作者:老刘
链接:https://www.zhihu.com/question/65502802/answer/802678798
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
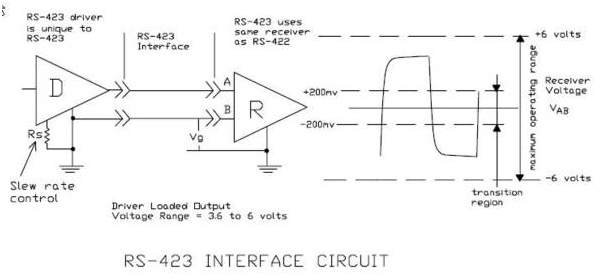
一文详解微服务架构本文将介绍微服务架构和相关的组件,介绍他们是什么以及为什么要使用微服务架构和这些组件。本文侧重于简明地表达微服务架构的全局图景,因此不会涉及具体如何使用组件等细节。要理解微服务,首先要先理解不是微服务的那些。通常跟微服务相对的是单体应用,即将所有功能都打包成在一个独立单元的应用程序。从单体应用到微服务并不是一蹴而就的,这是一个逐渐演变的过程。本文将以一个网上超市应用为例来说明这一过程。最初的需求几年前,小明和小皮一起创业做网上超市。小明负责程序开发,小皮负责其他事宜。当时互联网还不发达,网上超市还是蓝海。只要功能实现了就能随便赚钱。所以他们的需求很简单,只需要一个网站挂在公网,用户能够在这个网站上浏览商品、购买商品;另外还需一个管理后台,可以管理商品、用户、以及订单数据。我们整理一下功能清单:网站:用户注册、登录功能商品展示下单管理后台:用户管理商品管理订单管理由于需求简单,小明左手右手一个慢动作,网站就做好了。管理后台出于安全考虑,不和网站做在一起,小明右手左手慢动作重播,管理网站也做好了。总体架构图如下: 小明挥一挥手,找了家云服务部署上去,网站就上线了。上线后好评如潮,深受各类肥宅喜爱。小明小皮美滋滋地开始躺着收钱。随着业务发展……好景不长,没过几天,各类网上超市紧跟着拔地而起,对小明小皮造成了强烈的冲击。在竞争的压力下,小明小皮决定开展一些营销手段:开展促销活动。比如元旦全场打折,春节买二送一,情人节狗粮优惠券等等。拓展渠道,新增移动端营销。除了网站外,还需要开发移动端APP,微信小程序等。精准营销。利用历史数据对用户进行分析,提供个性化服务。……这些活动都需要程序开发的支持。小明拉了同学小红加入团队。小红负责数据分析以及移动端相关开发。小明负责促销活动相关功能的开发。因为开发任务比较紧迫,小明小红没有好好规划整个系统的架构,随便拍了拍脑袋,决定把促销管理和数据分析放在管理后台里,微信和移动端APP另外搭建。通宵了几天后,新功能和新应用基本完工。这时架构图如下:
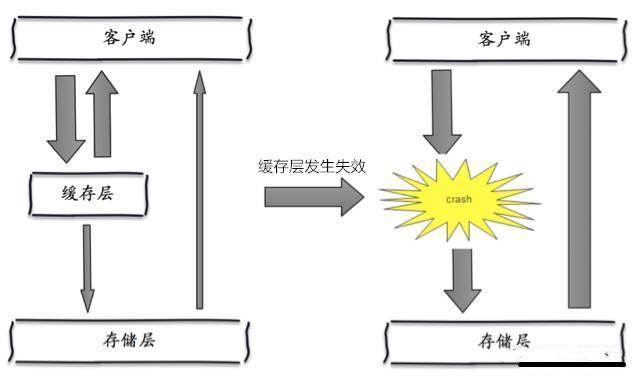
小明挥一挥手,找了家云服务部署上去,网站就上线了。上线后好评如潮,深受各类肥宅喜爱。小明小皮美滋滋地开始躺着收钱。随着业务发展……好景不长,没过几天,各类网上超市紧跟着拔地而起,对小明小皮造成了强烈的冲击。在竞争的压力下,小明小皮决定开展一些营销手段:开展促销活动。比如元旦全场打折,春节买二送一,情人节狗粮优惠券等等。拓展渠道,新增移动端营销。除了网站外,还需要开发移动端APP,微信小程序等。精准营销。利用历史数据对用户进行分析,提供个性化服务。……这些活动都需要程序开发的支持。小明拉了同学小红加入团队。小红负责数据分析以及移动端相关开发。小明负责促销活动相关功能的开发。因为开发任务比较紧迫,小明小红没有好好规划整个系统的架构,随便拍了拍脑袋,决定把促销管理和数据分析放在管理后台里,微信和移动端APP另外搭建。通宵了几天后,新功能和新应用基本完工。这时架构图如下: 这一阶段存在很多不合理的地方:网站和移动端应用有很多相同业务逻辑的重复代码。数据有时候通过数据库共享,有时候通过接口调用传输。接口调用关系杂乱。单个应用为了给其他应用提供接口,渐渐地越改越大,包含了很多本来就不属于它的逻辑。应用边界模糊,功能归属混乱。管理后台在一开始的设计中保障级别较低。加入数据分析和促销管理相关功能后出现性能瓶颈,影响了其他应用。数据库表结构被多个应用依赖,无法重构和优化。所有应用都在一个数据库上操作,数据库出现性能瓶颈。特别是数据分析跑起来的时候,数据库性能急剧下降。开发、测试、部署、维护愈发困难。即使只改动一个小功能,也需要整个应用一起发布。有时候发布会不小心带上了一些未经测试的代码,或者修改了一个功能后,另一个意想不到的地方出错了。为了减轻发布可能产生的问题的影响和线上业务停顿的影响,所有应用都要在凌晨三四点执行发布。发布后为了验证应用正常运行,还得盯到第二天白天的用户高峰期……团队出现推诿扯皮现象。关于一些公用的功能应该建设在哪个应用上的问题常常要争论很久,最后要么干脆各做各的,或者随便放个地方但是都不维护。尽管有着诸多问题,但也不能否认这一阶段的成果:快速地根据业务变化建设了系统。不过紧迫且繁重的任务容易使人陷入局部、短浅的思维方式,从而做出妥协式的决策。在这种架构中,每个人都只关注在自己的一亩三分地,缺乏全局的、长远的设计。长此以往,系统建设将会越来越困难,甚至陷入不断推翻、重建的循环。是时候做出改变了幸好小明和小红是有追求有理想的好青年。意识到问题后,小明和小红从琐碎的业务需求中腾出了一部分精力,开始梳理整体架构,针对问题准备着手改造。要做改造,首先你需要有足够的精力和资源。如果你的需求方(业务人员、项目经理、上司等)很强势地一心追求需求进度,以致于你无法挪出额外的精力和资源的话,那么你可能无法做任何事……在编程的世界中,最重要的便是抽象能力。微服务改造的过程实际上也是个抽象的过程。小明和小红整理了网上超市的业务逻辑,抽象出公用的业务能力,做成几个公共服务:用户服务商品服务促销服务订单服务数据分析服务各个应用后台只需从这些服务获取所需的数据,从而删去了大量冗余的代码,就剩个轻薄的控制层和前端。这一阶段的架构如下:
这一阶段存在很多不合理的地方:网站和移动端应用有很多相同业务逻辑的重复代码。数据有时候通过数据库共享,有时候通过接口调用传输。接口调用关系杂乱。单个应用为了给其他应用提供接口,渐渐地越改越大,包含了很多本来就不属于它的逻辑。应用边界模糊,功能归属混乱。管理后台在一开始的设计中保障级别较低。加入数据分析和促销管理相关功能后出现性能瓶颈,影响了其他应用。数据库表结构被多个应用依赖,无法重构和优化。所有应用都在一个数据库上操作,数据库出现性能瓶颈。特别是数据分析跑起来的时候,数据库性能急剧下降。开发、测试、部署、维护愈发困难。即使只改动一个小功能,也需要整个应用一起发布。有时候发布会不小心带上了一些未经测试的代码,或者修改了一个功能后,另一个意想不到的地方出错了。为了减轻发布可能产生的问题的影响和线上业务停顿的影响,所有应用都要在凌晨三四点执行发布。发布后为了验证应用正常运行,还得盯到第二天白天的用户高峰期……团队出现推诿扯皮现象。关于一些公用的功能应该建设在哪个应用上的问题常常要争论很久,最后要么干脆各做各的,或者随便放个地方但是都不维护。尽管有着诸多问题,但也不能否认这一阶段的成果:快速地根据业务变化建设了系统。不过紧迫且繁重的任务容易使人陷入局部、短浅的思维方式,从而做出妥协式的决策。在这种架构中,每个人都只关注在自己的一亩三分地,缺乏全局的、长远的设计。长此以往,系统建设将会越来越困难,甚至陷入不断推翻、重建的循环。是时候做出改变了幸好小明和小红是有追求有理想的好青年。意识到问题后,小明和小红从琐碎的业务需求中腾出了一部分精力,开始梳理整体架构,针对问题准备着手改造。要做改造,首先你需要有足够的精力和资源。如果你的需求方(业务人员、项目经理、上司等)很强势地一心追求需求进度,以致于你无法挪出额外的精力和资源的话,那么你可能无法做任何事……在编程的世界中,最重要的便是抽象能力。微服务改造的过程实际上也是个抽象的过程。小明和小红整理了网上超市的业务逻辑,抽象出公用的业务能力,做成几个公共服务:用户服务商品服务促销服务订单服务数据分析服务各个应用后台只需从这些服务获取所需的数据,从而删去了大量冗余的代码,就剩个轻薄的控制层和前端。这一阶段的架构如下: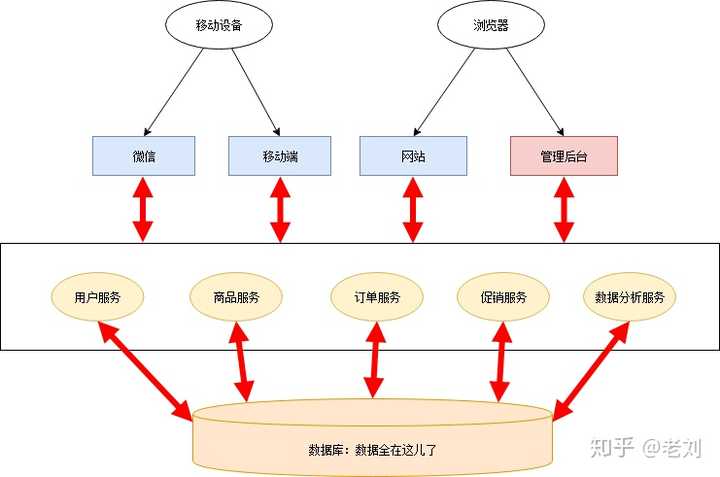 这个阶段只是将服务分开了,数据库依然是共用的,所以一些烟囱式系统的缺点仍然存在:数据库成为性能瓶颈,并且有单点故障的风险。数据管理趋向混乱。即使一开始有良好的模块化设计,随着时间推移,总会有一个服务直接从数据库取另一个服务的数据的现象。数据库表结构可能被多个服务依赖,牵一发而动全身,很难调整。如果一直保持共用数据库的模式,则整个架构会越来越僵化,失去了微服务架构的意义。因此小明和小红一鼓作气,把数据库也拆分了。所有持久化层相互隔离,由各个服务自己负责。另外,为了提高系统的实时性,加入了消息队列机制。架构如下:
这个阶段只是将服务分开了,数据库依然是共用的,所以一些烟囱式系统的缺点仍然存在:数据库成为性能瓶颈,并且有单点故障的风险。数据管理趋向混乱。即使一开始有良好的模块化设计,随着时间推移,总会有一个服务直接从数据库取另一个服务的数据的现象。数据库表结构可能被多个服务依赖,牵一发而动全身,很难调整。如果一直保持共用数据库的模式,则整个架构会越来越僵化,失去了微服务架构的意义。因此小明和小红一鼓作气,把数据库也拆分了。所有持久化层相互隔离,由各个服务自己负责。另外,为了提高系统的实时性,加入了消息队列机制。架构如下: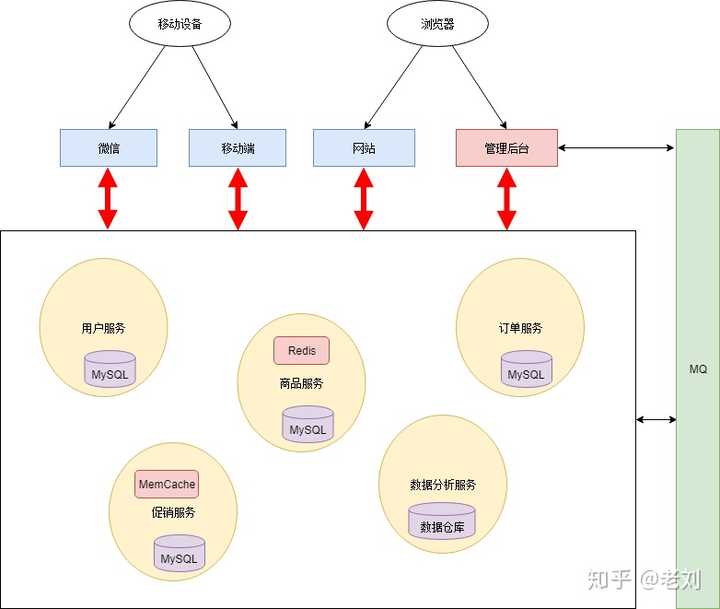 完全拆分后各个服务可以采用异构的技术。比如数据分析服务可以使用数据仓库作为持久化层,以便于高效地做一些统计计算;商品服务和促销服务访问频率比较大,因此加入了缓存机制等。还有一种抽象出公共逻辑的方法是把这些公共逻辑做成公共的框架库。这种方法可以减少服务调用的性能损耗。但是这种方法的管理成本非常高昂,很难保证所有应用版本的一致性。数据库拆分也有一些问题和挑战:比如说跨库级联的需求,通过服务查询数据颗粒度的粗细问题等。但是这些问题可以通过合理的设计来解决。总体来说,数据库拆分是一个利大于弊的。微服务架构还有一个技术外的好处,它使整个系统的分工更加明确,责任更加清晰,每个人专心负责为其他人提供更好的服务。在单体应用的时代,公共的业务功能经常没有明确的归属。最后要么各做各的,每个人都重新实现了一遍;要么是随机一个人(一般是能力比较强或者比较热心的人)做到他负责的应用里面。在后者的情况下,这个人在负责自己应用之外,还要额外负责给别人提供这些公共的功能——而这个功能本来是无人负责的,仅仅因为他能力较强/比较热心,就莫名地背锅(这种情况还被美其名曰能者多劳)。结果最后大家都不愿意提供公共的功能。长此以往,团队里的人渐渐变得各自为政,不再关心全局的架构设计。从这个角度上看,使用微服务架构同时也需要组织结构做相应的调整。所以说做微服务改造需要管理者的支持。改造完成后,小明和小红分清楚各自的锅。两人十分满意,一切就像是麦克斯韦方程组一样漂亮完美。然而……没有银弹春天来了,万物复苏,又到了一年一度的购物狂欢节。眼看着日订单数量蹭蹭地上涨,小皮小明小红喜笑颜开。可惜好景不长,乐极生悲,突然嘣的一下,系统挂了。以往单体应用,排查问题通常是看一下日志,研究错误信息和调用堆栈。而微服务架构整个应用分散成多个服务,定位故障点非常困难。小明一个台机器一台机器地查看日志,一个服务一个服务地手工调用。经过十几分钟的查找,小明终于定位到故障点:促销服务由于接收的请求量太大而停止响应了。其他服务都直接或间接地会调用促销服务,于是也跟着宕机了。在微服务架构中,一个服务故障可能会产生雪崩效用,导致整个系统故障。其实在节前,小明和小红是有做过请求量评估的。按照预计,服务器资源是足以支持节日的请求量的,所以肯定是哪里出了问题。不过形势紧急,随着每一分每一秒流逝的都是白花花的银子,因此小明也没时间排查问题,当机立断在云上新建了几台虚拟机,然后一台一台地部署新的促销服务节点。几分钟的操作后,系统总算是勉强恢复正常了。整个故障时间内估计损失了几十万的销售额,三人的心在滴血……事后,小明简单写了个日志分析工具(量太大了,文本编辑器几乎打不开,打开了肉眼也看不过来),统计了促销服务的访问日志,发现在故障期间,商品服务由于代码问题,在某些场景下会对促销服务发起大量请求。这个问题并不复杂,小明手指抖一抖,修复了这个价值几十万的Bug。问题是解决了,但谁也无法保证不会再发生类似的其他问题。微服务架构虽然逻辑设计上看是完美的,但就像积木搭建的华丽宫殿一样,经不起风吹草动。微服务架构虽然解决了旧问题,也引入了新的问题:微服务架构整个应用分散成多个服务,定位故障点非常困难。稳定性下降。服务数量变多导致其中一个服务出现故障的概率增大,并且一个服务故障可能导致整个系统挂掉。事实上,在大访问量的生产场景下,故障总是会出现的。服务数量非常多,部署、管理的工作量很大。开发方面:如何保证各个服务在持续开发的情况下仍然保持协同合作。测试方面:服务拆分后,几乎所有功能都会涉及多个服务。原本单个程序的测试变为服务间调用的测试。测试变得更加复杂。小明小红痛定思痛,决心好好解决这些问题。对故障的处理一般从两方面入手,一方面尽量减少故障发生的概率,另一方面降低故障造成的影响。
完全拆分后各个服务可以采用异构的技术。比如数据分析服务可以使用数据仓库作为持久化层,以便于高效地做一些统计计算;商品服务和促销服务访问频率比较大,因此加入了缓存机制等。还有一种抽象出公共逻辑的方法是把这些公共逻辑做成公共的框架库。这种方法可以减少服务调用的性能损耗。但是这种方法的管理成本非常高昂,很难保证所有应用版本的一致性。数据库拆分也有一些问题和挑战:比如说跨库级联的需求,通过服务查询数据颗粒度的粗细问题等。但是这些问题可以通过合理的设计来解决。总体来说,数据库拆分是一个利大于弊的。微服务架构还有一个技术外的好处,它使整个系统的分工更加明确,责任更加清晰,每个人专心负责为其他人提供更好的服务。在单体应用的时代,公共的业务功能经常没有明确的归属。最后要么各做各的,每个人都重新实现了一遍;要么是随机一个人(一般是能力比较强或者比较热心的人)做到他负责的应用里面。在后者的情况下,这个人在负责自己应用之外,还要额外负责给别人提供这些公共的功能——而这个功能本来是无人负责的,仅仅因为他能力较强/比较热心,就莫名地背锅(这种情况还被美其名曰能者多劳)。结果最后大家都不愿意提供公共的功能。长此以往,团队里的人渐渐变得各自为政,不再关心全局的架构设计。从这个角度上看,使用微服务架构同时也需要组织结构做相应的调整。所以说做微服务改造需要管理者的支持。改造完成后,小明和小红分清楚各自的锅。两人十分满意,一切就像是麦克斯韦方程组一样漂亮完美。然而……没有银弹春天来了,万物复苏,又到了一年一度的购物狂欢节。眼看着日订单数量蹭蹭地上涨,小皮小明小红喜笑颜开。可惜好景不长,乐极生悲,突然嘣的一下,系统挂了。以往单体应用,排查问题通常是看一下日志,研究错误信息和调用堆栈。而微服务架构整个应用分散成多个服务,定位故障点非常困难。小明一个台机器一台机器地查看日志,一个服务一个服务地手工调用。经过十几分钟的查找,小明终于定位到故障点:促销服务由于接收的请求量太大而停止响应了。其他服务都直接或间接地会调用促销服务,于是也跟着宕机了。在微服务架构中,一个服务故障可能会产生雪崩效用,导致整个系统故障。其实在节前,小明和小红是有做过请求量评估的。按照预计,服务器资源是足以支持节日的请求量的,所以肯定是哪里出了问题。不过形势紧急,随着每一分每一秒流逝的都是白花花的银子,因此小明也没时间排查问题,当机立断在云上新建了几台虚拟机,然后一台一台地部署新的促销服务节点。几分钟的操作后,系统总算是勉强恢复正常了。整个故障时间内估计损失了几十万的销售额,三人的心在滴血……事后,小明简单写了个日志分析工具(量太大了,文本编辑器几乎打不开,打开了肉眼也看不过来),统计了促销服务的访问日志,发现在故障期间,商品服务由于代码问题,在某些场景下会对促销服务发起大量请求。这个问题并不复杂,小明手指抖一抖,修复了这个价值几十万的Bug。问题是解决了,但谁也无法保证不会再发生类似的其他问题。微服务架构虽然逻辑设计上看是完美的,但就像积木搭建的华丽宫殿一样,经不起风吹草动。微服务架构虽然解决了旧问题,也引入了新的问题:微服务架构整个应用分散成多个服务,定位故障点非常困难。稳定性下降。服务数量变多导致其中一个服务出现故障的概率增大,并且一个服务故障可能导致整个系统挂掉。事实上,在大访问量的生产场景下,故障总是会出现的。服务数量非常多,部署、管理的工作量很大。开发方面:如何保证各个服务在持续开发的情况下仍然保持协同合作。测试方面:服务拆分后,几乎所有功能都会涉及多个服务。原本单个程序的测试变为服务间调用的测试。测试变得更加复杂。小明小红痛定思痛,决心好好解决这些问题。对故障的处理一般从两方面入手,一方面尽量减少故障发生的概率,另一方面降低故障造成的影响。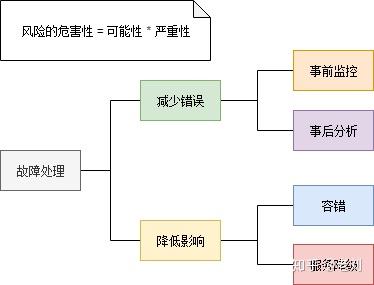 监控 - 发现故障的征兆在高并发分布式的场景下,故障经常是突然间就雪崩式爆发。所以必须建立完善的监控体系,尽可能发现故障的征兆。微服务架构中组件繁多,各个组件所需要监控的指标不同。比如Redis缓存一般监控占用内存值、网络流量,数据库监控连接数、磁盘空间,业务服务监控并发数、响应延迟、错误率等。因此如果做一个大而全的监控系统来监控各个组件是不大现实的,而且扩展性会很差。一般的做法是让各个组件提供报告自己当前状态的接口(metrics接口),这个接口输出的数据格式应该是一致的。然后部署一个指标采集器组件,定时从这些接口获取并保持组件状态,同时提供查询服务。最后还需要一个UI,从指标采集器查询各项指标,绘制监控界面或者根据阈值发出告警。大部分组件都不需要自己动手开发,网络上有开源组件。小明下载了RedisExporter和MySQLExporter,这两个组件分别提供了Redis缓存和MySQL数据库的指标接口。微服务则根据各个服务的业务逻辑实现自定义的指标接口。然后小明采用Prometheus作为指标采集器,Grafana配置监控界面和邮件告警。这样一套微服务监控系统就搭建起来了:
监控 - 发现故障的征兆在高并发分布式的场景下,故障经常是突然间就雪崩式爆发。所以必须建立完善的监控体系,尽可能发现故障的征兆。微服务架构中组件繁多,各个组件所需要监控的指标不同。比如Redis缓存一般监控占用内存值、网络流量,数据库监控连接数、磁盘空间,业务服务监控并发数、响应延迟、错误率等。因此如果做一个大而全的监控系统来监控各个组件是不大现实的,而且扩展性会很差。一般的做法是让各个组件提供报告自己当前状态的接口(metrics接口),这个接口输出的数据格式应该是一致的。然后部署一个指标采集器组件,定时从这些接口获取并保持组件状态,同时提供查询服务。最后还需要一个UI,从指标采集器查询各项指标,绘制监控界面或者根据阈值发出告警。大部分组件都不需要自己动手开发,网络上有开源组件。小明下载了RedisExporter和MySQLExporter,这两个组件分别提供了Redis缓存和MySQL数据库的指标接口。微服务则根据各个服务的业务逻辑实现自定义的指标接口。然后小明采用Prometheus作为指标采集器,Grafana配置监控界面和邮件告警。这样一套微服务监控系统就搭建起来了: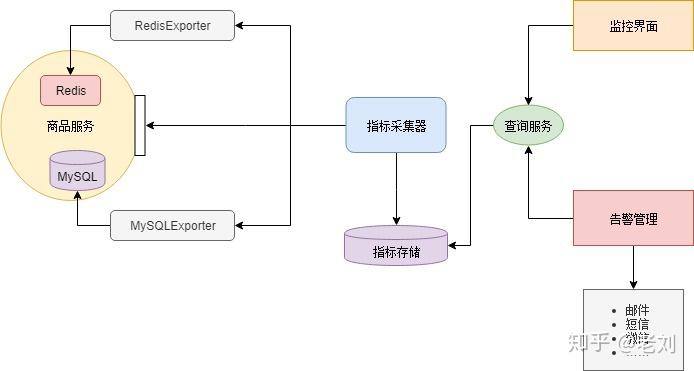 定位问题 - 链路跟踪在微服务架构下,一个用户的请求往往涉及多个内部服务调用。为了方便定位问题,需要能够记录每个用户请求时,微服务内部产生了多少服务调用,及其调用关系。这个叫做链路跟踪。我们用一个Istio文档里的链路跟踪例子来看看效果:
定位问题 - 链路跟踪在微服务架构下,一个用户的请求往往涉及多个内部服务调用。为了方便定位问题,需要能够记录每个用户请求时,微服务内部产生了多少服务调用,及其调用关系。这个叫做链路跟踪。我们用一个Istio文档里的链路跟踪例子来看看效果: 图片来自Istio文档从图中可以看到,这是一个用户访问productpage页面的请求。在请求过程中,productpage服务顺序调用了details和reviews服务的接口。而reviews服务在响应过程中又调用了ratings的接口。整个链路跟踪的记录是一棵树:
图片来自Istio文档从图中可以看到,这是一个用户访问productpage页面的请求。在请求过程中,productpage服务顺序调用了details和reviews服务的接口。而reviews服务在响应过程中又调用了ratings的接口。整个链路跟踪的记录是一棵树: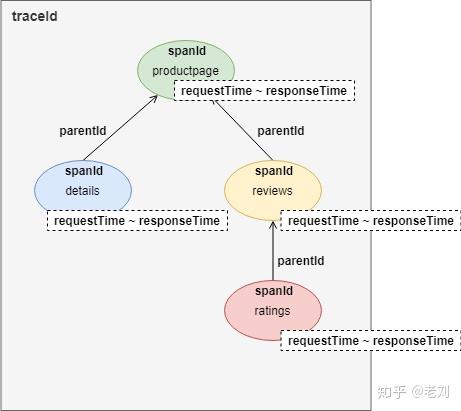 要实现链路跟踪,每次服务调用会在HTTP的HEADERS中记录至少记录四项数据:traceId:traceId标识一个用户请求的调用链路。具有相同traceId的调用属于同一条链路。spanId:标识一次服务调用的ID,即链路跟踪的节点ID。parentId:父节点的spanId。requestTime & responseTime:请求时间和响应时间。另外,还需要调用日志收集与存储的组件,以及展示链路调用的UI组件。
要实现链路跟踪,每次服务调用会在HTTP的HEADERS中记录至少记录四项数据:traceId:traceId标识一个用户请求的调用链路。具有相同traceId的调用属于同一条链路。spanId:标识一次服务调用的ID,即链路跟踪的节点ID。parentId:父节点的spanId。requestTime & responseTime:请求时间和响应时间。另外,还需要调用日志收集与存储的组件,以及展示链路调用的UI组件。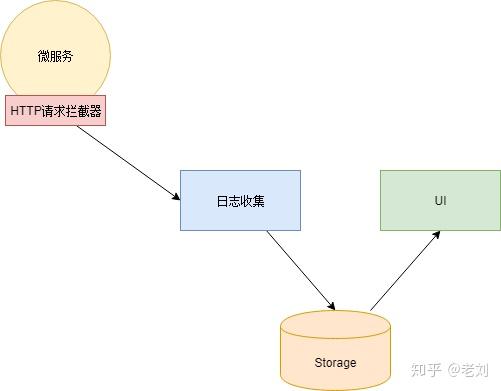 以上只是一个极简的说明,关于链路跟踪的理论依据可详见Google的Dapper了解了理论基础后,小明选用了Dapper的一个开源实现Zipkin。然后手指一抖,写了个HTTP请求的拦截器,在每次HTTP请求时生成这些数据注入到HEADERS,同时异步发送调用日志到Zipkin的日志收集器中。这里额外提一下,HTTP请求的拦截器,可以在微服务的代码中实现,也可以使用一个网络代理组件来实现(不过这样子每个微服务都需要加一层代理)。链路跟踪只能定位到哪个服务出现问题,不能提供具体的错误信息。查找具体的错误信息的能力则需要由日志分析组件来提供。分析问题 - 日志分析日志分析组件应该在微服务兴起之前就被广泛使用了。即使单体应用架构,当访问数变大、或服务器规模增多时,日志文件的大小会膨胀到难以用文本编辑器进行访问,更糟的是它们分散在多台服务器上面。排查一个问题,需要登录到各台服务器去获取日志文件,一个一个地查找(而且打开、查找都很慢)想要的日志信息。因此,在应用规模变大时,我们需要一个日志的“搜索引擎”。以便于能准确的找到想要的日志。另外,数据源一侧还需要收集日志的组件和展示结果的UI组件:
以上只是一个极简的说明,关于链路跟踪的理论依据可详见Google的Dapper了解了理论基础后,小明选用了Dapper的一个开源实现Zipkin。然后手指一抖,写了个HTTP请求的拦截器,在每次HTTP请求时生成这些数据注入到HEADERS,同时异步发送调用日志到Zipkin的日志收集器中。这里额外提一下,HTTP请求的拦截器,可以在微服务的代码中实现,也可以使用一个网络代理组件来实现(不过这样子每个微服务都需要加一层代理)。链路跟踪只能定位到哪个服务出现问题,不能提供具体的错误信息。查找具体的错误信息的能力则需要由日志分析组件来提供。分析问题 - 日志分析日志分析组件应该在微服务兴起之前就被广泛使用了。即使单体应用架构,当访问数变大、或服务器规模增多时,日志文件的大小会膨胀到难以用文本编辑器进行访问,更糟的是它们分散在多台服务器上面。排查一个问题,需要登录到各台服务器去获取日志文件,一个一个地查找(而且打开、查找都很慢)想要的日志信息。因此,在应用规模变大时,我们需要一个日志的“搜索引擎”。以便于能准确的找到想要的日志。另外,数据源一侧还需要收集日志的组件和展示结果的UI组件: 小明调查了一下,使用了大名鼎鼎地ELK日志分析组件。ELK是Elasticsearch、Logstash和Kibana三个组件的缩写。Elasticsearch:搜索引擎,同时也是日志的存储。Logstash:日志采集器,它接收日志输入,对日志进行一些预处理,然后输出到Elasticsearch。Kibana:UI组件,通过Elasticsearch的API查找数据并展示给用户。最后还有一个小问题是如何将日志发送到Logstash。一种方案是在日志输出的时候直接调用Logstash接口将日志发送过去。这样一来又(咦,为啥要用“又”)要修改代码……于是小明选用了另一种方案:日志仍然输出到文件,每个服务里再部署个Agent扫描日志文件然后输出给Logstash。网关 - 权限控制,服务治理拆分成微服务后,出现大量的服务,大量的接口,使得整个调用关系乱糟糟的。经常在开发过程中,写着写着,忽然想不起某个数据应该调用哪个服务。或者写歪了,调用了不该调用的服务,本来一个只读的功能结果修改了数据……为了应对这些情况,微服务的调用需要一个把关的东西,也就是网关。在调用者和被调用者中间加一层网关,每次调用时进行权限校验。另外,网关也可以作为一个提供服务接口文档的平台。使用网关有一个问题就是要决定在多大粒度上使用:最粗粒度的方案是整个微服务一个网关,微服务外部通过网关访问微服务,微服务内部则直接调用;最细粒度则是所有调用,不管是微服务内部调用或者来自外部的调用,都必须通过网关。折中的方案是按照业务领域将微服务分成几个区,区内直接调用,区间通过网关调用。由于整个网上超市的服务数量还不算特别多,小明采用的最粗粒度的方案:
小明调查了一下,使用了大名鼎鼎地ELK日志分析组件。ELK是Elasticsearch、Logstash和Kibana三个组件的缩写。Elasticsearch:搜索引擎,同时也是日志的存储。Logstash:日志采集器,它接收日志输入,对日志进行一些预处理,然后输出到Elasticsearch。Kibana:UI组件,通过Elasticsearch的API查找数据并展示给用户。最后还有一个小问题是如何将日志发送到Logstash。一种方案是在日志输出的时候直接调用Logstash接口将日志发送过去。这样一来又(咦,为啥要用“又”)要修改代码……于是小明选用了另一种方案:日志仍然输出到文件,每个服务里再部署个Agent扫描日志文件然后输出给Logstash。网关 - 权限控制,服务治理拆分成微服务后,出现大量的服务,大量的接口,使得整个调用关系乱糟糟的。经常在开发过程中,写着写着,忽然想不起某个数据应该调用哪个服务。或者写歪了,调用了不该调用的服务,本来一个只读的功能结果修改了数据……为了应对这些情况,微服务的调用需要一个把关的东西,也就是网关。在调用者和被调用者中间加一层网关,每次调用时进行权限校验。另外,网关也可以作为一个提供服务接口文档的平台。使用网关有一个问题就是要决定在多大粒度上使用:最粗粒度的方案是整个微服务一个网关,微服务外部通过网关访问微服务,微服务内部则直接调用;最细粒度则是所有调用,不管是微服务内部调用或者来自外部的调用,都必须通过网关。折中的方案是按照业务领域将微服务分成几个区,区内直接调用,区间通过网关调用。由于整个网上超市的服务数量还不算特别多,小明采用的最粗粒度的方案: 服务注册于发现 - 动态扩容前面的组件,都是旨在降低故障发生的可能性。然而故障总是会发生的,所以另一个需要研究的是如何降低故障产生的影响。最粗暴的(也是最常用的)故障处理策略就是冗余。一般来说,一个服务都会部署多个实例,这样一来能够分担压力提高性能,二来即使一个实例挂了其他实例还能响应。冗余的一个问题是使用几个冗余?这个问题在时间轴上并没有一个切确的答案。根据服务功能、时间段的不同,需要不同数量的实例。比如在平日里,可能4个实例已经够用;而在促销活动时,流量大增,可能需要40个实例。因此冗余数量并不是一个固定的值,而是根据需要实时调整的。一般来说新增实例的操作为:部署新实例将新实例注册到负载均衡或DNS上操作只有两步,但如果注册到负载均衡或DNS的操作为人工操作的话,那事情就不简单了。想想新增40个实例后,要手工输入40个IP的感觉……解决这个问题的方案是服务自动注册与发现。首先,需要部署一个服务发现服务,它提供所有已注册服务的地址信息的服务。DNS也算是一种服务发现服务。然后各个应用服务在启动时自动将自己注册到服务发现服务上。并且应用服务启动后会实时(定期)从服务发现服务同步各个应用服务的地址列表到本地。服务发现服务也会定期检查应用服务的健康状态,去掉不健康的实例地址。这样新增实例时只需要部署新实例,实例下线时直接关停服务即可,服务发现会自动检查服务实例的增减。
服务注册于发现 - 动态扩容前面的组件,都是旨在降低故障发生的可能性。然而故障总是会发生的,所以另一个需要研究的是如何降低故障产生的影响。最粗暴的(也是最常用的)故障处理策略就是冗余。一般来说,一个服务都会部署多个实例,这样一来能够分担压力提高性能,二来即使一个实例挂了其他实例还能响应。冗余的一个问题是使用几个冗余?这个问题在时间轴上并没有一个切确的答案。根据服务功能、时间段的不同,需要不同数量的实例。比如在平日里,可能4个实例已经够用;而在促销活动时,流量大增,可能需要40个实例。因此冗余数量并不是一个固定的值,而是根据需要实时调整的。一般来说新增实例的操作为:部署新实例将新实例注册到负载均衡或DNS上操作只有两步,但如果注册到负载均衡或DNS的操作为人工操作的话,那事情就不简单了。想想新增40个实例后,要手工输入40个IP的感觉……解决这个问题的方案是服务自动注册与发现。首先,需要部署一个服务发现服务,它提供所有已注册服务的地址信息的服务。DNS也算是一种服务发现服务。然后各个应用服务在启动时自动将自己注册到服务发现服务上。并且应用服务启动后会实时(定期)从服务发现服务同步各个应用服务的地址列表到本地。服务发现服务也会定期检查应用服务的健康状态,去掉不健康的实例地址。这样新增实例时只需要部署新实例,实例下线时直接关停服务即可,服务发现会自动检查服务实例的增减。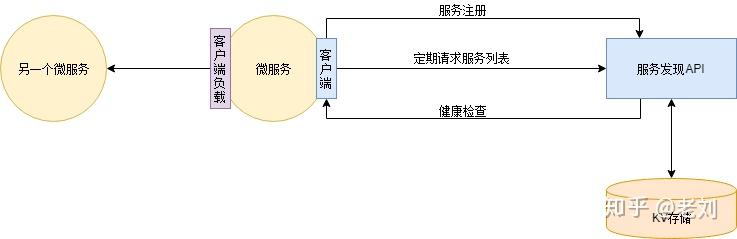 服务发现还会跟客户端负载均衡配合使用。由于应用服务已经同步服务地址列表在本地了,所以访问微服务时,可以自己决定负载策略。甚至可以在服务注册时加入一些元数据(服务版本等信息),客户端负载则根据这些元数据进行流量控制,实现A/B测试、蓝绿发布等功能。服务发现有很多组件可以选择,比如说Zookeeper 、Eureka、Consul、Etcd等。不过小明觉得自己水平不错,想炫技,于是基于Redis自己写了一个……熔断、服务降级、限流熔断当一个服务因为各种原因停止响应时,调用方通常会等待一段时间,然后超时或者收到错误返回。如果调用链路比较长,可能会导致请求堆积,整条链路占用大量资源一直在等待下游响应。所以当多次访问一个服务失败时,应熔断,标记该服务已停止工作,直接返回错误。直至该服务恢复正常后再重新建立连接。
服务发现还会跟客户端负载均衡配合使用。由于应用服务已经同步服务地址列表在本地了,所以访问微服务时,可以自己决定负载策略。甚至可以在服务注册时加入一些元数据(服务版本等信息),客户端负载则根据这些元数据进行流量控制,实现A/B测试、蓝绿发布等功能。服务发现有很多组件可以选择,比如说Zookeeper 、Eureka、Consul、Etcd等。不过小明觉得自己水平不错,想炫技,于是基于Redis自己写了一个……熔断、服务降级、限流熔断当一个服务因为各种原因停止响应时,调用方通常会等待一段时间,然后超时或者收到错误返回。如果调用链路比较长,可能会导致请求堆积,整条链路占用大量资源一直在等待下游响应。所以当多次访问一个服务失败时,应熔断,标记该服务已停止工作,直接返回错误。直至该服务恢复正常后再重新建立连接。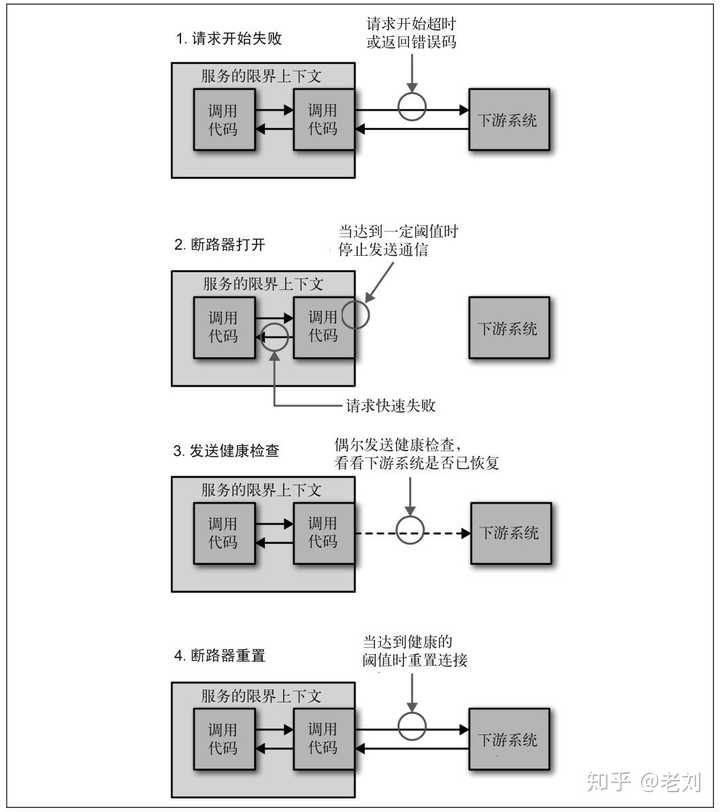 图片来自《微服务设计》服务降级当下游服务停止工作后,如果该服务并非核心业务,则上游服务应该降级,以保证核心业务不中断。比如网上超市下单界面有一个推荐商品凑单的功能,当推荐模块挂了后,下单功能不能一起挂掉,只需要暂时关闭推荐功能即可。限流一个服务挂掉后,上游服务或者用户一般会习惯性地重试访问。这导致一旦服务恢复正常,很可能因为瞬间网络流量过大又立刻挂掉,在棺材里重复着仰卧起坐。因此服务需要能够自我保护——限流。限流策略有很多,最简单的比如当单位时间内请求数过多时,丢弃多余的请求。另外,也可以考虑分区限流。仅拒绝来自产生大量请求的服务的请求。例如商品服务和订单服务都需要访问促销服务,商品服务由于代码问题发起了大量请求,促销服务则只限制来自商品服务的请求,来自订单服务的请求则正常响应。
图片来自《微服务设计》服务降级当下游服务停止工作后,如果该服务并非核心业务,则上游服务应该降级,以保证核心业务不中断。比如网上超市下单界面有一个推荐商品凑单的功能,当推荐模块挂了后,下单功能不能一起挂掉,只需要暂时关闭推荐功能即可。限流一个服务挂掉后,上游服务或者用户一般会习惯性地重试访问。这导致一旦服务恢复正常,很可能因为瞬间网络流量过大又立刻挂掉,在棺材里重复着仰卧起坐。因此服务需要能够自我保护——限流。限流策略有很多,最简单的比如当单位时间内请求数过多时,丢弃多余的请求。另外,也可以考虑分区限流。仅拒绝来自产生大量请求的服务的请求。例如商品服务和订单服务都需要访问促销服务,商品服务由于代码问题发起了大量请求,促销服务则只限制来自商品服务的请求,来自订单服务的请求则正常响应。 测试微服务架构下,测试分为三个层次:端到端测试:覆盖整个系统,一般在用户界面机型测试。服务测试:针对服务接口进行测试。单元测试:针对代码单元进行测试。三种测试从上到下实施的容易程度递增,但是测试效果递减。端到端测试最费时费力,但是通过测试后我们对系统最有信心。单元测试最容易实施,效率也最高,但是测试后不能保证整个系统没有问题。
测试微服务架构下,测试分为三个层次:端到端测试:覆盖整个系统,一般在用户界面机型测试。服务测试:针对服务接口进行测试。单元测试:针对代码单元进行测试。三种测试从上到下实施的容易程度递增,但是测试效果递减。端到端测试最费时费力,但是通过测试后我们对系统最有信心。单元测试最容易实施,效率也最高,但是测试后不能保证整个系统没有问题。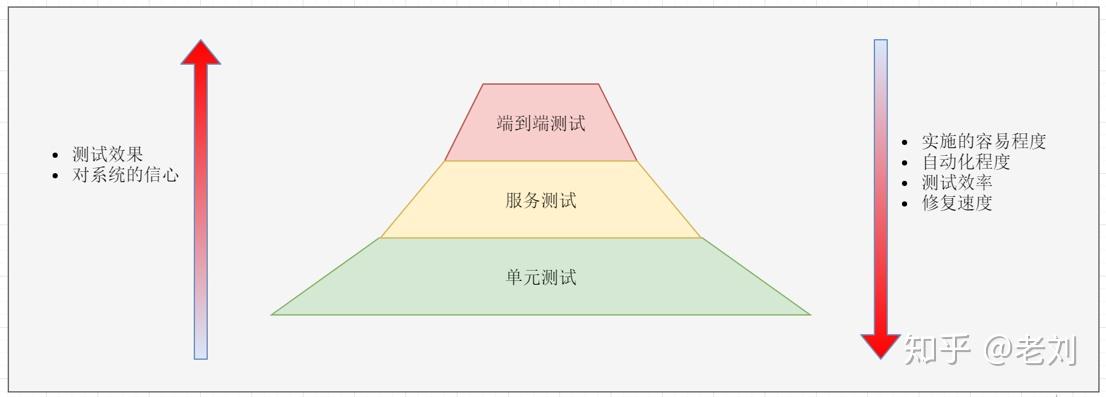 由于端到端测试实施难度较大,一般只对核心功能做端到端测试。一旦端到端测试失败,则需要将其分解到单元测试:则分析失败原因,然后编写单元测试来重现这个问题,这样未来我们便可以更快地捕获同样的错误。服务测试的难度在于服务会经常依赖一些其他服务。这个问题可以通过Mock Server解决:
由于端到端测试实施难度较大,一般只对核心功能做端到端测试。一旦端到端测试失败,则需要将其分解到单元测试:则分析失败原因,然后编写单元测试来重现这个问题,这样未来我们便可以更快地捕获同样的错误。服务测试的难度在于服务会经常依赖一些其他服务。这个问题可以通过Mock Server解决: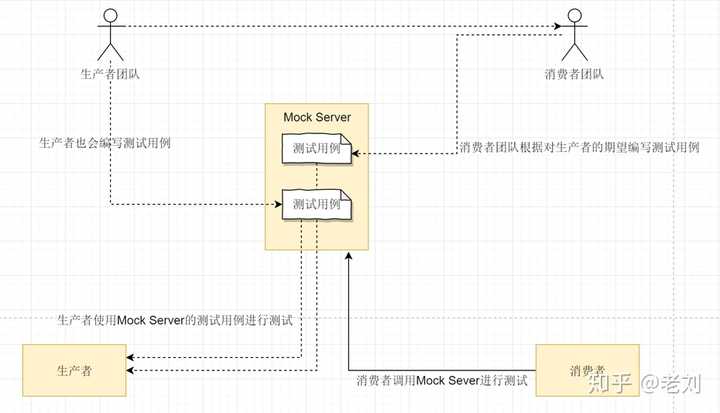 单元测试大家都很熟悉了。我们一般会编写大量的单元测试(包括回归测试)尽量覆盖所有代码。微服务框架指标接口、链路跟踪注入、日志引流、服务注册发现、路由规则等组件以及熔断、限流等功能都需要在应用服务上添加一些对接代码。如果让每个应用服务自己实现是非常耗时耗力的。基于DRY的原则,小明开发了一套微服务框架,将与各个组件对接的代码和另外一些公共代码抽离到框架中,所有的应用服务都统一使用这套框架进行开发。使用微服务框架可以实现很多自定义的功能。甚至可以将程序调用堆栈信息注入到链路跟踪,实现代码级别的链路跟踪。或者输出线程池、连接池的状态信息,实时监控服务底层状态。使用统一的微服务框架有一个比较严重的问题:框架更新成本很高。每次框架升级,都需要所有应用服务配合升级。当然,一般会使用兼容方案,留出一段并行时间等待所有应用服务升级。但是如果应用服务非常多时,升级时间可能会非常漫长。并且有一些很稳定几乎不更新的应用服务,其负责人可能会拒绝升级……因此,使用统一微服务框架需要完善的版本管理方法和开发管理规范。另一条路 - Service Mesh另一种抽象公共代码的方法是直接将这些代码抽象到一个反向代理组件。每个服务都额外部署这个代理组件,所有出站入站的流量都通过该组件进行处理和转发。这个组件被称为Sidecar。Sidecar不会产生额外网络成本。Sidecar会和微服务节点部署在同一台主机上并且共用相同的虚拟网卡。所以sidecar和微服务节点的通信实际上都只是通过内存拷贝实现的。
单元测试大家都很熟悉了。我们一般会编写大量的单元测试(包括回归测试)尽量覆盖所有代码。微服务框架指标接口、链路跟踪注入、日志引流、服务注册发现、路由规则等组件以及熔断、限流等功能都需要在应用服务上添加一些对接代码。如果让每个应用服务自己实现是非常耗时耗力的。基于DRY的原则,小明开发了一套微服务框架,将与各个组件对接的代码和另外一些公共代码抽离到框架中,所有的应用服务都统一使用这套框架进行开发。使用微服务框架可以实现很多自定义的功能。甚至可以将程序调用堆栈信息注入到链路跟踪,实现代码级别的链路跟踪。或者输出线程池、连接池的状态信息,实时监控服务底层状态。使用统一的微服务框架有一个比较严重的问题:框架更新成本很高。每次框架升级,都需要所有应用服务配合升级。当然,一般会使用兼容方案,留出一段并行时间等待所有应用服务升级。但是如果应用服务非常多时,升级时间可能会非常漫长。并且有一些很稳定几乎不更新的应用服务,其负责人可能会拒绝升级……因此,使用统一微服务框架需要完善的版本管理方法和开发管理规范。另一条路 - Service Mesh另一种抽象公共代码的方法是直接将这些代码抽象到一个反向代理组件。每个服务都额外部署这个代理组件,所有出站入站的流量都通过该组件进行处理和转发。这个组件被称为Sidecar。Sidecar不会产生额外网络成本。Sidecar会和微服务节点部署在同一台主机上并且共用相同的虚拟网卡。所以sidecar和微服务节点的通信实际上都只是通过内存拷贝实现的。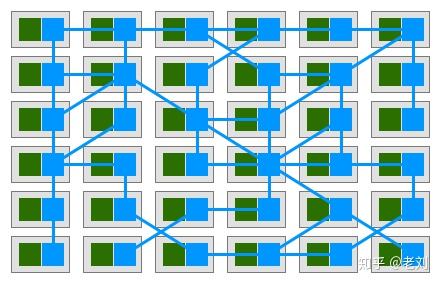 图片来自:Pattern: Service MeshSidecar只负责网络通信。还需要有个组件来统一管理所有sidecar的配置。在Service Mesh中,负责网络通信的部分叫数据平面(data plane),负责配置管理的部分叫控制平面(control plane)。数据平面和控制平面构成了Service Mesh的基本架构。
图片来自:Pattern: Service MeshSidecar只负责网络通信。还需要有个组件来统一管理所有sidecar的配置。在Service Mesh中,负责网络通信的部分叫数据平面(data plane),负责配置管理的部分叫控制平面(control plane)。数据平面和控制平面构成了Service Mesh的基本架构。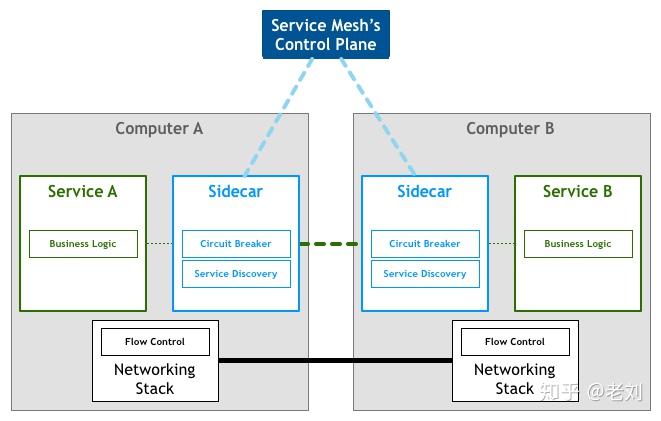 图片来自:Pattern: Service MeshSevice Mesh相比于微服务框架的优点在于它不侵入代码,升级和维护更方便。它经常被诟病的则是性能问题。即使回环网络不会产生实际的网络请求,但仍然有内存拷贝的额外成本。另外有一些集中式的流量处理也会影响性能。结束、也是开始微服务不是架构演变的终点。往细走还有Serverless、FaaS等方向。另一方面也有人在唱合久必分分久必合,重新发现单体架构……不管怎样,微服务架构的改造暂时告一段落了。小明满足地摸了摸日益光滑的脑袋,打算这个周末休息一下约小红喝杯咖啡。作者:古霜卡比链接:https://www.cnblogs.com/skabyy/p/11396571.html来源:博客园发布于 2019-08-26赞同 248293 条评论分享收藏喜欢收起华为云技术宅基地已认证的官方帐号207 人赞同了该回答“微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通(通常是基于HTTP的Restful API).每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构"---- Martin Fowler的博客微服务的特征与界定
图片来自:Pattern: Service MeshSevice Mesh相比于微服务框架的优点在于它不侵入代码,升级和维护更方便。它经常被诟病的则是性能问题。即使回环网络不会产生实际的网络请求,但仍然有内存拷贝的额外成本。另外有一些集中式的流量处理也会影响性能。结束、也是开始微服务不是架构演变的终点。往细走还有Serverless、FaaS等方向。另一方面也有人在唱合久必分分久必合,重新发现单体架构……不管怎样,微服务架构的改造暂时告一段落了。小明满足地摸了摸日益光滑的脑袋,打算这个周末休息一下约小红喝杯咖啡。作者:古霜卡比链接:https://www.cnblogs.com/skabyy/p/11396571.html来源:博客园发布于 2019-08-26赞同 248293 条评论分享收藏喜欢收起华为云技术宅基地已认证的官方帐号207 人赞同了该回答“微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通(通常是基于HTTP的Restful API).每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构"---- Martin Fowler的博客微服务的特征与界定 单体应用 vs 微服务架构 优点提升开发交流,每个服务足够内聚,足够小,代码容易理解;服务独立测试、部署、升级、发布;按需定制的DFX,资源利用率,每个服务可以各自进行x扩展和z扩展,而且,每个服务可以根据自己的需要部署到合适的硬件服务器上;每个服务按需要选择HA的模式,选择接受服务的实例个数;容易扩大开发团队,可以针对每个服务(service)组件开发团队;提高容错性(fault isolation),一个服务的内存泄露并不会让整个系统瘫痪;新技术的应用,系统不会被长期限制在某个技术栈上;缺点没有银弹,微服务提高了系统的复杂度;开发人员要处理分布式系统的复杂性;服务之间的分布式通信问题;服务的注册与发现问题;服务之间的分布式事务问题;数据隔离再来的报表处理问题;服务之间的分布式一致性问题;服务管理的复杂性,服务的编排;不同服务实例的管理。
单体应用 vs 微服务架构 优点提升开发交流,每个服务足够内聚,足够小,代码容易理解;服务独立测试、部署、升级、发布;按需定制的DFX,资源利用率,每个服务可以各自进行x扩展和z扩展,而且,每个服务可以根据自己的需要部署到合适的硬件服务器上;每个服务按需要选择HA的模式,选择接受服务的实例个数;容易扩大开发团队,可以针对每个服务(service)组件开发团队;提高容错性(fault isolation),一个服务的内存泄露并不会让整个系统瘫痪;新技术的应用,系统不会被长期限制在某个技术栈上;缺点没有银弹,微服务提高了系统的复杂度;开发人员要处理分布式系统的复杂性;服务之间的分布式通信问题;服务的注册与发现问题;服务之间的分布式事务问题;数据隔离再来的报表处理问题;服务之间的分布式一致性问题;服务管理的复杂性,服务的编排;不同服务实例的管理。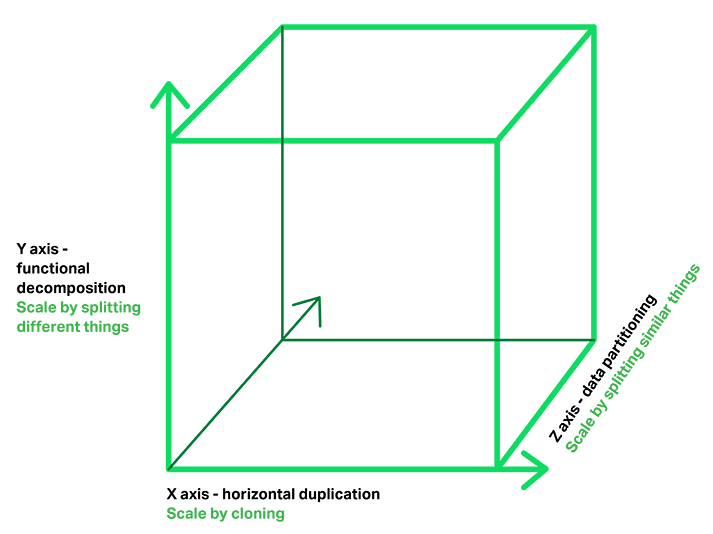 Chris Richardson提出的微服务的三维扩展模型:X轴,服务实例水平扩展,保证可靠性与性能;Y轴,功能的扩展,服务单一职责,功能独立;Z轴,数据分区,数据独立,可靠性保证;
Chris Richardson提出的微服务的三维扩展模型:X轴,服务实例水平扩展,保证可靠性与性能;Y轴,功能的扩展,服务单一职责,功能独立;Z轴,数据分区,数据独立,可靠性保证; 通信问题微服务的拆分一般会带来IPC通信的问题。通信机制需要完备可靠,服务之间的通信选择应尽量单一,从两个维度对通信的模式进行划分:第一个维度是一对一还是一对多:一对一:每个客户端请求有一个服务实例来响应。一对多:每个客户端请求有多个服务实例来响应。第二个维度是这些交互式同步还是异步:同步模式:客户端请求需要服务端即时响应,甚至可能由于等待而阻塞。异步模式:客户端请求不会阻塞进程,服务端的响应可以是非即时的。
通信问题微服务的拆分一般会带来IPC通信的问题。通信机制需要完备可靠,服务之间的通信选择应尽量单一,从两个维度对通信的模式进行划分:第一个维度是一对一还是一对多:一对一:每个客户端请求有一个服务实例来响应。一对多:每个客户端请求有多个服务实例来响应。第二个维度是这些交互式同步还是异步:同步模式:客户端请求需要服务端即时响应,甚至可能由于等待而阻塞。异步模式:客户端请求不会阻塞进程,服务端的响应可以是非即时的。 微服务架构认为,服务间通信应该就只有这几种模式。AC出于时延、编程模型等方面的考虑,提供了一套通信机制,业务之间的通信要按需选用。服务的发现与注册一般的微服务架构里都有两层API GetWay,一层是外部API GetWay,用于用户访问系统;一层是内部API GetWay,内部服务之间的API GetWay。内部API GetWay要解决的问题就是服务发现和服务注册。从这也能看出来,为什么通信的方式要尽量单一,API GetWay有一项工作就是协议转换。微服务可能是HA主备的,也可能是LB的,怎么找到一个服务?有两种思路,客户端发现(左图),客户端去注册中心查询服务实例列表,自行选择;另一种是服务端发现(右图),添加LB模块,客户端把请求发向LB,由LB根据负载均衡策略选择服务实例;
微服务架构认为,服务间通信应该就只有这几种模式。AC出于时延、编程模型等方面的考虑,提供了一套通信机制,业务之间的通信要按需选用。服务的发现与注册一般的微服务架构里都有两层API GetWay,一层是外部API GetWay,用于用户访问系统;一层是内部API GetWay,内部服务之间的API GetWay。内部API GetWay要解决的问题就是服务发现和服务注册。从这也能看出来,为什么通信的方式要尽量单一,API GetWay有一项工作就是协议转换。微服务可能是HA主备的,也可能是LB的,怎么找到一个服务?有两种思路,客户端发现(左图),客户端去注册中心查询服务实例列表,自行选择;另一种是服务端发现(右图),添加LB模块,客户端把请求发向LB,由LB根据负载均衡策略选择服务实例;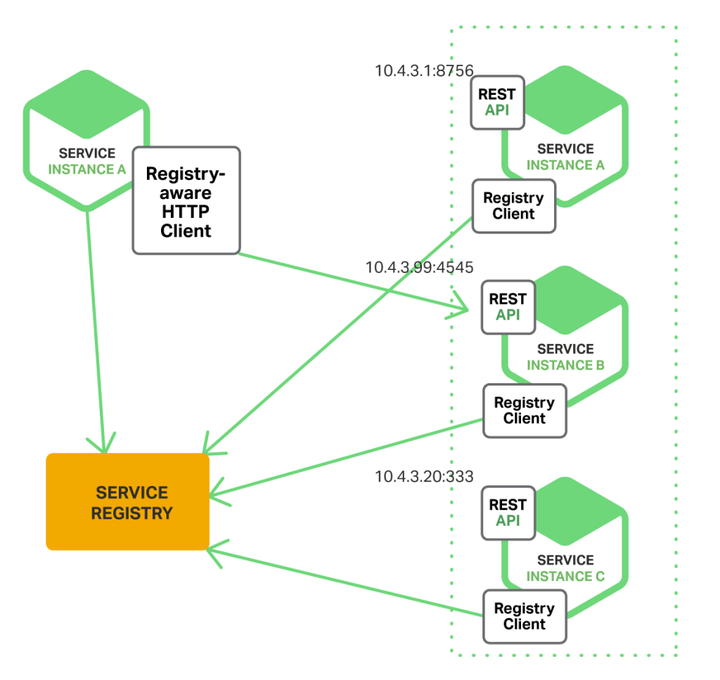
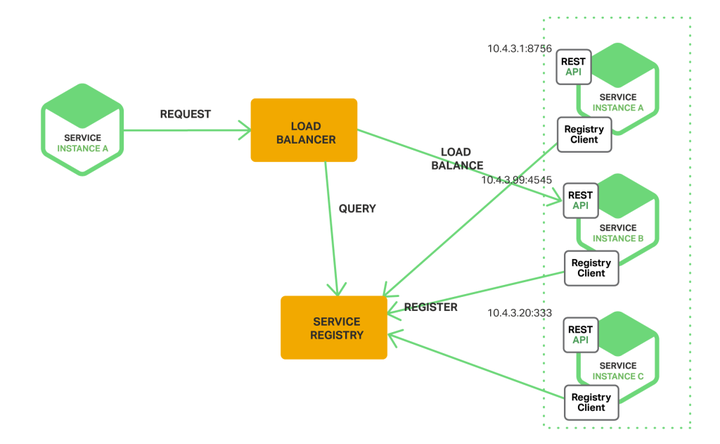 微服务注册表的典型实现: ETCD : 是一个高可用,分布式的,一致性的,键值表,用于共享配置和服务发现。两个著名案例包括Kubernetes和Cloud Foundry。 ZK: 是一个广泛使用,为分布式应用提供高性能整合的服务。Apache ZooKeeper最初是Hadoop的子项目,现在已经变成顶级项目。微服务架构的部署微服务架构对于部署的要求:部署速率,Amazon与NetFlix都有千个服务,每个服务都有持续部署的要求,Amazon的服务每秒都会部署一次;部署自动化,一切都要自动化,IaaS与PaaS解决I层与P层自动化部署,微服务有自动部署与运维工具,并实现Auto-Scaling;部署提供基础机制,为实现分布式部署要求,部署机制一般都有资源池化、服务的生命周期来看,部署服务 与服务注册是一体的; 部署的粒度:VM: 部署系统管理的VM的生命周期,如当前AC的iDeploy部署,把AC部署拆分为每个VM的安装、配置与启动;这种方式粒度粗,支撑不了微服务的部署(除非一个服务占用一个VM); App: 管理应用的生命周期及部署形态,生命周期分为部署、配置、启动、升级等,部署形态有主备、LB、Daemon等;Container: 相比于APP,容器有更好的隔离性和移植性;微服务:一般的微服务要么是APP,要么是Container,但AC就不是。受限于ONOS架构,我们的服务是一组feature;MS部署的解决方案:TOSCA: 云应用拓扑标准,一种描述云化部署的DSL,我司主推一个标准,PaaS的部署系统和MANO用的都是TOSCA;Kubernetes:Google开源的容器管理系统,提出了Pod/Service/Labels等概念,以ETCD为中心,PaaS基于K8S开发出了我司的云化部署平台;Mesosphere:DCOS,数据中心操作系统,基于mesos实现资源池化,有自身的编排工具;分布式LAB基于DCOS的思想做出了一套部署与集群管理系统(HASEN);微服务的划分微服务的划分主要是保证微服务功能内聚,职责单一。一般使用DDD(Domain Drive Design)的思想与方法对微服务进行划分,这种方法有点类似于数据库ER图的划分,不断分解数据,保证关系型数据库符合原子性、冗余性的范式要求。当然,微服务的划分比数据表划分更复杂,也没有微服务范式的概念,但思想是一致的。更多的内容,请参考《领域驱动设计》这本书。分布式一致性有两个大的思路:全局的分布式事务;事件驱动;分布式事务就是现在AC的思路,在设计开发中;事件驱动,忽略了事务的概念,由每个服务在应用层面保存服务的状态,服务之间的通信使用事件机制通知;此种方法可以保证微服务间的独立性,但把问题交给了服务的设计者;具体事件驱动的案例见参考材料;数据隔离问题微服务之间数据隔离可以保证服务的独立升级与部署,数据隔离有三个维度:数据表级隔离;数据表之间独立,没有外键关系;数据库级隔离;不同服务有不同的数据库;DBMS级隔离;不同服务有不同的数据库管理系统;一般做到数据库级隔离就可以了,服务之间的数据交换使用服务间接口。从单体到微服务微服务架构是一个衍生架构,都是从单体架构演化而来的。因为微服务架构本身的复杂性,初创系统出于快速开发、快速验证的考虑,很少在一开始就使用微服务架构。加之微服务的概念在这两年才火,大型单体应用也是看到了开发与维护的成本在不断增加,才会有转型微服务的动力。因此,如何从单体到微服务是一个普遍问题。从单体到微服务的原则:逐步演进,不要全部重构。全部重构,带来极大的成本和风险,系统会有很长的不稳定期。而且,最终的效果也不会很好,在设计时很难想到所有问题。微服务架构的演化思路应该是一步步铺基础设施,一点点拆分微服务。 DevOps与微服务架构DevOps是09年提出来的概念,但一直没有太火。直到14年,容器与微服务架构的提出,DevOps才得到了快速的发展。DevOps不单是一个实现自动化的工具链,而是组织、流程与技术的结合。组织上强调全栈团队、团队特性专一、团队自治;技术上打通开发与运维;流程上强调端到端、可视化、灰度升级、A/B测试等。对于DevOps,MS不是必须的,但MS为DevOps提供了最好的架构支撑,对于组织和流程的要求也是一致的。所以,也有人称MS是DevOps架构。
微服务注册表的典型实现: ETCD : 是一个高可用,分布式的,一致性的,键值表,用于共享配置和服务发现。两个著名案例包括Kubernetes和Cloud Foundry。 ZK: 是一个广泛使用,为分布式应用提供高性能整合的服务。Apache ZooKeeper最初是Hadoop的子项目,现在已经变成顶级项目。微服务架构的部署微服务架构对于部署的要求:部署速率,Amazon与NetFlix都有千个服务,每个服务都有持续部署的要求,Amazon的服务每秒都会部署一次;部署自动化,一切都要自动化,IaaS与PaaS解决I层与P层自动化部署,微服务有自动部署与运维工具,并实现Auto-Scaling;部署提供基础机制,为实现分布式部署要求,部署机制一般都有资源池化、服务的生命周期来看,部署服务 与服务注册是一体的; 部署的粒度:VM: 部署系统管理的VM的生命周期,如当前AC的iDeploy部署,把AC部署拆分为每个VM的安装、配置与启动;这种方式粒度粗,支撑不了微服务的部署(除非一个服务占用一个VM); App: 管理应用的生命周期及部署形态,生命周期分为部署、配置、启动、升级等,部署形态有主备、LB、Daemon等;Container: 相比于APP,容器有更好的隔离性和移植性;微服务:一般的微服务要么是APP,要么是Container,但AC就不是。受限于ONOS架构,我们的服务是一组feature;MS部署的解决方案:TOSCA: 云应用拓扑标准,一种描述云化部署的DSL,我司主推一个标准,PaaS的部署系统和MANO用的都是TOSCA;Kubernetes:Google开源的容器管理系统,提出了Pod/Service/Labels等概念,以ETCD为中心,PaaS基于K8S开发出了我司的云化部署平台;Mesosphere:DCOS,数据中心操作系统,基于mesos实现资源池化,有自身的编排工具;分布式LAB基于DCOS的思想做出了一套部署与集群管理系统(HASEN);微服务的划分微服务的划分主要是保证微服务功能内聚,职责单一。一般使用DDD(Domain Drive Design)的思想与方法对微服务进行划分,这种方法有点类似于数据库ER图的划分,不断分解数据,保证关系型数据库符合原子性、冗余性的范式要求。当然,微服务的划分比数据表划分更复杂,也没有微服务范式的概念,但思想是一致的。更多的内容,请参考《领域驱动设计》这本书。分布式一致性有两个大的思路:全局的分布式事务;事件驱动;分布式事务就是现在AC的思路,在设计开发中;事件驱动,忽略了事务的概念,由每个服务在应用层面保存服务的状态,服务之间的通信使用事件机制通知;此种方法可以保证微服务间的独立性,但把问题交给了服务的设计者;具体事件驱动的案例见参考材料;数据隔离问题微服务之间数据隔离可以保证服务的独立升级与部署,数据隔离有三个维度:数据表级隔离;数据表之间独立,没有外键关系;数据库级隔离;不同服务有不同的数据库;DBMS级隔离;不同服务有不同的数据库管理系统;一般做到数据库级隔离就可以了,服务之间的数据交换使用服务间接口。从单体到微服务微服务架构是一个衍生架构,都是从单体架构演化而来的。因为微服务架构本身的复杂性,初创系统出于快速开发、快速验证的考虑,很少在一开始就使用微服务架构。加之微服务的概念在这两年才火,大型单体应用也是看到了开发与维护的成本在不断增加,才会有转型微服务的动力。因此,如何从单体到微服务是一个普遍问题。从单体到微服务的原则:逐步演进,不要全部重构。全部重构,带来极大的成本和风险,系统会有很长的不稳定期。而且,最终的效果也不会很好,在设计时很难想到所有问题。微服务架构的演化思路应该是一步步铺基础设施,一点点拆分微服务。 DevOps与微服务架构DevOps是09年提出来的概念,但一直没有太火。直到14年,容器与微服务架构的提出,DevOps才得到了快速的发展。DevOps不单是一个实现自动化的工具链,而是组织、流程与技术的结合。组织上强调全栈团队、团队特性专一、团队自治;技术上打通开发与运维;流程上强调端到端、可视化、灰度升级、A/B测试等。对于DevOps,MS不是必须的,但MS为DevOps提供了最好的架构支撑,对于组织和流程的要求也是一致的。所以,也有人称MS是DevOps架构。 编辑于 2019-04-04赞同 20710 条评论分享收藏喜欢收起铁原数哲史,DDD,业务架构194 人赞同了该回答https://www.zhihu.com/question/366731124/answer/977346912上面答案各种名企、大师、名词乱飞,什么意思?为什么都不谈应用后的效果?毕竟用了也不是一天两天了比如51是国内最早做微服务的,为什么这么沉默,架构师出来走两步。华为可以说用了微服务以后,虽然我们IPD很慢,但是开发效率提升了3倍……阿里可以分享一下微服务后福报减少了多少…… 我观察业界这么多年,做微服务没几个好死的。据说马丁是微服务最初的提出者,但是我看了他的提法,狗屁不通。1, 微服务的起因是服务化普及以后带来的高开发成本、协作成本2, 但服务化本身是正确的,所以只能在降低成本、轻量级上做改进;而不是推翻。微服务的命名大概就是这么个初衷。3, 但独立部署比内部jar性能高?成本低?运维成本低?Restful比RPC性能高?成本低?运维成本低?拆分比合并成本低?效率高?这些全是增加成本的。他病看对了,药开错了。只有名字是对的,药方基本全错。尽管如此,我依然推崇微服务。不过不推荐大家去拥抱他——仅仅用,但是不要深入用,不要拥抱。比如框架换个皮,从以前框架换成微服务,你就能立即享受微服务的优势了。但是如果你进一步拥抱,拆分,独立部署。。。。。麻烦等着你呢(restful相对没那么重要,仅仅10%以内的性能消耗,并没有带来其他太大的弊病,但是带来了体系开放性——虽然99%的情况下没什么用。但是也凑合吧)本世纪初,IT圈面临的问题是信息化死局:上ERP是找死,不上是等死。为啥上了找死,不上等死?早期的信息化系统都是全家桶式的全套解决方案。比如买了个ERP挺合适,但是OA,财务什么的可能不合适。但是不能分开用,因为是封闭体系、不开放(闭环?)于是财务、OA什么的就得捏着鼻子用。业务不兼容?业务改造啊。。。。客户不接受?……这是找死。不上呢,你得想清楚了。未来的企业是不是还用算盘,容得下老古董。那是等死。SOA解决了这个问题。SOA在08年-10年左右开始大热、成熟。其中是走了一些“弯路”的。比如早起SOA方案疯狂推荐的时ESB,但今天ESB罕有人用。用的多数是拆分+RPC(dubbo等)这种P2PRPC的方案。这个“弯路”加引号是因为今天再去审视dubbo/springcloud等这些P2PRC的SOA架构普及以后,发现了很多问题,比如服务粒度细、体系架构复杂、开发效率低、服务治理难,监控维护难等……需要一大堆基础设施建设或者说擦屁股方案打补丁。这么看起来,ESB看起来更优秀,只不过门槛高,但是和那一大堆擦屁股方案比起来,他简单到极致了。P2PRPC才是弯路啊。其实这种弯路,OSGI(支付宝要不要给我点个赞,顺便把你们的弯路分享一下,还有你们在DDD上的“成就”),RIA,RCP,WEBSERVICE一样都走过。我们今天的微服务、中台一样正在走这个弯路。回顾所有这些曲折的话,你会发现并不一定道路是曲折的,前途是光明的。比如有些就一路曲折到火葬场。但是,对一个人成长最大的其实是弯路。走弯路之前你想了什么?是不是狐狸精勾引你了?还是你有什么心魔?你为什么做了这个选择 ?其中关键的要素是什么?我们漏掉了什么?自己还有哪些缺点?我们对现实世界的规律有没有多一点认识?以后怎么改进?所以其实相比现在业界各种效果不确定的所谓技术盛宴营销,我其实更想听他们走了啥弯路,开心开心,也更有收获一点。我在某宝的时候,就发现有个规律,内部最核心的最有用的技术架构和思想,从来不分享。外界几乎一个字都搜索不到,那些没什么用,但是看起来特别难,特别高大上的,分享的特别欢乐。外面趋之若鹜。这其实是一种很委婉的劝降行为:嗨,这事太难了,你不行,赶紧投降吧。我很牛逼的,都用我的。当然,绝大多数人都不会投降,但是的确会认可某里技术牛逼的现实。并且上进的人会追求进步,然后走了弯路。不过人家并没有说谎啊。所以,现在技术圈的文章,技术上看一半,信只能信1/4;还得多琢磨琢磨技术以外的因素。只是 看看,寻个思路,想还是要自己想,以自己为主。微服务、中台等,一样的 古人说圣人不止,大盗不止;原理就是大家推崇什么,就坏人一定就伪装什么,推崇的越厉害,坏人就越具有破坏性。技术这词,现在就这意思。现代人说:钱多的地方是非多。IT圈就能例外?每个人脸上写着他是天生的技术人?技术是纯粹的,但是技术后面的人是不纯粹的。技术不会自己张嘴说话。 编辑于 2020-01-18赞同 19414 条评论分享收藏喜欢收起小鹅通广告不感兴趣知乎广告介绍当下竞争风口,你的在线课堂如何在众多中脱颖而出?停课不停学!小鹅通为您打造专属在线课堂,支持大班课、小班课、公开课、1V1、1VN、免费试用7天,快来领取体验吧!查看详情技能树IT修真院已认证的官方帐号12 人赞同了该回答【什么是微服务? 】
编辑于 2019-04-04赞同 20710 条评论分享收藏喜欢收起铁原数哲史,DDD,业务架构194 人赞同了该回答https://www.zhihu.com/question/366731124/answer/977346912上面答案各种名企、大师、名词乱飞,什么意思?为什么都不谈应用后的效果?毕竟用了也不是一天两天了比如51是国内最早做微服务的,为什么这么沉默,架构师出来走两步。华为可以说用了微服务以后,虽然我们IPD很慢,但是开发效率提升了3倍……阿里可以分享一下微服务后福报减少了多少…… 我观察业界这么多年,做微服务没几个好死的。据说马丁是微服务最初的提出者,但是我看了他的提法,狗屁不通。1, 微服务的起因是服务化普及以后带来的高开发成本、协作成本2, 但服务化本身是正确的,所以只能在降低成本、轻量级上做改进;而不是推翻。微服务的命名大概就是这么个初衷。3, 但独立部署比内部jar性能高?成本低?运维成本低?Restful比RPC性能高?成本低?运维成本低?拆分比合并成本低?效率高?这些全是增加成本的。他病看对了,药开错了。只有名字是对的,药方基本全错。尽管如此,我依然推崇微服务。不过不推荐大家去拥抱他——仅仅用,但是不要深入用,不要拥抱。比如框架换个皮,从以前框架换成微服务,你就能立即享受微服务的优势了。但是如果你进一步拥抱,拆分,独立部署。。。。。麻烦等着你呢(restful相对没那么重要,仅仅10%以内的性能消耗,并没有带来其他太大的弊病,但是带来了体系开放性——虽然99%的情况下没什么用。但是也凑合吧)本世纪初,IT圈面临的问题是信息化死局:上ERP是找死,不上是等死。为啥上了找死,不上等死?早期的信息化系统都是全家桶式的全套解决方案。比如买了个ERP挺合适,但是OA,财务什么的可能不合适。但是不能分开用,因为是封闭体系、不开放(闭环?)于是财务、OA什么的就得捏着鼻子用。业务不兼容?业务改造啊。。。。客户不接受?……这是找死。不上呢,你得想清楚了。未来的企业是不是还用算盘,容得下老古董。那是等死。SOA解决了这个问题。SOA在08年-10年左右开始大热、成熟。其中是走了一些“弯路”的。比如早起SOA方案疯狂推荐的时ESB,但今天ESB罕有人用。用的多数是拆分+RPC(dubbo等)这种P2PRPC的方案。这个“弯路”加引号是因为今天再去审视dubbo/springcloud等这些P2PRC的SOA架构普及以后,发现了很多问题,比如服务粒度细、体系架构复杂、开发效率低、服务治理难,监控维护难等……需要一大堆基础设施建设或者说擦屁股方案打补丁。这么看起来,ESB看起来更优秀,只不过门槛高,但是和那一大堆擦屁股方案比起来,他简单到极致了。P2PRPC才是弯路啊。其实这种弯路,OSGI(支付宝要不要给我点个赞,顺便把你们的弯路分享一下,还有你们在DDD上的“成就”),RIA,RCP,WEBSERVICE一样都走过。我们今天的微服务、中台一样正在走这个弯路。回顾所有这些曲折的话,你会发现并不一定道路是曲折的,前途是光明的。比如有些就一路曲折到火葬场。但是,对一个人成长最大的其实是弯路。走弯路之前你想了什么?是不是狐狸精勾引你了?还是你有什么心魔?你为什么做了这个选择 ?其中关键的要素是什么?我们漏掉了什么?自己还有哪些缺点?我们对现实世界的规律有没有多一点认识?以后怎么改进?所以其实相比现在业界各种效果不确定的所谓技术盛宴营销,我其实更想听他们走了啥弯路,开心开心,也更有收获一点。我在某宝的时候,就发现有个规律,内部最核心的最有用的技术架构和思想,从来不分享。外界几乎一个字都搜索不到,那些没什么用,但是看起来特别难,特别高大上的,分享的特别欢乐。外面趋之若鹜。这其实是一种很委婉的劝降行为:嗨,这事太难了,你不行,赶紧投降吧。我很牛逼的,都用我的。当然,绝大多数人都不会投降,但是的确会认可某里技术牛逼的现实。并且上进的人会追求进步,然后走了弯路。不过人家并没有说谎啊。所以,现在技术圈的文章,技术上看一半,信只能信1/4;还得多琢磨琢磨技术以外的因素。只是 看看,寻个思路,想还是要自己想,以自己为主。微服务、中台等,一样的 古人说圣人不止,大盗不止;原理就是大家推崇什么,就坏人一定就伪装什么,推崇的越厉害,坏人就越具有破坏性。技术这词,现在就这意思。现代人说:钱多的地方是非多。IT圈就能例外?每个人脸上写着他是天生的技术人?技术是纯粹的,但是技术后面的人是不纯粹的。技术不会自己张嘴说话。 编辑于 2020-01-18赞同 19414 条评论分享收藏喜欢收起小鹅通广告不感兴趣知乎广告介绍当下竞争风口,你的在线课堂如何在众多中脱颖而出?停课不停学!小鹅通为您打造专属在线课堂,支持大班课、小班课、公开课、1V1、1VN、免费试用7天,快来领取体验吧!查看详情技能树IT修真院已认证的官方帐号12 人赞同了该回答【什么是微服务? 】 一、背景介绍:传统的it架构的缺陷:使用传统的整体式架构(Monolithic Architecture)应用开发系统,如CRM、ERP等大型应用,随着新需求的不断增加,企业更新和修复大型整体式应用变得越来越困难;随着移动互联网的发展,企业被迫将其应用迁移至现代化UI界面架构以便能兼容移动设备,这要求企业能实现应用功能的快速上线;许多企业在SOA投资中得到的回报有限,SOA可以通过标准化服务接口实现能力的重用,但对于快速变化的需求,受到整体式应用的限制,有时候显得力不从心;二、什么是微服务?微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。可以在“自己的程序”中运行,并通过“轻量级设备与HTTP型API进行沟通”。关键在于该服务可以在自己的程序中运行。通过这一点我们就可以将服务公开与微服务架构(在现有系统中分布一个API)区分开来。在服务公开中,许多服务都可以被内部独立进程所限制。如果其中任何一个服务需要增加某种功能,那么就必须缩小进程范围。在微服务架构中,只需要在特定的某种服务中增加所需功能,而不影响整体进程。三、微服务中的spring-cloudSpring Cloud是一个相对比较新的微服务框架,2016n年推出1.0的release版本. 虽然Spring Cloud时间最短, 但是相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案。Spring Cloud 为开发者提供了在分布式系统(配置管理,服务发现,熔断,路由,微代理,控制总线,一次性token,全居琐,leader选举,分布式session,集群状态)中快速构建的工具,使用Spring Cloud的开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。三、什么是Eureak?Eureak的结构特点1. 是纯正的 servlet 应用,需构建成war包部署2. 使用了 Jersey 框架实现自身的 RESTful HTTP接口3. peer之间的同步与服务的注册全部通过 HTTP 协议实现4. 定时任务(发送心跳、定时清理过期服务、节点同步等)通过 JDK 自带的 Timer 实现5. 内存缓存使用Google的guava包实现四、实战
一、背景介绍:传统的it架构的缺陷:使用传统的整体式架构(Monolithic Architecture)应用开发系统,如CRM、ERP等大型应用,随着新需求的不断增加,企业更新和修复大型整体式应用变得越来越困难;随着移动互联网的发展,企业被迫将其应用迁移至现代化UI界面架构以便能兼容移动设备,这要求企业能实现应用功能的快速上线;许多企业在SOA投资中得到的回报有限,SOA可以通过标准化服务接口实现能力的重用,但对于快速变化的需求,受到整体式应用的限制,有时候显得力不从心;二、什么是微服务?微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。可以在“自己的程序”中运行,并通过“轻量级设备与HTTP型API进行沟通”。关键在于该服务可以在自己的程序中运行。通过这一点我们就可以将服务公开与微服务架构(在现有系统中分布一个API)区分开来。在服务公开中,许多服务都可以被内部独立进程所限制。如果其中任何一个服务需要增加某种功能,那么就必须缩小进程范围。在微服务架构中,只需要在特定的某种服务中增加所需功能,而不影响整体进程。三、微服务中的spring-cloudSpring Cloud是一个相对比较新的微服务框架,2016n年推出1.0的release版本. 虽然Spring Cloud时间最短, 但是相比Dubbo等RPC框架, Spring Cloud提供的全套的分布式系统解决方案。Spring Cloud 为开发者提供了在分布式系统(配置管理,服务发现,熔断,路由,微代理,控制总线,一次性token,全居琐,leader选举,分布式session,集群状态)中快速构建的工具,使用Spring Cloud的开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。三、什么是Eureak?Eureak的结构特点1. 是纯正的 servlet 应用,需构建成war包部署2. 使用了 Jersey 框架实现自身的 RESTful HTTP接口3. peer之间的同步与服务的注册全部通过 HTTP 协议实现4. 定时任务(发送心跳、定时清理过期服务、节点同步等)通过 JDK 自带的 Timer 实现5. 内存缓存使用Google的guava包实现四、实战 项目结构如下
项目结构如下 首先创建moduel
首先创建moduel moudel里面创建服务:
moudel里面创建服务: 配置application.yml完成运行DemoApplication启动服务结果如图:
配置application.yml完成运行DemoApplication启动服务结果如图: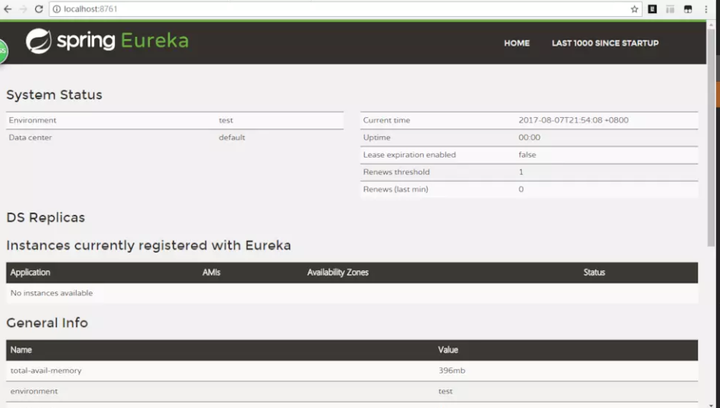 界面如下,Application为空说明没有注册service。接下来我们编写service-client同样创建model
界面如下,Application为空说明没有注册service。接下来我们编写service-client同样创建model 编写配置文件:
编写配置文件: 使用简单controller编写,告诉这个是Client端
使用简单controller编写,告诉这个是Client端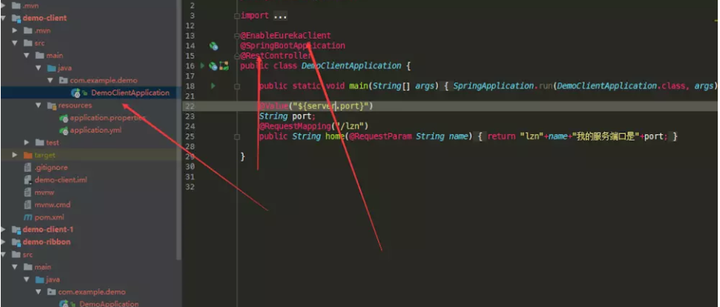 启动服务
启动服务 启动成功界面如图:查看我们的server:这里已经注册了我们的服务。说明服务的注册与获取成功了。接下来使用ribbon+restTemplate实现负载均衡:复制一个client,然后修改端口。方便等会测试负载均衡创建moduel-ribbon结构如上首先配置application.yml然后在application里面加载实现负载均衡的RestTemplate编写service和controller实现调用负载均衡完成编写,启动8632的service,启动ribbon,使用http:localhost:8634/lzn?name=lzn调用,刷新发现结果为8632、8633端口服务调用平均。这只是一个简单Eureka的调用。cloud有很多我们需要的可以学习的服务。更多内容,可以加入IT交流群565763832与大家一起讨论交流这里是技能树·IT修真院:https://www.jnshu.com,初学者转行到互联网的聚集地--------------------- 编辑于 2019-04-10赞同 12添加评论分享收藏喜欢收起蛙课网已认证的官方帐号36 人赞同了该回答如果你懂或者不理解,希望你看到这篇文章之后就能搞懂。以下:正文看到最近“微服务架构”这个概念这么火,作为一个积极上进的程序猿,成小胖忍不住想要学习学习。而架构师老王(不是隔壁老王)最近刚好在做公司基础服务的微服务化研究和落地,对此深有研究。于是成小胖马上屁颠屁颠的跑过去向老王请教:“王哥,我看微服务架构这么火,我也想学,您给我讲讲啥是微服务架构呗?”老王笑了笑说:“要想知道什么是微服务架构,你得先知道什么系统架构设计。”成小胖的理想是成为一名架构师,平时积累了不少知识,因此对“系统架构设计”这个概念还是很熟悉的,因此他马上就给出了答案【1】:系统架构设计描述了在应用系统的内部,如何根据业务、技术、组织、灵活性、可扩展性以及可维护性等多种因素,将应用系统划分成不同的部分,并使这些部分彼此之间相互分工、相互协作,从而为用户提供某种特定的价值的方式。老王满意的点点头,继续问:“你看最近我在做微服务的研究和落地,你知道为什么要做这个事情吗?”“因为目前的三层架构存在很多弊端,不满足业务发展的需求了呗。”“对的,我看你对公司目前的架构也非常熟悉了,你来仔细说说现在的三层架构吧。”于是成小胖拿了一张A4纸,图文并茂地给老王讲了他对三层架构的理解:三层架构是指在业务和技术的发展过程中,系统中不同职责的部分被定义在不同的层次,每一层负责的功能更加具体化。三层架构通常包括表示层、业务逻辑层和数据访问层,层与层之间互相连接、互相协作,构成一个整体,并且层的内部可以被替换成其他可以工作的部分,但对整体的影响不大。以 Web 应用程序为例,早期是将所有的表示逻辑、业务逻辑和数据访问逻辑放在一起,这就是一层架构。后来随着 java、.NET 等高级语言的发展,提供了越来越方便的数据访问机制,如 java 的 JDBC 和 .NET 的 http://ADO.NET。这时数据访问部分被分离开来,形成了二层架构。再后来,随着面向对象设计、企业架构模式等理念的不断发展,表示逻辑和业务逻辑也被分离开来,形成了现在的三层架构
启动成功界面如图:查看我们的server:这里已经注册了我们的服务。说明服务的注册与获取成功了。接下来使用ribbon+restTemplate实现负载均衡:复制一个client,然后修改端口。方便等会测试负载均衡创建moduel-ribbon结构如上首先配置application.yml然后在application里面加载实现负载均衡的RestTemplate编写service和controller实现调用负载均衡完成编写,启动8632的service,启动ribbon,使用http:localhost:8634/lzn?name=lzn调用,刷新发现结果为8632、8633端口服务调用平均。这只是一个简单Eureka的调用。cloud有很多我们需要的可以学习的服务。更多内容,可以加入IT交流群565763832与大家一起讨论交流这里是技能树·IT修真院:https://www.jnshu.com,初学者转行到互联网的聚集地--------------------- 编辑于 2019-04-10赞同 12添加评论分享收藏喜欢收起蛙课网已认证的官方帐号36 人赞同了该回答如果你懂或者不理解,希望你看到这篇文章之后就能搞懂。以下:正文看到最近“微服务架构”这个概念这么火,作为一个积极上进的程序猿,成小胖忍不住想要学习学习。而架构师老王(不是隔壁老王)最近刚好在做公司基础服务的微服务化研究和落地,对此深有研究。于是成小胖马上屁颠屁颠的跑过去向老王请教:“王哥,我看微服务架构这么火,我也想学,您给我讲讲啥是微服务架构呗?”老王笑了笑说:“要想知道什么是微服务架构,你得先知道什么系统架构设计。”成小胖的理想是成为一名架构师,平时积累了不少知识,因此对“系统架构设计”这个概念还是很熟悉的,因此他马上就给出了答案【1】:系统架构设计描述了在应用系统的内部,如何根据业务、技术、组织、灵活性、可扩展性以及可维护性等多种因素,将应用系统划分成不同的部分,并使这些部分彼此之间相互分工、相互协作,从而为用户提供某种特定的价值的方式。老王满意的点点头,继续问:“你看最近我在做微服务的研究和落地,你知道为什么要做这个事情吗?”“因为目前的三层架构存在很多弊端,不满足业务发展的需求了呗。”“对的,我看你对公司目前的架构也非常熟悉了,你来仔细说说现在的三层架构吧。”于是成小胖拿了一张A4纸,图文并茂地给老王讲了他对三层架构的理解:三层架构是指在业务和技术的发展过程中,系统中不同职责的部分被定义在不同的层次,每一层负责的功能更加具体化。三层架构通常包括表示层、业务逻辑层和数据访问层,层与层之间互相连接、互相协作,构成一个整体,并且层的内部可以被替换成其他可以工作的部分,但对整体的影响不大。以 Web 应用程序为例,早期是将所有的表示逻辑、业务逻辑和数据访问逻辑放在一起,这就是一层架构。后来随着 java、.NET 等高级语言的发展,提供了越来越方便的数据访问机制,如 java 的 JDBC 和 .NET 的 http://ADO.NET。这时数据访问部分被分离开来,形成了二层架构。再后来,随着面向对象设计、企业架构模式等理念的不断发展,表示逻辑和业务逻辑也被分离开来,形成了现在的三层架构 三层架构的具体内容如下:表示层: 用户使用应用程序时,看到的、听见的、输入的或者交互的部分。业务逻辑层: 根据用户输入的信息,进行逻辑计算或者业务处理的部分。数据访问层: 关注有效地操作原始数据的部分,如将数据存储到存储介质(如数据库、文件系统)及从存储介质中读取数据等。老王对这个解释非常满意,作了进一步的补充:“你看虽然现在程序被分成了三层,但只是逻辑上的分层,并不是物理上的分层。也就是说,对不同层的代码而言,经过编译、打包和部署后,所有的代码最终还是运行在同一个进程中。而这,就是所谓的单块架构。”成小胖挠了挠头:“原来单块架构是这个意思啊~~”“嗯。根据你的实际工作经验,你再总结下单块架构的优缺点吧。”平时勤于总结的成小胖很快便列出了单块架构的优缺点: 优点:易于开发: 开发方式简单,IDE 支持好,方便运行和调试。易于测试: 所有功能运行在一个进程中,一旦进程启动,便可以进行系统测试。易于部署: 只需要将打好的一个软件包发布到服务器即可。易于水平伸缩: 只需要创建一个服务器节点,配置好运行时环境,再将软件包发布到新服务器节点即可运行程序(当然也需要采取分发策略保证请求能有效地分发到新节点)。缺点:维护成本大: 当应用程序的功能越来越多、团队越来越大时,沟通成本、管理成本显著增加。当出现 bug 时,可能引起 bug 的原因组合越来越多,导致分析、定位和修复的成本增加;并且在对全局功能缺乏深度理解的情况下,容易在修复 bug 时引入新的 bug。持续交付周期长: 构建和部署时间会随着功能的增多而增加,任何细微的修改都会触发部署流水线。新人培养周期长: 新成员了解背景、熟悉业务和配置环境的时间越来越长。技术选型成本高: 单块架构倾向于采用统一的技术平台或方案来解决所有问题,如果后续想引入新的技术或框架,成本和风险都很大。可扩展性差: 随着功能的增加,垂直扩展的成本将会越来越大;而对于水平扩展而言,因为所有代码都运行在同一个进程,没办法做到针对应用程序的部分功能做独立的扩展。老王拍了拍成小胖的肩膀,眼睛眯成了一条缝:“小伙子总结的很不错!既然你已经对目前的单块架构的优缺点有了很好的理解,那现在咱们就可以开始来学习微服务架构了。”老王先从网上搜索“微服务架构”关键字,出来这么一段话:微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务于服务间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的 RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。成小胖看完了这段话,说:“看着有点晕,云里雾里的感觉……”老王嘿嘿一笑:“莫慌,现在就给你详细讲讲微服务架构的特性。” 1. 单一职责微服务架构中的每个服务,都是具有业务逻辑的,符合高内聚、低耦合原则以及单一职责原则的单元,不同的服务通过“管道”的方式灵活组合,从而构建出庞大的系统。2. 轻量级通信服务之间通过轻量级的通信机制实现互通互联,而所谓的轻量级,通常指语言无关、平台无关的交互方式。
三层架构的具体内容如下:表示层: 用户使用应用程序时,看到的、听见的、输入的或者交互的部分。业务逻辑层: 根据用户输入的信息,进行逻辑计算或者业务处理的部分。数据访问层: 关注有效地操作原始数据的部分,如将数据存储到存储介质(如数据库、文件系统)及从存储介质中读取数据等。老王对这个解释非常满意,作了进一步的补充:“你看虽然现在程序被分成了三层,但只是逻辑上的分层,并不是物理上的分层。也就是说,对不同层的代码而言,经过编译、打包和部署后,所有的代码最终还是运行在同一个进程中。而这,就是所谓的单块架构。”成小胖挠了挠头:“原来单块架构是这个意思啊~~”“嗯。根据你的实际工作经验,你再总结下单块架构的优缺点吧。”平时勤于总结的成小胖很快便列出了单块架构的优缺点: 优点:易于开发: 开发方式简单,IDE 支持好,方便运行和调试。易于测试: 所有功能运行在一个进程中,一旦进程启动,便可以进行系统测试。易于部署: 只需要将打好的一个软件包发布到服务器即可。易于水平伸缩: 只需要创建一个服务器节点,配置好运行时环境,再将软件包发布到新服务器节点即可运行程序(当然也需要采取分发策略保证请求能有效地分发到新节点)。缺点:维护成本大: 当应用程序的功能越来越多、团队越来越大时,沟通成本、管理成本显著增加。当出现 bug 时,可能引起 bug 的原因组合越来越多,导致分析、定位和修复的成本增加;并且在对全局功能缺乏深度理解的情况下,容易在修复 bug 时引入新的 bug。持续交付周期长: 构建和部署时间会随着功能的增多而增加,任何细微的修改都会触发部署流水线。新人培养周期长: 新成员了解背景、熟悉业务和配置环境的时间越来越长。技术选型成本高: 单块架构倾向于采用统一的技术平台或方案来解决所有问题,如果后续想引入新的技术或框架,成本和风险都很大。可扩展性差: 随着功能的增加,垂直扩展的成本将会越来越大;而对于水平扩展而言,因为所有代码都运行在同一个进程,没办法做到针对应用程序的部分功能做独立的扩展。老王拍了拍成小胖的肩膀,眼睛眯成了一条缝:“小伙子总结的很不错!既然你已经对目前的单块架构的优缺点有了很好的理解,那现在咱们就可以开始来学习微服务架构了。”老王先从网上搜索“微服务架构”关键字,出来这么一段话:微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务于服务间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的 RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。成小胖看完了这段话,说:“看着有点晕,云里雾里的感觉……”老王嘿嘿一笑:“莫慌,现在就给你详细讲讲微服务架构的特性。” 1. 单一职责微服务架构中的每个服务,都是具有业务逻辑的,符合高内聚、低耦合原则以及单一职责原则的单元,不同的服务通过“管道”的方式灵活组合,从而构建出庞大的系统。2. 轻量级通信服务之间通过轻量级的通信机制实现互通互联,而所谓的轻量级,通常指语言无关、平台无关的交互方式。 对于轻量级通信的格式而言,我们熟悉的 XML 和 JSON,它们是语言无关、平台无关的;对于通信的协议而言,通常基于 HTTP,能让服务间的通信变得标准化、无状态化。目前大家熟悉的 REST(Representational State Transfer)是实现服务间互相协作的轻量级通信机制之一。使用轻量级通信机制,可以让团队选择更适合的语言、工具或者平台来开发服务本身。3. 独立性每个服务在应用交付过程中,独立地开发、测试和部署。在单块架构中所有功能都在同一个代码库,功能的开发不具有独立性;当不同小组完成多个功能后,需要经过集成和回归测试,测试过程也不具有独立性;当测试完成后,应用被构建成一个包,如果某个功能存在 bug,将导致整个部署失败或者回滚。
对于轻量级通信的格式而言,我们熟悉的 XML 和 JSON,它们是语言无关、平台无关的;对于通信的协议而言,通常基于 HTTP,能让服务间的通信变得标准化、无状态化。目前大家熟悉的 REST(Representational State Transfer)是实现服务间互相协作的轻量级通信机制之一。使用轻量级通信机制,可以让团队选择更适合的语言、工具或者平台来开发服务本身。3. 独立性每个服务在应用交付过程中,独立地开发、测试和部署。在单块架构中所有功能都在同一个代码库,功能的开发不具有独立性;当不同小组完成多个功能后,需要经过集成和回归测试,测试过程也不具有独立性;当测试完成后,应用被构建成一个包,如果某个功能存在 bug,将导致整个部署失败或者回滚。 在微服务架构中,每个服务都是独立的业务单元,与其他服务高度解耦,只需要改变当前服务本身,就可以完成独立的开发、测试和部署。
在微服务架构中,每个服务都是独立的业务单元,与其他服务高度解耦,只需要改变当前服务本身,就可以完成独立的开发、测试和部署。 4. 进程隔离单块架构中,整个系统运行在同一个进程中,当应用进行部署时,必须停掉当前正在运行的应用,部署完成后再重启进程,无法做到独立部署。有时候我们会将重复的代码抽取出来封装成组件,在单块架构中,组件通常的形态叫做共享库(如 jar 包或者 DLL),但是当程序运行时,所有组件最终也会被加载到同一进程中运行。
4. 进程隔离单块架构中,整个系统运行在同一个进程中,当应用进行部署时,必须停掉当前正在运行的应用,部署完成后再重启进程,无法做到独立部署。有时候我们会将重复的代码抽取出来封装成组件,在单块架构中,组件通常的形态叫做共享库(如 jar 包或者 DLL),但是当程序运行时,所有组件最终也会被加载到同一进程中运行。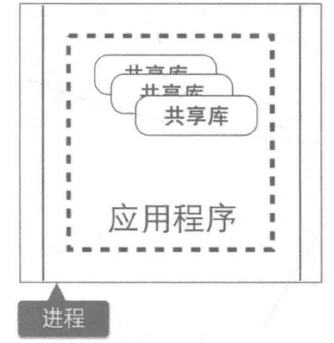 在微服务架构中,应用程序由多个服务组成,每个服务都是高度自治的独立业务实体,可以运行在独立的进程中,不同的服务能非常容易地部署到不同的主机上。
在微服务架构中,应用程序由多个服务组成,每个服务都是高度自治的独立业务实体,可以运行在独立的进程中,不同的服务能非常容易地部署到不同的主机上。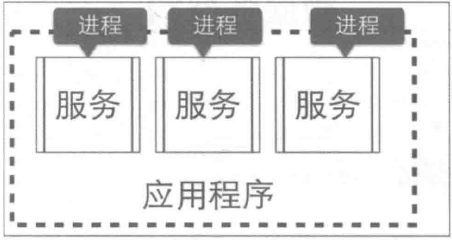 理论上所有服务可以部署在同一个服务器节点,但是并不推荐这么做,因为微服务架构的主旨就是高度自治和高度隔离。“王哥你真厉害,您这么一说我的思维清晰了很多!”成小胖激动的几乎要叫起来。“我之前了解过 SOA,好像跟微服务架构的思想很像啊,您能帮我区分一下吗?”成小胖追问到。老王嘿嘿一笑,拿起成小胖手上的A4纸,翻到另外一面画了个表格:
理论上所有服务可以部署在同一个服务器节点,但是并不推荐这么做,因为微服务架构的主旨就是高度自治和高度隔离。“王哥你真厉害,您这么一说我的思维清晰了很多!”成小胖激动的几乎要叫起来。“我之前了解过 SOA,好像跟微服务架构的思想很像啊,您能帮我区分一下吗?”成小胖追问到。老王嘿嘿一笑,拿起成小胖手上的A4纸,翻到另外一面画了个表格: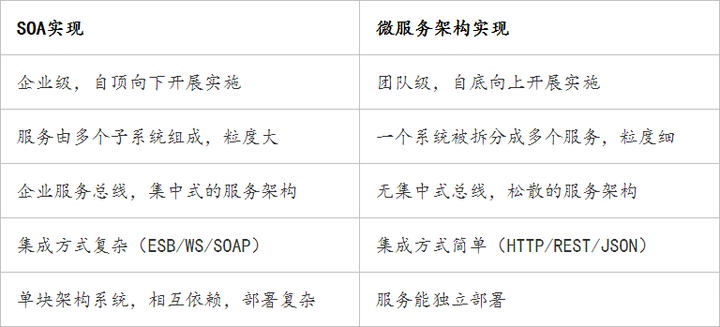 接着老王又画了一张图:
接着老王又画了一张图: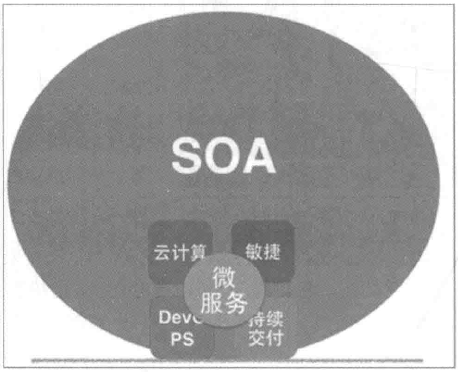 成小胖看了之后说:“您这么一画我倒是大概明白了,但是图里面的 DevOps 这个概念我不懂诶……”“这个 DevOps 就说来话长了,有时间你自己先去查查资料了解下吧。”“好的。现在我对微服务架构的概念有了了解,您能再深入剖析下它的本质吗?”“好,你可仔细听好了哈!” 1. 服务作为组件微服务也可以被认为是一种组件,但是跟传统组件的区别在于它可以独立部署,因此它的一个显著的优势。另外一个优点是,它在组件与组件之间定义了清晰的、语言无关、平台无关的规范接口,耦合度低,灵活性非常高。但它的不足之处是,分布式调用严重依赖于网络的可靠性和稳定性。2. 围绕业务组织团队在单块架构中,企业一般会根据技能划分团队,在这种组织架构下,即便是简单的需求变更都有可能需要跨团队协作,沟通成本很高。而在微服务架构中,它提倡以业务为核心,按照业务能力来组织团队,团队中的成员具有多样性的技能。3. 关注产品而非项目在单块架构中,应用基本上是基于“项目模式”构建的,即项目启动时从不同技能资源池中抽取相关资源组成团队,项目结束后释放所有资源。这种情况下团队成员缺乏主人翁意识和产品成就感。
成小胖看了之后说:“您这么一画我倒是大概明白了,但是图里面的 DevOps 这个概念我不懂诶……”“这个 DevOps 就说来话长了,有时间你自己先去查查资料了解下吧。”“好的。现在我对微服务架构的概念有了了解,您能再深入剖析下它的本质吗?”“好,你可仔细听好了哈!” 1. 服务作为组件微服务也可以被认为是一种组件,但是跟传统组件的区别在于它可以独立部署,因此它的一个显著的优势。另外一个优点是,它在组件与组件之间定义了清晰的、语言无关、平台无关的规范接口,耦合度低,灵活性非常高。但它的不足之处是,分布式调用严重依赖于网络的可靠性和稳定性。2. 围绕业务组织团队在单块架构中,企业一般会根据技能划分团队,在这种组织架构下,即便是简单的需求变更都有可能需要跨团队协作,沟通成本很高。而在微服务架构中,它提倡以业务为核心,按照业务能力来组织团队,团队中的成员具有多样性的技能。3. 关注产品而非项目在单块架构中,应用基本上是基于“项目模式”构建的,即项目启动时从不同技能资源池中抽取相关资源组成团队,项目结束后释放所有资源。这种情况下团队成员缺乏主人翁意识和产品成就感。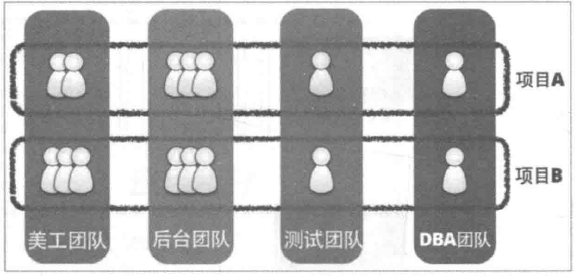 在微服务架构中,提倡采用“产品模式”构建,即更倾向于让团队负责整个服务的生命周期,以便提供更优质的服务。
在微服务架构中,提倡采用“产品模式”构建,即更倾向于让团队负责整个服务的生命周期,以便提供更优质的服务。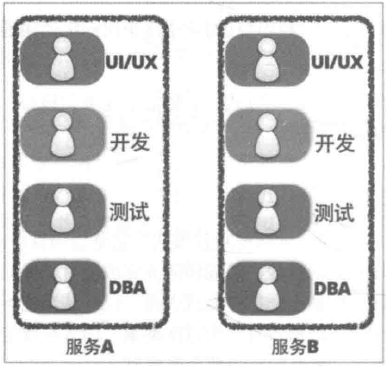 4. 技术多样性微服务架构中,提倡针对不同的业务特征选择合适的技术方案,有针对性的解决具体业务问题,而不是像单块架构中采用统一的平台或技术来解决所有问题。5. 业务数据独立微服务架构提供自主管理其相关的业务数据,这样可以随着业务的发展提供数据接口集成,而不是以数据库的方式同其他服务集成。另外,随着业务的发展,可以方便地选择更合的工具管理或者迁移业务数据。
4. 技术多样性微服务架构中,提倡针对不同的业务特征选择合适的技术方案,有针对性的解决具体业务问题,而不是像单块架构中采用统一的平台或技术来解决所有问题。5. 业务数据独立微服务架构提供自主管理其相关的业务数据,这样可以随着业务的发展提供数据接口集成,而不是以数据库的方式同其他服务集成。另外,随着业务的发展,可以方便地选择更合的工具管理或者迁移业务数据。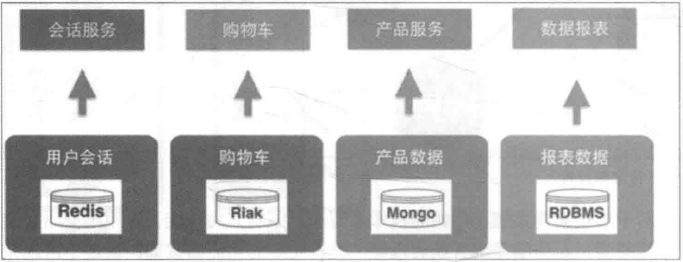 6. 基础设施自动化在微服务架构的实践过程中,对持续交付和部署流水线的要求很高,将促进企业不断寻找更高效的方式完成基础设施的自动化及 DevOps 运维能力的提升。听完成小胖忍不住表达了敬佩之意:“老司机就是老司机,噢说错了……架构师就是架构师,总结得这么简洁又深刻!”“咳咳,低调低调……”“听您讲解了这么多,我觉得微服务架构解决了很多当前三层架构的痛点。不过我觉得没有任何一项技术或架构是完美的。”“非常正确。进行微服务架构的落地是存在很多挑战的。” 1. 分布式系统的复杂性微服务架构是基于分布式的系统,而构建分布式系统必然会带来额外的开销。性能: 分布式系统是跨进程、跨网络的调用,受网络延迟和带宽的影响。可靠性: 由于高度依赖于网络状况,任何一次的远程调用都有可能失败,随着服务的增多还会出现更多的潜在故障点。因此,如何提高系统的可靠性、降低因网络引起的故障率,是系统构建的一大挑战。异步: 异步通信大大增加了功能实现的复杂度,并且伴随着定位难、调试难等问题。数据一致性: 要保证分布式系统的数据强一致性,成本是非常高的,需要在 C(一致性)A(可用性)P(分区容错性) 三者之间做出权衡。2. 运维成本运维主要包括配置、部署、监控与告警和日志收集四大方面。微服务架构中,每个服务都需要独立地配置、部署、监控和收集日志,成本呈指数级增长。3. 自动化部署在微服务架构中,每个服务都独立部署,交付周期短且频率高,人工部署已经无法适应业务的快速变化。因此如何有效地构建自动化部署体系,是微服务面临的另一个挑战。4. DevOps 与组织架构在微服务架构的实施过程中,开发人员和运维人员的角色发生了变化,开发者将承担起整个服务的生命周期的责任,包括部署和监控;而运维则更倾向于顾问式的角色,尽早考虑服务如何部署。因此,按需调整组织架构、构建全功能的团队,也是一个不小的挑战。5. 服务间的依赖测试单块架构中,通常使用集成测试来验证依赖是否正常。而在微服务架构中,服务数量众多,每个服务都是独立的业务单元,服务主要通过接口进行交互,如何保证依赖的正常,是测试面临的主要挑战。6. 服务间的依赖管理微服务架构中,服务数量众多,如何清晰有效地展示服务间的依赖关系也是个不小的挑战。“微服务的落地需要经过全面的考察和完善的试验,并不是每个场景都适合使用微服务架构,也不是每个企业都有能力或者精力去面对这些挑战。”老王最后语重心长的说。“嗯嗯,每件事都有两面性,最合适的才是最好的!对了王哥,您已经给我上完理论课了,啥时候带我实践下呗?”“你先好好消化完今天讲的这些,下次再说吧……”“好吧,很期待我们的下一次交流……”来源:博客园作者:cyfonly原文:https://www.cnblogs.com/cyfonly/p/6251944.html 发布于 2019-07-05赞同 361 条评论分享收藏喜欢收起李遥A Programmer12 人赞同了该回答如果你觉得函数调用实在太可靠了以至于无聊,那么可以采用微服务调用来找点刺激,多棒!编辑于 2018-07-28赞同 124 条评论分享收藏喜欢东方翌职猿,让IT面试更简单 www.jobyuan.com51 人赞同了该回答一、全面了解微服务a : 4个典型特点1.单个服务尽量专注一件事情,高内聚、低耦合;2.进程隔离;3.每个服务可以独立的开发、测试、构建、部署;4.小且灵活;
6. 基础设施自动化在微服务架构的实践过程中,对持续交付和部署流水线的要求很高,将促进企业不断寻找更高效的方式完成基础设施的自动化及 DevOps 运维能力的提升。听完成小胖忍不住表达了敬佩之意:“老司机就是老司机,噢说错了……架构师就是架构师,总结得这么简洁又深刻!”“咳咳,低调低调……”“听您讲解了这么多,我觉得微服务架构解决了很多当前三层架构的痛点。不过我觉得没有任何一项技术或架构是完美的。”“非常正确。进行微服务架构的落地是存在很多挑战的。” 1. 分布式系统的复杂性微服务架构是基于分布式的系统,而构建分布式系统必然会带来额外的开销。性能: 分布式系统是跨进程、跨网络的调用,受网络延迟和带宽的影响。可靠性: 由于高度依赖于网络状况,任何一次的远程调用都有可能失败,随着服务的增多还会出现更多的潜在故障点。因此,如何提高系统的可靠性、降低因网络引起的故障率,是系统构建的一大挑战。异步: 异步通信大大增加了功能实现的复杂度,并且伴随着定位难、调试难等问题。数据一致性: 要保证分布式系统的数据强一致性,成本是非常高的,需要在 C(一致性)A(可用性)P(分区容错性) 三者之间做出权衡。2. 运维成本运维主要包括配置、部署、监控与告警和日志收集四大方面。微服务架构中,每个服务都需要独立地配置、部署、监控和收集日志,成本呈指数级增长。3. 自动化部署在微服务架构中,每个服务都独立部署,交付周期短且频率高,人工部署已经无法适应业务的快速变化。因此如何有效地构建自动化部署体系,是微服务面临的另一个挑战。4. DevOps 与组织架构在微服务架构的实施过程中,开发人员和运维人员的角色发生了变化,开发者将承担起整个服务的生命周期的责任,包括部署和监控;而运维则更倾向于顾问式的角色,尽早考虑服务如何部署。因此,按需调整组织架构、构建全功能的团队,也是一个不小的挑战。5. 服务间的依赖测试单块架构中,通常使用集成测试来验证依赖是否正常。而在微服务架构中,服务数量众多,每个服务都是独立的业务单元,服务主要通过接口进行交互,如何保证依赖的正常,是测试面临的主要挑战。6. 服务间的依赖管理微服务架构中,服务数量众多,如何清晰有效地展示服务间的依赖关系也是个不小的挑战。“微服务的落地需要经过全面的考察和完善的试验,并不是每个场景都适合使用微服务架构,也不是每个企业都有能力或者精力去面对这些挑战。”老王最后语重心长的说。“嗯嗯,每件事都有两面性,最合适的才是最好的!对了王哥,您已经给我上完理论课了,啥时候带我实践下呗?”“你先好好消化完今天讲的这些,下次再说吧……”“好吧,很期待我们的下一次交流……”来源:博客园作者:cyfonly原文:https://www.cnblogs.com/cyfonly/p/6251944.html 发布于 2019-07-05赞同 361 条评论分享收藏喜欢收起李遥A Programmer12 人赞同了该回答如果你觉得函数调用实在太可靠了以至于无聊,那么可以采用微服务调用来找点刺激,多棒!编辑于 2018-07-28赞同 124 条评论分享收藏喜欢东方翌职猿,让IT面试更简单 www.jobyuan.com51 人赞同了该回答一、全面了解微服务a : 4个典型特点1.单个服务尽量专注一件事情,高内聚、低耦合;2.进程隔离;3.每个服务可以独立的开发、测试、构建、部署;4.小且灵活; b : 无与伦比的优点1.交付周期每个服务可以独立的开发、测试和交付,降低周期;2.快速沟通小团队开发,降低代码耦合度导致的沟通成本;业务按服务拆分,新人不需要了解整体架构,上手快;3.定制化可以根据市场需求,灵活多变的组合出新的业务场景;4.隔离性进程隔离方式,故障范围有效控制;5.技术栈可以根据需求按服务选择不同技术栈;6.演进优化可以按照服务粒度进行演进优化;二、微服务基础架构关键点下面脑图中芒果色标注的七个模块,被认为认为是构建微服务 2.0 技术栈的核心模块,本文后面的选型会分别基于这些模块展开。对于每个模块我也列出一些核心架构关注点,在选择具体产品时,需要尽可能覆盖到这些关注点。下图是我近期工作总结和参考的一个微服务技术体系,我想同时分享给一线架构师或者工程师参考,其中粉红色标注的模块是和微服务关系最密切的模块,大家在做技术选型时,可以同时对照这个体系。
b : 无与伦比的优点1.交付周期每个服务可以独立的开发、测试和交付,降低周期;2.快速沟通小团队开发,降低代码耦合度导致的沟通成本;业务按服务拆分,新人不需要了解整体架构,上手快;3.定制化可以根据市场需求,灵活多变的组合出新的业务场景;4.隔离性进程隔离方式,故障范围有效控制;5.技术栈可以根据需求按服务选择不同技术栈;6.演进优化可以按照服务粒度进行演进优化;二、微服务基础架构关键点下面脑图中芒果色标注的七个模块,被认为认为是构建微服务 2.0 技术栈的核心模块,本文后面的选型会分别基于这些模块展开。对于每个模块我也列出一些核心架构关注点,在选择具体产品时,需要尽可能覆盖到这些关注点。下图是我近期工作总结和参考的一个微服务技术体系,我想同时分享给一线架构师或者工程师参考,其中粉红色标注的模块是和微服务关系最密切的模块,大家在做技术选型时,可以同时对照这个体系。 三、 服务框架选型服务框架是一个比较成熟的领域,有太多可选项。Spring Boot/Cloud 由于 Spring 社区的影响力和 Netflix 的背书,目前可以认为是构建 Java 微服务的一个社区标准,Spring Boot 目前在 GitHub 上有超过 20k 星。基于 Spring 的框架本质上可以认为是一种 RESTful 框架(不是 RPC 框架),序列化协议主要采用基于文本的 JSON,通讯协议一般基于 HTTP。RESTful 框架天然支持跨语言,任何语言只要有 HTTP 客户端都可以接入调用,但是客户端一般需要自己解析 payload。目前 Spring 框架也支持 Swagger 契约编程模型,能够基于契约生成各种语言的强类型客户端,极大方便不同语言栈的应用接入,但是因为 RESTful 框架和 Swagger 规范的弱契约特性,生成的各种语言客户端的互操作性还是有不少坑的。Dubbo 是阿里多年构建生产级分布式微服务的技术结晶,服务治理能力非常丰富,在国内技术社区具有很大影响力,目前 github 上有超过 16k 星。Dubbo 本质上是一套基于 Java 的 RPC 框架,当当 Dubbox 扩展了 Dubbo 支持 RESTful 接口暴露能力。Dubbo 主要面向 Java 技术栈,跨语言支持不足是它的一个弱项,另外因为治理能力太丰富,以至于这个框架比较重,完全用好这个框架的门槛比较高,但是如果你的企业基本上投资在 Java 技术栈上,选 Dubbo 可以让你在服务框架一块站在较高的起点上,不管是性能还是企业级的服务治理能力,Dubbo 都做的很出色。新浪微博开源的 Motan(GitHub 4k stars)也不错,功能和 Dubbo 类似,可以认为是一个轻量裁剪版的 Dubbo。gRPC 是谷歌近年新推的一套 RPC 框架,基于 protobuf 的强契约编程模型,能自动生成各种语言客户端,且保证互操作。支持 HTTP2 是 gRPC 的一大亮点,通讯层性能比 HTTP 有很大改进。Protobuf 是在社区具有悠久历史和良好口碑的高性能序列化协议,加上 Google 公司的背书和社区影响力,目前 gRPC 也比较火,GitHub 上有超过 13.4k 星。目前看 gRPC 更适合内部服务相互调用场景,对外暴露 RESTful 接口可以实现,但是比较麻烦(需要 gRPC Gateway 配合),所以对于对外暴露 API 场景可能还需要引入第二套 RESTful 框架作为补充。总体上 gRPC 这个东西还比较新,社区对于 HTTP2 带来的好处还未形成一致认同,建议谨慎投入,可以做一些试点。四、 运行时支撑服务选型运行时支撑服务主要包括服务注册中心,服务路由网关和集中式配置中心三个产品。服务注册中心,如果采用 Spring Cloud 体系,则选择 Eureka 是最佳搭配,Eureka 在 Netflix 经过大规模生产验证,支持跨数据中心,客户端配合 Ribbon 可以实现灵活的客户端软负载,Eureka 目前在 GitHub 上有超过 4.7k 星;Consul 也是不错选择,天然支持跨数据中心,还支持 KV 模型存储和灵活健康检查能力,目前在 GitHub 上有超过 11k 星。服务网关也是一个比较成熟的领域,有很多可选项。如果采用 Spring Cloud 体系,则选择 Zuul 是最佳搭配,Zuul 在 Netflix 经过大规模生产验证,支持灵活的动态过滤器脚本机制,异步性能不足(基于 Netty 的异步 Zuul 迟迟未能推出正式版)。Zuul 网关目前在 github 上有超过 3.7k 星。基于 Nginx/OpenResty 的 API 网关 Kong 目前在 github 上比较火,有超过 14.1k 星。因为采用 Nginx 内核,Kong 的异步性能较强,另外基于 lua 的插件机制比较灵活,社区插件也比较丰富,从安全到限流熔断都有,还有不少开源的管理界面,能够集中管理 Kong 集群。配置中心,Spring Cloud 自带 Spring Cloud Config(GitHub 0.75k stars),个人认为算不上生产级,很多治理能力缺失,小规模场景可以试用。个人比较推荐携程的 Apollo 配置中心,在携程经过生产级验证,具备高可用,配置实时生效(推拉结合),配置审计和版本化,多环境多集群支持等生产级特性,建议中大规模需要对配置集中进行治理的企业采用。Apollo 目前在 github 上有超过 3.4k 星。五、服务监控选型主要包括日志监控,调用链监控,Metrics 监控,健康检查和告警通知等产品。ELK 目前可以认为是日志监控的标配,功能完善开箱即用,ElasticSearch 目前在 GitHub 上有超过 28.4k 星。Elastalert(GitHub 4k stars) 是 Yelp 开源的针对 ELK 的告警通知模块。调用链监控目前社区主流是点评 CAT(GitHub 4.3k stars),Twitter 之前开源现在由 OpenZipkin 社区维护的 Zipkin(GitHub 7.5k stars)和 Naver 开源的 Pinpoint(GitHub 5.3k stars)。个人比较推荐点评开源的 CAT,在点评和国内多家互联网公司有落地案例,生产级特性和治理能力较完善,另外 CAT 自带告警模块。下面是我之前对三款产品的评估表,供参考。
三、 服务框架选型服务框架是一个比较成熟的领域,有太多可选项。Spring Boot/Cloud 由于 Spring 社区的影响力和 Netflix 的背书,目前可以认为是构建 Java 微服务的一个社区标准,Spring Boot 目前在 GitHub 上有超过 20k 星。基于 Spring 的框架本质上可以认为是一种 RESTful 框架(不是 RPC 框架),序列化协议主要采用基于文本的 JSON,通讯协议一般基于 HTTP。RESTful 框架天然支持跨语言,任何语言只要有 HTTP 客户端都可以接入调用,但是客户端一般需要自己解析 payload。目前 Spring 框架也支持 Swagger 契约编程模型,能够基于契约生成各种语言的强类型客户端,极大方便不同语言栈的应用接入,但是因为 RESTful 框架和 Swagger 规范的弱契约特性,生成的各种语言客户端的互操作性还是有不少坑的。Dubbo 是阿里多年构建生产级分布式微服务的技术结晶,服务治理能力非常丰富,在国内技术社区具有很大影响力,目前 github 上有超过 16k 星。Dubbo 本质上是一套基于 Java 的 RPC 框架,当当 Dubbox 扩展了 Dubbo 支持 RESTful 接口暴露能力。Dubbo 主要面向 Java 技术栈,跨语言支持不足是它的一个弱项,另外因为治理能力太丰富,以至于这个框架比较重,完全用好这个框架的门槛比较高,但是如果你的企业基本上投资在 Java 技术栈上,选 Dubbo 可以让你在服务框架一块站在较高的起点上,不管是性能还是企业级的服务治理能力,Dubbo 都做的很出色。新浪微博开源的 Motan(GitHub 4k stars)也不错,功能和 Dubbo 类似,可以认为是一个轻量裁剪版的 Dubbo。gRPC 是谷歌近年新推的一套 RPC 框架,基于 protobuf 的强契约编程模型,能自动生成各种语言客户端,且保证互操作。支持 HTTP2 是 gRPC 的一大亮点,通讯层性能比 HTTP 有很大改进。Protobuf 是在社区具有悠久历史和良好口碑的高性能序列化协议,加上 Google 公司的背书和社区影响力,目前 gRPC 也比较火,GitHub 上有超过 13.4k 星。目前看 gRPC 更适合内部服务相互调用场景,对外暴露 RESTful 接口可以实现,但是比较麻烦(需要 gRPC Gateway 配合),所以对于对外暴露 API 场景可能还需要引入第二套 RESTful 框架作为补充。总体上 gRPC 这个东西还比较新,社区对于 HTTP2 带来的好处还未形成一致认同,建议谨慎投入,可以做一些试点。四、 运行时支撑服务选型运行时支撑服务主要包括服务注册中心,服务路由网关和集中式配置中心三个产品。服务注册中心,如果采用 Spring Cloud 体系,则选择 Eureka 是最佳搭配,Eureka 在 Netflix 经过大规模生产验证,支持跨数据中心,客户端配合 Ribbon 可以实现灵活的客户端软负载,Eureka 目前在 GitHub 上有超过 4.7k 星;Consul 也是不错选择,天然支持跨数据中心,还支持 KV 模型存储和灵活健康检查能力,目前在 GitHub 上有超过 11k 星。服务网关也是一个比较成熟的领域,有很多可选项。如果采用 Spring Cloud 体系,则选择 Zuul 是最佳搭配,Zuul 在 Netflix 经过大规模生产验证,支持灵活的动态过滤器脚本机制,异步性能不足(基于 Netty 的异步 Zuul 迟迟未能推出正式版)。Zuul 网关目前在 github 上有超过 3.7k 星。基于 Nginx/OpenResty 的 API 网关 Kong 目前在 github 上比较火,有超过 14.1k 星。因为采用 Nginx 内核,Kong 的异步性能较强,另外基于 lua 的插件机制比较灵活,社区插件也比较丰富,从安全到限流熔断都有,还有不少开源的管理界面,能够集中管理 Kong 集群。配置中心,Spring Cloud 自带 Spring Cloud Config(GitHub 0.75k stars),个人认为算不上生产级,很多治理能力缺失,小规模场景可以试用。个人比较推荐携程的 Apollo 配置中心,在携程经过生产级验证,具备高可用,配置实时生效(推拉结合),配置审计和版本化,多环境多集群支持等生产级特性,建议中大规模需要对配置集中进行治理的企业采用。Apollo 目前在 github 上有超过 3.4k 星。五、服务监控选型主要包括日志监控,调用链监控,Metrics 监控,健康检查和告警通知等产品。ELK 目前可以认为是日志监控的标配,功能完善开箱即用,ElasticSearch 目前在 GitHub 上有超过 28.4k 星。Elastalert(GitHub 4k stars) 是 Yelp 开源的针对 ELK 的告警通知模块。调用链监控目前社区主流是点评 CAT(GitHub 4.3k stars),Twitter 之前开源现在由 OpenZipkin 社区维护的 Zipkin(GitHub 7.5k stars)和 Naver 开源的 Pinpoint(GitHub 5.3k stars)。个人比较推荐点评开源的 CAT,在点评和国内多家互联网公司有落地案例,生产级特性和治理能力较完善,另外 CAT 自带告警模块。下面是我之前对三款产品的评估表,供参考。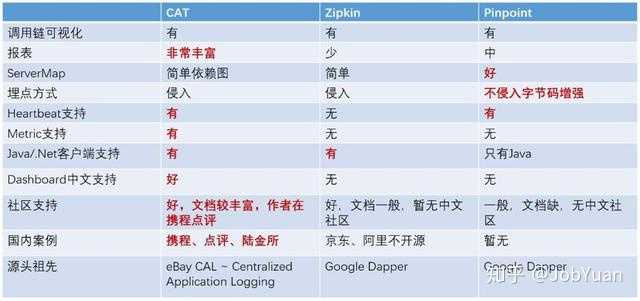 Metrics 监控主要依赖于时间序列数据库 (TSDB),目前较成熟的产品是 StumbleUpon 公司开源的基于 HBase 的 OpenTSDB(基于 Cassandra 的 KariosDB 也是一个选择,GitHub 1.1k stars,它基本上是 OpenTSDB 针对 Cassandra 的一个改造版),OpenTSDB 具有分布式能力可以横向扩展,但是相对较重,适用于中大规模企业,OpenTSDB 目前在 GitHub 上有近 2.9k 星。OpenTSDB 本身不提供告警模块,Argus(GitHub 0.29k 星)是 Salesforce 开源的基于 OpenTSDB 的统一监控告警平台,支持丰富的告警函数和灵活的告警配置,可以作为 OpenTSDB 的告警补充。近年也出现一些轻量级的 TSDB,如 InfluxDB(GitHub 12.4k stars)和 Prometheus(GitHub 14.3k stars),这些产品函数报表能力丰富,自带告警模块,但是分布式能力不足,适用于中小规模企业。Grafana(GitHub 19.9k stars)是 Metrics 报表展示的社区标配。社区还有一些通用的健康检查和告警产品,例如 Sensu(GitHub 2.7k stars),能够对各种服务(例如 Spring Boot 暴露的健康检查端点,时间序列数据库中的 metrics,ELK 中的错误日志等)定制灵活的健康检查 (check),然后用户可以针对 check 结果设置灵活的告警通知策略。Sensu 在 Yelp 等公司有落地案例。其它类似产品还有 Esty 开源的 411(GitHub 0.74k 星)和 Zalando 的 ZMon(GitHub 0.15k 星),它们是分别在 Esty 和 Zalando 落地的产品,但是定制 check 和告警配置的使用门槛比较高,社区不热,建议有定制自研能力的团队试用。ZMon 后台采用 KairosDB 存储,如果企业已经采用 KariosDB 作为时间序列数据库,则可以考虑 ZMon 作为告警通知模块。六、服务容错选型针对 Java 技术栈,Netflix 的 Hystrix(github 12.4k stars)把熔断、隔离、限流和降级等能力封装成组件,任何依赖调用(数据库,服务,缓存)都可以封装在 Hystrix Command 之内,封装后自动具备容错能力。Hystrix 起源于 Netflix 的弹性工程项目,经过 Netflix 大规模生产验证,目前是容错组件的社区标准,GitHub 上有超 12k 星。其它语言栈也有类似 Hystrix 的简化版本组件。Hystrix 一般需要在应用端或者框架内埋点,有一定的使用门槛。对于采用集中式反向代理(边界和内部)做服务路由的公司,则可以集中在反向代理上做熔断限流,例如采用 Nginx(GitHub 5.1k stars)或者 Kong(GitHub 11.4k stars)这类反向代理,它们都插件支持灵活的限流容错配置。Zuul 网关也可以集成 Hystrix 实现网关层集中式限流容错。集中式反向代理需要有一定的研发和运维能力,但是可以对限流容错进行集中治理,可以简化客户端。七、 后台服务选型后台服务主要包括消息系统,分布式缓存,分布式数据访问层和任务调度系统。后台服务是一个相对比较成熟的领域,很多开源产品基本可以开箱即用。消息系统,对于日志等可靠性要求不高的场景,则 Apache 顶级项目 Kafka(GitHub 7.2k stars)是社区标配。对于可靠性要求较高的业务场景,Kafka 其实也是可以胜任,但企业需要根据具体场景,对 Kafka 的监控和治理能力进行适当定制完善,Allegro 公司开源的 hermes(GitHub 0.3k stars)是一个可参考项目,它在 Kafka 基础上封装了适合业务场景的企业级治理能力。阿里开源的 RocketMQ(GitHub 3.5k 星)也是一个不错选择,具备更多适用于业务场景的特性,目前也是 Apache 顶级项目。RabbitMQ(GitHub 3.6k 星)是老牌经典的 MQ,队列特性和文档都很丰富,性能和分布式能力稍弱,中小规模场景可选。对于缓存治理,如果倾向于采用客户端直连模式(个人认为缓存直连更简单轻量),则 SohuTv 开源的 cachecloud(GitHub 2.5k stars)是一款不错的 Redis 缓存治理平台,提供诸如监控统计,一键开启,自动故障转移,在线伸缩,自动化运维等生产级治理能力,另外其文档也比较丰富。如果倾向采用中间层 Proxy 模式,则 Twitter 开源的 twemproxy(GitHub 7.5k stars)和 CodisLab 开源的 codis(GitHub 6.9k stars)是社区比较热的选项。对于分布式数据访问层,如果采用 Java 技术栈,则当当开源的 shardingjdbc(GitHub 3.5k stars)是一个不错的选项,分库分表逻辑做在客户端 jdbc driver 中,客户端直连数据库比较简单轻量,建议中小规模场景采用。如果倾向采用数据库访问中间层 proxy 模式,则从阿里 Cobar 演化出来的社区开源分库分表中间件 MyCAT(GitHub 3.6k stars)是一个不错选择 。proxy 模式运维成本较高,建议中大规模场景,有一定框架自研和运维能力的团队采用。任务调度系统,个人推荐徐雪里开源的 xxl-job(GitHub 3.4k stars),部署简单轻量,大部分场景够用。当当开源的 elastic-job(GitHub 3.2k stars)也是一个不错选择,相比 xxl-job 功能更强一些也更复杂。八、 服务安全选型对于微服务安全认证授权机制一块,目前业界虽然有 OAuth 和 OpenID connect 等标准协议,但是各家具体实现的做法都不太一样,企业一般有很多特殊的定制需求,整个社区还没有形成通用生产级开箱即用的产品。有一些开源授权服务器产品,比较知名的如 Apereo CAS(GitHub 3.6k stars),JBoss 开源的 keycloak(GitHub 1.9 stars),spring cloud security 等,大都是 opinionated(一家观点和做法)的产品,同时因支持太多协议造成产品复杂,也缺乏足够灵活性。个人建议基于 OAuth 和 OpenID connect 标准,在参考一些开源产品的基础上(例如 Mitre 开源的 OpenID-Connect-Java-Spring-Server,GitHub 0.62k stars),定制自研轻量级授权服务器。Wso2 提出了一种微服务安全的参考方案,建议参考,该方案的关键步骤如下:
Metrics 监控主要依赖于时间序列数据库 (TSDB),目前较成熟的产品是 StumbleUpon 公司开源的基于 HBase 的 OpenTSDB(基于 Cassandra 的 KariosDB 也是一个选择,GitHub 1.1k stars,它基本上是 OpenTSDB 针对 Cassandra 的一个改造版),OpenTSDB 具有分布式能力可以横向扩展,但是相对较重,适用于中大规模企业,OpenTSDB 目前在 GitHub 上有近 2.9k 星。OpenTSDB 本身不提供告警模块,Argus(GitHub 0.29k 星)是 Salesforce 开源的基于 OpenTSDB 的统一监控告警平台,支持丰富的告警函数和灵活的告警配置,可以作为 OpenTSDB 的告警补充。近年也出现一些轻量级的 TSDB,如 InfluxDB(GitHub 12.4k stars)和 Prometheus(GitHub 14.3k stars),这些产品函数报表能力丰富,自带告警模块,但是分布式能力不足,适用于中小规模企业。Grafana(GitHub 19.9k stars)是 Metrics 报表展示的社区标配。社区还有一些通用的健康检查和告警产品,例如 Sensu(GitHub 2.7k stars),能够对各种服务(例如 Spring Boot 暴露的健康检查端点,时间序列数据库中的 metrics,ELK 中的错误日志等)定制灵活的健康检查 (check),然后用户可以针对 check 结果设置灵活的告警通知策略。Sensu 在 Yelp 等公司有落地案例。其它类似产品还有 Esty 开源的 411(GitHub 0.74k 星)和 Zalando 的 ZMon(GitHub 0.15k 星),它们是分别在 Esty 和 Zalando 落地的产品,但是定制 check 和告警配置的使用门槛比较高,社区不热,建议有定制自研能力的团队试用。ZMon 后台采用 KairosDB 存储,如果企业已经采用 KariosDB 作为时间序列数据库,则可以考虑 ZMon 作为告警通知模块。六、服务容错选型针对 Java 技术栈,Netflix 的 Hystrix(github 12.4k stars)把熔断、隔离、限流和降级等能力封装成组件,任何依赖调用(数据库,服务,缓存)都可以封装在 Hystrix Command 之内,封装后自动具备容错能力。Hystrix 起源于 Netflix 的弹性工程项目,经过 Netflix 大规模生产验证,目前是容错组件的社区标准,GitHub 上有超 12k 星。其它语言栈也有类似 Hystrix 的简化版本组件。Hystrix 一般需要在应用端或者框架内埋点,有一定的使用门槛。对于采用集中式反向代理(边界和内部)做服务路由的公司,则可以集中在反向代理上做熔断限流,例如采用 Nginx(GitHub 5.1k stars)或者 Kong(GitHub 11.4k stars)这类反向代理,它们都插件支持灵活的限流容错配置。Zuul 网关也可以集成 Hystrix 实现网关层集中式限流容错。集中式反向代理需要有一定的研发和运维能力,但是可以对限流容错进行集中治理,可以简化客户端。七、 后台服务选型后台服务主要包括消息系统,分布式缓存,分布式数据访问层和任务调度系统。后台服务是一个相对比较成熟的领域,很多开源产品基本可以开箱即用。消息系统,对于日志等可靠性要求不高的场景,则 Apache 顶级项目 Kafka(GitHub 7.2k stars)是社区标配。对于可靠性要求较高的业务场景,Kafka 其实也是可以胜任,但企业需要根据具体场景,对 Kafka 的监控和治理能力进行适当定制完善,Allegro 公司开源的 hermes(GitHub 0.3k stars)是一个可参考项目,它在 Kafka 基础上封装了适合业务场景的企业级治理能力。阿里开源的 RocketMQ(GitHub 3.5k 星)也是一个不错选择,具备更多适用于业务场景的特性,目前也是 Apache 顶级项目。RabbitMQ(GitHub 3.6k 星)是老牌经典的 MQ,队列特性和文档都很丰富,性能和分布式能力稍弱,中小规模场景可选。对于缓存治理,如果倾向于采用客户端直连模式(个人认为缓存直连更简单轻量),则 SohuTv 开源的 cachecloud(GitHub 2.5k stars)是一款不错的 Redis 缓存治理平台,提供诸如监控统计,一键开启,自动故障转移,在线伸缩,自动化运维等生产级治理能力,另外其文档也比较丰富。如果倾向采用中间层 Proxy 模式,则 Twitter 开源的 twemproxy(GitHub 7.5k stars)和 CodisLab 开源的 codis(GitHub 6.9k stars)是社区比较热的选项。对于分布式数据访问层,如果采用 Java 技术栈,则当当开源的 shardingjdbc(GitHub 3.5k stars)是一个不错的选项,分库分表逻辑做在客户端 jdbc driver 中,客户端直连数据库比较简单轻量,建议中小规模场景采用。如果倾向采用数据库访问中间层 proxy 模式,则从阿里 Cobar 演化出来的社区开源分库分表中间件 MyCAT(GitHub 3.6k stars)是一个不错选择 。proxy 模式运维成本较高,建议中大规模场景,有一定框架自研和运维能力的团队采用。任务调度系统,个人推荐徐雪里开源的 xxl-job(GitHub 3.4k stars),部署简单轻量,大部分场景够用。当当开源的 elastic-job(GitHub 3.2k stars)也是一个不错选择,相比 xxl-job 功能更强一些也更复杂。八、 服务安全选型对于微服务安全认证授权机制一块,目前业界虽然有 OAuth 和 OpenID connect 等标准协议,但是各家具体实现的做法都不太一样,企业一般有很多特殊的定制需求,整个社区还没有形成通用生产级开箱即用的产品。有一些开源授权服务器产品,比较知名的如 Apereo CAS(GitHub 3.6k stars),JBoss 开源的 keycloak(GitHub 1.9 stars),spring cloud security 等,大都是 opinionated(一家观点和做法)的产品,同时因支持太多协议造成产品复杂,也缺乏足够灵活性。个人建议基于 OAuth 和 OpenID connect 标准,在参考一些开源产品的基础上(例如 Mitre 开源的 OpenID-Connect-Java-Spring-Server,GitHub 0.62k stars),定制自研轻量级授权服务器。Wso2 提出了一种微服务安全的参考方案,建议参考,该方案的关键步骤如下: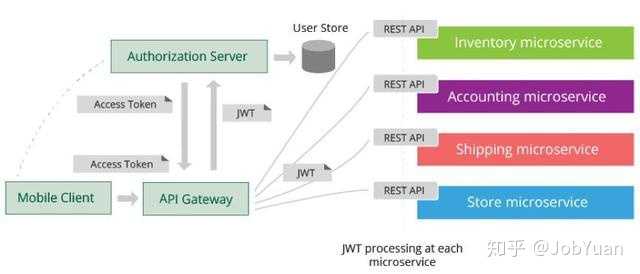 1. 使用支持 OAuth 2.0 和 OpenID Connect 标准协议的授权服务器(个人建议定制自研);2. 使用 API 网关作为单一访问入口,统一实现安全治理;3. 客户在访问微服务之前,先通过授权服务器登录获取 access token,然后将 access token 和请求一起发送到网关;4. 网关获取 access token,通过授权服务器校验 token,同时做 token 转换获取 JWT token。5. 网关将 JWT Token 和请求一起转发到后台微服务。6. JWT 中可以存储用户会话信息,该信息可以传递给后台的微服务,也可以在微服务之间传递,用作认证授权等用途;7. 每个微服务包含 JWT 客户端,能够解密 JWT 并获取其中的用户会话信息。8. 整个方案中,access token 是一种 by reference token,不包含用户信息可以直接暴露在公网上;JWT token 是一种 by value token,可以包含用户信息但不暴露在公网上。九、 服务部署平台选型容器已经被社区接受为交付微服务的一种理想手段,可以实现不可变(immutable)发布模式。一个轻量级的基于容器的服务部署平台主要包括容器资源调度,发布系统,镜像治理,资源治理和 IAM 等模块。集群资源调度系统:屏蔽容器细节,将整个集群抽象成容器资源池,支持按需申请和释放容器资源,物理机发生故障时能够实现自动故障迁移 (fail over)。目前 Google 开源的 Kubernetes,在 Google 背书和社区的强力推动下,基本已经形成市场领导者地位,GitHub 上有 31.8k 星,社区的活跃度已经远远超过了 mesos(GitHub 3.5k stars)和 swarm 等竞争产品,所以容器资源调度建议首选 K8s。当然如果你的团队有足够定制自研能力,想深度把控底层调度算法,也可以基于 Mesos 做定制自研。镜像治理:基于 Docker Registry,封装一些轻量级的治理功能。VMware 开源的 harbor(GitHub 3.5k stars) 是目前社区比较成熟的企业级产品,在 Docker Registry 基础上扩展了权限控制,审计,镜像同步,管理界面等治理能力,可以考虑采用。资源治理:类似于 CMDB 思路,在容器云环境中,企业仍然需要对应用 app,组织 org,容器配额和数量等相关信息进行轻量级的治理。目前这块还没有生产级的开源产品,一般企业需要根据自己的场景定制自研。发布平台:面向用户的发布管理控制台,支持发布流程编排。它和其它子系统对接交互,实现基本的应用发布能力,也实现如蓝绿,金丝雀和灰度等高级发布机制。目前这块生产级的开源产品很少,Netflix 开源的 spinnaker(github 4.2k stars)是一个,但是这个产品比较复杂重量(因为它既要支持适配对接各种 CI 系统,同时还要适配对接各种公有云和容器云,使得整个系统异常复杂),一般企业建议根据自己的场景定制自研轻量级的解决方案。IAM:是 identity & access management 的简称,对发布平台各个组件进行身份认证和安全访问控制。社区有不少开源的 IAM 产品,比较知名的有 Apereo CAS(GitHub 3.6k stars),JBoss 开源的 keycloak(GitHub 1.9 stars)等。但是这些产品一般都比较复杂重量,很多企业考虑到内部各种系统灵活对接的需求,都会考虑定制自研轻量级的解决方案。考虑到服务部署平台目前还没有端到端生产级解决方案,企业一般需要定制集成,下面给出一个可以参考的具备轻量级治理能力的发布体系:
1. 使用支持 OAuth 2.0 和 OpenID Connect 标准协议的授权服务器(个人建议定制自研);2. 使用 API 网关作为单一访问入口,统一实现安全治理;3. 客户在访问微服务之前,先通过授权服务器登录获取 access token,然后将 access token 和请求一起发送到网关;4. 网关获取 access token,通过授权服务器校验 token,同时做 token 转换获取 JWT token。5. 网关将 JWT Token 和请求一起转发到后台微服务。6. JWT 中可以存储用户会话信息,该信息可以传递给后台的微服务,也可以在微服务之间传递,用作认证授权等用途;7. 每个微服务包含 JWT 客户端,能够解密 JWT 并获取其中的用户会话信息。8. 整个方案中,access token 是一种 by reference token,不包含用户信息可以直接暴露在公网上;JWT token 是一种 by value token,可以包含用户信息但不暴露在公网上。九、 服务部署平台选型容器已经被社区接受为交付微服务的一种理想手段,可以实现不可变(immutable)发布模式。一个轻量级的基于容器的服务部署平台主要包括容器资源调度,发布系统,镜像治理,资源治理和 IAM 等模块。集群资源调度系统:屏蔽容器细节,将整个集群抽象成容器资源池,支持按需申请和释放容器资源,物理机发生故障时能够实现自动故障迁移 (fail over)。目前 Google 开源的 Kubernetes,在 Google 背书和社区的强力推动下,基本已经形成市场领导者地位,GitHub 上有 31.8k 星,社区的活跃度已经远远超过了 mesos(GitHub 3.5k stars)和 swarm 等竞争产品,所以容器资源调度建议首选 K8s。当然如果你的团队有足够定制自研能力,想深度把控底层调度算法,也可以基于 Mesos 做定制自研。镜像治理:基于 Docker Registry,封装一些轻量级的治理功能。VMware 开源的 harbor(GitHub 3.5k stars) 是目前社区比较成熟的企业级产品,在 Docker Registry 基础上扩展了权限控制,审计,镜像同步,管理界面等治理能力,可以考虑采用。资源治理:类似于 CMDB 思路,在容器云环境中,企业仍然需要对应用 app,组织 org,容器配额和数量等相关信息进行轻量级的治理。目前这块还没有生产级的开源产品,一般企业需要根据自己的场景定制自研。发布平台:面向用户的发布管理控制台,支持发布流程编排。它和其它子系统对接交互,实现基本的应用发布能力,也实现如蓝绿,金丝雀和灰度等高级发布机制。目前这块生产级的开源产品很少,Netflix 开源的 spinnaker(github 4.2k stars)是一个,但是这个产品比较复杂重量(因为它既要支持适配对接各种 CI 系统,同时还要适配对接各种公有云和容器云,使得整个系统异常复杂),一般企业建议根据自己的场景定制自研轻量级的解决方案。IAM:是 identity & access management 的简称,对发布平台各个组件进行身份认证和安全访问控制。社区有不少开源的 IAM 产品,比较知名的有 Apereo CAS(GitHub 3.6k stars),JBoss 开源的 keycloak(GitHub 1.9 stars)等。但是这些产品一般都比较复杂重量,很多企业考虑到内部各种系统灵活对接的需求,都会考虑定制自研轻量级的解决方案。考虑到服务部署平台目前还没有端到端生产级解决方案,企业一般需要定制集成,下面给出一个可以参考的具备轻量级治理能力的发布体系: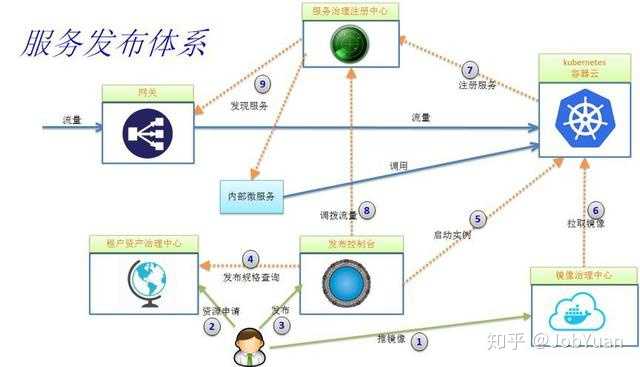 简化发布流程如下:1. 应用通过 CI 集成后生成镜像,用户将镜像推到镜像治理中心;2. 用户在资产治理中心申请发布,填报应用,发布和配额相关信息,然后等待审批通过;3. 发布审批通过,开发人员通过发布控制台发布应用;4. 发布系统通过查询资产治理中心获取发布规格信息;5. 发布系统向容器云发出启动容器实例指令;6. 容器云从镜像治理中心拉取镜像并启动容器;7. 容器内服务启动后自注册到服务注册中心,并保持定期心跳;8. 用户通过发布系统调用服务注册中心调拨流量,实现蓝绿,金丝雀或灰度发布等机制;9. 网关和内部微服务客户端定期同步服务注册中心上的服务路由表,将流量按负载均衡策略分发到新的服务实例上。另外,持续交付流水线(CD Pipeline)也是微服务发布重要环节,这块主要和研发流程相关,一般需要企业定制,下面是一个可供参考的流水线模型,在镜像治理中心上封装一些轻量级的治理流程,例如只有通过测试环境测试的镜像才能升级发布到 UAT 环境,只有通过 UAT 环境测试的镜像才能升级发布到生产环境,通过在流水线上设置一些质量门,保障应用高质量交付到生产。十、总结注意,本文限于篇幅,对测试和 CI 等环节没有涉及,但它们同样是构建微服务架构的重要环节,也有众多成熟的开源产品可选。技术选型虽然重要,但还只是微服务建设的一小部分工作,选型后的产品要在企业内部真正落地,形成完整的微服务技术栈体系,则后续还有大量集成、定制、治理、运维和推广等工作。以上是理论部分,具体实践请详细参照各大公司的系统微服务演进,包括华为、阿里、百度、滴滴、豆瓣、七牛、小米、360、58等公司的实践案例以及两本最佳学习微服务的电子书,王磊著的《微服务架构与实践》以及国外Sam Newman著的《微服务设计》。转自10步骤轻松学会微服务架构希望回答对大家有所帮助,更多文章后续会更新出来,发现好的资源会与大家分享,敬请期待哦(如获取最新的文章,进行点赞关注收藏哦)发布于 2018-07-30赞同 513 条评论分享收藏喜欢收起kimmking研究应用技术,改进产品体验,提升业务能力,服务广大客户10 人赞同了该回答微服务这个概念最早是在2011年5月威尼斯的一个软件架构会议上讨论并提出的,用于描述一些作为通用架构风格的设计原则。2012年3月在波兰克拉科夫举行的33rd Degree Conference大会上,Thoughtworks首席咨询师James Lewis做了题为《Microservices - Java, the Unix Way》的演讲(http://2012.33degree.org/talk/show/67),这次演讲里James讨论了微服务的一些原则和特征,例如单一服务职责、康威定律、自动扩展、DDD等等。微服务架构则是由Fred George在2012年的一次技术大会上所提出(http://oredev.org/oredev2012/2012/sessions/micro-service-architecture.html),在大会的演讲中他讲解了如何分拆服务以及如何利用MQ来进行服务间的解耦,这就是最早的微服务架构雏形。而后由Martin Fowler发扬光大并且在2014年发表了一篇著名的微服务文章(https://martinfowler.com/articles/microservices.html),这篇文章深入全面的讲解了什么是微服务架构。随后,微服务架构逐渐成为一种非常流行的架构模式,一大批的技术框架和文章涌现出来,越来越多的公司借鉴和使用微服务架构相关的技术。然而微服务并不是万能药,我们在实施的过程中不能简单的使用某些个微服务框架或者组件一蹴而就,而是需要将业务、技术和运维有机结合起来,配合同步实施,并且在此过程中还需要趟过很多的坑才能够取得成功。本书通过 Dubbo、Spring Cloud、Service Mesh 等技术构建微服务体系,并深入浅出的介绍了微服务架构发展历程、领域驱动设计、稳定性保证的常用手段、分布式事务的一致性方案,以及通过大量的案例探讨微服务落地方案,例如双活体系建设,分布式监控,微服务编排,百亿流量微服务网关的设计与实现,基于支付场景下的微服务改造等,展示了实现微服务架构的完整蓝图,并让读者了解到如何借助于微服务来增强和重构现有的遗留系统。不管你是还没听过或者刚接触过微服务的新手,还是正在尝试借助微服务解放生产力的开发人员或者运维人员,或者是立志于构建高可用可伸缩的微服务体系的架构师,阅读本书,对读者必有裨益。本书的每一个章节都是相关领域的专家经过多年的技术积累提炼而成,秉承以理论为基础,以大量企业实战案例为核心,深入全面的介绍了微服务架构的实施方法以及在实施过程中所遇到的问题和解决方案,是一本内容详实、“可落地”的理论实践相结合的技术书籍。内容简介本书共分为十四章:第一章:微服务概述从软件架构的发展历程讲起,分别对单体架构、SOA架构和微服务架构的演进过程做了深入浅出的讲解,同时也深入介绍了微服务架构的特点,本章以宏观的视角为读者打开微服务的大门。第二章:微服务领域驱动设计本章介绍了领域驱动设计是什么,常见的领域架构有哪些,如何将领域驱动应用到微服务中,以及如何使用领域驱动进行合理的服务划分等,帮助读者在正式学习微服务前修炼内功。第三章:Dubbo原理与实现目前Dubbo已经被阿里巴巴技术团队重新维护并且得到了大力的发展和推广,使用Dubbo依然可以很好的进行微服务建设,本章较为深入的讲解了Dubbo的使用和技巧,以及通过源码的深入分析能够让读者对Dubbo的原理实现有一个全面的认识。第四章:Spring Cloud实战案例Spring Boot/Cloud是目前较为流行的微服务框架,本章以大量的实战案例为读者讲解如何才能应用好Spring Cloud框架,以及如何避免在使用过程中遇到的坑。第五章:微服务稳定性保证常用手段当业务发展越来越快,规模也越来越大的情况下,我们所面临的就是如何在服务越来越多的情况下保证微服务架构的稳定性,本章带领读者逐步揭开保障稳定性的常用技巧和手段。第六章:微服务下事务的一致性保证本章介绍了从本地事务到分布式事务的演变,深入分析了微服务在强一致性场景和最终一致性场景下的解决方案,探讨了二阶段提交协议、三阶段提交协议、TCC 模式、补偿模式、可靠事件模式等。同时,对开源项目的分布式事务进行解读,包括 RocketMQ 和 ServiceComb。第七章:微服务亿级网关设计本章从百亿流量交易系统微服务网关(API Gateway)的现状和面临问题出发,阐述微服务架构与 API 网关的关系,理顺流量网关与业务网关的脉络,带来最全面的 API 网关知识与经验。第八章:微服务编排本章以Netflix Conductor框架为核心,从框架的使用和原理深入介绍了什么是微服务编排,为微服务执行复杂的业务逻辑提供了一种新的思路。第九章:微服务统计与数据抽取方案在微服务架构下,服务必将越来越多,在这各情况下如何进行数据统计和分析将变得非常困难,本章将深入讲解如何从不同服务的数据库中抽取数据到统一的大数据平台中,帮忙使用者更方便的进行数据的统计。第十章:微服务双活体系建设在企业发展规模越来越大的情况下,用户对系统的稳定性要求也越来越高,那么单机房布署势必成为发展的瓶颈,本章将带领读者从零开始以实际案例出发进行同城双活的建设。第十一章:基于支付场景下的微服务改造和性能优化本章从实际的案例出发,在具体的支付业务场景下,从一个新项目开始逐步讲解如何利用领域驱动划分服务,如何利用微服务框架进行服务治理,以及项目完成后怎样提升微服务架构的性能。第十二章:遗留系统的微服务改造本章介绍了遗留系统的微服务架构改造,梳理了代码分层结构的转变,提出一个新的代码分层思路来应对微服务的流行与普及,并深入思考了遗留系统的债券,深入探讨单体系统拆分服务的方法论。同时,对遗留系统的微服务架构改造的解决方案给出 9 个切实可行的核心实践思路。第十三章:Service Mesh的入门与案例随着微服务的持续发展,下一代微服务架构已然出现,本章将深入介绍Service Mesh发展历程,以及结合具体案例带领读者使用Istio进行具体实践。第十四章:微服务监控实战本章重点介绍APM的原理,从零开始开发APM监控系统,还深入介绍Prometheus的安装和原理,以及如何使用Prometheus进行监控和预警。1.6 架构的不同风格典型的企业级应用系统或者互联网应用系统一般都是通过Web提供一组业务服务能力。这类系统包括提供给用户操作的、运行于浏览器中、具有UI的业务逻辑展示和输入部分,运行于服务器端、用后端编程语言构建的业务逻辑处理部分,以及用于存储业务数据的关系数据库或其他类型的存储软件。根据软件系统在运行期的表现风格和部署结构,我们可以粗略地将其划分为两大类:1) 整个系统的所有功能单元,整体部署到同一个进程(所有代码可以打包成1个或多个文件),我们可以称之为“单体架构”(Monolithic Architecture);2) 整个系统的功能单元分散到不同的进程,然后由多个进程共同提供不同的业务能力,我们称之为“分布式架构”(Distributed Architecture);任何一个体系(产品、平台、商业模式等)如果想要发展壮大,途径只有两个模式:a) 容器模式:从外部提供越来越多的资源和能力,注入到体系的内部,不断的从内扩充自己。单体架构的系统类似这种模式。b) 生态模式:以自己的核心能力为内核,持续的在外部吸引合作者,形成一个可以不断成长的生态体系。分布式架构越来越像这种模式。再结合软件系统在整个生命周期的特点,我们可以进一步区分不同的架构风格。对于单体架构,我们根据设计期和开发实现期的不同模式和划分结构,可以分为:简单单体模式:代码层面没有拆分,所有的业务逻辑都在一个项目(project)里打包成一个二进制的编译后文件,通过这个文件进行部署,并提供业务能力;MVC模式:系统内每个模块的功能组件按照不同的职责划分为模型(Model)、视图(View)、控制器(Controller)等角色,并以此来组织研发实现工作;前后端分离模式:将前后端代码耦合的设计改为前端逻辑和后端逻辑独立编写实现的处理模式;组件模式:系统的每一个模块拆分为一个子项目(subproject),每个模块独立编译打包成一个组件,然后所有需要的组件一起再部署到同一个容器里;类库模式:A系统需要复用B系统的某些功能,这时可以直接把B系统的某些组件作为依赖库,打包到A系统来使用。对于分布式架构,我们根据设计期的架构思想和运行期的不同结构,可以分为:面向服务架构(Service Oriented Architecture,SOA):以业务服务的角度和服务总线的方式(一般是WebService与ESB)考虑系统架构和企业IT治理;分布式服务架构(Distributed Service Architecture,DSA):基于去中心化的分布式服务框架与技术,考虑系统架构和服务治理;微服务架构(MicroServices Architecture,MSA):微服务架构可以看做是面向服务架构和分布式服务架构的拓展,使用更细粒度的服务(所以叫微服务)和一组设计准则来考虑大规模的复杂系统架构设计。此外,传统的企业集成领域的EAI架构模式,本身还是各个系统独立部署,但是各系统之间的部分业务使用特定的技术打通了,因此我们可以看做是单体和分布式之间的过渡状态。也有人把如上的各个架构风格总结为4个大的架构发展阶段,如图1-6所示:1)单体架构阶段2)垂直架构阶段3)SOA架构阶段4)微服务架构阶段
简化发布流程如下:1. 应用通过 CI 集成后生成镜像,用户将镜像推到镜像治理中心;2. 用户在资产治理中心申请发布,填报应用,发布和配额相关信息,然后等待审批通过;3. 发布审批通过,开发人员通过发布控制台发布应用;4. 发布系统通过查询资产治理中心获取发布规格信息;5. 发布系统向容器云发出启动容器实例指令;6. 容器云从镜像治理中心拉取镜像并启动容器;7. 容器内服务启动后自注册到服务注册中心,并保持定期心跳;8. 用户通过发布系统调用服务注册中心调拨流量,实现蓝绿,金丝雀或灰度发布等机制;9. 网关和内部微服务客户端定期同步服务注册中心上的服务路由表,将流量按负载均衡策略分发到新的服务实例上。另外,持续交付流水线(CD Pipeline)也是微服务发布重要环节,这块主要和研发流程相关,一般需要企业定制,下面是一个可供参考的流水线模型,在镜像治理中心上封装一些轻量级的治理流程,例如只有通过测试环境测试的镜像才能升级发布到 UAT 环境,只有通过 UAT 环境测试的镜像才能升级发布到生产环境,通过在流水线上设置一些质量门,保障应用高质量交付到生产。十、总结注意,本文限于篇幅,对测试和 CI 等环节没有涉及,但它们同样是构建微服务架构的重要环节,也有众多成熟的开源产品可选。技术选型虽然重要,但还只是微服务建设的一小部分工作,选型后的产品要在企业内部真正落地,形成完整的微服务技术栈体系,则后续还有大量集成、定制、治理、运维和推广等工作。以上是理论部分,具体实践请详细参照各大公司的系统微服务演进,包括华为、阿里、百度、滴滴、豆瓣、七牛、小米、360、58等公司的实践案例以及两本最佳学习微服务的电子书,王磊著的《微服务架构与实践》以及国外Sam Newman著的《微服务设计》。转自10步骤轻松学会微服务架构希望回答对大家有所帮助,更多文章后续会更新出来,发现好的资源会与大家分享,敬请期待哦(如获取最新的文章,进行点赞关注收藏哦)发布于 2018-07-30赞同 513 条评论分享收藏喜欢收起kimmking研究应用技术,改进产品体验,提升业务能力,服务广大客户10 人赞同了该回答微服务这个概念最早是在2011年5月威尼斯的一个软件架构会议上讨论并提出的,用于描述一些作为通用架构风格的设计原则。2012年3月在波兰克拉科夫举行的33rd Degree Conference大会上,Thoughtworks首席咨询师James Lewis做了题为《Microservices - Java, the Unix Way》的演讲(http://2012.33degree.org/talk/show/67),这次演讲里James讨论了微服务的一些原则和特征,例如单一服务职责、康威定律、自动扩展、DDD等等。微服务架构则是由Fred George在2012年的一次技术大会上所提出(http://oredev.org/oredev2012/2012/sessions/micro-service-architecture.html),在大会的演讲中他讲解了如何分拆服务以及如何利用MQ来进行服务间的解耦,这就是最早的微服务架构雏形。而后由Martin Fowler发扬光大并且在2014年发表了一篇著名的微服务文章(https://martinfowler.com/articles/microservices.html),这篇文章深入全面的讲解了什么是微服务架构。随后,微服务架构逐渐成为一种非常流行的架构模式,一大批的技术框架和文章涌现出来,越来越多的公司借鉴和使用微服务架构相关的技术。然而微服务并不是万能药,我们在实施的过程中不能简单的使用某些个微服务框架或者组件一蹴而就,而是需要将业务、技术和运维有机结合起来,配合同步实施,并且在此过程中还需要趟过很多的坑才能够取得成功。本书通过 Dubbo、Spring Cloud、Service Mesh 等技术构建微服务体系,并深入浅出的介绍了微服务架构发展历程、领域驱动设计、稳定性保证的常用手段、分布式事务的一致性方案,以及通过大量的案例探讨微服务落地方案,例如双活体系建设,分布式监控,微服务编排,百亿流量微服务网关的设计与实现,基于支付场景下的微服务改造等,展示了实现微服务架构的完整蓝图,并让读者了解到如何借助于微服务来增强和重构现有的遗留系统。不管你是还没听过或者刚接触过微服务的新手,还是正在尝试借助微服务解放生产力的开发人员或者运维人员,或者是立志于构建高可用可伸缩的微服务体系的架构师,阅读本书,对读者必有裨益。本书的每一个章节都是相关领域的专家经过多年的技术积累提炼而成,秉承以理论为基础,以大量企业实战案例为核心,深入全面的介绍了微服务架构的实施方法以及在实施过程中所遇到的问题和解决方案,是一本内容详实、“可落地”的理论实践相结合的技术书籍。内容简介本书共分为十四章:第一章:微服务概述从软件架构的发展历程讲起,分别对单体架构、SOA架构和微服务架构的演进过程做了深入浅出的讲解,同时也深入介绍了微服务架构的特点,本章以宏观的视角为读者打开微服务的大门。第二章:微服务领域驱动设计本章介绍了领域驱动设计是什么,常见的领域架构有哪些,如何将领域驱动应用到微服务中,以及如何使用领域驱动进行合理的服务划分等,帮助读者在正式学习微服务前修炼内功。第三章:Dubbo原理与实现目前Dubbo已经被阿里巴巴技术团队重新维护并且得到了大力的发展和推广,使用Dubbo依然可以很好的进行微服务建设,本章较为深入的讲解了Dubbo的使用和技巧,以及通过源码的深入分析能够让读者对Dubbo的原理实现有一个全面的认识。第四章:Spring Cloud实战案例Spring Boot/Cloud是目前较为流行的微服务框架,本章以大量的实战案例为读者讲解如何才能应用好Spring Cloud框架,以及如何避免在使用过程中遇到的坑。第五章:微服务稳定性保证常用手段当业务发展越来越快,规模也越来越大的情况下,我们所面临的就是如何在服务越来越多的情况下保证微服务架构的稳定性,本章带领读者逐步揭开保障稳定性的常用技巧和手段。第六章:微服务下事务的一致性保证本章介绍了从本地事务到分布式事务的演变,深入分析了微服务在强一致性场景和最终一致性场景下的解决方案,探讨了二阶段提交协议、三阶段提交协议、TCC 模式、补偿模式、可靠事件模式等。同时,对开源项目的分布式事务进行解读,包括 RocketMQ 和 ServiceComb。第七章:微服务亿级网关设计本章从百亿流量交易系统微服务网关(API Gateway)的现状和面临问题出发,阐述微服务架构与 API 网关的关系,理顺流量网关与业务网关的脉络,带来最全面的 API 网关知识与经验。第八章:微服务编排本章以Netflix Conductor框架为核心,从框架的使用和原理深入介绍了什么是微服务编排,为微服务执行复杂的业务逻辑提供了一种新的思路。第九章:微服务统计与数据抽取方案在微服务架构下,服务必将越来越多,在这各情况下如何进行数据统计和分析将变得非常困难,本章将深入讲解如何从不同服务的数据库中抽取数据到统一的大数据平台中,帮忙使用者更方便的进行数据的统计。第十章:微服务双活体系建设在企业发展规模越来越大的情况下,用户对系统的稳定性要求也越来越高,那么单机房布署势必成为发展的瓶颈,本章将带领读者从零开始以实际案例出发进行同城双活的建设。第十一章:基于支付场景下的微服务改造和性能优化本章从实际的案例出发,在具体的支付业务场景下,从一个新项目开始逐步讲解如何利用领域驱动划分服务,如何利用微服务框架进行服务治理,以及项目完成后怎样提升微服务架构的性能。第十二章:遗留系统的微服务改造本章介绍了遗留系统的微服务架构改造,梳理了代码分层结构的转变,提出一个新的代码分层思路来应对微服务的流行与普及,并深入思考了遗留系统的债券,深入探讨单体系统拆分服务的方法论。同时,对遗留系统的微服务架构改造的解决方案给出 9 个切实可行的核心实践思路。第十三章:Service Mesh的入门与案例随着微服务的持续发展,下一代微服务架构已然出现,本章将深入介绍Service Mesh发展历程,以及结合具体案例带领读者使用Istio进行具体实践。第十四章:微服务监控实战本章重点介绍APM的原理,从零开始开发APM监控系统,还深入介绍Prometheus的安装和原理,以及如何使用Prometheus进行监控和预警。1.6 架构的不同风格典型的企业级应用系统或者互联网应用系统一般都是通过Web提供一组业务服务能力。这类系统包括提供给用户操作的、运行于浏览器中、具有UI的业务逻辑展示和输入部分,运行于服务器端、用后端编程语言构建的业务逻辑处理部分,以及用于存储业务数据的关系数据库或其他类型的存储软件。根据软件系统在运行期的表现风格和部署结构,我们可以粗略地将其划分为两大类:1) 整个系统的所有功能单元,整体部署到同一个进程(所有代码可以打包成1个或多个文件),我们可以称之为“单体架构”(Monolithic Architecture);2) 整个系统的功能单元分散到不同的进程,然后由多个进程共同提供不同的业务能力,我们称之为“分布式架构”(Distributed Architecture);任何一个体系(产品、平台、商业模式等)如果想要发展壮大,途径只有两个模式:a) 容器模式:从外部提供越来越多的资源和能力,注入到体系的内部,不断的从内扩充自己。单体架构的系统类似这种模式。b) 生态模式:以自己的核心能力为内核,持续的在外部吸引合作者,形成一个可以不断成长的生态体系。分布式架构越来越像这种模式。再结合软件系统在整个生命周期的特点,我们可以进一步区分不同的架构风格。对于单体架构,我们根据设计期和开发实现期的不同模式和划分结构,可以分为:简单单体模式:代码层面没有拆分,所有的业务逻辑都在一个项目(project)里打包成一个二进制的编译后文件,通过这个文件进行部署,并提供业务能力;MVC模式:系统内每个模块的功能组件按照不同的职责划分为模型(Model)、视图(View)、控制器(Controller)等角色,并以此来组织研发实现工作;前后端分离模式:将前后端代码耦合的设计改为前端逻辑和后端逻辑独立编写实现的处理模式;组件模式:系统的每一个模块拆分为一个子项目(subproject),每个模块独立编译打包成一个组件,然后所有需要的组件一起再部署到同一个容器里;类库模式:A系统需要复用B系统的某些功能,这时可以直接把B系统的某些组件作为依赖库,打包到A系统来使用。对于分布式架构,我们根据设计期的架构思想和运行期的不同结构,可以分为:面向服务架构(Service Oriented Architecture,SOA):以业务服务的角度和服务总线的方式(一般是WebService与ESB)考虑系统架构和企业IT治理;分布式服务架构(Distributed Service Architecture,DSA):基于去中心化的分布式服务框架与技术,考虑系统架构和服务治理;微服务架构(MicroServices Architecture,MSA):微服务架构可以看做是面向服务架构和分布式服务架构的拓展,使用更细粒度的服务(所以叫微服务)和一组设计准则来考虑大规模的复杂系统架构设计。此外,传统的企业集成领域的EAI架构模式,本身还是各个系统独立部署,但是各系统之间的部分业务使用特定的技术打通了,因此我们可以看做是单体和分布式之间的过渡状态。也有人把如上的各个架构风格总结为4个大的架构发展阶段,如图1-6所示:1)单体架构阶段2)垂直架构阶段3)SOA架构阶段4)微服务架构阶段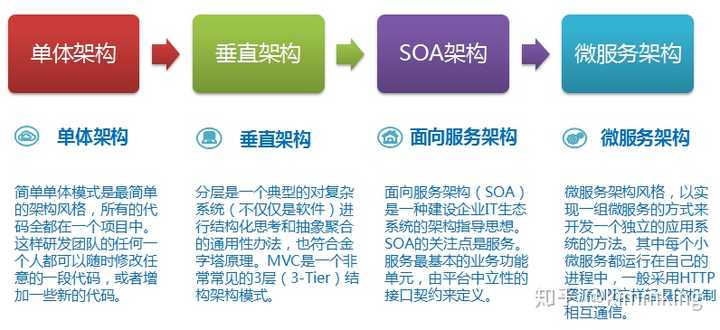 微服务架构发展阶段图1-61.6.1 单体架构:简单单体模式简单单体模式是最简单的架构风格,所有的代码全都在一个项目中。这样研发团队的任何一个人都可以随时修改任意的一段代码,或者增加一些新的代码。开发人员也可以只在自己的电脑上就可以随时开发、调试、测试整个系统的功能。也不需要额外的一些依赖条件和准备步骤,我们就可以直接编译打包整个系统代码,创建一个可以发布的二进制版本。这种方式对于一个新团队的创立初期,需要迅速开始从0到1,抓住时机实现产品最短时间推向市场,可以省去各种额外的设计,直接上手干活,争取了时间,因而是非常有意义的。但是这种简单粗暴的方式对于一个系统的长期稳定发展确实有很多坏处的。但是正如一个新出生的小动物野蛮生长,如果没有正确的教导和规则的约束,最后成为一个忠实的导盲犬还是一条携带病毒的狂犬,就不得而知了。首先,简单单体模式的系统存在代码严重耦合的问题。所有的代码都在一起,就算是按照package来切分了不同的模块,各不同模块的代码还是可以直接相互引用,这就导致了系统内的对象间依赖关系混乱,修改一处代码,可能会影响一大片的功能无法正常使用。为了保障每次上线时的可靠性,我们必须花费很多的精力做大量的回归测试,对于经常需要修改维护的系统,这种代价是可怕的。第二,简单单体模式的系统变更对部署影响大,并且这个问题是所有的单体架构系统都存在的问题。系统作为一个单体部署,每次发布的部署单元就是一个新版本的整个系统,系统内的任何业务逻辑调整都会导致整个系统的重新打包,部署、停机、再重启,进而导致了系统的停机发布时间较长。每次发布上线都是生产系统的重大变更,这种部署模式大大提升了系统风险,降低了系统的可用性。第三,简单单体模式的系统影响开发效率。如果一个使用Java的简单单体项目代码超过100万行,那么在一台笔记本电脑上修改了代码后执行自动编译,可能需要等待十分钟以上,并且内存可能不够编译过程使用,这是非常难以忍受的。第四,简单单体模式打包后的部署结构可能过于庞大,导致业务系统启动很慢,进而也会影响系统的可用性。这一条也是所有单体架构的系统都有的问题。第五,扩展性受限,也是所有单体架构的一个问题。如果任何一个业务存在性能问题,那么都需要考虑多部署几个完整的实例的集群,或者再加上负载均衡设备,才能保证整个系统的性能可以支撑用户的使用。所以,简单单体模式比较适用于规模较小的系统,特别是需要快速推出原型实现,以质量换速度的场景。1.6.2 分布式架构:面向服务架构(SOA)随着IT技术逐渐成为各行各业的基础性支撑技术之一,并且很多大型公司内部的IT系统规模越来越大,传统架构思想的不足越来越明显。针对如何更好的利用企业内部的各个IT系统能力,解决数据孤岛问题,整合业务功能,先是出现了企业应用集成(Enterprise Application Integration,EAI)解决方案,即通过对现有各系统的数据接口改造,实现系统互通(特别是异构系统),这样不同系统的数据就可以被整合到一起了。在大量的EAI项目实施的基础上,架构设计关注的不仅仅是单个的项目,而是企业的整个IT系统集合。架构师们以超越单体架构的分布式思想和业务服务能力的角度来看待问题,这样面向服务架构即SOA就发展起来了。2006年IBM、Oracle、SAP、普元公司等一起建立了OSOA联盟,共同制定 SCA/SDO标准。2007年4月,国际标准组织OASIS宣布成立OASIS Open Composite Services Architecture (Open CSA) 委员会,自此,OSOA的职能移转至Open CSA组织。SOA的概念最初由Gartner公司提出,2000 年以后,业界普遍认识到SOA思想的重要性。从2005年开始,SOA推广和普及工作开始加速,几乎所有关心软件行业发展的人士都开始把目光投向SOA,各大厂商也通过建立厂商间的协作组织共同努力制定中立的SOA标准:SCA/SDO规范。同时产生了一个Apache基金会顶级项目Tuscany作为SCA/SDO的参考实现。SCA和SDO构成了SOA编程模型的基础。经过10多年的广泛探索研究和实际应用,SOA本身的理论、相关技术、工具等也已经发展到成熟、稳定的阶段,在信息化系统建设时普遍采用了SOA架构思想。1.6.2.1 服务与SOA面向服务架构(SOA)是一种建设企业IT生态系统的架构指导思想。SOA的关注点是服务。服务最基本的业务功能单元,由平台中立性的接口契约来定义。通过将业务系统服务化,可以将不同模块解耦,各种异构系统间可以轻松实现服务调用、消息交换和资源共享。1) 从宏观的视角来看,不同于以往的孤立业务系统,SOA强调整个企业IT生态环境是一个大的整体。整个IT生态中的所有业务服务构成了企业的核心IT资源。各系统的业务拆解为不同粒度和层次的模块和服务,服务可以组装到更大的粒度,不同来源的服务可以编排到同一个处理流程,实现非常复杂的集成场景和更加丰富的业务功能。2) 从研发的视角来看,系统的复用可以从以前代码级的粒度,扩展到业务服务的粒度;能够快速应对业务需求和集成需求的变更。3) 从管理的角度来看,SOA从更高的层次对整个企业IT生态进行统一的设计与管理,对消息处理与服务调用进行监控,优化资源配置,降低系统复杂度和综合成本,为业务流程梳理和优化提供技术支撑。在SOA体系下,应用软件被划分为具有不同功能的服务单元,并通过标准的软件接口把这些服务联系起来,以SOA架构实现的企业应用可以更灵活快速地响应企业业务变化,实现新旧软件资产的整合和复用,降低软件整体拥有成本。1.6.2.2 SOA战略SOA的实施对整个IT生态环境都有重要的影响,作为一种重大的IT变革和技术决策,必然要自上而下的进行。必须获得管理层的支持,由技术决策层面直接推动,并和技术部门、相关业务部门一起,根据目前各个IT业务系统的现状,统一规划SOA战略和分阶段目标,制定可行方案与计划步骤,逐步推进实施。1.6.2.3 SOA落地方式SOA的落地方式与水平,跟企业IT特点、服务能力和发展阶段直接相关。目前常见的落地方式主要有分布式服务化和集中式管理两种。1) 分布式服务化互联网类型的企业,业务与技术发展快,数据基数与增量都大,并发访问量高,系统间依赖关系复杂、调用频繁,分布式服务化与服务治理迫在眉睫。通过统一的服务化技术手段,进一步实现服务的注册与寻址、服务调用关系查找、服务调用与消息处理监控、服务质量与服务降级等等。现有的一些分布式服务化技术有dubbo(基于java)、finagle(基于scala)和ICE(跨平台)等。2) 集中式管理化传统企业的IT内部遗留系统包袱较重,资源整合很大一部分是需要打通新旧技术体系的任督二脉,所以更偏重于以esb作为基础支撑技术,以整合集成为核心,将各个新旧系统的业务能力逐渐的在ESB容器上聚合和集成起来。比较流行的商业ESB有IBM的WMB和oracle的osb,开源esb有mule、servicemix、jbossesb、wso2esb和openesb。商业的esb,一般来说除了功能丰富以外,配套设置都比较齐全,对于比较简单的场景来说可以做到开箱即用,维护性也比较强,但是一般来说过于复杂非常难用、内部基本是黑盒、而且很贵。开源的esb,由于开发成本和通用性开放性的考虑,往往在esb server上做的比较强大、扩展性比较好,但是配套设置做的很差(这也是绝大多数开源项目共有的问题,不仅是开源esb的问题)。对企业来说可管理性非常重要,选择开源esb的话,这一块需要结合企业的实际情况,一步步的积累,下大功夫来自己做好。一方面,集中式管理的SOA,其优势在于管理和集成企业内部各处散落的业务服务能力,同时一个明显的不足在于其中心化的架构方法,并不同解决各个系统自己内部的问题。另一方面,随着自动化测试技术、轻量级容器技术等相关技术的发展,分布式服务技术越来越像微服务架构方向发展。EIP(Enterprise Integration Patterns,企业集成模式)是集成领域的圣经,也是各种MOM和ESB的理论基础。我们在MQ和ESB中常见的各种概念和术语,基本都是来自于EIP,比如消息代理、消息通道、消息端点、消息路由、消息转换、消息增强、信息分支、消息聚合、消息分解、消息重排等等,并在《企业集成模式:设计、构建及部署消息传递解决方案》一书中详细的描述了它们的内容与特点。EIP的直接实现一般叫EIP框架,开源的知名EIP框架有两个:camel和spring integration。EIP可以作为ESB的基础骨架,在这个基础上填充其他必要的部分,定制出来一个ESB容器。EIP的介绍可以看这里:http://www.enterpriseintegrationpatterns.com/1.6.2.4 SOA的两大基石:RPC与MQSOA关注于系统的服务化,不同系统服务间的相互通信就成为了一个重要的话题。并且随着RPC和MQ技术的发展,这两种技术逐渐成为SOA的两大基石,也是分布式技术体系里的重要基础设施。1) RPC(Remote Procedure Call,远程过程调用)两个不同系统间的数据通信,往往可以通过socket+自定义数据报文来实现。但是这种方式比较繁琐,需要针对每个通信场景定义自己的数据格式和报文标准,甚至交互的行为、异常和错误的处理等等。有没有一种通用的技术手段呢?答案就是RPC技术。RPC是一种通用性的系统通信手段,使得我们可以像调用本地方法一样调用远程系统提供的方法。一个场景的RPC机制如图1-7:
微服务架构发展阶段图1-61.6.1 单体架构:简单单体模式简单单体模式是最简单的架构风格,所有的代码全都在一个项目中。这样研发团队的任何一个人都可以随时修改任意的一段代码,或者增加一些新的代码。开发人员也可以只在自己的电脑上就可以随时开发、调试、测试整个系统的功能。也不需要额外的一些依赖条件和准备步骤,我们就可以直接编译打包整个系统代码,创建一个可以发布的二进制版本。这种方式对于一个新团队的创立初期,需要迅速开始从0到1,抓住时机实现产品最短时间推向市场,可以省去各种额外的设计,直接上手干活,争取了时间,因而是非常有意义的。但是这种简单粗暴的方式对于一个系统的长期稳定发展确实有很多坏处的。但是正如一个新出生的小动物野蛮生长,如果没有正确的教导和规则的约束,最后成为一个忠实的导盲犬还是一条携带病毒的狂犬,就不得而知了。首先,简单单体模式的系统存在代码严重耦合的问题。所有的代码都在一起,就算是按照package来切分了不同的模块,各不同模块的代码还是可以直接相互引用,这就导致了系统内的对象间依赖关系混乱,修改一处代码,可能会影响一大片的功能无法正常使用。为了保障每次上线时的可靠性,我们必须花费很多的精力做大量的回归测试,对于经常需要修改维护的系统,这种代价是可怕的。第二,简单单体模式的系统变更对部署影响大,并且这个问题是所有的单体架构系统都存在的问题。系统作为一个单体部署,每次发布的部署单元就是一个新版本的整个系统,系统内的任何业务逻辑调整都会导致整个系统的重新打包,部署、停机、再重启,进而导致了系统的停机发布时间较长。每次发布上线都是生产系统的重大变更,这种部署模式大大提升了系统风险,降低了系统的可用性。第三,简单单体模式的系统影响开发效率。如果一个使用Java的简单单体项目代码超过100万行,那么在一台笔记本电脑上修改了代码后执行自动编译,可能需要等待十分钟以上,并且内存可能不够编译过程使用,这是非常难以忍受的。第四,简单单体模式打包后的部署结构可能过于庞大,导致业务系统启动很慢,进而也会影响系统的可用性。这一条也是所有单体架构的系统都有的问题。第五,扩展性受限,也是所有单体架构的一个问题。如果任何一个业务存在性能问题,那么都需要考虑多部署几个完整的实例的集群,或者再加上负载均衡设备,才能保证整个系统的性能可以支撑用户的使用。所以,简单单体模式比较适用于规模较小的系统,特别是需要快速推出原型实现,以质量换速度的场景。1.6.2 分布式架构:面向服务架构(SOA)随着IT技术逐渐成为各行各业的基础性支撑技术之一,并且很多大型公司内部的IT系统规模越来越大,传统架构思想的不足越来越明显。针对如何更好的利用企业内部的各个IT系统能力,解决数据孤岛问题,整合业务功能,先是出现了企业应用集成(Enterprise Application Integration,EAI)解决方案,即通过对现有各系统的数据接口改造,实现系统互通(特别是异构系统),这样不同系统的数据就可以被整合到一起了。在大量的EAI项目实施的基础上,架构设计关注的不仅仅是单个的项目,而是企业的整个IT系统集合。架构师们以超越单体架构的分布式思想和业务服务能力的角度来看待问题,这样面向服务架构即SOA就发展起来了。2006年IBM、Oracle、SAP、普元公司等一起建立了OSOA联盟,共同制定 SCA/SDO标准。2007年4月,国际标准组织OASIS宣布成立OASIS Open Composite Services Architecture (Open CSA) 委员会,自此,OSOA的职能移转至Open CSA组织。SOA的概念最初由Gartner公司提出,2000 年以后,业界普遍认识到SOA思想的重要性。从2005年开始,SOA推广和普及工作开始加速,几乎所有关心软件行业发展的人士都开始把目光投向SOA,各大厂商也通过建立厂商间的协作组织共同努力制定中立的SOA标准:SCA/SDO规范。同时产生了一个Apache基金会顶级项目Tuscany作为SCA/SDO的参考实现。SCA和SDO构成了SOA编程模型的基础。经过10多年的广泛探索研究和实际应用,SOA本身的理论、相关技术、工具等也已经发展到成熟、稳定的阶段,在信息化系统建设时普遍采用了SOA架构思想。1.6.2.1 服务与SOA面向服务架构(SOA)是一种建设企业IT生态系统的架构指导思想。SOA的关注点是服务。服务最基本的业务功能单元,由平台中立性的接口契约来定义。通过将业务系统服务化,可以将不同模块解耦,各种异构系统间可以轻松实现服务调用、消息交换和资源共享。1) 从宏观的视角来看,不同于以往的孤立业务系统,SOA强调整个企业IT生态环境是一个大的整体。整个IT生态中的所有业务服务构成了企业的核心IT资源。各系统的业务拆解为不同粒度和层次的模块和服务,服务可以组装到更大的粒度,不同来源的服务可以编排到同一个处理流程,实现非常复杂的集成场景和更加丰富的业务功能。2) 从研发的视角来看,系统的复用可以从以前代码级的粒度,扩展到业务服务的粒度;能够快速应对业务需求和集成需求的变更。3) 从管理的角度来看,SOA从更高的层次对整个企业IT生态进行统一的设计与管理,对消息处理与服务调用进行监控,优化资源配置,降低系统复杂度和综合成本,为业务流程梳理和优化提供技术支撑。在SOA体系下,应用软件被划分为具有不同功能的服务单元,并通过标准的软件接口把这些服务联系起来,以SOA架构实现的企业应用可以更灵活快速地响应企业业务变化,实现新旧软件资产的整合和复用,降低软件整体拥有成本。1.6.2.2 SOA战略SOA的实施对整个IT生态环境都有重要的影响,作为一种重大的IT变革和技术决策,必然要自上而下的进行。必须获得管理层的支持,由技术决策层面直接推动,并和技术部门、相关业务部门一起,根据目前各个IT业务系统的现状,统一规划SOA战略和分阶段目标,制定可行方案与计划步骤,逐步推进实施。1.6.2.3 SOA落地方式SOA的落地方式与水平,跟企业IT特点、服务能力和发展阶段直接相关。目前常见的落地方式主要有分布式服务化和集中式管理两种。1) 分布式服务化互联网类型的企业,业务与技术发展快,数据基数与增量都大,并发访问量高,系统间依赖关系复杂、调用频繁,分布式服务化与服务治理迫在眉睫。通过统一的服务化技术手段,进一步实现服务的注册与寻址、服务调用关系查找、服务调用与消息处理监控、服务质量与服务降级等等。现有的一些分布式服务化技术有dubbo(基于java)、finagle(基于scala)和ICE(跨平台)等。2) 集中式管理化传统企业的IT内部遗留系统包袱较重,资源整合很大一部分是需要打通新旧技术体系的任督二脉,所以更偏重于以esb作为基础支撑技术,以整合集成为核心,将各个新旧系统的业务能力逐渐的在ESB容器上聚合和集成起来。比较流行的商业ESB有IBM的WMB和oracle的osb,开源esb有mule、servicemix、jbossesb、wso2esb和openesb。商业的esb,一般来说除了功能丰富以外,配套设置都比较齐全,对于比较简单的场景来说可以做到开箱即用,维护性也比较强,但是一般来说过于复杂非常难用、内部基本是黑盒、而且很贵。开源的esb,由于开发成本和通用性开放性的考虑,往往在esb server上做的比较强大、扩展性比较好,但是配套设置做的很差(这也是绝大多数开源项目共有的问题,不仅是开源esb的问题)。对企业来说可管理性非常重要,选择开源esb的话,这一块需要结合企业的实际情况,一步步的积累,下大功夫来自己做好。一方面,集中式管理的SOA,其优势在于管理和集成企业内部各处散落的业务服务能力,同时一个明显的不足在于其中心化的架构方法,并不同解决各个系统自己内部的问题。另一方面,随着自动化测试技术、轻量级容器技术等相关技术的发展,分布式服务技术越来越像微服务架构方向发展。EIP(Enterprise Integration Patterns,企业集成模式)是集成领域的圣经,也是各种MOM和ESB的理论基础。我们在MQ和ESB中常见的各种概念和术语,基本都是来自于EIP,比如消息代理、消息通道、消息端点、消息路由、消息转换、消息增强、信息分支、消息聚合、消息分解、消息重排等等,并在《企业集成模式:设计、构建及部署消息传递解决方案》一书中详细的描述了它们的内容与特点。EIP的直接实现一般叫EIP框架,开源的知名EIP框架有两个:camel和spring integration。EIP可以作为ESB的基础骨架,在这个基础上填充其他必要的部分,定制出来一个ESB容器。EIP的介绍可以看这里:http://www.enterpriseintegrationpatterns.com/1.6.2.4 SOA的两大基石:RPC与MQSOA关注于系统的服务化,不同系统服务间的相互通信就成为了一个重要的话题。并且随着RPC和MQ技术的发展,这两种技术逐渐成为SOA的两大基石,也是分布式技术体系里的重要基础设施。1) RPC(Remote Procedure Call,远程过程调用)两个不同系统间的数据通信,往往可以通过socket+自定义数据报文来实现。但是这种方式比较繁琐,需要针对每个通信场景定义自己的数据格式和报文标准,甚至交互的行为、异常和错误的处理等等。有没有一种通用的技术手段呢?答案就是RPC技术。RPC是一种通用性的系统通信手段,使得我们可以像调用本地方法一样调用远程系统提供的方法。一个场景的RPC机制如图1-7: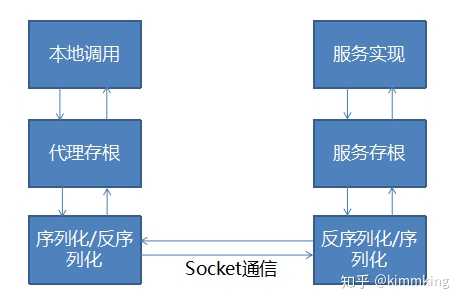 RPC机制图1-7RPC的调用关系里,我们把提供具体的调用方法的系统叫服务提供者(Provider),调用服务的系统称为服务消费者(Consumer)。把对象转换为以便于网络传输的二进制或文本数据的过程,叫做序列化(Serialization);二进制或文本数据再还原为对象的过程,叫做反序列化(Deserialization)。我们可以看到,典型的RPC处理机制包括两部分:通信协议,可以是基于tcp的,也可以是基于http的。数据格式,一般是一套序列化+反序列化机制。常见的RPC技术有Cobra、RMI、.NET Remoting、WebService、JSON-RPC、XML-RPC、Hessian、Thrift、Protocol Buffer、gRPC等等。按照序列化机制的特点,我们可以把RPC技术分为文本的(WebService、JSON-RPC、XML-RPC等)和二进制的(RMI、Hessian、Thrift、Protocol Buffer等)。按照常见的通信协议来看,我们又可以分为基于HTTP的(WebService、Hessian等)和基于TCP的(RMI、.NET Remoting等)。按照是否可以用于多个不同平台,又可以分为平台特定的(RMI是Java平台特定的、.NET Remoting是.NET平台特定的)和平台无关的(比如WebService、JSON-RPC、Hessian等可以用于http://Java.Net\PHP\Python等就是平台无关的)。在Java里,我们一般可以基于JDK自带的动态代理机制+Java的对象序列化方式实现一个简单的RPC,但是由于动态代理和Java对象序列化都比较低效,导致这种方式性能较低。目前更常见的是基于AOP和代码生成技术实现stub和skeleton,然后用一个紧凑的二进制序列化方式,实现一个高效的RPC框架。按照调用方式来看,RPC有四种模式:RR(Request-Response)模式,又叫请求响应模式,指每个调用都要有具体的返回结果信息。Oneway模式,又叫单向调用模式,调用即返回,没有响应的信息。Future模式,又叫异步模式,返回拿到一个Future对象,然后执行完获取到返回结果信息。Callback模式,又叫回调模式,处理完请求以后,将处理结果信息作为参数传递给回调函数进行处理。这四种调用模式中,前两种最常见,后两种一般是RR和Oneway方式的包装,所以从本质上看,RPC一般对于客户端的来说是一种同步的远程服务调用技术。与其相对应的,一般来说MQ恰恰是一种异步的调用技术。2) MQ(Message Queue,消息队列)异步的远程调用,如果能同时存在很多个请求,该如何处理呢?进一步地,由于不能立即拿到处理结果,假若需要考虑失败策略,重试次数等,应该怎么设计呢?如果有N个不同系统相互之间都有RPC调用,这时候整个系统环境就是一个很大的网状结构,依赖关系有N*(N-1)/2个。任何一个系统出问题,都会影响剩下N-1个系统,怎么降低这种耦合呢?如图1-8所示:
RPC机制图1-7RPC的调用关系里,我们把提供具体的调用方法的系统叫服务提供者(Provider),调用服务的系统称为服务消费者(Consumer)。把对象转换为以便于网络传输的二进制或文本数据的过程,叫做序列化(Serialization);二进制或文本数据再还原为对象的过程,叫做反序列化(Deserialization)。我们可以看到,典型的RPC处理机制包括两部分:通信协议,可以是基于tcp的,也可以是基于http的。数据格式,一般是一套序列化+反序列化机制。常见的RPC技术有Cobra、RMI、.NET Remoting、WebService、JSON-RPC、XML-RPC、Hessian、Thrift、Protocol Buffer、gRPC等等。按照序列化机制的特点,我们可以把RPC技术分为文本的(WebService、JSON-RPC、XML-RPC等)和二进制的(RMI、Hessian、Thrift、Protocol Buffer等)。按照常见的通信协议来看,我们又可以分为基于HTTP的(WebService、Hessian等)和基于TCP的(RMI、.NET Remoting等)。按照是否可以用于多个不同平台,又可以分为平台特定的(RMI是Java平台特定的、.NET Remoting是.NET平台特定的)和平台无关的(比如WebService、JSON-RPC、Hessian等可以用于http://Java.Net\PHP\Python等就是平台无关的)。在Java里,我们一般可以基于JDK自带的动态代理机制+Java的对象序列化方式实现一个简单的RPC,但是由于动态代理和Java对象序列化都比较低效,导致这种方式性能较低。目前更常见的是基于AOP和代码生成技术实现stub和skeleton,然后用一个紧凑的二进制序列化方式,实现一个高效的RPC框架。按照调用方式来看,RPC有四种模式:RR(Request-Response)模式,又叫请求响应模式,指每个调用都要有具体的返回结果信息。Oneway模式,又叫单向调用模式,调用即返回,没有响应的信息。Future模式,又叫异步模式,返回拿到一个Future对象,然后执行完获取到返回结果信息。Callback模式,又叫回调模式,处理完请求以后,将处理结果信息作为参数传递给回调函数进行处理。这四种调用模式中,前两种最常见,后两种一般是RR和Oneway方式的包装,所以从本质上看,RPC一般对于客户端的来说是一种同步的远程服务调用技术。与其相对应的,一般来说MQ恰恰是一种异步的调用技术。2) MQ(Message Queue,消息队列)异步的远程调用,如果能同时存在很多个请求,该如何处理呢?进一步地,由于不能立即拿到处理结果,假若需要考虑失败策略,重试次数等,应该怎么设计呢?如果有N个不同系统相互之间都有RPC调用,这时候整个系统环境就是一个很大的网状结构,依赖关系有N*(N-1)/2个。任何一个系统出问题,都会影响剩下N-1个系统,怎么降低这种耦合呢?如图1-8所示: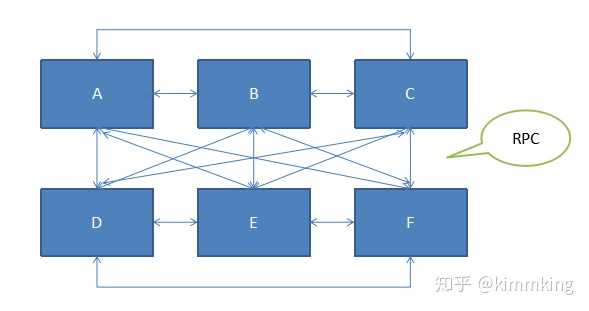 系统依赖关系图1-8基于这些问题,我们发展出来了消息队列(MQ)技术,所有的处理请求先作为一个消息发送到MQ(一般我们叫做broker),接着处理消息的系统从MQ拿到消息并进行处理。这样就实现了各个系统间的解耦,同时可以把失败策略、重试等作为一个机制,对各个应用透明,直接在MQ与各调用方的应用接口层面实现即可,如图1-9所示:
系统依赖关系图1-8基于这些问题,我们发展出来了消息队列(MQ)技术,所有的处理请求先作为一个消息发送到MQ(一般我们叫做broker),接着处理消息的系统从MQ拿到消息并进行处理。这样就实现了各个系统间的解耦,同时可以把失败策略、重试等作为一个机制,对各个应用透明,直接在MQ与各调用方的应用接口层面实现即可,如图1-9所示: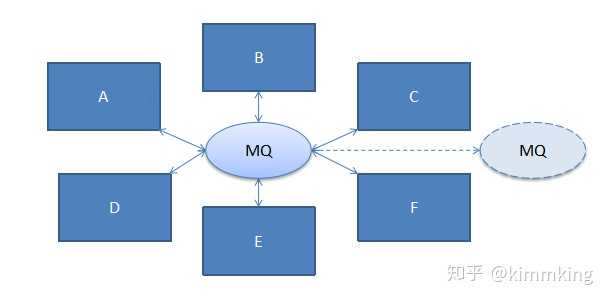 基于MQ的系统依赖关系图1-9一般来说,我们把发送消息的系统称为消息生产者(message producer),接受处理消息的系统称为消息消费者(message consumer)。根据消息处理的特点,我们又可以总结两种消息模式:点对点模式(Point to Point,PTP),一个生产者发送的每一个消息,都只能有一个消费者能消费,看起来消息就像从一个点传递到了另外一个点。发布订阅模式(Publish-Subscribe,PubSub),一个生产者发送的每一个消息,都会发送到所有订阅了此队列的消费者,这样对这个消息感兴趣的系统都可以拿到这个消息。通过这两种消息模式的灵活应用以及功能扩展,我们可以实现各种具体的消息应用场景,比如高并发下的订单异步处理,海量日志数据的分析处理等等。如果要总结一下消息队列在各类架构设计中能起到的作用,一般有如下几点:为系统增加了通用性的异步业务处理能力,这个前面讨论过了。降低系统间的耦合性,无论是开发期的引用关系依赖,还是运行期的调用关系依赖,都明显简化或降低了。通信的双方只需要定义好消息的数据格式(消息头有什么字段,消息体是什么格式的数据),就可以各自开发和测试,最后再各自上线即可集成到一起。提升了系统间通信可靠性,无论是从通信本身的可靠性上(请求响应机制、重试),还是业务意义上(处理顺序、事务、失败策略),都相比RPC等方式有所增强。提升了系统的业务缓冲能力,一般又叫削峰填谷,指的是经过MQ做为中间的缓冲,如果业务量突然增大时可以先把处理请求缓冲到队列中,再根据业务消费处理能力逐个消息处理,保障了系统不会因为突然爆发的大量请求而过载瘫痪,影响系统的连续服务能力。增强了系统的扩展能力,通过消息队列处理的业务,消费端的处理能力如果不够,一般可以随时多加几个消费者来处理,从而可以直接扩展系统的业务处理能力,而不需要额外的代价。1.6.3 分布式架构:微服务架构(MSA)随着目前互联网的飞速发展,我们发现大型项目的设计开发和维护过程中,存在如下几个重点的困难点:扩容困难我们之前开发项目用的是虚拟机,每次上线项目需要加机器总会遇到资源不足的情况,还要走非常复杂工单审批流程,还要与运维人员不断PK,才能申请下来资源,整个流程冗长,机器资源申请困难。部署困难每次上线采用专门的人进行布署,上线之前需要与上线人员沟通上线的环境,防止上线出错。发布回滚困难每次上线发现问题后,需要重新从SVN/GIT主干上面进行代码编译,但是有时候会因为各种问题回滚失败,而且重新编译很耗时导致回滚缓慢。适配新技术困难如果打算在不同的模块采用不同的语言开发,或者想在架构中做技术升级都很困难或者不支持。快速开发困难复杂项目中采用单体应用或者简单的分拆成2-3个系统,里面集成了太多功能模块,无法快速进行功能开发并且很容易牵一发动全身。测试困难测试人员没有自动化测试框架,或者Mock系统,导致只能采用简单的人工测试流程,而且还经常发生功能覆盖不全面等问题。学习困难业务变化日新月薪,功能和项目结构都太复杂,整个项目中的逻辑关系相互关联影响,采用的技术五花八门,技术本身的更新换代也很快,导致技术人员学习曲线非常陡峭。我们把遇到以上这些问题的项目也叫做单体项目。1.6.3.1 什么是微服务The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services , which may be written in different programming languages and use different data storage technologies.引用自http://martinfowler.com/articles/microservices.html 通过Martin Flowler的这段微服务描述,可以抽象出以下几个关键点:由一些独立的服务共同组成应用系统每个服务单独布署、独立跑在自己的进程中每个服务都是独立的业务分布式管理通过几个关键点可以看出微服务重在独立布署和独立业务,而所谓的微服务,并不是越小越好,而是通过团队规模和业务复杂度由粗到细的划分过程,所遵循的原则是松耦合和高内聚,如图1-10所示:
基于MQ的系统依赖关系图1-9一般来说,我们把发送消息的系统称为消息生产者(message producer),接受处理消息的系统称为消息消费者(message consumer)。根据消息处理的特点,我们又可以总结两种消息模式:点对点模式(Point to Point,PTP),一个生产者发送的每一个消息,都只能有一个消费者能消费,看起来消息就像从一个点传递到了另外一个点。发布订阅模式(Publish-Subscribe,PubSub),一个生产者发送的每一个消息,都会发送到所有订阅了此队列的消费者,这样对这个消息感兴趣的系统都可以拿到这个消息。通过这两种消息模式的灵活应用以及功能扩展,我们可以实现各种具体的消息应用场景,比如高并发下的订单异步处理,海量日志数据的分析处理等等。如果要总结一下消息队列在各类架构设计中能起到的作用,一般有如下几点:为系统增加了通用性的异步业务处理能力,这个前面讨论过了。降低系统间的耦合性,无论是开发期的引用关系依赖,还是运行期的调用关系依赖,都明显简化或降低了。通信的双方只需要定义好消息的数据格式(消息头有什么字段,消息体是什么格式的数据),就可以各自开发和测试,最后再各自上线即可集成到一起。提升了系统间通信可靠性,无论是从通信本身的可靠性上(请求响应机制、重试),还是业务意义上(处理顺序、事务、失败策略),都相比RPC等方式有所增强。提升了系统的业务缓冲能力,一般又叫削峰填谷,指的是经过MQ做为中间的缓冲,如果业务量突然增大时可以先把处理请求缓冲到队列中,再根据业务消费处理能力逐个消息处理,保障了系统不会因为突然爆发的大量请求而过载瘫痪,影响系统的连续服务能力。增强了系统的扩展能力,通过消息队列处理的业务,消费端的处理能力如果不够,一般可以随时多加几个消费者来处理,从而可以直接扩展系统的业务处理能力,而不需要额外的代价。1.6.3 分布式架构:微服务架构(MSA)随着目前互联网的飞速发展,我们发现大型项目的设计开发和维护过程中,存在如下几个重点的困难点:扩容困难我们之前开发项目用的是虚拟机,每次上线项目需要加机器总会遇到资源不足的情况,还要走非常复杂工单审批流程,还要与运维人员不断PK,才能申请下来资源,整个流程冗长,机器资源申请困难。部署困难每次上线采用专门的人进行布署,上线之前需要与上线人员沟通上线的环境,防止上线出错。发布回滚困难每次上线发现问题后,需要重新从SVN/GIT主干上面进行代码编译,但是有时候会因为各种问题回滚失败,而且重新编译很耗时导致回滚缓慢。适配新技术困难如果打算在不同的模块采用不同的语言开发,或者想在架构中做技术升级都很困难或者不支持。快速开发困难复杂项目中采用单体应用或者简单的分拆成2-3个系统,里面集成了太多功能模块,无法快速进行功能开发并且很容易牵一发动全身。测试困难测试人员没有自动化测试框架,或者Mock系统,导致只能采用简单的人工测试流程,而且还经常发生功能覆盖不全面等问题。学习困难业务变化日新月薪,功能和项目结构都太复杂,整个项目中的逻辑关系相互关联影响,采用的技术五花八门,技术本身的更新换代也很快,导致技术人员学习曲线非常陡峭。我们把遇到以上这些问题的项目也叫做单体项目。1.6.3.1 什么是微服务The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services , which may be written in different programming languages and use different data storage technologies.引用自http://martinfowler.com/articles/microservices.html 通过Martin Flowler的这段微服务描述,可以抽象出以下几个关键点:由一些独立的服务共同组成应用系统每个服务单独布署、独立跑在自己的进程中每个服务都是独立的业务分布式管理通过几个关键点可以看出微服务重在独立布署和独立业务,而所谓的微服务,并不是越小越好,而是通过团队规模和业务复杂度由粗到细的划分过程,所遵循的原则是松耦合和高内聚,如图1-10所示: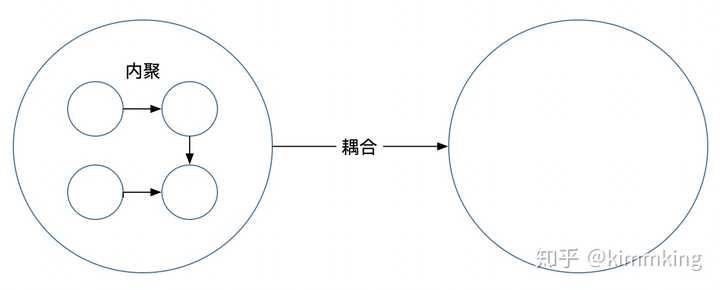 微服务架构图1-10松耦合修改一个服务不需要同时修改另一个,每个微服务都可以单独修改和布署高内聚把相关的事务放在一起,把不相关的排除出去,聚集在一起的事务只能干同一件事1.6.3.2 微服务和SOA的区别1、微服务只是一种为经过良好架构设计的SOA解决方案,是面向服务的交付方案。2、微服务更趋向于以自治的方式产生价值。3、微服务与敏捷开发的思想高度结合在一起,服务的定义更加清晰,同时减少了企业ESB开发的复杂性。4、微服务是SOA思想的一种提炼!5、SOA是重ESB,微服务是轻网关。1.6.3.3 大规模使用微服务使用微服务也就面临着由单体项目向微服务项目过渡,而采用了微服务架构后也就意味着服务之间的调用链路会比以前延长了很多,在调用链路上发生故障的几率也就随之增大,同时调用链路越长,性能越会受影响。微服务架构中是存在很多陷阱的,并不是简单的拿来使用就可以,所以企业要大规模使用微服务不仅仅是从思想和业务上面进行合理划分,还需要诸多技术组件以及高效的运维来协同合作,如图1-11所示。
微服务架构图1-10松耦合修改一个服务不需要同时修改另一个,每个微服务都可以单独修改和布署高内聚把相关的事务放在一起,把不相关的排除出去,聚集在一起的事务只能干同一件事1.6.3.2 微服务和SOA的区别1、微服务只是一种为经过良好架构设计的SOA解决方案,是面向服务的交付方案。2、微服务更趋向于以自治的方式产生价值。3、微服务与敏捷开发的思想高度结合在一起,服务的定义更加清晰,同时减少了企业ESB开发的复杂性。4、微服务是SOA思想的一种提炼!5、SOA是重ESB,微服务是轻网关。1.6.3.3 大规模使用微服务使用微服务也就面临着由单体项目向微服务项目过渡,而采用了微服务架构后也就意味着服务之间的调用链路会比以前延长了很多,在调用链路上发生故障的几率也就随之增大,同时调用链路越长,性能越会受影响。微服务架构中是存在很多陷阱的,并不是简单的拿来使用就可以,所以企业要大规模使用微服务不仅仅是从思想和业务上面进行合理划分,还需要诸多技术组件以及高效的运维来协同合作,如图1-11所示。 微服务架构图1-11防止雪崩当一个服务无法承受大请求压力的时候,是否会影响所依赖的其他服务?这时候可以考虑限流等措施。功能降级当某个服务出现故障时,是否有容错手段能够让业务继续跑下去,而不影响整体应用。冥等当用户多次下同一订单时,得到的结果永远同一个。缓存当请求量较大时,为避免对数据库造成较大压力,可以适当将一些变化较小,读取量较大的数据放入缓存。超时超时时间对于调用服务来说非常重要,超时时间设置太长可能会把整体系统拖慢,而设置短了又会造成调用服务未完成而返回,我们在实际工作中需要根据业务场景进行分析,选择一个恰当的超时设定值。熔断使用熔断器(断路器),当请求下游的服务时发生了一定数量的失败后,熔断器打开,接下来的请求快速返回失败。过一段时间后再来查看下游服务是否已恢复正常,重置熔断器。服务隔离当所调用的服务发生故障的时候,上游服务能够隔离故障确保业务能够继续运行下去可伸缩当并发量较大,原有服务集群无法满足现有业务场景时,可以采用扩容策略,而当并发量较小时,服务集群可以采用缩容策略,以节省资源。
微服务架构图1-11防止雪崩当一个服务无法承受大请求压力的时候,是否会影响所依赖的其他服务?这时候可以考虑限流等措施。功能降级当某个服务出现故障时,是否有容错手段能够让业务继续跑下去,而不影响整体应用。冥等当用户多次下同一订单时,得到的结果永远同一个。缓存当请求量较大时,为避免对数据库造成较大压力,可以适当将一些变化较小,读取量较大的数据放入缓存。超时超时时间对于调用服务来说非常重要,超时时间设置太长可能会把整体系统拖慢,而设置短了又会造成调用服务未完成而返回,我们在实际工作中需要根据业务场景进行分析,选择一个恰当的超时设定值。熔断使用熔断器(断路器),当请求下游的服务时发生了一定数量的失败后,熔断器打开,接下来的请求快速返回失败。过一段时间后再来查看下游服务是否已恢复正常,重置熔断器。服务隔离当所调用的服务发生故障的时候,上游服务能够隔离故障确保业务能够继续运行下去可伸缩当并发量较大,原有服务集群无法满足现有业务场景时,可以采用扩容策略,而当并发量较小时,服务集群可以采用缩容策略,以节省资源。



![linuex查看繁忙_[个人笔记] 关于linux的常见问题合集](/images/no-images.jpg)