导读:在当前复杂的零售环境下,选址对于零售企业而言变得格外重要,因为位置就是线下流量的直接入口。本文将从三个维度来为大家揭晓如何通过地理方法解决选址问题?融合机器学习的智能地图如何赋能商业选址?
1.0时代:地理可视化
1.0时代即通常所说的数据上图,将数据投放至地图上,用地理可视化的方式展现出来。
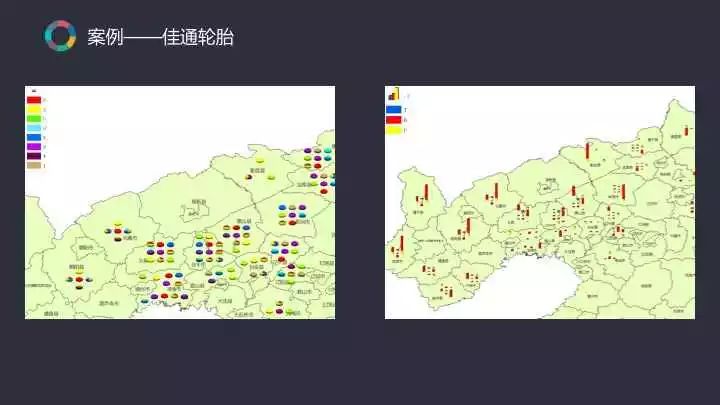
佳通轮胎是我接触这一行业所做的第一个项目,这一项目对于现在而言能轻而易举地做到并且能够做得更好但对当时而言则较为复杂。
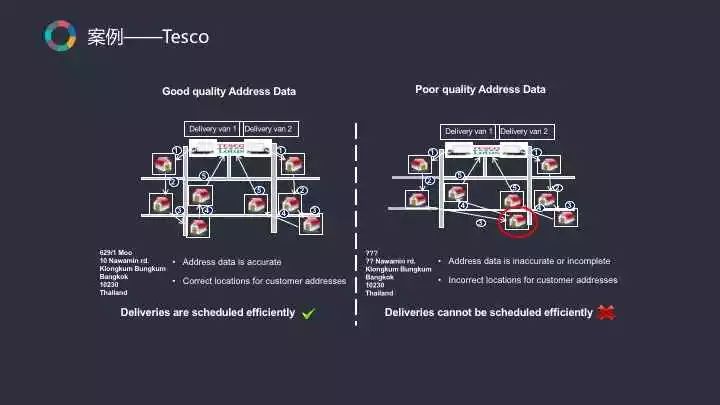
在可视化1.0时代,Tesco走在行业前端,已经开始用地理可视化的方式做选址。用户只需在其在线商城注册账号后输入自己的地址,系统后台便会将用户分配到他所属的门店。但这对地理编码的精度要求特别高,假设你的地址定位不准确就会影响后续的整个配送路径。
在选址之前需对现有门店进行较深的认知,以麦当劳商圈调查为例,在选址之前需要对已经开业的门店做很多商业调研,将这些收集回来的数据呈现在地图上,目的是帮助他们了解其客户,这些客户分布在哪里?
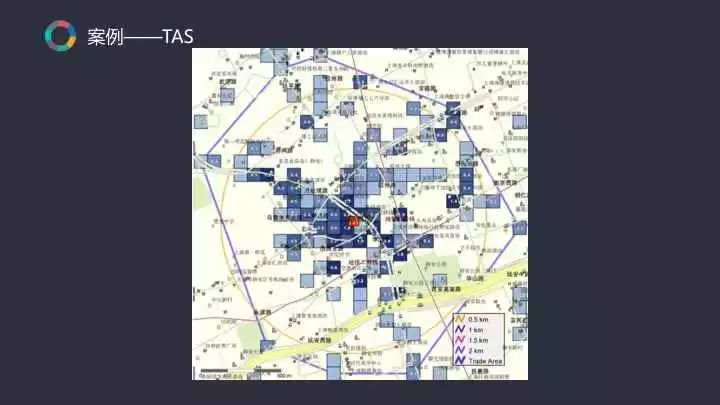
上图每一个格子代表客户百分比,颜色越深就代表这个地方的客户越多。可以发现,大部分客户都来自于离店铺越近的地方,越远的地方它的颜色越浅。另外还可以发现这家店的商圈大小,商圈的范围是80%的客户所分布的范围。通过调研的方式计算出80%的客户分布哪些范围以内?另外还能了解有哪些因素会影响到商圈的大小及形状。比如在上图的右下角为一个高等级道路,可以发现在道路上方集中了大部分客户,而在道路下方并没有很多客户,那就说明高等级道路是影响商圈形状的重要因素。通过这种方式还能得到其他认知,例如河流也是影响商圈形状的一个因素。
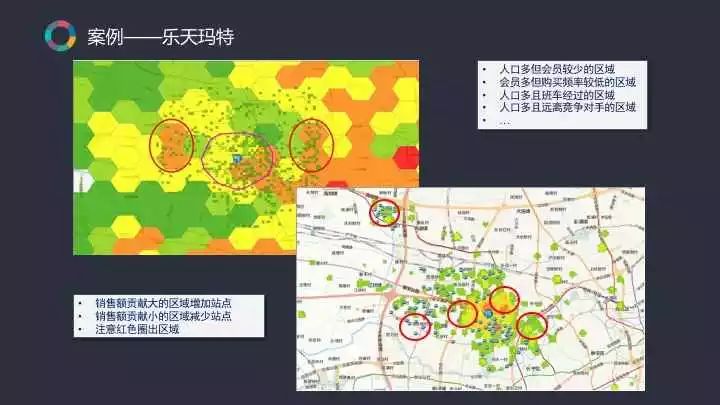
再以乐天玛特为例,他的需求是根据会员分布结合人口数据帮助其制定DM投放策略。例如人口多、会员较少的区域或是会员多、购买频率较低的区域都是需要重点关注的地方,如上图右上角圈出来的红色区域,它就是DM投放重点关注的区域。
当我们有了会员数据之后,继续把会员的消费金额、消费频次投放到地图之上,帮助他们安排接送车及站点分布。如在销售额贡献大的区域增加站点等。
在地理可视化1.0时代,阿迪达斯是一个较为特殊的案例。
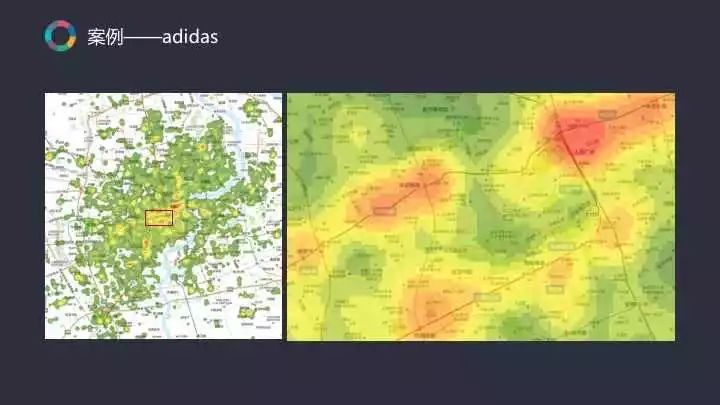
一直到现在为止,收集商圈市场容量数据是较难的一件事情。但我们通过可以获取到的POI数据模拟商圈的市场潜力以达到发现其市场容量的目的。对于某些大家熟悉的大城市如上海而言,所有人都能大致了解其核心商圈。但我们的最终目的是帮助商户了解二三线城市,甚至是四线城市。当对这个城市不够了解时,如何挑选品牌应该进入的区域?这就是阿迪达斯服务案例解决的问题。
2.0时代:分析与流程
2.0时代是如今大部分企业所处的一个阶段。由于数据量急剧上升,我们需要针对这种大数据做分析,从1.0时代针对单个点解决具体问题,上升至2.0时代帮助企业建立流程进而处理选址过程中可能面临的一些问题。
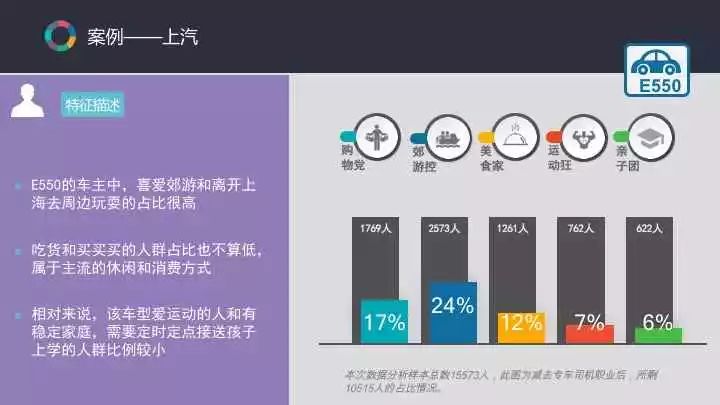
以上汽为例,在收集了新能源车辆的的行车轨迹数据后,提前制定好用户标签从而制定出用户画像,汽车厂商就会根据这些标签找到一些异业联盟。例如这一品牌的客户经常会去某个购物中心,那么就可将车放在这个购物中心供潜在的客户试驾,这也就是一个潜在的获取客户的渠道。
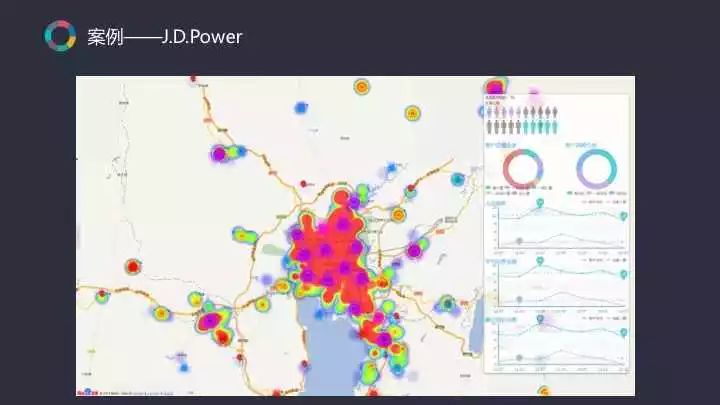
再以JDPower所做的会员管理系统为例。根据客户的到店频次、消费金额以及最近到店消费时间,将会员划分成不同等级,如高价值客户、低价值客户、高风险客户、低风险客户等,针对不同的客户类型进行不同的营销策略。在此平台基础上,还可以交互地针对某一区域的客户做营销。通过对会员更深入的分析,帮助他们更好地制定一个选址策略。
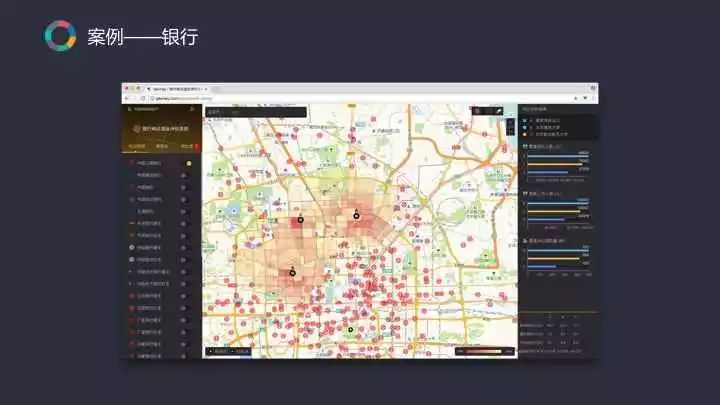
以极海和某银行的合作平台为例,对于现阶段而言,增加网点并不是银行主要的目的,而是通过系统的层次建立一个流程,对网点进评估,针对不同的网点从数据的角度制定开、停、并、转的决策。
3.0时代:机器学习辅助决策
从去年开始就有很多企业慢慢在选址策略上应用机器学习的方式。这里引入自然街区这一概念。

自然街区是规划里的一个概念,将它应用到零售选址这一行业中代替原先的网格方式。网格方式最大的缺点在于网格可能会横跨一条路、覆盖了两个小区,这样就有可能出现一种分歧。假设一个小区是公寓,一个小区是别墅,那么这两个小区的人其实是没有同质性可言的。为了解决这一问题,我们引入自然街区的方式。
沿街道、河流等天然屏障划分的自然街区对此就具有天然优势,因为各等级街道是人口的隔离和聚拢的自然表现,小巷胡同可以把附近的人聚拢在一块,高速路和主干道却把一块地切割成比较独立的活动区域,这种符合情理的划分方式会为各种各样的分析提供可靠性上的保障。
生成自然街区之后,将所有的数据基于这个统计单元做出分析。对每一个区块做出区分,打上标签,如办公区、大学城、购物中心等。
不同的零售业态关注的类型是不一样的,如高档的化妆品关注购物中心,而像麦当劳、肯德基则更关注居民区、商业街等人流更为集中的地方。
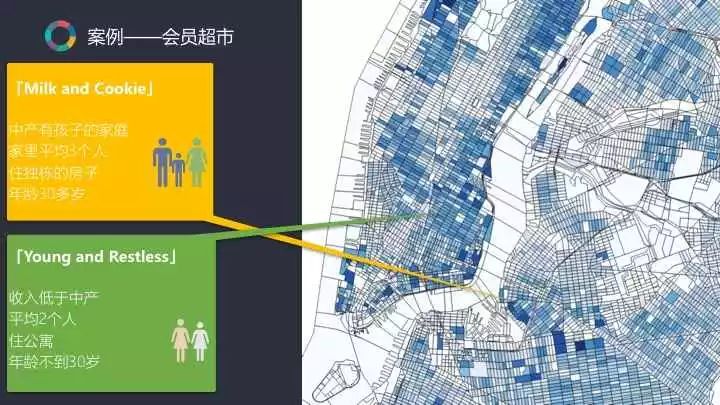
在美国,数据的完整度是非常好的,他可以做到对每一个街区定一个类别,假设这个街区叫做Milk and Cookie,那在这个街区生活的人则是中产阶级有孩子的家庭,这一家庭平均两三个人住在独栋的房子中。有了这样的分析结果后,就能在选址的时候做出很明确的目标。
但是来到国内后发现数据没有这么好的完整度,这就意味着你很难说清每个街道住的人都是怎样的档次,其消费能力如何?因此我们的解决方案是将会员数据投放至自然街区上,每一个自然街区有相对应的会员数,会有各维度统计而来的数据,通过机器学习的方式了解哪些因素对它有正向作用,经过不断的学习和迭代后,预测每块区域中可能会带来多少潜在会员。
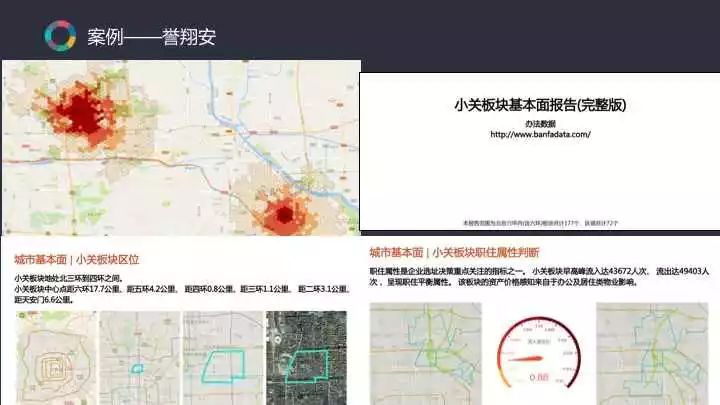
这是在2016年我们给北京一个做房地产的房产中介公司推出的自动报告的工作平台。根据每个月更新的数据,机器会自动利用30多大类数据做400多项小指标的运算,生成一份一百多页的PPT报告,而且整个过程就用一分钟。我们把北京分成了两千多个自然街区,在一分钟之内就能同时出两千份一百页的PPT投策报告。我们希望跟房地产公司等各行业的客户合作,通过这些新技术,把他们从以前不熟悉的技术工作中解脱出来。让他们把自己更多的精力,投入到他们更擅长的专业里去,真正做到术业有专攻、共赢,提高他们的工作效率,也同时大大的促进他们的工作成果。
我们希望搭建一个一站式云平台帮助用户解决一些他们不需要关注的问题,如数据安全问题、服务问题、模型问题,在这个平台环境下,帮助用户尽可能提供现成数据,在数据基础上搭建常见应用,所有的数据和应用利用API、SDK的方式封装起来,能够在这个基础上做一些更复杂的应用场景。
在平台上可以支持不同数据源、不同维度、不同格式的数据。另外公共数据也是非常重要的数据,目前极海团队会定期更新和处理大量的数据。针对大数据如何做可视化这一问题,我们采用了云端与前端相结合的方式,在后端对数据进行切片渲染,推送到前端进行可视化。
但现在企业自己内部的业务数据越来越多,外部的多源的数据获取也越来越容易,价格越来越便宜。我们怎么把这些多源的大数据进行整合,是否能真正有效的挖掘他们的价值?根据这些数据能否做出预测?这个是我们有了人工智能才敢想的。很庆幸,我们极海的小伙伴们,对人工智能的算法很早就非常的痴迷。
我们高效整合了内外网丰富的位置数据、商业数据、政府公开数据,采用机器学习技术提高数据质量并生产更多独有的数据。生产基于各种地理数据的深度学习模型,诸如交通分析、客源分析等大数据分析方法,通过这些数据和方法可以对街区中的用户群进行精细分析,高效调查区域内数以万计的用户群。
这所有的数据和分析方法,都被封装到一个数据容器内方便使用提取,这个容器,我们称之为“城市基因”,犹如生物研究的DNA一般,帮助精细精准地描述城市,为解决店铺选址,提供丰富、高质量的数据基础。
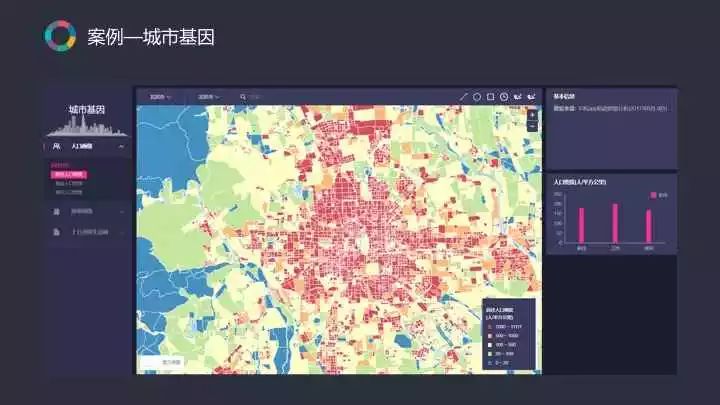
基于城市基因,我们能够轻松搭建面向行业应用的服务平台,如与IBM合作的平台 Metro Pulse。
这一阶段的云平台基本可以满足到2.0需求,在未来会有更多的新技术加入这一平台。
作者:何宇兵
来源:DT数据侠(ID:DTdatahero)
推荐阅读
日本老爷爷坚持17年用Excel作画,我可能用了假的Excel···
180页PPT,讲解人工智能技术与产业发展
终于有人把云计算、大数据和人工智能讲明白了!
数据告诉你:跟缺“芯”相比,中国当前的这个问题更致命!
Q: 好了,现在你发现开店发财的秘密了吗?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:baiyu@hzbook.com
更多精彩文章,请在公众号后台点击“历史文章”查看