在实现DINO Detection方法时,我们可能会遇到以上问题。因为在DeformableAttention模块,为了加速,需要自己去编译这个模块。
如果你的环境变量中能够找到cuda路径,使用正确的torch版本和cuda版本的话,这个问题很容易解决。(ps:一般情况下,cuda会安装在/usr/local文件夹下,但是很多情况下,虽然cuda可以使用,但是你可能就是无法找到cuda路径)
但是,如果你在一个集群中,可能找不到cuda路径,那么编译起来就困难多了。
# 找cuda环境
nvcc -Vwhereis cuda我在集群中来编译这个模块,编译源文件:https://github.com/IDEA-Research/DINO/tree/main/models/dino/ops
首先想到的是,通过在非集群服务器中,配置与集群服务器相同的python环境和cuda环境;
编译完成之后,把生成的库文件拷贝过去(路径:./envs/python39/lib/python3.9/site-packages):

把生成的info文件也拷贝过去:
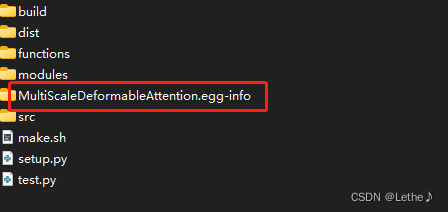
这时,通过conda list,可以看到已经安装了这个库:
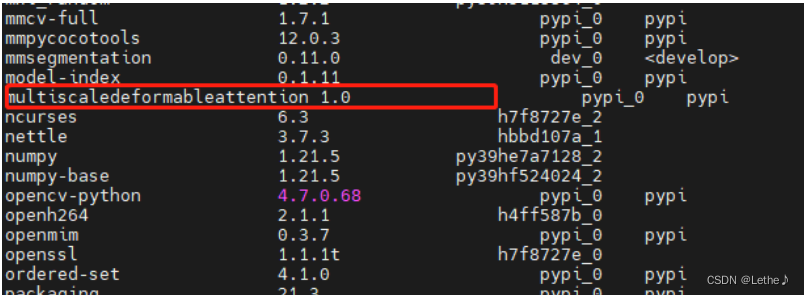
但是,呀,但是,实际使用时:

那么接下来,尝试用easy_install egg文件来安装,因为在另一个服务器已经生成了这个文件(在dist文件夹下),拷贝过去,然后安装:
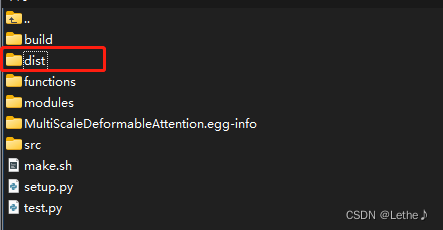
easy_install MultiScaleDeformableAttention-1.0-py3.9-linux-x86_64.egg安装的时候遇到问题:
![]()
经过研究,这是setuptools版本的问题,升级到最新版(67),当前问题解决,出现另一个问题:

这个问题查了半天,无法解决,仔细想还是版本问题,所以就盲试更改版本,发现以下版本解决问题:
pip install setuptools==40再次运行安装,终于安装成功:

但是,在实际运行时确发现另一个bug:

这个库在网上没有找到,所以想到原来我们用来编译的服务器上应该有,搜索之后找到了,然后将它放在了与egg文件相同的目录下,即./envs/python39/lib/python3.9/site-packages对应的文件夹下,但是测试发现系统并没有直接去这个目录下找这个库文件,还是提示找不到。思考是,在源服务器编译时,这个依赖库的路径写死了,写到了so中,还是无法解决问题。
-------------------------------------------------------------------
痛定思痛,决定看看没有root权限,来安装cuda,根据自己torch安装的版本,确定cuda版本,去官网下载run file,然后安装过程中,不选择驱动安装,设置自己的路径(包括cuda-toolkit路径和lib路径),进行安装。可参考:https://blog.csdn.net/u013602059/article/details/121225915
这样cuda是可以安装好的。之后,需要写run.sh文件:
export CUDA_HOME="/xx/./cuda/"
export TORCH_CUDA_ARCH_LIST="8.0"
cd ./models/dino/ops
python setup.py install
这里需要注意:TORCH_CUDA_ARCH_LIST的值与算力有关,TITAN服务器,可以设置8.0,如果时Tesla V100,应该是7.0,否则即使能够编译成功,会报如下错误:
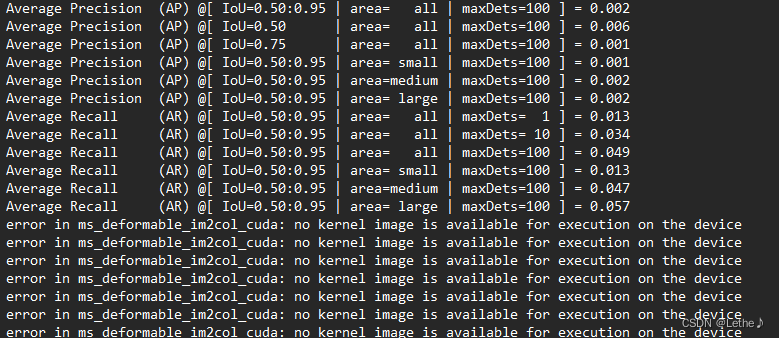
并且,训练过程完全无效。。。
这里提供算力查询网址:https://developer.nvidia.com/cuda-gpus#compute
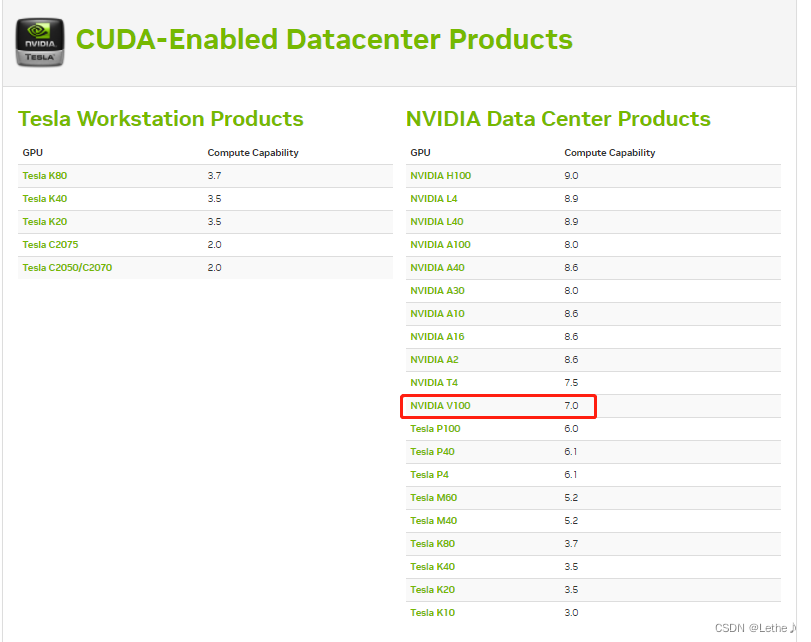

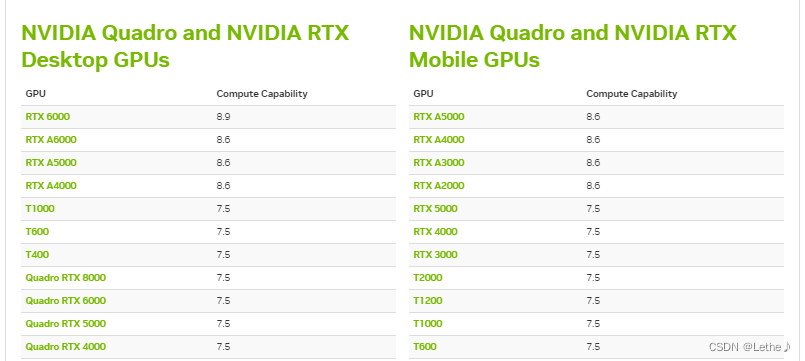
按照自己的服务器GPU硬件条件 去设置就行。
再然后,sbatch run.sh,提交运行,发现能够正确安装,可喜可贺。
![]()
并且,最关键的是,自己的代码能够跑起来了。
总结:整个过程,虽然前面浪费了很多时间,但是还是了解了很多工具。 遇到问题一步一步解决。