Linux之旅 13:磁盘配额与高级文件管理

图源:pixels
磁盘配额(quota)的应用与实践
什么是磁盘配额
磁盘配额的一般用途
- 限制某一用户组能使用的最大磁盘配额
- 限制某一用户的最大磁盘配额
- 限制某一目录的最大磁盘配额
磁盘配额是为管理员提供磁盘使用率以及让管理员管理磁盘的工具。
磁盘配额的使用限制
-
ext文件系统仅能针对整个文件系统xfs可以使用project模式针对目录设置磁盘配额。 -
内核必须支持磁盘配额
CentOS7.X内核是支持的。
-
只对一般用户有效
-
若启动SELinux,并非所有目录都可以设置磁盘配额
新版的CentOS都会启用SELinux,在这种情况下,仅有
/home目录可以设置磁盘配额。
磁盘配额的规范设置选项
针对xfs文件系统,磁盘配额可以从这些方面进行限制:
- 用户、用户组和个别目录(user、group与project)
- 容量限制或文件数量限制(block或inode)
- 软限制与硬限制(soft/hard)
- hard:用户的使用量绝对不能超过这个值,如果超过将锁定用户对磁盘的使用权,不能再写入数据。
- soft:用户对磁盘的使用量可以超过这个值,但会在再次登录系统时收到警告信息,且需要在一个宽限日期(grace time)内将使用量削减到这个数值以下,如果超过宽限期依然超过这个值,则系统会使用
hard设定的值替换soft的值,并将用户的磁盘使用权限锁定。
一个xfs文件系统的磁盘配额实践
在进行实战前,需要先准备一下需要使用的环境,这是我编写的脚本(参考了《鸟哥的私房菜》):
#!/bin/bash
# add account before quota test
group_name='my_quota_group'
groupadd $group_name
accounts=('myquota1' 'myquota2' 'myquota3' 'myquota4' 'myquota5')
for account in ${accounts[@]}
douseradd -g $group_name $accountecho 'password' | passwd --stdin $account
done
project_dir='/home/myquota'
mkdir $project_dir
chmod 2770 $project_dir
chgrp $group_name $project_dir
exit 0
使用root账号执行脚本:
[root@xyz ~]# cd ~icexmoon/
[root@xyz icexmoon]# cd shell_scripts/
[root@xyz shell_scripts]# sh add_account.sh
更改用户 myquota1 的密码 。
passwd:所有的身份验证令牌已经成功更新。
更改用户 myquata2 的密码 。
passwd:所有的身份验证令牌已经成功更新。
更改用户 myquota3 的密码 。
passwd:所有的身份验证令牌已经成功更新。
更改用户 myquota4 的密码 。
passwd:所有的身份验证令牌已经成功更新。
更改用户 myquota5 的密码 。
passwd:所有的身份验证令牌已经成功更新。
[root@xyz shell_scripts]# grep myquota* /etc/passwd
myquota1:x:1508:1511::/home/myquota1:/bin/bash
myquota3:x:1510:1511::/home/myquota3:/bin/bash
myquota4:x:1511:1511::/home/myquota4:/bin/bash
myquota5:x:1512:1511::/home/myquota5:/bin/bash
[root@xyz shell_scripts]# grep quota /etc/group
my_quota_group:x:1511:
[root@xyz shell_scripts]# ll -d /home/myquota
drwxrws---. 2 root my_quota_group 6 8月 23 16:57 /home/myquota
用户和用户组以及项目目录配置无误后我们进行下一步。
实战1:文件系统的支持与查看
给/home目录所在的xfs文件系统开启磁盘配额功能:
[root@xyz shell_scripts]# vim /etc/fstab
...省略...
#filesystem name mount point type
...省略...
/dev/mapper/centos-home /home xfs defaults,usrquota,grpquota 0 0
...省略...
[root@xyz ~]# umount /home
[root@xyz ~]# mount -a
[root@xyz ~]# mount | grep home
/dev/mapper/centos-home on /home type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,grpquota)
需要注意的是,卸载/home目录的时候需要先切换到/home之外的目录,如果是通过su -切换进root用户的,则切换前的用户的工作目录也必须不在/home中,否则都会显示umount: /home:目标忙。。
在fstab中添加的选项defaults,usrquota,grpquota实际上对应着前边说的这几个磁盘配额限制项:
uquota/usrquota/quota:针对用户账号的限制gquota/grpquota:针对用户组的限制pquota/prjquota:针对单一目录的限制(不能与对用户组的限制同时使用)
实战2:查看磁盘配额报告数据
可以使用xfs_quota命令查看哪些文件系统开启了磁盘配额功能:
[root@xyz ~]# xfs_quota -x -c 'print'
Filesystem Pathname
/ /dev/mapper/centos-root
/srv/myproject /dev/sda4
/boot /dev/sda2
/home /dev/mapper/centos-home (uquota, gquota)
这里的-x参数的作用是“专家模式”,只有使用了这个参数才可以使用-c参数执行各种子命令。
还可以查看指定文件系统的使用情况:
[root@xyz ~]# xfs_quota -x -c 'df -h' /home
Filesystem Size Used Avail Use% Pathname
/dev/mapper/centos-home5.0G 1.1G 3.9G 22% /home
有点像df -h。
查看文件系统当前的磁盘配额设置情况:
[root@xyz ~]# xfs_quota -x -c 'report -ubih' /home
User quota on /home (/dev/mapper/centos-home)Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
root 0 0 0 00 [------] 4 0 0 00 [------]
icexmoon 1.0G 0 0 00 [------] 2.8k 0 0 00 [------]
user1 20K 0 0 00 [------] 13 0 0 00 [------]
chagetest 20K 0 0 00 [------] 13 0 0 00 [------]
myuser1 20K 0 0 00 [------] 13 0 0 00 [------]
myuser2 12K 0 0 00 [------] 7 0 0 00 [------]
myuser3 12K 0 0 00 [------] 7 0 0 00 [------]
pro1 20K 0 0 00 [------] 13 0 0 00 [------]
pro2 12K 0 0 00 [------] 7 0 0 00 [------]
pro3 12K 0 0 00 [------] 7 0 0 00 [------]
myquota1 12K 0 0 00 [------] 7 0 0 00 [------]
myquata2 12K 0 0 00 [------] 7 0 0 00 [------]
myquota3 12K 0 0 00 [------] 7 0 0 00 [------]
myquota4 12K 0 0 00 [------] 7 0 0 00 [------]
myquota5 12K 0 0 00 [------] 7 0 0 00 [------]
子命令report的参数分别表示:
u:用户g:用户组p:projectb:blocki:inodeh:human,类似于df -h中的h参数的作用。
xfs_quota子命令几乎都支持上面的这几个参数。
打印的配额情况分为两部分,左边是Blocks,也就是对容量的限制,右边是Inodes,也就是文件数量的限制。
如果要查看磁盘配额功能的状态:
[root@xyz ~]# xfs_quota -x -c 'state' /home
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
可以看到,用户和用户组的磁盘配额功能都已开启,而目录(Project)的磁盘配额功能则处于关闭状态。此外Accounting的含义为对当前配额使用情况的记录功能,Enforcement的含义是对超过Soft或Hard的情况进行处理。一般来说是会同时开启和关闭的,但特殊情况下我们可以单独关闭Enforcement,只让Accounting生效,此时磁盘配额功能只会对超出配额的情况进行记录,但不会实际执行限制操作。
实战3:限制值设置
给前边通过脚本添加的用户添加磁盘配额限制:
[root@xyz ~]# xfs_quota -x -c 'limit -u bsoft=250M bhard=300M myquota1' /home
[root@xyz ~]# xfs_quota -x -c 'limit -u bsoft=250M bhard=300M myquota2' /home
[root@xyz ~]# xfs_quota -x -c 'limit -u bsoft=250M bhard=300M myquota3' /home
[root@xyz ~]# xfs_quota -x -c 'limit -u bsoft=250M bhard=300M myquota4' /home
[root@xyz ~]# xfs_quota -x -c 'limit -u bsoft=250M bhard=300M myquota5' /home
[root@xyz ~]# xfs_quota -x -c 'report -ubih' /home
User quota on /home (/dev/mapper/centos-home)Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
root 0 0 0 00 [------] 4 0 0 00 [------]
icexmoon 1.0G 0 0 00 [------] 2.8k 0 0 00 [------]
user1 20K 0 0 00 [------] 13 0 0 00 [------]
chagetest 20K 0 0 00 [------] 13 0 0 00 [------]
myuser1 20K 0 0 00 [------] 13 0 0 00 [------]
myuser2 12K 0 0 00 [------] 7 0 0 00 [------]
myuser3 12K 0 0 00 [------] 7 0 0 00 [------]
pro1 20K 0 0 00 [------] 13 0 0 00 [------]
pro2 12K 0 0 00 [------] 7 0 0 00 [------]
pro3 12K 0 0 00 [------] 7 0 0 00 [------]
myquota1 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota2 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota3 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota4 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota5 12K 250M 300M 00 [------] 7 0 0 00 [------]
bsoft=250M是指block的soft限制为250M,bhard则是block的hard限制。对应的,inode的soft和hard限制参数则是isoft和ihard。
类似的,可以对用户组设置磁盘配额:
[root@xyz ~]# xfs_quota -xc 'limit -g bsoft=950M bhard=1G my_quota_group' /home
[root@xyz ~]# xfs_quota -xc 'report -gbih' /home
Group quota on /home (/dev/mapper/centos-home)Blocks Inodes
Group ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
root 0 0 0 00 [------] 3 0 0 00 [------]
icexmoon 1.0G 0 0 00 [------] 2.8k 0 0 00 [------]
user1 20K 0 0 00 [------] 13 0 0 00 [------]
chagetest 20K 0 0 00 [------] 13 0 0 00 [------]
myuser1 20K 0 0 00 [------] 13 0 0 00 [------]
myuser2 12K 0 0 00 [------] 7 0 0 00 [------]
myuser3 12K 0 0 00 [------] 7 0 0 00 [------]
pro1 20K 0 0 00 [------] 13 0 0 00 [------]
pro2 12K 0 0 00 [------] 7 0 0 00 [------]
pro3 12K 0 0 00 [------] 7 0 0 00 [------]
my_quota_group 60K 950M 1G 00 [------] 36 0 0 00 [------]
如果要修改磁盘配额的宽限时间,可以:
[root@xyz ~]# xfs_quota -xc 'timer -b -u 14days' /home
[root@xyz ~]# xfs_quota -xc 'timer -b -g 14days' /home
[root@xyz ~]# xfs_quota -xc 'state'
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [14 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
子命令timer默认接收的时间单位为秒,但是可以使用一些常见的时间字符串,比如14days。
切换到myquota1用户进行测试:
[root@xyz ~]# su - myquota1
[myquota1@xyz ~]$ dd if=/dev/zero of=./quota_test bs=1M count=310
dd: 写入"./quota_test" 出错: 超出磁盘限额
记录了300+0 的读入
记录了299+0 的写出
313524224字节(314 MB)已复制,1.36042 秒,230 MB/秒
[myquota1@xyz ~]$ ll -h
总用量 299M
-rw-r--r--. 1 myquota1 my_quota_group 299M 8月 23 18:05 quota_test
[myquota1@xyz ~]$ exit
登出
[root@xyz ~]# xfs_quota -xc 'report -ubih' /home
User quota on /home (/dev/mapper/centos-home)Blocks Inodes
User ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
root 0 0 0 00 [0 days] 4 0 0 00 [------]
icexmoon 1.0G 0 0 00 [------] 2.8k 0 0 00 [------]
user1 20K 0 0 00 [------] 13 0 0 00 [------]
chagetest 20K 0 0 00 [------] 13 0 0 00 [------]
myuser1 20K 0 0 00 [------] 13 0 0 00 [------]
myuser2 12K 0 0 00 [------] 7 0 0 00 [------]
myuser3 12K 0 0 00 [------] 7 0 0 00 [------]
pro1 20K 0 0 00 [------] 13 0 0 00 [------]
pro2 12K 0 0 00 [------] 7 0 0 00 [------]
pro3 12K 0 0 00 [------] 7 0 0 00 [------]
myquota1 299.0M 250M 300M 00 [13 days] 14 0 0 00 [------]
myquota2 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota3 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota4 12K 250M 300M 00 [------] 7 0 0 00 [------]
myquota5 12K 250M 300M 00 [------] 7 0 0 00 [------]
实战4:目录(project)的限制
要使用project磁盘配额,需要先修改/etc/fstab,并且重新挂载/home:
[root@xyz ~]# vim /etc/fstab
...省略...
/dev/mapper/centos-home /home xfs defaults,usrquota,prjquota 0 0
...省略...
[root@xyz ~]# umount /home
[root@xyz ~]# mount -a
[root@xyz ~]# mount | grep /home
/dev/mapper/centos-home on /home type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,prjquota)
[root@xyz ~]# xfs_quota -xc 'state' /home
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [14 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
可以看到用户组的磁盘配额功能已关闭,Project相关的磁盘配额则已开启。
要配置project磁盘配额,还需要设置一个project_name和project_id:
[root@xyz ~]# echo 'myquotaproject:11' >> /etc/projid
[root@xyz ~]# echo '11:/home/myquota' >> /etc/projects
初始化project:
[root@xyz ~]# xfs_quota -xc 'project -s myquotaproject'
Setting up project myquotaproject (path /home/myquota)...
Processed 1 (/etc/projects and cmdline) paths for project myquotaproject with recursion depth infinite (-1).
Setting up project myquotaproject (path /home/myquota)...
Processed 1 (/etc/projects and cmdline) paths for project myquotaproject with recursion depth infinite (-1).
Setting up project myquotaproject (path /home/myquota)...
Processed 1 (/etc/projects and cmdline) paths for project myquotaproject with recursion depth infinite (-1).
Setting up project myquotaproject (path /home/myquota)...
Processed 1 (/etc/projects and cmdline) paths for project myquotaproject with recursion depth infinite (-1).
这样就设置好一个可以在xfs_quota中使用的project了,可以进行查看:
[root@xyz ~]# xfs_quota -xc 'print' /home
Filesystem Pathname
/home /dev/mapper/centos-home (uquota, pquota)
/home/myquota /dev/mapper/centos-home (project 11, myquotaproject)
[root@xyz ~]# xfs_quota -xc 'report -pbih' /home
Project quota on /home (/dev/mapper/centos-home)Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 1.3G 0 0 00 [------] 3.0k 0 0 00 [------]
myquotaproject 0 0 0 00 [------] 1 0 0 00 [------]
子命令print可以显示/home目录下设置了磁盘配额的目录和相应的方式。
下面添加myquotaproject这个project的磁盘配额限制:
[root@xyz ~]# xfs_quota -xc 'limit -p bsoft=450M bhard=500M myquotaproject' /home
[root@xyz ~]# xfs_quota -xc 'report -pbih' /home
Project quota on /home (/dev/mapper/centos-home)Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 1.3G 0 0 00 [------] 3.0k 0 0 00 [------]
myquotaproject 0 450M 500M 00 [------] 1 0 0 00 [------]
测试一下,在/home/myquota目录添加一个510M大小的文件:
[root@xyz myquota]# dd if=/dev/zero of=./quota_test bs=1M count=510
dd: 写入"./quota_test" 出错: 设备上没有空间
记录了501+0 的读入
记录了500+0 的写出
524288000字节(524 MB)已复制,1.45692 秒,360 MB/秒
[root@xyz myquota]# df -h /home
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-home 5.0G 1.9G 3.2G 38% /home
[root@xyz myquota]# xfs_quota -xc 'report -pbih' /home
Project quota on /home (/dev/mapper/centos-home)Blocks Inodes
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
---------- --------------------------------- ---------------------------------
#0 1.3G 0 0 00 [------] 3.0k 0 0 00 [------]
myquotaproject 500M 450M 500M 00 [13 days] 2 0 0 00 [------]
我们设置的限制的确起作用了,即使我们当前是使用root在操作,也无法创建超过配额的文件。
磁盘配额的额外命令
如果需要暂时关闭磁盘配额功能,可以:
[root@xyz myquota1]# xfs_quota -xc 'disable -up' /home
[root@xyz myquota1]# xfs_quota -xc 'state' /home
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: OFFInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [14 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
可以看到虽然Accounting是开启的,但Enforcement关闭了,也就不存在实际的磁盘配额限制。
实际测试一下:
[root@xyz myquota1]# !724
dd if=/dev/zero of=./quota_test bs=1M count=510
记录了510+0 的读入
记录了510+0 的写出
534773760字节(535 MB)已复制,1.01029 秒,529 MB/秒
[root@xyz myquota1]# ll -h
总用量 510M
-rw-r--r--. 1 root root 510M 8月 23 19:02 quota_test
project限制已经不起作用了。
要重新启用也很容易:
[root@xyz myquota1]# xfs_quota -xc 'enable -up' /home
[root@xyz myquota1]# xfs_quota -xc 'state' /home
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [14 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
如果要完全关闭磁盘配额功能:
[root@xyz myquota1]# xfs_quota -xc 'off -up' /home
[root@xyz myquota1]# xfs_quota -xc 'state' /home
[root@xyz myquota1]# xfs_quota -xc 'enable' /home
XFS_QUOTAON: 函数未实现
关闭后state子命令不会再打印任何信息,并且也无法通过enable重新启用,如果要重新启用,只能通过将文件系统卸载后再重新加载的方式开启:
[root@xyz myquota1]# cd /
[root@xyz /]# umount /home
[root@xyz /]# mount -a
[root@xyz /]# xfs_quota -xc 'state' /home
User quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200363 (3 blocks, 3 extents)
Group quota state on /home (/dev/mapper/centos-home)Accounting: OFFEnforcement: OFFInode: #200364 (3 blocks, 3 extents)
Project quota state on /home (/dev/mapper/centos-home)Accounting: ONEnforcement: ONInode: #200364 (3 blocks, 3 extents)
Blocks grace time: [7 days]
Inodes grace time: [7 days]
Realtime Blocks grace time: [7 days]
如果要移除已经设定的某种磁盘配额限制:
[root@xyz /]# xfs_quota -xc 'off -up' /home
[root@xyz /]# xfs_quota -xc 'remove -p' /home
[root@xyz /]# umount /home
[root@xyz /]# mount -a
[root@xyz /]# xfs_quota -xc 'report' /home
User quota on /home (/dev/mapper/centos-home)Blocks
User ID Used Soft Hard Warn/Grace
---------- --------------------------------------------------
root 0 0 0 00 [--------]
icexmoon 1091852 0 0 00 [--------]
user1 20 0 0 00 [--------]
chagetest 20 0 0 00 [--------]
myuser1 20 0 0 00 [--------]
myuser2 12 0 0 00 [--------]
myuser3 12 0 0 00 [--------]
pro1 20 0 0 00 [--------]
pro2 12 0 0 00 [--------]
pro3 12 0 0 00 [--------]
myquota1 20 256000 307200 00 [--------]
myquota2 12 256000 307200 00 [--------]
myquota3 12 256000 307200 00 [--------]
myquota4 12 256000 307200 00 [--------]
myquota5 12 256000 307200 00 [--------]Project quota on /home (/dev/mapper/centos-home)Blocks
Project ID Used Soft Hard Warn/Grace
---------- --------------------------------------------------
#0 1092048 0 0 00 [--------]
myquotaproject 0 0 0 00 [--------]
需要说明的是,要使用remove子命令,必须要先使用off关闭磁盘配额功能,而且虽然我们只是移除project的相关配置,但是我们需要使用off关闭project和user的所有功能。然后还要卸载和重新加载/home,以重新启用磁盘配额功能。最后可以看到project的相关配额设置都被消除了,而用户相关的配额设置还在。
不修改既有系统的磁盘配额实例
如前边所说,一般情况下我们只能在/home目录下使用磁盘配额,且无法对两个目录使用一个project配额限制,但是我们可以通过另一种方法实现类似的需求,比如将某个目录移动到一个配置了project配额的/home子目录下,然后设置一个软链接从原来的位置指向新的位置。
但这种设置依然可能受到SELinux限制,可能需要先关闭SELinux,处理完后再重新开启。
软件磁盘阵列
什么是RAID
RAID的全称为 Redundant Arrays of Independent Disks,翻译为独立磁盘冗余阵列。大概的意思应当是将多个独立磁盘组合起来,形成一个有冗余的存储系统。
RAID不仅有数据存储的功能,还可以有数据保护的功能。
RAID因为功能和使用场景的不同,划分为很多级别,以下是几种常见的RAID:
RAID0
RAID0很容易理解,通常我们买笔记本的时候会挑选有双通道内存的型号为佳,所谓的双通道就是有两根同一个型号的内存条,安装到主板的内存插槽上,这样一来CPU对内存中数据的读写速度都会翻倍,性能自然要优于单通道内存的笔记本。而RAID0的原理和双通道内存一样,通过挂载两块以上的硬盘,当CPU将输出从数据总线传输到磁盘存储时,数据将会切分为多块,同时存储到组成RAID0的多个磁盘上,如果数据总线的性能不是瓶颈的话,数据的传输速度就会是单个磁盘的N倍,N是组成RAID0的磁盘个数。
整个RAID0系统可以用下图表示:
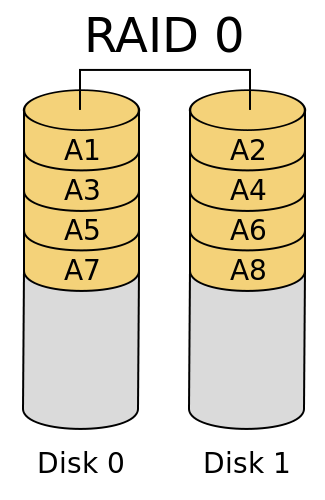
图源:RAID有哪几种?有什么区别?
需要注意的是,因为RAID0进行存储时,会将数据以chunck为单位,“均匀地”存储在每个磁盘上,所以最好每块磁盘具有相同地大小,因为整个磁盘整列所能存储的最大容量为“最小的磁盘容量*N”。
RAID0的优点是具有良好的读写性能,这是显而易见的。缺点也很明显,如果不使用RAID,你会顺序存储文件,一个磁盘满了以后存储另一个,如果有一个磁盘损坏,也只会影响该磁盘内的数据。但使用RAID0之后,所有的数据都是切分后均匀地存储在每一个磁盘上,所以一旦有有一个磁盘损坏,所有数据都会损坏。
RAID1
RAID0是侧重于读写性能的方案,RAID1则是侧重于数据安全的方案。
一般来说RAID1会由两块磁盘组成,对于每一个从数据总线写入RAID1的数据,都会在写入一个磁盘的同时复制一份,保存在另一块磁盘中。整个系统可以用下图表示:
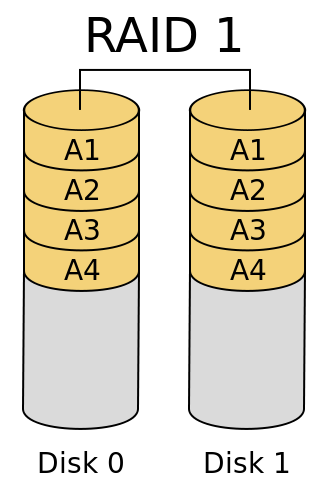
图源:RAID有哪几种?有什么区别?
从结果上看,一个磁盘可以看作另一个磁盘的镜像。
RAID1的优点很明显,一个磁盘损坏后另一个磁盘上的数依然是完整的,它们互为备份,而两块磁盘同时损坏的概率还是非常低的,所以可以看作是数据安全的结构。此外,在数据读取方面性能依然是不错的,因为一份数据可以从两块硬盘上分别读入两部分,读入性能翻倍。
但缺点也同样明显,相对于非RAID的方案,不仅没有提升数据写入性能,反而可能因为需要CPU的南桥多复制一份数据通过数据总线传输,不仅加重了CPU的负担,还占用了数据总线的带宽,导致的结果就是写入性能的下降。当然,如果使用硬件磁盘阵列卡,不通过CPU和数据总线,而是在磁盘这端通过阵列卡的芯片进行数据复制和分发,就不会有上边的问题,不会大幅度影响写入性能,但一来同样不会提升写入速度,二来磁盘阵列卡很贵。
RAID1+0(RAID10)
现在肯定有人问了,能不能既有读写速度提升的优点,又有数据安全的优点。
答案是有的,RAID1+0方案就是其中之一,所谓的1+0,就是先用两块硬盘组成一个RAID1,即互为备份。然后用多组RAID1组成一个RAID0,自然也就可以提升读写性能。如果使用硬件的磁盘阵列卡,忽略RAID1对写入速度的影响,则整个系统在数据安全的基础上,读写性能均提升了N/2倍(N为整个磁盘阵列的磁盘个数)。
整个系统可以用下图表示:
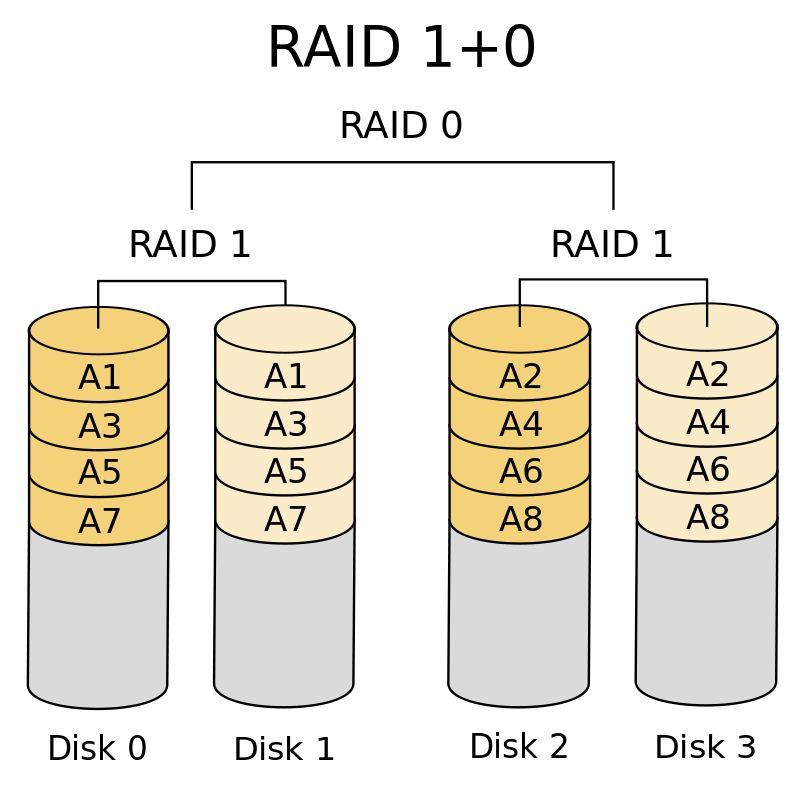
图源:RAID有哪几种?有什么区别?
这种方案同时具有RAID0与RAID1的优点,但是缺点是需要大量磁盘,因为整个系统的容量是“单个磁盘的容量*N/2”,系统中有一半的磁盘都是用于备份的磁盘,可以说有较高的存储成本。
RAID0+1(RAID01)
RAID0+1与RAID1+0的组成顺序相反,先用块硬盘组成RAID0,再将两组RAID0组成RAID1,整个系统可以用下图表示:
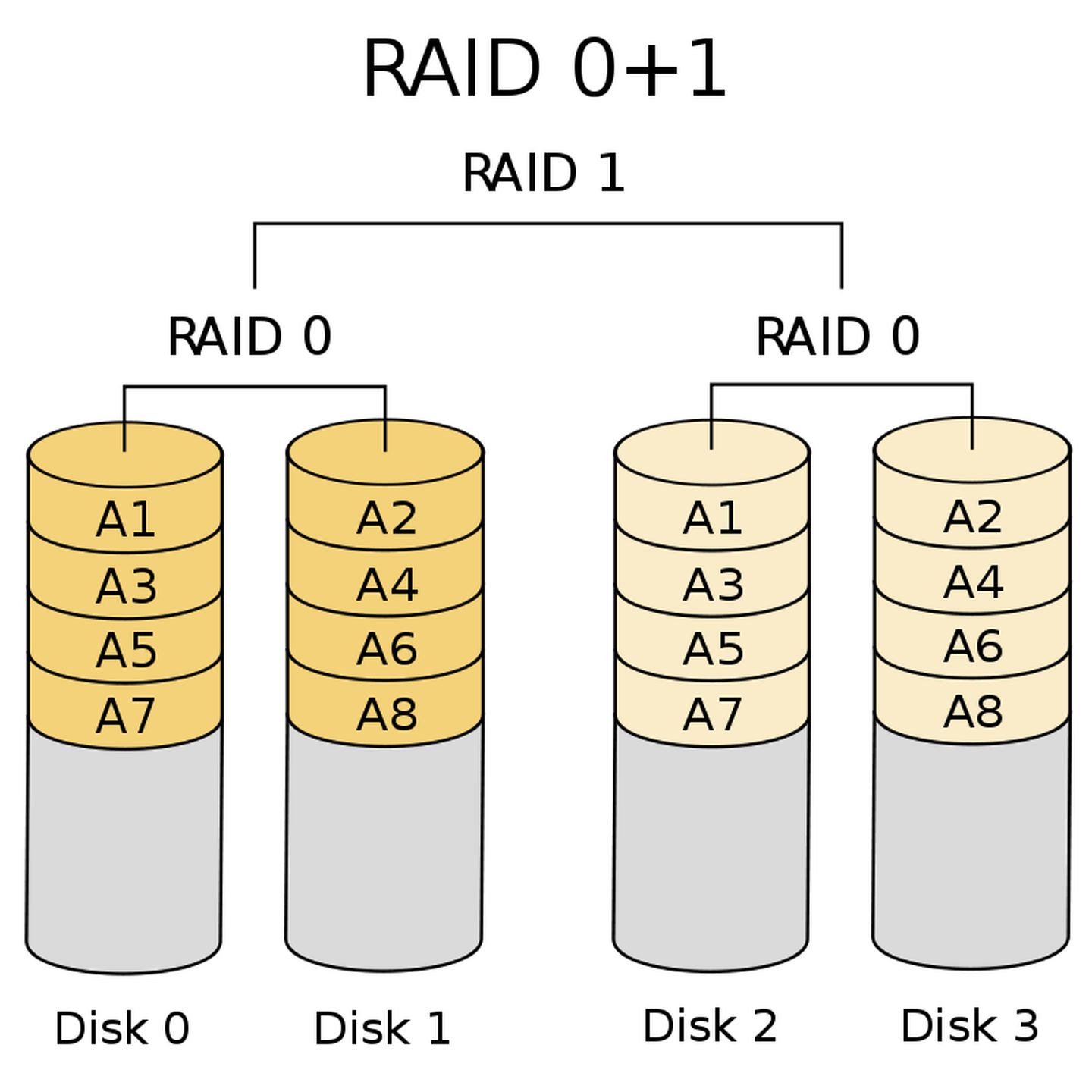
图源:RAID有哪几种?有什么区别?
RAID0+1的有缺点与RAID1+0相同。
RAID5
RAID5可以看作是RAID0和RAID1的折衷方案,对于每一个将要写入RAID5的数据,会将其切割为N-1份,同时会根据N-1份数据产生一份校验数据,每一次数据写入,校验数据都会均匀地分布于构成RAID5的磁盘中,如果某一块磁盘损坏,则可以通过其它N-1块磁盘上的数据和校验数据还原出损坏磁盘上的数据。整个系统可以用下图表示:
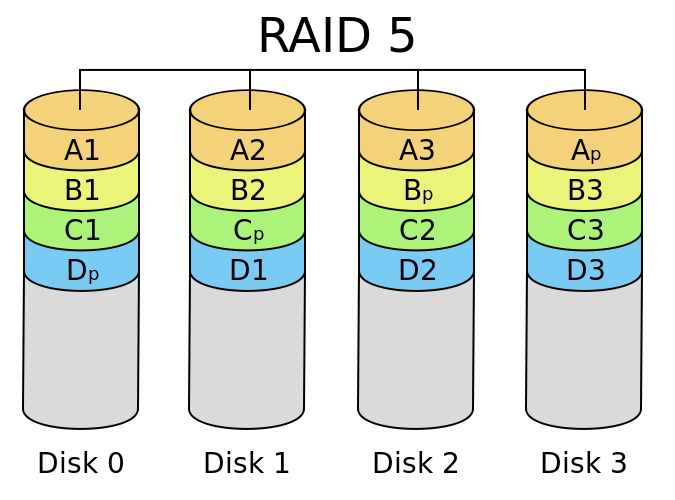
图源:RAID有哪几种?有什么区别?
RAID5的优点是在具有高的读写性能(N-1倍)的同时具有数据安全的优点,而且还有较低的存储成本。整个系统的总容量是“单个磁盘的容量*(N-1)”。
缺点是如果有超过一个磁盘损坏,数据就无法还原,不过一般来说两块磁盘同时损坏的概率几乎可以不计,如果结合了其它自动更换补充磁盘的技术,这个缺点被认为是可以接受的。此外还有一个缺点,校验数据的计算相当消耗计算资源,如果并非使用磁盘阵列卡,而使用软件实现,则会消耗一部分CPU计算资源。
但无论如何,综合来看,RAID5是一个不错的方案,目前许多商业存储都采用RAID5。
RAID6
RAID6可以看作是RAID5的扩展版本,但并不能简单看作是RAID5的替代,因为它们的有缺点还是具有很大的不同的,所以适用场景也不同。
RAID6同样会通过计算产生校验数据,不同的是,为了解决RAID5在损坏两块硬盘就会导致全部数据损毁的问题,RAID6采用双重校验:即使用两种不同的算法计算出两份校验数据,并均匀地分布在磁盘阵列中,即使同时出现两块硬盘损坏,也可以进行数据恢复。
真个系统可以用下图表示:
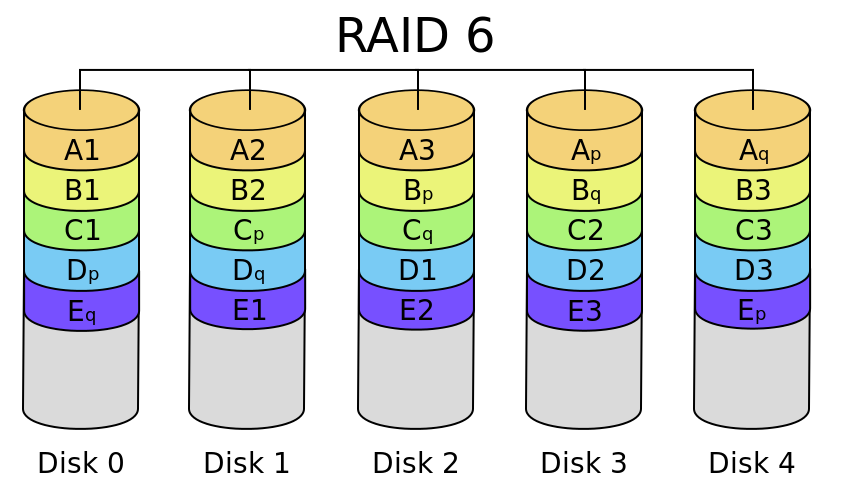
图源:RAID有哪几种?有什么区别?
图中Ap和Aq分别表示两种不同的校验算法计算出的校验数据。
RAID6的主要优点是在一个较低存储成本下有一个较高的数据安全性,缺点也很明显,计算校验数据的方式想比 RAID5更复杂,自然也需要消耗更多的计算资源,如果依赖于CPU计算,则对主机的性能是一个拖累。
一般来说,RAID6会应用于需要高数据安全级别的场景。
热备份磁盘
在介绍RAID5的时候说过,因为RAID5在超过一块以上磁盘损坏时就无法恢复数据,所以当其中有一个磁盘损坏时就需要及时更换磁盘和恢复数据,如果要时时有人值守显然不现实,为了一个几年内可能不会出现,但一旦出现就要及时进行的操作,人显然是靠不住的。
这时候就要依赖于热备份磁盘(spare disk)了,通过在RAID中设置一块平时不使用的热备份磁盘,就可以在有磁盘出现问题的时候,系统自动移除有问题的磁盘,并用热备份磁盘替换问题磁盘的位置,然后进行数据恢复。
RAID的选取
关于不同RAID方案的选取,我个人的建议是:
- 对于不重要的个人数据,比如下载的电影、游戏等,可以使用RAID0。
- 对于重要的个人数据,比如照片等,如果你只有两块硬盘,使用RAID1,有两块以上的硬盘,使用RAID5。
- 商业数据,使用RAID5。
硬件RAID,软件RAID
就像之前我们说的,通过使用硬件设备,如磁盘阵列卡实现的RAID就叫硬件RAID,反之,如果通过软件实现的RAID,就叫软件RAID。
硬件RAID的优点是因为使用了单独的硬件设备完成组成RAID所需的校验数据计算或者数据复制等操作,不会影响主机性能,有较好的性能表现。缺点是费钱…
软件RAID的优点是省钱,缺点自然是会有性能损耗。
CentOS提供的软件磁盘阵列程序为mdadm,该程序可以以分区或disk为单位组成磁盘阵列。也就是说我们不需要多块磁盘,就可以实验性地用多个分区组建磁盘阵列。但需要注意的是,用一个磁盘的多个分区组件磁盘阵列,只能用来实验模拟,并不具有读写性能提升的优点。
此外,mdadm除了可以组建前边提到的所有RAID方案外,还支持热插拔,即在不重启系统的情况下完成分区的替换和数据恢复。
最后需要注意的是,硬件RAID和软件RAID在Linux系统中分配的设备文件名是不同的,一般来说,硬件RAID会被看作是一个大的实体磁盘,所以分配的设备文件名是/dev/sd[a-p],软件RAID通过软件实现,分配的设备文件名是/dev/md0、/dev/md1等。
软件磁盘阵列的设置
在组建磁盘阵列前,我们需要先使用gdisk之类的分区工具划分出待用的分区,具体的分区过程就不重复了,可以参考Linux 之旅 5:磁盘与文件系统管理。最终的分区结果是这样的:
Number Start (sector) End (sector) Size Code Name1 2048 6143 2.0 MiB EF022 6144 2103295 1024.0 MiB 07003 2103296 65026047 30.0 GiB 8E004 65026048 67123199 1024.0 MiB 8300 Linux filesystem5 67123200 69220351 1024.0 MiB FD00 Linux RAID6 69220352 71317503 1024.0 MiB FD00 Linux RAID7 71317504 73414655 1024.0 MiB FD00 Linux RAID8 73414656 75511807 1024.0 MiB FD00 Linux RAID9 75511808 77608959 1024.0 MiB FD00 Linux RAID
即划分出5个1G大小的分区,其中4个用来组建磁盘阵列,1个备用。
需要注意的是分区时候最好将分区的GUID设置为
fd00,即Linux RAID类型。虽然不这样设置也问题不大,但在某些可以自动识别并加载RAID的程序可能会识别不了。
创建RAID
创建RAID的方式很简单:
[root@xyz ~]# mdadm --create /dev/md0 --auto=yes --level=5 --chunk=256K --raid-devices=4 --spare-devices=1 /dev/sda{5,6,7,8,9}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
其中参数的含义为:
--auto=yes:是指通过指定RAID设备文件名的方式进行创建(--create /dev/md0)。--level=5:指所创建的级别是RAID5。--chunk=256K:RAID中最小的数据单元是chunk,每个chunk的大小为256K。--raid-devices=4:整个RAID由4个设备(分区)组成。--spare-devices=1:有1个热备份设备(分区)。
可以查看RAID的信息:
[root@xyz ~]# mdadm --detail /dev/md0
/dev/md0:Version : 1.2Creation Time : Tue Aug 24 14:15:21 2021Raid Level : raid5Array Size : 3139584 (2.99 GiB 3.21 GB) # RAID的总容量Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB) # 单个设备(分区)的容量Raid Devices : 4 # 组成RAID的设备数目Total Devices : 5 # 总的设备数目Persistence : Superblock is persistentUpdate Time : Tue Aug 24 14:15:31 2021State : clean # 目前RAID的使用状态Active Devices : 4 # 处于活动状态的设备数目Working Devices : 5 # 可以随时使用的设备数目Failed Devices : 0 # 已损坏的设备数目Spare Devices : 1 # 热备份设备数目Layout : left-symmetricChunk Size : 256K # 单个chunk的大小Consistency Policy : resyncName : xyz.icexmoon.centos:0 (local to host xyz.icexmoon.centos)UUID : 06ade86c:edac1ae0:b215697f:374ef009Events : 18Number Major Minor RaidDevice State0 8 5 0 active sync /dev/sda51 8 6 1 active sync /dev/sda62 8 7 2 active sync /dev/sda75 8 8 3 active sync /dev/sda84 8 9 - spare /dev/sda9
重要的信息我用注释的方式进行了标注。
磁盘阵列的创建需要时间,如果第一时间使用mdadm --detail /dev/md0没有打印出信息,请等会再尝试。
除了使用上述的方法查看RAID的信息,还可以:
[root@xyz ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda8[5] sda9[4](S) sda7[2] sda6[1] sda5[0]3139584 blocks super 1.2 level 5, 256k chunk, algorithm 2 [4/4] [UUUU]unused devices: <none>
这里清楚地显示了RAID的文件名为md0。级别为raid5。处于活动状态的设备有sda8、sda9、sda7、sda6、sda5。其中sda9为热备份设备(S)。设备对应的RAID中的编号分别为:[5]、[4]、[2]、[1]、[0]。总共有3139584个数据块(每个block大小为1KB),所以总容量为3G。总共有4个设备,且4个设备正常运行([4/4])。[UUUU]表示4个设备具体的运行状态,U表示正常运行,_表示不正常。
格式化与挂载
与使用普通的磁盘类似,我们同样需要对RAID进行格式化后挂载才能正常使用:
[root@xyz ~]# mkfs.xfs -f -d su=256k,sw=3 -r extsize=768k /dev/md0
meta-data=/dev/md0 isize=512 agcount=8, agsize=98048 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=784384, imaxpct=25= sunit=64 swidth=192 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=64 blks, lazy-count=1
realtime =none extsz=786432 blocks=0, rtextents=0
使用的方式和格式化普通分区类似,不过需要注意的是这里要指定一些额外参数:
-f:强制格式化-d:后边跟数据相关的子设置项su=256k:su即stripe unit(条带单元),之前说过,RAID5会将每次写入的数据拆分成多份进行存储,每个拆分出的最小单元就是stripe unit,这个值不能太大也不能太小,可以根据系统的评价I/O进行设置。sw=3:sw即stripe width,对于RAID,这个值一般是数据磁盘的个数,对于RAID5来说就是N-1,而su*sw就是一个stripe的数据量。
-r:real_time_section_options,其后跟xfs文件系统中real time区的相关子设定extsize=768:Real time区中一个扇区的大小,应该是block的倍数。
更多
stripe相关的概念请阅读阵列中条带(stripe)、stripe unit。
下面进行挂载:
[root@xyz ~]# mkdir /srv/raid
[root@xyz ~]# mount /dev/md0 /srv/raid
[root@xyz ~]# df -h /srv/raid
文件系统 容量 已用 可用 已用% 挂载点
/dev/md0 3.0G 33M 3.0G 2% /srv/raid
模拟RAID数据恢复
为了模拟数据恢复,我们要先写入一些数据:
[root@xyz ~]# cp -a /etc /var/log /srv/raid
[root@xyz ~]# ll /srv/raid
总用量 16
drwxr-xr-x. 139 root root 8192 8月 24 11:23 etc
drwxr-xr-x. 18 root root 4096 8月 24 12:34 log
[root@xyz ~]# df /srv/raid
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/md0 3127296 105168 3022128 4% /srv/raid
将磁盘设置为错误状态
使用mdadm命令将一个设备设置为已损坏的状态:
[root@xyz ~]# mdadm --manage /dev/md0 --fail /dev/sda7
mdadm: set /dev/sda7 faulty in /dev/md0
[root@xyz ~]# mdadm --detail
mdadm: No devices given.
[root@xyz ~]# mdadm --detail /dev/md0
... 省略...Number Major Minor RaidDevice State0 8 5 0 active sync /dev/sda51 8 6 1 active sync /dev/sda64 8 9 2 active sync /dev/sda95 8 8 3 active sync /dev/sda82 8 7 - faulty /dev/sda7
可以看到/dev/sda7是faulty状态,而原本的热备设备dev/sda9顶替了/dev/sda7的位置。
因为这里的数据量比较少,所以系统自动恢复的速度很快,否则可能需要较长的时间等待RAID进行数据重建(rebuild)的工作。
将错误的设备删除并加入新设备
在RAID自动使用热备设备代替已损坏设备之后,我们需要将已损坏的设备从RAID移除,并添加一个新的设备作为热备设备。在真实磁盘组成的RAID系统中,这意味着我们需要卸载磁盘,并将磁盘本体从USB之类的接口拔除,然后插上一个新的磁盘,然后加载,但我们现在是用分区进行模拟,所以不需要物理层面的操作。
只需要执行:
[root@xyz ~]# mdadm --manage /dev/md0 --remove /dev/sda7
mdadm: hot removed /dev/sda7 from /dev/md0
[root@xyz ~]# mdadm --manage /dev/md0 --add /dev/sda7
mdadm: added /dev/sda7
[root@xyz ~]# mdadm --detail /dev/md0
/dev/md0:
...省略...Number Major Minor RaidDevice State0 8 5 0 active sync /dev/sda51 8 6 1 active sync /dev/sda64 8 9 2 active sync /dev/sda95 8 8 3 active sync /dev/sda86 8 7 - spare /dev/sda7
开机自动启动RAID并挂载
新的Linux发行版大多数会在开机时自动查找/dev/md[0-9]的RAID设备并进行加载,但依然建议进行手动设置。
mdadm对应的配置文件是/etc/mdadm.conf。
要在mdadm的配置文件中添加RAID配置,需要先查询RAID的uuid:
[root@xyz ~]# mdadm --detail /dev/md0 | grep -i uuidUUID : 06ade86c:edac1ae0:b215697f:374ef009
需要注意的是,RAID的
UUID和其上边的xfs文件系统的UUID并不相同。
修改mdadm的配置文件:
[root@xyz ~]# vim /etc/mdadm.conf
ARRAY /dev/md0 UUID=06ade86c:edac1ae0:b215697f:374ef009
添加文件系统自动挂载:
[root@xyz ~]# blkid | grep md0
/dev/md0: UUID="873913d8-2e18-4e14-9b69-e4ee63fdb9ce" TYPE="xfs"
[root@xyz ~]# vim /etc/fstab
...省略...
UUID=873913d8-2e18-4e14-9b69-e4ee63fdb9ce /srv/raid xfs defaults 0 0
...省略...
[root@xyz ~]# umount /srv/raid
[root@xyz ~]# mount -a
[root@xyz ~]# mount | grep raid
/dev/md0 on /srv/raid type xfs (rw,relatime,seclabel,attr2,inode64,logbsize=256k,sunit=512,swidth=1536,noquota)
关闭软件RAID
先卸载并删除fstab中的自动挂载信息:
[root@xyz ~]# umount /srv/raid
[root@xyz ~]# vim /etc/fstab
[root@xyz ~]# mount -a
[root@xyz ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
devtmpfs 480712 0 480712 0% /dev
tmpfs 497836 0 497836 0% /dev/shm
tmpfs 497836 8556 489280 2% /run
tmpfs 497836 0 497836 0% /sys/fs/cgroup
/dev/mapper/centos-root 10475520 6585624 3889896 63% /
/dev/sda4 1038336 32992 1005344 4% /srv/myproject
/dev/sda2 1038336 185940 852396 18% /boot
/dev/mapper/centos-home 5232640 1126540 4106100 22% /home
tmpfs 99568 12 99556 1% /run/user/42
tmpfs 99568 0 99568 0% /run/user/1000
使用dd命令覆盖RAID的metadata以及xfs文件系统的super block:
[root@xyz ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50
记录了50+0 的读入
记录了50+0 的写出
52428800字节(52 MB)已复制,0.514041 秒,102 MB/秒
[root@xyz ~]# mdadm --stop /dev/md0
mdadm: stopped /dev/md0
[root@xyz ~]# dd if=/dev/zero of=/dev/sda5 bs=1M count=10
记录了10+0 的读入
记录了10+0 的写出
10485760字节(10 MB)已复制,0.0335274 秒,313 MB/秒
[root@xyz ~]# dd if=/dev/zero of=/dev/sda6 bs=1M count=10
记录了10+0 的读入
记录了10+0 的写出
10485760字节(10 MB)已复制,0.0201498 秒,520 MB/秒
[root@xyz ~]# dd if=/dev/zero of=/dev/sda7 bs=1M count=10
记录了10+0 的读入
记录了10+0 的写出
10485760字节(10 MB)已复制,0.0209833 秒,500 MB/秒
[root@xyz ~]# dd if=/dev/zero of=/dev/sda8 bs=1M count=10
记录了10+0 的读入
记录了10+0 的写出
10485760字节(10 MB)已复制,0.042459 秒,247 MB/秒
[root@xyz ~]# dd if=/dev/zero of=/dev/sda9 bs=1M count=10
记录了10+0 的读入
记录了10+0 的写出
10485760字节(10 MB)已复制,0.0181525 秒,578 MB/秒
[root@xyz ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none>
[root@xyz ~]# vim /etc/mdadm.conf
之所以用dd写入空文件覆盖super block的方式关闭RAID,是因为某些Linux发行版可以自动识别已经组织成RAID的设备并加载。
最后还需要修改mdadm配置文件以删除RAID的配置。
逻辑卷管理器(Logical Volume Manager)
LVM可以弹性地调整文件系统的容量。通过整合多个磁盘,让这些磁盘看起来像是一个磁盘。并且还可以在未来动态地在LVM管理的磁盘中删除或者添加一个物理磁盘。
LVM的相关概念
PV(Physical Volume,物理卷)
PV是构成LVM最底层的部分。分区(或磁盘)需要修改系统标识为8e(LVM的标识符)之后,再使用pvcreate才能转化为PV。
VG(Volume Group,卷组)
多个PV可以组成一个VG,VG就是我们使用LVM创建的“大磁盘”。
PE(Physical Extent,物理扩展块)
LVM最小的存储数据单位。
LV(Logical Volume,逻辑卷)
最终我们需要将VG切分成多个LV才可以格式化后使用,LV就像是VG的分区一样。
LV的大小与其中的PE总数有关,LV的设备名称通常为/dev/vgname/lvname。
LV可以实现“PE的交换”,即可以将LV内的PE移入其它设备以降低容量,或者从其它设备中移入PE以增加容量。
LVM使用流程
整个LVM的使用流程可以用下图表示:
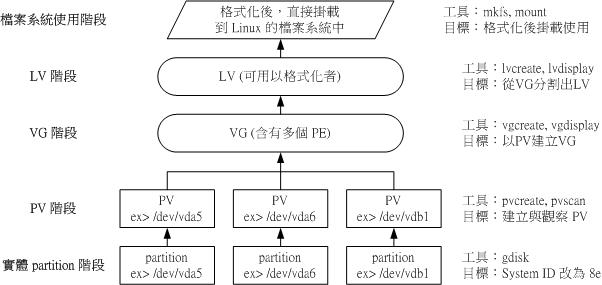
图源:鸟哥的Linux私房菜
可能有人会注意到,将多个物理磁盘整合成一个逻辑上的大磁盘使用的方式和RAID0有点相似,实际上LVM的使用有两种方式:
-
线性模式(linear):
LVM的默认模式,会在组成LVM的磁盘中依次线性写入数据,所以也不会有改善读写性能的效果。
-
交错模式(triped):
类似于RAID0,会将数据切分后同时在组成LVM的多个磁盘中写入,也具有提升读写性能的效果。
虽然交错模式可以让LVM具有Raid0的优点,但同时也会有Raid0的缺点,此外,与RAID不同,LVM的主要用途是合并使用多个磁盘,并灵活调整容量,而非改善读写性能,所以并不建议使用交错模式。
LVM实战
实战0:准备分区
需要先准备将转换为PV的分区,最终准备的分区如下:
Number Start (sector) End (sector) Size Code Name1 2048 6143 2.0 MiB EF022 6144 2103295 1024.0 MiB 07003 2103296 65026047 30.0 GiB 8E004 65026048 67123199 1024.0 MiB 8300 Linux filesystem5 67123200 69220351 1024.0 MiB 8E00 Linux LVM6 69220352 71317503 1024.0 MiB 8E00 Linux LVM7 71317504 73414655 1024.0 MiB 8E00 Linux LVM8 73414656 75511807 1024.0 MiB 8E00 Linux LVM9 75511808 77608959 1024.0 MiB 8E00 Linux LVM
在
gdisk中依次输入命令t>5>8e00就可以修改分区的类型。
实战1:创建PV
创建PV很简单:
[root@xyz ~]# pvscanPV /dev/sda3 VG centos lvm2 [30.00 GiB / 14.00 GiB free]Total: 1 [30.00 GiB] / in use: 1 [30.00 GiB] / in no VG: 0 [0 ]
[root@xyz ~]# pvcreate /dev/sda{5,6,7,8}Physical volume "/dev/sda5" successfully created.Physical volume "/dev/sda6" successfully created.Physical volume "/dev/sda7" successfully created.Physical volume "/dev/sda8" successfully created.
[root@xyz ~]# pvscanPV /dev/sda3 VG centos lvm2 [30.00 GiB / 14.00 GiB free]PV /dev/sda8 lvm2 [1.00 GiB]PV /dev/sda5 lvm2 [1.00 GiB]PV /dev/sda6 lvm2 [1.00 GiB]PV /dev/sda7 lvm2 [1.00 GiB]Total: 5 [34.00 GiB] / in use: 1 [30.00 GiB] / in no VG: 4 [4.00 GiB]
如果要查看具体PV的详细信息,可以:
[root@xyz ~]# pvdisplay /dev/sda5"/dev/sda5" is a new physical volume of "1.00 GiB"--- NEW Physical volume ---PV Name /dev/sda5VG NamePV Size 1.00 GiBAllocatable NO # 是否已被分配到VGPE Size 0 # PE大小Total PE 0 # 供划分出几个PEFree PE 0 Allocated PE 0 # 可以被分配的PEPV UUID spO7yF-5HpV-GTHW-1MQP-T02w-GzO8-OE30vq
具体的PE设置需要在被划分给VG时才会生成(VG中的PE是一样的大小),所以这里PE向相关的信息都是0。
实战2:创建VG
使用命令vgcreate可以创建VG:
[root@xyz ~]# vgcreate -s 16M myvg /dev/sda{5,6,7}Volume group "myvg" successfully created
[root@xyz ~]# vgscanReading volume groups from cache.Found volume group "myvg" using metadata type lvm2Found volume group "centos" using metadata type lvm2
[root@xyz ~]# pvscanPV /dev/sda5 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda6 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda7 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda3 VG centos lvm2 [30.00 GiB / 14.00 GiB free]PV /dev/sda8 lvm2 [1.00 GiB]Total: 5 [33.95 GiB] / in use: 4 [32.95 GiB] / in no VG: 1 [1.00 GiB]
[root@xyz ~]# pvdisplay /dev/sda5--- Physical volume ---PV Name /dev/sda5VG Name myvgPV Size 1.00 GiB / not usable 16.00 MiBAllocatable yesPE Size 16.00 MiBTotal PE 63Free PE 63Allocated PE 0PV UUID spO7yF-5HpV-GTHW-1MQP-T02w-GzO8-OE30vq
vgcreate的-s参数(size)指定的是VG中PE的大小。
如果要将未分配的PV加入VG,可以:
[root@xyz ~]# pvscanPV /dev/sda5 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda6 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda7 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda3 VG centos lvm2 [30.00 GiB / 14.00 GiB free]PV /dev/sda8 lvm2 [1.00 GiB]Total: 5 [33.95 GiB] / in use: 4 [32.95 GiB] / in no VG: 1 [1.00 GiB]
[root@xyz ~]# vgextend myvg /dev/sda8Volume group "myvg" successfully extended
[root@xyz ~]# pvscanPV /dev/sda5 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda6 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda7 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda8 VG myvg lvm2 [1008.00 MiB / 1008.00 MiB free]PV /dev/sda3 VG centos lvm2 [30.00 GiB / 14.00 GiB free]Total: 5 [<33.94 GiB] / in use: 5 [<33.94 GiB] / in no VG: 0 [0 ]
实战3:划分LV
要从VG中划分LV,可以:
[root@xyz ~]# lvcreate -L 2G -n mylv1 myvgLogical volume "mylv1" created.
参数-L用于指定划分出的LV的大小,-n为新建的LV的名称。
如果要查看已创建的LV:
[root@xyz ~]# lvscanACTIVE '/dev/myvg/mylv1' [2.00 GiB] inheritACTIVE '/dev/centos/swap' [1.00 GiB] inheritACTIVE '/dev/centos/home' [5.00 GiB] inheritACTIVE '/dev/centos/root' [10.00 GiB] inherit
如果要查看LV的详细信息,可以:
[root@xyz ~]# lvdisplay /dev/myvg/mylv1--- Logical volume ---LV Path /dev/myvg/mylv1LV Name mylv1VG Name myvgLV UUID knGtsK-OGld-4yDc-h3Up-nuuL-xMwq-MOqKOzLV Write Access read/writeLV Creation host, time xyz.icexmoon.centos, 2021-08-24 16:55:01 +0800LV Status available# open 0LV Size 2.00 GiBCurrent LE 128Segments 3Allocation inheritRead ahead sectors auto- currently set to 8192Block device 253:3
实战4:格式化
对LV的格式化方式和普通的分区完全相同:
[root@xyz ~]# mkfs.xfs /dev/myvg/mylv1
meta-data=/dev/myvg/mylv1 isize=512 agcount=4, agsize=131072 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=524288, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@xyz ~]# mkdir /srv/lvm
[root@xyz ~]# mount /dev/myvg/mylv1 /srv/lvm
[root@xyz ~]# df -Th /srv/lvm
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mylv1 xfs 2.0G 33M 2.0G 2% /srv/lvm
[root@xyz ~]# cp -a /etc /var/log /srv/lvm
[root@xyz ~]# df -Th /srv/lvm
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mylv1 xfs 2.0G 102M 1.9G 6% /srv/lvm
可以看到,虽然底层是用多个1G大小的分区,但通过LVM创建的LV,可以是2G大小。
放大LV容量
之前说过,使用LVM的优点之一是可以灵活调整容量,具体到如果要对一个LV上的文件系统扩容,需要以下步骤:
-
VG有剩余容量
如果没有,可以通过增加PV,并使用
vgextend命令添加新的PV的方式对VG进行扩容。 -
LV有更多的可用容量
如果没有,可以通过
lvresize命令对LV进行扩容。 -
文件系统阶段的放大
如果是
xfs文件系统,需要使用xfs_growfs命令放大xfs文件系统,以识别新加入进行来的容量。
目前
xfs文件系统仅能放大,不能缩小。
[root@xyz ~]# lvdisplay /dev/myvg/mylv1 | grep vgLV Path /dev/myvg/mylv1VG Name myvg
[root@xyz ~]# vgdisplay myvg | grep -i freeFree PE / Size 124 / <1.94 GiB
[root@xyz ~]# lvresize -L +500M /dev/myvg/mylv1Rounding size to boundary between physical extents: 512.00 MiB.Size of logical volume myvg/mylv1 changed from 2.00 GiB (128 extents) to 2.50 GiB (160 extents).Logical volume myvg/mylv1 successfully resized.
[root@xyz ~]# lvdisplay /dev/myvg/mylv1 | grep -i sizeLV Size 2.50 GiB
lvresize命令并不需要指定LV所属的VG,会自动从所属VG的剩余部分进行扩容。
但此时如果查看文件系统大小:
[root@xyz ~]# df -Th /srv/lvm
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mylv1 xfs 2.0G 102M 1.9G 5% /srv/lvm
文件系统并不会自动识别出LV新增加的部分,所以需要:
[root@xyz ~]# xfs_growfs /srv/lvm
meta-data=/dev/mapper/myvg-mylv1 isize=512 agcount=4, agsize=131072 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=524288, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 524288 to 655360
[root@xyz ~]# df -Th /srv/lvm
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mylv1 xfs 2.5G 102M 2.4G 4% /srv/lvm
使用LVM thin Volume
虽然理论上LV可以灵活扩展,但我们之前说了,xfs文件系统本身只能扩展不能压缩,这意味着如果我们一开始给某个LV分配了一个很大的空间,但使用了一段时间后发现实际上不需要那么大,反而另一个LV需要更多的空间,这时候就很尴尬了(如果使用的还是xfs文件系统的话)。
LVM thin Volume给了我们一个额外的选项,我们可以先创建一个磁盘容量存储池(thin pool),然后利用这个存储池生成一个指定大小的LV。这个方案比较有意思的是,我们可以随便给存储池产生的LV指定大小,多大都可以,就算超过存储池的大小都是允许的,但实际上其真实占用的空间就是其上边存储的数据的大小,也就是说用多少占多少,且所有空间都来自存储池。如果要继续存储更多的数据,就从存储池继续申请空间。
这样无疑更为灵活。
下面我们看如何创建,先查询VG剩余空间,然后创建thin pool:
[root@xyz ~]# vgdisplay myvg | grep -i freeFree PE / Size 92 / <1.44 GiB
[root@xyz ~]# lvcreate -L 1G -T myvg/mythinpoolThin pool volume with chunk size 64.00 KiB can address at most 15.81 TiB of data.Logical volume "mythinpool" created.
[root@xyz ~]# lvdisplay myvg/mythinpool--- Logical volume ---LV Name mythinpoolVG Name myvgLV UUID PBsWgG-CoL5-Xcnl-VuvW-BJaS-2AWq-OkEwhBLV Write Access read/writeLV Creation host, time xyz.icexmoon.centos, 2021-08-24 20:41:24 +0800LV Pool metadata mythinpool_tmetaLV Pool data mythinpool_tdataLV Status available# open 0LV Size 1.00 GiBAllocated pool data 0.00% # 已分配的容量百分比Allocated metadata 10.23% # 已分配的元数据百分比Current LE 64Segments 1Allocation inheritRead ahead sectors auto- currently set to 8192Block device 253:6
从thin pool的信息中可以看到容量分配相关的信息,这意味着thin pool作为一个特殊的LV,可以再次进行容量分配(就像VG一样)。
可以通过命令lvs查看VG中所有的LV:
[root@xyz ~]# lvs myvgLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convertmylv1 myvg -wi-ao---- 2.50gmythinpool myvg twi-a-tz-- 1.00g 0.00 10.23
输出的信息中同样有Data%和Meta%这样关于容量分配的信息。
下面利用thin pool创建一个新的LV:
[root@xyz ~]# lvcreate -V 10G -T myvg/mythinpool -n poollv1WARNING: Sum of all thin volume sizes (10.00 GiB) exceeds the size of thin pool myvg/mythinpool and the size of whole volume group (<3.94 GiB).WARNING: You have not turned on protection against thin pools running out of space.WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full.Logical volume "poollv1" created.
参数-V(virtual size)是为LV指定了一个虚拟的大小,参数-T指定了LV所属的thin pool。
可以看到创建这个LV的时候出现了很多警告信息,着是因为创建的这个LV超过了所属thin pool的实际大小,这样是不安全的,因为如果所创建的LV实际使用的数据量超过了thin pool的最大容量1G,就将会发生数据损坏,带来一些不安定的因素,除非我们在那之前就对thin pool进行扩容。
下面格式化并挂载LV:
[root@xyz ~]# mkfs.xfs /dev/myvg/poollv1
Discarding blocks...Done.
meta-data=/dev/myvg/poollv1 isize=512 agcount=16, agsize=163840 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25= sunit=16 swidth=16 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=16 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@xyz ~]# mkdir /srv/poollv
[root@xyz ~]# mount /dev/myvg/poollv1 /srv/poollv
[root@xyz ~]# df -h /srv/poollv
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-poollv1 10G 33M 10G 1% /srv/poollv
下面在该LV上创建一个500M文件进行测试(不能超过1G):
[root@xyz poollv]# dd if=/dev/zero of=pool_test bs=1M count=500
记录了500+0 的读入
记录了500+0 的写出
524288000字节(524 MB)已复制,8.6242 秒,60.8 MB/秒
[root@xyz poollv]# ll -h
总用量 500M
-rw-r--r--. 1 root root 500M 8月 24 21:04 pool_test
[root@xyz poollv]# lvs myvgLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convertmylv1 myvg -wi-ao---- 2.50gmythinpool myvg twi-aotz-- 1.00g 49.92 11.82poollv1 myvg Vwi-aotz-- 10.00g mythinpool 4.99
可以看到,虽然poollv1显示只用了4.99%的容量,但实际上已经使用了mythinpool的49.92%的容量,可见poollv1的标准容量(10G)的确是虚假的。
利用thin pool的这种特性,我们可以在一个thin pool上创建多个LV,这样就可以更有效率地使用磁盘空间,只要保证所有的LV实际存储的数据总量不超过thin pool即可。这样做某种程度上可以避免一个xfs文件系统的PV有过多的剩余空间但无法压缩空间的尴尬。
LV磁盘快照
LVM有一个有趣的功能:对LV进行快照(snapshot)。
所谓的快照即将某一刻LV上的数据状态记录下来,产生一份快照,然后后续所有的数据修改会将原数据移入快照的存储空间,而没有发生变化的数据则依然保留在原有存储,只不过快照会对其进行“引用”。
通过这种机制,可以使用较少的空间保留一个某一时刻LV的数据“备份”。需要注意的是着并非真正的完整数据备份,更像是编程领域的“视图”这个概念,仅是提供给我们一种途径可以“观察到”那一刻的数据。
快照与产生快照的LV的关系可以用下图表示:
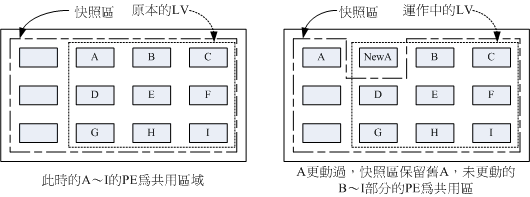
图源:鸟哥的私房菜
因为快照的原理会用到“PE的交换”,所以快照应当与产生快照的LV位于同一个VG之下。
此外,如果牵扯到磁盘存储池,会有一些其它的限制条件,这里不过多讨论,仅讨论普通的LV快照。
下面我们创建快照:
[root@xyz poollv]# vgdisplay myvg | grep -i freeFree PE / Size 26 / 416.00 MiB
[root@xyz poollv]# lvcreate -s -l 26 -n mysnap1 /dev/myvg/mylv1WARNING: Sum of all thin volume sizes (10.00 GiB) exceeds the size of thin pools and the size of whole volume group (<3.94 GiB).WARNING: You have not turned on protection against thin pools running out of space.WARNING: Set activation/thin_pool_autoextend_threshold below 100 to trigger automatic extension of thin pools before they get full.Logical volume "mysnap1" created.
这里myvg仅剩余26个PE,全部拿来创建快照。
lvcreate命令中的-s参数意思为snape,即创建的是快照。-l 26为指定26个PE。
可以查看快照的详细信息:
[root@xyz poollv]# lvdisplay /dev/myvg//mysnap1--- Logical volume ---LV Path /dev/myvg/mysnap1LV Name mysnap1VG Name myvgLV UUID igMos9-hlmT-UQcQ-wMq7-IqUE-GvJC-7gbs2MLV Write Access read/writeLV Creation host, time xyz.icexmoon.centos, 2021-08-24 21:25:34 +0800LV snapshot status active destination for mylv1LV Status available# open 0LV Size 2.50 GiB # 产生快照的LV的容量Current LE 160COW-table size 416.00 MiB # 快照区的容量COW-table LE 26Allocated to snapshot 0.01% # 快照区已用的容量Snapshot chunk size 4.00 KiBSegments 1Allocation inheritRead ahead sectors auto- currently set to 8192Block device 253:11
因为之前所说的原理,虽然快照本身占用的实际容量可能远远小于产生快照的LV,但快照可以提供一个类似“视窗”的功能,让我们看到产生快照的那一刻的LV的完整内容。现在我们挂载上快照试试看:
[root@xyz poollv]# mkdir /srv/snapshot1
[root@xyz poollv]# mount -o nouuid /dev/myvg/mysnap1 /srv/snapshot1
[root@xyz poollv]# ll /srv/snapshot1/
总用量 16
drwxr-xr-x. 139 root root 8192 8月 24 16:08 etc
drwxr-xr-x. 18 root root 4096 8月 24 12:34 log
[root@xyz poollv]# df -h /srv/snapshot1/
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mysnap1 2.5G 102M 2.4G 4% /srv/snapshot1
可以看到无论是文件系统的容量和使用情况,还是实际目录中的数据,都和我们对LV制作快照时候LV内的数据情况一致。
需要注意的是挂载快照的时候需要使用-o nouuid参数,因为快照的文件系统的UUID与被快照的LV的文件系统的UUID是一摸一样的,所以必须要使用这个参数忽略UUID才可以挂载。
快照的一个用途是可以当作备份使用,在需要的时候对数据进行还原。
先对被快照的LV内的数据进行修改:
[root@xyz poollv]# cp -a /usr/share/doc /srv/lvm
[root@xyz poollv]# rm -rf /srv/lvm/log
[root@xyz poollv]# rm -rf /srv/lvm/etc/sysconfig
[root@xyz poollv]# df -Th /srv/lvm /srv/snapshot1/
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/myvg-mylv1 xfs 2.5G 175M 2.4G 7% /srv/lvm
/dev/mapper/myvg-mysnap1 xfs 2.5G 102M 2.4G 4% /srv/snapshot1
[root@xyz poollv]# ll /srv/lvm /srv/snapshot1/
/srv/lvm:
总用量 60
drwxr-xr-x. 931 root root 32768 8月 20 20:53 doc
drwxr-xr-x. 138 root root 8192 8月 24 21:41 etc/srv/snapshot1/:
总用量 16
drwxr-xr-x. 139 root root 8192 8月 24 16:08 etc
drwxr-xr-x. 18 root root 4096 8月 24 12:34 log
[root@xyz poollv]# lvdisplay /dev/myvg/mysnap1--- Logical volume ---LV Path /dev/myvg/mysnap1LV Name mysnap1VG Name myvgLV UUID igMos9-hlmT-UQcQ-wMq7-IqUE-GvJC-7gbs2MLV Write Access read/writeLV Creation host, time xyz.icexmoon.centos, 2021-08-24 21:25:34 +0800LV snapshot status active destination for mylv1LV Status available# open 1LV Size 2.50 GiBCurrent LE 160COW-table size 416.00 MiBCOW-table LE 26Allocated to snapshot 24.63%Snapshot chunk size 4.00 KiBSegments 1Allocation inheritRead ahead sectors auto- currently set to 8192Block device 253:11
可以看到mylv1中的数据已发生改变,而改变的数据移动到了快照中,所以快照已使用的容量上升了(24.63%)。
因为我们说过,快照仅仅相当于一个“视图”,并不能直接进行数据覆盖方式的还原,所以我们需要先利用快照制作一个完整备份文件:
[root@xyz poollv]# xfsdump -l 0 -L lvm1 -M lvm1 -f /home/lvm.dump /srv/snapshot1
xfsdump: using file dump (drive_simple) strategy
xfsdump: version 3.1.7 (dump format 3.0) - type ^C for status and control
xfsdump: level 0 dump of xyz.icexmoon.centos:/srv/snapshot1
xfsdump: dump date: Tue Aug 24 21:47:01 2021
xfsdump: session id: 5f78be5f-bc06-424d-b002-0642a174b555
xfsdump: session label: "lvm1"
xfsdump: ino map phase 1: constructing initial dump list
xfsdump: ino map phase 2: skipping (no pruning necessary)
xfsdump: ino map phase 3: skipping (only one dump stream)
xfsdump: ino map construction complete
xfsdump: estimated dump size: 72060992 bytes
xfsdump: creating dump session media file 0 (media 0, file 0)
xfsdump: dumping ino map
xfsdump: dumping directories
xfsdump: dumping non-directory files
xfsdump: ending media file
xfsdump: media file size 66677872 bytes
xfsdump: dump size (non-dir files) : 64217144 bytes
xfsdump: dump complete: 8 seconds elapsed
xfsdump: Dump Summary:
xfsdump: stream 0 /home/lvm.dump OK (success)
xfsdump: Dump Status: SUCCESS
然后利用这个备份文件进行还原:
[root@xyz poollv]# umount /srv/snapshot1
[root@xyz poollv]# lvremove /dev/myvg/mysnap1
Do you really want to remove active logical volume myvg/mysnap1? [y/n]: yLogical volume "mysnap1" successfully removed
[root@xyz poollv]# umount /srv/lvm
[root@xyz poollv]# mkfs.xfs -f /dev/myvg/mylv1
meta-data=/dev/myvg/mylv1 isize=512 agcount=4, agsize=163840 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=655360, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@xyz poollv]# mount /dev/myvg/mylv1 /srv/lvm
[root@xyz poollv]# xfsrestore -f /home/lvm.dump -L lvm1 /srv/lvm
xfsrestore: using file dump (drive_simple) strategy
xfsrestore: version 3.1.7 (dump format 3.0) - type ^C for status and control
xfsrestore: using online session inventory
xfsrestore: searching media for directory dump
xfsrestore: examining media file 0
xfsrestore: reading directories
xfsrestore: 769 directories and 3724 entries processed
xfsrestore: directory post-processing
xfsrestore: restoring non-directory files
xfsrestore: restore complete: 1 seconds elapsed
xfsrestore: Restore Summary:
xfsrestore: stream 0 /home/lvm.dump OK (success)
xfsrestore: Restore Status: SUCCESS
[root@xyz poollv]# ll /srv/lvm
总用量 16
drwxr-xr-x. 139 root root 8192 8月 24 16:08 etc
drwxr-xr-x. 18 root root 4096 8月 24 12:34 log
因为快照本身会影响到我们对mylv1的还原,所以需要先卸载并移除快照。然后再卸载并格式化mylv1,然后再次加载,并使用备份进行还原。
除了上边的用途,实际上快照还可以用来创建教学环境,比如我们可以用LV创建一个完整的练习环境,然后对该LV进行快照,创建多个快照提供给学生进行练习,无论学生怎么玩都可以,即使搞坏了也只需要删除该快照重新再创建一份就行了。
LVM的关闭
LVM相关内容的关闭和删除也很简单,大概顺序和创建顺序反着来就行:
[root@xyz /]# umount /srv/poollv /srv/lvm
[root@xyz /]# lvsLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Converthome centos -wi-ao---- 5.00groot centos -wi-ao---- 10.00gswap centos -wi-ao---- 1.00gmylv1 myvg -wi-a----- 2.50gmythinpool myvg twi-aotz-- 1.00g 49.92 11.82poollv1 myvg Vwi-a-tz-- 10.00g mythinpool 4.99
[root@xyz /]# lvremove myvg/poollv1
Do you really want to remove active logical volume myvg/poollv1? [y/n]: yLogical volume "poollv1" successfully removed
[root@xyz /]# lvremove myvg/mythinpool
Do you really want to remove active logical volume myvg/mythinpool? [y/n]: yLogical volume "mythinpool" successfully removed
[root@xyz /]# lvremove myvg/mylv1
Do you really want to remove active logical volume myvg/mylv1? [y/n]: yLogical volume "mylv1" successfully removed
[root@xyz /]# vgchange -a n myvg0 logical volume(s) in volume group "myvg" now active
[root@xyz /]# vgremove myvgVolume group "myvg" successfully removed
[root@xyz /]# pvremove /dev/sda{5,6,7,8}Labels on physical volume "/dev/sda5" successfully wiped.Labels on physical volume "/dev/sda6" successfully wiped.Labels on physical volume "/dev/sda7" successfully wiped.Labels on physical volume "/dev/sda8" successfully wiped.
最后再将5~8分区的类型改回Linux filesystem就恢复到建立LVM之前的样子了。
以上就是磁盘管理相关的内容了,谢谢阅读。