无锁环ring是DPDK提供的一种较为基础的数据结构,其支持多生产者和多消费者同时访问。
经过我的经验,无锁结构的实现主要依靠两方面:
- 最终的数据交换一定要是原子级的操作,最常用到的自然就是比较后交换(Compare And Swap,CAS)
- 数据的实际写入与原子级的交换操作相分离
只是这么说可能不是很好理解,我们以我目前知道的两种实现方式,即RCU和DPDK ring的实现来举例子就好理解了。
CAS
首先我们需要之后CAS的原理,CAS共有三个输入,分别是将要修改的地址reg,reg中的原数据oldvalue,以及想要更新的新数据newvalue。
在CAS的执行流程如下:
- 取出reg中的当前数据regvalue
- 将regvalue与oldvalue进行比较
- 如果二者相等说明在当前核读取数据到写入数据的这一段时间reg中的值没有被修改过,可以直接写入。CAS函数在写入后返回成功信号
- 如果二者不等说明该数据已经被修改过了,当前核使用的数据有可能是错的,因此不会执行写入操作,并返回一个错误信号
上述的所有步骤均由一个原子级的CPU指令完成,在CAS失败时,通常需要用户重新读取新数据执行对应操作,再尝试执行一次CAS,直到写入成功为止。
RCU和无锁Ring
RCU和无锁Ring都是无锁通信的实现,二者在原理上有上述的类似却又不同,适用场景也不同。
首先,既然是CPU之间的通信,那么就一定会有数据被修改,加锁也只是为了保证写核在修改数据时不会被其他读核读取到数据。
而CAS恰恰就是一个原子级的操作,也就是说通过CAS在修改数据的时候,别的核是无法读取到对应数据的,也就是相当于自带加锁了。
那既然有了CAS为什么不能所有数据都这样写呢?因为种种原因(例如CPU指令集限制,以及需要比较的字节数等等),CAS只支持基本数据类型(int, bool)维度的操作。
那假如我要修改一个很长的结构体对象该怎么办呢?
RCU
原理
很自然的可以想到,我们可以先创建一个新的结构体对象,这个对象不会被任何其他核访问到,无论花多少时间都可以。
在对象创建好之后,我们取出他的指针,由于指针是基本数据类型,我们可以使用CAS完成一次狸猫换太子,将指向原来对象的指针替换成新对象的指针,这样之后的读核就会无感的访问到新对象了。
在完成指针更新之后,为了防止内存泄露,我们需要将原来的对象释放掉。
这里就需要注意一个问题,原来的数据结构可能还在被其他核所读取,冒然释放可能引发系统错误,因此我们要等所有读核都不在使用该地址再进行释放。
也就是说这块内存会额外存活一段时间,这段时间在RCU中就被成为宽限区,宽限区从写核修改指针开始,到所有读核读取结束为止。
为了让写核能够感知到释放内存的时间,需要为每一个对象内存添加一个引用计数。读核每次开始读取时引用计数加1,结束读取时引用计数减1,当引用计数为0就说明可以释放了。
至此我们已经掌握了RCU的基本原理。
特点
优点:对于读核来说无需进行任何加锁操作,只需要在开始读取和结束读取时修改一个引用计数,这一操作同样可以使用CAS实现。
缺点:拖慢写核的工作进程,同时需要额外的内存地址,无法做到原址修改。
因此RCU适合读多写少,并且不需要原址修改的场景中。
无锁Ring
原理
假如我们想要实现一个存储对象的循环队列,队列的底层是一个数组,自然需要在原址修改,此时RCU就不适用了,我们需要实现新的无锁方案。
为了利用CAS,我们需要找到能够代表一个对象的基本数据类型,那自然是对象在数组中的索引了。
在写入时,我们可以先修改队尾的下标地址,相当于在实际写入数据之前通告其他写核,这块地址已经被我占据了,你们不要再往里面写了,由于交换的只是一个索引,因此可以使用CAS。
在新下标确定之后,写核会对数据进行实际的写入,这里有一个问题,由于我们已经修改了队尾指针,那么虽然其他写核访问不到这片内存,但是现在其他读核可以了啊。
解决方法也很简单粗暴,我们再加一个索引就好了。新加的索引在没有写操作进行时指向与队尾相同的位置,在开始写入时不变,写入结束时再与队尾同步,只要让读核所看到的队尾一直是该索引即可。
当然,上述讨论的只是多生产者单消费者的情况,如果是多生产者多消费者,那么我们需要为队头也创建一个额外的索引,其余原理其实都相同。
至此,我们就掌握了无锁循环队列的基本原理。
DPDK实现
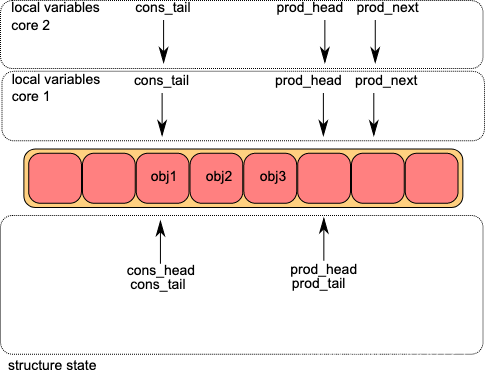
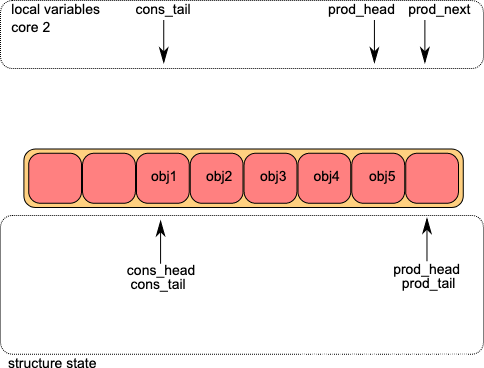
下图展示的是DPDK中无锁Ring的基本结构,其中prod_head和prod_tail分别上述的队尾指针和队尾额外指针,同样cons_head和cons_tail也是队头指针和队头额外指针。
对于生产者来说,它在任意时刻看到的队列实际是prod_head到cons_tail,而对消费者来说,其看到的队列始终是prod_tail和cons_head。

DPDK Ring单生产者入队流程
下面是单生产者的入队流程,我们已经介绍过了
需要注意的是,local variables中的prod_head核prod_next分别是CAS操作中的oldvalue和newvalue,而队列中的prod_head则是reg。
第一步:读取原始prod_head,根据入队数量计算新的prod_head,即prod_next
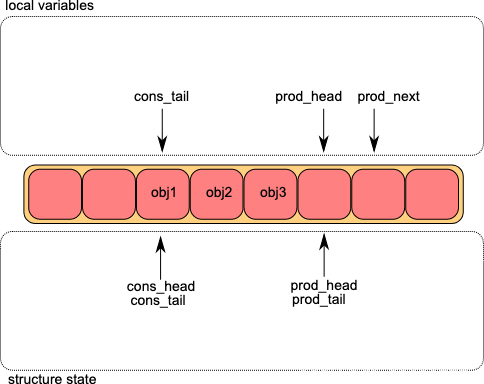
第二步:通过CAS修改prod_head,占据内存
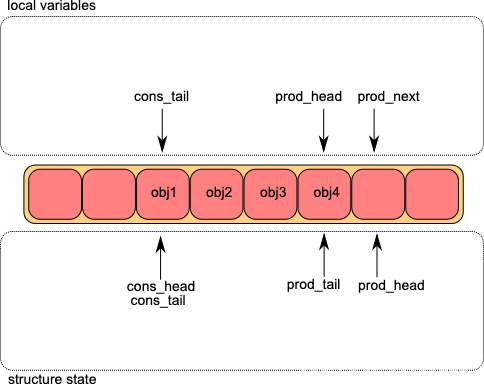
第三步:实际写入数据,并使用CAS修改prod_tail

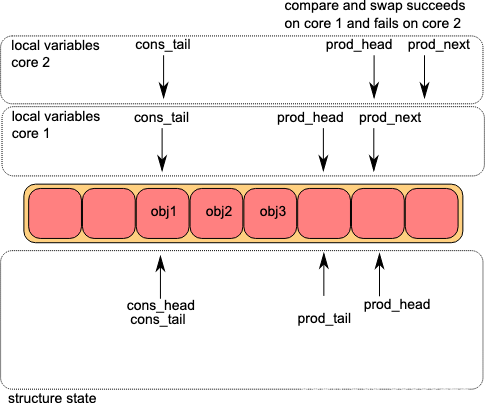
DPDK Ring多生产者入队流程
第二步:先提交的核完成CAS占据内存,后提交的CAS失败,重新读取prod_head并计算prod_next
第三步:core1开始写入数据,core2重新CAS成功
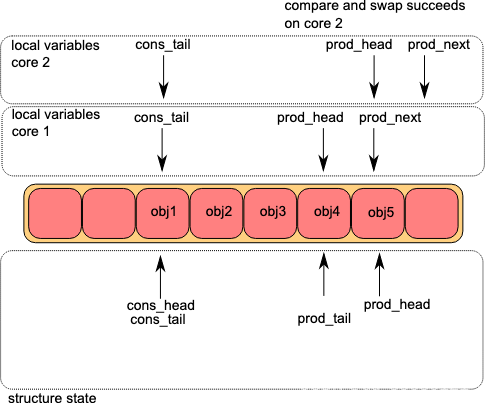
第四步:core2写入数据,core1通过CAS修改prod_tail
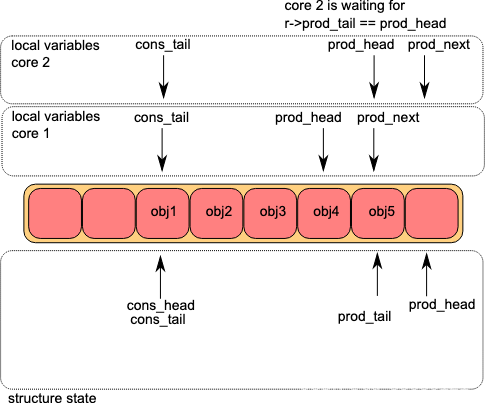
第五步:core2修改prod_tail,至此多生产者入队结束。
由于消费者出队的操作与生产者入队几乎完全相同,在此不做赘述,可以参考https://dpdk-docs.readthedocs.io/en/latest/prog_guide/ring_lib.html
优点:可以原址修改,支持批量入队和出队,也就是可以通过一次CAS占据大片内存,这都是RCU做不到的。如果使用CAS直接操作内存地址队列,也做不到批量操作。
缺点:内存空间需要预先分配,不像RCU使用是才申请,比较费内存。
进程间通信
通过Ring和mempool的结合使用还可以实现进程间的通信,原理与共享内存类似,DPDK在创建Primary Process时会将使用的大页内存的详细信息记录到文件中,在启动Secondary Process时会读取这些信息,这样就能实现类似共享内存的效果。
在两个进程内都需要调用rte_eal_init初始化DPDK环境。
在一个进程内创建Ring和Mempool,在另一个进程内调用rte_ring_lookup和rte_mempool_lookup函数获取对应的Ring和Mempool。
通信时,一个进程从Mempool中取一个元素,放入Ring中,另一个进程从Ring中取出,处理完之后再放回Mempool即可。