guava cache是谷歌开源的一种本地缓存,实现原理类似于ConcurrentHashMap,使用segments分段锁,保证线程安全,支持高并发场景。同时支持多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等。
这里要讲是 它的cache下的get接口:
V get(K key, Callable<? extends V> loader) throws ExecutionException;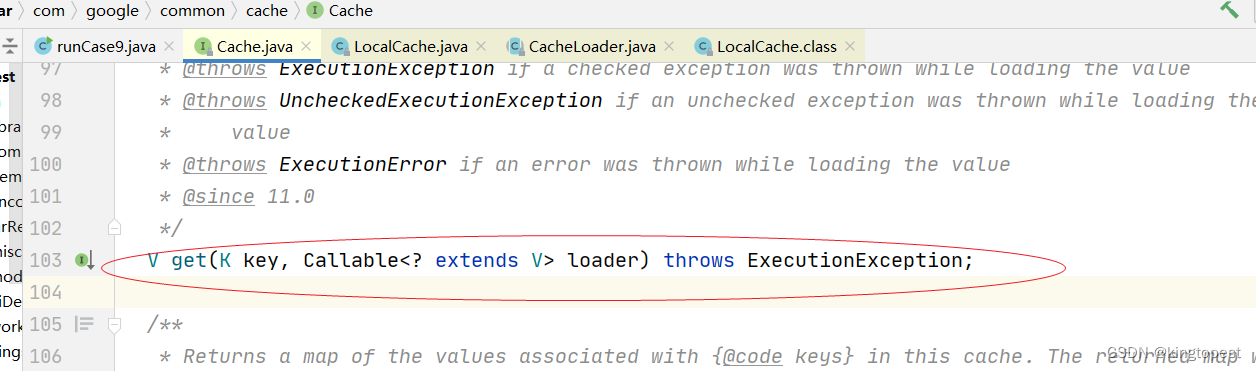
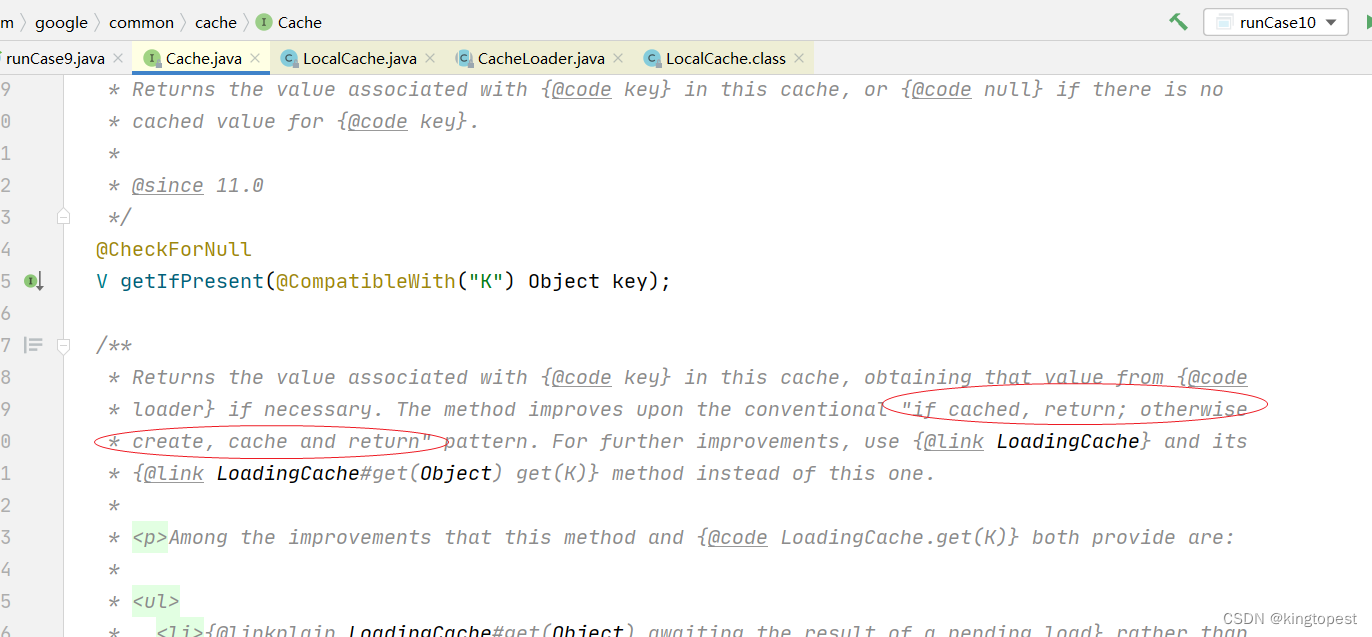
这个接口有个注意点:如上英文圈红部分: if cached,return;otherwise create,cache and return.
意思就是: 查询缓存:如果有记录,就返回该记录;如果没有,就创建记录,并缓存起来,然后返回。
实际应用场合也确实是这么用的,如下面的代码:
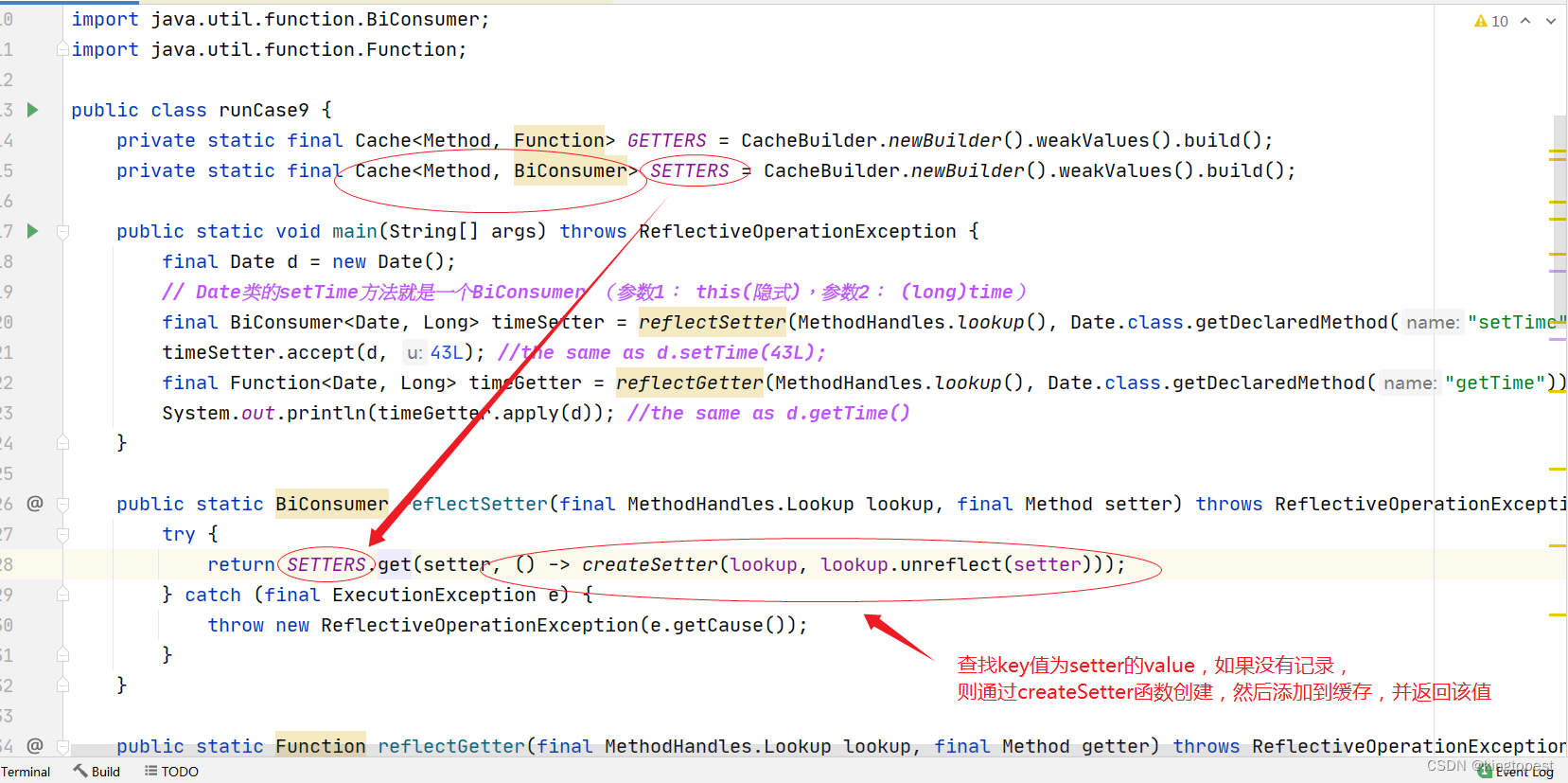
但是这种机制是怎么实现的,特别是:如果查询不到key对应的值,就通过函数loader创建,这个具体是如何通过代码实现的,下面就通过源码来分析:
首先跟进上面SETTERS的build方法

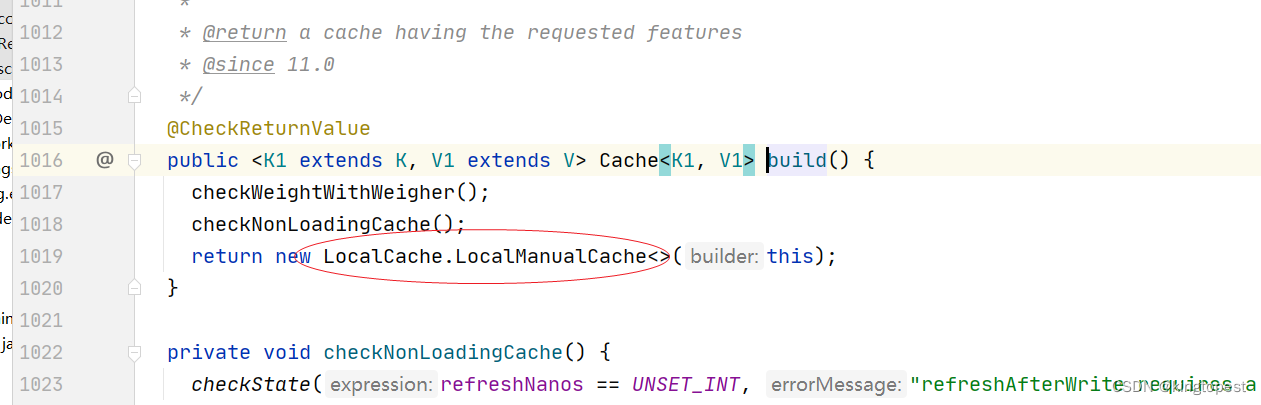
发现是通过 LocalCache.LocalManualCache方法创建的,
所以cache.get方法的实现类也是LocalManualCache
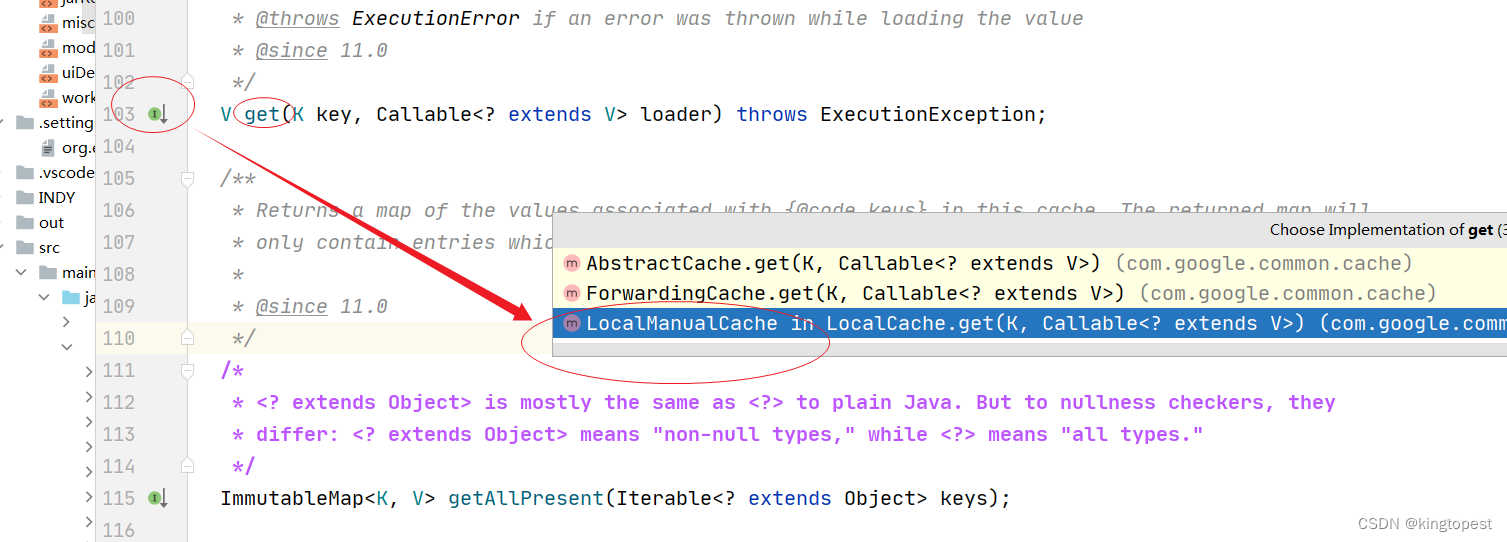
跟进LocalManualCache.get方法,点击加号展开CacheLoader所在行的lambda表达式,查看它具体覆写了什么抽象方法/接口

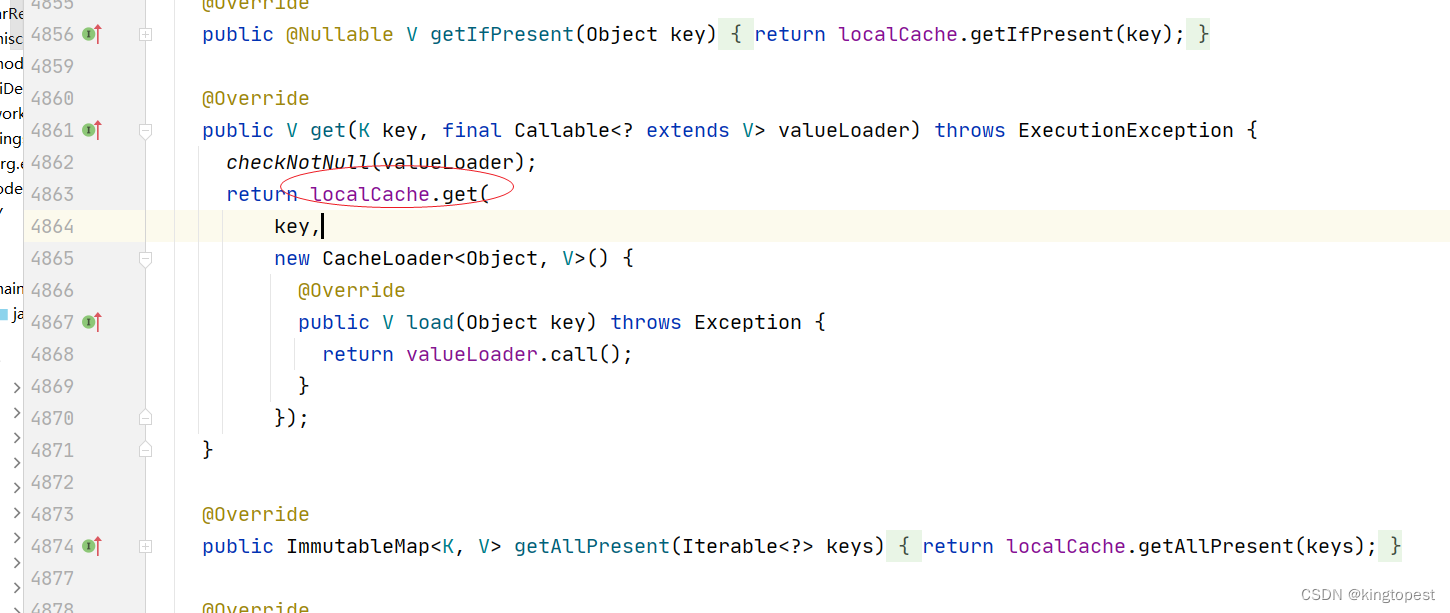
这里实际是覆写了抽象类CacheLoader的load方法:get不到key值时,通过调用valueLoader的call方法获取到key值(valueLoader是一个Callable函数式接口,通过call方法可以调用它的接口实现)
但问题的关键是:在代码层面什么时候才会调用valueLoader的call方法,执行的时机是什么,具体机制是什么?
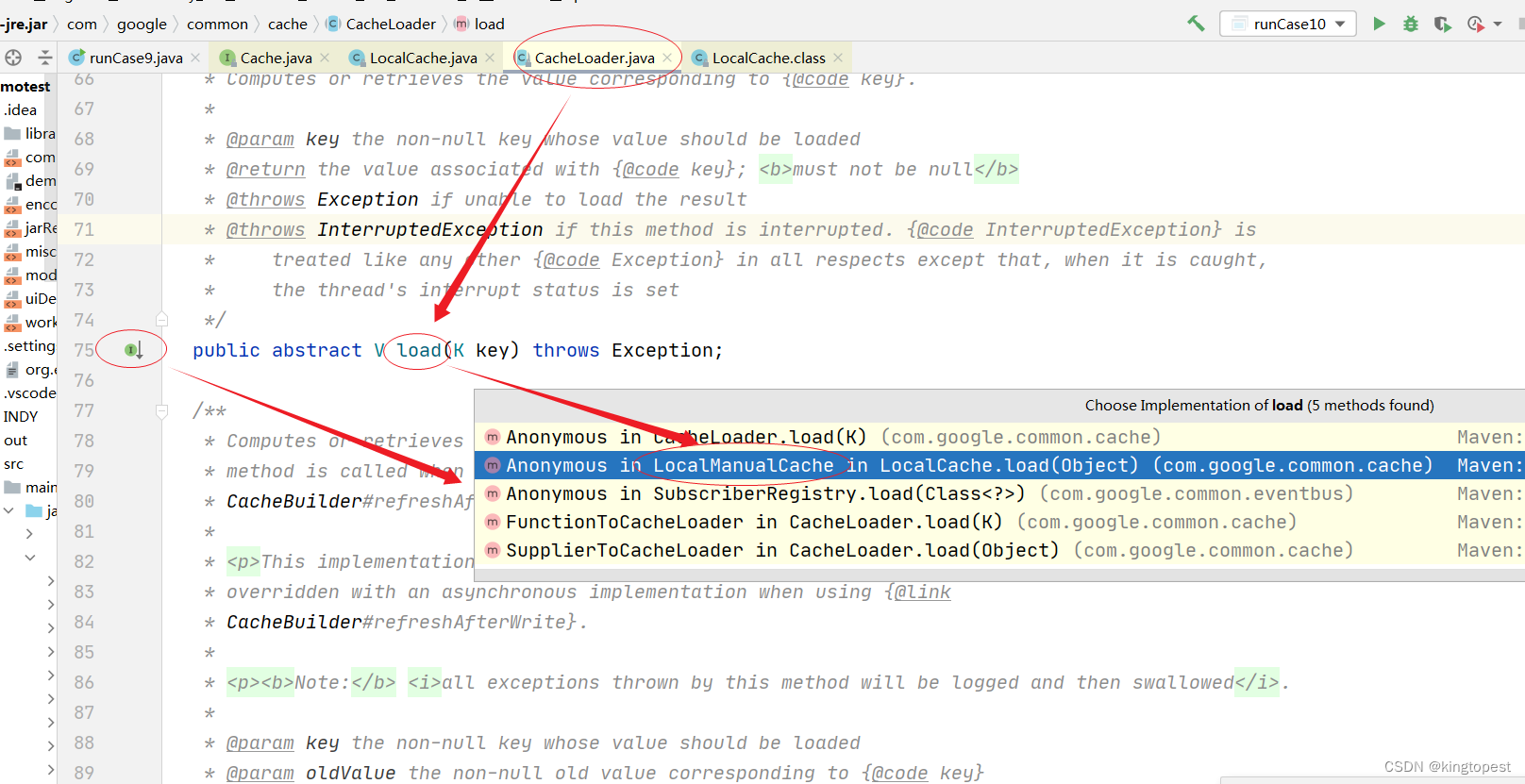
考虑到valueLoader.call方法是在覆写CacheLoader的load方法里面实现的,所以问题转换成==》CacheLoader的load方法是在什么时候被触发执行的?
继续跟进localCache.get方法, 跟进到 它里面的segmentFor(hash).get方法

可以看到:get不到key值时,必然进入lockedGetOrLoad方法
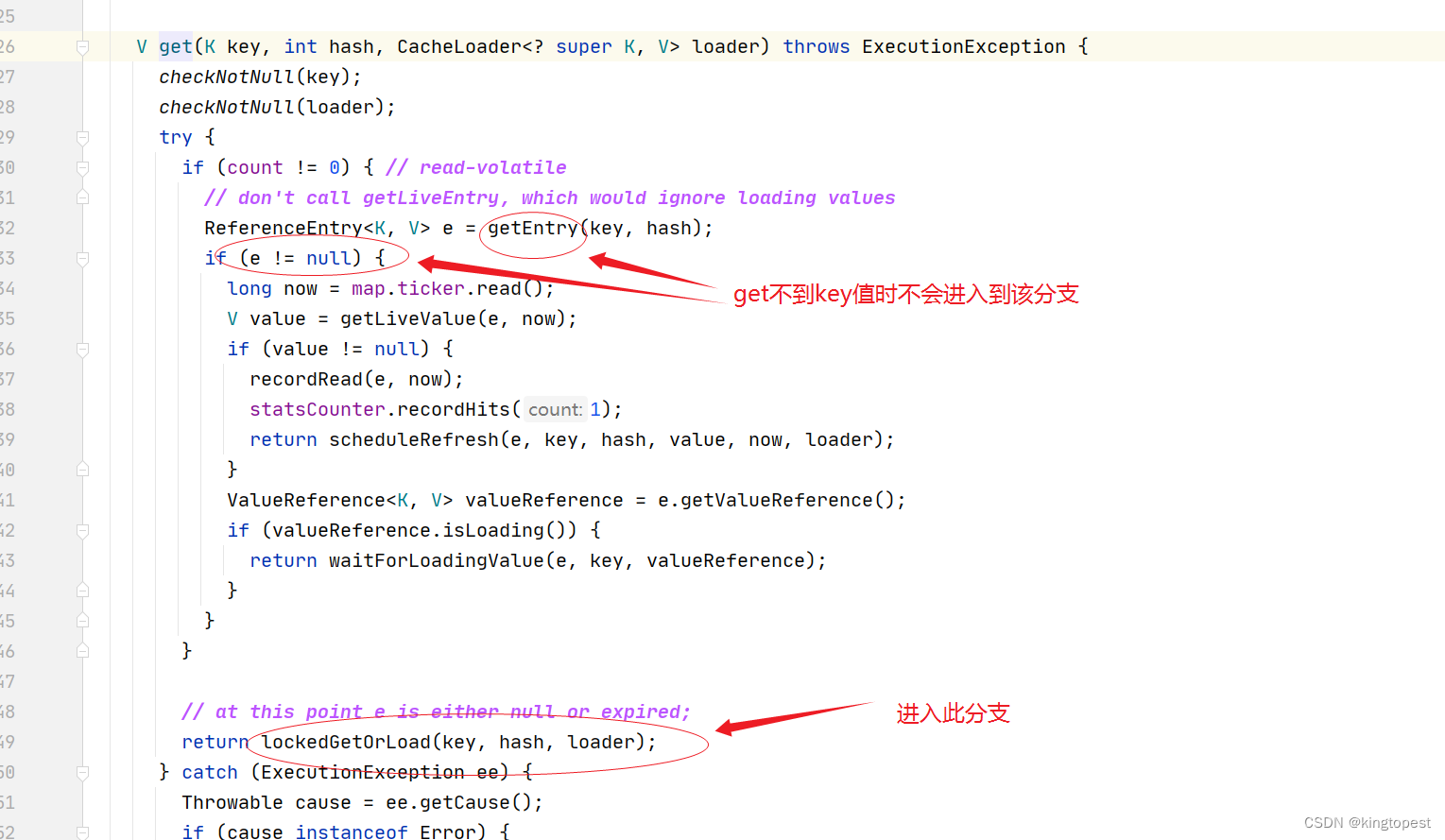
跟进lockedGetOrLoad方法,进入下图中的loadSync方法
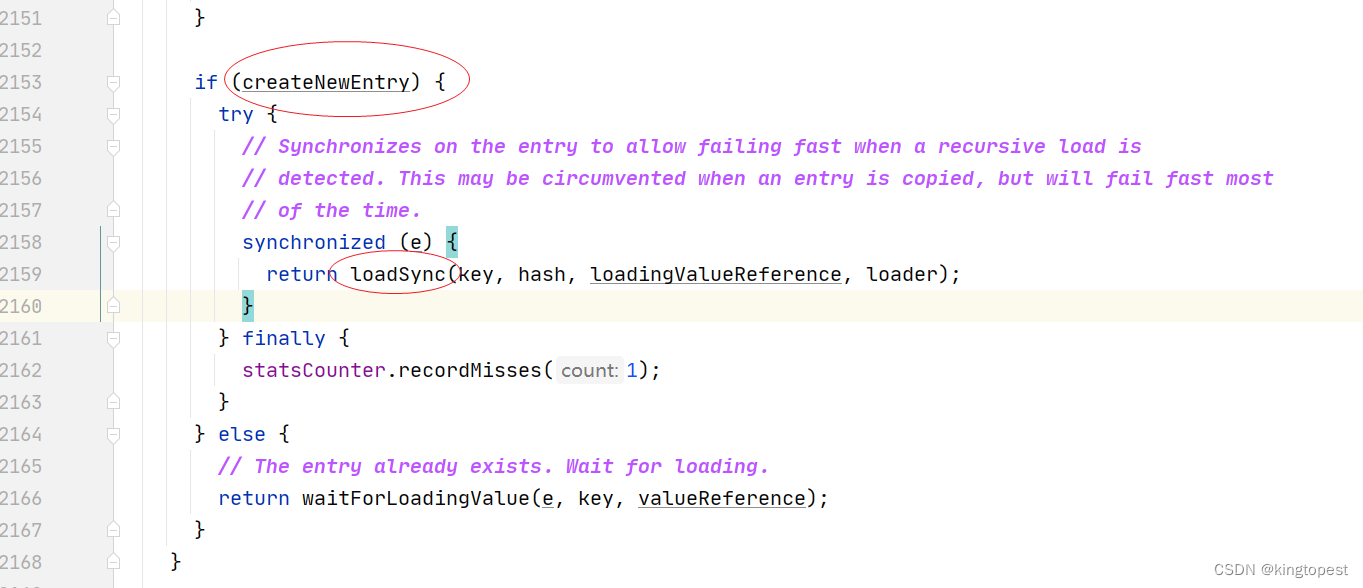
跟进loadSync方法,进入其中的loadFuture方法(这里明显就是个异步回调)
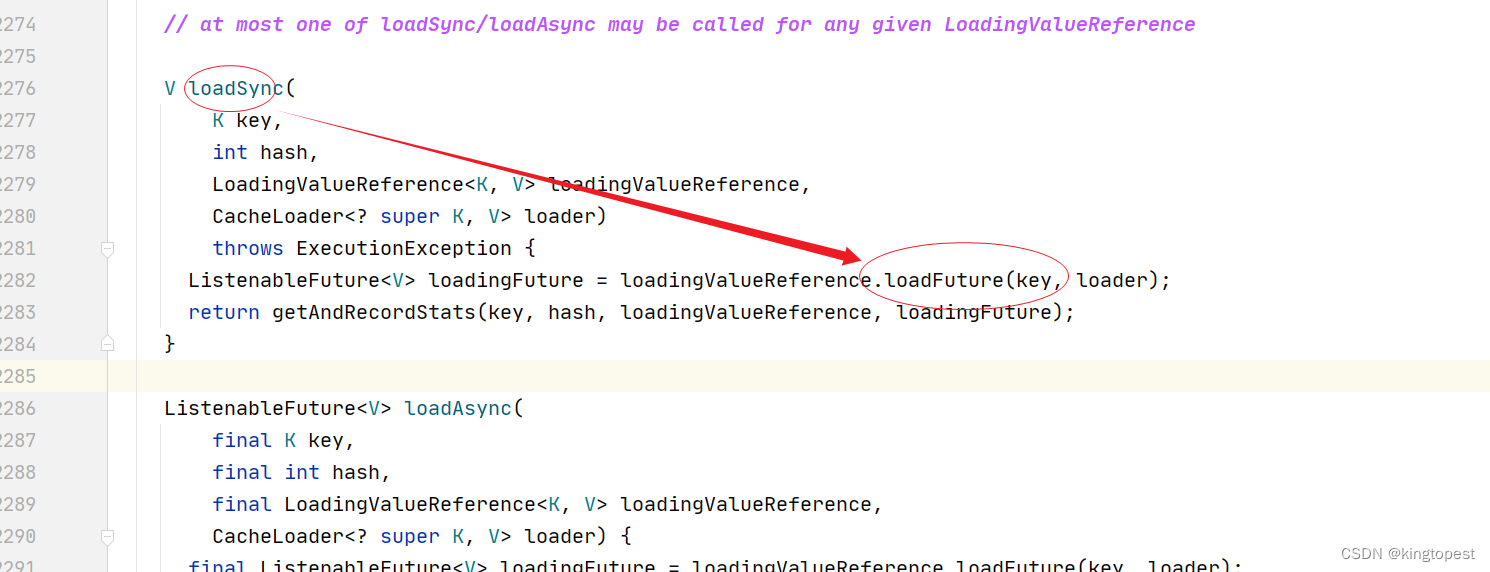
loadFuture方法里面可以看到 CacheLoader的load方法的调用
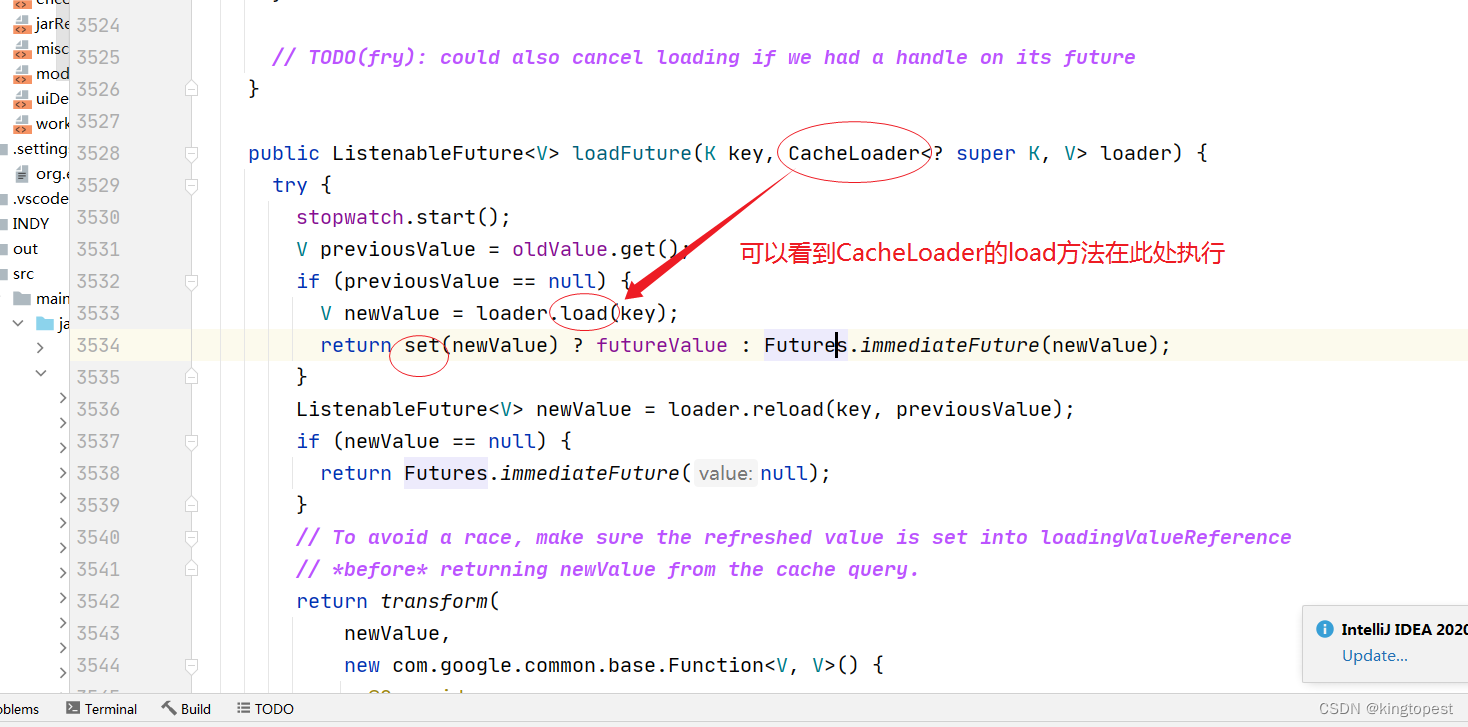
而 CacheLoader.load方法 的执行意味着前面的valueLoader函数的call方法执行:
因为localCache.get方法的入参valueLoader实际是覆写了CacheLoader.load方法,并在load方法中执行了valueLoader.call().
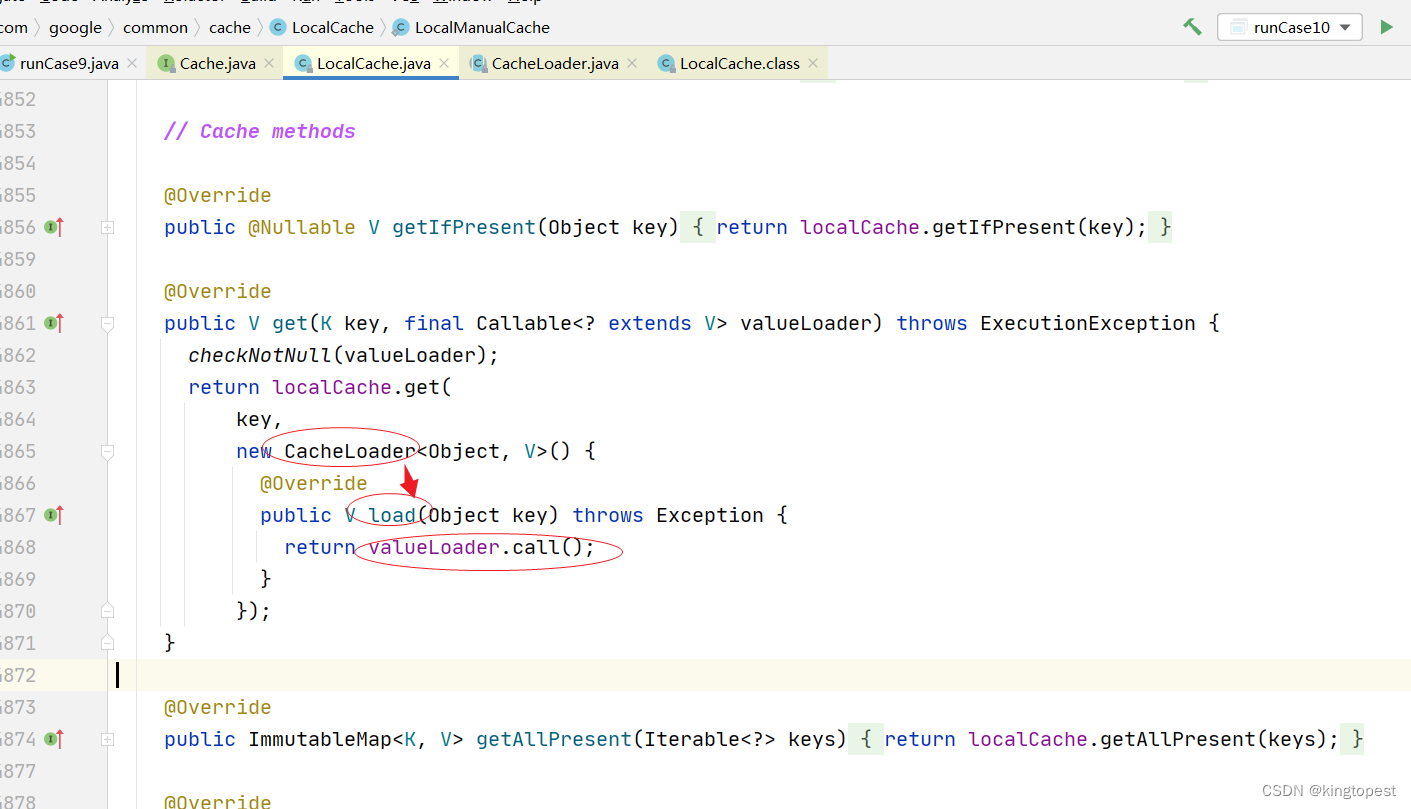
这也就回答了: 当Cache get不到key时,会从valueLoader函数的返回结果获取key值