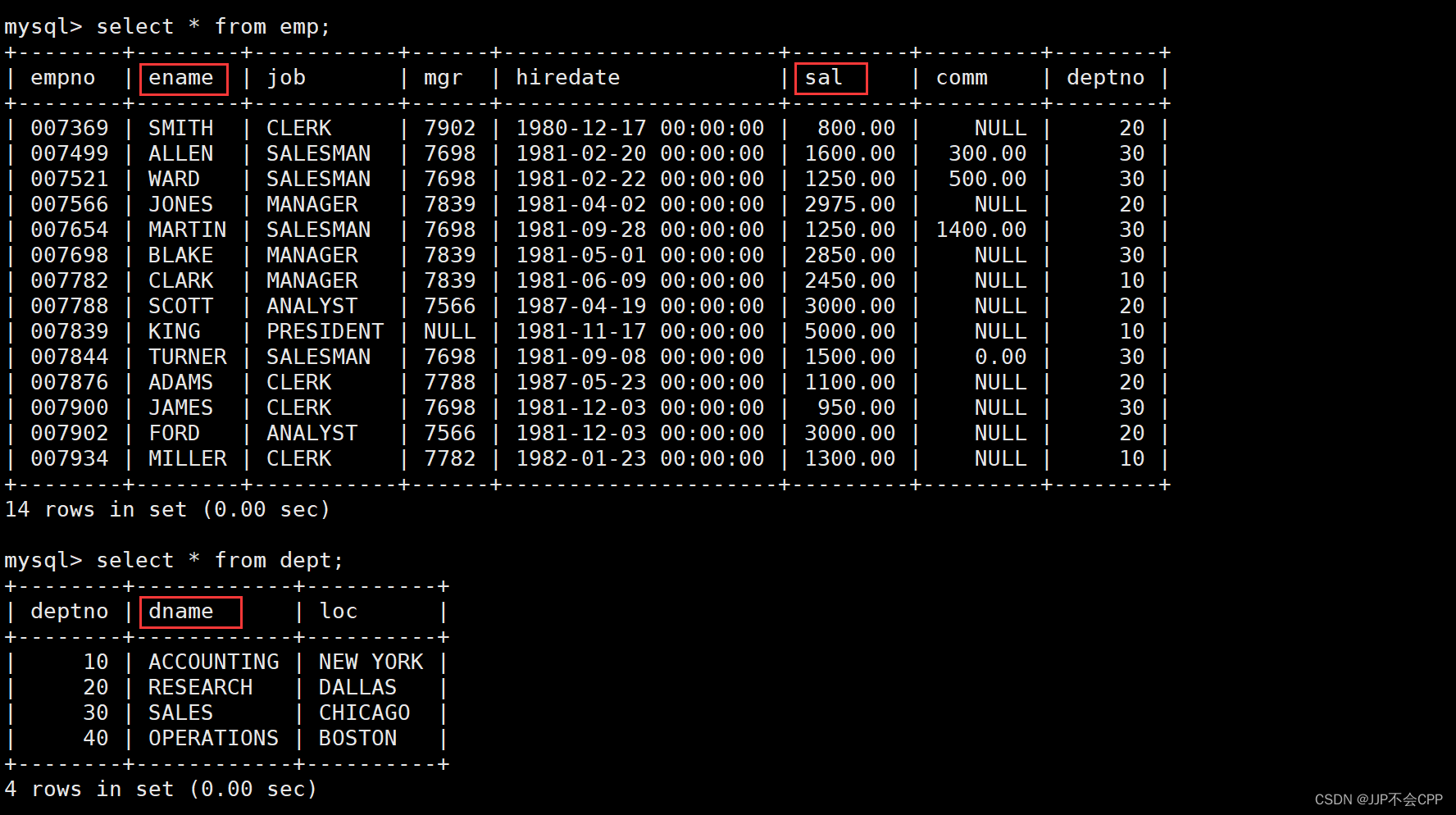
在实际开发中,我们需要查询的数据往往会来自不同的表,所以需要进行多表查询。下面我们用一个简单的公司管理系统,有emp、dept、salgrade三张表,来演示如何进行多表查询。
案例一:
显示雇员名、雇员工资以及所在部门的名字。
由于雇员名和雇员工资在emp表中,雇员所在的部门在dept表中,所以需要进行两张表的联合查询。
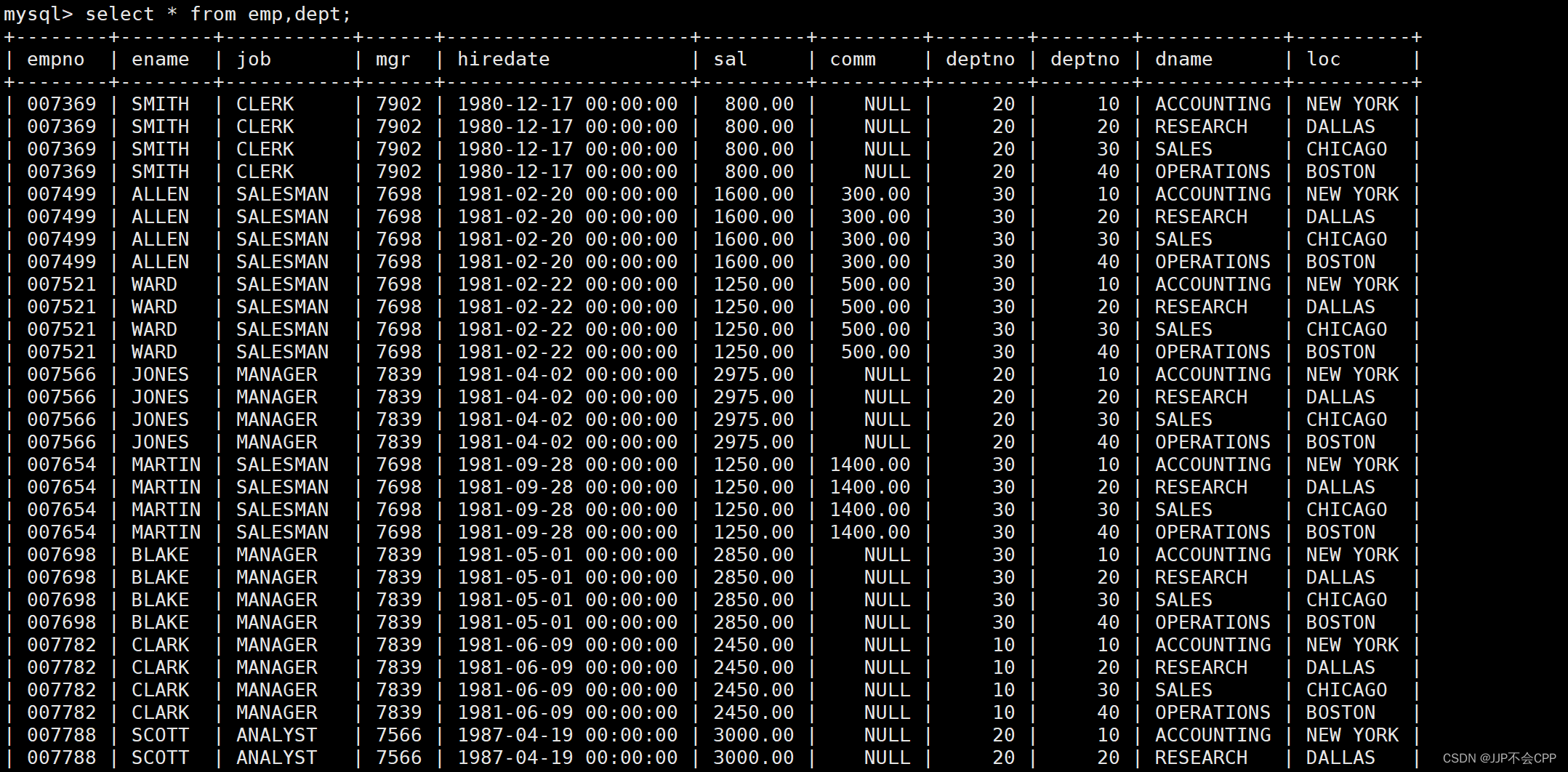
MySQL的select语句其实不是一次只能查询一张表,它可以一次性查询多张表,表与表之间用逗号隔开,例如我们想要查找emp表和dept表,输入指令select * from emp,dept;即可查询到两张表的组合:
上表的组合方式是,先从第一张表即emp表中选出第一条记录,和第二张表即dept表中的所有记录进行组合。然后从第一张表中选第二条记录,和第二张表中的所有记录进行组合。不加过滤条件,最后得到的结果称为笛卡尔积。
多表查询,将多张表的结果进行组合,形成笛卡尔积,它的本质是对表中所有数据的穷举。既然我们得到了这些笛卡尔积,有了所有数据组合的穷举内容,那么我们就可以添加过滤条件,筛选出我们需要查询的数据。
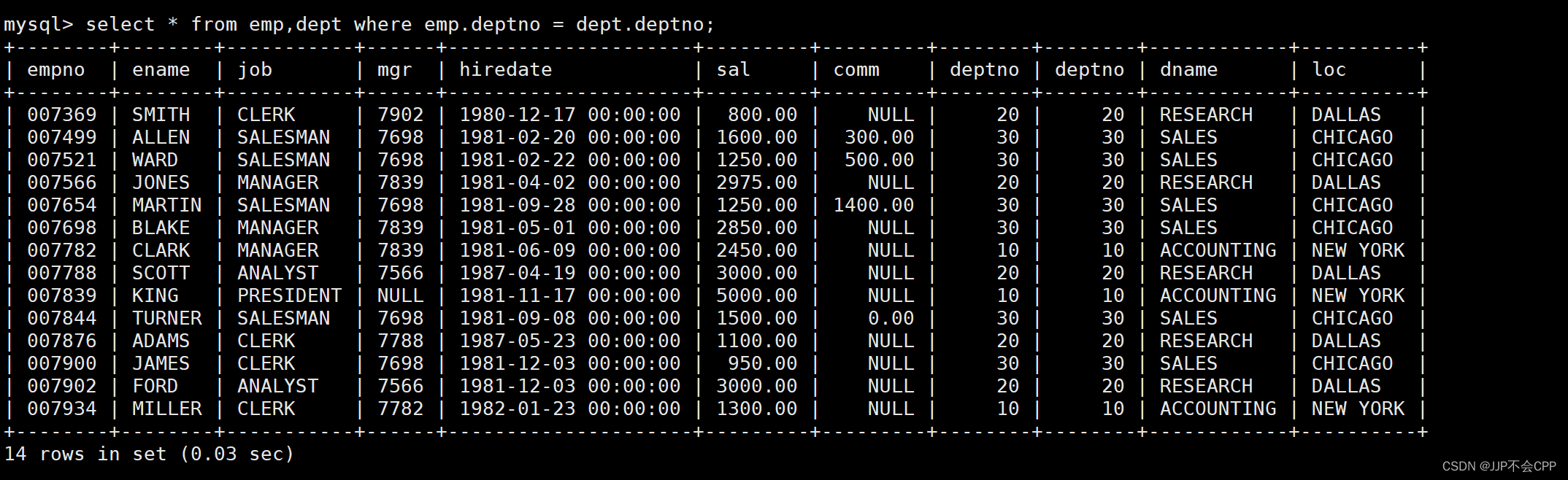
回到案例中的题面,它需要我们查询雇员名和雇员工资以及所在部门的名字,但是我们将两张表组合出来的时候,会出现两个deptno字段,只有两个的deptno相等的数据才是我们需要的。所以我们需要首先筛选出这样的数据,输入指令select * from emp,dept where emp.deptno = dept.deptno;即可。
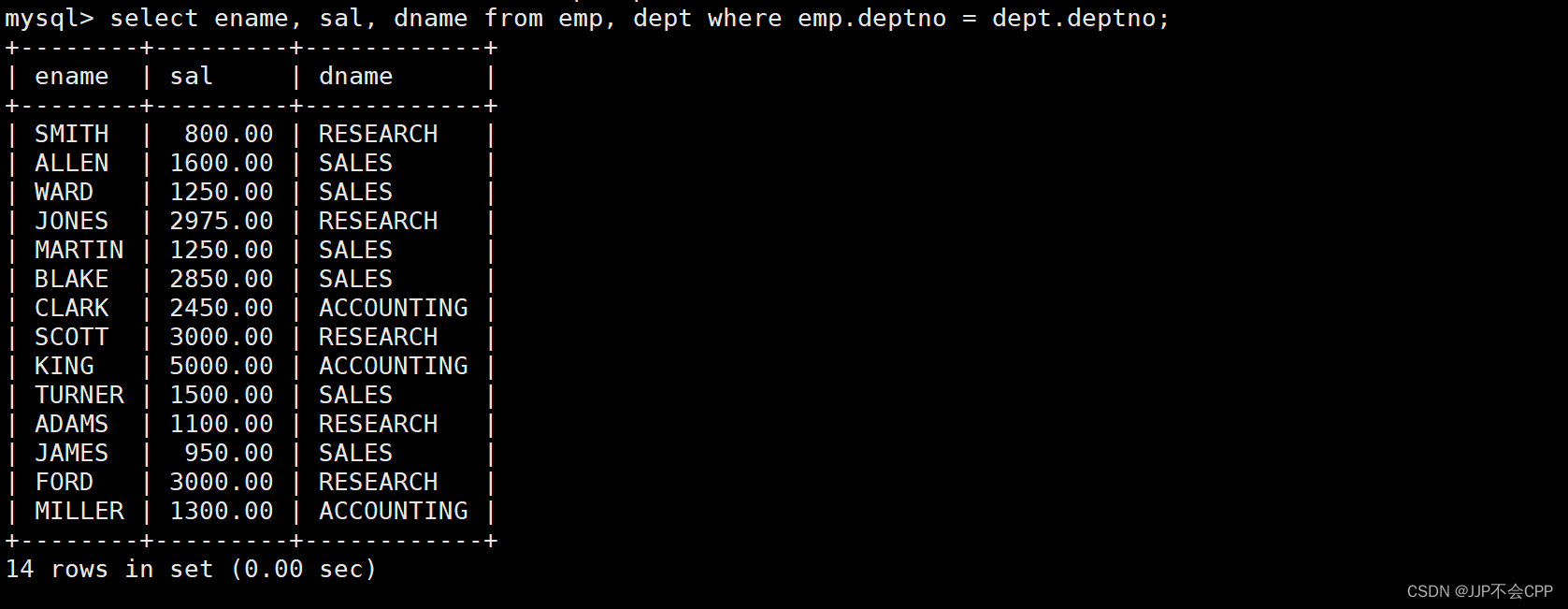
最后我们再筛选出雇员姓名、工资以及所在部门,输入指令select ename, sal, dname from emp, dept where emp.deptno = dept.deptno;即可。
案例二:
显示部门号为10的部门名、员工名和工资。
这道题也不难,只需要再加上部门号为10这一限制条件即可,输入指令select ename, sal, dname from emp, dept where emp.deptno = dept.deptno and dept.deptno = 10;即可。

二、自连接
同一张表自己和自己连接称为自连接,指的是在同一张表中连接查询。也就是说依旧是使用多表查询,只不过查询的两张表是同一张表。我们可以尝试一下,输入指令select * from emp, emp;,我们会发现报错了,查询不了。原因是两张相同的表有重复的冲突元素。

解决这个问题,我们可以将两张相同的表分别重命名为两个不一样的名字,输入指令select * from emp as e1, emp as e2;
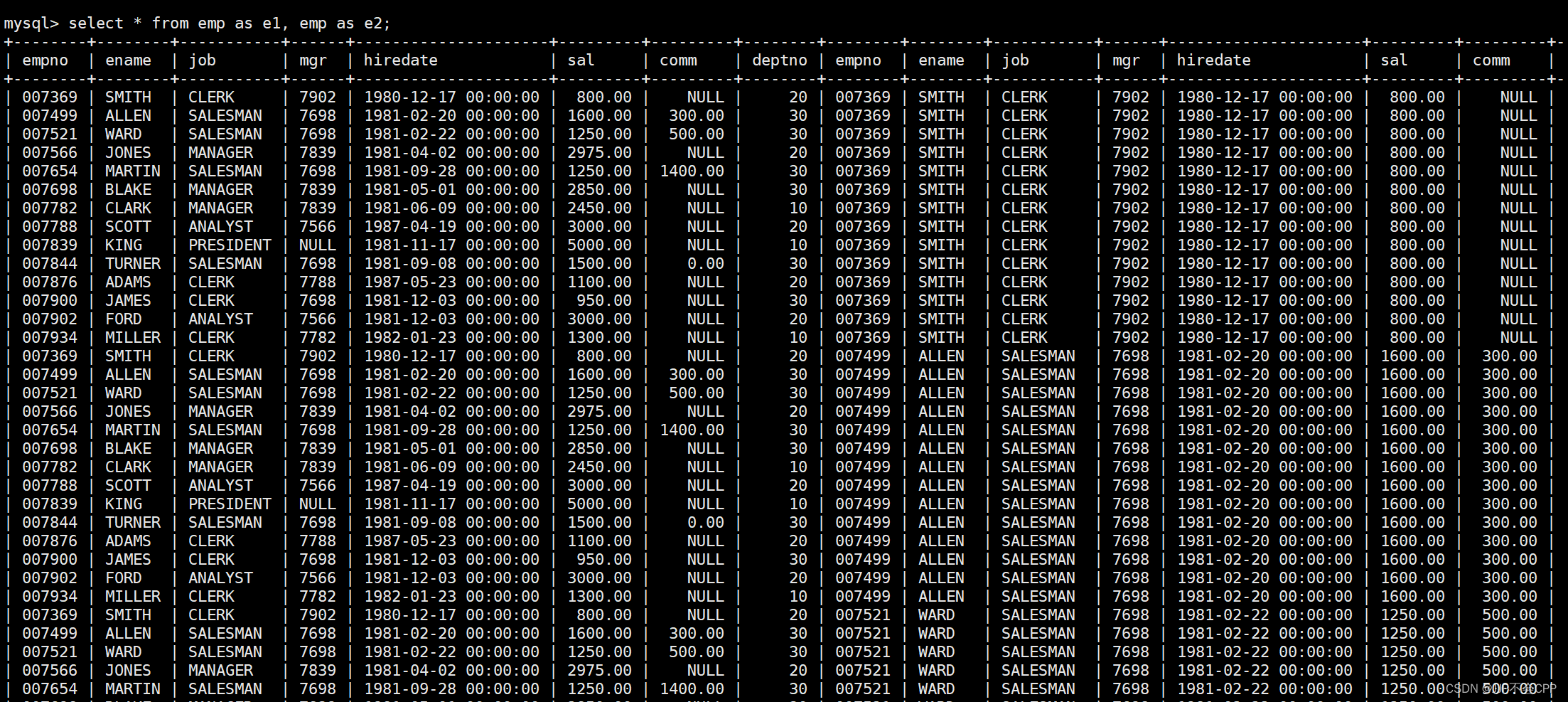
这样就实现了自连接查询。假如我们想在emp表中查询员工FORD的上级领导的编号和姓名,使用自连接查询,其中mgr是员工领导的编号,所以我们首先要查找员工领导编号mgr和该员工自己的编号empno相等的数据,输入指令select * from emp e1, emp e2 where e1.mgr = e2.empno;
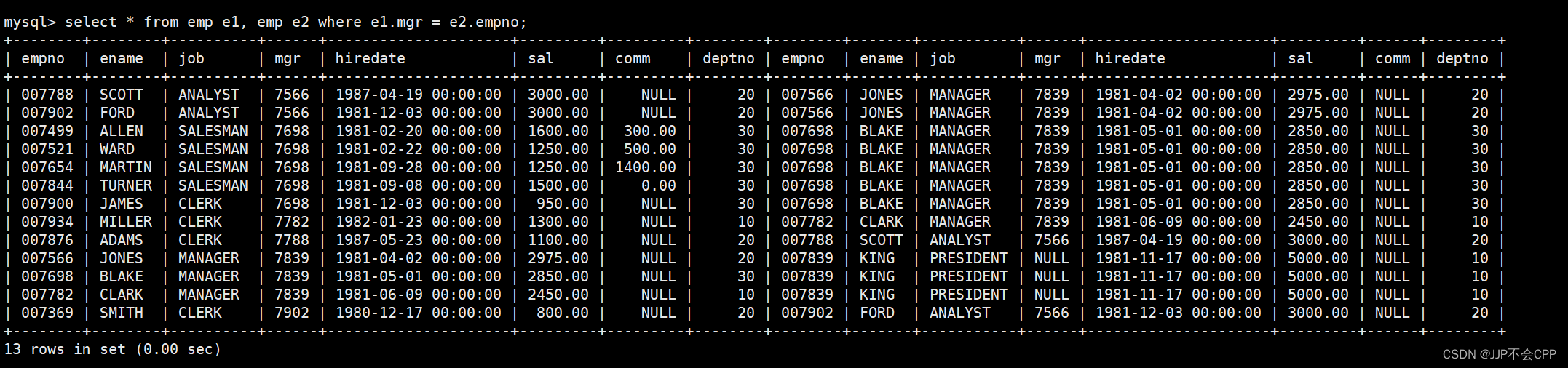
接下来我们需要在上面查询结果的基础上,再添加员工名为FORD的限制条件,因为我们是要查询FORD员工的上级领导编号和姓名,输入指令select * from emp e1, emp e2 where e1.mgr = e2.empno and e1.ename = 'FORD';

最后再查询FORD上级领导的编号和姓名,输入指令:
select e2.ename, e2.empno from emp e1, emp e2 where e1.mgr = e2.empno and e1.ename = 'FORD';

三、子查询
子查询是指嵌入在其它SQL语句中的select语句,也叫作嵌套查询。子查询分为单行子查询和多行子查询。
1.单行子查询
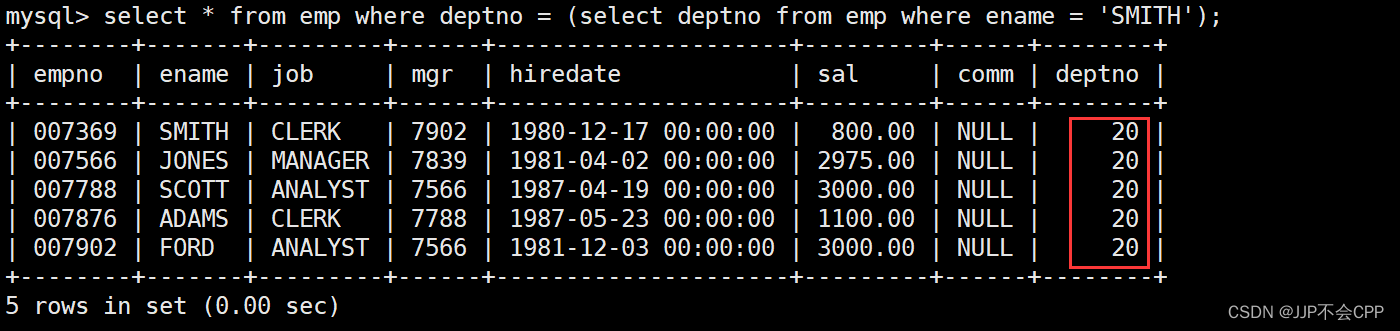
例如我们想要查询在emp表中和SMITH同一部门的员工,使用子查询的话,可以将SMITH的部门编号拿出来,再与表中所有员工的部门编号进行对比,找出与SMITH部门编号相同的员工。输入语句select * from emp where deptno = (select deptno from emp where ename = 'SMITH');
2.多行子查询
单行子查询有时候不能满足我们的需求,一般我们需要使用多行子查询。多行子查询是可以返回多行记录的子查询,多行子查询需要用到in关键字、all关键字、any关键字,下面分别介绍这三个关键字的使用。
in关键字:
in关键字的基本语法如下,列名+in后面跟一条select语句的子查询,它代表的是只要列名在后面子查询的集合中,就显示出来。
列名 in (select ......)
例如我们想要在emp表中查询和10号部门的工作岗位相同的雇员的名字、岗位、工资和部门号,但是不包括10号部门自己的。
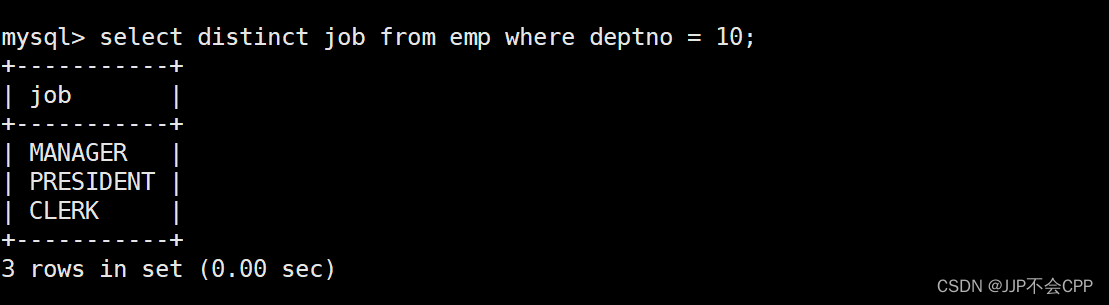
做这道题首先可以查找出emp表中部门号为10的所有员工的工作岗位,输入语句select distinct job from emp where deptno = 10;
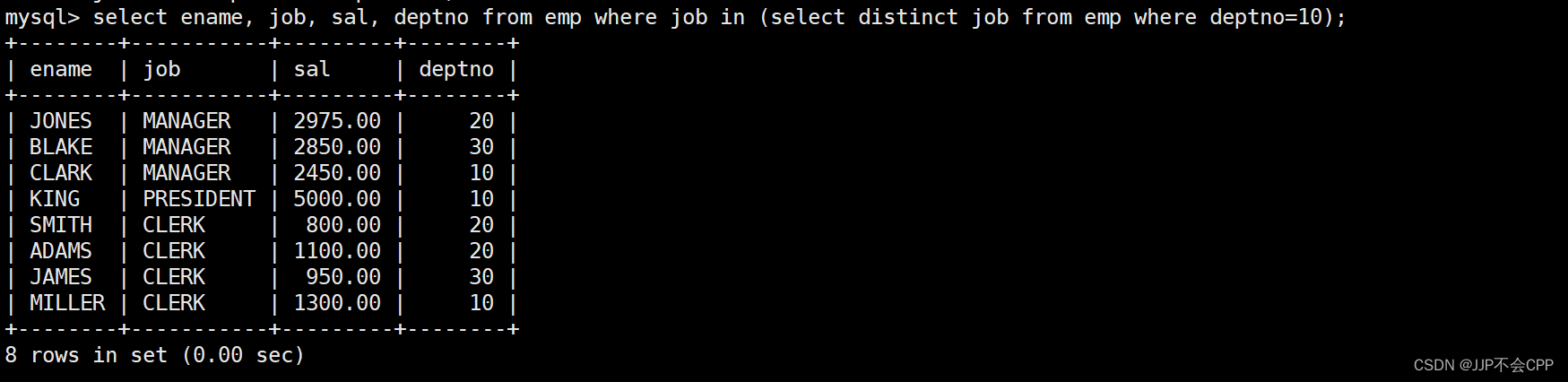
选择出来之后,我们再用in关键字,选择出job列属于上述结果的员工,显示他们的名字、岗位、工资和部门号,输入语句select ename, job, sal, deptno from emp where job in (select distinct job from emp where deptno = 10);
最后,题目要求查询结果不包括部门编号为10本身,所以我们可以再将上述查找出的结果加上deptno不等于10的限制条件即可。输入语句select ename, job, sal, deptno from emp where (job in (select distinct job from emp where deptno = 10)) and (deptno != 10);

all关键字:
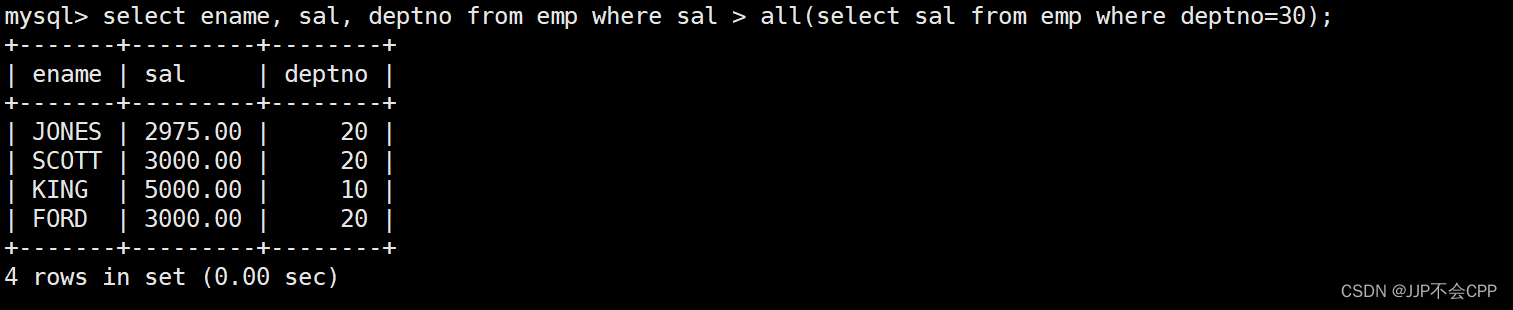
all关键字的基本语法和in关键字一样,all后面跟一条select语句的子查询,它代表的是选出select语句集合中的所有元素。例如我们想要显示工资比部门30的所有员工的工资高的员工姓名、工资和部门号,输入语句select ename, sal, deptno from emp where sal > all(select sal from emp where deptno=30);这里使用的all关键字,代表的意思是从emp表中选择薪资大于后面子查询集合的所有工资。
any关键字:
any关键字的使用和all关键字的使用相似,只不过二者在含以上有区别。举个例子,如果我们要选择比所有学生成绩都高的学生,就要使用all关键字。如果我们要选择比任意一个学生成绩都高的学生,就要使用any关键字。all关键字选择出来的一定是比集合里最高成绩的学生还要高的,any关键字选择出来的只要比集合里最低成绩的学生还要高的就可以了。
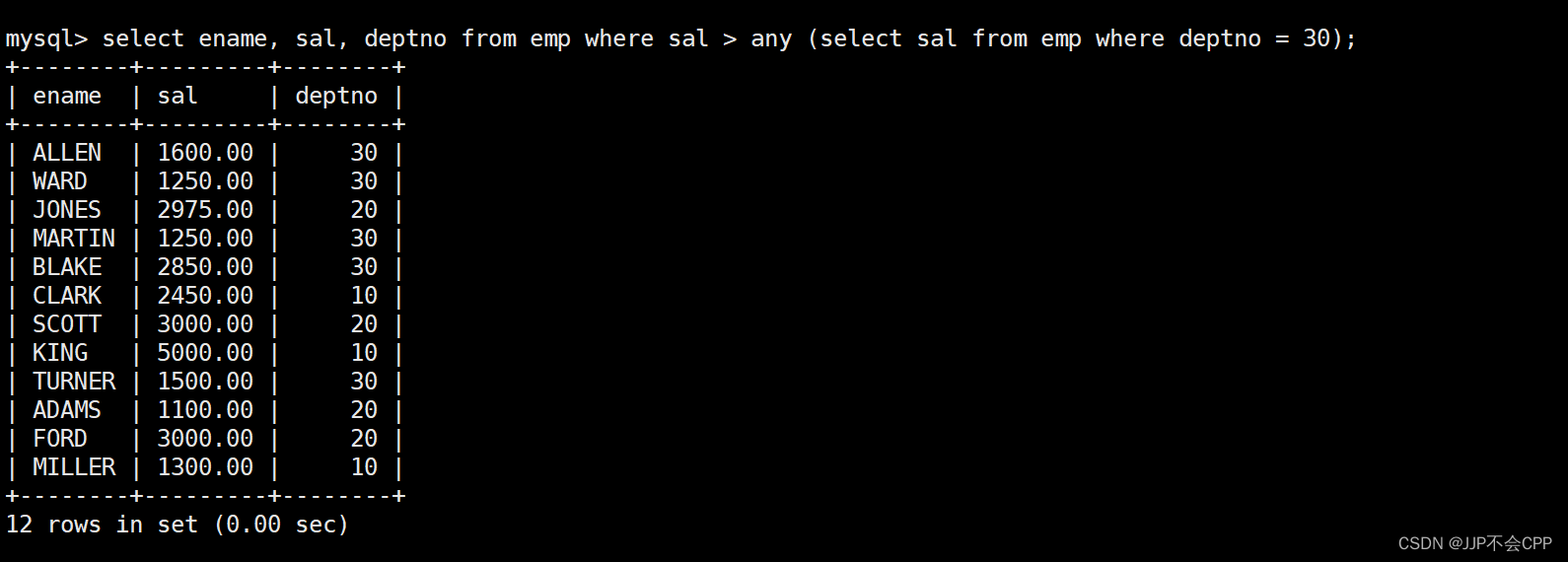
例如我们想在emp表中显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工),输入语句select ename, sal, deptno from emp where sal > any (select sal from emp where deptno = 30);
3.多列子查询
单行子查询是指子查询返回的集合中只会是单列单行的数据,例如上面说的查询和SMITH同一部门的员工,子查询返回的是SMITH的部门编号,是单列单行数据。多行子查询是指子查询返回的集合中是单列多行的数据,例如上面说的查询和10号部门的工作岗位相同的雇员名字、岗位、工资和部门号,子查询返回的是部门号为10的所有员工的工作岗位,是单列多行数据。而多列子查询是指子查询返回的是多个列的数据。
例如我们想要查询和SMITH的部门和岗位完全相同的所有雇员,不包含SMITH本人。
这个题目首先要查出SMITH的部门和岗位,输入语句select job, deptno from emp where ename = 'SMITH';

然后我们查询和SMITH的部门和岗位完全相同的所有雇员,多列查询可以使用如下类型的语句:select * from emp where (job, deptno) = (select job, deptno from emp where ename = 'SMITH');

最后,由于题目要求查询结果不包含SMITH,所以输入语句select * from emp where ((job, deptno) = (select job, deptno from emp where ename = 'SMITH')) and ename != 'SMITH';

4.在from子句中使用子查询
我们前面用到的子查询都是放在where子句中,from子句中也可以使用子查询。这里要用到数据查询的一个技巧,即把一个子查询当作一个临时表来使用。
例如,我们想显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资。
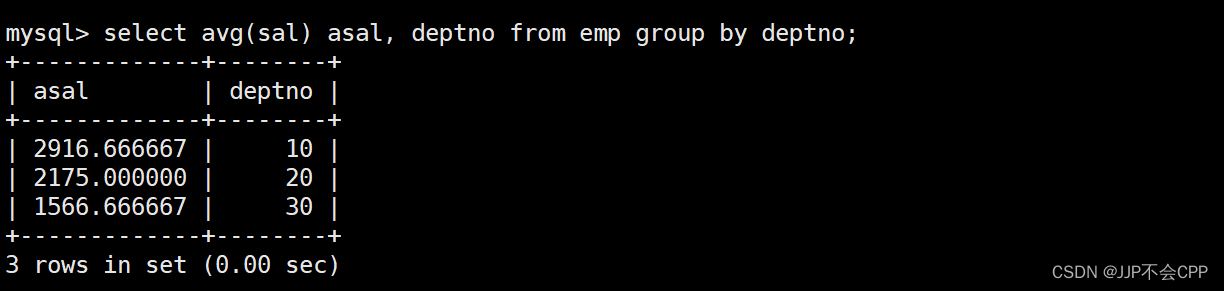
这道题目我们逐层分解的话,首先需要查询到各个部门的平均工资,输入语句select avg(sal) asal, deptno from emp group by deptno;
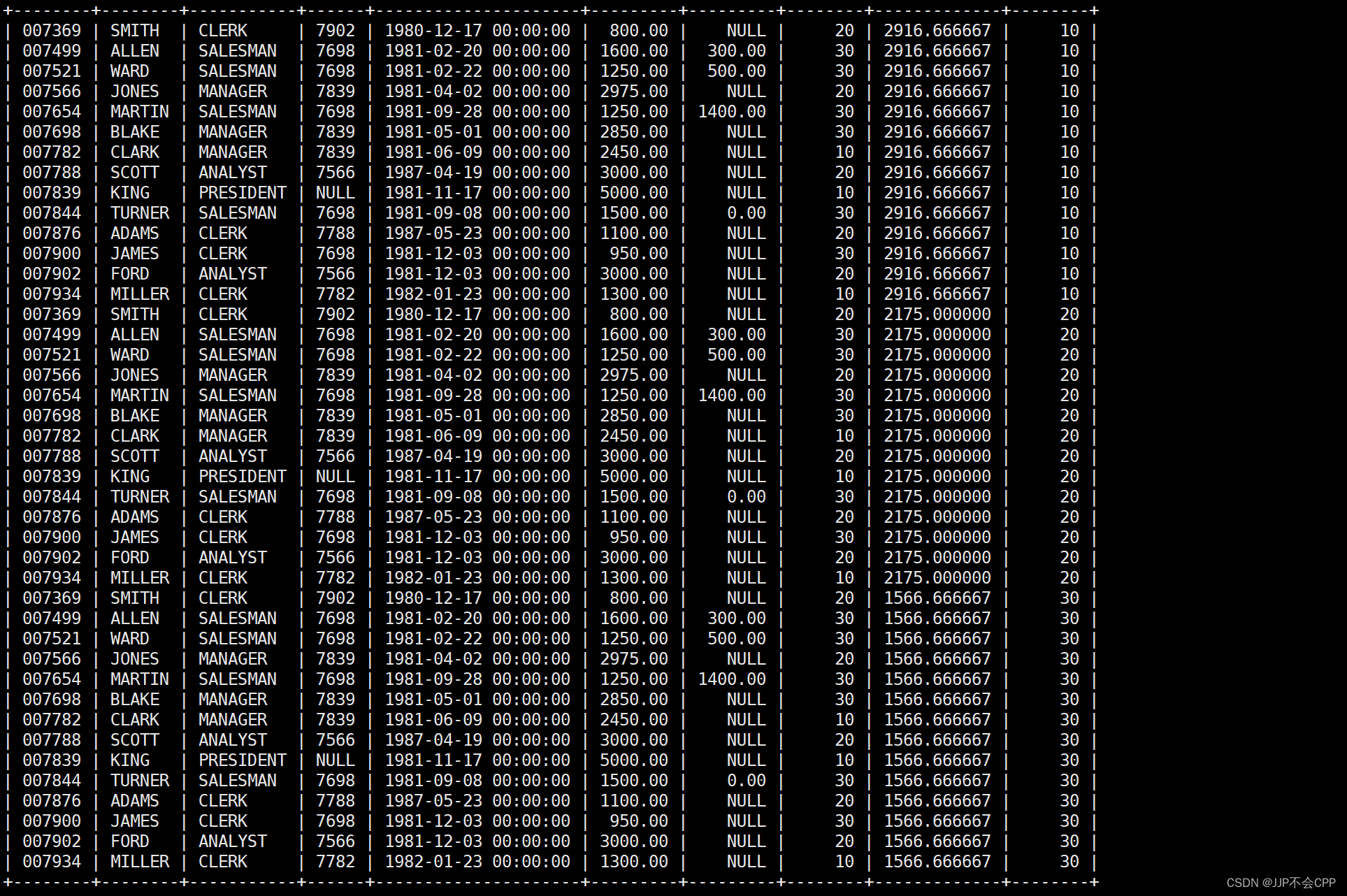
查询到结果之后,我们将上述结果当成一张临时表,与原来的emp表做笛卡尔积,输入语句select * from emp, (select avg(sal) asal, deptno from emp group by deptno) tmp;
这样就得到了所有的组合结果,但是我们发现这上面的组合结果中有一些是不符合实际的数据,我们还需要进一步筛选,筛选出emp表的deptno和tmp表中deptno相等的数据,才是符合实际的。输入语句select * from emp, (select avg(sal) asal, deptno from emp group by deptno) tmp where emp.deptno = tmp.deptno;
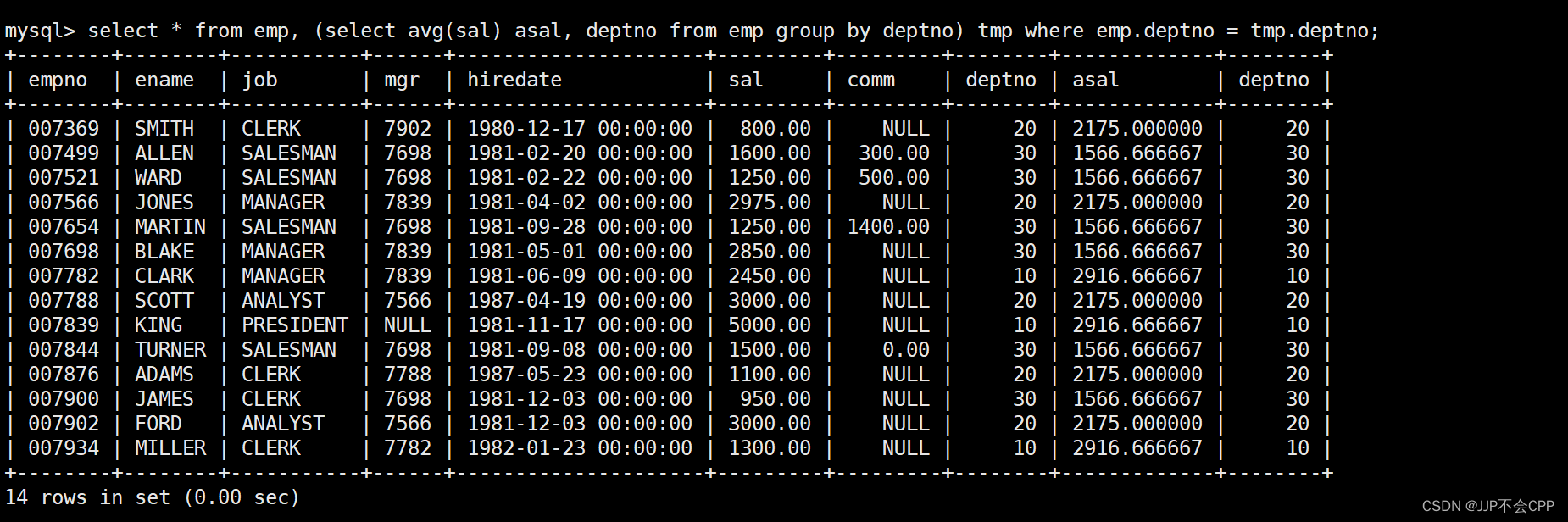
最后,我们可以在上面查找到的表中进一步查询,查询高于自己部门平均工资的员工的姓名、部门、工资和平均工资。输入语句select emp.ename, emp.deptno, emp.sal, format(asal, 2) myavg from emp, (select avg(sal) asal, deptno from emp group by deptno) tmp where (emp.deptno = tmp.deptno) and emp.sal > tmp.asal;

四、合并查询
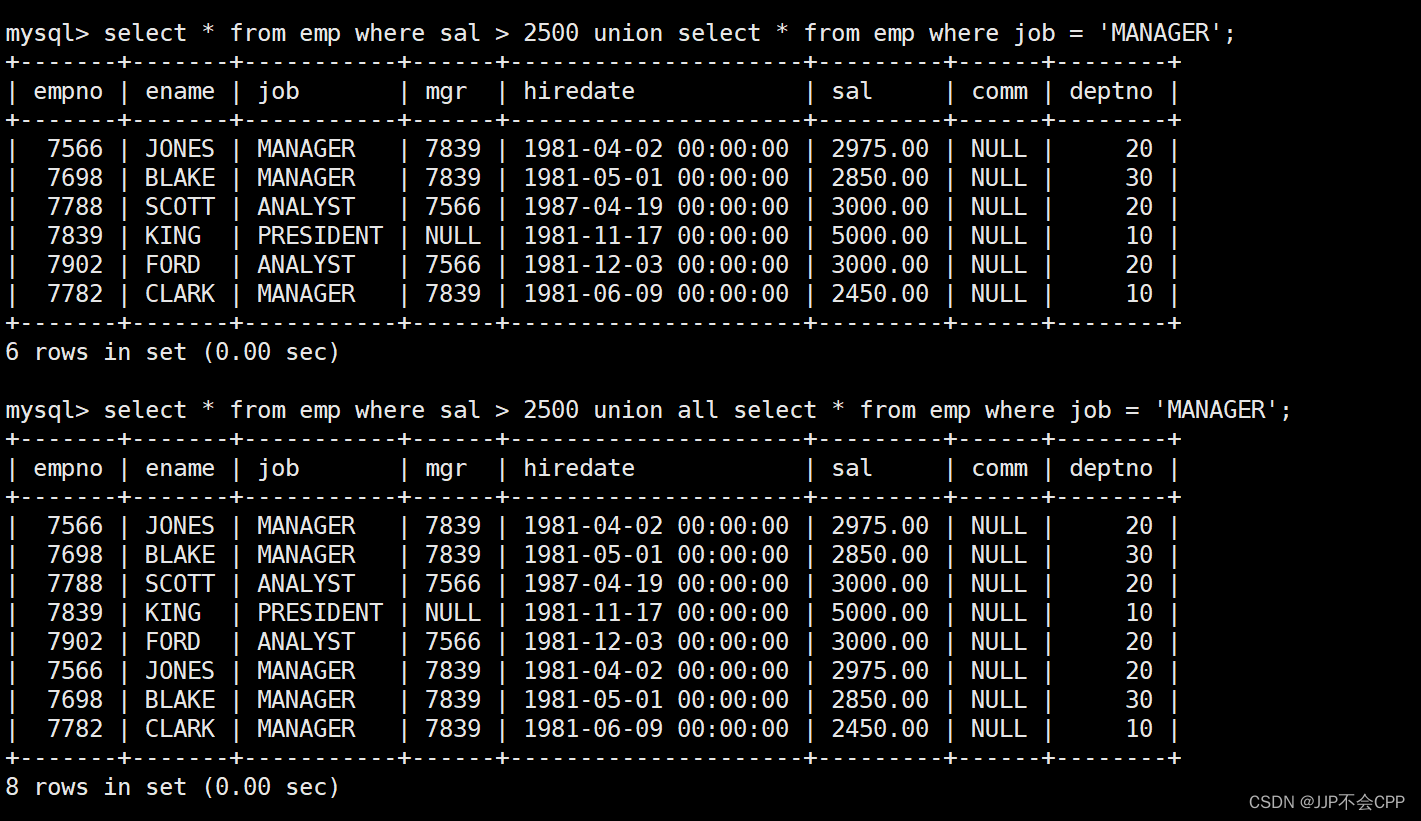
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符union和union all来合并。union操作符用于取得两个结果集的并集,当使用该操作符时,会自动去掉结果集中的重复行。union all操作符也是用于取得两个结果集的并集,但使用该操作符时,不会去掉结果集中的重复行。
例如,我们想要查找emp表中工资大于2500或者职位是MANAGER的人,分别使用union和union all操作符看看效果:
select * from emp where sal > 2500 union select * from emp where job = 'MANAGER';
select * from emp where sal > 2500 union all select * from emp where job = 'MANAGER';