- 拍照,监控等场景,由于玻璃的反射和折射,滤光膜等因素,图像质量大大降低,那么我们可以通过什么手段去除,降低这种影响,从而提升图像质量以获取更多场景本身的信息?
文章目录
- Single image reflection removal beyond linearity
- 一些想法
- Single Image Reflection Separation with Perceptual Losses
- A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing
- Single-image reflection removal: from computational imaging to deep learning
- Benchmarking Evaluation Dataset for Reflection Removal Methods
- Separating reflections from a single image using local features
- Sparsity based reflection removal by using external patch search
- Region-Aware Reflection Removal with Unified Content and Gradient Priors
Single image reflection removal beyond linearity
章博推的cvpr2019的文章
开篇题图就告诉我们,以前做反射消除严重依赖线性仿真数据,文章提出基于非线性的仿真的反射消除
- 摘要
摘要老生常谈,由于缺少成对的数据,深度学习需要仿真数据,但是以前的仿真数据基于线性缺少多样性,文章适时提出一个非线性的仿真数据,然后通过一个级联的网络得到了一个RR的benchmark
- 数据仿真
- 网络结构,训练的设计
reflection removal formulation
S = α T + ( 1 − α ) ( K ⊗ R ) S=\alpha T+(1-\alpha)(K\otimes R) S=αT+(1−α)(K⊗R)
α ∈ ( 0.5 , 1 ) \alpha \in(0.5,1) α∈(0.5,1)
S ∈ [ 0 , 1 ] m × n × 3 S\in[0,1]^{m\times n\times 3} S∈[0,1]m×n×3 reflection image 反射图像
T ∈ [ 0 , 1 ] m × n × 3 T\in[0,1]^{m\times n\times 3} T∈[0,1]m×n×3 transmission layer 都不知道怎么翻译了,这里的layer就是指图像,只不过这里他作为反射图像的一层嵌入在其中
R ∈ [ 0 , 1 ] m × n × 3 R\in[0,1]^{m\times n\times 3} R∈[0,1]m×n×3 reflection layer
K K K 高斯模糊
简单的线性组合并不能表示复杂的显示场景,~~废话,我当然知道,~~因为反射受相机和图像平面的相对位置和光照影响[9]
- 反射的分类
根据不同的场景,反射方式可以大致分为
- focused reflection
When the object behind the glass and the reflected object are in the same focal plane, the reflection layer will be as sharp as the transmission layer in the reflection image. In this case, the kernel K is considered as a one-pulse kernel
当物体在镜面后面,反射物体也在聚焦平面,K被认为是一种单脉冲核
- defocused reflection
In most reflection images, they are captured from a certain distance to the camera, and therefore the reflected objects are usually out of focus when the object behind the glass is in the focal plane. In this case, the reflection layer is blurry and smoother than the transmission layer. Most linear blending methods [29, 31, 2] model this type of reflection images by setting the kernel K as a Gaussian kernel to simulate the blurry reflection
一般来说反射物体离拍摄相机都有一定的距离,因此他们大多在焦距之外,这就是类似的线性模型,K选择高斯核
- and ghosting reflection
For the two above types, we assume the thickness of the medium, such as a glass, is thin enough to regard it as single-surface. However, when the thickness is non-negligible, we should take the refraction into consideration, as it will cause the quadric reflection with shifting. To model this ghosting reflection, Shih et al. [18] set the kernel K as a two-pulse kernel which is called the ghosting kernel
如果镜面的厚度不可忽略的话,二次反射是必须考虑的,K是重影核,是一个二脉冲核
SynNet
预测一个alpha mask,由用户决定使用何种反射方式(K)
S = W ∘ T + ( 1 − α ) ∘ ( K ⊗ R ) S=W\circ T+(1-\alpha)\circ(K\otimes R) S=W∘T+(1−α)∘(K⊗R)
∘ \circ ∘ element-wise
K K K 由玻璃的厚度和光线和表面的角度决定- Architecture
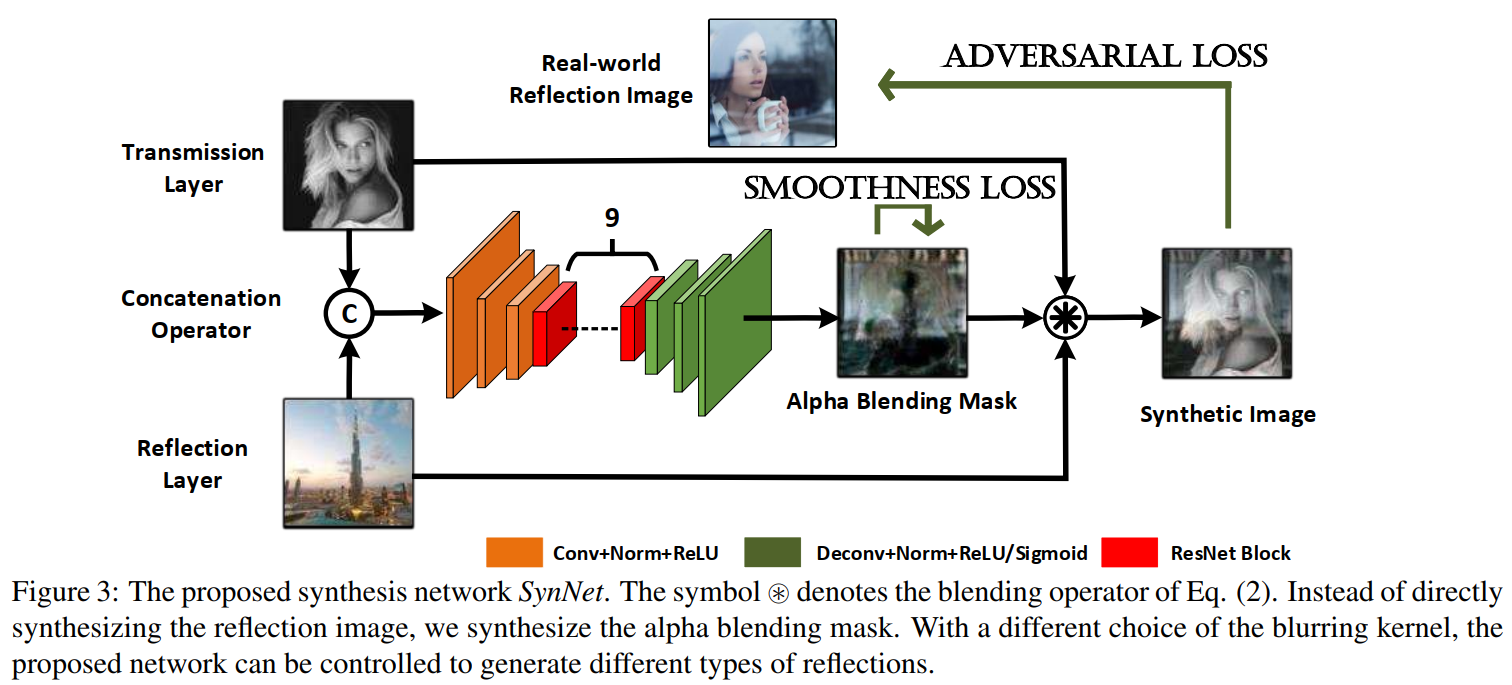
网络架构如上,
输入:原图 + K(反射图);
卷积:3 x encoder + 9 x resBlocks + 3 x decoder (InstanceNorm+Relu)
输出:3层alpha mask - Loss

- Adversarial Loss


- Smoothness Loss
We add a smoothness loss Lsmooth as an augmented loss to avoid the value mutation in the alpha blending mask, which will cause the unexpected color change in the synthetic image
使得像素不要突变

RmNet
predicting the reflection layertransmission layeralpha blend mask—side output
- Architecture
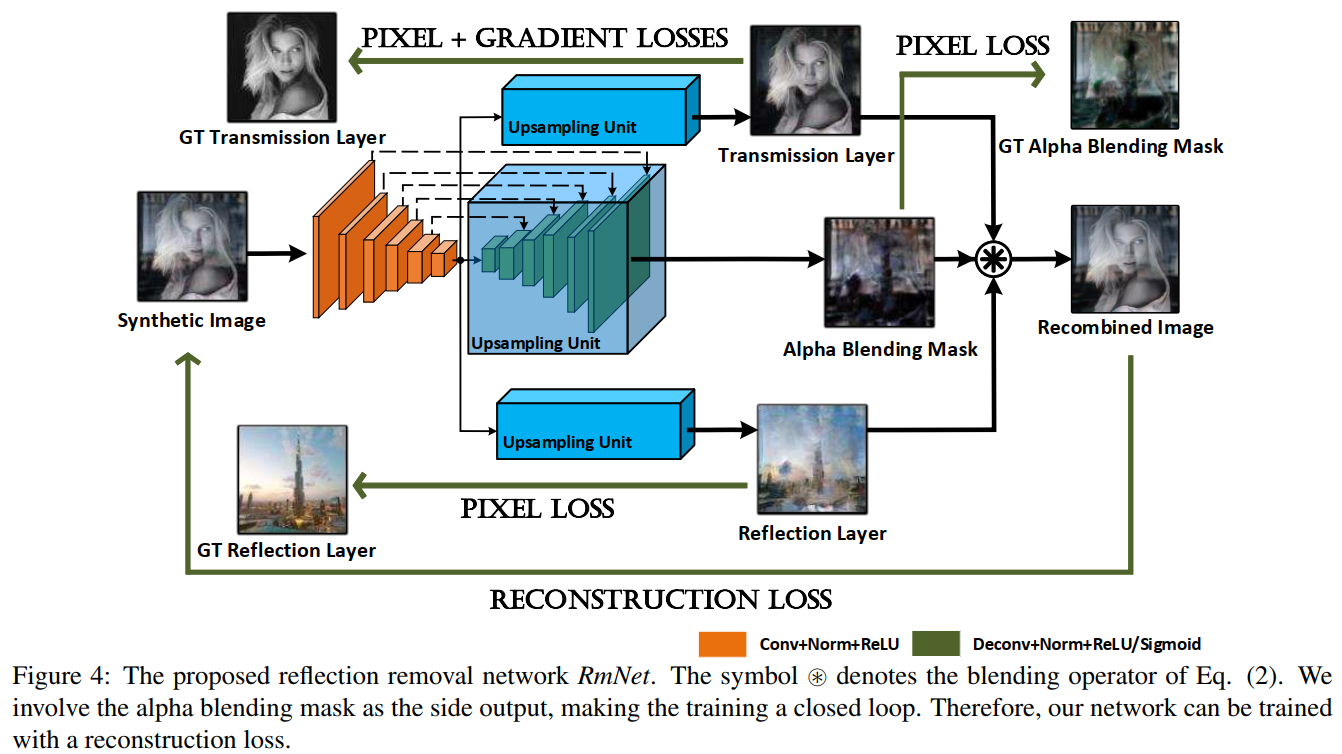
- Loss

- Pixel Loss

- Gradient Loss

- Reconstruction Loss


- Training
epoch 130
batchsize 10
optimizer Adam
lr 0.0002
- Dataset
已有的两个真实数据集
Zhang et al.[31] and SIR^2 datasets [24]
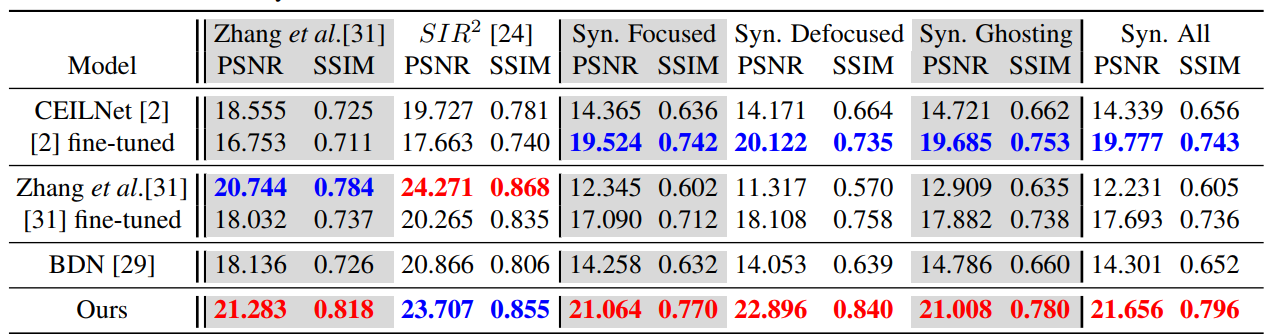
- 对比方法
CEILNet [2], Zhang et al.[31], and BDN[29]
- 反射图像评价/评价仿真图像真实性
inception score[16]

- reflection removal 评价
- PSNR & SSIM
- User

- Ablation
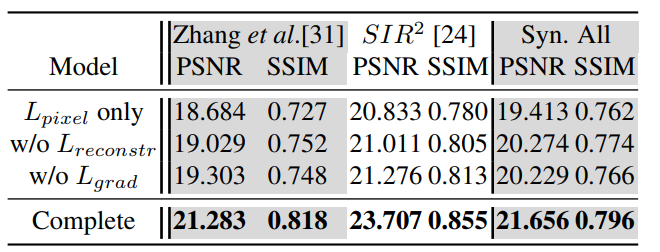
看代码吧
流程很简单,没有复杂的trick,尝试训练了下数据仿真,可能是只使用了100组训练数据,生成仿真数据的质量可能需要把控,得搞一个inception_v3?
他在写D更新的时候有一个有意思的做法,贴出来看看
- ImagePool
class ImagePool():"""Notes: 关于参数的解释option中这样写道 the size of image buffer that stores previously generated images没看懂,看下代码就知道了,他提供了一个image pool 图像池,最大可以容纳pool size 个图像,这里特别的只容纳mixAB,也只在更新D时使用,防止某一个batch过小或者某一次生成的结果不好影响梯度的反向传播。当self.images 里面存满了图像后,后面每次新生成的图像都有50%的概率替代图像池中某一个图像,所以若干次后,每次D 的反向传播都使用pool size 这么多个图像计算loss,这样做 1. 使得以前的loss又可以传播 2. 训练时利用了更多的信息 但是 3. 这样做就没有坏处吗"""def __init__(self, pool_size):self.pool_size = pool_sizeif self.pool_size > 0:self.num_imgs = 0self.images = []def query(self, images):if self.pool_size == 0:return Variable(images)return_images = []for image in images: # 遍历每个batch中的数据1xhxwimage = torch.unsqueeze(image, 0) # 现在变为1x1xhxw了if self.num_imgs < self.pool_size: # 0self.num_imgs = self.num_imgs + 1 # 1self.images.append(image) # hxw的数据加入列表return_images.append(image) ##else:p = random.uniform(0, 1)if p > 0.5:random_id = random.randint(0, self.pool_size - 1)tmp = self.images[random_id].clone()self.images[random_id] = imagereturn_images.append(tmp)else:return_images.append(image)return_images = Variable(torch.cat(return_images, 0))return return_images
一些想法

Single Image Reflection Separation with Perceptual Losses
zoom-to-learn的作者UCB的作者xueer zhang
- Abstruction
- end-to-end with loss exploit low-level and high-level image infomation
- two perception loss: feature loss(perceptin network) + GANLoss of transmission layer
- pixel-level loss: noval exclusion loss in the gradient domain
- real-world dataset, reflection image with ground-truth transmission layer
文章竟然说到了这个 ,和我的想法差不多,看下他后面怎么说
Our trained model on reflection separation can be directly applied to two other image enhancement tasks, flare removal and dehazing
–
- CEILNet
- pix2pix
写了半天停电了,写过的就暂时不补了
总而言之
- Architecture
输入为1472 + 3
文章并没有对比hyprtcolumn的影响,没有人argue一下? - loss


真实数据R是不存在的,尝试使用R=I-T来估计R
-
Dataset
5000个仿真数据+500真实数据(extract form 90 real-world)
batch sie = 1
random resize keeping the original aspect ratio
Adam lr=10e-4 250epoch -
Synthetic data
pairs: one outdoor & one indoor
他们随机选择一个作为T, R使用3-17的高斯核
composition approach 和引文[5]相似, -
but remove gamma correction from the images and operate in linear space to better approximate the physical formation of images
改变gamma为线性 -
Instead of fixing the intensity decay on R, we apply variation to the intensity decay since we observe that reflection in real images could have comparable or higher intensity level than the transmission layer.
这句话没怎么懂,使用一个变化的衰减系数,因为真实数据中反射layer往往拥有和背景layer拥有相当或更高的灰度?这意思是融合时选择更高的系数吗?这样不会掩饰更多的背景细节 -
We apply slight vignette centered at random position in the reflection layer, which simulates the scenario when camera views the reflection from oblique angles
我们在反射层中应用了以随机位置为中心的小图形,它模拟了摄像机从倾斜角度观察反射的场景
怎么做的?
看代码吧
A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing
- CEILNet
上面两篇文章的引文
exploits edge information in addressing representative low-level vision tasks such as layer separation and image filtering
文章的出发点是利用边缘信息在low-level视觉任务方面的应用,例如图像分离和图像滤波
Single-image reflection removal: from computational imaging to deep learning
renjie wan, 一个南洋理工大学博士的论文,他在这个领域发了N篇文章,拜读一下
- instruction
different from other layer separation problems (e.g., haze removal and rain streak removal) with significant difference between the layer to be recovered and the layer to be removed, the similarities between the properties of the background and reflections make it more difficult to simultaneously remove the reflections and restore the contents in the background.
开篇介绍了,rr和其他layer separation(dehaze, derain)问题的区别, transmission layer 和reflection layer 特征上更具与相似性,所以在移除反射layer的同时恢复transmission的内容更困难

这个图也是不太理解的
1 分别预测 2 预测重叠部分 3 图1为主图和图2为主体?其实就是表示不同的分解方式。。。
I = T + F I=T+F I=T+F
我们可以看出来,他是一个不适定问题,需要额外引入一些先验约束
- T,F梯度平滑约束
- ghosting effects
- so on
- related work
标记下缩写。。。SK13-模型三,LB14,NR17-模型二
问题分类,首先分为单张图像还是多张图像,在由解决这个问题的约束分类
- single image

- 反射物理模型
- 模型一 focused
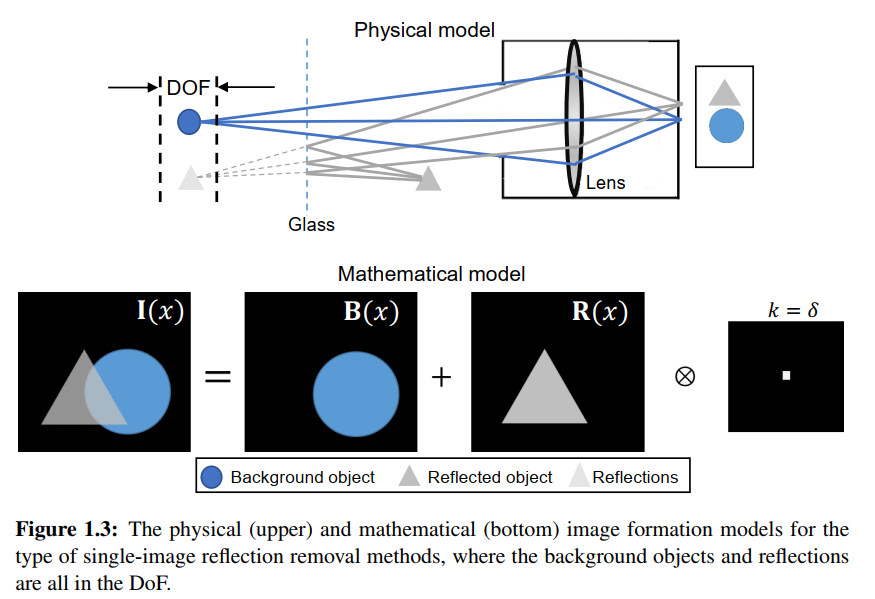
上图 objects behind the glass and reflections are approximately in the same focal plane, k 退化为one-pulse kernel - 模型二—defocused
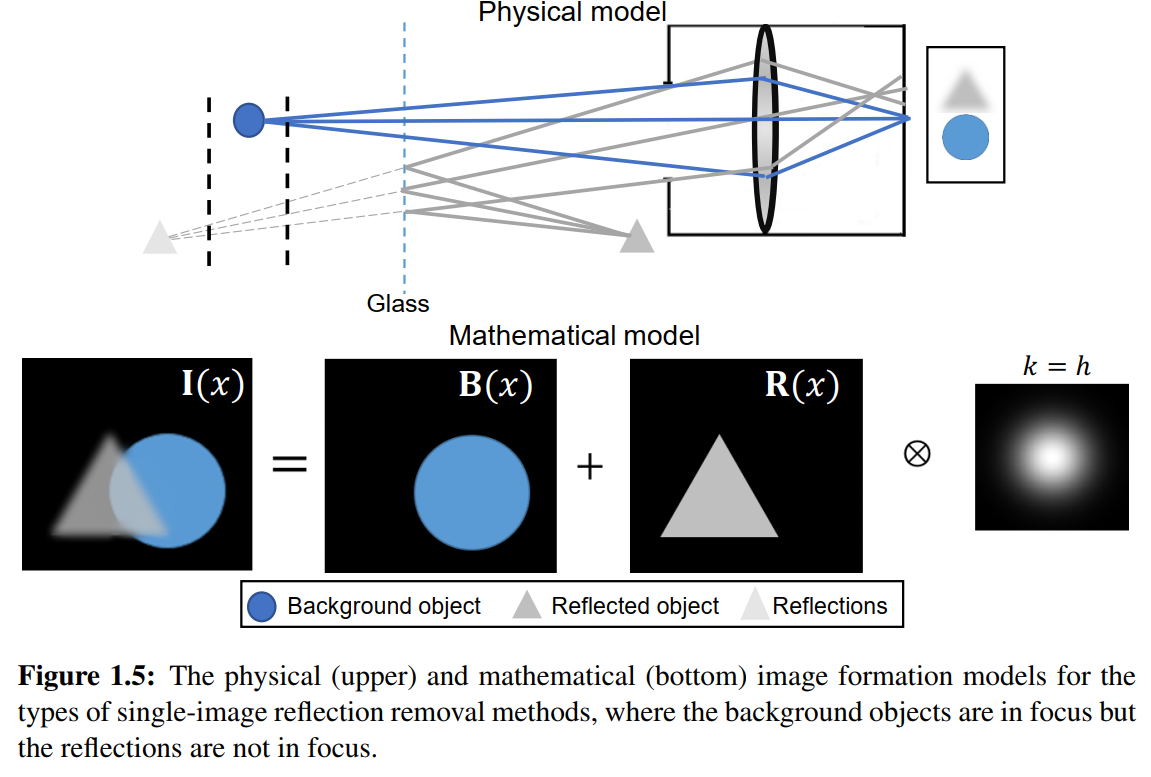
一般来说,我们想要拍摄的物体都在焦平面内,二反射物体可能不在焦平面内,他们对于相机的距离是不一样的。
kernel k depends on the point spread function of thecamera which is parameterized by a 2D Gaussian function denoted as h
k取决于点扩散函数,这里被参数化为2D的高斯函数
- 模型三— ghosting effect
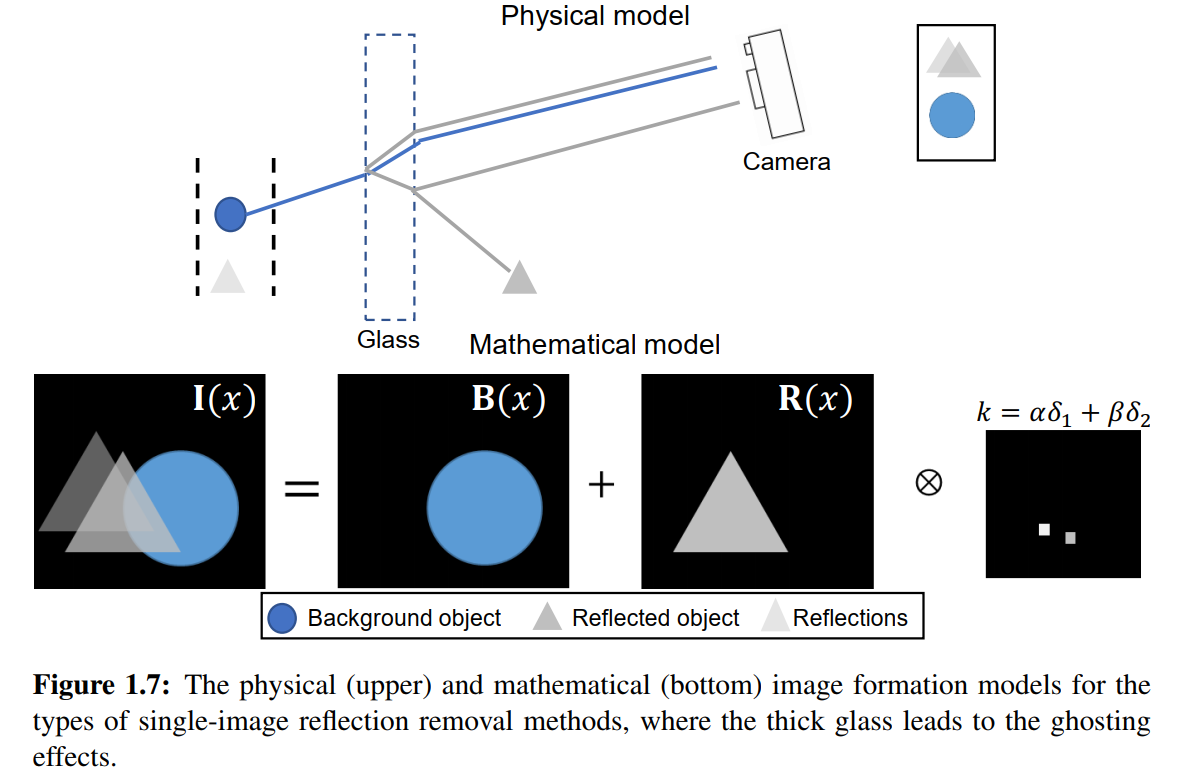
如果glass有不可忽略的厚度的话,那么反射又是不一样的情况
light rays from the objects in front of the glass are partially reflected on the outside facet of the glass, and the remaining rays penetrate the glass and are reflected again from the inside facet of the glass
如上图所示,可能会反射两次,k退化为双脉冲函数
- type-I: gradient sparsity prior
在统计上来说,自然图像的梯度都是稀疏的(sparse)
- minimal corners and edges [22] or gradients
最小化梯度?下面有引文[22]的做法 - labeling the gradients for background and reflection

没看,大概就是利用梯度的系数表示,两个高斯分布,然后判断这个梯度是那个属于那个分布来分离两个图像
- Type-II: Layer smoothness analysis
基于物理模型二,人们使用了[9]的pipleline,但是其实两个图像的分布P_1, P_2是不一样

引文[1]设计了两种分布模式来做这件事
引文[3] l_0 gradient sparsity prior based on a Laplacian data fidelity term,克服亮度颜色偏移
- Trpe-III: ghosting effect
双脉冲函数和GMM都OK
- 深度学习
[28] [10] 学习反射图的边缘特征
- mutil image
- Type-I: motion cues between T&F
the multipleimage methods use multiple images taken with different conditions (e.g., illuminations, viewpoints, different focuses, or varied polarizer angles)
引文[31],他是怎么保证场景一致的?还是不需要保证场景一致?



- Type-II: linear conbination if T&F

偏振和光照
- Type-III
takes a set of images under special conditions and camera settings
flash, focus
- our contributions
We first introduce three methods on the basis of the non-learning framework and a benchmark evaluation dataset.
At last, we introduce a data-driven method based on the deep learning framework
Depth of field guided reflection removal
有代码Benchmarking Evaluation Dataset for Reflection Removal Methods
- 数据的看下,下面会讲到
Sparsity based reflection removal by using external patch search
combining the sparsity prior and the nonlocal image prior into a unified framework
下面有一点名词的解释和做法Region-aware reflection removal by using content prior
- 这篇文章看下基于区域的,先检测反射和非反射区域,基于反射regional恢复反射缺失的部分,基于global的梯度和颜色分离两个layer
Deep learning based reflection removal
Concurrent Reflection Removal Network (CRRN)
integrates image appearance information and multi-scale gradient information with human perception inspired loss functions and is trained on a new dataset with 3250 reflection images taken under diverse real-world scenes
- 看下
Benchmarking Evaluation Dataset for Reflection Removal Methods
S I R 2 SIR^2 SIR2 1500 images, 1726 × 1234
we use three steps to capture a triplet of images:
- The mixture image is first captured through the glass;
- we capture the ground truth of the reflection R with a sheet of black paper behind the glass; and
- finally the ground truth of the background B is taken by removing the glass

- image aligment
We first extract SURF feature points [55] from two images, and then estimate the homographic transformation matrix by using the RANSAC algorithm. Finally, the mixture image is aligned to the ground truth of background with the estimated transformation
Separating reflections from a single image using local features
上面的引文,基于边缘和拐角的local feature
Given a single image as input, the algorithm searches for a decomposition into two images that minimize the total amount of edges and corners
还是不太理解minimize the total amount edges and corners
edges due to shading and edges due to reflectance have different statistics. e.g. shading edges tend to be monochromatic
引文[13, 4]在分离阴影时利用了一张图像可以用来分解为T和R的原因是他们的边缘统计是不同的,例如T的边缘通常是单色的,但是在reflection 两者是i相同的
high level knowledge would know to prefer the good decomposition
高维的特征可能可以得到更好的结果,但是没有高维特征可以分解出一个好的图像吗?
这篇文章使用single image without high level konwledge

- 由上图可知,一张图片可以有无数种分解。我们现在要做的就是
在解空间中寻找到最合适的分解方法—二这个解文章称为the perceptually “correct” decomposition视觉正确的分解
观察之,a拥有10个转角,看起来‘正确的分解’应该是分解为两个矩形b,但是e也是两个矩形,再但是他多了两个边(edge),那么我们约束使得分解图像具有少的转角和边缘是不是可以呢?这样一个简单的假设竟然得到了还不错的效果!
- two decisions
(1) what operators to use for edge and corner detectors and
(2) what mathematical form to give the cost.
接下来就是怎样检测转角和边缘以及数学求解的问题
S1:- gradient magnitude ∣ ∇ I ( x , y ) ∣ |\nabla I(x,y)| ∣∇I(x,y)∣ as edge operator
- a Harris-like operator c ( x , y ) c(x,y) c(x,y) as a corner operator
使用梯度幅值作为边缘算子,Harris算子转角算子(这个算子挺神奇的)
S2:
负log似然函数

这些参数是直方图统计得到,并且至关重要


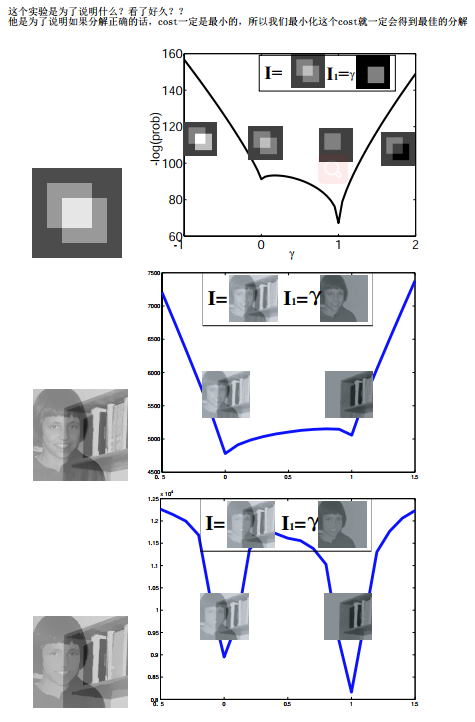
后面的优化就不看了,感兴趣的可以再去看看
Sparsity based reflection removal by using external patch search
combining the sparsity prior and the non-local image prior into a unified framework
使用了稀疏先验和非局部先验,拿什么叫稀疏先验,什么又叫非局部先验呢?
这种思想和上面那篇文章的做法很相似,同时恢复出T和F, 做更好的分解
- sparse representation

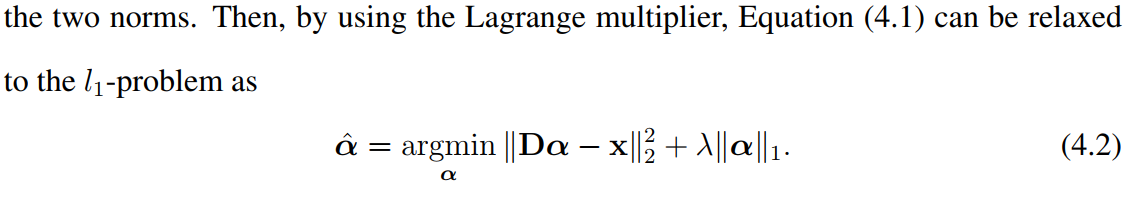
其实对上面的优化不是特别懂。。。。
可以被用在图像恢复(去噪,修复,超分,去模糊…)
- non-local priors
第一眼想到BM3D—patch based denoising
nonlocally centralized sparse representation (NCSR) model
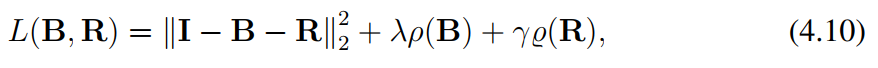
优化太长不看了
Region-Aware Reflection Removal with Unified Content and Gradient Priors
全局处理反射图会使得没有反射的地方图像质量退化,文章detect reflection region,并且基于上面的方法使用self-similarity without external dataset
文章认为我们的mixture image 会受到外界干扰,所以修改了reflection image的公式

- framework
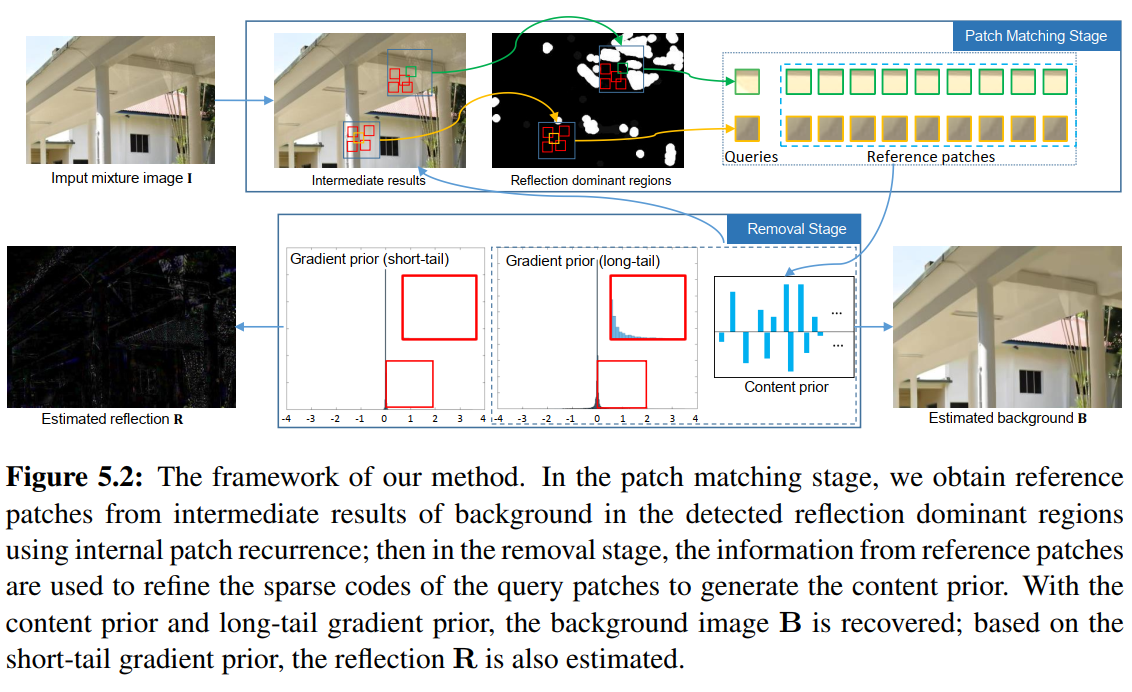
that the regional part focuses on removing the reflections and the global part keeps the consistency of the color and gradient information. We integrate both the content and gradient priors
大概理解什么意思,但是具体怎么做有兴趣在看论文吧


