数据安全分类分级实施指南
重点 (Top highlight)
Balance within the imbalance to balance what’s imbalanced — Amadou Jarou Bah
在不平衡中保持平衡以平衡不平衡— Amadou Jarou Bah
Disclaimer: This is a comprehensive tutorial on handling imbalanced datasets. Whilst these approaches remain valid for multiclass classification, the main focus of this article will be on binary classification for simplicity.
免责声明:这是有关处理不平衡数据集的综合教程。 尽管这些方法对于多类分类仍然有效,但为简单起见,本文的主要重点将放在二进制分类上。
介绍 (Introduction)
As any seasoned data scientist or statistician will be aware of, datasets are rarely distributed evenly across attributes of interest. Let’s imagine we are tasked with discovering fraudulent credit card transactions — naturally, the vast majority of these transactions will be legitimate, and only a very small proportion will be fraudulent. Similarly, if we are testing individuals for cancer, or for the presence of a virus (COVID-19 included), the positive rate will (hopefully) be only a small fraction of those tested. More examples include:
正如任何经验丰富的数据科学家或统计学家都会意识到的那样,数据集很少会在感兴趣的属性之间均匀分布。 想象一下,我们负有发现欺诈性信用卡交易的任务-自然,这些交易中的绝大多数都是合法的,只有很小一部分是欺诈性的。 同样,如果我们正在测试个人是否患有癌症或是否存在病毒(包括COVID-19),那么(希望)阳性率仅是所测试者的一小部分。 更多示例包括:
- An e-commerce company predicting which users will buy items on their platform 一家电子商务公司预测哪些用户将在其平台上购买商品
- A manufacturing company analyzing produced materials for defects 一家制造公司分析所生产材料的缺陷
- Spam email filtering trying to differentiation ‘ham’ from ‘spam’ 垃圾邮件过滤试图区分“火腿”和“垃圾邮件”
- Intrusion detection systems examining network traffic for malware signatures or atypical port activity 入侵检测系统检查网络流量中是否存在恶意软件签名或非典型端口活动
- Companies predicting churn rates amongst their customers 预测客户流失率的公司
- Number of clients who closed a specific account in a bank or financial organization 在银行或金融组织中关闭特定帐户的客户数量
- Prediction of telecommunications equipment failures 预测电信设备故障
- Detection of oil spills from satellite images 从卫星图像检测漏油
- Insurance risk modeling 保险风险建模
- Hardware fault detection 硬件故障检测
One has usually much fewer datapoints from the adverse class. This is unfortunate as we care a lot about avoiding misclassifying elements of this class.
通常,来自不利类的数据点少得多。 这很不幸,因为我们非常在意避免对此类元素进行错误分类。
In actual fact, it is pretty rare to have perfectly balanced data in classification tasks. Oftentimes the items we are interested in analyzing are inherently ‘rare’ events for the very reason that they are rare and hence difficult to predict. This presents a curious problem for aspiring data scientists since many data science programs do not properly address how to handle imbalanced datasets given their prevalence in industry.
实际上,在分类任务中拥有完全平衡的数据非常罕见。 通常,我们感兴趣的项目本质上是“稀有”事件,原因是它们很少见,因此难以预测。 对于有抱负的数据科学家而言,这是一个令人好奇的问题,因为鉴于其在行业中的普遍性,许多数据科学程序无法正确解决如何处理不平衡的数据集。
数据集什么时候变得“不平衡”? (When does a dataset become ‘imbalanced’?)
The notion of an imbalanced dataset is a somewhat vague one. Generally, a dataset for binary classification with a 49–51 split between the two variables would not be considered imbalanced. However, if we have a dataset with a 90–10 split, it seems obvious to us that this is an imbalanced dataset. Clearly, the boundary for imbalanced data lies somewhere between these two extremes.
不平衡数据集的概念有些模糊。 通常,在两个变量之间划分为49-51的二进制分类数据集不会被认为是不平衡的。 但是,如果我们有一个90-10分割的数据集,对我们来说显然这是一个不平衡的数据集。 显然,不平衡数据的边界介于这两个极端之间。
In some sense, the term ‘imbalanced’ is a subjective one and it is left to the discretion of the data scientist. In general, a dataset is considered to be imbalanced when standard classification algorithms — which are inherently biased to the majority class (further details in a previous article) — return suboptimal solutions due to a bias in the majority class. A data scientist may look at a 45–55 split dataset and judge that this is close enough that measures do not need to be taken to correct for the imbalance. However, the more imbalanced the dataset becomes, the greater the need is to correct for this imbalance.
从某种意义上说,“不平衡”一词是主观的,由数据科学家自行决定。 通常,当标准分类算法(固有地偏向多数类(在上一篇文章中有更多详细信息))由于多数类的偏向而返回次优解时,则认为数据集不平衡。 数据科学家可以查看45–55的分割数据集,并判断该数据集足够接近,因此无需采取措施来纠正不平衡。 但是,数据集变得越不平衡,就越需要纠正这种不平衡。
In a concept-learning problem, the data set is said to present a class imbalance if it contains many more examples of one class than the other.
在概念学习问题中,如果数据集包含一个类别的实例多于另一个类别的实例,则称该数据集存在类别不平衡。
As a result, these classifiers tend to ignore small classes while concentrating on classifying the large ones accurately.
结果,这些分类器倾向于忽略小类别,而专注于准确地对大类别进行分类。
Imagine you are working for Netflix and are tasked with determining which customer churn rates (a customer ‘churning’ means they will stop using your services or using your products).
想象您正在为Netflix工作,并负责确定哪些客户流失率(客户“流失”意味着他们将停止使用您的服务或产品)。
In an ideal world (at least for the data scientist), our training and testing datasets would be close to fully balanced, having around 50% of the dataset containing individuals that will churn and 50% who will not. In this case, a 90% accuracy will more or less indicate a 90% accuracy on both the positively and negatively classed groups. Our errors will be evenly split across both groups. In addition, we have roughly the same number of points in both classes, which from the law of large numbers tells us reduces the overall variance in the class. This is great for us, accuracy is an informative metric in this situation and we can continue with our analysis unimpeded.
在理想的世界中(至少对于数据科学家而言),我们的训练和测试数据集将接近完全平衡,大约50%的数据集包含会搅动的人和50%不会搅动的人。 在这种情况下,90%的准确度将或多或少地表明在正面和负面分类组中都达到90%的准确度。 我们的错误将平均分配给两个组。 此外,两个类中的点数大致相同,这从大数定律可以看出,这减少了类中的总体方差。 这对我们来说非常好,在这种情况下,准确性是一个有用的指标,我们可以继续进行不受阻碍的分析。
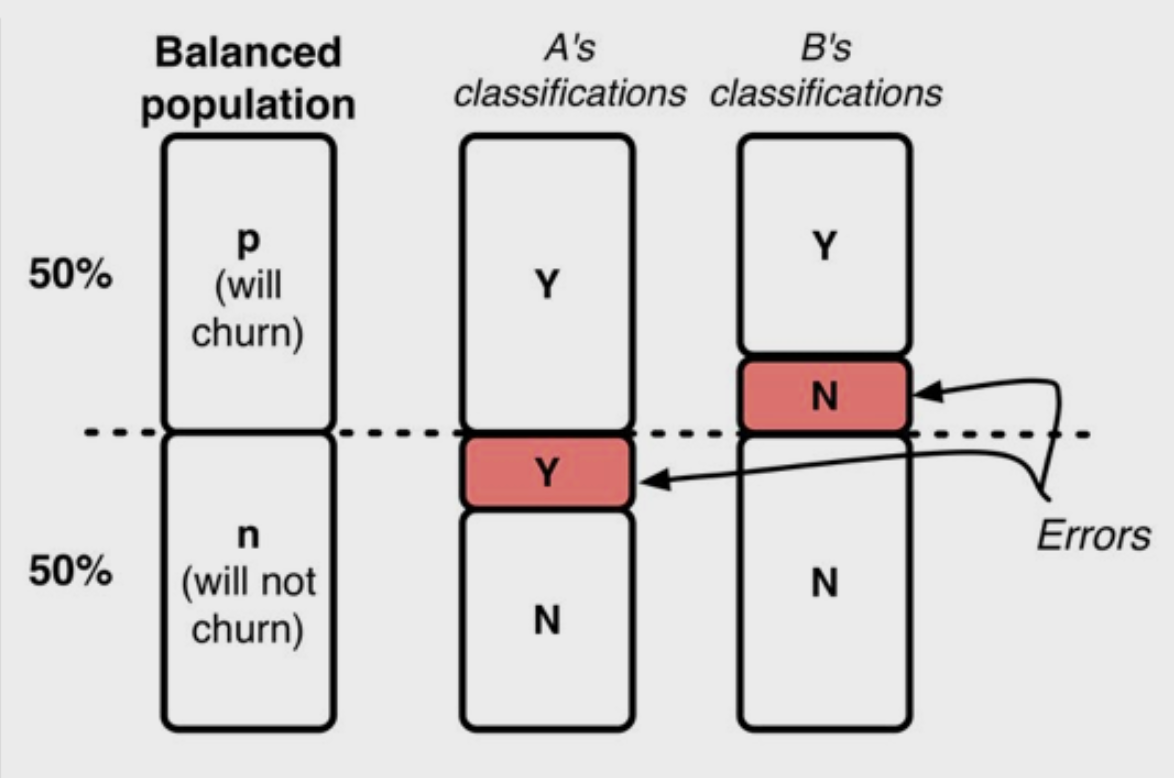
As you may have suspected, most people that already pay for Netflix don't have a 50% chance of stopping their subscription every month. In fact, the percentage of people that will churn is rather small, closer to a 90–10 split. How does the presence of this dataset imbalance complicate matters?
您可能会怀疑,大多数已经为Netflix付款的人没有50%的机会每月停止订阅。 实际上,会流失的人数比例很小,接近90-10。 这个数据集的不平衡如何使问题复杂化?
Assuming a 90–10 split, we now have a very different data story to tell. Giving this data to an algorithm without any further consideration will likely result in an accuracy close to 90%. This seems pretty good, right? It’s about the same as what we got previously. If you try putting this model into production your boss will probably not be so happy.
假设拆分为90-10,我们现在要讲一个非常不同的数据故事。 将此数据提供给算法而无需进一步考虑,可能会导致接近90%的精度。 这看起来还不错吧? 它与我们之前获得的内容大致相同。 如果您尝试将这种模型投入生产,您的老板可能不会很高兴。
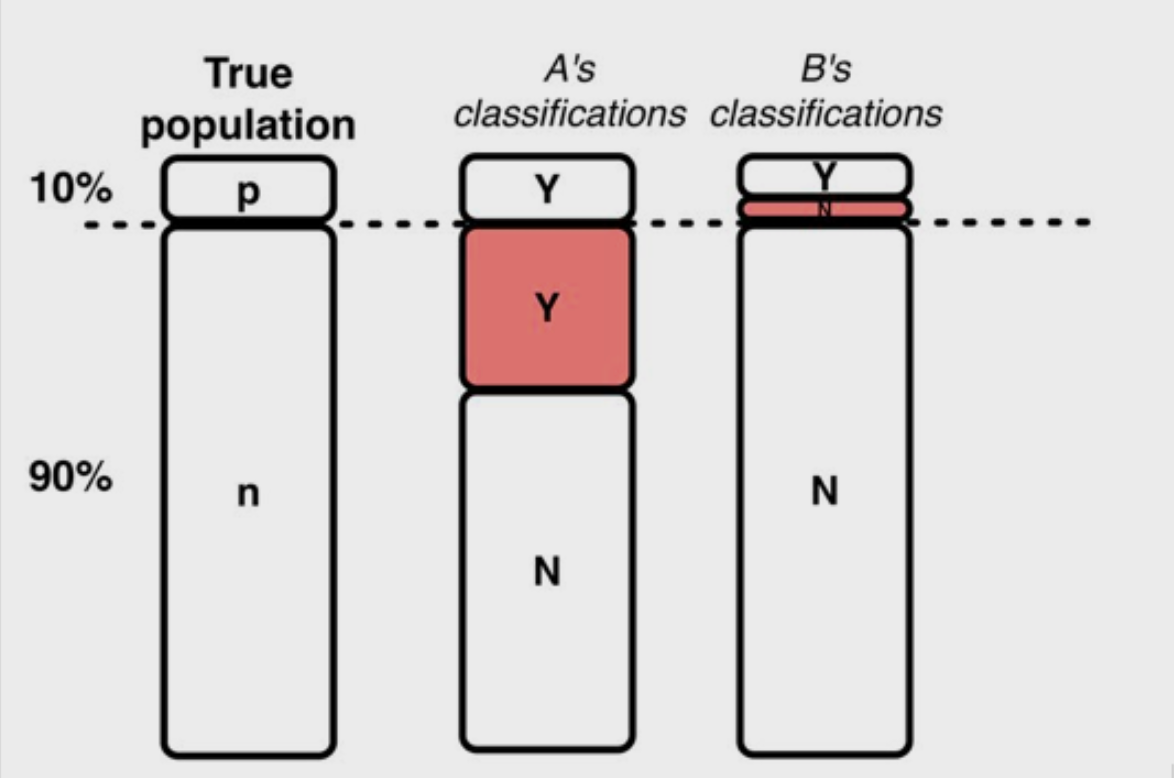
Given the prevalence of the majority class (the 90% class), our algorithm will likely regress to a prediction of the majority class. The algorithm can pretty closely maximize its accuracy (our scoring metric of choice) by arbitrarily predicting that the majority class occurs every time. This is a trivial result and provides close to zero predictive power.
给定多数类别(90%类别)的患病率,我们的算法可能会回归到多数类别的预测。 通过任意预测每次都会出现多数类,该算法可以非常精确地最大程度地提高其准确性(我们的选择评分标准)。 这是微不足道的结果,并提供接近零的预测能力。
Predictive accuracy, a popular choice for evaluating the performance of a classifier, might not be appropriate when the data is imbalanced and/or the costs of different errors vary markedly.
当数据不平衡和/或不同错误的成本明显不同时,预测准确性是评估分类器性能的一种普遍选择,可能不合适。
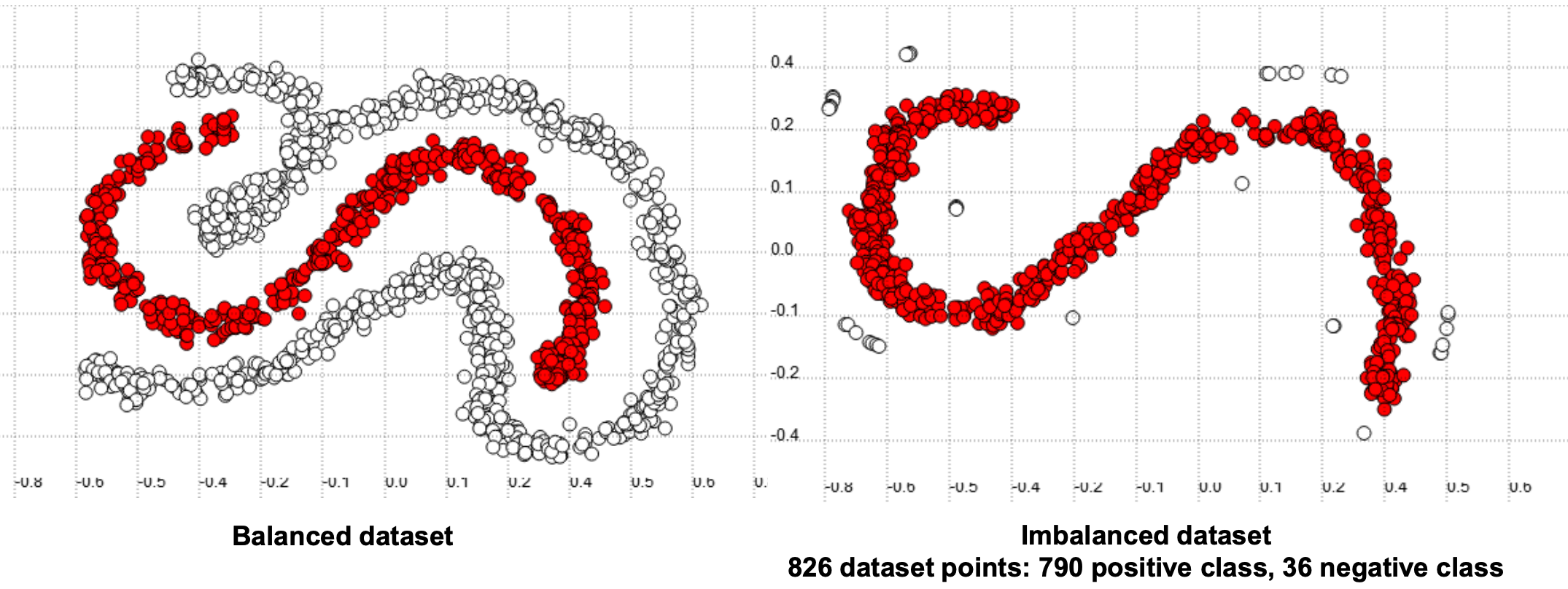
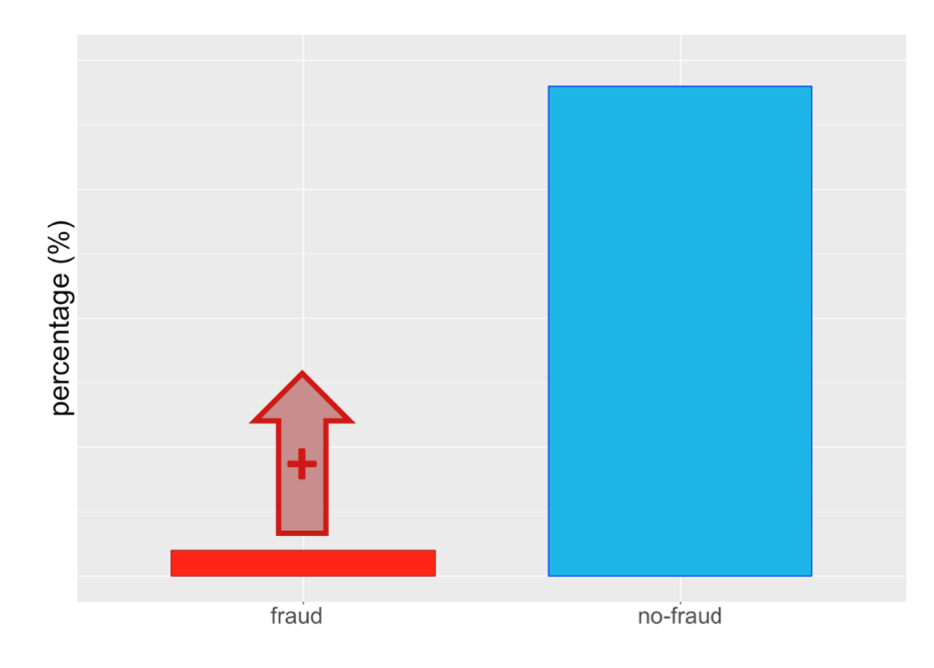
Visually, this dataset might look something like this:
从视觉上看,该数据集可能看起来像这样:
Machine learning algorithms by default assume that data is balanced. In classification, this corresponds to a comparative number of instances of each class. Classifiers learn better from a balanced distribution. It is up to the data scientist to correct for imbalances, which can be done in multiple ways.
默认情况下,机器学习算法假定数据是平衡的。 在分类中,这对应于每个类的比较实例数。 分类器从均衡的分布中学习得更好。 数据科学家可以纠正不平衡,这可以通过多种方式来完成。
不同类型的失衡 (Different Types of Imbalance)
We have clearly shown that imbalanced datasets have some additional challenges to standard datasets. To further complicate matters, there are different types of imbalance that can occur in a dataset.
我们已经清楚地表明,不平衡的数据集对标准数据集还有一些其他挑战。 更复杂的是,数据集中可能会出现不同类型的失衡。
(1) Between-Class
(1)课间
A between-class imbalance occurs when there is an imbalance in the number of data points contained within each class. An example of this is shown below:
当每个类中包含的数据点数量不平衡时,将发生类间不平衡。 下面是一个示例:
An example of this would be a mammography dataset, which uses images known as mammograms to predict breast cancer. Consider the number of mammograms related to positive and negative cancer diagnoses:
这样的一个例子是乳腺X射线摄影数据集,它使用称为乳腺X线照片的图像来预测乳腺癌。 考虑与阳性和阴性癌症诊断相关的乳房X线照片数量:
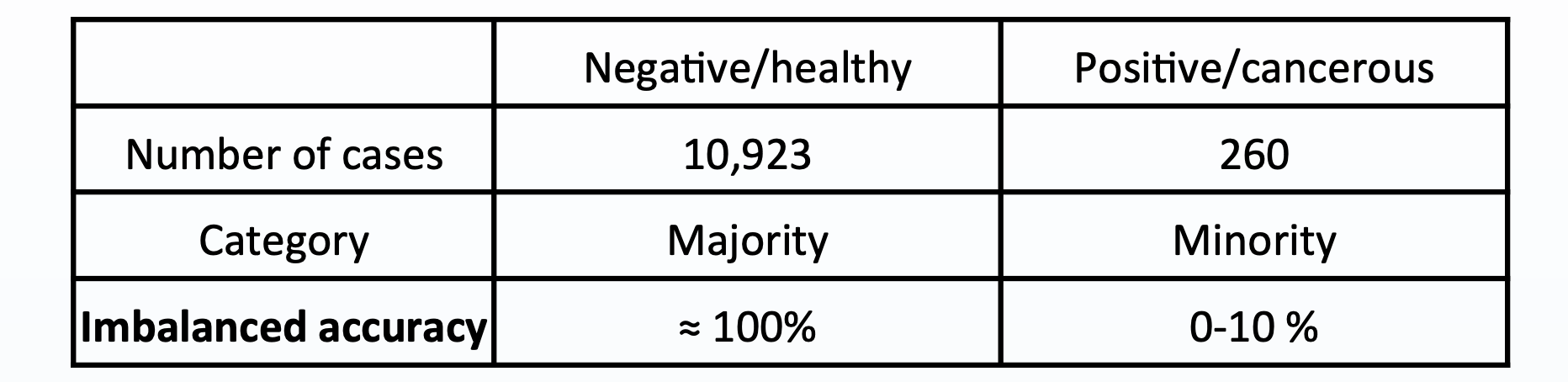
Note that given enough data samples in both classes the accuracy will improve as the sampling distribution is more representative of the data distribution, but by virtue of the law of large numbers, the majority class will have inherently better representation than the minority class.
请注意,如果两个类别中都有足够的数据样本,则精度会随着采样分布更能代表数据分布而提高,但是由于数量规律,多数类别在本质上要比少数类别更好。
(2) Within-Class
(2)班内
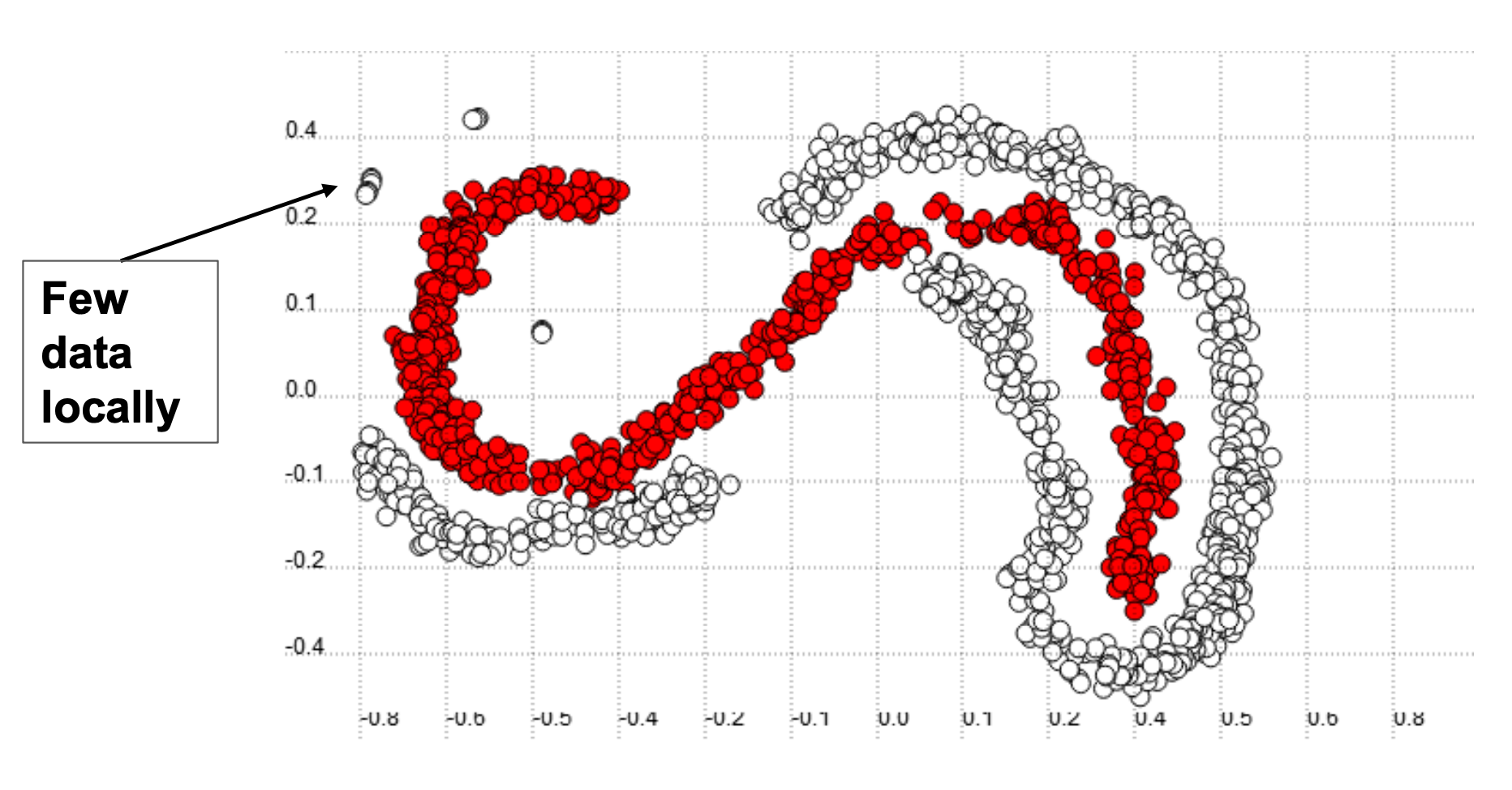
A within-class imbalance occurs when the dataset has balanced between-class data but one of the classes is not representative in some regions. An example of this is shown below:
当数据集具有平衡的类间数据,但其中一个类在某些区域中不具有代表性时,会发生类内不平衡。 下面是一个示例:
(3) Intrinsic and Extrinsic
(3)内部和外部
An intrinsic imbalance is due to the nature of the dataset, while extrinsic imbalance is related to time, storage, and other factors that limit the dataset or the data analysis. Intrinsic characteristics are relatively simple and are what we commonly see, but extrinsic imbalance can exist separately and can also work to increase the imbalance of a dataset.
内在的不平衡归因于数据集的性质, 而外在的不平衡则与时间,存储以及其他限制数据集或数据分析的因素有关。 内部特征相对简单,这是我们通常看到的特征,但是外部不平衡可以单独存在,也可以用来增加数据集的不平衡。
For example, companies often use intrusion detection systems that analyze packets of data sent in and out of networks in order to detect malware of malicious activity. Depending on whether you analyze all data or just data sent through specific ports or specific devices, this will significantly influence the imbalance of the dataset (most network traffic is likely legitimate). Similarly, if log files or data packets related to suspected malicious behavior are commonly stored but normal log are not (or only a select few types are stored), then this can also influence the imbalance of the dataset. Similarly, if logs were only stored during a normal working day (say, 9–5 PM) instead of 24 hours, this will also affect the imbalance.
例如,公司经常使用入侵检测系统来分析进出网络的数据包,以检测恶意活动的恶意软件。 根据您是分析所有数据还是仅分析通过特定端口或特定设备发送的数据,这将严重影响数据集的不平衡(大多数网络流量可能是合法的)。 同样,如果通常存储与可疑恶意行为有关的日志文件或数据包,但不存储常规日志(或仅存储少数几种类型的日志),则这也可能会影响数据集的不平衡。 同样,如果日志仅在正常工作日(例如9-5 PM)而非24小时内存储,这也会影响不平衡。
不平衡的进一步复杂化 (Further Complication of Imbalance)
There are a couple more difficulties increased by imbalanced datasets. Firstly, we have class overlapping. This is not always a problem, but can often arise in imbalanced learning problems and cause headaches. Class overlapping is illustrated in the below dataset.
不平衡的数据集会增加更多的困难。 首先,我们有班级重叠 。 这并不总是一个问题,但是经常会在学习不平衡的问题中出现并引起头痛。 下面的数据集说明了类重叠。
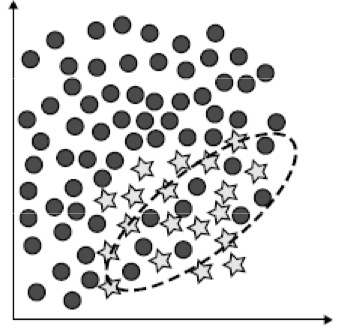
Class overlapping occurs in normal classification problems, so what is the additional issue here? Well, the class more represented in overlap regions tends to be better classified by methods based on global learning (on the full dataset). This is because the algorithm is able to get a more informed picture of the data distribution of the majority class.
在正常的分类问题中会发生类重叠,那么这里还有什么其他问题? 好吧,在重叠区域中表示更多的类倾向于通过基于全局学习的方法(在完整数据集上)更好地分类。 这是因为该算法能够获得多数类数据分布的更多信息。
In contrast, the class less represented in such regions tends to be better classified by local methods. If we take k-NN as an example, as the value of k increases, it becomes increasingly global and increasingly local. It can be shown that performance for low values of k has better performance on the minority dataset, and lower performance at high values of k. This shift in accuracy is not exhibited for the majority class because it is well-represented at all points.
相反,在此类区域中较少代表的类别倾向于通过本地方法更好地分类。 如果以k-NN为例,随着k值的增加,它变得越来越全球化,也越来越局部化。 可以证明,k值较低时的性能在少数数据集上具有较好的性能,而k值较高时的性能较低。 准确性的这种变化在大多数类别中都没有表现出来,因为它在所有方面都得到了很好的体现。
This suggests that local methods may be better suited for studying the minority class. One method to correct for this is the CBO Method. The CBO Method uses cluster-based resampling to identify ‘rare’ cases and resample them individually, so as to avoid the creation of small disjuncts in the learned hypothesis. This is a method of oversampling — a topic that we will discuss in detail in the following section.
这表明本地方法可能更适合于研究少数群体。 一种纠正此问题的方法是CBO方法 。 CBO方法使用基于聚类的重采样来识别“稀有”案例并分别对其进行重采样,以避免在学习的假设中产生小的歧义。 这是一种过采样的方法-我们将在下一节中详细讨论这个主题。

纠正数据集不平衡 (Correcting Dataset Imbalance)
There are several techniques to control for dataset imbalance. There are two main types of techniques to handle imbalanced datasets: sampling methods, and cost-sensitive methods.
有几种控制数据集不平衡的技术。 处理不平衡数据集的技术主要有两种: 抽样方法和成本敏感方法 。

The simplest and most commonly used of these are sampling methods called oversampling and undersampling, which we will go into more detail on.
其中最简单,最常用的是称为过采样和欠采样的采样方法,我们将对其进行详细介绍。
Oversampling/Undersampling
过采样/欠采样
Simply stated, oversampling involves generating new data points for the minority class, and undersampling involves removing data points from the majority class. This acts to somewhat reduce the extent of the imbalance in the dataset.
简而言之,过采样涉及为少数类生成新的数据点,而欠采样涉及从多数类中删除数据点。 这在某种程度上减少了数据集中的不平衡程度。
What does undersampling look like? We continually remove like-samples in close proximity until both classes have the same number of data points.
欠采样是什么样的? 我们会不断删除附近的相似样本,直到两个类具有相同数量的数据点。
Is undersampling a good idea? Undersampling is recommended by many statistical researchers but is only good if enough data points are available on the undersampled class. Also, since the majority class will end up with the same number of points as the minority class, the statistical properties of the distributions will become ‘looser’ in a sense. However, we have not artificially distorted the data distribution with this method by adding in artificial data points.
采样不足是个好主意吗? 许多统计研究人员建议进行欠采样,但是只有在欠采样类别上有足够的数据点可用时,采样才是好的。 同样,由于多数类最终将获得与少数类相同的分数,因此从某种意义上说,分布的统计属性将变为“较弱”。 但是,我们没有通过添加人工数据点来使用这种方法人为地扭曲数据分布。

What does oversampling look like? In shot, the opposite of undersampling. We are artificially adding data points to our dataset to make the number of instances in each class balanced.
过采样看起来像什么? 在拍摄中,欠采样的情况与之相反。 我们正在人为地向数据集中添加数据点,以使每个类中的实例数量保持平衡。
How do we generate these samples? The most common way is to generate points that are close in dataspace proximity to existing samples or are ‘between’ two samples, as illustrated below.
我们如何生成这些样本? 最常见的方法是生成在数据空间中与现有样本接近或在两个样本“之间”的点,如下所示。

As you may have suspected, there are some downsides to adding false data points. Firstly, you risk overfitting, especially if one does this for points that are noise — you end up exacerbating this noise by adding reinforced measurements. In addition, adding these values randomly can also contribute additional noise to our model.
您可能已经怀疑过,添加错误的数据点有一些缺点。 首先,您可能会面临过度拟合的风险,特别是如果对噪声点进行过度拟合时,最终会通过添加增强的测量来加剧这种噪声。 此外,随机添加这些值也会给我们的模型带来额外的噪声。
SMOTE (Synthetic minority oversampling technique)
SMOTE(合成少数群体过采样技术)
Luckily for us, we don’t have to write an algorithm for randomly generating data points for the purpose of oversampling. Instead, we can use the SMOTE algorithm.
对我们来说幸运的是,我们不必编写用于过采样的随机生成数据点的算法。 相反,我们可以使用SMOTE算法。
How does SMOTE work? SMOTE generates new samples in between existing data points based on their local density and their borders with the other class. Not only does it perform oversampling, but can subsequently use cleaning techniques (undersampling, more on this shortly) to remove redundancy in the end. Below is an illustration for how SMOTE works when studying class data.
SMOTE如何工作? SMOTE根据现有数据点的局部密度及其与其他类别的边界在新数据点之间生成新样本。 它不仅执行过采样,而且可以随后使用清除技术(欠采样,稍后对此进行更多介绍)最终消除冗余。 下面是学习班级数据时SMOTE如何工作的图示。
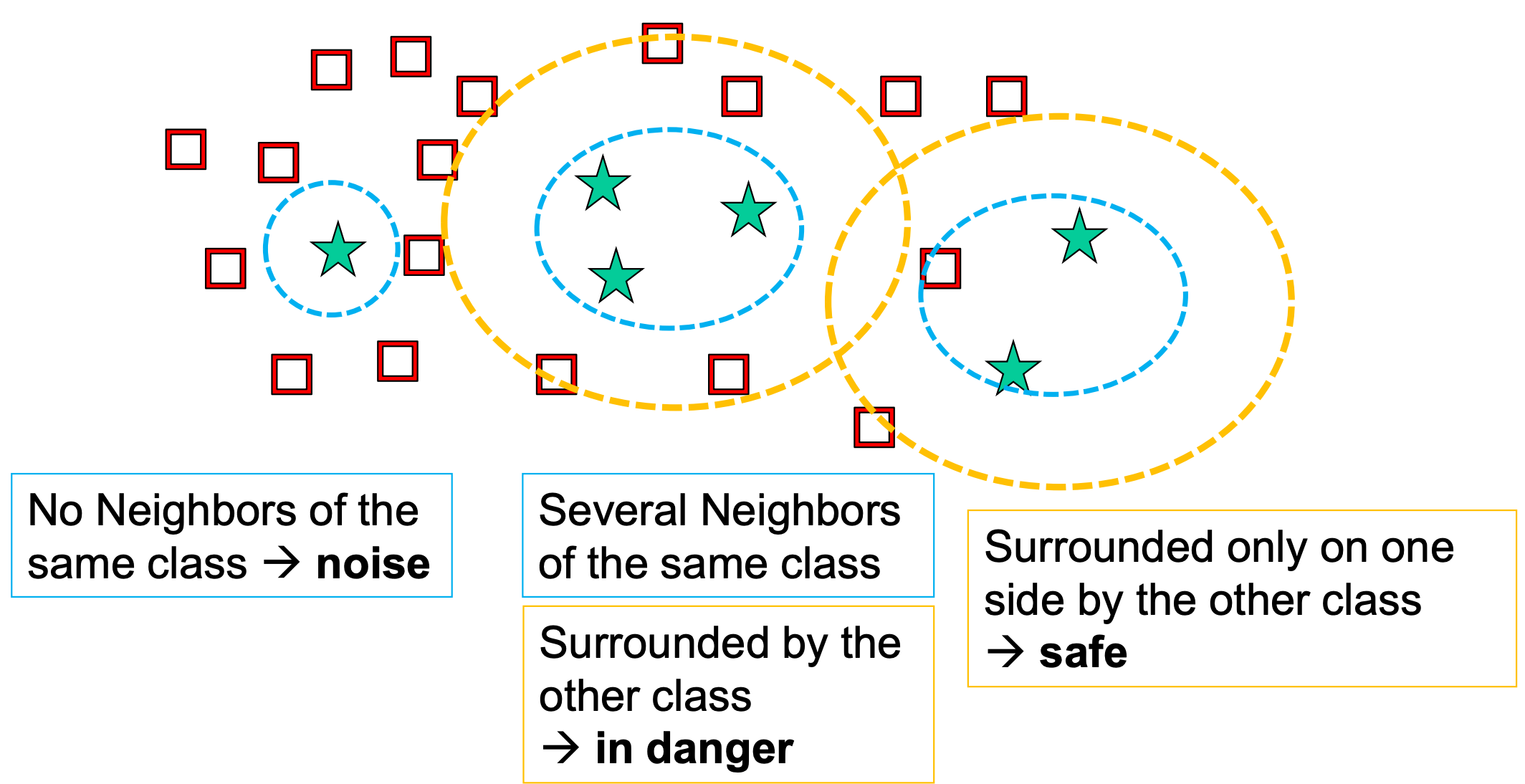
The algorithm for SMOTE is as follows. For each minority sample:
SMOTE的算法如下。 对于每个少数族裔样本:
– Find its k-nearest minority neighbours
–寻找其k最近的少数族裔邻居
– Randomly select j of these neighbours
–随机选择这些邻居中的j个
– Randomly generate synthetic samples along the lines joining the minority sample and its j selected neighbours (j depends on the amount of oversampling desired)
–沿连接少数样本及其j个选定邻居的直线随机生成合成样本(j取决于所需的过采样量)
Informed vs. Random Oversampling
知情vs.随机过采样
Using random oversampling (with replacement) of the minority class has the effect of making the decision region for the minority class very specific. In a decision tree, it would cause a new split and often lead to overfitting. SMOTE’s informed oversampling generalizes the decision region for the minority class. As a result, larger and less specific regions are learned, thus, paying attention to minority class samples without causing overfitting.
使用少数类的随机过采样 (替换)具有使少数类的决策区域非常具体的效果。 在决策树中,这将导致新的分裂并经常导致过度拟合。 SMOTE的明智超采样概括了少数群体的决策区域。 结果,学习了更大和更少的特定区域,因此,在不引起过度拟合的情况下注意少数类样本。
Drawbacks of SMOTE
SMOTE的缺点
Overgeneralization. SMOTE’s procedure can be dangerous since it blindly generalizes the minority area without regard to the majority class. This strategy is particularly problematic in the case of highly skewed class distributions since, in such cases, the minority class is very sparse with respect to the majority class, thus resulting in a greater chance of class mixture.
过度概括。 SMOTE的程序可能很危险,因为它盲目地将少数民族地区泛化而无视多数阶级。 这种策略在阶级分布高度偏斜的情况下尤其成问题,因为在这种情况下,少数阶级相对于多数阶级而言非常稀疏,因此导致阶级混合的机会更大。
Inflexibility. The number of synthetic samples generated by SMOTE is fixed in advance, thus not allowing for any flexibility in the re-balancing rate.
僵硬。 SMOTE生成的合成样本的数量是预先固定的,因此再平衡速率不具有任何灵活性。
Another potential issue is that SMOTE might introduce the artificial minority class examples too deeply in the majority class space. This drawback can be resolved by hybridization: combining SMOTE with undersampling algorithms. One of the most famous of these is Tomek Links. Tomek Links are pairs of instances of opposite classes who are their own nearest neighbors. In other words, they are pairs of opposing instances that are very close together.
另一个潜在的问题是,SMOTE可能会在多数阶层的空间中过于深入地介绍人工少数群体的例子。 这个缺点可以通过杂交解决:将SMOTE与欠采样算法结合在一起。 其中最著名的就是Tomek Links 。 Tomek链接是一对相反类别的实例,它们是自己最近的邻居。 换句话说,它们是一对非常靠近的相对实例。
Tomek’s algorithm looks for such pairs and removes the majority instance of the pair. The idea is to clarify the border between the minority and majority classes, making the minority region(s) more distinct. Scikit-learn has no built-in modules for doing this, though there are some independent packages (e.g., TomekLink, imbalanced-learn).
Tomek的算法会查找此类对,并删除该对的多数实例。 这样做的目的是弄清少数民族和多数阶级之间的界限,使少数民族地区更加鲜明。 尽管有一些独立的软件包(例如TomekLink , imbalanced -learn ),但Scikit-learn没有内置模块可以执行此操作。
Thus, Tomek’s algorithm is an undersampling technique that acts as a data cleaning method for SMOTE to regulate against redundancy. As you may have suspected, there are many additional undersampling techniques that can be combined with SMOTE to perform the same function. A comprehensive list of these functions can be found in the functions section of the imbalanced-learn documentation.
因此,Tomek的算法是一种欠采样技术,可作为SMOTE调节冗余的数据清洗方法。 您可能已经怀疑,还有许多其他的欠采样技术可以与SMOTE结合使用以执行相同的功能。 这些功能的全面列表可在不平衡学习文档的功能部分中找到。
An additional example is Edited Nearest Neighbors (ENN). ENN removes any example whose class label differs from the class of at least two of their neighbor. ENN removes more examples than the Tomek links does and also can remove examples from both classes.
另一个示例是“最近的邻居”(ENN)。 ENN删除任何其类别标签不同于其至少两个邻居的类别的示例。 与Tomek链接相比,ENN删除的示例更多,并且还可以从两个类中删除示例。
Other more nuanced versions of SMOTE include Borderline SMOTE, SVMSMOTE, and KMeansSMOTE, and more nuanced versions of the undersampling techniques applied in concert with SMOTE are Condensed Nearest Neighbor (CNN), Repeated Edited Nearest Neighbor, and Instance Hardness Threshold.
SMOTE的其他细微差别版本包括Borderline SMOTE,SVMSMOTE和KMeansSMOTE,与SMOTE结合使用的欠采样技术的细微差别版本是压缩最近邻(CNN),重复编辑最近邻和实例硬度阈值。
成本敏感型学习 (Cost-Sensitive Learning)
We have discussed sampling techniques and are now ready to discuss cost-sensitive learning. In many ways, the two approaches are analogous — the main difference being that in cost-sensitive learning we perform under- and over-sampling by altering the relative weighting of individual samples.
我们已经讨论了采样技术,现在准备讨论对成本敏感的学习。 在许多方面,这两种方法是相似的-主要区别在于在成本敏感型学习中,我们通过更改单个样本的相对权重来进行欠采样和过采样。
Upweighting. Upweighting is analogous to over-sampling and works by increasing the weight of one of the classes keeping the weight of the other class at one.
增重。 上权类似于过采样,其工作方式是增加一个类别的权重,将另一类别的权重保持为一个。
Down-weighting. Down-weighting is analogous to under-sampling and works by decreasing the weight of one of the classes keeping the weight of the other class at one.
减重。 减权类似于欠采样,它通过减小一个类别的权重而将另一类别的权重保持为一个来工作。
An example of how this can be performed using sklearn is via the sklearn.utils.class_weight function and applied to any sklearn classifier (and within keras).
如何使用sklearn执行此操作的示例是通过sklearn.utils.class_weight函数并将其应用于任何sklearn分类器(以及在keras中)。
from sklearn.utils import class_weight
class_weights = class_weight.compute_class_weight('balanced', np.unique(y_train), y_train)
model.fit(X_train, y_train, class_weight=class_weights)In this case, we have set the instances to be ‘balanced’, meaning that we will treat these instances to have balanced weighting based on their relative number of points — this is what I would recommend unless you have a good reason for setting the values yourself. If you have three classes and wanted to weight one of them 10x larger and another 20x larger (because there are 10x and 20x fewer of these points in the dataset than the majority class), then we can rewrite this as:
在这种情况下,我们将实例设置为“平衡”,这意味着我们将根据它们的相对点数将这些实例视为具有均衡的权重-这是我的建议,除非您有充分的理由来设置值你自己 如果您有三个类别,并且想要将其中一个类别的权重放大10倍,将另一个类别的权重增大20倍(因为数据集中这些点的数量比多数类别少10倍和20倍),则可以将其重写为:
class_weight = {0: 0.1,
1: 1.,
2: 2.}Some authors claim that cost-sensitive learning is slightly more effective than random or directed over- or under-sampling, although all approaches are helpful, and directed oversampling, is close to cost-sensitive learning in efficacy. Personally, when I am working on a machine learning problem I will use cost-sensitive learning because it is much simpler to implement and communicate to individuals. However, there may be additional aspects of using sampling techniques that provide superior results of which I am not aware.
一些作者声称,成本敏感型学习比随机或有针对性的过度采样或欠采样略有效果,尽管所有方法都是有帮助的,有针对性的过度采样在效果上接近于成本敏感型学习。 就个人而言,当我处理机器学习问题时,我将使用成本敏感型学习,因为它易于实现并与个人进行交流 。 但是,使用采样技术可能存在其他方面,这些方面提供了我所不知道的优异结果。
评估指标 (Assessment Metrics)
In this section, I outline several metrics that can be used to analyze the performance of a classifier trained to solve a binary classification problem. These include (1) the confusion matrix, (2) binary classification metrics, (3) the receiver operating characteristic curve, and (4) the precision-recall curve.
在本节中,我概述了几个可用于分析经过训练以解决二进制分类问题的分类器的性能的指标。 其中包括(1)混淆矩阵,(2)二进制分类指标,(3)接收器工作特性曲线和(4)精确调用曲线。
混淆矩阵 (Confusion Matrix)
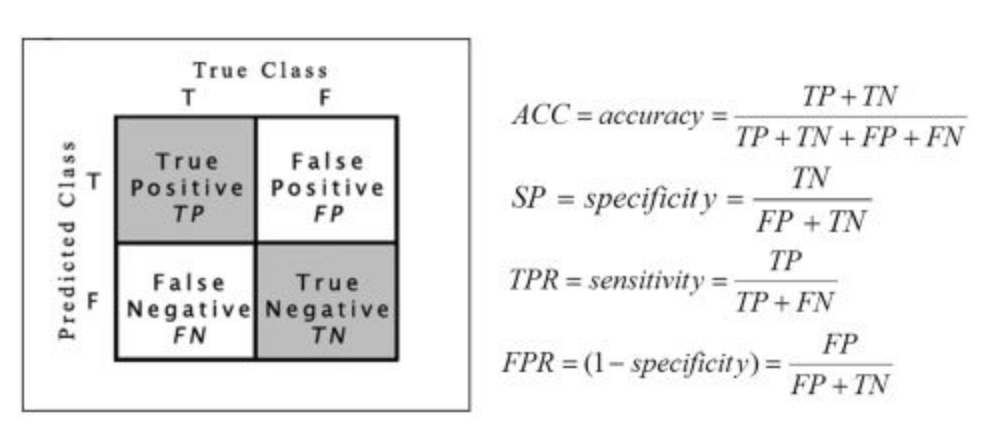
Despite what you may have garnered from its name, a confusion matrix is decidedly confusing. A confusion matrix is the most basic form of assessment of a binary classifier. Given the prediction outputs of our classifier and the true response variable, a confusion matrix tells us how many of our predictions are correct for each class, and how many are incorrect. The confusion matrix provides a simple visualization of the performance of a classifier based on these factors.
尽管您可能从它的名字中学到了什么,但是混乱矩阵显然令人困惑。 混淆矩阵是二进制分类器评估的最基本形式。 给定分类器的预测输出和真实的响应变量,混淆矩阵会告诉我们每个类别正确的预测有多少,不正确的预测有多少。 混淆矩阵基于这些因素提供了分类器性能的简单可视化。
Here is an example of a confusion matrix:
这是一个混淆矩阵的示例:
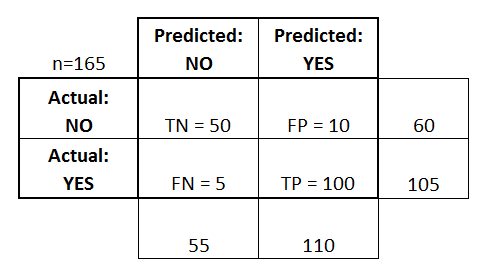
Hopefully what this is showing is relatively clear. The TN cell tells us the number of true positives: the number of positive samples that I predicted were positive.
希望这显示的是相对清楚的。 TN细胞告诉我们真正的阳性数量:我预测的阳性样品数量为阳性。
The TP cell tells us the number of true negatives: the number of negative samples that I predicted were negative.
TP单元告诉我们真实阴性的数量:我预测的阴性样品的数量为阴性。
The FP cell tells us the number of false positives: the number of negative samples that I predicted were positive.
FP细胞告诉我们假阳性的数量:我预测的阴性样品的数量是阳性的。
The FN cell tells us the number of false negatives: the number of positive samples that I predicted were positive.
FN细胞告诉我们假阴性的数量:我预测的阳性样品的数量为阳性。
These numbers are very important as they form the basis of the binary classification metrics discussed next.
这些数字非常重要,因为它们构成了下面讨论的二进制分类指标的基础。
二进制分类指标 (Binary Classification Metrics)
There are a plethora of single-value metrics for binary classification. As such, only a few of the most commonly used ones and their different formulations are presented here, more details can be found on scoring metrics in the sklearn documentation and on their relation to confusion matrices and ROC curves (discussed in the next section) here.
二进制分类有很多单值指标。 因此,此处仅介绍一些最常用的方法及其不同的公式,有关更多详细信息,请参见sklearn文档中的评分指标以及它们与混淆矩阵和ROC曲线的关系(在下一节中讨论) 。 。
Arguably the most important five metrics for binary classification are: (1) precision, (2) recall, (3) F1 score, (4) accuracy, and (5) specificity.
可以说,二元分类最重要的五个指标是:(1)精度,(2)回忆,(3)F1得分,(4)准确性和(5)特异性。
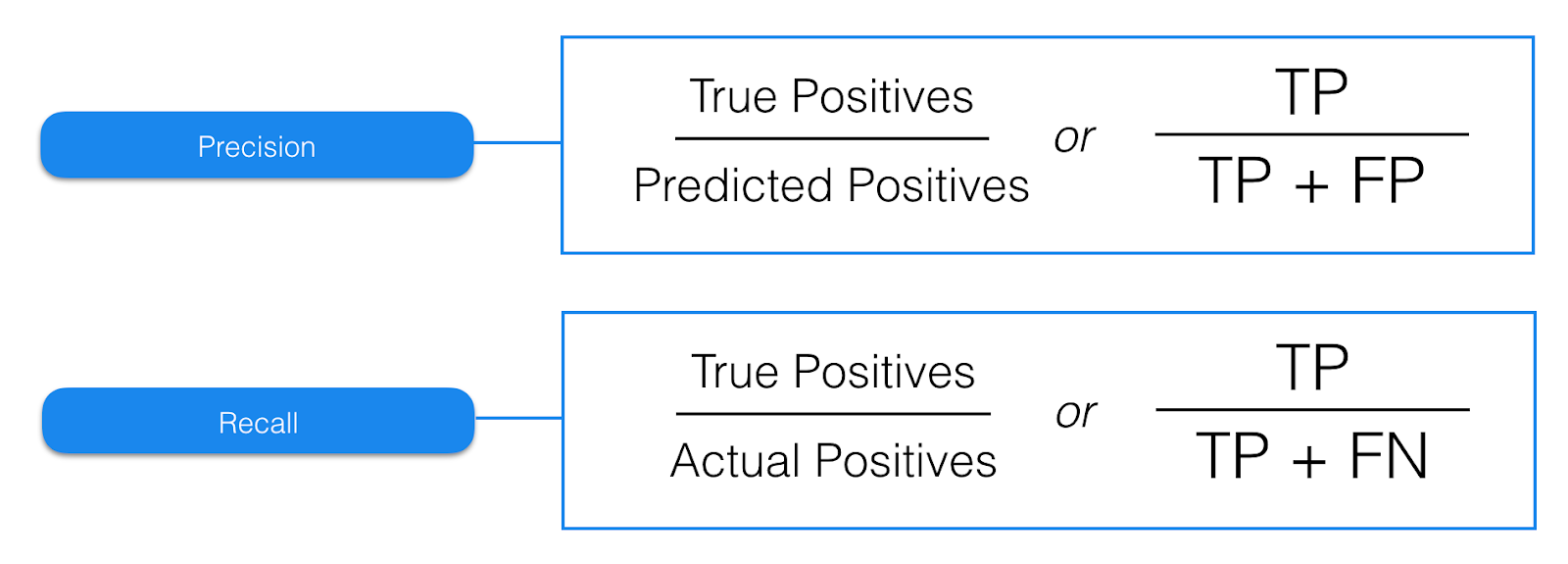
Precision. Precision provides us with the answer to the question “Of all my positive predictions, what proportion of them are correct?”. If you have an algorithm that predicts all of the positive class correctly but also has a large portion of false positives, the precision will be small. It makes sense why this is called precision since it is a measure of how ‘precise’ our predictions are.
精确。 Precision为我们提供了以下问题的答案: “在我所有的积极预测中,有多少是正确的?” 。 如果您有一种算法可以正确预测所有肯定分类,但也有很大一部分误报,则精度会很小。 之所以将其称为“精度”是有道理的,因为它可以衡量我们的预测有多“精确”。
Recall. Recall provides us with the answer to a different question “Of all of the positive samples, what proportion did I predict correctly?”. Instead of false positives, we are now interested in false negatives. These are items that our algorithm missed, and are often the most egregious errors (e.g. failing to diagnose something with cancer that actually has cancer, failing to discover malware when it is present, or failing to spot a defective item). The name ‘recall’ also makes sense for this circumstance as we are seeing how many of the samples the algorithm was able to pick up on.
召回。 Recall为我们提供了一个不同问题的答案: “在所有阳性样本中,我正确预测的比例是多少?” 。 现在,我们对假阴性感兴趣了,而不是假阳性。 这些是我们的算法遗漏的项目,并且通常是最严重的错误(例如,未能诊断出确实患有癌症的癌症,无法发现恶意软件或存在缺陷的项目)。 在这种情况下,“召回”这个名称也很有意义,因为我们看到了该算法能够提取多少个样本。
It should be clear that these questions, whilst related, are substantially different to each other. It is possible to have a very high precision and simultaneously have a low recall, and vice versa. For example, if you predicted the majority class every time, you would have 100% recall on the majority class, but you would then get a lot of false positives from the minority class.
应当明确的是,这些问题虽然相关,但彼此之间却有很大不同。 可能有很高的精度,同时召回率也很低,反之亦然。 例如,如果您每次都预测多数派,则多数派将有100%的回忆率,但随后您将从少数派中得到很多误报。
One other important point to make is that precision and recall can be determined for each individual class. That is, we can talk about the precision of class A, or the precision of class B, and they will have different values — when doing this, we assume that the class we are interested in is the positive class, regardless of its numeric value.
另一个重要的观点是, 可以为每个单独的类确定精度和召回率 。 也就是说,我们可以谈论类A的精度或类B的精度,并且它们将具有不同的值-这样做时,我们假设我们感兴趣的类是正类,而不管其数值如何。
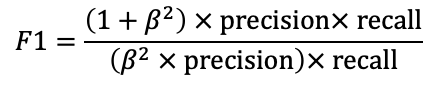
F1 Score. The F1 score is a single-value metric that combines precision and recall by using the harmonic mean (a fancy type of averaging). The β parameter is a strictly positive value that is used to describe the relative importance of recall to precision. A larger β value puts a higher emphasis on recall than precision, whilst a smaller value puts less emphasis. If the value is 1, precision and recall are treated with equal weighting.
F1分数。 F1分数是一个单值指标,通过使用谐波均值(一种奇特的平均值)将精度和召回率结合在一起。 β参数是一个严格的正值,用于描述召回对精度的相对重要性。 β值较大时,对查全率的重视程度要高于精度,而β值较小时,对查全率的重视程度较低。 如果该值为1,则精度和召回率将以相等的权重处理。
What does a high F1 score mean? It suggests that both the precision and recall have high values — this is good and is what you would hope to see upon generating a well-functioning classification model on an imbalanced dataset. A low value indicates that either precision or recall is low, and maybe a call for concern. Good F1 scores are generally lower than good accuracies (in many situations, an F1 score of 0.5 would be considered pretty good, such as predicting breast cancer from mammograms).
F1高分意味着什么? 它表明精度和查全率都具有很高的值-这很好,这是在不平衡数据集上生成功能良好的分类模型时希望看到的。 较低的值表示准确性或召回率较低,可能表示需要关注。 良好的F1分数通常低于良好的准确性(在许多情况下,F1分数0.5被认为是相当不错的,例如根据乳房X线照片预测乳腺癌)。
Specificity. Simply stated, specificity is the recall of negative values. It answers the question “Of all of my negative predictions, what proportion of them are correct?”. This may be important in situations where examining the relative proportion of false positives is necessary.
特异性。 简而言之,特异性就是召回负值。 它回答了一个问题: “在我所有的负面预测中,有多少比例是正确的?” 。 这在需要检查假阳性的相对比例的情况下可能很重要。
Macro, Micro, and Weighted Scores
宏观,微观和加权分数
This is where things get a little complicated. Anyone who has delved into these metrics on sklearn may have noticed that we can refer to the recall-macro or f1-weighted score.
这会使事情变得有些复杂。 认真研究了sklearn的这些指标的任何人都可能已经注意到,我们可以参考召回宏或f1加权得分。
A macro-F1 score is the average of F1 scores across each class.
宏观F1分数是每个课程中F1分数的平均值。
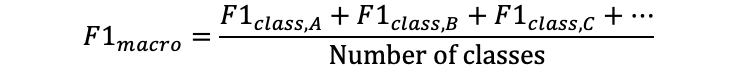
This is most useful if we have many classes and we are interested in the average F1 score for each class. If you only care about the F1 score for one class, you probably won’t need a macro-F1 score.
如果我们有很多班,并且我们对每个班的平均F1成绩感兴趣,这将是最有用的。 如果您只关心一个班级的F1分数,则可能不需要宏F1分数。
A micro-F1 score takes all of the true positives, false positives, and false negatives from all the classes and calculates the F1 score.
微型F1分数采用所有类别中的所有真实肯定,错误肯定和错误否定,并计算F1得分。
The micro-F1 score is pretty similar in utility to the macro-F1 score as it gives an aggregate performance of a classifier over multiple classes. That being said, they will give different results and understand the underlying difference in that result may be informative for a given application.
微型F1得分的效用与宏观F1得分非常相似,因为它提供了多个类别的分类器的综合性能。 话虽如此,他们将给出不同的结果,并了解该结果的根本差异可能对给定的应用程序有帮助。
A weighted-F1 score is the same as the macro-F1 score, but each of the class-specific F1 scores is scaled by the relative number of samples from that class.
加权F1分数与宏F1分数相同,但是每个类别特定的F1分数均根据该类别的样本的相对数量进行缩放。
In this case, N refers to the proportion of samples in the dataset belonging to a single class. For class A, where class A is the majority class, this might be equal to 0.8 (80%). The values for B and C might be 0.15 and 0.05, respectively.
在这种情况下, N是指数据集中属于单个类别的样本所占的比例。 对于A类,其中A类为多数类,这可能等于0.8(80%)。 B和C的值分别为0.15和0.05。
For a highly imbalanced dataset, a large weighted-F1 score might be somewhat misleading because it is overly influenced by the majority class.
对于高度不平衡的数据集,较大的F1加权分数可能会引起误导,因为它受到多数类别的过度影响。
Other Metrics
其他指标
Some other metrics that you may see around that can be informative for binary classification (and multiclass classification to some extent) are:
您可能会发现的一些其他指标可对二进制分类(在某种程度上,以及多类分类)有所帮助:
Accuracy. If you are reading this, I would imagine you are already familiar with accuracy, but perhaps not so familiar with the others. Cast in the light of a metric for a confusion matrix, the accuracy can be described as the ratio of true predictions (positive and negative) to the sum of the total number of positive and negative samples.
准确性。 如果您正在阅读本文,我想您已经对准确性很熟悉,但对其他准确性可能不太了解。 根据混淆矩阵的度量标准,可以将准确度描述为真实预测(阳性和阴性)与阳性和阴性样本总数之和的比率。
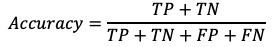
G-Mean. A less common metric that is somewhat analogous to the F1 score is the G-Mean. This is often cast in two different formulations, the first being the precision-recall g-mean, and the second being the sensitivity-specificity g-mean. They can be used in a similar manner to the F1 score in terms of analyzing algorithmic performance. The precision-recall g-mean can also be referred to as the Fowlkes-Mallows Index.
G均值。 G均值是一种不太常见的指标,与F1分数有些相似。 通常用两种不同的公式表示,第一种是精确调用g均值,第二种是敏感性特异性g均值。 就分析算法性能而言,它们可以与F1分数类似的方式使用。 精确调用g均值也可以称为Fowlkes-Mallows索引 。
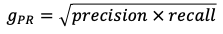
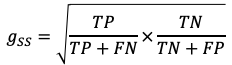
There are many other metrics that can be used, but most have specialized use cases and offer little additional utility over the metrics described here. Other metrics the reader may be interested in viewing are balanced accuracy, Matthews correlation coefficient, markedness, and informedness.
可以使用许多其他指标,但是大多数指标都有专门的用例,并且与此处描述的指标相比,几乎没有其他用途。 读者可能感兴趣的其他指标是平衡的准确性 , 马修斯相关系数 , 标记性和信息灵通性 。
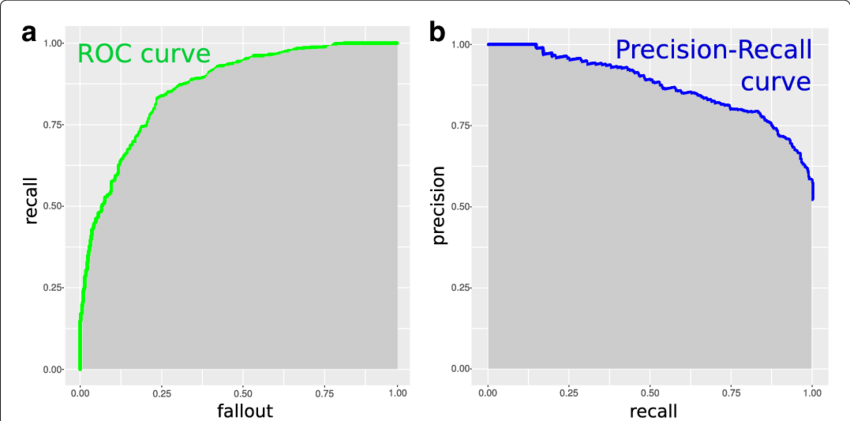
Receiver Operating Characteristic (ROC) Curve
接收器工作特性(ROC)曲线
An ROC curve is a two-dimensional graph to depicts trade-offs between benefits (true positives) and costs (false positives). It displays a relation between sensitivity and specificity for a given classifier (binary problems, parameterized classifier or a score classification).
ROC曲线是一个二维图形,用于描述收益(真实肯定)和成本(错误真实)之间的权衡。 它显示了给定分类器(二进制问题,参数化分类器或分数分类)的敏感性和特异性之间的关系。
Here is an example of an ROC curve.
这是ROC曲线的示例。
There is a lot to unpack here. Firstly, the dotted line through the center corresponds to a classifier that acts as a ‘coin flip’. That is, it is correct roughly 50% of the time and is the worst possible classifier (we are just guessing). This acts as our baseline, against which we can compare all other classifiers — these classifiers should be closer to the top left corner of the plot since we want high true positive rates in all cases.
这里有很多要解压的东西。 首先,通过中心的虚线对应于充当“硬币翻转”的分类器。 也就是说,大约50%的时间是正确的,并且是最糟糕的分类器(我们只是在猜测)。 这是我们的基准,可以与所有其他分类器进行比较-这些分类器应更靠近图的左上角,因为在所有情况下我们都希望有较高的真实阳性率。
It should be noted that an ROC curve does not assess a group of classifiers. Rather, it examines a single classifier over a set of classification thresholds.
应该注意的是,ROC曲线不评估一组分类器。 而是,它在一组分类阈值上检查单个分类器 。
What does this mean? It means that for one point, I take my classifier and set the threshold to be 0.3 (30% propensity) and then assess the true positive and false positive rates.
这是什么意思? 这意味着,我将分类器的阈值设置为0.3(倾向性为30%),然后评估真实的阳性和假阳性率。
True Positive Rate: Percentage of true positives (to the sum of true positives and false negatives) generated by the combination of a specific classifier and classification threshold.
真实肯定率: 特定分类器和分类阈值的组合所生成的 真实肯定率 (相对于真实肯定率和错误否定率)。
False Positive Rate: Percentage of false positives (to the sum of false positives and true negatives) generated by the combination of a specific classifier and classification threshold.
误报率: 特定分类器和分类阈值的组合所产生的误报率(占误报率和真实否定值的总和)。
This gives me two numbers, which I can then plot on the curve. I then take another threshold, say 0.4, and repeat this process. After doing this for every threshold of interest (perhaps in 0.1, 0.01, or 0.001 increments), we have constructed an ROC curve for this classifier.
这给了我两个数字,然后可以在曲线上绘制它们。 然后,我将另一个阈值设为0.4,然后重复此过程。 在对每个感兴趣的阈值执行此操作后(可能以0.1、0.01或0.001为增量),我们为此分类器构建了ROC曲线。
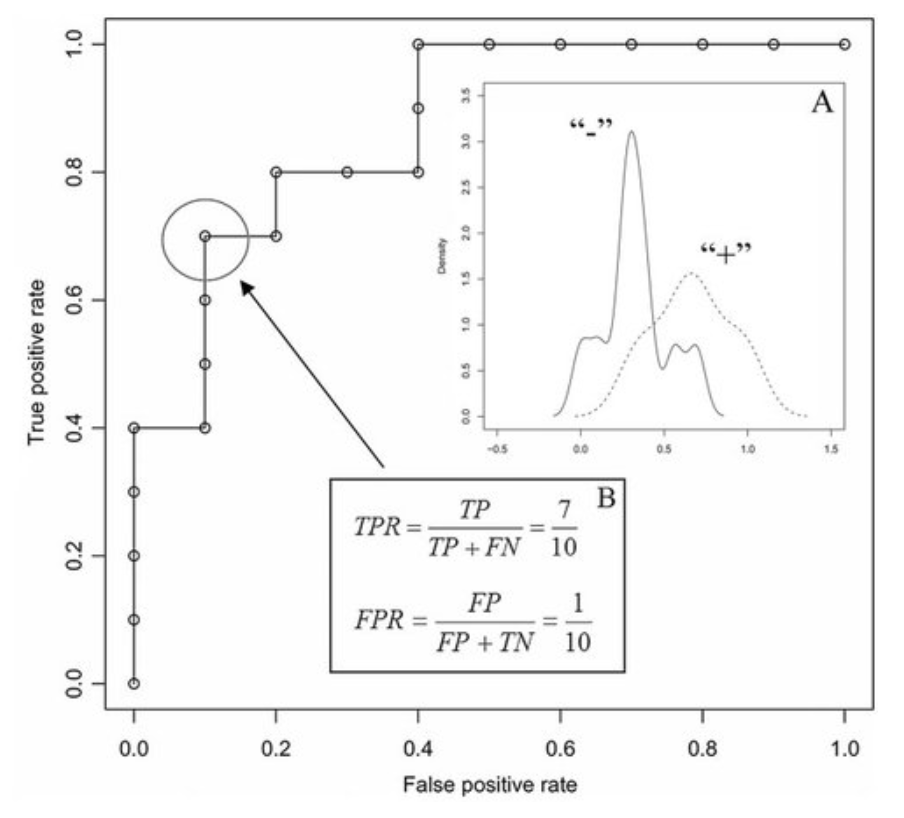
What is the point of doing this? Depending on your application, you may be very averse to false positives as they may be very costly (e.g. launches of nuclear missiles) and thus would like a classifier that has a very low false-positive rate. Conversely, you may not care so much about having a highfalse positive rate as long as you get a high true positive rate (stopping most events of fraud may be worth it even if you have to check many more occurrences that are flagged by the algorithm as flawed). For the optimal balance between these two ratios (where false positives and false negatives are equally costly), we would take the classification threshold which results in the minimum diagonal distance from the top left corner.
这样做有什么意义? 根据您的应用,您可能会反对误报,因为误报的代价可能很高(例如,发射核导弹),因此希望分类器的误报率非常低。 相反,只要您获得很高的真实阳性率,您可能就不会太在意高假阳性率(即使必须检查该算法标记为的更多事件,停止大多数欺诈事件也是值得的)有缺陷的)。 为了在这两个比率之间实现最佳平衡(假阳性和假阴性的代价均相同),我们将采用分类阈值,以使距左上角的对角线距离最小。
Why does the top left corner correspond to the ideal classifier? The ideal point on the ROC curve would be (0,100), that is, all positive examples are classified correctly and no negative examples are misclassified as positive. In a perfect classifier, there would be no misclassification!
为什么左上角对应于理想分类器? ROC曲线上的理想点是(0,100) ,也就是说,所有正样本都正确分类,没有负样本被误分类为正样本。 在一个完美的分类器中,不会出现分类错误!
Whilst a graph may not seem pretty useful in itself, it is helpful in comparing classifiers. One particular metric, the Area Under Curve (AUC) score, allows us to compare classifiers by comparing the total area underneath the line produced on the ROC curve. For an ideal classifier, the AUC equals 1, since we are multiplying 100% (1.0) true positive rate by 100% (1.0) false-positive rate. If a particular classifier has an ROC of 0.6 and another has an ROC of 0.8, the latter is clearly a better classifier. The AUC has the benefit that it is independent of the decision criteria — the classification threshold — and thus makes it easier to compare these classifiers.
虽然图本身似乎不太有用,但它有助于比较分类器。 一种特殊的度量标准,即曲线下面积(AUC)得分,使我们可以通过比较ROC曲线上生成的线下的总面积来比较分类器。 For an ideal classifier, the AUC equals 1, since we are multiplying 100% (1.0) true positive rate by 100% (1.0) false-positive rate. If a particular classifier has an ROC of 0.6 and another has an ROC of 0.8, the latter is clearly a better classifier. The AUC has the benefit that it is independent of the decision criteria — the classification threshold — and thus makes it easier to compare these classifiers.
A question may have come to mind now — what if some classifiers are better at lower thresholds and some are better at higher thresholds? This is where the ROC convex hull comes in. The convex hull provides us with a method of identifying potentially optimal classifiers — even though we may not have directly observed them, we can infer their existence. Consider the following diagram:
A question may have come to mind now — what if some classifiers are better at lower thresholds and some are better at higher thresholds? This is where the ROC convex hull comes in. The convex hull provides us with a method of identifying potentially optimal classifiers — even though we may not have directly observed them, we can infer their existence. Consider the following diagram:
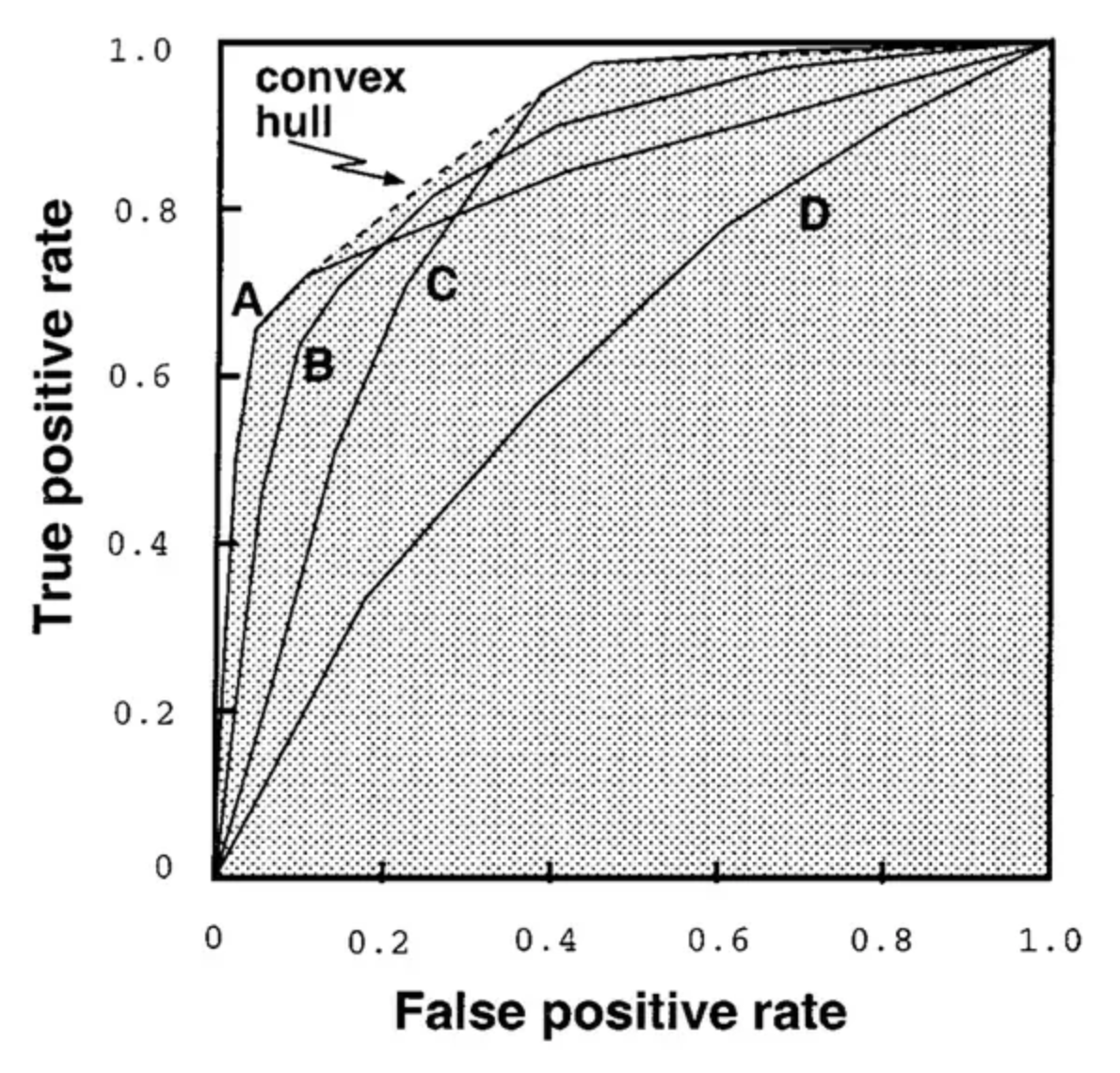
Given a family of ROC curves, the ROC convex hull can include points that are more towards the top left corner (perfect classifier) of the ROC space. If a line passes through a point on the convex hull, then there is no other line with the same slope passing through another point with a larger true positive intercept. Thus, the classifier at that point is optimal under any distribution assumptions in tandem with that slope. This is perhaps easier to understand after examining the image.
Given a family of ROC curves, the ROC convex hull can include points that are more towards the top left corner (perfect classifier) of the ROC space. If a line passes through a point on the convex hull, then there is no other line with the same slope passing through another point with a larger true positive intercept. Thus, the classifier at that point is optimal under any distribution assumptions in tandem with that slope. This is perhaps easier to understand after examining the image.
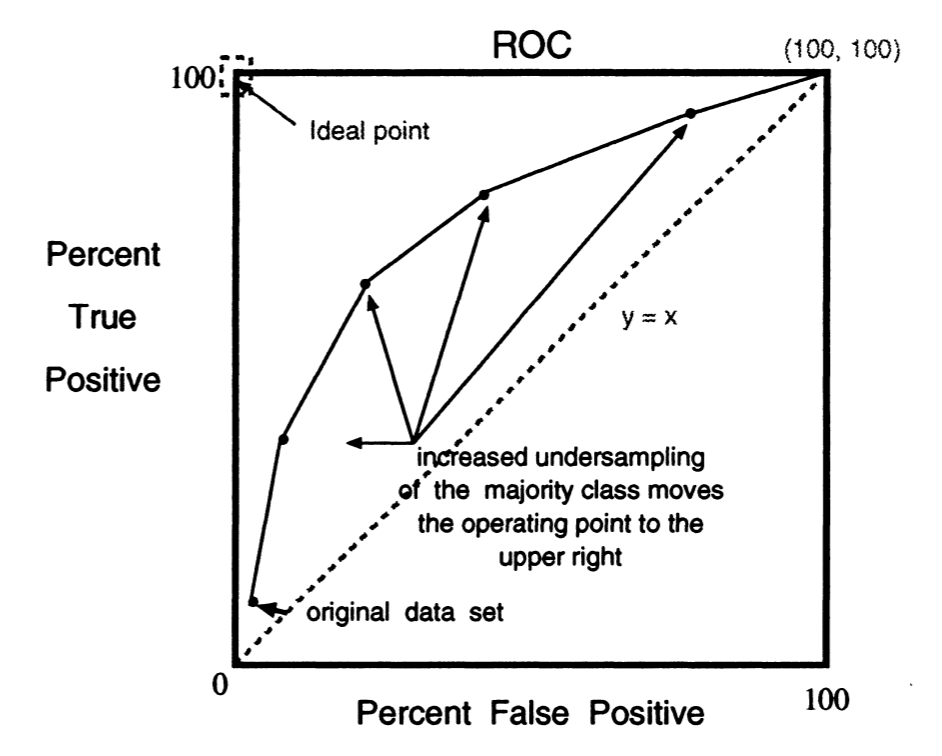
How does undersampling/oversampling influence the ROC curve? A famous paper on SMOTE (discussed previously) titled “SMOTE: Synthetic Minority Over-sampling Technique” outlines that by undersampling the majority class, we force the ROC curve to move up and to the right, and thus has the potential to increase the AUC of a given classifier (this is essentially just validation that SMOTE functions correctly, as expected). Similarly, oversampling the minority class has a similar impact.
How does undersampling/oversampling influence the ROC curve? A famous paper on SMOTE (discussed previously) titled “ SMOTE: Synthetic Minority Over-sampling Technique ” outlines that by undersampling the majority class, we force the ROC curve to move up and to the right, and thus has the potential to increase the AUC of a given classifier (this is essentially just validation that SMOTE functions correctly, as expected). Similarly, oversampling the minority class has a similar impact.
Precision-Recall (PR) Curves
Precision-Recall (PR) Curves
An analogous diagram to an ROC curve can be recast from ROC space and reformulated into PR space. These diagrams are in many ways analogous to the ROC curve, but instead of plotting recall against fallout (true positive rate vs. false positive rate), we are instead plotting precision against recall. This produces a somewhat mirror-image (the curve itself will look somewhat different) of the ROC curve in the sense that the top right corner of a PR curve designates the ideal classifier. This can often be more understandable than an ROC curve but provides very similar information. The area under a PR curve is often called mAP and is analogous to the AUC in ROC space.
An analogous diagram to an ROC curve can be recast from ROC space and reformulated into PR space. These diagrams are in many ways analogous to the ROC curve, but instead of plotting recall against fallout (true positive rate vs. false positive rate), we are instead plotting precision against recall. This produces a somewhat mirror-image (the curve itself will look somewhat different) of the ROC curve in the sense that the top right corner of a PR curve designates the ideal classifier. This can often be more understandable than an ROC curve but provides very similar information. The area under a PR curve is often called mAP and is analogous to the AUC in ROC space.
Final Comments (Final Comments)
Imbalanced datasets are underrepresented (no pun intended) in many data science programs contrary to their prevalence and importance in many industrial machine learning applications. It is the job of the data scientist to be able to recognize when a dataset is imbalanced and follow procedures and utilize metrics that allow this imbalance to be sufficiently understood and controlled.
Imbalanced datasets are underrepresented (no pun intended) in many data science programs contrary to their prevalence and importance in many industrial machine learning applications. It is the job of the data scientist to be able to recognize when a dataset is imbalanced and follow procedures and utilize metrics that allow this imbalance to be sufficiently understood and controlled.
I hope that in the course of reading this article you have learned something about dealing with imbalanced datasets and are in the future will be comfortable in the face of such imbalanced problems. If you are a serious data scientist, it is only a matter of time before one of these applications will pop up!
I hope that in the course of reading this article you have learned something about dealing with imbalanced datasets and are in the future will be comfortable in the face of such imbalanced problems. If you are a serious data scientist, it is only a matter of time before one of these applications will pop up!
Newsletter (Newsletter)
For updates on new blog posts and extra content, sign up for my newsletter.
For updates on new blog posts and extra content, sign up for my newsletter.
翻译自: https://towardsdatascience.com/guide-to-classification-on-imbalanced-datasets-d6653aa5fa23
数据安全分类分级实施指南
相关文章

宁波财经学院计算机原理题库,计算机原理题库(整合版)

力扣 538. 把二叉搜索树转换为累加树 1038. 从二叉搜索树到更大和树

计算机组成原理实验运动码表,计算机组成原理

第六章——计算机的运算方法

计算机组成原理——计算机的运算方法

