目录
案例一 : 输出Hello World
案例二 :作业依赖
案例三 :内嵌工作流
案例四 :自动失败
案例五 :手动失败
案例六 :JavaProcess
案例七 :启动服务
案例八 :Hbase
案例九 :SQL
案例十 :条件工作流
运行时参数案例
预定义宏案例
安装azkaban教程 & 基本使用
案例一 : 输出Hello World
案例二 :作业依赖
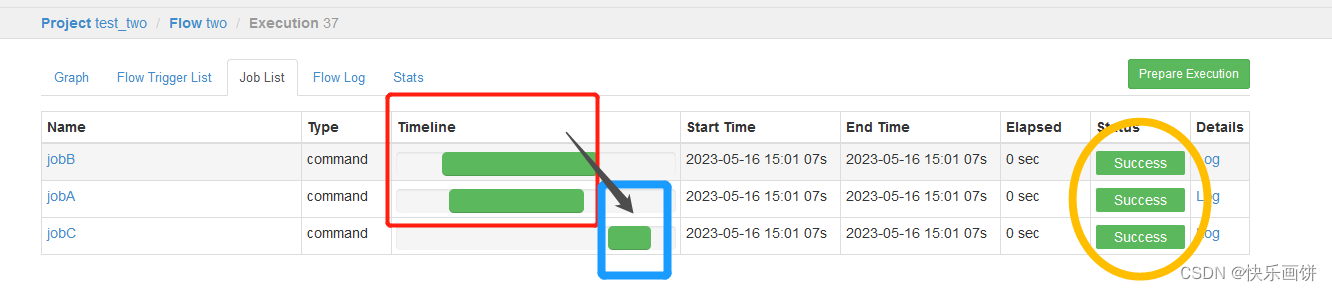
需求:JobA和JobB执行完了,才能执行JobC
azkaban.project文件
azkaban-flow-version: 2.0修改two.flow为如下内容
nodes:- name: jobCtype: commanddependsOn:- jobA- jobBconfig:command: echo "I’m JobC"- name: jobAtype: commandconfig:command: echo "I’m JobA"- name: jobBtype: commandconfig:command: echo "I’m JobB"
将修改后的basic.flow和azkaban.project压缩成two.zip文件
dependsOn: jobC 依赖 JobA和JobB
执行成功就是下面的这样
案例三 :内嵌工作流
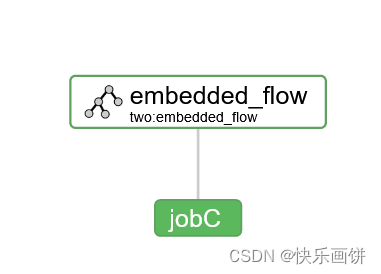
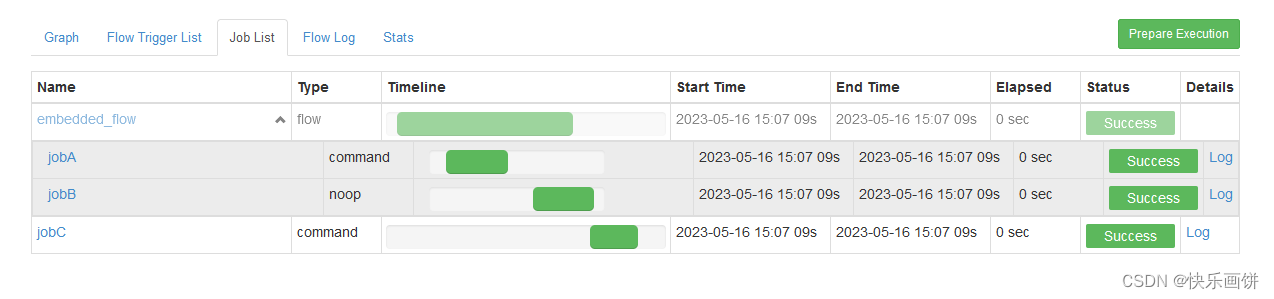
需求:JobA执行完后执行JobB,JobA和JobB形成一个工作流embedded_flow;JobC依赖于embedded_flow该工作流。
修改three.flow为如下内容
nodes:- name: jobCtype: commanddependsOn:- embedded_flowconfig:command: echo "I’m JobC"- name: embedded_flowtype: flownodes:- name: jobBtype: noopdependsOn:- jobA- name: jobAtype: commandconfig:command: pwd
将修改后的three.flow和azkaban.project压缩成three.zip文件
参数说明:
type: 作业类型。flow表示,定义为工作流类型
type: noop 什么也不处理
工作流定义文件中可以添加子工作流
案例四 :自动失败
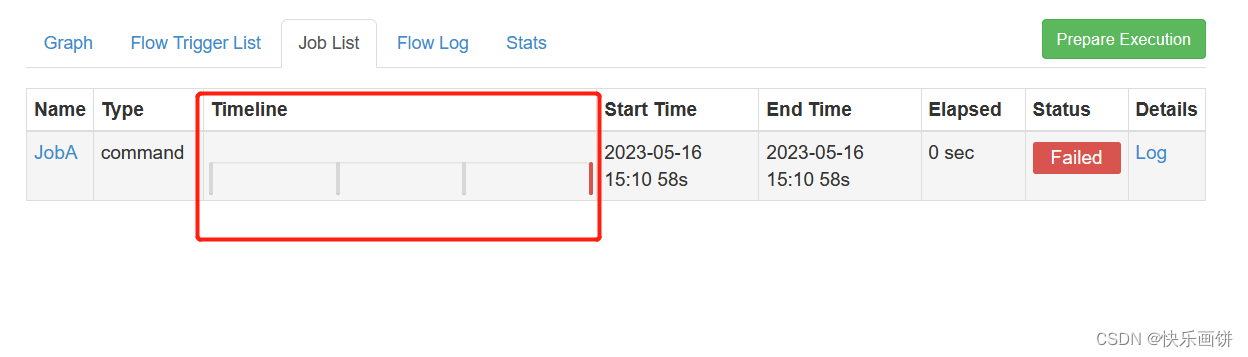
需求:如果执行任务失败,需要重试3次,重试的时间间隔10000ms
修改four.flow为如下内容
nodes:- name: JobAtype: commandconfig:command: sh four.shretries: 3retry.backoff: 10000
将修改后的four.flow和azkaban.project压缩成four.zip文件
配置中没有four.sh这个文件
参数说明:
retries:重试次数
retry.backoff:重试的时间间隔
案例五 :手动失败
需求:JobA=>JobB(依赖于A)=>JobC=>JobD=>JobE=>JobF。
生产环境,任何Job都有可能挂掉,可以根据需求执行想要执行的Job。
修改five.flow为如下内容
nodes:- name: JobAtype: commandconfig:command: echo "This is JobA."- name: JobBtype: commanddependsOn:- JobAconfig:command: echo "This is JobB."- name: JobCtype: commanddependsOn:- JobBconfig:command: echo "This is JobC."- name: JobDtype: commanddependsOn:- JobCconfig:command: echo "This is JobD."- name: JobEtype: commanddependsOn:- JobDconfig:command: echo "This is JobE."- name: JobFtype: commanddependsOn:- JobEconfig:command: echo "This is JobF."
将修改后的five.flow和azkaban.project压缩成five.zip文件
这个是一层依赖一层
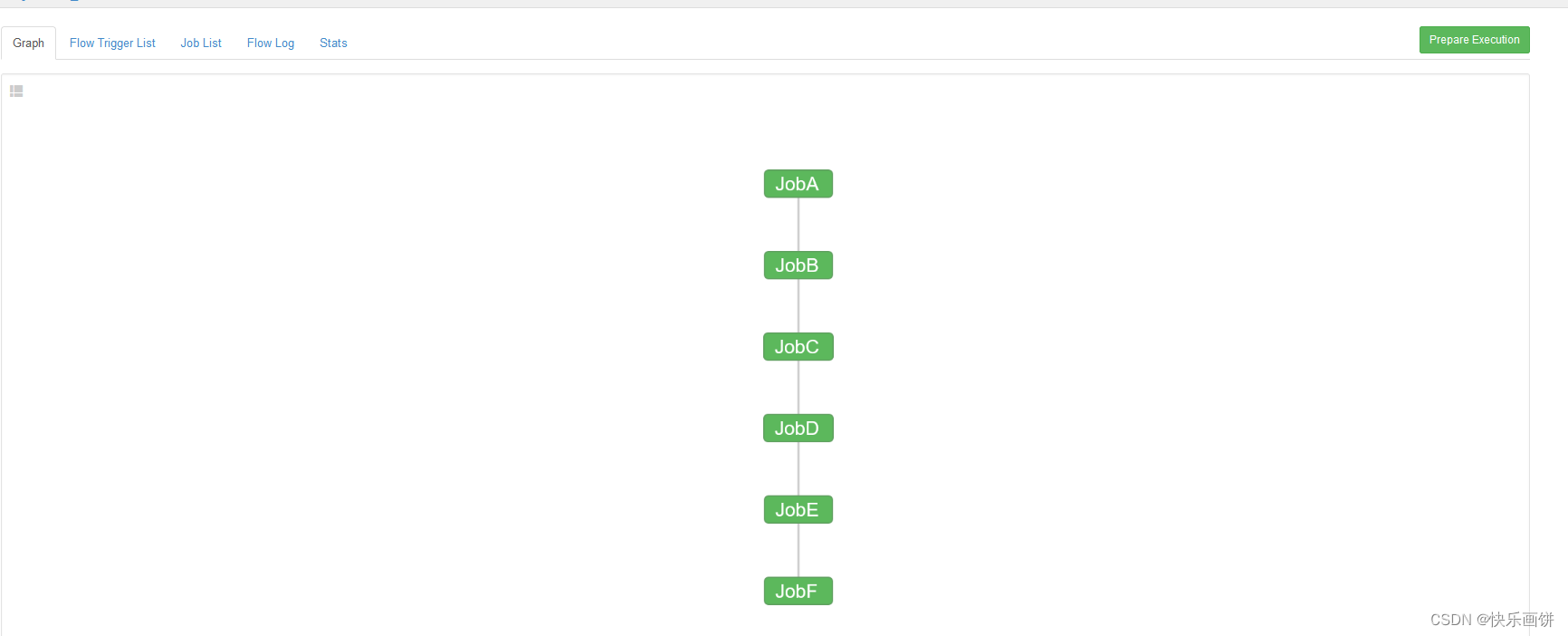
按照道理应该是这样每一层都是成功的
但是如果手动干掉一个节点,或者干掉下一个节点
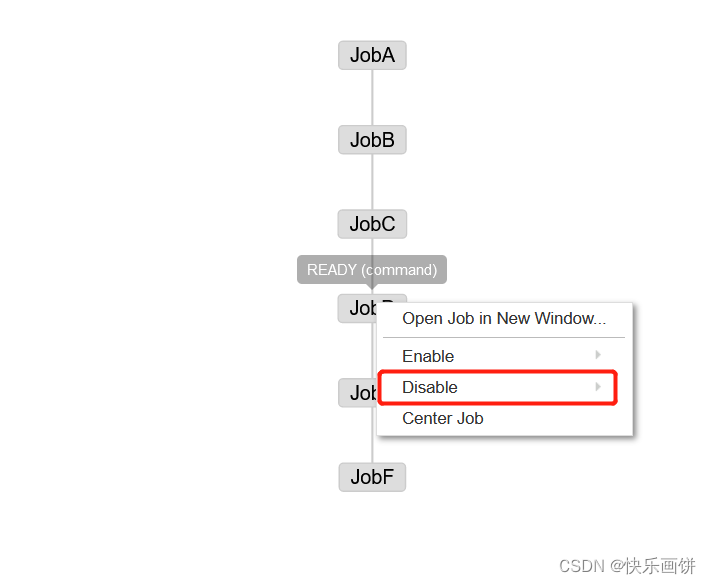
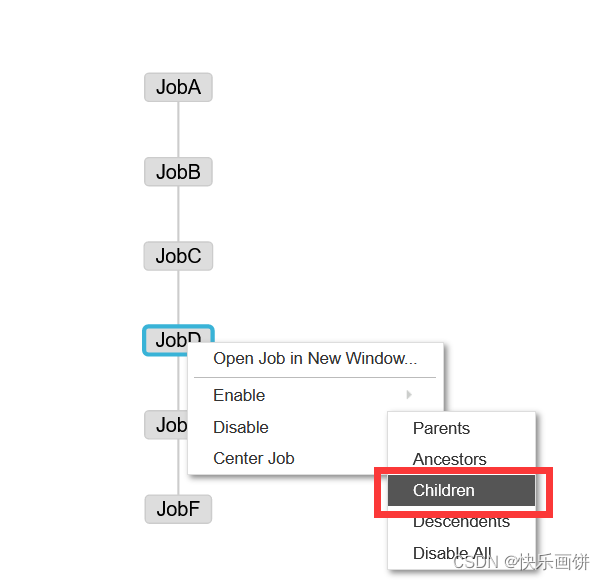
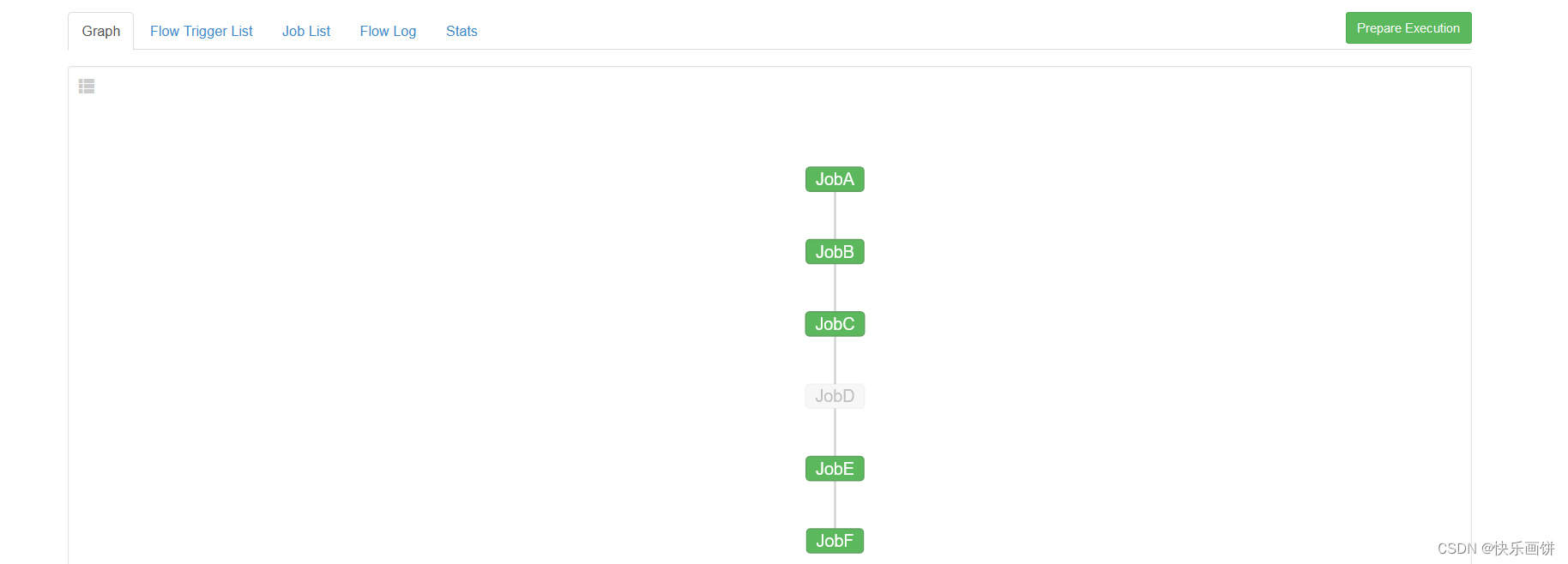
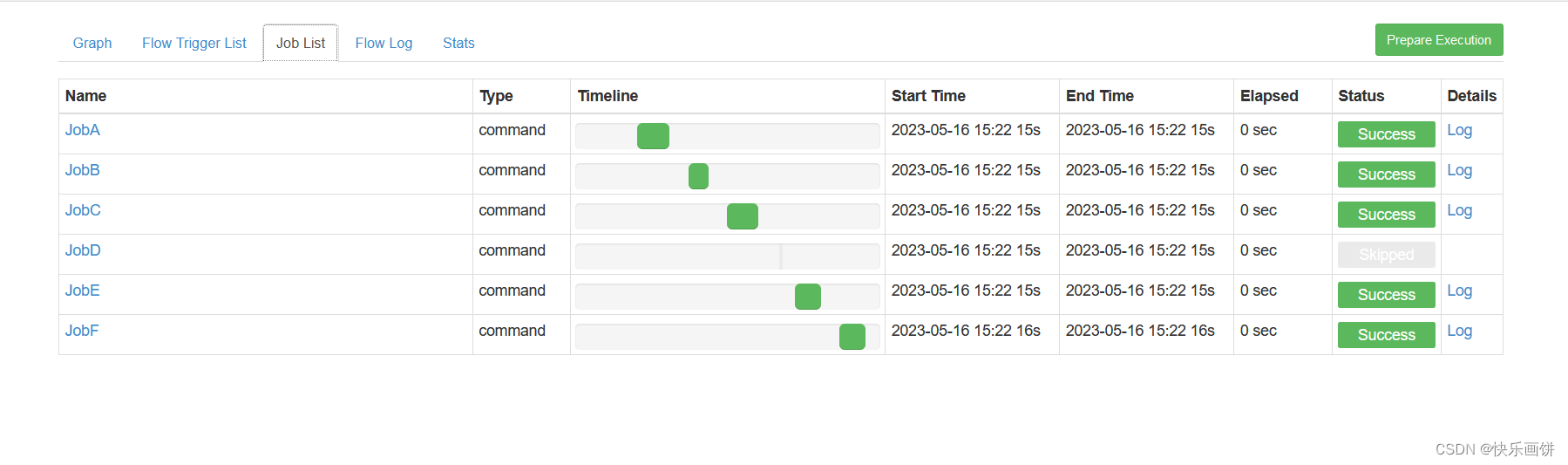
这样这个节点就不会运行
Enable和Disable下面都分别有如下参数:
Parents:该作业的上一个任务
Ancestors:该作业前的所有任务
Children:该作业后的一个任务
Descendents:该作业后的所有任务
Enable All:所有的任务
案例六 :JavaProcess
创建一个java类
public class azkabanTest {public static void main(String[] args) {System.out.println("this is azkaban");}
}
打包成jar包azkaban-1.0-SNAPSHOT.jar
修改four.flow为如下内容
nodes:- name: test_javatype: javaprocessconfig:Xms: 96MXmx: 200Mjava.class: azkaban.AzkabanTest
将Jar包、flow文件和project文件打包成six.zip


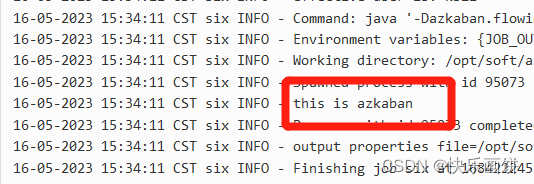
JavaProcess类型可以运行一个自定义主类方法,type类型为javaprocess,可用的配置为
Xms:最小堆
Xmx:最大堆
java.class:要运行的Java对象,其中必须包含Main方法
案例七 :启动服务
修改seven.flow为如下内容
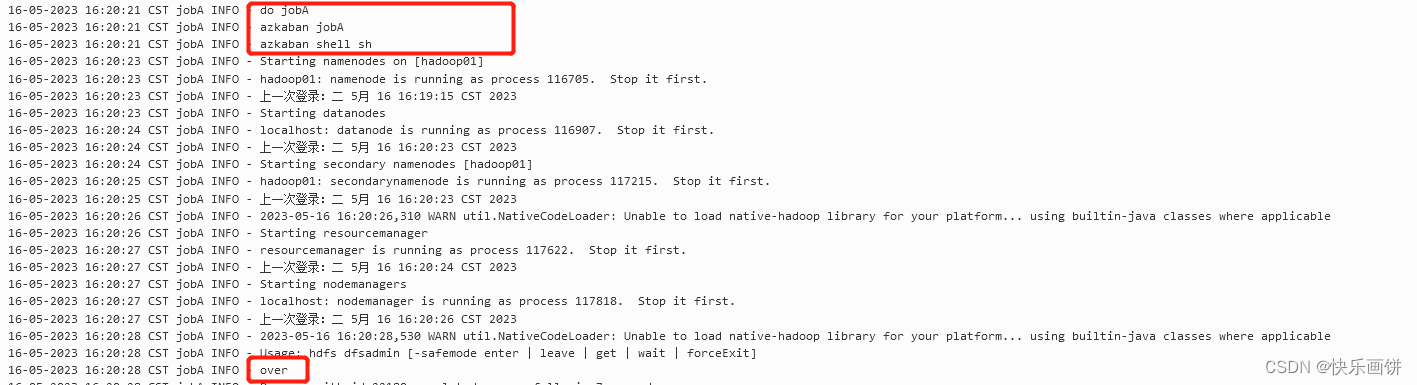
nodes: - name: jobAtype: commandconfig: command: sh jobshell.sh新建jobshell.sh文件,内容如下:
#!/bin/bash
echo "do jobA"
echo "azkaban jobA"
echo "azkaban shell sh"start-all.sh
hdfs dfsadmin -safemode leavelecho "over"将jobshell.sh、seven.flow和azkaban.project打包成seven.zip
案例八 :Hbase
先启动hbase
修改eight.flow为如下内容
nodes:- name: jobhbasetype: commandconfig:command: hbase shell hbasedemo.sh新建hbasedemo.sh文件,内容如下:
#!/bin/bashcreate_namespace 'test0516'create 'test0516:tb1','family','student'list_namespacelist_namespace_tables 'test0516' exit将hbasedemo.sh、eight.flow和azkaban.project打包成eight.zip


案例九 :SQL
启动hive
修改nine.flow为如下内容
nodes: - name: jobhivetype: commandconfig: command: hive -f myhive.sql新建myhive.sql,内容如下:
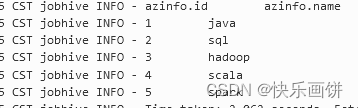
create database if not exists test0516DB;use test0516DB;create table if not exists azinfo(id int,name string) row format delimited fields terminated by ',';load data inpath '/opt/azkaban/info.txt' into table azinfo;select * from azinfo;info.txt内容如下:
1,java
2,sql
3,hadoop
4,scala
5,spark将myhive.sql、nine.flow和azkaban.project打包成nine.zip
案例十 :条件工作流
条件工作流功能允许用户根据条件指定是否运行某些作业。条件由先前作业的运行时参数(例如输出)和预定义宏组成。在这些条件下,用户可以在确定作业执行逻辑时获得更大的灵活性。例如,只要父作业之一成功,他们就可以运行当前作业。他们可以在工作流内部实现分支逻辑。
运行时参数案例
运行时参数一般指作业的输出,使用时有以下几个条件:
(1)使用 ${jobName:param}来定义作业运行时参数的条件
(2)“:” 用于分隔jobName和参数
(3)job运行时,使用参数与条件中的字符串或数字进行比较
(4)用户需要事先将参数的值写入$JOB_OUTPUT_PROP_FILE
需求:
JobA执行一个shell脚本;
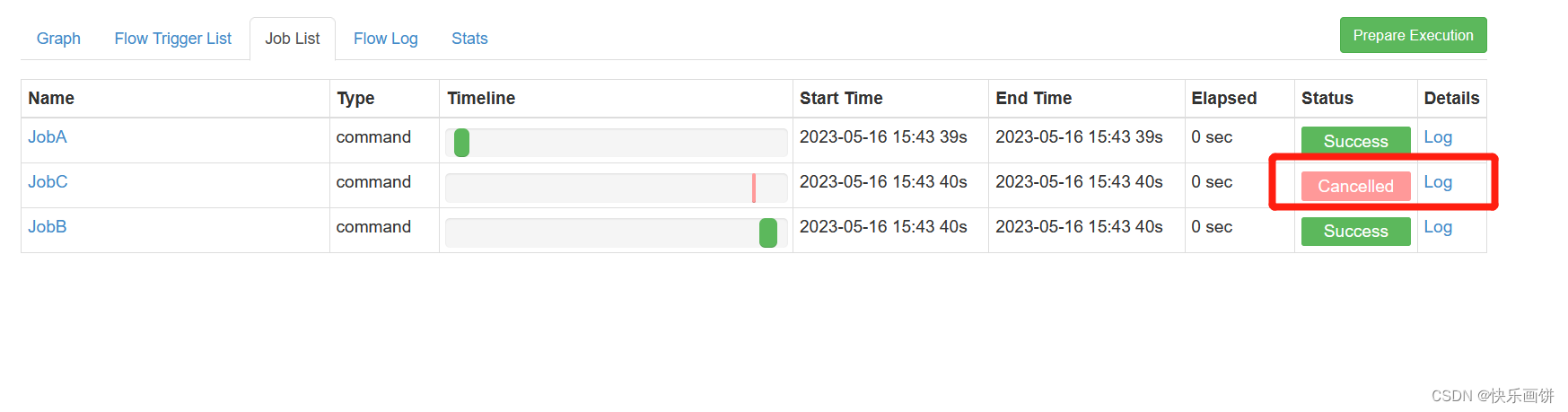
JobB条件依赖于JobA,当JobA中param1的值为“BBB”,执行JobB;
JobC也条件依赖于JobA,当JobA中param1的值为“CCC”,执行JobC
新建ten.flow,内容如下:
nodes:- name: JobAtype: commandconfig:command: sh parameter.sh- name: JobBtype: commanddependsOn:- JobAconfig:command: echo "This is JobB."condition: ${JobA:param1} == "BBB"- name: JobCtype: commanddependsOn:- JobAconfig:command: echo "This is JobC."condition: ${JobA:param1} == "CCC"
新建parameter.sh,内容为:
echo '{"param1":"BBB"}' > $JOB_OUTPUT_PROP_FILE
将parameter.sh、ten.flow和azkaban.project打包成ten.zip

支持的运算符:
(1)== 等于
(2)!= 不等于
(3)> 大于
(4)>= 大于等于
(5)< 小于
(6)<= 小于等于
(7)&& 与
(8)|| 或
(9)! 非
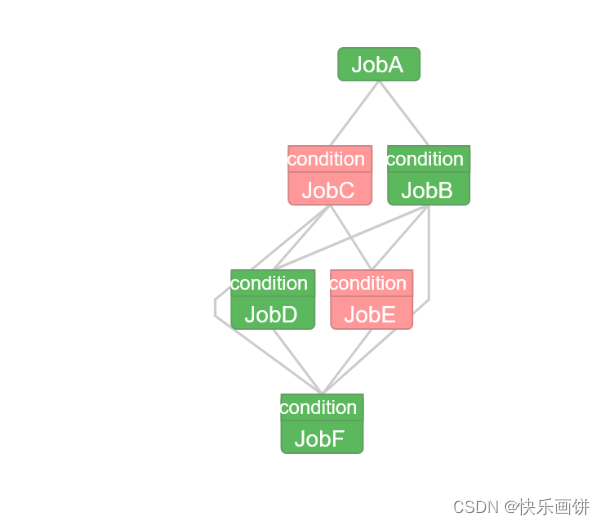
预定义宏案例
需求:
JobA执行一个shell脚本;
JobB条件依赖于JobA,当JobA中param1的值为“BBB”,执行JobB;
JobC也条件依赖于JobA,当JobA中param1的值为“CCC”,执行JobC
JobD依赖于JobB、JobC,JobB和JobC有任何一个执行成功后,执行JobD。
JobE依赖于JobB、JobC,JobB和JobC都执行成功,执行JobE。
JobF依赖于JobB、JobC、JobD、JobE。
JobB、JobC、JobD、JobE都执行完了,执行JobF。
修改上个案例的ten.flow
nodes:- name: JobAtype: commandconfig:command: sh parameter.sh- name: JobBtype: commanddependsOn:- JobAconfig:command: echo "This is JobB."condition: ${JobA:param1} == "BBB"- name: JobCtype: commanddependsOn:- JobAconfig:command: echo "This is JobC."condition: ${JobA:param1} == "CCC"- name: JobDtype: commanddependsOn:- JobB- JobCconfig:command: echo "This is JobD."condition: one_success- name: JobEtype: commanddependsOn:- JobB- JobCconfig:command: echo "This is JobE."condition: all_success- name: JobFtype: commanddependsOn:- JobB- JobC- JobD- JobEconfig:command: echo "This is JobF."condition: all_done
将parameter.sh、ten.flow和azkaban.project打包成ten.zip

预定义宏将会在所有父作业上评估,即YAML文件中的dependsOn部分。
可用的预定义宏如下:
(1)all_success: 全部成功(默认)
(2)all_done:全部完成
(3)all_failed:全部失败
(4)one_success:至少一个成功
(5)one_failed:至少一个失败