文章目录
- Redis数据类型的详解与使用场景
- 1-1 NoSQL的概述
- 1. 概述
- 2. 为什么需要NoSQL
- 3. NoSQL产品
- 4. 分类
- 5. 特点
- 2-1 Redis的概述
- 1. 概述
- 2. 应用场景
- 3. Redis的特点
- 4. Redis为什么如此快
- A. 数据保存在内存中
- B. 底层数据结构
- C. 单线程模型
- D. IO多路复用
- 3-1 Redis的安装
- 1. CentOS 安装 Redis
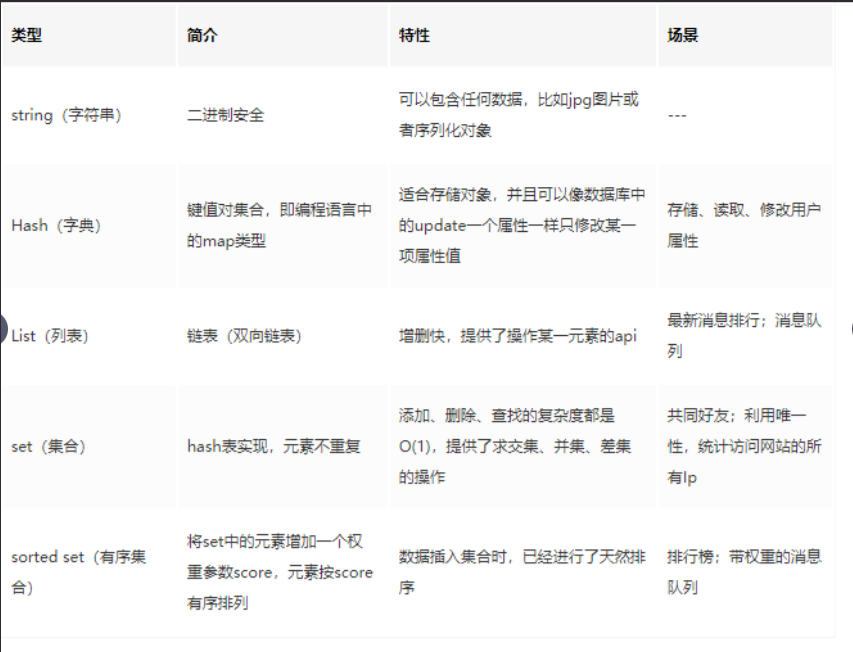
- 4-1 Redis的数据类型
- 1. Redis的数据类型
- 2. 规范
- 3. 内存管理
- 4. 简单介绍
- 4-2 Redis的数据类型之字符串
- 1. 字符串
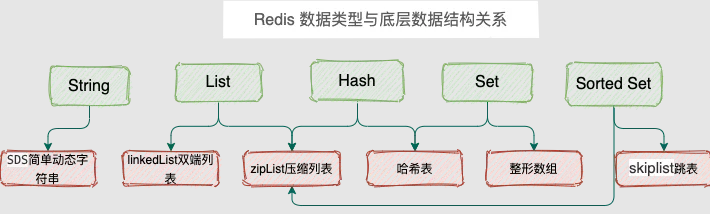
- 2. 底层实现
- 3. 命令
- 4. 场景:缓存
- 5. 场景:计数器
- 6. 场景:共享session
- 7. 场景:限速
- 8. 场景:分布式锁
- 9. 场景:ID生成器
- 4-3 Redis的数据类型之哈希
- 1. 哈希
- 2. 底层实现
- 3. 命令
- 4. 场景:缓存
- 5. 场景:短网址生成程序
- 6. 场景:实现用户登录会话
- 7. 场景:计数器
- 4-4 Redis的数据类型之列表
- 1. 概述
- 2. 底层实现
- 3. 命令
- 4. 场景:先进先出队列
- 5. 场景:消息队列
- 6. 场景:异步队列
- 7. 场景:栈
- 4-5 Redis的数据类型之集合
- 1. 概述
- 2. 底层实现
- 3. 命令
- 4. 使用场景
- 5. 场景:唯一计数器
- 6. 场景:点赞
- 7. 场景:投票
- 8. 场景:社交关系
- 9. 场景:抽奖
- 10. 场景:共同关注与推荐关注
- 11. 场景:商品筛选器
- 4-6 Redis的数据类型之有序集合
- 1. 概述
- 2. 底层实现
- 3. 命令
- 4. 场景:排行榜
- 5. 场景:时间线
- 6. 场景:商品推荐
- 7. 场景:延时队列
- 8. 其他场景
- 4-7 Redis的数据类型之HyperLogLog
- 1. 概述
- 2. 底层实现
- 3. 命令
- 4. 场景:优化唯一计数器
- 5. 场景:检测重复信息
- 6. 场景:每周/月度/年度计数器
- 4-8 Redis的数据类型之位图
- 1. 概述
- 2. 命令
- 3. 场景:用户行为记录器
- 4. 场景:0-1矩阵
- 5. 场景:紧凑计数器
- 6. 其他场景
- 4-9 Redis的数据类型之地理坐标
- 1. 概述
- 2. 命令
- 3. 场景:用户地理位置程序
- 4. 场景:查找附近用户
- 4-10 Redis的数据类型之流
- 1. 概述
- 2. 底层实现
- 3. 命令
- 4. 场景:消息队列
- 5. 消费者组
- 创建消费者组
- 查看消费者组信息
- 修改消费者组的消息id
- 删除消费者组/消费者
- 读取消费者组的消息
- 消费者
- 6. 场景:消息队列(消费者组)
- 5-1 Redis的通用命令
- 参考
Redis数据类型的详解与使用场景
1-1 NoSQL的概述
1. 概述
NoSQL,Not Only SQL,泛指非关系型数据库。
随 Web2.0 的诞生,传统关系型数据库难以应对 Web2.0,尤其是超大规模的高并发社区。NoSQL 在当今大数据程序下较为流行。
2. 为什么需要NoSQL
关系型数据库容易暴露如下问题:
- High performance - 高并发读写问题
- Huge Storage - 海量数据的高效率存储和访问
- High Scalability && High Availability -高可扩展性和高可用性
扩展:Web 1.0时,浏览网页都是不能互动的,而Web 2.0时,基于Web的时代,这时候已经可以互动了,比如微博对他人进行点赞等操作,但是用的传统关系型数据库已经不再是最合适的选择,尤其对于超大规模和高并发SNS交互型类型的网站。这里就会暴露很多问题,如下三个问题:
-
High performance - 高并发读写问题,因此数据库的并发负载就非常高了。
-
Huge Storage - 海量数据的高效率存储和访问(例如:某软件、每月2.5亿数据需要插入,如果查询在这2.5亿,那么对于关系型数据库效率是非常低的)。
-
High Scalability && High Availability -高可扩展性和高可用性,基于Web的架构中,数据库很难横向扩展,当一个应用的用户量和访问量与日俱增的时候,关系型数据库无法像应用服务器、数据库服务器这些通过添加硬件来搭建负载均衡,这样对于数据库系统的升级和扩展是很痛苦的事情(往往需要停机维护,数据迁移)。
3. NoSQL产品
主流产品有:Redis、mongoDB、CouchDB、Cassandra、riak、membase
4. 分类
四大分类:
- 键值(Key-Value)存储:比如Redis,优点是快速查询,缺点:存储的数据缺少结构化。
- 列存储
- 文档数据库:比如mongoDB,优点:要求数据格式不是很严格。缺点:查询性能不是很好,缺少统一的查询语法。
- 图形数据库
| 分类 | 实例 | 应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值对(key-value) | Redis、Voldemort | 内存缓存,用于处理大量数据的高访问负载,也可用于日志系统等 | key 指向 value 的键值对,通常是用 HashTable 来实现 | 查找速度快 | 数据无结构化,通常只被当做字符串或二进制数据 |
| 列存储数据库 | HBase、Riak | 分布式文件系统 | 以列簇式存储,讲同一列数据存储在一起 | 1. 查找速度快 2. 扩展性强 3. 更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | MongoDb、CouchDB | Web 应用,类似于 Key-Value | key-value 对应的键值对,value 为结构化的数据 | 1. 数据结构要求宽松 2. 表结构可变,无需像关系型数据库一样预先定义表结构 | 查询性能低,且查询语法不统一 |
| 图形数据库(Graph) | Neo4j、InfoGrid | 社交网络、推荐系统等 | 图结构 | 可以利用图结构相关算法,如最短路径寻址、N度关系查找等 | 许多时候需要对整个图进行计算才能得到最终结果,效率不高;而且做分布式集群较困难 |
5. 特点
- 易扩展:由于属于非关系型的,数据之间没有关系,所以非常易扩展
- 灵活的数据模型:不需要对读写的数据建立字段
- 大数据量,高性能:对于大数据量和高并发的读写性能支持很好,官方给定数据,写操作 8w次/s,读操作 11w次/s
- 高可用:在不影响系统性能情况下,可以使用框架
2-1 Redis的概述
1. 概述
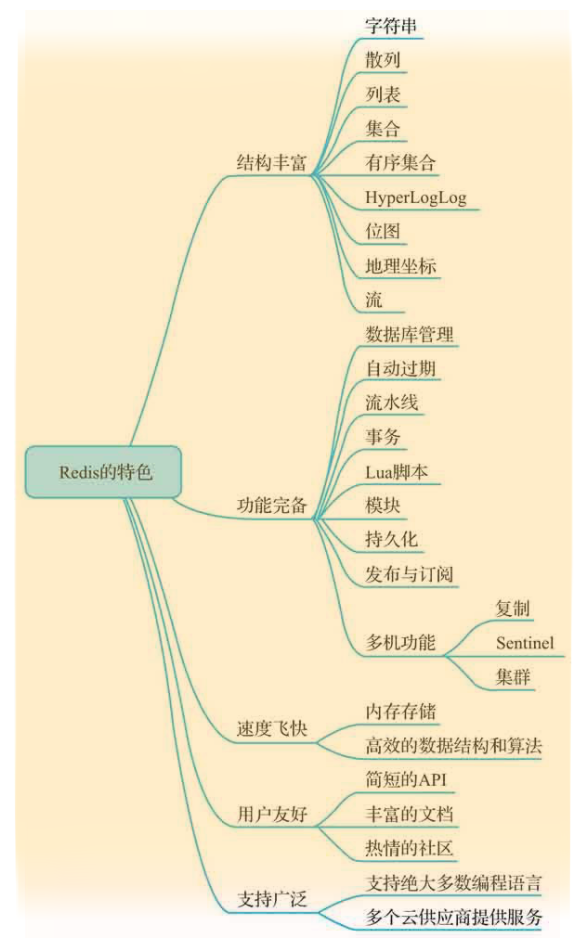
Redis,是C语言开发的开源的高性能的键值对的数据库,通过提供多种键值数据类型来适应不同场景下的存储需求,目前支持的键值数据类型有很多种,支持的键值数据类型:
- 字符串类型
- 列表类型
- 有序集合类型
- 散列类型
- 集合类型
2. 应用场景
- 缓存:数据的查询,新闻和商品的查询等,聊天室的在线好友列表
- 任务队列
- 应用排行榜
- 网站访问统计
- 数据过期处理
- 分布式集群架构中的session分离
3. Redis的特点
- 性能优秀,数据在内存中,读写速度非常快,支持并发 10W QPS。
- 单进程单线程,是线程安全的,采用 IO 多路复用机制。
- 丰富的数据类型,支持字符串(strings)、散列(hash )、列表(lists)、集合(sets)、有序集合(sorted sets)、HyperLogLog、位图、流、地理坐标等。
- 支持数据持久化。可以将内存中数据保存在磁盘中,重启时加载。
- 不仅可单机使用,还可多机使用,支持主从复制,哨兵(Sentinel)和集群功能。
- 功能完备,Redis提供了很多非常实用的附加功能,比如自动过期、流水线、事务、数据持久化等。
- 可以用作分布式锁。
- 可以作为消息中间件使用,支持发布订阅。
如图:
4. Redis为什么如此快
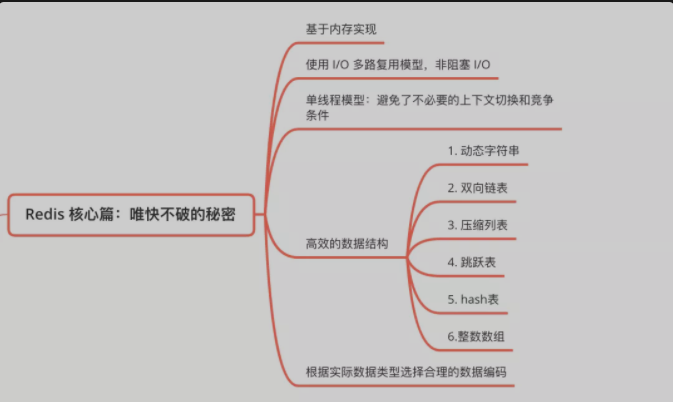
A. 数据保存在内存中
Redis数据保存在内存中,读写操作只需要访问内存,不需要磁盘IO
B. 底层数据结构
Redis的数据是以key:value的格式存储在散列表中的,时间复杂度为:o(1)
Redis为value定义了丰富的数据结构,包括动态字符串、双向链表、压缩列表、hash、跳表和整数数组,可以根据value的特性选择最高效的数据结构
C. 单线程模型
Redis的网络IO和数据读写使用单线程模型,可以绑定CPU,这避免了线程上下文切换带来的开销。
注意:Redis 6.0对网络请求引入了多线程模型,但读写操作还是单线程。
如下图:
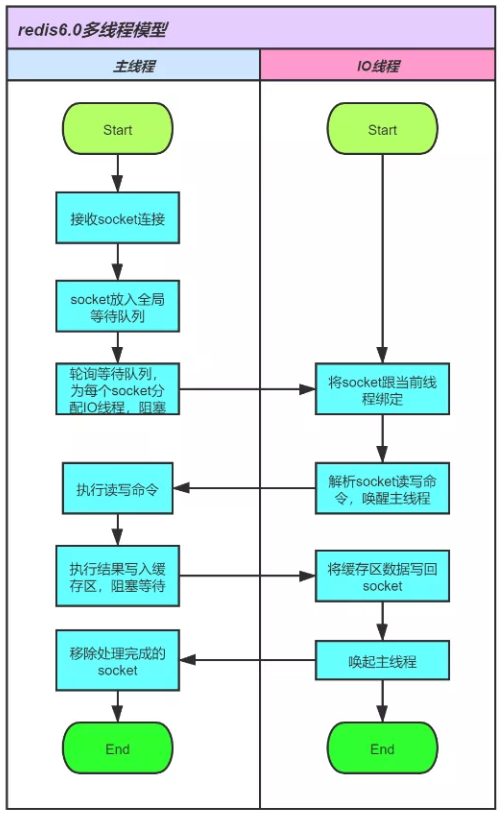
D. IO多路复用
Redis采用epoll的网络模型,如下图:
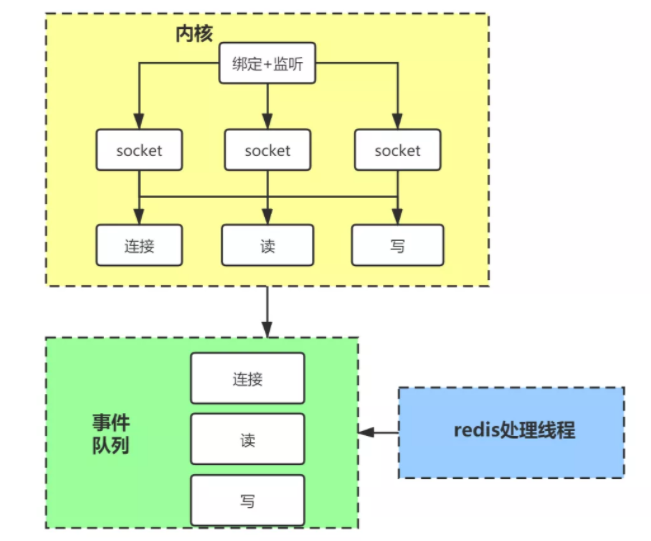
内核会一直监听新的 socket 连接事件的和已建立 socket 连接的读写事件,把监听到的事件放到事件队列,Redis 使用单线程不停的处理这个事件队列,这避免了阻塞等待连接和读写事件到来。
这些事件绑定了回调函数,会调用 Redis 的处理函数进行处理。
3-1 Redis的安装
Redis官方并不支持Windows系统,所以Windows下可通过虚拟机或Docker等手段进行安装,但如果是只用来测试的话,也可以通过下载msi文件进行下载安装,下载地址为:
https://github.com/microsoftarchive/redis/releases/tag/win-3.2.100
注意:Windows下的安装包还停留在3.2版本且很久没更新,只用来测试,不建议生产环境使用。
这里主要是介绍Linux下的安装,主要有几种方式:
- Docker安装
- Github源码编译安装
- 直接yum install
1. CentOS 安装 Redis
安装步骤:
A. 安装编译器
yum install -y gcc-c++
B. 官网下载Redis:https://redis.io/download
wget https://download.redis.io/releases/redis-6.0.8.tar.gz
也可去官网下载最新的稳定版本。
C. 解压
tar -zxvf redis-6.0.8.tar.gz
D. 编译安装到指定安装目录
cd redis-6.0.8 && make && make PREFIX=/usr/local/redis install
安装目录可自定义,我这里是/usr/local/redis
E. 复制redis.conf到安装目录
cp redis.conf /usr/local/redis
F. 修改redis.conf
vim /usr/local/redis/redis.conf# 修改daemonize为yes,即可以后台模板运行
daemonize yes
注意:如需要更改redis的端口也可以在这里面改,默认端口是6379。
注意:如需要设置密码也同样在这里改,默认是无密码的。
G. 启动服务端
cd /usr/local/redis && ./bin/redis-server ./redis.conf
可以通过ps -ef | grep redis来查看是否启动,默认端口是6379
H. 终止
cd /usr/local/redis && ./bin/redis-cli shutdown
也可以通过kill - 9 进程号来终止,但是不建议。
I. 连接Redis
redis-cli
即可进入Redis客户端
补充:
一般redis服务器不会直接通过./redis-server来启动,一般是会通过systemd来做成守护进程进行启动关闭等。
systemd添加redis服务
# vi /etc/systemd/system/redis.service[Unit]
Description=redis-server
After=network.target[Service]
Type=forking
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
PrivateTmp=true[Install]
WantedBy=multi-user.target
注意:ExecStart需要配置为redis的路径
设置开机启动以及启动redsi-serser
systemctl daemon-reload
systemctl start redis.service
systemctl enable redis.service
创建软连接【非必要,把redis-cli简化为redis】
ln -s /usr/local/redis/bin/redis-cli /usr/bin/redis
服务操作命令
systemctl start redis.service #启动redis服务
systemctl stop redis.service #停止redis服务
systemctl restart redis.service #重新启动服务
systemctl status redis.service #查看服务当前状态
systemctl enable redis.service #设置开机自启动
systemctl disable redis.service #停止开机自启动
4-1 Redis的数据类型
1. Redis的数据类型
- 字符串(String)
- 哈希(hash)
- 列表(list)
- 集合(set)
- 有序集合(sorted set)
- 基数(HyperLogLog)
- 位图(Bitmaps)
- 流(Streams)
- 地理坐标(Geospatial)
注意:很多教程只介绍了前5种数据类型,但官网是有提及支持的数据类型是9种。
但其实呢,HyperLogLog底层是String实现,相当于是对String数据类型封装的应用程序,而Bitmap底层也是String实现,赋值的每一个bit均对应ASCII码的二进制位。Geospatial是基于有序集合实现的。Streams是Redis5.0引入的一个新的数据类型,支持消费者组,借鉴Kafka设计的支持多播的可持久化消息队列(支持group,不支持partition)。
2. 规范
- key值不要太长也不能太短,应该有一个统一的命名规范,一般来说不使用特殊字符,使用冒号或下划线进行连接
- key必须有合理的过期时间
- value值不要过大,不要超过100M
3. 内存管理
Redis的所有数据结构都是以唯一的key字符串作为名称,然后通过这个唯一key值来获取相应的value数据,不同类型的数据结构的差异就在于value的结构不一样。如下图:
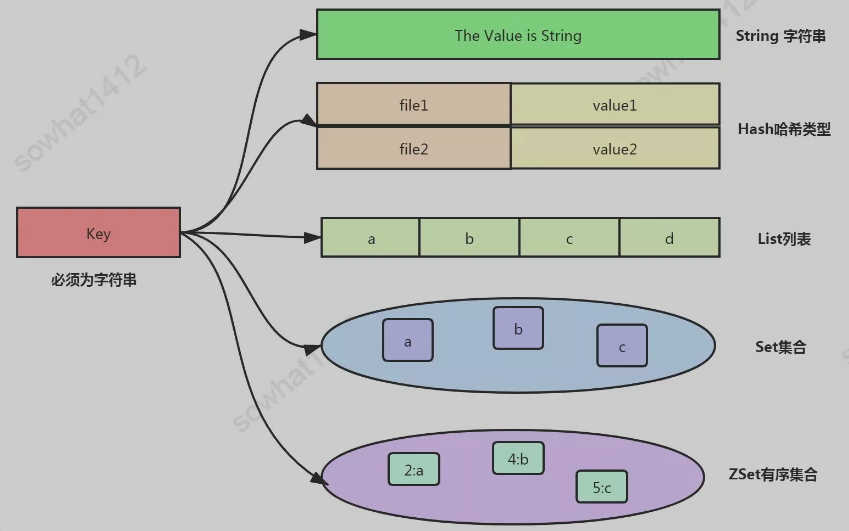
Redis内部使用一个redisObject对象来表示所有的key和value。
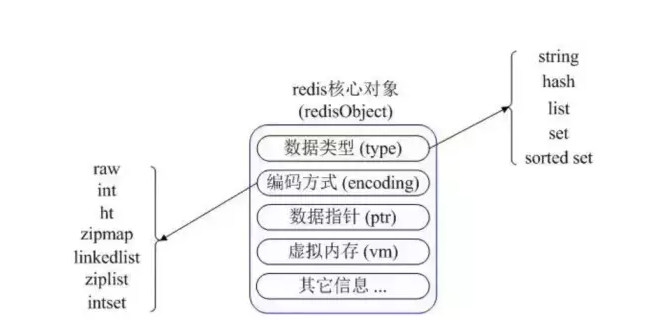
redisObject 最主要的信息如上图所示:
- type 表示一个 value 对象具体是何种数据类型
- encoding 是不同数据类型在 Redis 内部的存储方式
比如:type=string 表示 value 存储的是一个普通字符串,那么 encoding 可以是 raw 或者 int。
4. 简单介绍
4-2 Redis的数据类型之字符串
1. 字符串
- 字符串(String)是最基本的类型,可以理解成与Memcached一样的类型,一个Key对应一个Value,Value不仅是String,也可以是数字
- 字符串类型是二进制安全的,存入和获取的数据相同,可以包含任何数据,比如jpb图片或序列化对象
- Value最多可以容纳的数据长度是512M
- 如果value是一个整数,可以进行自增自减操作,但value的整数范围是在signed long的最大值和最小值之间,超过这个范围会报错
2. 底层实现
内部是一个字符数组,如图:

Redis的字符串是动态字符串,内部结构的实现类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。如图:
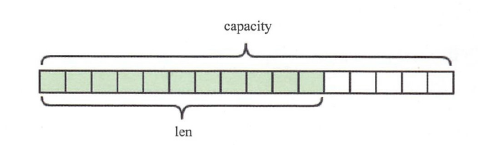
内部为当前字符串分配的实际空间capacity一般要高于实际字符串长度len 。
当字符串长度小于1MB 肘,扩容都是加倍现有的空间。如果字符串长度超过1MB ,扩容时一次只会多扩1MB 的空间。
需要注意的是字符串最大长度为512MB 。
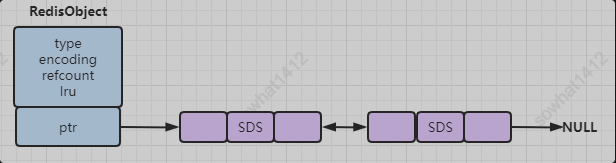
底层是C语言中String用char[]数组表示,源码中用SDS(simple dynamic string)封装char[],这是是Redis存储的最小单元,一个SDS最大可以存储512M信息。
struct sdshdr{unsigned int len; // 标记char[]的长度unsigned int free; //标记char[]中未使用的元素个数char buf[]; // 存放元素的坑
}
Redis对SDS再次封装生成了RedisObject,核心有两个作用:
- 说明是哪种数据类型,string、hash、list、set或者是sorted set
- 里面有指针用来指向SDS
比如当执行set name aaa的时候,其实Redis会创建两个RedisObject对象,键的RedisObject 和 值的RedisOjbect 其中它们type = REDIS_STRING,而SDS分别存储的就是 name 跟 aaa字符串。
并且Redis底层对SDS有如下优化:
- SDS修改后大小 > 1M时 系统会多分配空间来进行
空间预分配。- SDS是
惰性释放空间的,你free了空间,可是系统把数据记录下来下次想用时候可直接使用。不用新申请空间。
3. 命令
# 赋值,注意:Redis 2.6.12版本才有NX、XX的可选项
set 属性名 字符串值 [ex 时间] [NX|XX]# 如属性名没有值才进行设置,如已经有值则设置失败返回nil
set 属性名 字符串值 NX# 获取值,如不存在返回nil
get 属性名# 获取属性的ttl时间
ttl 属性名# 给属性设置过期时间
expire 属性名 秒数# 先获取值再设置,如不存在返回nil且进行设置,注意:获取的是属性名之前的值
getset 属性名 新字符串值# 删除值,成功返回1,失败返回9
del 属性名# 值递增加1,如不存在会默认为0然后加1,如属性名存在但值不为整型的话会报错
incr 属性名# 值递减1,如不存在会默认为0然后减1,如属性名存在但值不为整型的话会报错
decr 属性名# 值递增n,用法类似于incr,只不过n是可以自定义的
incrby 属性名 n# 值递减n
decrby 属性名 n# 值追加字符串n,如不存在则直接追加字符串n,注意是字符串
append 属性名 n# 判断属性名是否存在
exists 属性名# 在指定的 key 不存在时,为 key 设置指定的值,set if not exists,如存在则不做任何操作,该指令在高并发下经常使用,新版本被set 属性 字符串值 EX 时间 NX 替代
setnx 属性名 字符串值
# 等同于 set 属性名 字符串值 NX# 设置多个
mset 属性名1 value1 [属性名2 value2 ...]# 获取多个
mget 属性名1 [属性名2 ...]
比如:
127.0.0.1:6379> set aaa test
OK
127.0.0.1:6379> get aaa
"test"
127.0.0.1:6379> get bbb
(nil)
127.0.0.1:6379> set test test_value ex 20
OK
127.0.0.1:6379> ttl test
(integer) 17
127.0.0.1:6379> getset aaa new_test
"test"
127.0.0.1:6379> get aaa
"new_test"
127.0.0.1:6379> getset ccc test
(nil)
127.0.0.1:6379> get ccc
"test"
127.0.0.1:6379> del ccc
(integer) 1
127.0.0.1:6379> get ccc
(nil)
127.0.0.1:6379> incr num
(integer) 1
127.0.0.1:6379> get num
"1"
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> get num
"2"
127.0.0.1:6379> incr aaa
(error) ERR value is not an integer or out of range
127.0.0.1:6379> decr num
(integer) 1
127.0.0.1:6379> decr num
(integer) 0
127.0.0.1:6379> get num
"0"
127.0.0.1:6379> decr new_num
(integer) -1
127.0.0.1:6379> get new_num
"-1"
127.0.0.1:6379> decr aaa
(error) ERR value is not an integer or out of range
127.0.0.1:6379> decrby num 6
(integer) -6
127.0.0.1:6379> get num
"-6"
127.0.0.1:6379> decrby num2 4
(integer) -4
127.0.0.1:6379> append num2 10
(integer) 4
127.0.0.1:6379> get num2
"-410"
127.0.0.1:6379> append hahha test
(integer) 4
127.0.0.1:6379> get hahha
"test"
4. 场景:缓存
在web服务中,使用MySQL作为数据库,Redis作为缓存。由于Redis具有支撑高并发的特性,通常能起到加速读写和降低后端压力的作用。web端的大多数请求都是从Redis中获取的数据,如果Redis中没有需要的数据,则会从MySQL中去获取,并将获取到的数据写入redis。
import redisclass Cache:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def set(self, key, value):"""把需要被缓存的数据储存到键 key 里面,如果键 key 已经有值,那么使用新值去覆盖旧值。"""self.client.set(key, value)def get(self, key):"""获取储存在键 key 里面的缓存数据,如果数据不存在,那么返回 None 。"""return self.client.get(key)def update(self, key, new_value):"""对键 key 储存的缓存数据进行更新,并返回键 key 在被更新之前储存的缓存数据。如果键 key 之前并没有储存数据,那么返回 None 。"""return self.client.getset(key, new_value)def is_exists(self, key):"""检查给定的字段是否储存了缓存值,是的话返回 True ,否则的话返回 False 。"""return self.client.exists(key)def size(self, key):"""返回目前已缓存的值长度"""return self.client.strlen(key)def delete(self, key):"""删除指定字段储存的缓存值,删除成功时返回 True ,因为缓存值不存在而导致删除失败时返回 False 。"""return self.client.del(key) == 1
5. 场景:计数器
计数器也是构建应用程序时必不可少的组件之一,比如网站的访客数量、用户执行某个操作的次数、某个视频的播放量、论坛帖子的回复数量等,记录这些信息都需要用到计数器。
Redis中有一个字符串相关的命令incr key,incr命令对值做自增操作,返回结果分为以下三种情况:
- 值不是整数,返回错误
- 值是整数,返回自增后的结果
- key不存在,默认键为
0,返回1
比如文章的阅读量,视频的播放量等等都会使用redis来计数,每播放一次,对应的播放量就会加1,同时将这些数据异步存储到数据库中达到持久化的目的。
在必要时,用户还可以通过调用getset方法来清零计数器并获得清零之前的旧值。
import redisclass Counter:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef increase(self, n=1):"""将计数器的值加上 n ,然后返回计数器当前的值。如果用户没有显式地指定 n ,那么将计数器的值加上一。"""return self.client.incr(self.key, n)def decrease(self, n=1):"""将计数器的值减去 n ,然后返回计数器当前的值。如果用户没有显式地指定 n ,那么将计数器的值减去一。"""return self.client.decr(self.key, n)def get(self):"""返回计数器当前的值。"""# 尝试获取计数器当前的值value = self.client.get(self.key)# 如果计数器并不存在,那么返回 0 作为计数器的默认值if value is None:return 0else:# 因为 redis-py 的 get() 方法返回的是字符串值# 所以这里需要使用 int() 函数,将字符串格式的数字转换为真正的数字类型# 比如将 "10" 转换为 10return int(value)def reset(self):"""清零计数器,并返回计数器在被清零之前的值。"""old_value = self.client.getset(self.key, 0)# 如果计数器之前并不存在,那么返回 0 作为它的旧值if old_value is None:return 0else:# 跟 redis-py 的 get() 方法一样, getset() 方法返回的也是字符串值# 所以程序在将计数器的旧值返回给调用者之前,需要先将它转换成真正的数字return int(old_value)
6. 场景:共享session
在分布式系统中,用户的每次请求会访问到不同的服务器,这就会导致session不同步的问题,假如一个用来获取用户信息的请求落在A服务器上,获取到用户信息后存入session。下一个请求落在B服务器上,想要从session中获取用户信息就不能正常获取了,因为用户信息的session在服务器A上,为了解决这个问题,使用redis集中管理这些session,将session存入redis,使用的时候直接从redis中获取就可以了。
7. 场景:限速
为了保障系统的安全性和性能,并保证系统的重要资源不被滥用,应用程序经常会对用户的某些行为进行限制,比如:
- 为了防止网站内容被忘了爬虫抓取,网站管理者通常会限制每个IP地址在固定时间段内能够访问的页面数量,比如1分钟之内最多只能访问30个页面,超过这一限制的用户将被要求进行身份验证,确认本人并非网络爬虫,或者是等到限制解除之后再进行访问。
- 为了防止用户的账号遭到暴力破解,网上银行通常会对访客的密码试错次数进行限制,如果一个访客在尝试登录某个账号的过程中,连续好几次输入了错误的密码,那么这个账号将被冻结,只能等到第二天再尝试登录,有的银行还会向账号持有者的手机发送通知来汇报这一情况。
- 限制输入密码的错误次数
实现这些限制机制的其中一种方法是使用限速器,它可以限制用户在指定时间段之内能够执行某项操作的次数。
限速器,可以使用Redis的字符串来进行实现,限速器程序会把操作的最大可执行次数存储在一个字符串键里面,然后在用户每次尝试执行被限制的操作之前,使用DECR命令将操作的可执行次数减1,最后通过检查可执行次数的值来判断是否执行该操作。
import redisclass Limiter:def __init__(self, key, client=None):def __init__(self, limiter_name, client=None):self.client = client if client else redis.Redis(decode_response=True)self.max_execute_times_key = limiter_name + '::max_execute_times'self.current_execute_times_key = limiter_name + '::current_execute_times'def set_max_execute_times(self, n):"""设置操作的最大可执行次数。"""self.client.set(self.max_execute_times_key, n)# 初始化操作的已执行次数为 0self.client.set(self.current_execute_times_key, 0)def get_max_execute_times(self):"""返回操作的最大可执行次数。"""return int(self.client.get(self.max_execute_times_key))def get_current_execute_times(self):"""返回操作的当前已执行次数。"""current_execute_times = int(self.client.get(self.current_execute_times_key))max_execute_times = self.get_max_execute_times()if current_execute_times > max_execute_times:# 当用户尝试执行操作的次数超过最大可执行次数时# current_execute_times 的值就会比 max_execute_times 的值更大# 为了将已执行次数的值保持在 # 0 <= current_execute_times <= max_execute_times 这一区间# 如果已执行次数已经超过最大可执行次数# 那么程序将返回最大可执行次数作为结果return max_execute_timeselse:# 否则的话,返回真正的当前已执行次数作为结果return current_execute_timesdef still_valid_to_execute(self):"""检查是否可以继续执行被限制的操作,是的话返回 True ,不是的话返回 False 。"""updated_current_execute_times = self.client.incr(self.current_execute_times_key)max_execute_times = self.get_max_execute_times()return (updated_current_execute_times <= max_execute_times)def remaining_execute_times(self):"""返回操作的剩余可执行次数。"""current_execute_times = self.get_current_execute_times()max_execute_times = self.get_max_execute_times()return max_execute_times - current_execute_timesdef reset_current_execute_times(self):"""清零操作的已执行次数。"""self.client.set(self.current_execute_times_key, 0)
8. 场景:分布式锁
分布式锁是一种同步机制,用于保证一项资源在任何时候只能被一个进程使用,如果有其它进程想要使用相同的资源,那么必须等待直到正在使用资源的进程放弃使用为止。
一个锁的实现通常由获取锁和释放锁这两种操作:
- 获取锁一般是通过执行带有NX选项的set命令来实现的,且带有过期时间
- 释放锁虽然可以通过delete方法来进行释放,但为了保证不错删别的进行的锁,一般是用lua脚本来进行释放锁
具体可参考:三种分布式锁的实现
9. 场景:ID生成器
在构建应用程序的时候,经常需要用到各式各样的ID,比如存储用户信息的程序需要创建一个新的用户ID等,ID通常会以数字形式出现,并且通过递增的方式来创建新的ID,Redis的字符串可以通过执行Incr命令来生成新的ID,并且可以通过set命令来保留数字之前的ID,从而避免用户为了得到某个指定的ID而生成大量无效ID。
import redisclass IdGenerator:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef produce(self):"""生成并返回下一个 ID 。"""return self.client.incr(self.key)def reserve(self, n):"""保留前 n 个 ID ,使得之后执行的 produce() 方法产生的 ID 都大于 n 。为了避免 produce() 方法产生重复 ID ,这个方法只能在 produce() 方法和 reserve() 方法都没有执行过的情况下使用。这个方法在 ID 被成功保留时返回 True ,在 produce() 方法或 reserve() 方法已经执行过而导致保留失败时返回 False 。"""result = self.client.set(self.key, n, nx=True)return result is True
4-3 Redis的数据类型之哈希
1. 哈希
- 哈希(Hash)是一个键值(key-value)的集合,是String key 和 String Value的map容器(比如:姓名、年龄),又可称之为字典、散列
- 适合存储对象
- 每一个Hash可以存储4294967295个键值对
- 相比String操作消耗内存与CPU更小,且更节省空间
- 过期功能不能使用在field上,只能作用于key上
- hash在Redis集群架构下不适合大规模使用,hash的会分配槽位,集群中会导致数据过于集中,没办法分片
当hash移除了最后一个元素之后,该数据结构被自动删除,内存被回收。
hash结构也可以用来存储用户信息,与字符串需要一次性全部序列化整个对象不同,hash可以对用户结构中的每个字段单独存储,这样当我们需要获取用户信息时可以进行部分获取。
而以整个字符串的形式去保存用户信息的话, 就只能一次性全部读取,这样就会浪费网络流量。
hash也有缺点,hash结构的存储消耗要高于单个字符串。
两者对比如下:

什么时候选择字符串什么时候使用哈希?对于这个问题,以下总结了一些选择的条件和方法:
- 如果程序需要为每个数据项单独设置过期时间,那么使用字符串键。
- 如果程序需要对数据项执行诸如SETRANGE、GETRANGE或者APPEND等操作,那么优先考虑使用字符串键。当然,用户也可以选择把数据存储在散列中,然后将类似SETRANGE、GETRANGE这样的操作交给客户端执行。
- 如果程序需要存储的数据项比较多,并且希望尽可能地减少存储数据所需的内存,就应该优先考虑使用散列键。
- 如果多个数据项在逻辑上属于同一组或者同一类,那么应该优先考虑使用散列键。
2. 底层实现
底层实现有两种数据结构:
- 压缩列表(ziplist)
- hash表
如果同时满足下面 2 个条件,就使用压缩列表,否则使用 hash 表:
- 字典中每个 entry 的 key/value 都小于 64 字节
- 字典中元素个数小于 512 个
3. 命令
# 存单个
hset 名称 键 值# 存多个
hmset 名称 键1 值1 键2 值2 ...# 取名称的单个键的值,如不存在则返回nil
hget 名称 键# 取名称的多个键的值,如不存在则返回nil
hmget 名称 键1 键2 ...# 删除名称的某个键
hdel 名称 键1 键2 ...# 删除整个名称
del 名称# 获取名称的所有键值,如不存在返回empty list or set
hgetall 名称# 对名称的某个键递增n,如键非整数会报错
hincrby 名称 键 n# 判断名称的某个键是否存在,存在返回1,不存在返回0
hexists 名称 键 # 获取名称下的键值对数量
hlen 名称# 获取名称下的所有键
hkeys 名称# 获取名称下的所有值
hvals 名称# 只在名称不存在的情况下才设置值,设置成功返回1,如已存在返回0
hsetnx 名称 键 值
比如:
127.0.0.1:6379> hset user01 username John
(integer) 0
127.0.0.1:6379> hset user01 age 23
(integer) 0
127.0.0.1:6379> hmset user02 username Hello age 30
OK
127.0.0.1:6379> hget user01 age
"23"
127.0.0.1:6379> hmget user01 age username
1) "23"
2) "John"
127.0.0.1:6379> hdel user02 age
(integer) 1
127.0.0.1:6379> hgetall user02
1) "username"
2) "Hello"
127.0.0.1:6379> del user02
(integer) 1
127.0.0.1:6379> hget user02 age
(nil)
127.0.0.1:6379> hgetall user02
(empty list or set)
127.0.0.1:6379> hincrby user01 age 5
(integer) 28
127.0.0.1:6379> hincrby user01 username 5
(error) ERR hash value is not an integer
127.0.0.1:6379> hexists user02 age
(integer) 0
127.0.0.1:6379> hexists user01 age
(integer) 1
127.0.0.1:6379> hlen user01
(integer) 2
127.0.0.1:6379> hvals user01
1) "John"
2) "28"
4. 场景:缓存
和字符串实现的缓存很类似,最大的区别是字符串是处理的是字符串键,而哈希处理的是散列键。
import redisclass Cache:def __init__(self, hash, client=None):self.client = client if client else redis.Redis(decode_response=True)self.hash = hashdef set(self, field, value):"""将给定的值缓存到散列的指定字段中。"""self.client.hset(self.hash, field, value)def get(self, field):"""从散列的指定字段中获取被缓存的值,如果值不存在,那么返回 None 。"""return self.client.hget(self.hash, field)def is_exists(self, field):"""检查给定的字段是否储存了缓存值,是的话返回 True ,否则的话返回 False 。"""return self.client.hexists(self.hash, field)def size(self):"""返回散列目前已缓存的值数量。"""return self.client.hlen(self.hash)def delete(self, field):"""从散列中删除指定字段储存的缓存值,删除成功时返回 True ,因为缓存值不存在而导致删除失败时返回 False 。"""return self.client.hdel(self.hash, field) == 1
5. 场景:短网址生成程序
Redis的哈希很适合用来存储短网址ID与目标网址之间的映射,所以可以基于Redis的哈希来实现短网址程序。
注意:里面的Cache指的是场景4中实现的Cache类。
import redis
from cache import CacheID_COUNTER = "ShortyUrl::id_counter"
URL_HASH = "ShortyUrl::url_hash"
URL_CACHE = "ShortyUrl::url_cache"class ShortyUrl:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)self.cache = Cache(self.client, URL_CACHE) # 创建缓存对象def shorten(self, target_url):"""为目标网址创建一个短网址 ID 。"""# 尝试在缓存里面寻找目标网址对应的短网址 IDcached_short_id = self.cache.get(target_url)if cached_short_id is not None:return cached_short_idnew_id = self.client.incr(ID_COUNTER)short_id = self.base10_to_base36(new_id)self.client.hset(URL_HASH, short_id, target_url)# 在缓存里面关联起目标网址和短网址 ID# 这样程序就可以在用户下次输入相同的目标网址时# 直接重用已有的短网址 IDself.cache.set(target_url, short_id)return short_iddef restore(self, short_id):"""根据给定的短网址 ID ,返回与之对应的目标网址。"""return self.client.hget(URL_HASH, short_id)def base10_to_base36(number):"""将十进制数字转换为36进制数字"""alphabets = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"result = ""while number != 0 :number, i = divmod(number, 36)result = (alphabets[i] + result)return result or alphabets[0]
6. 场景:实现用户登录会话
为了方便用户,网站一般都会为已登录的用户生成一个加密令牌,然后把这个令牌分别存储在服务器端和客户端,之后每当用户再次访问该网站的时候,网站就可以通过验证客户端提交的令牌来确认用户的身份,从而使得用户不必重复地执行登录操作。
另外,为了防止用户因为长时间不输入密码而遗忘密码,以及为了保证令牌的安全性,网站一般都会为令牌设置一个过期期限(比如一个月),当期限到达之后,用户的会话就会过时,而网站则会要求用户重新登录。
上面描述的这种使用令牌来避免重复登录的机制一般称为登录会话(login session),可以通过使用Redis的哈希来实现。
import redis
import random
from time import time # 获取浮点数格式的 unix 时间戳
from hashlib import sha256# 会话的默认过期时间
DEFAULT_TIMEOUT = 3600*24*30 # 一个月# 储存会话令牌以及会话过期时间戳的散列
SESSION_TOKEN_HASH = "session::token"
SESSION_EXPIRE_TS_HASH = "session::expire_timestamp"# 会话状态
SESSION_NOT_LOGIN = "SESSION_NOT_LOGIN"
SESSION_EXPIRED = "SESSION_EXPIRED"
SESSION_TOKEN_CORRECT = "SESSION_TOKEN_CORRECT"
SESSION_TOKEN_INCORRECT = "SESSION_TOKEN_INCORRECT"def generate_token():"""生成一个随机的会话令牌。"""random_string = str(random.getrandbits(256)).encode('utf-8')return sha256(random_string).hexdigest()class LoginSession:def __init__(self, user_id, client=None):self.client = client if client else redis.Redis(decode_response=True)self.user_id = user_iddef create(self, timeout=DEFAULT_TIMEOUT):"""创建新的登录会话并返回会话令牌,可选的 timeout 参数用于指定会话的过期时间(以秒为单位)。"""# 生成会话令牌user_token = generate_token()# 计算会话到期时间戳expire_timestamp = time()+timeout# 以用户 ID 为字段,将令牌和到期时间戳分别储存到两个散列里面self.client.hset(SESSION_TOKEN_HASH, self.user_id, user_token)self.client.hset(SESSION_EXPIRE_TS_HASH, self.user_id, expire_timestamp)# 将会话令牌返回给用户return user_tokendef validate(self, input_token):"""根据给定的令牌验证用户身份。这个方法有四个可能的返回值,分别对应四种不同情况:1. SESSION_NOT_LOGIN —— 用户尚未登录2. SESSION_EXPIRED —— 会话已过期3. SESSION_TOKEN_CORRECT —— 用户已登录,并且给定令牌与用户令牌相匹配4. SESSION_TOKEN_INCORRECT —— 用户已登录,但给定令牌与用户令牌不匹配"""# 尝试从两个散列里面取出用户的会话令牌以及会话的过期时间戳user_token = self.client.hget(SESSION_TOKEN_HASH, self.user_id)expire_timestamp = self.client.hget(SESSION_EXPIRE_TS_HASH, self.user_id)# 如果会话令牌或者过期时间戳不存在,那么说明用户尚未登录if (user_token is None) or (expire_timestamp is None):return SESSION_NOT_LOGIN# 将当前时间戳与会话的过期时间戳进行对比,检查会话是否已过期# 因为 HGET 命令返回的过期时间戳是字符串格式的# 所以在进行对比之前要先将它转换成原来的浮点数格式if time() > float(expire_timestamp):return SESSION_EXPIRED# 用户令牌存在并且未过期,那么检查它与给定令牌是否一致if input_token == user_token:return SESSION_TOKEN_CORRECTelse:return SESSION_TOKEN_INCORRECTdef destroy(self):"""销毁会话。"""# 从两个散列里面分别删除用户的会话令牌以及会话的过期时间戳self.client.hdel(SESSION_TOKEN_HASH, self.user_id)self.client.hdel(SESSION_EXPIRE_TS_HASH, self.user_id)
7. 场景:计数器
使用字符串类型可以实现计数器程序,同样也可以使用哈希来实现计数器。
和字符串实现的不一样:
- 允许用户将多个相关联的计数器存储到同一个散列键中实行集中管理,而不必像字符串计数器那样,为每个计数器单独设置一个字符串键
- 通过对散列中的不同字段执行HINCRBY命令,程序可以对指定的计数器执行加法操作和减法操作,而不会影响到存储在同一散列中的其他计数器
import redisclass Counter:def __init__(self, hash_key, counter_name, client=None):self.client = client if client else redis.Redis(decode_response=True)self.hash_key = hash_keyself.counter_name = counter_namedef increase(self, n=1):"""将计数器的值加上 n ,然后返回计数器当前的值。如果用户没有显式地指定 n ,那么将计数器的值加上一。"""return self.client.hincrby(self.hash_key, self.counter_name, n)def decrease(self, n=1):"""将计数器的值减去 n ,然后返回计数器当前的值。如果用户没有显式地指定 n ,那么将计数器的值减去一。"""return self.client.hincrby(self.hash_key, self.counter_name, -n)def get(self):"""返回计数器的当前值。"""value = self.client.hget(self.hash_key, self.counter_name)# 如果计数器并不存在,那么返回 0 作为默认值。if value is None:return 0else:return int(value)def reset(self):"""将计数器的值重置为 0 。"""self.client.hset(self.hash_key, self.counter_name, 0)
4-4 Redis的数据类型之列表
1. 概述
list列表是简单的字符串列表,相当于链表,可以用来当消息队列用,Redis List的实现是一个双向链表,既可以支持反向查找和遍历,更方便操作,不过带来了额外的内存开销。
list结构进行存储的时候,在元素插入的时候,如果是在链表表头或者是结尾插入的话,那么效率是很高效的(快),时间复杂度为O(1),而如果是插入到中间元素的话那么是很低效的(慢),时间复杂度为O(n),同样的,索引定位某个元素也同样是很慢,时间复杂度为:O(n)。
注意:列表中的元素是可以重复出现。
当list弹出了最后一个元素时,该数据结构会被自动删除,内存被回收。
存储list有多种方式:
- ArrayList:使用数据方式,使用索引进行查询,所以速度很快,但在新增/删除的时候涉及到位移操作,所以比较慢,时间复杂度为:O(n)
- LinkedList:使用双向链接方式,每个元素记录前后元素指针,新增/删除的时候只需要改变元素的前后指针,所以很快,时间复杂度为O(1)
- 双向链表增加数据
- 双向链表删除数据
常用数据结构:
- 栈(Stack ),先进后出(FILO):lpush + lpop
- 队列(Queue),先进先出(FIFIO):lpush + rpop
- 阻塞队列(Blocking MQ),消息队列:lpush + brpop
- 有限集合(capped collection):lpush + ltrim
2. 底层实现
底层实现有两种数据结构:
- 压缩列表(ziplist)
- 双向链表
如果同时满足以下条件,则使用压缩列表,否则使用双向列表:
- 列表中单个元素小于64字节
- 列表中的元素个数少于512
压缩列表在内存中是一块连续的内存空间,结构如下:

压缩列表查找时间复杂度为:o(n)
【快速列表】
如果再深入一点,你会发现Redis 底层存储的不是个简单的linkedlist,而是称之为“快速链表” ( quicklist )的一个结构。首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会浪费空间,还会加重内存的碎片化,比如某普通链表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串起来使用。quicklist 既满足了快速的插入删除性能,又不会出现太大的空间冗余。
如图:

3. 命令
# 左侧添加元素
lpush 链表名 元素1 [元素2 ...]# 右侧添加元素
rpush 链表名 元素1 [元素2 ...]# 查看链表,查看全部可以使用lrange 链表名 0 -1
lrange 链表名 起始值 末尾值# 获取左侧第一个值并且删除,如链表不存在或链表无素则返回nil
lpop 链表名# 获取右侧第一个值并且删除,如链表不存在或链表无素则返回nil
rpop 链表名# 获取链表个数
llen 链表名# 左侧添加元素(链表存在且不为空才会添加)
lpushx 链表名 元素# 右侧添加元素(链表存在且不为空才会添加)
rpushx 链表名 元素# 删除链表中从头到尾x个值为y的元素,如果x为0则为全部值为y,如果x为负的则是从尾到头
lrem 链表名 x y# 设置从左到右第n个值的元素的值,如第n个值不存在则报错:(error) ERR index out of range
lset 链表名 n value# 在链表中的元素值前面插入某个元素值,如果元素值不存在会报-1,如果元素值有多个则每个前面都会插入
linsert 链表名 before 元素值 值# 在链表中的元素值后面插入某个元素值,如果元素值不存在会报-1,如果元素值有多个则每个后面都会插入
linsert 链表名 after 元素值 值# 将list1表的开头压入到list2表的结尾,常用于消息队列
rpoplpush list1 list2# 获取指定索引上的元素,索引值可为负值
lindex 链表名 索引值# 阻塞式获取右侧第一个值并且删除,和rpop一样,但如果没有值会阻塞
rpop 链表名
比如:
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> lpush mylist 1 2 3
(integer) 6
127.0.0.1:6379> rpush mylist2 a b c
(integer) 3
127.0.0.1:6379> rpush mylist2 1 2 3
(integer) 6
127.0.0.1:6379> lrange mylist 0 -1
1) "3"
2) "2"
3) "1"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> lrange mylist 0 3
1) "3"
2) "2"
3) "1"
4) "c"
127.0.0.1:6379> lpop mylist
"3"
127.0.0.1:6379> lrange mylist 0 -1
1) "2"
2) "1"
3) "c"
4) "b"
5) "a"
127.0.0.1:6379> rpop mylist
"a"
127.0.0.1:6379> lrange mylist 0 -1
1) "2"
2) "1"
3) "c"
4) "b"
127.0.0.1:6379> llen mylist
(integer) 4
127.0.0.1:6379> lpushx mylist2 ddd
(integer) 7
127.0.0.1:6379> lrange mylist2 0 -1
1) "ddd"
2) "a"
3) "b"
4) "c"
5) "1"
6) "2"
7) "3"
127.0.0.1:6379> lpushx mylist4 value
(integer) 0
127.0.0.1:6379> lrange mylist4 0 -1
(empty list or set)
127.0.0.1:6379> lpush mylist4 1 2 3
(integer) 3
127.0.0.1:6379> lpush mylist4 1 2 3
(integer) 6
127.0.0.1:6379> lrange mylist4 0 -1
1) "3"
2) "2"
3) "1"
4) "3"
5) "2"
6) "1"
127.0.0.1:6379> lrem mylist4 2 3 # 从头到尾删除mylist4中2个值为3的元素
(integer) 2
127.0.0.1:6379> lrange mylist4 0 -1
1) "2"
2) "1"
3) "2"
4) "1"
127.0.0.1:6379> lrem mylist4 -2 1 # 从尾到头删除mylist4中2个值为1的元素
(integer) 2
127.0.0.1:6379> lrange mylist4 0 -1
1) "2"
2) "2"
127.0.0.1:6379> lrange mylist2 0 -1
1) "ddd"
2) "a"
3) "b"
4) "c"
5) "1"
6) "2"
7) "3"
127.0.0.1:6379> lset mylist2 3 new_value # 设置第三个值为new_value
OK
127.0.0.1:6379> lrange mylist2 0 -1
1) "ddd"
2) "a"
3) "b"
4) "new_value"
5) "1"
6) "2"
7) "3"
127.0.0.1:6379> lset mylist2 30 new_value # 设置不存在的值会报错
(error) ERR index out of range
127.0.0.1:6379> linsert mylist2 after ddd after_ddd # 在ddd后面插入新的元素值:after_ddd
(integer) 8
127.0.0.1:6379> lrange mylist2 0 -1
1) "ddd"
2) "after_ddd"
3) "a"
4) "b"
5) "new_value"
6) "1"
7) "2"
8) "3"
127.0.0.1:6379> lpush mylist5 1 2 3
(integer) 3
127.0.0.1:6379> lpush mylist6 a b c
(integer) 3
127.0.0.1:6379> lrange mylist5 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lrange mylist6 0 -1
1) "c"
2) "b"
3) "a"
127.0.0.1:6379> rpoplpush mylist5 mylist6
"1"
127.0.0.1:6379> lrange mylist5 0 -1
1) "3"
2) "2"
127.0.0.1:6379> lrange mylist6 0 -1
1) "1"
2) "c"
3) "b"
4) "a"
4. 场景:先进先出队列
先进先出队列(first in first out queue)是一种非常常见的数据结构,一般都会包含入队(enqueue)和出队(dequeue)这两个操作,其中入队操作会将一个元素放入队列中,而出队操作则会从队列中移除最先入队的元素。
先进先出队列的应用非常广泛,各式各样的应用程序中都有使用。举个例子,很多电商网站都会在节日时推出一些秒杀活动,这些活动会放出数量有限的商品供用户抢购,秒杀系统的一个特点就是在短时间内会有大量用户同时进行相同的购买操作,如果使用事务或者锁去实现秒杀程序,那么就会因为锁和事务的重试特性而导致性能低下,并且由于重试行为的存在,成功购买商品的用户可能并不是最早执行购买操作的用户,因此这种秒杀系统实际上是不公平的。
解决上述问题的方法之一就是把用户的购买操作都放入先进先出队列里面,然后以队列方式处理用户的购买操作,这样程序就可以在不使用锁或者事务的情况下实现秒杀系统,并且得益于先进先出队列的特性,这种秒杀系统可以按照用户执行购买操作的顺序来判断哪些用户可以成功执行购买操作,因此它是公平的。
主要是使用rpush和lpop来实现先进先出队列的。

import redisclass FIFOqueue:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef enqueue(self, item):"""将给定元素放入队列,然后返回队列当前包含的元素数量作为结果。"""return self.client.rpush(self.key, item)def dequeue(self):"""移除并返回队列目前入队时间最长的元素。"""return self.client.lpop(self.key)def count(self):"""返回栈当前包含的元素数量。"""return self.client.llen(self.key)
5. 场景:消息队列
rpoplpush的使用场景非常多,比如微博/Twitter的关注列表,粉丝列表都可以使用List结构来实现。
也可以用在消息队列中,主要是使用List的rpush和lpop操作。
简单的消息队列如下:
import redisclass MessageQueue:def __init__(self, queue_name, client=None):self.client = client if client else redis.Redis(decode_response=True)self.queue_name = queue_namedef add_message(self, message):"""将一条消息放入到队列里面。"""self.client.rpush(self.queue_name, message)def get_message(self, timeout=0):"""从队列里面获取一条消息,如果暂时没有消息可用,那么就在 timeout 参数指定的时限内阻塞并等待可用消息出现。timeout 参数的默认值为 0 ,表示一直等待直到消息出现为止。"""# blpop 的结果可以是 None ,也可以是一个包含两个元素的元组# 元组的第一个元素是弹出元素的来源队列,而第二个元素则是被弹出的元素result = self.client.blpop(self.queue_name, timeout)if result is not None:source_queue, poped_item = resultreturn poped_itemdef len(self):"""返回队列目前包含的消息数量。"""return self.client.llen(self.queue_name)
如下,在消息队列中的消息发送成功存入一个链表(发送成功的),发送失败存入一个链表(发送失败的),一段时间后将发送成功的链表清空,发送失败的链表中的消息继续发送,直到成功后存入成功的链表,目的是为了保证数据的一致性。

或者是实现生产者消费者模式
list1是生产消费队列
list2常用于备份数据
问题:生产者提供消息给消费者的时候(pop),消费者还没处理完就挂了。
解决办法:生产者通过rpoplpush先放到list2,消费者处理完再从list2删掉。
6. 场景:异步队列
Redis 的列表结构常用来做异步队列使用。
将需要延后处理的任务结构体序列化成字符串,塞进Redis的列表,另一个线程从这个列表中轮询数据进行处理。
7. 场景:栈
栈是先进后出的数据结构,跟队列正好相反。拿Redis 的列表数据结构来做栈使用的业务场景并不多见。
主要是使用rpush和rpop来实现的。
import redisclass Stack:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef push(self, item):"""将给定的元素推入到栈中,然后返回栈当前包含的元素数量。"""return self.client.rpush(self.key, item)def pop(self):"""弹出最新被推入到栈中的元素。"""return self.client.rpop(self.key)def count(self):"""返回栈当前包含的元素数量。"""return self.client.llen(self.key)
4-5 Redis的数据类型之集合
1. 概述
- 数据结构和list类似,但和list数据类型不同,Set集合中是不允许出现重复的元素,以及Set是无序的,并且set提供了判断某个成员是否在一个set集合中的方法
- set集合是通过hashtable实现的
- 插入多个重复的元素,set集合只会保留一个
- set集合里面是无序的
- set集合可以用于集合运算操作,效率非常高,比如说差集、并集等
- set可包含的最大元素数量为:429467295
2. 底层实现
内部实现相当于一个特殊的字典,字典中所有的value都是一个值NULL。
底层实现有两种数据结构:
- 有序整数数组
- hash表
如果同时满足以下条件,则使用有序整数数组,否则使用hash表:
- 集合中元素都是整数类型
- 集合中的元素个数不超过512个
3. 命令
# 新增,返回插入成功的个数,0表示插入不成功
sadd set名 值1 [值2 ...]# 删除,返回删除成功的个数,0表示删除不成功
srem set名 值1 [值2 ...]# 查询全部元素,如为空返回:(empty list or set),顺序不固定
smembers set名# 查询元素是否存在,1表示存在,0表示不存在
sismember set名 值# 获取全部元素数量
scard set名# 返回随机一个元素
srandmember set名# 返回差集,即返回set1中set2不存在的元素(与顺序有关)
sdiff set1名 set2名# 返回交集,即返回set1和set2中共同的元素(与顺序无关)
sinter set1名 set2名# 返回并集,即set1和set2中所有元素相加并去掉重复(与顺序无关)
sunion set1名 set2名# 将差集存到新集合中
sdiffstore 新set名 set1名 set2名# 将交集存到新集合中
sinterstore 新set名 set1名 set2名# 将并集存到新集合中
sunionstore 新set名 set1名 set2名# 将元素从一个集合移动到另一个集合中
smove set1名 set2名 值# 随机的从集合中移除指定数量的元素,如不填数量则默认为1,返回被移除的元素
spop set名 [数量]
比如:
127.0.0.1:6379> smembers myset
(empty list or set)
127.0.0.1:6379> sadd myset a b c
(integer) 3
127.0.0.1:6379> smembers myset
1) "b"
2) "a"
3) "c"
127.0.0.1:6379> sadd myset a
(integer) 0
127.0.0.1:6379> sadd myset 1 2
(integer) 2
127.0.0.1:6379> smembers myset
1) "b"
2) "a"
3) "c"
4) "1"
5) "2"
127.0.0.1:6379> srem myset b
(integer) 1
127.0.0.1:6379> smembers test
(empty list or set)
127.0.0.1:6379> sadd myset1 a b c
(integer) 3
127.0.0.1:6379> sadd myset2 a c 1 2
(integer) 4
127.0.0.1:6379> sdiff myset1 myset2 # 返回myset1和myset2的差集
1) "b"
127.0.0.1:6379> sdiff myset2 myset1
1) "1"
2) "2"
127.0.0.1:6379> sinter myset1 myset2 # 返回myset1和myset2的交集
1) "a"
2) "c"
127.0.0.1:6379> sinter myset2 myset1
1) "a"
2) "c"
127.0.0.1:6379> sunion myset1 myset2 # 返回myset1和myset2的并集
1) "2"
2) "c"
3) "a"
4) "1"
5) "b"
127.0.0.1:6379> scard myset1
(integer) 3
127.0.0.1:6379> sdiffstore new_set myset1 myset2 # 将myset1和myset2的差集保存到new_set中
(integer) 1
127.0.0.1:6379> smembers new_set
1) "b"
4. 使用场景
- 跟踪一些具有的唯一性的数据,比如访问博客的唯一IP地址的信息(访问该博客,用set记录用户的IP)
- 维护数据对象之间的关联关系,比如淘宝统计两个用户是否买了一样的商品(用户购买的商品放到set中,将两个用户的set进行交集操作)
5. 场景:唯一计数器
某些情况下,需要唯一计数器,即这种计数器只会对特定的动作或对象进行一次计数而不是多次计数
举个例子,一个网站的受欢迎程度通常可以用浏览量和用户数量这两个指标进行描述:
- 浏览量记录的是网站页面被用户访问的总次数,网站的每个用户都可以重复的对同一个页面进行多次访问,而这些访问会被浏览量计数器一个不漏的记下来,这个可以用普通计数器
- 用户数量记录的是访问网站的IP地址数量,即使同一个IP地址多次访问相同的页面,用户数量计数器也只会对这个IP地址进行一次计数。这种就需要唯一计数器了。
import redisclass UniqueCounter:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef count_in(self, item):"""尝试将给定元素计入到计数器当中:如果给定元素之前没有被计数过,那么方法返回 True 表示此次计数有效;如果给定元素之前已经被计数过,那么方法返回 False 表示此次计数无效。"""return self.client.sadd(self.key, item) == 1def get_result(self):"""返回计数器的值。"""return self.client.scard(self.key)
6. 场景:点赞
点赞(like)功能可以使用集合来实现,使用集合来存储对内容进行了点赞的用户,从而确保每个用户只能对同一内容点赞一次,并通过使用不同的集合命令来实现查看点赞数量、查看所有点赞用户以及取消点赞等功能。
类似的还有+1、顶、喜欢等功能
class Like:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef cast(self, user):"""用户尝试进行点赞。如果此次点赞执行成功,那么返回 True ;如果用户之前已经点过赞,那么返回 False 表示此次点赞无效。"""return self.client.sadd(self.key, user) == 1def undo(self, user):"""取消用户的点赞。"""self.client.srem(self.key, user)def is_liked(self, user):"""检查用户是否已经点过赞。是的话返回 True ,否则的话返回 False 。"""return self.client.sismember(self.key, user)def get_all_liked_users(self):"""返回所有已经点过赞的用户。"""return self.client.smembers(self.key)def count(self):"""返回已点赞用户的人数。"""return self.client.scard(self.key)
7. 场景:投票
使用集合实现的投票程序:对于每一项需要投票的内容,这个程序都会使用两个集合来分别存储投支持票的用户以及投反对票的用户,然后通过对这两个集合执行命令来实现投票、取消投票、统计投票数量、获取已投票用户名单等功能。
import redisdef vote_up_key(vote_target):return vote_target + "::vote_up"def vote_down_key(vote_target):return vote_target + "::vote_down"class Vote:def __init__(self, vote_target, client=None):self.client = client if client else redis.Redis(decode_response=True)self.vote_up_set = vote_up_key(vote_target)self.vote_down_set = vote_down_key(vote_target)def is_voted(self, user):"""检查用户是否已经投过票(可以是赞成票也可以是反对票),是的话返回 True ,否则返回 False 。"""return self.client.sismember(self.vote_up_set, user) or \self.client.sismember(self.vote_down_set, user)def vote_up(self, user):"""让用户投赞成票,并在投票成功时返回 True ;如果用户已经投过票,那么返回 False 表示此次投票无效。"""if self.is_voted(user): return Falseself.client.sadd(self.vote_up_set, user)return Truedef vote_down(self, user):"""让用户投反对票,并在投票成功时返回 True ;如果用户已经投过票,那么返回 False 表示此次投票无效。"""if self.is_voted(user): return Falseself.client.sadd(self.vote_down_set, user)return Truedef undo(self, user):"""取消用户的投票。"""self.client.srem(self.vote_up_set, user)self.client.srem(self.vote_down_set, user)def vote_up_count(self):"""返回投支持票的用户数量。"""return self.client.scard(self.vote_up_set)def get_all_vote_up_users(self):"""返回所有投支持票的用户。"""return self.client.smembers(self.vote_up_set)def vote_down_count(self):"""返回投反对票的用户数量。"""return self.client.scard(self.vote_down_set)def get_all_vote_down_users(self):"""返回所有投反对票的用户。"""return self.client.smembers(self.vote_down_set)
8. 场景:社交关系
微博、Twitter以及类似的社交网站都允许用户通过加关注或者加好友的方式,构建一种社交关系。这些网站上的每个用户都可以关注其他用户,也可以被其他用户关注。通过正在关注名单(following list),用户可以查看自己正在关注的用户及其人数;通过关注者名单(followerlist),用户可以查看有哪些人正在关注自己,以及有多少人正在关注自己。
使用集合来记录社交关系的方法:
- 程序为每个用户维护两个集合,一个集合存储用户的正在关注名单,而另一个集合则存储用户的关注者名单。
- 当一个用户(关注者)关注另一个用户(被关注者)的时候,程序会将被关注者添加到关注者的正在关注名单中,并将关注者添加到被关注者的关注者名单里面。
- 当关注者取消对被关注者的关注时,程序会将被关注者从关注者的正在关注名单中移除,并将关注者从被关注者的关注者名单中移除。
import redisdef following_key(user):return user + "::following"def follower_key(user):return user + "::follower"class Relationship:def __init__(self, user, client=None):self.client = client if client else redis.Redis(decode_response=True)self.user = userdef follow(self, target):"""关注目标用户。"""# 把 target 添加到当前用户的正在关注集合里面user_following_set = following_key(self.user)self.client.sadd(user_following_set, target)# 把当前用户添加到 target 的关注者集合里面target_follower_set = follower_key(target)self.client.sadd(target_follower_set, self.user)def unfollow(self, target):"""取消对目标用户的关注。"""# 从当前用户的正在关注集合中移除 targetuser_following_set = following_key(self.user)self.client.srem(user_following_set, target)# 从 target 的关注者集合中移除当前用户target_follower_set = follower_key(target)self.client.srem(target_follower_set, self.user)def is_following(self, target):"""检查当前用户是否正在关注目标用户,是的话返回 True ,否则返回 False 。"""# 如果 target 存在于当前用户的正在关注集合中# 那么说明当前用户正在关注 targetuser_following_set = following_key(self.user)return self.client.sismember(user_following_set, target)def get_all_following(self):"""返回当前用户正在关注的所有人。"""user_following_set = following_key(self.user)return self.client.smembers(user_following_set)def get_all_follower(self):"""返回当前用户的所有关注者。"""user_follower_set = follower_key(self.user)return self.client.smembers(user_follower_set)def count_following(self):"""返回当前用户正在关注的人数。"""user_following_set = following_key(self.user)return self.client.scard(user_following_set)def count_follower(self):"""返回当前用户的关注者人数。"""user_follower_set = follower_key(self.user)return self.client.scard(user_follower_set)
9. 场景:抽奖
使用集合实现的抽奖程序,程序会把所有参与抽奖活动的玩家都添加到一个集合中,然后通过srandmember命令随机地选出获奖者。
考虑到保留完整的抽奖者名单可能会有用,所以这个抽奖程序使用了随机获取元素的SRANDMEMBER命令而不是随机移除元素的SPOP命令。
在不需要保留完整的抽奖者名单的情况下,也可以使用SPOP命令去实现抽奖程序。
import redisclass Lottery:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef add_player(self, user):"""将用户添加到抽奖名单当中。"""self.client.sadd(self.key, user)def get_all_players(self):"""返回参加抽奖活动的所有用户。"""return self.client.smembers(self.key)def player_count(self):"""返回参加抽奖活动的用户人数。"""return self.client.scard(self.key)def draw(self, number):"""抽取指定数量的获奖者。 - 保留完整的抽奖者名单,即中奖的人还在抽奖池中"""return self.client.srandmember(self.key, number)def draw_new(self, number):"""抽取指定数量的获奖者。 - 不需要保留完整的抽奖者名单"""# 因为 redis-py 目前还不支持 SPOP 命令的 count 参数# 所以在这里只能通过调用多次 SPOP 命令来获得多个随机元素winners = list()for i in range(number):winners.append(self.client.spop(self.key))return winners10. 场景:共同关注与推荐关注
要实现共同关注功能,程序需要做的就是计算出两个用户的正在关注集合之间的交集,这一点可以通过SINTER命令和SINTERSTORE命令来完成。
推荐关注:推荐关注程序,这个程序会从用户的正在关注集合中随机选出指定数量的用户作为种子用户,然后对这些种子用户的正在关注集合执行并集计算,最后从这个并集中随机地选出一些用户作为推荐关注的对象。
import redisdef following_key(user):return user + "::following"def recommend_follow_key(user):return user + "::recommend_follow"class CommonFollowing:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def calculate(self, user, target):"""计算并返回当前用户和目标用户共同关注的人。"""user_following_set = following_key(user)target_following_set = following_key(target)return self.client.sinter(user_following_set, target_following_set)def calculate_and_store(self, user, target, store_key):"""计算出当前用户和目标用户共同关注的人,并把结果储存到 store_key 指定的键里面,最后返回共同关注的人数作为返回值。"""user_following_set = following_key(user)target_following_set = following_key(target)return self.client.sinterstore(store_key, user_following_set, target_following_set)class RecommendFollow:def __init__(self, user, client=None):self.client = client if client else redis.Redis(decode_response=True)self.user = userdef calculate(self, seed_size):"""计算并储存用户的推荐关注数据。"""# 1)从用户关注的人中随机选一些人作为种子用户user_following_set = following_key(self.user)following_targets = self.client.srandmember(user_following_set, seed_size)# 2)收集种子用户的正在关注集合键名target_sets = set()for target in following_targets:target_sets.add(following_key(target))# 3)对所有种子用户的正在关注集合执行并集计算,并储存结果return self.client.sunionstore(recommend_follow_key(self.user), *target_sets)def fetch_result(self, number):"""从已有的推荐关注数据中随机地获取指定数量的推荐关注用户。"""return self.client.srandmember(recommend_follow_key(self.user), number)def delete_result(self):"""删除已计算出的推荐关注数据。"""self.client.delete(recommend_follow_key(self.user))
11. 场景:商品筛选器
在访问购物网站的时候,经常可以看到商品筛选器,对于不同的筛选条件,筛选器会给出不同的选项。如下图:

实现商品筛选器的方法之一是使用反向索引,这种数据结构可以为每个物品添加多个关键字,然后根据关键字去反向获取相应的物品。
举个例子,对于"X1 Carbon"这台笔记本电脑来说,我们可以为它添加"ThinkPad"、“14inch”、"Windows"等关键字,然后通过这些关键字来反向获取"X1Carbon"这台笔记本电脑。
实现反向索引的关键是要在物品和关键字之间构建起双向的映射关系,比如对于刚刚提到的"X1Carbon"笔记本电脑来说,反向索引程序需要构建出图5-16所示的两种映射关系:
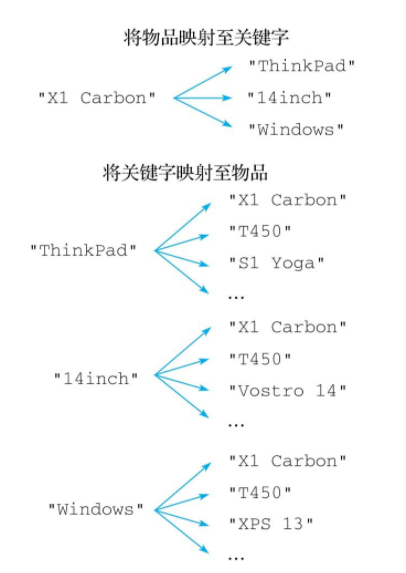
- 第一种映射关系将"X1 Carbon"映射至它带有的各个关键字。
- 第二种映射关系将"ThinkPad"、“14inch”、“Windows"等多个关键字映射至"X1 Carbon”。
一个使用集合实现的反向索引程序,对于用户给定的每一件物品,这个程序都会使用一个集合去存储物品带有的多个关键字,与此同时,对于这件物品的每一个关键字,程序都会使用一个集合去存储关键字与物品之间的映射。因为构建反向索引所需的这两种映射都是一对多映射,所以使用集合来存储这两种映射关系的做法是可行的。
import redisdef make_item_key(item):return "InvertedIndex::" + item + "::keywords"def make_keyword_key(keyword):return "InvertedIndex::" + keyword + "::items"class InvertedIndex:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def add_index(self, item, *keywords):"""为物品添加关键字。"""# 将给定关键字添加到物品集合中item_key = make_item_key(item)result = self.client.sadd(item_key, *keywords)# 遍历每个关键字集合,把给定物品添加到这些集合当中for keyword in keywords:keyword_key = make_keyword_key(keyword)self.client.sadd(keyword_key, item)# 返回新添加关键字的数量作为结果return resultdef remove_index(self, item, *keywords):"""移除物品的关键字。"""# 将给定关键字从物品集合中移除item_key = make_item_key(item)result = self.client.srem(item_key, *keywords)# 遍历每个关键字集合,把给定物品从这些集合中移除for keyword in keywords:keyword_key = make_keyword_key(keyword)self.client.srem(keyword_key, item)# 返回被移除关键字的数量作为结果return resultdef get_keywords(self, item):"""获取物品的所有关键字。"""return self.client.smembers(make_item_key(item))def get_items(self, *keywords):"""根据给定的关键字获取物品。"""# 根据给定的关键字,计算出与之对应的集合键名keyword_key_list = map(make_keyword_key, keywords)# 然后对这些储存着各式物品的关键字集合执行并集计算# 从而查找出带有给定关键字的物品return self.client.sinter(*keyword_key_list)
4-6 Redis的数据类型之有序集合
1. 概述
- 有序集合,sorted-set,又称之为zset
- 可存储有序但不重复的数据,存储的每个元素都有一个分数,元素根据分数指定存储顺序,即根据分数进行排序,不同的元素分数可能是相同的
- 和set一样是String类型元素的集合,每个元素都是不重复的,Sorted Set关联了一个Double类型权重的参数Score,使得集合中的元素能够按照Score进行有序排列
- 不同元素的分数是可以相同的,如分数相同的话,则是按照元素进行排序
- 分数除了可以是数字之外,还可以是字符串"+inf"或者"-inf",这两个特殊值分别用于表示无穷大和无穷小
2. 底层实现
底层实现有三种数据结构:
- hash表(HashMap)
- 跳表(skipList)
- 压缩列表
如果同时满足下面 2 个条件,就使用压缩列表,否则使用跳表:
- 集合中元素都小于 64 字节
- 集合中元素个数小于 128 个
使用 HashMap 和跳表(skipList)或压缩列表来保证数据的存储和有序,HashMap 里放的是成员到 Score 的映射,做zscores查询操作时查询的就是这个hash表,所以效率很高。
而跳表或压缩列表里存放的是所有的成员,排序依据是 HashMap 里存的 Score,使用跳表的结构可以获得比较高的查找效率,并且在实现上比较简单。
跳表结构如下:
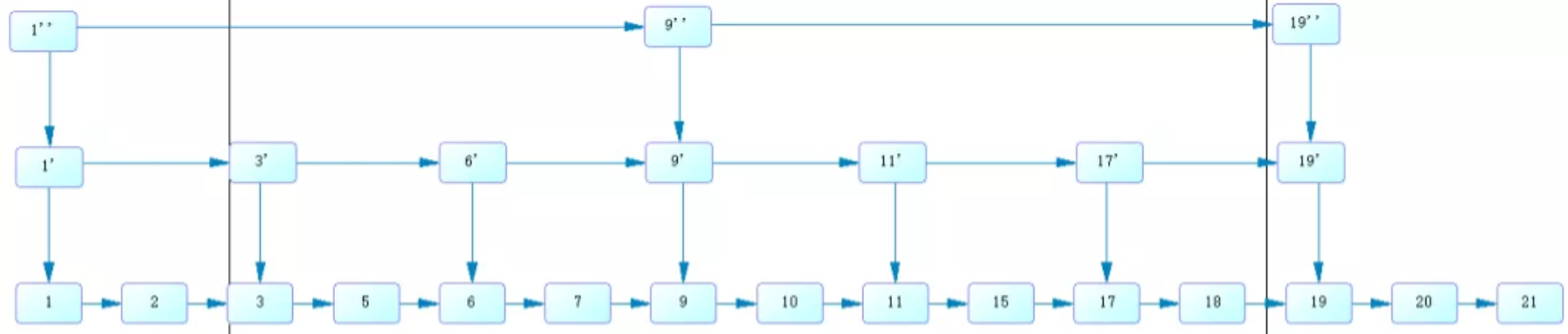
如果不加索引,查找 10 这个数字需要查询 10 次,使用了二级索引,查找 10 这个数字需要 5 次,而使用一级索引,需要查询 3 次。
跳表的每一层都是一个有序链表,最下面一层保存了全部数据。跳表插入、删除、查询的时间复杂度是 o(logN)。跳表需要存储额外的索引节点,会增加额外的空间开销。
3. 命令
常用命令:
- 添加元素:zadd
- 获取元素:zscores获得分数、zcard获得个数、
- 删除元素:zrem、zremrangerank按照排名删除、zremrangebyscores按照分数范围删除
- 范围查询:zrange从小大大、zrevrange从大到小
- 并集交集运算:zunionstore并集、zinterstore交集
具体命令如下:
# 添加元素,返回添加成功的个数,如已存在该元素则分数进行更新,但返回0
zadd set名 分数 元素名# 添加多个元素,返回添加成功的个数
zadd set名 分数1 元素名1 分数2 元素名2# 查看元素的分数
zscore set名 元素名# 获取set的元素个数
zcard set名# 对某个元素自增,数量可以是负值
zincrby set名 数量 元素名# 查看所有的元素(分数由小到大),如果想要显示元素对应的分数,加上withscores即可
zrange set名 0 -1 [withscores]# 查看所有的元素,分数从大到小,可显示分数,也可使用limit
zrevrange set名 0 -1 [withscores] [limit offset count]# 范围查询,查询从0到第N个元素,分数由小到大,可显示分数,也可使用limit
zrangebyrank set名 0 N [withscores] [limit offset count]# 范围查询,查询分数处于某个范围的元素,可显示分数,也可使用limit
zrangebyscore set名 分数1 分数2 [withscores] [limit offset count]# 获取分数处于某个范围的元素个数
zcount set名 分数1 分数2# 某个元素的分数增加
zincrby set名 元素名 增加的值# 删除元素,返回删除成功的个数
zrem set名 元素名1 元素名2# 删除从start_num到第end_num个元素,分数从小到大,比如0到5,可以是负数的,比如-1到-3
zremrangebyrank set名 start_num end_num# 删除分数处于某个范围的元素
zremrangebyscore set名 分数1 分数2# 计算出多个集合的并集并保存到目的集合,返回并集的数量
zunionstore 目的set名 计算的集合数 set1 [set2 ...]
比如:
127.0.0.1:6379> zadd sorttest 100 zhangshan # 添加元素
(integer) 1
127.0.0.1:6379> zadd sorttest 90 wangwu 50 xiaoming # 添加多个元素
(integer) 2
127.0.0.1:6379> zadd sorttest 120 zhangshan
(integer) 0
127.0.0.1:6379> zscore sorttest zhangshan # 获取元素分数
"120"
127.0.0.1:6379> zcard sorttest # 获取元素个数
(integer) 3
127.0.0.1:6379> zrem sorttest zhangshan wangwu # 删除元素
(integer) 2
127.0.0.1:6379> zcard sorttest
(integer) 3
127.0.0.1:6379> zrange sorttest 0 -1 # 获取元素排行
1) "xiaoming"
2) "lisi"
3) "xiaohong"
127.0.0.1:6379> zrange sorttest 0 -1 withscores # 获取元素排行,显示分数
1) "xiaoming"
2) "50"
3) "lisi"
4) "60"
5) "xiaohong"
6) "70"
127.0.0.1:6379> zrangebyscore sorttest 60 70 # 获取分数处于60-70的元素
1) "lisi"
2) "xiaoli"
3) "xiaohong"
4. 场景:排行榜
排行榜,比如游戏排名、积分排行榜等
使用有序集合实现的排行榜:
- 使用ZADD命令向排行榜中添加被排序的元素及其分数,并使用ZREVRANK命令去获取元素在排行榜中的排名,以及使用ZSCORE命令去获取元素的分数
- 当用户不再需要对某个元素进行排序的时候,可以调用由ZREM命令实现的remove()方法,从排行榜中移除该元素
- 如果用户想要修改某个被排序元素的分数,那么只需要调用由ZINCRBY命令实现的increase_score()方法或者decrease_score()方法即可
- 当用户想要获取排行榜前N位的元素及其分数时,只需要调用由ZREVRANGE命令实现的top()方法即可
import redisclass RankingList:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef set_score(self, item, score):"""为排行榜中的指定元素设置分数,不存在的元素会被添加到排行榜里面。"""self.client.zadd(self.key, {item:score})def get_score(self, item):"""获取排行榜中指定元素的分数。"""return self.client.zscore(self.key, item)def remove(self, item):"""从排行榜中移除指定的元素。"""self.client.zrem(self.key, item)def increase_score(self, item, increment):"""将给定元素的分数增加 increment 分。"""self.client.zincrby(self.key, increment, item)def decrease_score(self, item, decrement):"""将给定元素的分数减少 decrement 分。"""# 因为 Redis 没有直接提供能够减少元素分值的命令# 所以这里通过传入一个负数减量来达到减少分值的目的self.client.zincrby(self.key, 0-decrement, item)def get_rank(self, item):"""获取给定元素在排行榜中的排名。"""rank = self.client.zrevrank(self.key, item)# 因为 Redis 元素的排名是以 0 为开始的,# 而现实世界中的排名通常以 1 为开始,# 所以这里在返回排名之前会执行加一操作。if rank is not None: return rank+1def top(self, n, with_score=False):"""获取排行榜中得分最高的 n 个元素,如果可选的 with_score 参数的值为 True ,那么将元素的分数(分值)也一并返回。"""return self.client.zrevrange(self.key, 0, n-1, withscores=with_score)
5. 场景:时间线
很多网站会根据内容的发布时间对内容进行排序,比如博客系统会根据文章发布时间的先后,将最近的文章放前面,类似微博和Twitter也是会把用户最新发布的消息放前面等。
使用有序集合实现的时间线程序:
- 会把被添加到时间线里面的元素用作成员,与元素相关联的时间戳用作分值,将元素和它的时间戳添加到有序集合中
- 因为时间线中的每个元素都有一个与之相关联的时间戳,所以时间线中的元素将按照时间戳的大小进行排序
- 通过对时间线中的元素执行ZREVRANGE命令或者ZREVRANGEBYSCORE命令,用户可以以分页的方式按顺序取出时间线中的元素,或者从时间线中取出指定时间区间内的元素
import redisclass Timeline:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef add(self, item, time):"""将元素添加到时间线里面。"""self.client.zadd(self.key, {item:time})def remove(self, item):"""从时间线里面移除指定元素。"""self.client.zrem(self.key, item)def count(self):"""返回时间线包含的元素数量。"""return self.client.zcard(self.key)def pagging(self, number, count, with_time=False):"""按照每页 count 个元素计算,取出时间线第 number 页上的所有元素,这些元素将根据时间戳逆序排列。如果可选参数 with_time 的值为 True ,那么元素对应的时间戳也会一并被返回。注意:number 参数的起始值是 1 而不是 0 。"""start_index = (number - 1)*countend_index = number*count-1return self.client.zrevrange(self.key, start_index, end_index, withscores=with_time) def fetch_by_time_range(self, min_time, max_time, number, count, with_time=False):"""按照每页 count 个元素计算,获取指定时间段第 number 页上的所有元素,这些元素将根据时间戳逆序排列。如果可选参数 with_time 的值为 True ,那么元素对应的时间戳也会一并被返回。注意:number 参数的起始值是 1 而不是 0 。"""start_index = (number-1)*countreturn self.client.zrevrangebyscore(self.key, max_time, min_time, start_index, count, withscores=with_time)
6. 场景:商品推荐
在浏览网上商城时经常会看到“购买此商品的顾客也同时购买”这样的商品推荐功能。
从抽象的角度来讲,这些推荐功能实际上都是通过记录用户的访问路径来实现的:
如果用户在对一个目标执行了类似浏览或者购买这样的操作之后,也对另一个目标执行了相同的操作,那么程序就会对这次操作的访问路径进行记录和计数,然后程序就可以通过计数结果来知道用户在对指定目标执行了某个操作之后,还会对哪些目标执行相同的操作。
使用以上原理实现的路径统计程序:
- 每当用户从起点origin对终点destination进行一次访问,程序都会使用ZINCRBY命令对存储着起点origin访问记录的有序集合的destination成员执行一次分值加1操作
- 在此之后,程序只需要对存储着origin访问记录的有序集合执行ZREVRANGE命令,就可以知道用户在访问了起点origin之后,最经常访问的目的地有哪些
import redisdef make_record_key(origin):return "forward_to_record::{0}".format(origin)class Path:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def forward_to(self, origin, destination):"""记录一次从起点 origin 到目的地 destination 的访问。"""key = make_record_key(origin)self.client.zincrby(key, 1, destination)def pagging_record(self, origin, number, count, with_time=False):"""按照每页 count 个目的地计算,从起点 origin 的访问记录中取出位于第 number 页的访问记录,其中所有访问记录均按照访问次数从多到小进行排列。如果可选的 with_time 参数的值为 True ,那么将具体的访问次数也一并返回。"""key = make_record_key(origin)start_index = (number-1)*countend_index = number*count-1return self.client.zrevrange(key, start_index, end_index, withscores=with_time, score_cast_func=int) # score_cast_func = int 用于将成员的分值从浮点数转换为整数
7. 场景:延时队列
Redis的有序列表可以实现延时队列。
将消息序列化成一个字符串作为zset的value,这个消息的到期处理时间作为score,然后使用多个线程轮询zset来获取到期的任务进行处理。
注意:多个线程是为了保障可用性,万一有一个线程挂了之后还有其他的线程可以继续处理。
注意:因为使用多个线程,所以需要考虑到并发争抢任务,确保任务不会被多次重复执行。这里呢,使用zrem来保证并发争抢任务,通过zrem的返回值来判断当前的线程有没有抢到任务。
简单的示例代码如下:
import json
import uuid
import time
import redisclass DelayQueue:QueueName = 'delay-queue'host = 'localhost'port = 6379password = ''db = 1def __init__(self, conn=None):"""如果不传连接池的话,默认读取配置的Redis作为连接池:param conn:"""self.conn = conn if conn else self.get_redis_client()def get_redis_client(self):"""获取Redis连接:return:"""return redis.Redis(host=self.host,port=self.port,password=self.password,db=self.db)def delay(self, msg):"""往延时队列里面加入消息:param msg::return:"""# 保证value值唯一msg.id = str(uuid.uuid4())value = json.dumps(msg)# 过期时间5秒,即5秒之后进行重试retry_time = time.time() + 5self.conn.zadd(self.QueueName, retry_time, value)def loop(self):"""轮询处理延时队列的消息:return:"""while True:values = self.conn.zrangebyscore(self.QueueName, 0, time.time(), start=0, num=1)# 如果队列是空的,则sleep 1秒再来获取if not values:time.sleep(1)continue# 每次只获取一条value = values[0]# 从消息队列中移除该消息is_success = self.conn.zrem(self.QueueName)# 由于有多进程/线程并发的可能,最终只会有一个进程/线程可以拿到该消息if is_success:msg = json.loads(value)self.handle_msg(msg)def handle_msg(self, msg):try:# todo 处理消息print(msg)except Exception as e:print(str(e))
注意:这只是个简单的示例,示例代码并不完善,在上面的代码中,同一个任务可能会被多个进程获取到之后,再使用zrem进行争抢,那么没抢到的进程都白取了一次任务,比较浪费,可以考虑使用lua脚本进行优化这个逻辑,将zrangebyscore和zrem放一起进行原子化操作,这样多个进程之间争抢任务时就不会出现这种浪费了。
8. 其他场景
- 自动补全
- 微博的热点
- 构建索引数据
4-7 Redis的数据类型之HyperLogLog
1. 概述
HyperLogLog是一个专门为了计算集合的基数而创建的概率算法,对于一个给定的集合,HyperLogLog可以计算出这个集合的近似基数:近似基数并非集合的实际基数,它可能会比实际的基数小一点或者大一点,但是估算基数和实际基数之间的误差会处于一个合理的范围之内,因此那些不需要知道实际基数或者因为条件限制而无法计算出实际基数的程序就可以把这个近似基数当作集合的基数来使用。
HyperLogLog的优点在于它计算近似基数所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog进行计算所需的内存总是固定的,并且是非常少的。
具体到实现上,Redis的每个HyperLogLog只需要使用12KB内存空间,就可以对接近:2^64个元素进行计数,而算法的标准误差仅为0.81%,因此它计算出的近似基数是相当可信的。
但是,由于HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog不能像集合那样返回输入的各个元素。
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
注意:HyperLogLog不能用来做精确判断,比如不能应用于判断某个值在不在HyperLogLog里面,这种情况下使用布隆过滤器更好一点。
HyperLogLog一般用于两种场景:
- 计数问题
- 去重问题
2. 底层实现
一个HyperLogLog实际占用的空间大约是 13684 * 6bit / 8 = 12k 字节。但是在计数比较小的时候,大多数桶的计数值都是零。如果 12k 字节里面太多的字节都是零,那么这个空间是可以适当节约一下的。
Redis 在计数值比较小的情况下采用了稀疏存储,稀疏存储的空间占用远远小于 12k 字节。相对于稀疏存储的就是密集存储,密集存储会恒定占用 12k 字节。
具体的内部数据结构可参考:见缝插针 —— 深入 Redis HyperLogLog 内部数据结构分析
3. 命令
# 添加指定元素到 某个HyperLogLog 中,如已存在则返回0,不存在则返回1
pfadd HyperLogLog名 元素 [元素 ...]# 返回给定 HyperLogLog 的基数估算值
pfcount HyperLogLog名# 返回多个HyperLogLog的基数估算值(并集)
pfcount HyperLogLog名 [HyperLogLog名 ...]# 将多个 HyperLogLog 合并为一个 HyperLogLog
PFMERGE 目的HyperLogLog名 HyperLogLog名 [HyperLogLog名 ...]
4. 场景:优化唯一计数器
在集合有一个场景是实现了唯一计数器,比如说用来统计网站的唯一访客IP,但会存在明显的缺陷:随着需要统计的网站越来越多,那么需要的计数器也会越来越多,另外,如果某个网站访问量特别大,达到几千万的级别,使用Set集合来统计是需要很大的空间内存的,为这样的一个去重统计功能来耗费这么多存储空间,其实很不划算。
其实很多时候所需要的数据并不需要太精确,105万和106万其实区别并不大,HyperLogLog数据结构可以来解决这种统计问题,HyperLogLog提供了不精确的去重计数方案,虽然不精确,标准误差是0.81%,满足一般的去重统计需求了。
使用方法也很简单,一直通过pfadd往HyperLogLog添加元素即可,然后使用pfcount来获取值即可。
与集合实现的唯一计数器相比,使用HyperLogLog实现的唯一计数器并不会因为元素的增多而变大。
import redisclass UniqueCounter:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef count_in(self, item):"""对给定元素进行计数。"""self.client.pfadd(self.key, item)def get_result(self):"""返回计数器的值。"""return self.client.pfcount(self.key)
5. 场景:检测重复信息
经常有一种场景需要判断两端信息是否相同,如果使用一般的字符串对比函数(比如strcmp)来完成这一操作,那么每当有新的信息的时候,就需要把信息与系统当前已有的信息进行一一比对,复杂度达到了O(N*M),N为信息的长度,M为系统目前已有的信息数量。
随着系统存储的信息越来越多,这种对比操作将会越来越慢,最终成为系统的瓶颈。
为了降低鉴别重复信息的复杂度,可以使用HyperLogLog来解决:
- 当有新的信息的时候,使用pfadd将这条信息添加到HyperLogLog中
- 如果命令返回1,说明这条信息未出现过,是新的
- 如果命令返回0,说明已经出现过了
由于HyperLogLog使用的是概率算法,所以即使信息长度很长,HpyerLogLog判断是否重复所需的时间也是非常短的。
import redisclass DuplicateChecker:def __init__(self, key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = keydef is_duplicated(self, content):"""在信息重复时返回 True ,未重复时返回 False 。"""return self.client.pfadd(self.key, content) == 0def unique_count(self):"""返回检查器已经检查过的非重复信息数量。""" return self.client.pfcount(self.key)
6. 场景:每周/月度/年度计数器
通过使用pfmerge命令可以对多个HyperLogLog实现的唯一计数器执行并集计算,从而实现每周/月度/年度计数器:
- 通过对一周内的每天的唯一访客IP计数器执行pfmerge命令,可以计算出这一周的唯一访客IP数量
import redisclass UniqueCounterMerger:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def merge(self, destination, *hyperloglogs):self.client.pfmerge(destination, *hyperloglogs)
4-8 Redis的数据类型之位图
1. 概述
Redis的位图(bitmap)是由多个二进制位组成的数组,数组中的每个二进制位都有与之对应的偏移量(也称索引),用户通过这些偏移量可以对位图中指定的一个或多个二进制位进行操作。
如图展示了一个包含8个二进制位的位图示例,这个位图存储的值为:10010100

Redis为位图提供了一系列操作命令,通过这些命令,用户可以:
- 为位图指定偏移量上的二进制位设置值,或者获取位图指定偏移量上的二进制位的值
- 统计位图中有多少个二进制位被设置成了1
- 查找位图中第一个被设置为指定值的二进制位并返回它的偏移值
- 对一个或多个位图执行逻辑并、逻辑或、逻辑异或以及逻辑非运算
- 将执行类型的整数存储到位图中
2. 命令
使用setbit的时候,需要注意:
- 由于是二进制,设置的值只能0或1
- 偏移量即offset只能为正整数偏移量,至少为0
- 未被设置的二进制位都会被初始化为0
使用getbit的时候,需要注意:
- 如果输入的偏移量超过了位图的最大偏移量,则返回0
# 为位图指定偏移量上的二进制位设置值,设置的值只能0/1
setbit bitmap名 offset value# 获取二进制位的值
getbit bitmap名 offset# 统计被设置的二进制位数量,只统计值为1的二进制位的数量
bitcount bitmap名# 统计某个位置之间的被设置的二进制位数量
bitcount bitmap名 [start end]# 查找第一个被设置为指定值的二进制位的偏移量,指定值要么是0要么是1
bitpos bitmap名 二进制值 [start end]# 执行二进制位运算(AND、OR、XOR、NOT),并存储到指定的bitmap中
bitos operation 指定bitmap名 bitmap01 [bitmap02 ...]# 存储整数值,u表示无符号,i表示有符号,比如存储无符号整数值198,bitfield bitmap_test set u8 0198
bitfield bitmap名 set u/i位数 整数值# 读取存储的值
bitfield bitmap名 get u/i位数 offset
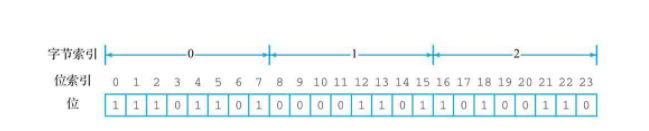
注意:使用bitcount命令的时候,这里的start和end参数与getbit里面的offset参数不一样,这两个参数是用来指定字节偏移量而不是二进制位偏移量的。一个字节有8个二进制位,比如bitcount bitmap01 0 0 ,是表示:bitmap01这个位图的第一个字节里面的二进制位的数量,即从第1个到第8个二进制位之间的
如图所示,该位图包含3个字节共24个二进制位,bitcount xxx 0 0,即表示第1个二进制位到第8个二进制位的值,即6
如果想知道该位图的第二个字节和第三个字节里面有多少个二进制位被设置为1,那么可以使用以下命令:
bitcount xxx 1 2
注意:bitcount的start和end参数也可以是负数,表示倒数第几个字节
注意:bitpos的start和end参数是一致的,也可以是负数
注意:使用bitop命令的时候,operation参数可以是AND、OR、XOR、NOT中的任意一个,这4个值分别对应逻辑并、逻辑或、逻辑异或和逻辑非4种运算,其中呢只有NOT运算只允许一个位图作为输入,其他的允许使用任意数量的位图作为输入。
3. 场景:用户行为记录器
有的时候为了对用户的行为进行分析,需要记录用户在网站上从操作记录,比如说登录记录、发表文章、消费等。为此,可以使用前面介绍的集合或者是HyperLogLog来记录所有执行了指定行为的用户,但这两种做法都有相应的缺陷:
- 如果使用集合来记录的话,那么集合的体积会随着用户数量的增多而变大,从而小号大量内存
- 使用HyperLogLog来记录虽然可以记录大量内存,但HyperLogLog是概率算法,只能给出执行了指定行为的人数的估算值,无法准确判断某个用户是否执行了指定行为
为了尽可能节约内存,并且精确记录特定用户是否执行了指定的行为,可以使用位图来记录:
- 对于每项行为,一个用户要么执行了该行为,要么没有执行,没有其他的可能性,因此可以通过一个二进制位来记录用户是否执行了指定行为
- 通过将用户ID与位图中二进制位偏移量进行一对一映射,可以使用位图来记录所有执行了指定行为的用户:比如ID为10086的用户记录在偏移量为10086的二进制位上
- 每当用户执行了指定行为,就调用setbit命令将用户在位图中对应的二进制位的值设置为1
- 通过调用getbit命令判断用户对应的二进制位是否为1,就可以知道用户是否指定了指定的行为
- 通过对位图执行bitcount命令,就可以知道有多少用户执行了指定行为
使用位图实现的行为记录器同时具备了集合和HyperLogLog的优点,既可以像集合那样准确地判断特定用户是否执行了指定行为,又可以像HyperLogLog那样大量减少内存消耗:对于每项行为,使用这个程序去记录100万个用户的信息只需要耗费125KB内存,而记录1000万个用户的信息也只需要1.25MB内存
import redisdef make_action_key(action):return "action_recorder::" + actionclass ActionRecorder:def __init__(self, action, client=None):self.client = client if client else redis.Redis(decode_response=True)self.bitmap = make_action_key(action)def perform_by(self, user_id):"""记录执行了指定行为的用户。"""self.client.setbit(self.bitmap, user_id, 1)def is_performed_by(self, user_id):"""检查给定用户是否执行了指定行为,是的话返回 True ,反之返回 False 。"""return self.client.getbit(self.bitmap, user_id) == 1def count_performed(self):"""返回执行了指定行为的用户人数。""" return self.client.bitcount(self.bitmap)class ActionAggregation:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)def calc_and(self, result_action, *input_actions):"""对给定的用户行为记录执行并计算。"""action_keys = map(make_action_key, input_actions)result_key = make_action_key(result_action)self.client.bitop("AND", result_key, *action_keys)def calc_or(self, result_action, *input_actions):"""对给定的用户行为记录执行或计算。"""action_keys = map(make_action_key, input_actions)result_key = make_action_key(result_action)self.client.bitop("OR", result_key, *action_keys)def calc_xor(self, result_action, *input_actions):"""对给定的用户行为记录执行异或计算。"""action_keys = map(make_action_key, input_actions)result_key = make_action_key(result_action)self.client.bitop("XOR", result_key, *action_keys)def calc_not(self, result_action, input_action):"""对给定的用户行为记录执行非计算。"""action_key = make_action_key(input_action)result_key = make_action_key(result_action)self.client.bitop("NOT", result_key, action_key)
4. 场景:0-1矩阵
0-1矩阵(又称逻辑矩阵或者二进制矩阵)是由0和1组成的矩阵,这种矩阵通常用于表示离散结构。下图展示了一个0-1矩阵的例子:
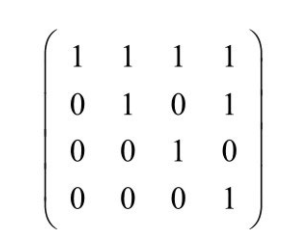
Redis的位图可以用于存储0-1矩阵,只需要将0-1矩阵种的各个元素与位图中的各个二进制位一对一关联起来即可,上图中的矩阵可以用如下的位图表示:

原理:
- 在初始化矩阵对象时,需要输入矩阵的行数和列数,然后将两个值存储到对象的row_num和col_num属性中
- 对矩阵的第row行第col列的元素进行设置的时候,根据公式row * col_num + col 找出被设置的元素在位图中对应二进制位的偏移量,执行setbit命令得对该二进制位进行设置
- 获取矩阵在指定位置上的元素时,使用相同的公式找出元素在位图中对应的二进制位,返回它的值
import redisdef make_matrix_key(matrix_name):return "matrix::" + matrix_namedef calculate_index(row, col, row_num, col_num):if not (row < row_num):raise ValueError("row out of range")if not (col < col_num):raise ValueError("col out of range")return row*col_num+colclass ZeroOneMatrix:def __init__(self, name, row_num, col_num, client=None):self.client = client if client else redis.Redis(decode_response=True)self.bitmap = make_matrix_key(name)self.row_num = row_numself.col_num = col_numdef set(self, row, col, value):"""对矩阵的指定位置进行设置。"""index = calculate_index(row, col, self.row_num, self.col_num)self.client.setbit(self.bitmap, index, value)def get(self, row, col):"""获取矩阵在指定位置上的值。"""index = calculate_index(row, col, self.row_num, self.col_num)return self.client.getbit(self.bitmap, index)def show(self):"""打印出整个矩阵。"""for row in range(self.row_num):elements = []for col in range(self.col_num):elements.append(self.get(row, col))print("matrix[{0}]: {1}".format(row, elements))
5. 场景:紧凑计数器
与之前实现的计数器类似,但有不同之处:
- 这个计数器允许用户自行指定计数器值的位长以及类型(有符号整数或无符号整数),而不是使用Redis默认的long类型来存储计数器值,如果用户想要在计数器中存储比long类型要短的整数,那么使用这个计数器将比使用其他计数器更节约内存
- 与字符串或者散列实现的计数器不同,这个计数器只能使用整数作为索引(键),因此它只适合存储一些与数字ID相关联的计数数据
比如,我们现在是一间游戏公司的程序员,并且打算为每个玩家创建一个计数器,用于记录玩家一个月登录游戏的次数。按照一个月30天,一天登录2~3次的频率来计算,一个普通玩家一个月的登录次数通常不会超过100次。对于这么小的数值,使用long类型进行存储将浪费大量的空间,考虑到这一点,我们可以使用上面展示的紧凑计数器来存储用户的登录次数:
- 因为每个玩家都有一个整数类型的用户ID,所以我们可以使用这个ID作为计数器的索引(键)
- 对于每位玩家,我们使用一个16位长的无符号整数来存储其一个月内的登录次数
- 16位无符号整数计数器能够存储的最大值为65536,对于我们来说,这个值已经非常大,不太可能达到
- 因为紧凑计数器使用饱和运算方式处理计算溢出,所以即使玩家的登录次数超过了65536次,计数器的值也只会被设置为65536,而不会真的造成溢出。这种处理方式非常安全,不会给程序带来bug或者其他奇怪的问题
import redisdef get_bitmap_index(index):return "#"+str(index)class CompactCounter:def __init__(self, key, bit_length, signed=True, client=None):"""初始化紧凑计数器,其中 client 参数用于指定客户端,key 参数用于指定计数器的键名,bit_length 参数用于指定计数器储存的整数位长,而 signed 参数则用于指定计数器储存的是有符号整数还是无符号整数。"""self.client = client if client else redis.Redis(decode_response=True)self.key = keyif signed:self.type = "i" + str(bit_length)else:self.type = "u" + str(bit_length)def increase(self, index, n=1):"""对索引 index 上的计数器执行加法操作,然后返回计数器的当前值。"""bitmap_index = get_bitmap_index(index)result = self.client.execute_command("BITFIELD", self.key, "OVERFLOW", "SAT", "INCRBY", self.type, bitmap_index, n)return result[0]def decrease(self, index, n=1):"""对索引 index 上的计数器执行减法操作,然后返回计数器的当前值。"""bitmap_index = get_bitmap_index(index)decrement = -nresult = self.client.execute_command("BITFIELD", self.key, "OVERFLOW", "SAT", "INCRBY", self.type, bitmap_index, decrement)return result[0]def get(self, index):"""获取索引 index 上的计数器的当前值。"""bitmap_index = get_bitmap_index(index)result = self.client.execute_command("BITFIELD", self.key, "GET", self.type, bitmap_index)return result[0]
6. 其他场景
- 用户签到
key = 年份:用户id offset = (今天是一年中的第几天) % (今年的天数)
- 统计活跃用户
使用日期作为 key,然后用户 id 为 offset 设置不同offset为0 1 即可。
4-9 Redis的数据类型之地理坐标
1. 概述
Redis GEO是在3.2版本新添加 ,可以将经纬度格式的地理坐标存储到Redis中,并对这些坐标执行距离计算、范围查找等操作。
Redis的GEO提供了以下功能:
- 将位置的名字以及它的经纬度存储到位置集合中
- 根据给定的位置名字,从位置集合中取出与之相对应的经纬度
- 计算两个位置之间的直线距离
- 根据给定的经纬度或位置,找出该位置指定半径范围内的其他位置
- 获取指定位置的Geohash编码值
- 经度范围[-180, 180],纬度范围[-90, 90]
注意:Redis是使用有序集合来存储GEO数据,一个位置集合实际上就是一个有序集合:调用geo命令对位置集合进行操作时,实际上是在操作一个有序集合。所以可以使用有序集合的命令来操作位置集合。
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有几百万条甚至几千万条,如果使用Redis 的Geo 数据结构,它们将被全部放在一个zset 集合中。
在Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个key 对应的数据量不宜超过1MB,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
所以,这里建议Geo 的数据使用单独的Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,需要对Geo数据进行拆分,比如按国家、按照省份进行拆分等,这样可以显著降低单个zset的大小。
2. 命令
# 存储坐标,可多个
geoadd 集合名 经度 纬度 坐标名 [经度1 纬度1 坐标名1 ...] # 获取指定位置的坐标,可多个
geopos 集合名 坐标名 [坐标名1 ... ]# 计算两个位置之间的直线距离,默认以米为单位,单位可以是:m:米,km:千米,mi:英里,ft:英尺
geodist 集合名 坐标名1 坐标名2 [单位]# 查找指定坐标半径范围内的其他位置,返回位置,比如georadius guagndong-cities 112.22123 23.05812 50 km,查找广东城市里面距离某个坐标50km范围内的城市
georadius 集合名 经度 纬度 半径 单位# 查找指定坐标半径范围内的其他位置,返回位置和坐标的距离,加上withcoord可选项的话会同时返回这些位置的坐标,也可以加上排序,默认是无序的,count是限制返回的最大数量
georadius 集合名 经度 纬度 半径 单位 [withdist] [withcoord] [ASC|DESC] [count n]# 查找指定位置半径范围内的其他位置,作用以及用法和georadius类似,但这个不是使用经纬度来指定位置的,而是通过选择位置集合中的一个位置作为中心点的
georadiusbymember 集合名 坐标名 半径 [单位] [withdist] [withcoord] [ASC|DESC] [count n]# 获取某个坐标名的Geohash,该Geohash可以转换为经纬度
geohash 集合名 坐标名 [坐标名1 ...]
比如:
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2
# 范围20公里以内最多3个元素,按照距离正序排列,不会排除自身
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> geopos company juejin
1) 1) "116.4810499548912" 2) "39.996793488582597"
127.0.0.1:6379> geopos company juejin ireader
1) 1) "116.4810499548912" 2) "39.996793488582597"
2) 1) "116.51420205831528"2) "39.905409186624944"
127.0.0.1:6379> geohash company jd
1) "wx4fk7jgtf0"
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc
1) "ireader"
2) "juejin"
3) "meituan"
127.0.0.1:6379> georadiusbymember company ireader 20 km withcoord withdist withhash count 3 desc
1) 1) "jd"2) "13.7269"3) (integer) 40691540334287154) 1) "116.56210631132126"2) "39.787602951302354"
2) 1) "meituan"2) "11.5748"3) (integer) 40698871790834784) 1) "116.48903220891953"2) "40.00766997707732"
3) 1) "juejin"2) "10.5501"3) (integer) 40698871543881674) 1) "116.4810499548912"2) "39.996793488582597"
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc
1) 1) "ireader"2) "0.0000"
2) 1) "juejin"2) "10.5501"
3) 1) "meituan"2) "11.5748"
3. 场景:用户地理位置程序
可以使用geoadd、geopos、geodist这3个命令来实现一个具有基本功能的用户地理位置程序,能够记录用户所在的位置、获取指定用户的位置和计算两个用户之间的直线距离
import redisUSER_LOCATION_KEY = "user_location"class Location:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = USER_LOCATION_KEYdef pin(self, user, longitude, latitude):"""记录指定用户的坐标。"""self.client.geoadd(self.key, longitude, latitude, user)def get(self, user):"""获取指定用户的坐标。"""position_list = self.client.geopos(self.key, user)# geopos() 允许用户输入多个用户,然后以列表形式返回各个用户的坐标# 因为我们这里只传入了一个用户,所以只需要取出列表的第一个元素即可if position_list != []:return position_list[0]def calculate_distance(self, user_a, user_b):"""以公里为单位,计算两个用户之间的直线距离。"""return self.client.geodist(self.key, user_a, user_b, unit="km")
4. 场景:查找附近用户
可以通过某个用户的坐标或位置来查找附近的用户,使用georadius或georadiusbymember命令来实现
import redis
import random
from time import timeRADIUS_CACHE_TIME = 60
USER_LOCATION_KEY = "user_location"def make_cache_radius_key(user, radius):return "cached_radius::{0}::{1}".format(user, radius)def make_last_cache_time_key(user, radius):return "last_cache_time::{0}::{1}".format(user, radius)class Location:def __init__(self, client=None):self.client = client if client else redis.Redis(decode_response=True)self.key = USER_LOCATION_KEYdef pin(self, user, longitude, latitude):"""记录指定用户的坐标。"""self.client.geoadd(self.key, longitude, latitude, user)def get(self, user):"""获取指定用户的坐标。"""position_list = self.client.geopos(self.key, user)# geopos() 允许用户输入多个用户,然后以列表形式返回各个用户的坐标# 因为我们这里只传入了一个用户,所以只需要取出列表的第一个元素即可if position_list != []:return position_list[0]def calculate_distance(self, user_a, user_b):"""以公里为单位,计算两个用户之间的直线距离。"""return self.client.geodist(self.key, user_a, user_b, unit="km")def find_nearby(self, user, radius=1):"""以公里为单位,寻找并返回 user 指定半径范围内的所有其他用户。"""# 检查缓存的更新时间,并在有需要时删除已过期的缓存cache_key = make_cache_radius_key(user, radius) # 缓存查找结果的键last_cache_time_key = make_last_cache_time_key(user, radius) # 记录缓存最后更新时间的键last_cache_time = self.client.get(last_cache_time_key) # 缓存的最后更新时间current_time = time() # 当前时间if (last_cache_time is not None) and (float(last_cache_time)+RADIUS_CACHE_TIME < current_time):# 缓存已过期,删除它self.client.delete(cache_key)# 尝试获取已缓存的查找结果,并在结果可用时,直接返回它cached_result = self.client.lrange(cache_key, 0, -1)if cached_result != []:return cached_result# 没有缓存可用,进行实际的查找,并将结果缓存起来,最后向调用者返回结果result = self.client.georadiusbymember(self.key, user, radius, unit="km") # 获取附近的所有用户all_nearby_users = filter(lambda other_user: other_user != user, result) # 移除结果中的 user 自身if all_nearby_users != []:# 缓存查找结果self.client.rpush(cache_key, *all_nearby_users)# 修改缓存的最后更新时间self.client.set(last_cache_time_key, current_time) # 返回结果return all_nearby_usersdef find_random_nearby(self, user, radius=1):"""以公里为单位,随机地返回一个位于 user 指定半径内的其他用户。"""# random.choice() 方法用于从列表中随机地选择并返回一个项return random.choice(self.find_nearby(user, radius))
4-10 Redis的数据类型之流
1. 概述
流,即stream是Redis 5.0版本新增的数据类型。流是一个包含0个或任意等多个流元素的有序队列,队列中的每个元素都包含一个ID和任意多个键值对,这些元素会根据ID的大小在流中有序排列。
**Redis流是使用Redis实现消息队列应用的最佳选择。**在Redis 5.0之前的版本中,为了实现消息队列这个应用,可以使用的方式有:列表、有序集合和发布与订阅这3种,但这3种都存在一些问题:
- 列表实现的消息队列虽然可以快速地将新消息追加到列表的末尾,但因为列表为线性结构,所以程序如果想要查找包含指定数据的元素,或者进行范围查找,就需要遍历整个列表
- 有序集合虽然可以有效地进行范围查找,但缺少列表和发布与订阅提供的阻塞弹出原语,这使得程序无法使用有序集合去实现可阻塞的消息弹出操作
- 发布与订阅虽然拥有将消息传递给多个客户端的能力,并且也拥有相应的阻塞弹出原语,但发布与订阅的“发送即忘(fire and forget)”策略会导致离线的客户端丢失消息,所以它是无法实现可靠的消息队列的
除了以上3种数据结构各自具有的问题之外,还有一个问题是3种数据结构共有的:无论是列表、有序集合还是发布与订阅,它们的元素都只能是单个值。换句话说,如果用户想要用这些数据结构实现的消息队列传递多项信息,那么必须使用JSON之类的序列化格式来将多项信息打包存储到单个元素中,然后再在取出元素之后进行相应的反序列化操作。
Redis流的出现解决了上述提到的所有问题,它是上述3种数据结构的综合体,具备它们各自的所有优点以及特点。
如下,展示了一个记录用户访问轨迹的流visits,这个流包含了ID为1100000000000-0、1200000000000-0和1300000000000-0的3个元素,它们每个都包含有3个键值对,这些键值对分别用于记录网站的访客、被访问的位置以及访客停留的时长。比如,根据ID为1100000000000-0的流元素的显示,名为peter的用户访问了位置/book/10086,并在该位置停留了150s。

流中的每个元素可以包含一个或任意多个键值对,并且同一个流中的不同元素可以包含不同数量的键值对,比如其中一个元素可以包含3个键值对,而另一个元素则可以包含5个键值对。
注意:与哈希以无序方式存储键值对的做法不同,流元素会以有序方式存储用户给定的键值对:用户在创建元素时以什么顺序给定键值对,它们在被取出的时候就是什么顺序。
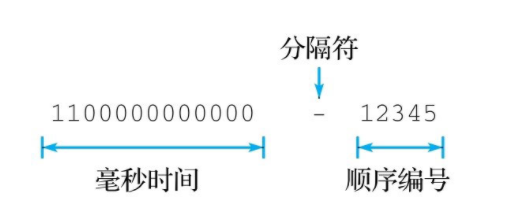
流元素的ID是由两部分组成,中间用-来隔开:
- 毫秒时间(millisecond):使用unix时间戳,用于标识与元素相关联的时间
- 顺序编号(sequcen number):用来区分同一时间内产生的多个不同元素,以0为起始值,如果不指定顺序编号,则默认从0开始
因为毫秒时间和顺序编号都使用64位的非负整数表示,所以整个流ID的总长为128位,而Redis在接受流ID输入以及展示流ID的时候都会使用连字符-分割这两个部分,比如:
注意:同一个流中的每个元素必须是唯一的,不允许重复,如添加重复的元素会报错。
除了要求元素不能重复,Redis还要求新元素的ID必须比流中所有已有元素的ID都要大。具体来说,Redis会记住每个流已有元素的最大ID,并在用户尝试向流里面添加新元素的时候,使用新元素的ID与流目前最大的ID进行对比:
- 如果新ID的毫秒时间部分比最大ID的毫秒时间部分要大,那么允许添加新元素
- 如果新ID的毫秒时间部分与最大ID的毫秒时间部分相同,那么对比两个ID的顺序编号部分,如果新ID的顺序编号部分比最大ID的顺序编号部分要大,那么允许添加新元素
相反,不符合上述两种情况的添加操作将会被拒绝,并返回一个错误。
通过将元素ID与时间进行关联,并强制要求新元素的ID必须大于旧元素的ID,Redis从逻辑上将流变成了一种只执行追加操作(append only)的数据结构,这种特性对于使用流实现消息队列和事件系统的用户来说是非常重要的:用户可以确信,新的消息和事件只会出现在已有消息和事件之后,就像现实世界里新事件总是发生在已有事件之后一样,一切都是有序进行的。
此外,只能将新元素添加到末尾而不允许在数据结构的“中间”添加新元素,这也是流与列表以及有序集合之间的一个显著区别。
流适用的场景主要是两个:
- 消息队列
- 时间序列存储,如日志
注意:Windows下的Redis版本并没有5.0版本,所以在Windows下无法执行流的相关命令。
2. 底层实现
Redis Stream的结构如上图所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
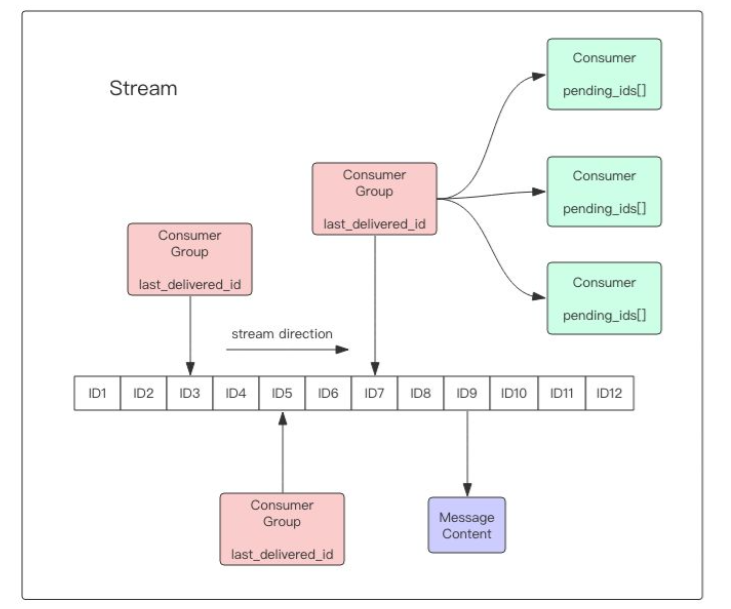
每个Stream都有唯一的名称,它就是Redis的key,在首次使用xadd指令追加消息时自动创建。
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
3. 命令
# 追加元素到流的末尾,如给定的流不存在,则会创建,返回元素id
xadd stream名 元素id key value [key1 value1 ...]# 追加元素到流的末尾,并限制流的长度,超过则根据先进先出规则移除元素
xadd stream名 maxlen 长度 元素id key value [key1 value1 ...]# 自动生成元素ID,并添加到流的末尾,生成的元素ID:当前unix时间戳和当前已有ID的最大顺序编号加1
xadd stream名 * key value [key1 value ...]# 对流进行修剪,限制流的长度,移除超过长度的元素,返回删除成功的元素个数
xtrim stream名 maxlen 长度# 移除元素,返回移除的元素数量
xdel stream名 元素id [元素id1 ...]# 获取流的元素数量
xlen stream名# 获取指定的ID范围内的多个元素,count表示指定的数量,如起始ID和结束ID一样则可认为是获取单个元素
xrange stream名 起始ID 结束ID [count 数量]# 获取大于指定的ID的所有元素,count表示指定的数量,+表示最大值
xrange stream名 起始ID + [count 数量]# 获取小于指定的ID的所有元素,count表示指定的数量,-表示最小值
xrange stream名 - 结束ID [count 数量]# 倒序获取指定的ID范围内的多个元素,count表示指定的数量,结束ID是大的id,起始ID是小的,结束ID也可以是+,起始ID也可以是-
xrevrange stream名 结束ID 起始ID [count 数量]# 从多个流中获取大于指定ID的元素,count是可选的,限制每个流最多返回的元素数量,注意,count必须放前面,block是可选的,能够以堵塞的方式来获取,如果毫秒数是为0则表示一直堵塞直到有可返回的元素,注意是所有的流都没有元素才会堵塞,某个流有元素则直接返回
xread [block 毫秒数] [count 数量] streams stream名1 [stream名2 ...] id1 [id2 ...]# 堵塞的方式只获取给定流在命令执行之后新出现的元素
xread block 毫秒数 streams stream名1 [stream名2 ...] $ [$ ...]# 查看流的信息,包括流的长度、流在底层的基数树表示的相关信息、流相关的消费者组数量、流最后生成的消息的ID以及流的第一个节点和最后一个节点
xinfo stream stream名
注意:使用XREAD命令对流进行迭代,与使用XRANGE命令、XREVRANGE命令对流进行迭代,这两种迭代方式之间主要有4点区别:
- XRANGE命令和XREVRANGE命令接受ID区间范围作为输入,而XREAD命令接受单个ID作为输入,并且前者在每次进行后续迭代时,都需要手动计算下一次迭代的起始ID,而后者只需要将上一次迭代返回的最后元素的ID用作输入即可。两者比较起来,明显是XREAD命令更方便
- 用户使用XRANGE命令和XREVRANGE命令,可以按照从头到尾和从尾到头两个方向对流进行迭代,而XREAD命令只能从流的开头向结尾进行迭代
- XREAD命令可以一次接受多个流作为输入,可以同时迭代多个流,而XRANGE命令和XREVRANGE命令每次只能迭代一个流
- XREAD命令具备阻塞功能,所以它既可以以同步方式执行,也可以以异步方式执行,而XRANGE命令和XREVRANGE命令只能以同步方式执行
比如:
# 追加元素到流的末尾
127.0.0.1:6379> xadd temp-stream 1100000000000-12345 key01 value01 key02 value02
1100000000000-12345# 流元素可以是不完整的,只有毫秒时间的,Redis会把顺序编号部分设置为0
127.0.0.1:6379> xadd temp-stream 1200000000000 k1 v1
1100000000000-0# 自动生成元素
127.0.0.1:6379> xadd temp-stream * k2 v2
15501231674520-0# 获取单个元素,如为元素不存在则返回empty list
127.0.0.1:6379> xrange temp-stream 1100000000000-12345 1100000000000-12345
1) 1) "1100000000000-12345"2) 1) "key01"2) "value01"3) "key02"4) "value02"# 获取多个元素,正序,只获取两个
127.0.0.1:6379> xrange temp-stream 1000000000000 4000000000000 count 2
1) 1) "1100000000000-12345"2) 1) "key01"2) "value01"3) "key02"4) "value02"
2) 1) "1200000000000-0"2) 1) "k1"2) "v1"# 获取所有元素
127.0.0.1:6379> xrange temp-stream - +
1) 1) "1100000000000-12345"2) 1) "key01"2) "value01"3) "key02"4) "value02"
2) 1) "1200000000000-0"2) 1) "k1"2) "v1"
3) 1) "1619532850580-0"2) 1) "k2"2) "v2"# 获取所有元素,倒序
127.0.0.1:6379> xrevrange temp-stream + -
1) 1) "1619532850580-0"2) 1) "k2"2) "v2"
2) 1) "1200000000000-0"2) 1) "k1"2) "v1"
3) 1) "1100000000000-12345"2) 1) "key01"2) "value01"3) "key02"4) "value02"# 修剪流的长度,返回删除成功的个数
127.0.0.1:6379> xtrim temp-stream maxlen 1
(integer) 2# 删除元素
127.0.0.1:6379> xdel temp-stream 100000000000 400000000000
(integer) 2# 从流mystream中获取最多2个id大于1000000000000的元素
127.0.0.1:6379> xread count 2 streams mystream 100000000000
1) 1) "mystream"2) 1) 1) 1519073278252-02) 1) "foo"2) "value_1"2) 1) 1519073279157-02) 1) "foo"2) "value_2"# 从流mystream中获取最开头的2个元素
127.0.0.1:6379> xread count 2 streams mystream 0
1) 1) "mystream"2) 1) 1) 1519073278252-02) 1) "foo"2) "value_1"2) 1) 1519073279157-02) 1) "foo"2) "value_2"# 从3个流mystream中获取最多1个id大于1000000000000的元素
127.0.0.1:6379> xread count 1 streams s1 s2 s3 100000000000 100000000000 100000000000
1) 1) "s1"2) 1) 1) 1519073278252-02) 1) "foo"2) "value_1"
2) 1) "s2"2) 1) 1) 1519073278252-02) 1) "foo"2) "value_1"
3) 1) "s3"2) 1) 1) 1519073278252-02) 1) "foo"2) "value_1" # 查看流的信息
127.0.0.1:6379> xinfo stream temp-stream1) "length"2) (integer) 13) "radix-tree-keys" # 基数树的键数量4) (integer) 15) "radix-tree-nodes" # 基数树的节点数量6) (integer) 27) "groups" # 消费者组数量8) (integer) 19) "last-generated-id" # 最后生成的消息ID
10) "1619532850580-0"
11) "first-entry" # 第一个节点
12) 1) "1619532850580-0"2) 1) "k2"2) "v2"
13) "last-entry"
14) 1) "1619532850580-0" # 最后一个节点2) 1) "k2"2) "v2"
4. 场景:消息队列
使用Stream来展示一个具有基本功能的消息队列:
def reconstruct_message_list(message_list):"""为了让多条消息能够以更结构化的方式返回给调用者,将 Redis 返回的多条消息从原来的格式:[(id1, {k1:v1, k2:v2, ...}), (id2, {k1:v1, k2:v2, ...}), ...]转换成以下格式:[{id1: {k1:v1, k2:v2, ...}}, {id2: {k1:v1, k2:v2, ...}}, ...]"""result = []for id, kvs in message_list:result.append({id: kvs})return resultdef get_message_from_nested_list(lst):"""从嵌套列表中取出消息本体。"""return lst[0][1]class MessageQueue:"""使用 Redis 流实现的消息队列。"""def __init__(self, stream_key, client=None):self.client = client if client else redis.Redis(decode_response=True)self.stream = stream_keydef add_message(self, key_value_pairs):"""将给定的键值对存入到消息里面,并返回相应的消息 ID 。"""return self.client.xadd(self.stream, key_value_pairs)def get_message(self, message_id):"""根据给定的消息 ID 返回相应的消息,如果消息不存在则返回 None 。"""reply = self.client.xrange(self.stream, message_id, message_id)if len(reply) == 1:return get_message_from_nested_list(reply)def remove_message(self, message_id):"""根据给定的消息 ID 删除相应的消息,如果消息不存在则忽略该动作。"""self.client.xdel(self.stream, message_id)def len(self):"""返回消息队列的长度。"""return self.client.xlen(self.stream)def get_by_range(self, start_id, end_id, max_item=10):"""根据给定的 ID 区间范围返回队列中的消息。"""reply = self.client.xrange(self.stream, start_id, end_id, max_item)return reconstruct_message_list(reply)def iterate(self, start_id=0, max_item=10):"""对消息队列进行迭代,返回最多 N 条大于给定 ID 的消息。"""reply = self.client.xread({self.stream: start_id}, max_item)if len(reply) == 0:return list()else:messages = get_message_from_nested_list(reply)return reconstruct_message_list(messages)
实例化之后,使用add_message来插入到队列中,使用get_by_range或者是使用iterater来进行迭代获取消息等
5. 消费者组
Redis的流在数量非常大的时候或者是当某些消息在消费比较耗时的情况下,如果只有一个消费者那么消息的速度会比较慢,消费者承担了比较大的压力,因此,Redis流提供了消费者组的概念,从而允许多个消费者处理同一个流来实现负载平衡。
Redis流的消费者组(consumer group)允许用户将一个流从逻辑上划分为多个不同的流,并让消费者组属下的消费者去处理组中的消息。
比如有如下一个流,有3个消费者组,处理的元素的不同,如下:
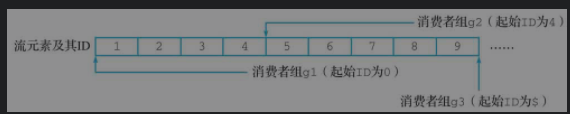
通过为不同的消费者组设置不同的起点ID,我们把一个流从逻辑上划分成了3个不同的流,它们包含各不相同的元素,如下:

同一个流的消息在不同消费者组之间是共享而不是独占的,换句话说,流中的同一条消息可以被多个不同组的消费者读取,并且来自不同消费者组的读取操作不会对其他消费者组的读取操作产生任何影响。
创建消费者组
# 创建消费者组,起始id决定了消费者组从哪个id开始读取,如果想从流开头进行读取,那么起始id可设置为0,注意:创建消费者组之前,必须存在流,如流不存在则会报错
xgroup create stream名 group名 起始id
在使用该命令xgroup create stream名 group名 起始id创建消费者组的时候,有几个注意的地方:
- 创建消费者组之前,必须存在流,如流不存在则会报错
- 起始id指定了消费者组的最后递送的消息id,即消费者组下的消费者只能接收到ID大于该起始id的消息,并且消费者组的最后递送消息ID还会随着消费者执行的读取操作而不断的更新
- 起始id可以设置为0,0表示从流的最开始的元素开始读取
如下为temp-stream创建一个消费者组group_a:
127.0.0.1:6379> xgroup create temp-stream group_a 0
OK
查看消费者组信息
可以通过以下命令来查看:
# 查看流下的消费者组的信息
xinfo groups stream名
返回的信息包括:
- 消费者组名字
- 所拥有的消费者数量
- 组中正在处理消息的数量
- 最后递送消息ID
如下:
127.0.0.1:6379> xinfo groups temp-stream
1) 1) "name"2) "group_a"3) "consumers"4) (integer) 05) "pending"6) (integer) 07) "last-delivered-id"8) "0-0"
修改消费者组的消息id
对于一个已经存在的消费者组来说,用户可以通过执行XGROUP SETID命令来为消费者组设置新的最后递送消息ID:
# 修改消费者组的最后递送消息id,也可以是$,表示消费者组的最后消息id,注意,该消息id是可以小于旧的id的,但会产生问题:消费者可能会重新读取到之前已经消费过的消息
xgroup setid stream名 group名 消息id
命令给定的ID可以是任意合法的消息ID,ID对应的消息不必实际存在,并且新ID可以大于、小于甚至等于当前ID。
除了合法的消息ID之外,特殊符号$也可以用作id参数的值,这个符号可以把消费者组的最后递送消息ID设置为流最新消息的ID。
修改了之后可以通过xinfo groups group名命令来查看
需要注意的是,使用XGROUP SETID命令显式地修改最后递送消息ID将对后续执行的XREADGROUP命令的结果产生影响,简单来说:
- 如果新ID大于旧ID,那么消费者可能会漏掉一些原本应该读取的消息
- 如果新ID小于旧ID,那么消费者可能会重新读取到一些之前已经被确认过的消息
所以,该命令需要谨慎使用。
删除消费者组/消费者
当用户不再需要某个消费者/消费者组的时候,可以通过执行以下命令将其删除:
# 删除消费者组,成功返回1,失败返回0,返回消费者被删除时,它仍在处理的消息数量。
xgroup destroy stream名 group名# 删除消费者,返回消费者仍在处理的消息数量
xgroup delconsumer stream名 group名 consumer名
需要注意的是,当消费者被删除之后,它在被删除时处理的消息也会从消费者组的待处理消息队列中移除。换句话说,属于被删除消费者的待处理消息将不再处于“待处理”状态,这些消息可能已经被消费者处理掉了,但也可能尚未得到妥善的处理。
为了避免这个问题,用户在删除一个消费者之前应该确保递送给它的所有消息均已处理完毕,或者使用XCLAIM命令显式地转移待处理消息的归属权。换句话说,为了保证程序的正确性,用户应该保证每个XGROUP DELCONSUMER命令的返回值都为0。
同样的,删除消费者组也同样存在以上问题,所以在删除消费者组的时候,需要保证组中已经没有待处理的消息,否则这些待处理消息可能无法得到妥善的处理。
读取消费者组的消息
用户可以使用以下命令来读取消费者组中的消息:
# 读取消费者组
xreadgroup group group名 consumer名 [block 毫秒数] [count 数量] streams stream名1 [stream名2 ...] 起始id [起始id ...]
xreadgroup命令和xread命令格式和用法基本一致,如下:
127.0.0.1:6379> xreadgroup group group_a worker_a count 3 streams temp-stream 0
1) 1) "temp-stream"2) (empty list or set)
该命令在读取消息的同时,如果消费者不存在的话,则会自动创建消费者,而且还会将该消息分别添加到消费者组的待处理消息队列以及消费者的待处理消息队列中,从而使得被读取消息的状态从原来的“未递送”转变成“待处理”,这一点可以通过以下两条命令来确认:
# 查看消费者组的待处理消息队列
xpending stream名 group名# 查看消费者的待处理消息队列,-表示最小值,+表示最大值
xpending stream名 group名 - + 消费者名
xreadgroup命令除了会把被读取的消息添加到上述两个队列之外,还会将最后一条被读取的消息的ID设置成消费者组的最后递送消息ID,这一点可以通过命令xinfo groups group名来确认。
注意:与多个消费者组能够共享同一个流中的元素不一样,同一消费者组中的每条消息只能有一个消费者,换句话说,不同的消费者将独占组中的不同消息:当一个消费者读取了组中的一条消息之后,同组的其他消费者将无法读取这条消息。
消费者
当消费者处理完一条消息之后,它需要向Redis发送一条针对该消息的XACK命令:
xack stream名 group名 id [id ...]
当Redis接收到消费者发来的XACK命令之后,就会从消费者组的待处理消息队列以及消费者的待处理消息队列中移除指定的消息。这样一来,这些消息的状态就会从“待处理”转换为“已确认”,以此来表示消费者已经处理完这些消息了。
综合起来,一条消费者组消息从出现到处理完毕,需要经历以下阶段:
- 首先,当一个生产者通过XADD命令向流中添加一条消息时,该消息就从原来的“不存在”状态转换成了“未递送”状态。
- 然后,当一个消费者通过XREADGROUP命令从流中读取一条消息时,该消息就从原来的“未递送”状态转换成了“待处理”状态。
- 最后,当消费者完成了对消息的处理,并通过XACK命令向服务器进行确认时,该消息就从原来的“待处理”状态转换成了“已确认”状态,此时通过xpending查看消费者组或消费者的待处理消息队列就不存在该消息了。
如下图:

6. 场景:消息队列(消费者组)
在消息队列类MessageQueue(场景4)的基础上,为其提供基于消费者组的消息读取功能,用户只需要使用MessageQueue类向队列中添加消息,然后使用Group类创建出消费者组,就可以通过消费者组方式读取组的消息了。
from message_queue import reconstruct_message_list, get_message_from_nested_listclass Group:"""为消息队列提供消费者组功能。"""def __init__(self, stream, group, client=None):self.client = client if client else redis.Redis(decode_response=True)self.stream = streamself.group = groupdef create(self, start_id):"""创建消费者组。"""self.client.xgroup_create(self.stream, self.group, start_id)def destroy(self):"""删除消费者组。"""self.client.xgroup_destroy(self.stream, self.group)def read_message(self, consumer, id, count=10):"""从消费者组中读取消息。"""reply = self.client.xreadgroup(self.group, consumer, {self.stream: id}, count)if len(reply) == 0:return list()else:messages = get_message_from_nested_list(reply)return reconstruct_message_list(messages)def ack_message(self, id):"""确认已处理完毕的消息。"""self.client.xack(self.stream, self.group, id)def info(self):"""返回消费者组的相关信息。"""# 因为一个流可以拥有多个消费者组# 所以我们需要从命令返回的多个组信息中找到正确的信息for group_info in self.client.xinfo_groups(self.stream):if group_info['name'] == self.group:return group_infoelse:return dict()def consumer_info(self):"""返回消费者组属下消费者的相关信息。"""return self.client.xinfo_consumers(self.stream, self.group)def delete_consumer(self, consumer):"""删除指定消费者。"""self.client.xgroup_delconsumer(self.stream, self.group, consumer)
要使用该消费者功能的话,需要同时引入消息队列类MessageQueue和消费者类Group,并创建对应实例,然后向消息队列添加消息,并通过消费者组来读取消息:
from message_queue import MessageQueue
from group import Groupstream = 'test_stream'
group = 'test_group'
queue = MessageQueue(stream)
group = Group(stream, group)# 添加消息
queue.add_message({'key1': 'value1'})# 创建消费者组
group.create(0)# 通过消费者组来读取消息
message_list = group.read_message('worker1', ">")# todo 处理消息# 确认消息
group.ack_message(消息id)# 查看消费者组
group.info()# 查看消费者信息
group.consumer_info()
5-1 Redis的通用命令
命令:
# 选择某个db,不选的话默认是0,即第一个,Redis一共有16个db
select db# 查询所有key,会影响Redis的性能,堵塞线程,慎用,可使用scan代替
keys *# 查询以字符串str开头的key,?表示一个字符,即只符合str1、str2这种,不能符合strtest这种
keys str?# 查询以字符串str开头的key,*表示一个或多个字符
keys str*# 删除多个key,返回成功删除的个数
del key1 key2 key3 ...# 判断key是否存在,存在返回1不存在返回0
exists key# 对key进行重命名
rename key newkey# 设置过期的时间
expire key times(秒) # 查看key所剩的时间,若没有设置,则返回-1
ttl key# 获取指定key的类型吗,比如string、list、hash、set、zset等
type key# 查询对应的key
scan 游标 [match 正则表达式] [count 数量]
参考
- Redis官网
- Redis中文官网
- 慕课网-Redis入门
- 《Redis使用手册》
- 《Redis深度历险:核心原理与应用实践》
- 我画了19张图,帮你彻底搞懂Redis
- 见缝插针 —— 深入 Redis HyperLogLog 内部数据结构分析
- [Redis:从应用到底层,一文帮你搞定](Redis:从应用到底层,一文帮你搞定 (qq.com))
- GitHub - huangz1990/RedisGuide-code