🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
技术要求
NLP 向 Transformers 的演变
理解分布语义
BoW 的实施
克服维度问题
语言建模和生成
利用深度学习
学习词嵌入
RNN 的简要概述
LSTM 和门控循环单元
使用 Keras 实现 LSTM 的温和实现
CNN的简要概述
Transformer 架构概述
注意力机制
多头注意力机制
将 TL 与 Transformer 一起使用
概括
在本章中,我们将讨论自然语言处理( NLP ) 二十年来发生的变化。我们经历了不同的范式,最终进入了 Transformer 架构的时代。所有范式都帮助我们更好地表示单词和文档以解决问题。分布语义用矢量表示来描述单词或文档的含义,查看文章集合中的分布证据。向量用于解决有监督和无监督管道中的许多问题。对于语言生成问题,n-gram 语言模型多年来一直被用作传统方法。然而,这些传统方法有很多弱点,我们将在本章中讨论这些弱点。
我们将进一步讨论经典的深度学习( DL ) 架构,例如循环神经网络(RNN)、前馈神经网络 ( FFNN )和卷积神经网络( CNN ))。这些改进了该领域问题的性能,并克服了传统方法的局限性。然而,这些模型也有自己的问题。最近,Transformer 模型因其在从文本分类到文本生成的所有 NLP 任务中的有效性而引起了极大的兴趣。然而,主要的成功在于 Transformers 有效地提高了多语言和多任务 NLP 问题的性能,以及单语言和单任务的性能。这些贡献使迁移学习( TL ) 在 NLP 中更有可能实现,其目的是使模型可重用于不同的任务或不同的语言。
从注意力机制开始,我们将简要讨论 Transformer 架构以及之前 NLP 模型之间的差异。在进行理论讨论的同时,我们将展示流行的 NLP 框架的实际示例。为了简单起见,我们将选择尽可能短的介绍性代码示例。
在本章中,我们将介绍以下主题:
- NLP 向 Transformers 的演变
- 理解分布语义
- 利用深度学习
- Transformer 架构概述
- 将 TL 与 Transformer 一起使用
技术要求
我们将使用 Jupyter Notebook 运行需要python >=3.6.0的编码练习,以及需要使用pip install命令安装的以下软件包:
- sklearn
- nltk==3.5.0
- Gensim==3.8.3
- fasttext
- keras>=2.3.0
- Transformers >=4.00
所有带有编码练习的笔记本都可以在以下 GitHub 链接中找到:https ://github.com/PacktPublishing/Advanced-Natural-Language-Processing-with-Transformers/tree/main/CH01 。
查看以下链接以查看代码实战视频:https ://bit.ly/2UFPuVd
NLP 向 Transformers 的演变
我们看到了深刻的过去 20 年 NLP 的变化。在此期间,我们经历了不同的范式,最终进入了一个以魔幻Transformer架构为主的新时代。这种架构并非凭空出现。在各种基于神经的 NLP 方法的帮助下,它逐渐演变为基于注意力的编码器-解码器类型架构,并且仍在不断发展。该架构及其变体已过去十年取得的成功得益于以下发展:
- 上下文词嵌入
- 更好的子词标记化算法,用于处理看不见的词或稀有词
- 注入额外的记忆令牌成句子,例如Doc2vec中的段落 ID或来自 Transformers ( BERT )的双向编码器表示中的分类( CLS ) 标记
- 注意力机制,它克服了强制输入句子将所有信息编码到一个上下文向量中的问题
- 多头自注意力
- 位置编码到大小写词序
- 可并行化的架构,可加快训练和微调
- 模型压缩(蒸馏、量化等)
- TL(跨语言、多任务学习)
多年来,我们使用传统的 NLP 方法,例如n-gram 语言模型、基于 TF-IDF 的信息检索模型和one-hot 编码的文档术语矩阵。所有这些方法都为解决序列分类、语言生成、语言理解等许多 NLP 问题做出了很大贡献。另一方面,这些传统的 NLP 方法也有其自身的弱点——例如,在解决稀疏性、看不见的单词表示、跟踪长期依赖等问题方面存在不足。为了应对这些弱点,我们开发了基于 DL 的方法,例如:
- RNNs
- CNNs
- FFNNs
- RNNs、CNNs 和 FFNNs 的几种变体
2013 年,作为两层 FFNN 字编码器模型Word2vec,通过产生短而密的词的表示,称为词嵌入。这个早期的模型成功地产生了快速有效的静态词嵌入。它通过使用上下文预测目标词或基于滑动窗口预测相邻词,将无监督文本数据转换为监督数据(自我监督学习)。手套,另一种广泛使用和流行的模型,认为基于计数的模型可以比神经模型更好。它利用语料库的全局和局部统计数据来学习基于词-词共现统计的嵌入。它在一些句法和语义任务上表现良好,如下图所示。屏幕截图告诉我们,术语之间的嵌入偏移有助于应用面向向量的推理。我们可以学习性别关系的泛化,这是从男人和女人之间的偏移量(男人->女人)的语义关系。然后,我们可以通过添加术语actor的向量来算术估计actor的向量和之前计算的偏移量。同样,我们可以学习诸如单词复数形式之类的句法关系。例如,如果给定Actor、Actors和Actress的向量,我们可以估计 Actors 的向量:
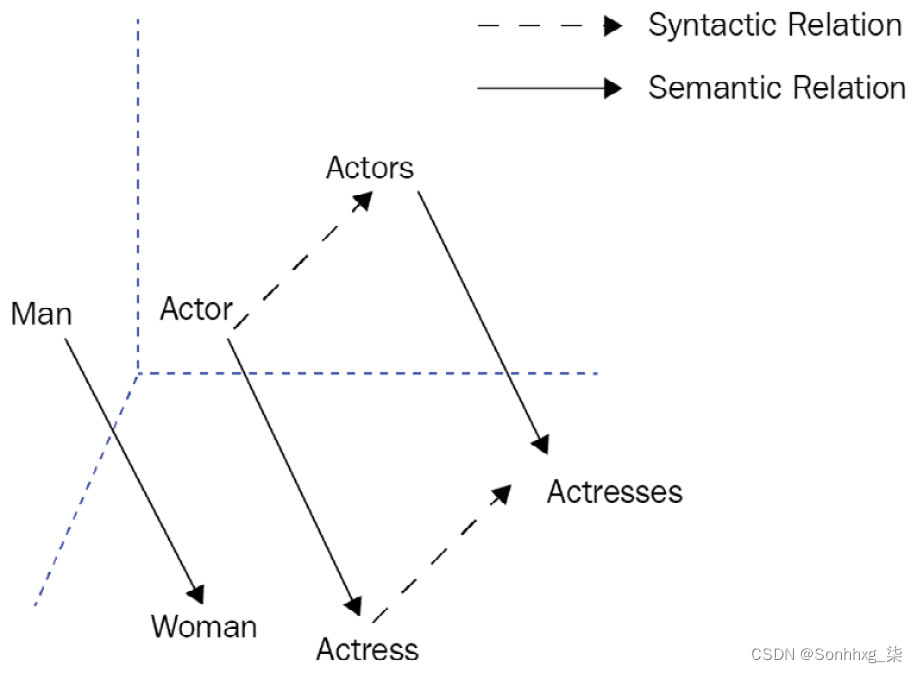
图 1.1 – 关系提取的词嵌入偏移
循环和卷积RNN、长短期记忆( LSTM ) 和 CNN 等架构开始被用作序列到序列( seq2seq ) 问题的编码器和解码器。主要的这些早期模型的挑战是多义词。由于为每个单词分配了一个固定的表示,因此忽略了单词的意义,这对于多义词和句子语义尤其严重。
进一步的先驱神经网络模型,例如通用语言模型微调( ULMFit ) 和语言模型嵌入( ELMo ) 管理与静态词嵌入不同,对句子级信息进行编码并最终缓解多义问题。这两种重要的方法都是基于 LSTM 网络的。他们还引入了预训练和微调的概念。它们帮助我们应用 TL,使用针对具有大量文本数据集的一般任务训练的预训练模型。然后,我们可以通过在有监督的目标任务上恢复预训练网络的训练来轻松地进行微调。表示不同于传统的词嵌入,因此每个词表示都是整个输入句子的函数。现代 Transformer 架构利用了这个想法。
与此同时,注意力机制的想法在 NLP 领域留下了深刻的印象并取得了显着的成功,尤其是在 seq2seq 问题中。早期的方法将通过最后状态(称为上下文向量或思想向量)从整个输入序列到输出序列,没有链接或消除。注意力机制能够通过将从输入序列确定的标记链接到输出序列中的特定标记来构建更复杂的模型。例如,假设您在英语到土耳其语翻译任务的输入句子中有一个关键字词组Government of Canada 。在输出句子中,Kanada Hükümeti标记与输入短语建立了强连接,并与输入中的其余单词建立了较弱的连接,如下面的屏幕截图所示:

图 1.2 – 注意机制的粗略可视化
因此,这种机制使得模型在翻译、问答和文本摘要等 seq2seq 问题上更加成功。
2017 年,提出了基于 Transformer 的编码器-解码器模型并取得了成功。该设计基于 FFNN,丢弃 RNN 重复性并仅使用注意力机制(Vaswani 等人,All you need is attention, 2017)。迄今为止,基于 Transformer 的模型已经克服了其他方法面临的许多困难,并已成为一种新的范式。在本书中,您将探索和理解基于 Transformer 的模型是如何工作的。
理解分布语义
分布语义用矢量表示来描述单词的含义,最好查看其分布证据,而不是查看其预定义的字典定义。该理论表明,在相似环境中同时出现的单词往往具有相似的含义。这首先由学者哈里斯(Distributional Structure Word,1954)提出。例如,狗和猫等相似词大多同时出现在相同的上下文中。分布式方法的优点之一是帮助研究人员理解和监控单词跨时间和跨域的语义演变,也称为作为词汇语义变化问题。
传统方法多年来一直应用词袋( BoW ) 和 n-gram 语言模型来构建单词和句子的表示。在 BoW 方法中,单词和文档用 one-hot 编码表示,作为一种稀疏表示方式,也称为作为向量空间模型(VSM)。
文本分类、词相似度、语义关系抽取、词义消歧等多年来,这些 one-hot 编码技术已经解决了 NLP 问题。另一方面,n-gram 语言模型为单词序列分配概率,以便我们可以计算序列属于语料库的概率,或者根据给定的语料库生成随机序列。
BoW 的实施
BoW 是一种文档表示技术数着里面的字。该技术的主要数据结构是文档术语矩阵。让我们看一下使用 Python 的 BoW 的简单实现。以下代码说明了如何使用 Python sklearn库为包含三个句子的玩具语料库构建文档术语矩阵:
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
import pandas as pdtoy_corpus= ["the fat cat sat on the mat","the big cat slept","the dog chased a cat"]vectorizer=TfidfVectorizer()
corpus_tfidf=vectorizer.fit_transform(toy_corpus)print(f"The vocabulary size is \{len(vectorizer.vocabulary_.keys())} ")
print(f"The document-term matrix shape is\{corpus_tfidf.shape}")df=pd.DataFrame(np.round(corpus_tfidf.toarray(),2))
df.columns=vectorizer.get_feature_names()代码的输出是一个文档术语矩阵,如以下屏幕截图所示。大小为 (3 x 10),但在现实场景中,矩阵大小可以增长到更大的数字,例如 10K x 10M:

图 1.3 – 文档术语矩阵
该表指示基于计数的数学矩阵,其中单元格值被转换通过词频-逆文档频率( TF-IDF ) 加权模式。这种方法不关心单词的位置。由于词序强烈地决定了意义,忽视它会导致意义的丧失。这是BoW方法中的常见问题,最终通过RNN中的递归机制和Transformers中的位置编码来解决。
矩阵中的每一列代表一个向量词表中的单词,每一行代表一个文档的向量。语义相似度度量可用于计算单词和文档的相似度或不相似度。大多数时候,我们使用cat_sat和the_street等二元组来丰富文档表示。例如,当参数ngram_range=(1,2)被传递给TfidfVectorizer时,它会构建一个向量空间,其中包含一元组(big、cat、dog)和二元组(big_cat、big_dog)。因此,此类模型也称为bag-of-n-grams,即BoW的自然延伸。
如果一个词在每个文档中都被常用到,那么就可以认为是高频词,比如和 。相反,有些词几乎不会出现在文档中,称为低频(或稀有)词。由于高频和低频词可能会妨碍模型正常工作,因此这里使用最重要和最知名的加权机制之一 TF-IDF 作为解决方案。
逆文档频率( IDF ) 是用于衡量文档中单词重要性的统计权重——例如,虽然单词the没有区分能力,但Chasched可以提供大量信息并提供有关文本主题的线索。这是因为高频词(停用词、功能词)在理解文档方面几乎没有辨别力。
术语的区分性还取决于在域上——例如,一个深度学习文章列表最有可能在几乎每个文档中都有网络这个词。IDF 可以通过使用它们的文档频率( DF )来缩小所有术语的权重,其中一个词的 DF 是由一个词出现在其中的文档的数量来计算的。词频( TF ) 是文档中术语(单词)的原始计数。
下面列出了基于 TF-IDF 的 BoW 模型的一些优缺点:
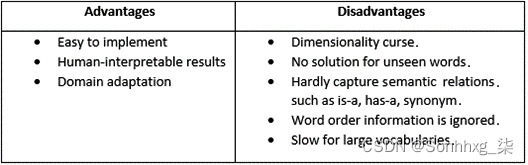
表 1 – TF-IDF BoW 模型的优缺点
克服维度问题
对于自然语言理解( NLU ) 任务,传统管道从一些准备步骤开始,例如标记化、词干提取、名词短语检测、分块、停用词消除等等。之后,使用任何加权模式构建文档术语矩阵,其中 TF-IDF 是最流行的。最后,矩阵被用作列表机器学习( ML ) 管道、情感分析、文档相似性、文档聚类或测量查询与文档之间的相关性分数的输入。同样,术语表示为表格矩阵,并且可以输入到令牌分类问题中,我们可以在其中应用命名实体识别、语义关系提取等。
分类阶段包括监督 ML 算法的直接实现例如支持向量机( SVM )、随机森林、逻辑、朴素贝叶斯和多学习器(Boosting 或 Bagging)。实际上,这种管道的实现可以简单地编码如下:
from sklearn.pipeline import make_pipeline
from sklearn.svm import SVClabels= [0,1,0]
clf = SVC()
clf.fit(df.to_numpy(), labels)如前面的代码所示,我们可以很容易地应用拟合操作感谢sklearn 应用程序编程接口( API )。为了将学习到的模型应用于训练数据,执行以下代码:
clf.predict(df.to_numpy())# Output: array([0, 1, 0])让我们继续下一节吧!
语言建模和生成
对于语言生成问题,传统方法是基于利用 n-gram 语言模型。这是也称为马尔科夫过程,它是一个随机模型,其中每个单词(事件)依赖于先前单词的子集——unigram、bigram或n-gram,概述如下:
- Unigram(所有单词都是独立的,没有链):这个估计单词在词汇表中的概率,简单地通过它的频率计算到总单词数。
- Bigram(一阶马尔可夫过程):这个根据wordi-1估计 wordi 的P (word i | wordi -1 )概率,它简单地通过P (word i , wordi -1 )与P (wordi -1 )的比率来计算。
- Ngram(N阶马尔可夫过程):这个估计P (wordi | wordi0, ..., wordi-1)。
让我们给出一个简单的语言模型使用自然语言工具包( NLTK ) 库实现。在下面的实现中,我们训练一个最大似然估计器(MLE),阶数为n=2。我们可以选择任何 n-gram 顺序,例如n=1表示一元组,n=2表示二元组,n=3表示三元组,等等:
import nltk
from nltk.corpus import gutenberg
from nltk.lm import MLE
from nltk.lm.preprocessing import padded_everygram_pipelinenltk.download('gutenberg')
nltk.download('punkt')
macbeth = gutenberg.sents('shakespeare-macbeth.txt')
model, vocab = padded_everygram_pipeline(2, macbeth)
lm=MLE(2)
lm.fit(model,vocab)print(list(lm.vocab)[:10])
print(f"The number of words is {len(lm.vocab)}")nltk包首先下载古腾堡语料库,其中包括来自托管在https://www.gutenberg.org的古腾堡计划电子文本档案中的一些文本。它还下载用于标点符号处理的punkt tokenizer 工具。该分词器使用无监督算法将原始文本划分为句子列表。nltk包已经包含一个用于缩写词和搭配的预训练英语 punkt 标记器模型。它可以在使用前接受任何语言的文本列表的培训。在接下来的章节中,我们还将讨论如何为 Transformer 模型训练不同且更有效的标记器。以下代码生成语言模型到目前为止所学的内容:
print(f"The frequency of the term 'Macbeth' is {lm.counts['Macbeth']}")
print(f"The language model probability score of 'Macbeth' is {lm.score('Macbeth')}")
print(f"The number of times 'Macbeth' follows 'Enter' is {lm.counts[['Enter']]['Macbeth']} ")
print(f"P(Macbeth | Enter) is {lm.score('Macbeth', ['Enter'])}")
print(f"P(shaking | for) is {lm.score('shaking', ['for'])}")这是输出:
The frequency of the term 'Macbeth' is 61
The language model probability score of 'Macbeth' is 0.00226
The number of times 'Macbeth' follows 'Enter' is 15
P(Macbeth | Enter) is 0.1875
P(shaking | for) is 0.0121n-gram 语言模型保持n-gram计数并计算句子生成的条件概率。lm=MLE(2)代表 MLE,它从每个标记概率中产生最大可能的句子。以下代码生成一个包含 10 个单词的随机句子,并给出了<s>起始条件:
lm.generate(10, text_seed=['<s>'], random_seed=42)输出显示在以下代码段中:
['My', 'Bosome', 'franchis', "'", 's', 'of', 'time', ',', 'We', 'are']
我们可以给出一个通过text_seed参数指定特定的起始条件,使生成以前面的上下文为条件。在我们前面的例子中,前面的上下文是<s>,它是一个表示句子开头的特殊标记。
到目前为止,我们已经讨论了传统 NLP 模型的范式,并提供了非常简单的流行框架实现。我们现在转到 DL 部分,讨论神经语言模型如何塑造 NLP 领域以及神经模型如何克服传统模型的局限性。
利用深度学习
NLP 是其中之一深度学习架构已被广泛且成功地使用。几十年来,我们见证了成功的架构,尤其是在单词和句子表示方面。在本节中,我们将与常用框架分享这些不同方法的故事。
学习词嵌入
基于神经网络的语言模型有效地解决了特征表示和语言建模问题,因为可以在更大的数据集上训练更复杂的神经架构来构建短而密集的表示。2013 年,流行的Word2vec 模型词嵌入技术,使用简单有效的架构来学习高质量的连续词表示。它在各种句法和语义语言任务(例如情感分析、释义检测、关系提取等)方面优于其他模型。该模型流行的另一个关键因素是其计算复杂度低得多。在给定任何周围的上下文单词的情况下,它最大化当前单词的概率,反之亦然。
下面一段代码说明了如何训练词向量对于戏剧麦克白的句子:
from gensim.models import Word2vecmodel = Word2vec(sentences=macbeth, size=100, window= 4, min_count=10, workers=4, iter=10)该代码通过一个滑动的 5 长度上下文窗口来训练向量大小为 100 的词嵌入。为了可视化单词嵌入,我们需要通过应用主成分分析( PCA )将维度减少到 3如下代码片段所示:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import randomnp.random.seed(42)
words=list([e for e in model.wv.vocab if len(e)>4])
random.shuffle(words)
words3d = PCA(n_components=3,random_state=42).fit_transform(model.wv[words[:100]])def plotWords3D(vecs, words, title):...plotWords3D(words3d, words, "Visualizing Word2vec Word Embeddings using PCA")这是输出:

图 1.4 – 使用 PCA 可视化词嵌入
如图所示,莎士比亚戏剧的主要人物——麦克白、马尔科姆、班柯、麦克德夫等——被映射到接近彼此。同样,助动词shall、should和will在图1.4的左下角彼此靠近。我们还可以通过使用嵌入偏移来捕捉诸如man-woman= uncle-aunt 之类的类比。有关此主题的更多有趣的视觉示例,请查看以下项目:https ://projector.tensorflow.org/ 。
类似 Word2vec 的模型通过采用基于预测的神经架构来学习词嵌入。他们对一些目标函数和附近的词预测采用梯度下降。传统方法应用基于计数的方法,而神经模型为分布式语义设计了基于预测的架构。基于计数的方法或基于预测的方法是分布式词表示的最佳选择吗?GloVe 方法解决了这个问题,并认为这两种方法没有显着不同。杰弗里·佩宁顿等人。甚至支持基于计数的方法可以通过捕获全球统计数据更成功的想法。他们表示 GloVe 表现优于其他关于词类比、词相似性和命名实体识别( NER ) 任务的神经网络语言模型。
然而,这两种范式确实没有提供有用的解决方案看不见的单词和词义问题。它们不利用子词信息,因此无法学习稀有和不可见词的嵌入。
FastText , 另一个广泛使用的模型,提出了一种新的使用子词信息的丰富方法,其中每个词都表示为一袋字符 n-gram。该模型为每个字符 n-gram 设置一个常量向量,并将单词表示为其子向量的总和,这是 Hinrich Schütze 首次引入的想法(Word Space,1993 年)。该模型甚至可以计算看不见的单词的单词表示,并学习单词的内部结构,例如后缀/词缀,这对于芬兰语、匈牙利语、土耳其语、蒙古语、韩语、日语、印度尼西亚语等形态丰富的语言尤其重要. 目前,现代变压器架构使用各种子词标记化WordPiece 、SentencePiece或字节对编码( BPE ) 等方法。
RNN 的简要概述
RNN 模型可以学习每个令牌表示通过在较早的时间步汇总其他标记的信息并在最后一个时间步学习句子表示。已发现这种机制在许多方面都是有益的,概述如下:
- 首先,RNN 可以重新设计为一对多模型,用于语言生成或音乐生成。
- 其次,多对一模型可用于文本分类或情感分析。
- 最后,多对多模型用于 NER 问题。多对多模型的第二个用途是解决编码器-解码器问题,例如机器翻译、问答和文本摘要。
与其他神经网络模型一样,RNN 模型采用由标记化算法生成的标记,该算法将整个原始文本分解为原子单元,也称为标记。此外,它将标记单元与在训练期间学习的数字向量(标记嵌入)相关联。作为替代方案,我们可以提前将嵌入式学习任务分配给众所周知的词嵌入算法,例如 Word2vec 或 FastText。
这是一个简单的例子RNN 架构句子猫很伤心。,其中 x 0是 的向量嵌入, x 1是cat的向量嵌入,依此类推。图 1.5说明了一个RNN 被展开成一个完整的深度神经网络( DNN )。
展开意味着我们为每个单词关联一个层。因为猫很伤心。序列,我们处理五个单词的序列。每一层的隐藏状态充当网络的记忆。它编码有关所有先前时间步和当前时间步中发生的事情的信息。这在下图中表示:
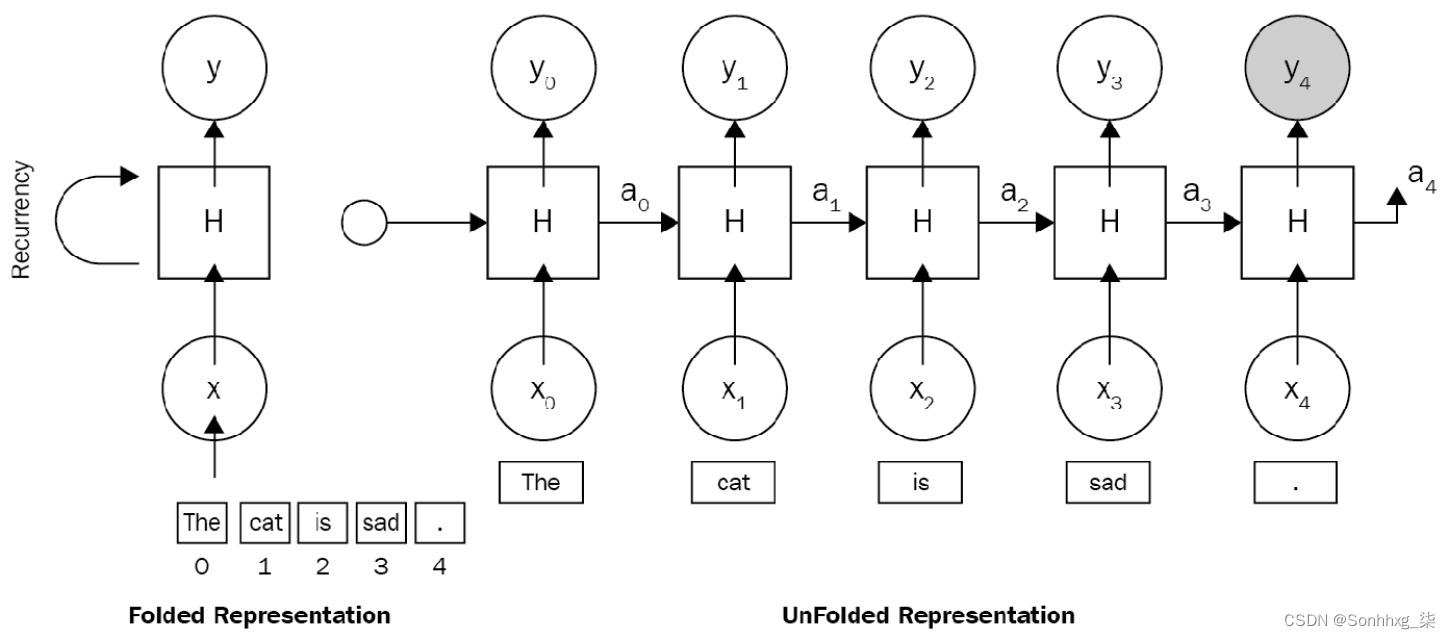
图 1.5 – RNN 架构
- 可变长度输入:无论输入的句子大小如何,都可以处理可变长度输入。我们可以在不更改参数的情况下向网络提供 3 或 300 个单词的句子。
- 关心词序:按顺序逐词处理序列,关心词的位置。
- 适合在各种模式下工作(多对多、一对多):我们可以使用相同的递归范式训练机器翻译模型或情感分析。两种架构都将基于 RNN。
这RNN 架构的缺点是此处列出:
- 长期依赖问题:当我们处理一个很长的文档并尝试链接彼此相距较远的术语时,我们需要关心和编码这些术语之间所有不相关的其他术语。
- 容易出现梯度爆炸或消失问题:在处理长文档时,更新第一个单词的权重是一件大事,这使得模型由于梯度消失问题而无法训练。
- 难以应用可并行化训练:并行化将主要问题分解为较小的问题并同时执行解决方案,但 RNN 遵循经典的顺序方法。每一层都强烈依赖于前一层,这使得并行化变得不可能。
- 由于序列很长,计算速度很慢:RNN 对于短文本问题可能非常有效。除了长期依赖问题之外,它处理较长文档的速度非常慢。
虽然 RNN 理论上可以在之前的许多时间步长上参与信息,但在现实世界中,长文档和长期依赖等问题是不可能发现的。长序列在许多深层中表示。许多研究已经解决了这些问题,其中一些其中是此处概述:
- 霍克赖特和施米德胡伯。长短期记忆。1997 年。
- 本吉奥等人。用梯度下降学习长期依赖是很困难的。1993 年。
- K. Cho 等人。使用 RNN 编码器-解码器学习短语表示以进行统计机器翻译。2014 年。
LSTM 和门控循环单元
LSTM ( Schmidhuber, 1997 ) 和门控循环单元( GRUs ) ( Cho, 2014 ) 是 RNN 的新变体,具有长期解决依赖问题,并且有引起了极大的关注。LSTM 是专门为解决长期依赖问题而开发的。LSTM 模型的优势在于它使用了额外的单元状态,即 LSTM 单元顶部的水平序列线。此单元状态由用于忘记、插入或更新操作的专用门控制。LSTM 架构的复杂单元如下图所示:
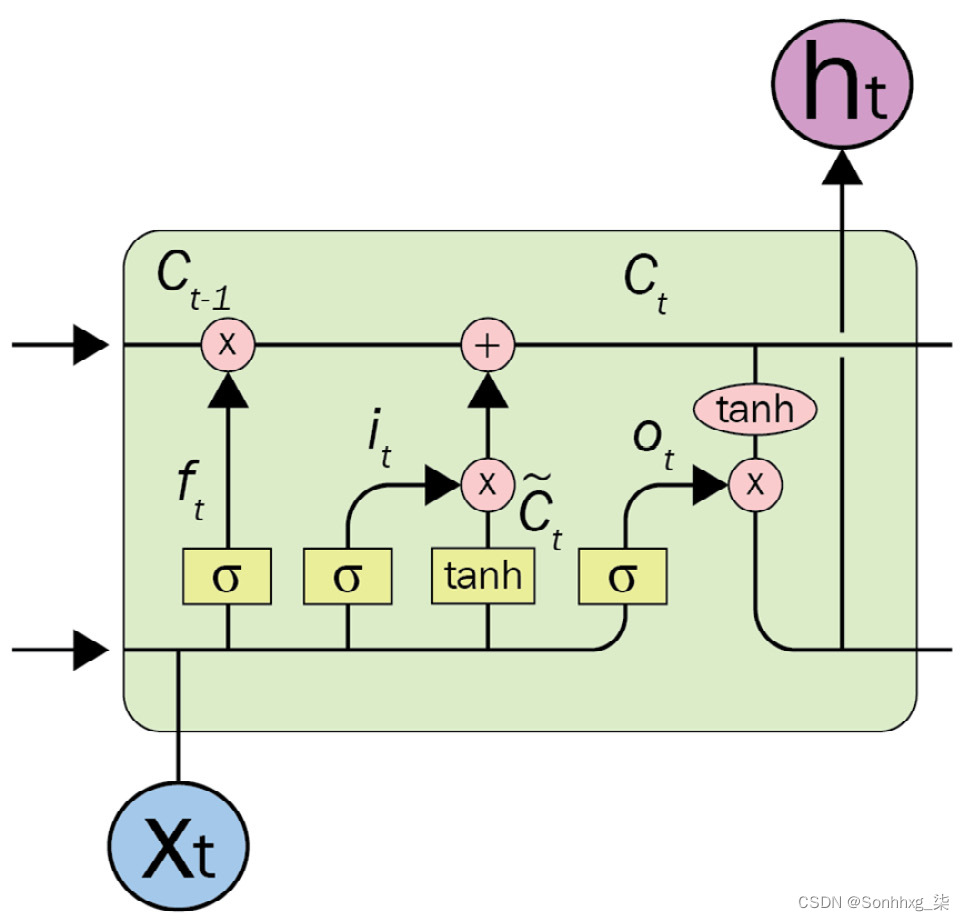
图 1.6 – 一个 LSTM 单元
它能够决定以下内容:
- 我们将在细胞状态中存储什么样的信息
- 哪些信息会被遗忘或删除
在原始 RNN 中,在为了学习I 标记的状态,它在时间步0和时间步-1之间反复处理先前标记的整个状态。携带全部信息来自较早的时间步长会导致梯度消失问题,这使得模型无法训练。LSTM 中的门机制允许架构在某个时间步跳过一些不相关的令牌或记住远程状态以学习当前令牌状态。
GRU 在很多方面类似于 LSTM,主要区别在于 GRU 不使用单元状态。相反,通过将单元状态的功能转移到隐藏状态,它只包括两个门:更新门和重置门。更新门决定有多少来自先前和当前时间步的信息将被向前推进。此功能有助于模型保留过去的相关信息,从而将梯度消失问题的风险降至最低。重置门检测到不相关的数据并让模型忘记它。
使用 Keras 实现 LSTM 的温和实现
我们要下载斯坦福情绪树库( SST-2 ) 情绪数据集来自通用语言理解评估( GLUE ) 基准。我们可以通过运行以下代码:
$ wget https://dl.fbaipublicfiles.com/glue/data/SST-2.zip$ unzip SST-2.zip重要的提示
SST-2:这是一个完全标记的解析树,允许用英语进行完整的情感分析。语料库最初由从电影评论中提取的大约 12K 单句组成。它由斯坦福解析器解析,包含超过 20 万个独特的短语,每个短语都由三名人工评委注释。有关详细信息,请参阅Socher 等人的 Parsing With Compositional Vector Grammars,EMNLP。2013 ( Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank )。
下载完数据后,我们将其读取为pandas对象,如下:
import tensorflow as tf
import pandas as pddf=pd.read_csv('SST-2/train.tsv',sep="\t")
sentences=df.sentence
labels=df.label我们需要设置最大句子长度,构建词汇和字典(word2idx,idx2words),最后将每个句子表示为索引列表而不是字符串。我们可以通过运行以下代码来做到这一点:
max_sen_len=max([len(s.split()) for s in sentences])
words = ["PAD"]+\list(set([w for s in sentences for w in s.split()]))
word2idx= {w:i for i,w in enumerate(words)}
max_words=max(word2idx.values())+1idx2word= {i:w for i,w in enumerate(words)}
train=[list(map(lambda x:word2idx[x], s.split()))\for s in sentences]短于max_sen_len(最大句子长度)的序列会被填充一个PAD值,直到它们的长度为max_sen_len。另一方面,较长的序列被截断,以便它们适合max_sen_len。这是实现:
from keras import preprocessing
train_pad = preprocessing.sequence.pad_sequences(train,maxlen=max_sen_len)
print('Train shape:', train_pad.shape)# Output: Train shape: (67349, 52)我们准备设计和训练一个 LSTM 模型,如下:
from keras.layers import LSTM, Embedding, Dense
from keras.models import Sequentialmodel = Sequential()
model.add(Embedding(max_words, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy', metrics=['acc'])
history = model.fit(train_pad,labels, epochs=30, batch_size=32, validation_split=0.2)该模型将是训练了 30 个 epoch。为了要绘制 LSTM 模型到目前为止所学的内容,我们可以执行以下代码:
import matplotlib.pyplot as pltdef plot_graphs(history, string):...plot_graphs(history, 'acc')
plot_graphs(history, 'loss')该代码生成以下图表,它向我们展示了基于 LSTM 的文本分类的训练和验证性能:
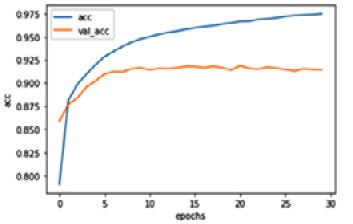
图 1.7 – LSTM 网络的分类性能
CNN的简要概述

图 1.8 – One-hot 向量
每个令牌,代表通过 one-hot 向量,被馈送到嵌入层。嵌入层可以通过随机值或使用预先训练的词向量(如 GloVe、Word2vec 或 FastText)进行初始化。然后将一个句子转换为 NxE 形状的密集矩阵(其中N是句子中的标记数,E是嵌入大小)。以下屏幕截图说明了 1D CNN 如何处理该密集矩阵:
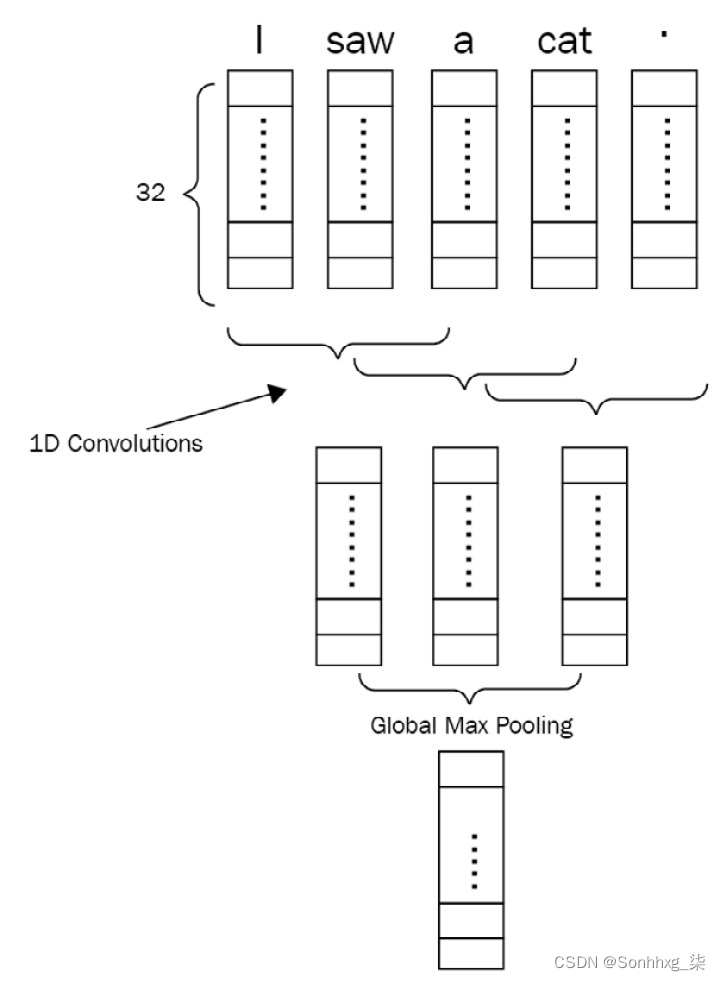
图 1.9 – 一个包含五个标记的句子的 1D CNN 网络

图 1.10 – CNN 中多种表示的组合
图 1.11 – 卷积方向
以下代码片段是一维 CNN 实现处理 LSTM 管道中使用的相同数据。它包括Conv1D和MaxPooling层的组合,然后是GlobalMaxPooling层。我们可以通过调整参数和添加更多层来优化模型来扩展管道:
from keras import layersmodel = Sequential()
model.add(layers.Embedding(max_words, 32, input_length=max_sen_len))
model.add(layers.Conv1D(32, 8, activation='relu'))
model.add(layers.MaxPooling1D(4))
model.add(layers.Conv1D(32, 3, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1, activation= 'sigmoid')
model.compile(loss='binary_crossentropy', metrics=['acc'])history = model.fit(train_pad,labels, epochs=15, batch_size=32, validation_split=0.2)事实证明,CNN 模型的性能与其 LSTM 模型相当。尽管 CNN已经成为标准在图像处理中,我们已经看到了 CNN 在 NLP 中的许多成功应用。LSTM 模型被训练为跨时间识别模式,而 CNN 模型可以跨空间识别模式。
Transformer 架构概述
变压器型号有由于它们在从文本分类到文本生成的大量 NLP 问题中的有效性而引起了极大的兴趣。注意机制是这些模型的重要组成部分,起着非常关键的作用。在 Transformer 模型之前,注意力机制被提出来作为改进传统 DL 模型(如 RNN)的辅助工具。为了更好地理解 Transformer 及其对 NLP 的影响,我们将首先研究注意力机制。
注意力机制
的第一个变体之一注意机制是由Bahdanau 等人提出。(2015 年)。这种机制基于这样一个事实,即 GRU 或 LSTM 等基于 RNN 的模型具有信息神经机器翻译( NMT )等任务的瓶颈。这些基于编码器-解码器的模型以令牌 ID的形式获取输入,并以循环方式(编码器)对其进行处理。之后,处理后的中间表示被送入另一个循环单元(解码器)以提取结果。这种雪崩式的信息就像一个滚动的球,消耗了所有的信息,对于解码器部分来说,滚动它是很困难的,因为解码器部分看不到所有的依赖关系,只得到中间表示(上下文向量)作为输入。
为了调整这种机制,Bahdanau 提出了一种注意力机制,在中间隐藏值上使用权重。这些权重与模型在每个解码步骤中必须对输入的关注量保持一致。如此精彩的指导帮助模型完成特定任务,例如 NMT,这是一个多对多的任务。这里提供了一个典型的注意力机制图:

图 1.12 – 注意力机制
不同的注意力机制有被提议与不同的改进。加法、乘法、一般和点积注意力出现在这些机制的家族中。后者是具有缩放参数的修改版本,被称为缩放点积注意力。这种特定的注意力类型是变形金刚模型的基础,并且是称为多头注意力机制。附加注意力也是前面介绍的 NMT 任务的显着变化。您可以在此处查看不同类型的注意力机制的概述:
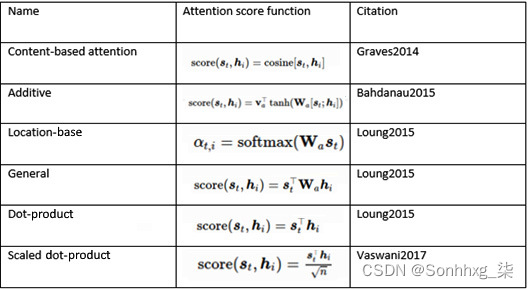
表 2 – 注意力机制的类型(图片来自 https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html)
由于注意力机制不是特定于 NLP 的,它们是还用于从计算机视觉到语音识别等各个领域的不同用例。以下屏幕截图显示了针对神经图像字幕训练的多模态方法的可视化(K Xu 等人,展示、参加和讲述:具有视觉注意力的神经图像字幕生成,2015 年):

图 1.13 – 计算机视觉中的注意力机制
多头注意力如图所示的机制下图是 Transformer 架构的重要组成部分:

图 1.14 – 多头注意力机制
接下来,让我们了解一下多头注意力机制。
多头注意力机制
在跳入之前规模化的点积注意力机制,更好得到一个好的对自注意力的理解。自注意力,如图 1.15所示,是缩放自注意力机制的基本形式。该机制使用显示为X的输入矩阵,并在X中的各个项目之间产生注意力分数。我们将X视为 3x4 矩阵,其中 3 表示标记的数量,4 表示嵌入大小。图 1.15中的Q也称为查询,K称为键,V称为值。三种类型的矩阵显示为theta、phi和g在产生Q、K和V之前乘以X。查询 ( Q ) 和关键 ( K )之间的相乘结果产生一个注意力得分矩阵。这也可以看作是一个数据库,我们使用查询和键来找出各种项目在数值评估方面的相关程度。注意力分数和V矩阵的乘积产生了这种注意力机制的最终结果。它被称为self-attention的主要原因是它的统一输入X;Q、K和V从X计算。您可以在下图中看到所有这些:

图 1.15 – 注意力机制的数学表示(图片来自 https://blogs.oracle.com/datascience/multi-head-self-attention-in-nlp)
缩放的点积注意机制与自我注意(点积)机制非常相似,只是它使用了缩放因子。另一方面,多头部分确保模型能够查看各个级别的输入的各个方面。变压器模型参加编码器注释和来自过去层的隐藏值。Transformer 模型的架构没有循环的分步流程;相反,它使用位置编码来获得有关输入序列中每个标记的位置的信息。嵌入的连接值(随机初始化)和位置编码的固定值是输入到第一个编码器部分的层中,并通过架构传播,如下图所示:
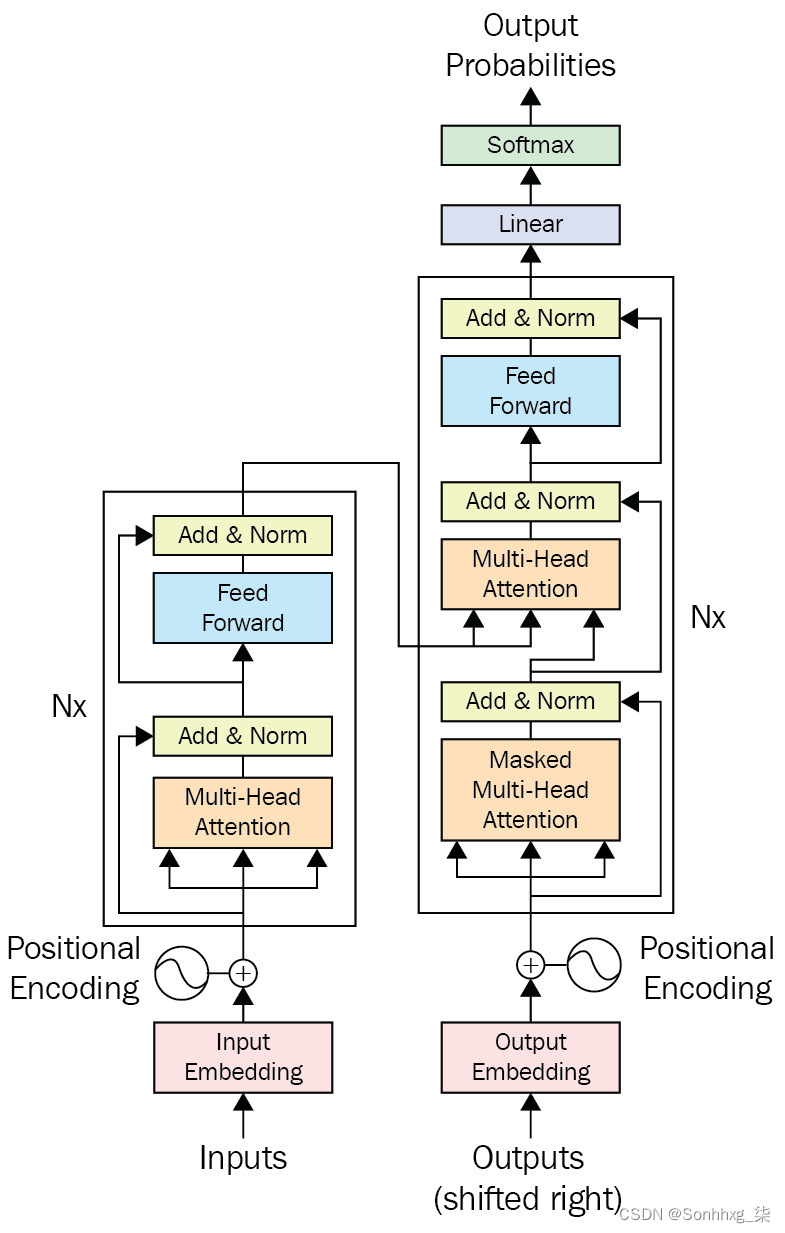
图 1.16 – Transformer
通过评估不同频率的正弦波和余弦波来获得位置信息。以下屏幕截图显示了位置编码的示例:
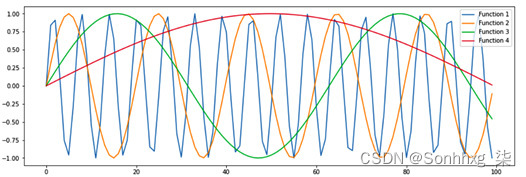
图 1.17 – 位置编码(图片来自 http://jalammar.github.io/illustrated-Transformer/)
一个很好的例子上的表现Transformer 架构和缩放的点积注意力机制在以下流行的屏幕截图中给出:
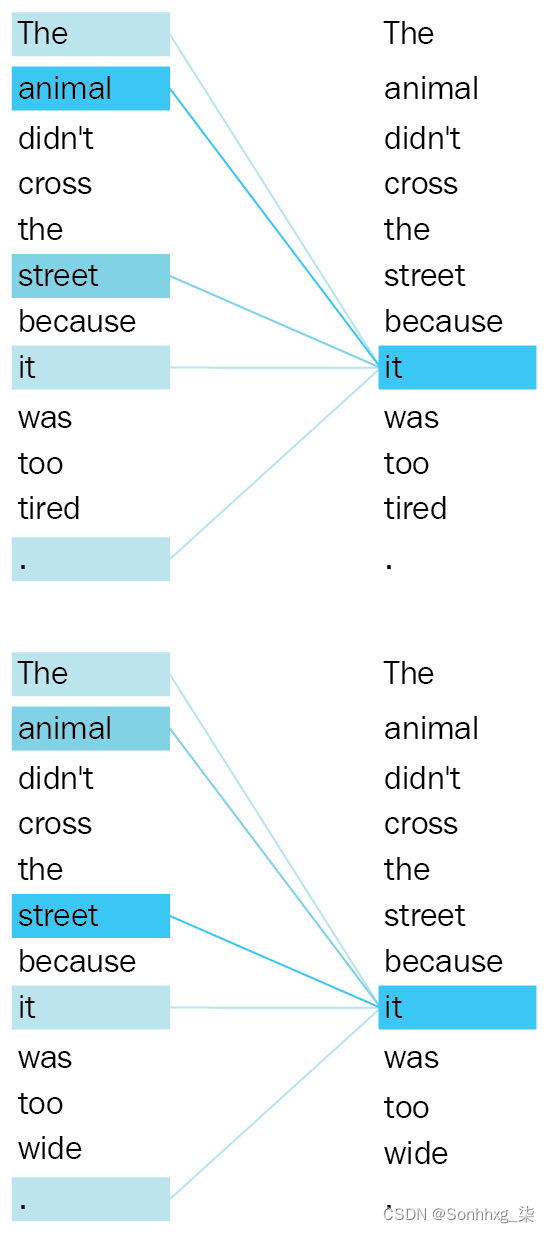
图 1.18 – Transformers 的注意力映射(图片灵感来自 https://ai.googleblog.com/2017/08/Transformer-novel-neural-network.html)
从前面的屏幕截图可以看出,它在不同的上下文中指的是不同的实体。使用 Transformer 架构的另一个改进是并行性。传统的顺序循环模型,如 LSTM 和 GRU 不具备这样的能力因为他们处理逐个令牌输入令牌。另一方面,前馈层的速度要快一些,因为单矩阵乘法比循环单元快得多。堆叠的多头注意力层可以更好地理解复杂的句子。以下屏幕截图显示了多头注意力机制的一个很好的视觉示例:

图 1.19 - 多头注意力机制(图片来自 https://imgur.com/gallery/FBQqrxw)
在注意力机制的解码器端,使用与编码器非常相似的方法,只需稍作修改。多头注意力机制是相同的,但也使用了编码器堆栈的输出。这种编码被赋予第二个多头注意力层中的每个解码器堆栈。这个小小的修改在解码时引入了编码器堆栈的输出。这种修改让模型在解码时知道编码器的输出,同时在训练期间帮助它在各个层上有更好的梯度流。解码器层末尾的最终 softmax 层用于为各种用例(例如 NMT)提供输出,为此引入了原始的 Transformer 架构。
该架构有两个输入,称为输入和输出(右移)。一个总是存在于训练和推理中(输入),而另一个只存在于训练和推理中,这是由模型产生的。我们在推理中不使用模型预测的原因是为了防止模型本身出错。但是这是什么意思?想象一个神经翻译模型试图将一个句子从英语翻译成法语——在每一步,它都会对一个单词进行预测,并使用该预测的单词来预测下一个单词。但是,如果它在某个步骤出错,那么以下所有预测也将是错误的。为了阻止模型出现这样的错误,我们提供了正确的单词作为右移版本。
一个视觉示例变压器型号为在下图中给出。它显示了一个带有两个编码器和两个解码器层的 Transformer 模型。此图中的Add & Normalize层添加并规范化它从前馈层获取的输入:
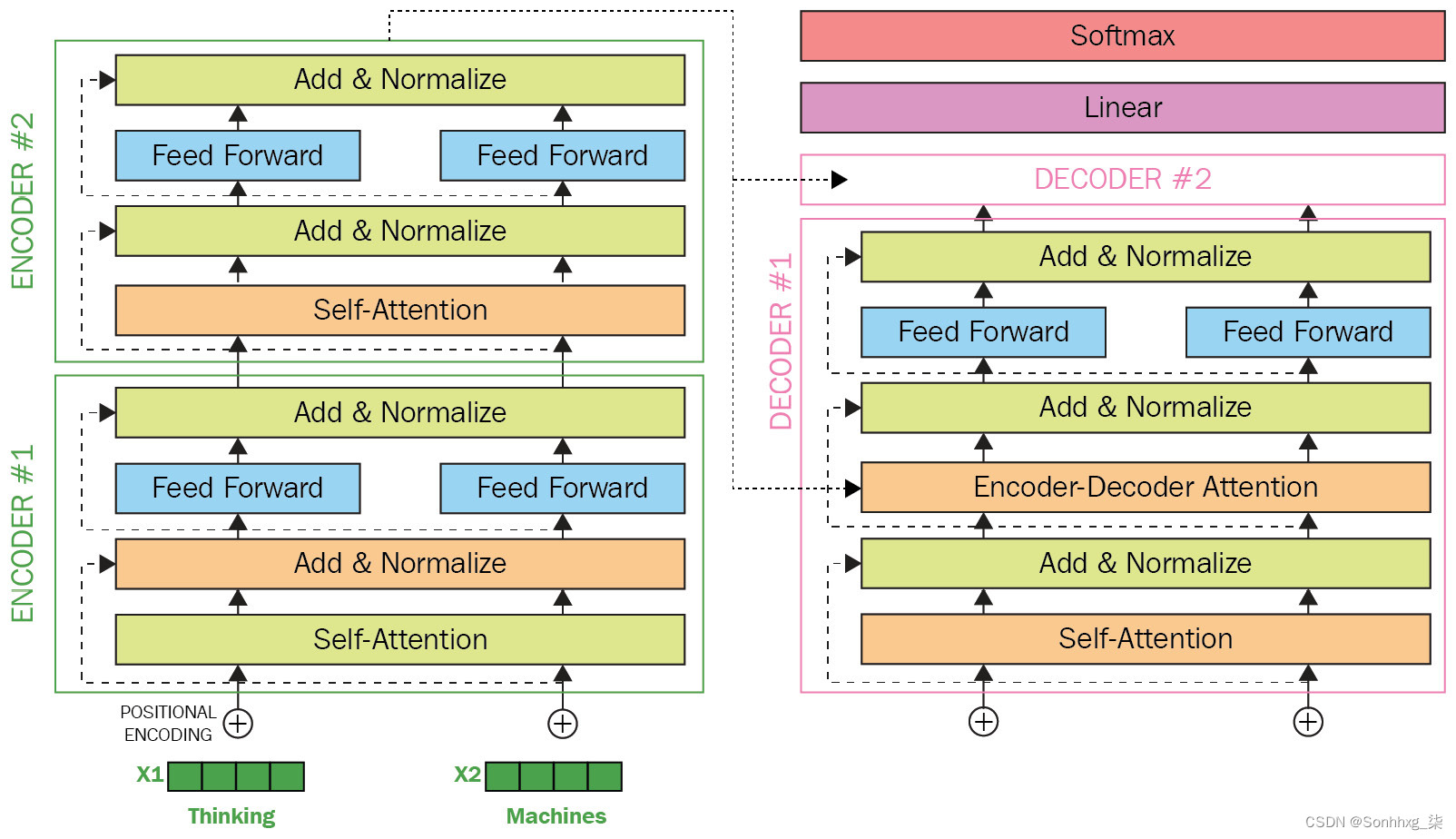
图 1.20 – Transformer 模型(图片来自 http://jalammar.github.io/illustrated-Transformer/)
基于 Transformer 的架构使用的另一个主要改进是基于简单的通用文本压缩方案,以防止在输入端出现看不见的标记。这种方法通过使用不同的方法(例如字节对编码和句子编码)来实现,提高了 Transformer 在处理看不见的标记方面的性能。当模型遇到形态上接近的标记时,它也会指导模型。这样的标记在过去是看不见的,也很少在训练中使用,然而,一个推论可能会被看到。在某些情况下,块在训练中可以看到它;后者发生在形态丰富的语言中,例如土耳其语、德语、捷克语和拉脱维亚语。例如,模型可能会看到单词training但看不到trainings。在这种情况下,它可以将训练标记为training+s。当我们将它们视为两个部分时,通常会看到这两个。
基于 Transformer 的模型具有相当普遍的特征——例如,它们都基于这种原始架构,但它们使用和不使用的步骤不同。在某些情况下,会有细微的差异——例如,对多头注意力机制的改进。
将 TL 与 Transformer 一起使用
TL是人工智能( AI ) 和 ML的一个领域旨在使模型可重复用于不同的任务——例如,在给定任务(例如A )上训练的模型可在不同任务(例如B)上重用(微调)。在 NLP 领域,这可以通过使用类似 Transformer 的架构来实现,该架构可以通过语言建模来捕捉对语言本身的理解。这样的模型被称为语言模型——它们为他们训练过的语言提供了一个模型。TL 并不是一项新技术,它已被用于计算机视觉等各个领域。ResNet、Inception、VGG 和 EfficientNet 是此类模型的示例,它们可以用作能够在不同的计算机视觉任务上进行微调的预训练模型。
在 NLP 中也可以使用Word2vec、GloVe和Doc2vec等模型进行浅 TL 。之所以称为浅层,是因为这种 TL 背后没有模型,而是使用了词/标记的预训练向量。您可以使用这些令牌或文档嵌入模型,然后使用分类器,或者将它们与 RNN 等其他模型结合使用,而不是使用随机嵌入。
使用 Transformer 模型的 NLP 中的 TL 也是可能的,因为这些模型可以在没有任何标记数据的情况下学习语言本身。语言建模是一项用于训练各种问题的可转移权重的任务。掩蔽语言建模是用于学习语言本身的方法之一。与 Word2vec 用于预测中心标记的基于窗口的模型一样,在掩码语言建模中,也采用了类似的方法,但存在关键差异。给定一个概率,每个单词都被屏蔽并替换为一个特殊的标记,例如[MASK]。语言模型(在我们的例子中是基于 Transformer 的模型)必须预测被屏蔽的单词。与 Word2vec 不同的是,它没有使用窗口,而是给出了一个完整的句子,并且模型的输出必须是填充了掩码单词的同一个句子。
使用 Transformer 架构进行语言建模的首批模型之一是BERT,它基于Transformer 架构的编码器部分。掩码语言建模是由 BERT 通过使用在训练语言模型之前和之后描述的相同方法来完成的。BERT 是一种可迁移的语言模型,适用于不同的 NLP 任务,例如令牌分类、序列分类,甚至是问答。
一旦训练了语言模型,这些任务中的每一个都是 BERT 的微调任务。BERT 以其在基本 Transformer 编码器模型上的关键特性而闻名,通过改变这些特性,提出了它的不同版本——小型、微型、基本、大型和超大型。上下文嵌入使模型能够根据给出每个单词的上下文具有正确的含义——例如,单词Cold可以有不同的两个不同句子的含义:冷酷的杀手和寒冷的天气。编码器部分的层数、输入维度、输出嵌入维度和多头注意力机制的数量是这些关键特征,如下图所示:
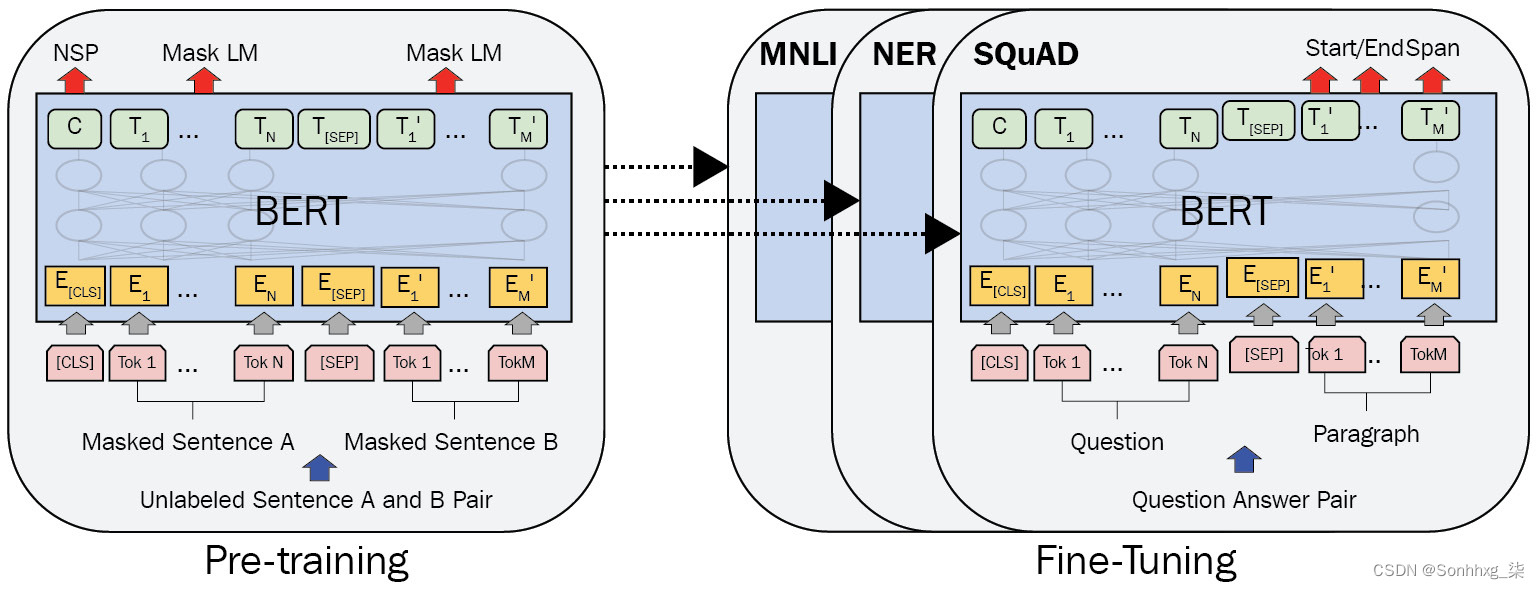
图 1.21 – BERT 的预训练和微调程序(图片灵感来自 J. Devlin 等人,Bert:用于语言理解的深度双向 Transformers 的预训练,2018)
如图1.21 所示,预训练阶段还包括另一个称为下一句预测的目标。众所周知,每个文档都是由一个个句子组成的,训练模型掌握语言的另一个重要部分是理解句子之间的关系——换句话说,它们是否相关。为了完成这些任务,BERT 引入了[CLS]和[SEP]等特殊令牌。[CLS]标记是最初无意义的标记,用作所有任务的开始标记,它包含有关句子的所有信息。在 NSP 等序列分类任务中,在这个 token 的输出之上的分类器(输出位置为0) 用来。它在评估句子的意义或捕获其语义方面也很有用——例如,在使用连体 BERT 模型时,通过余弦相似度等度量比较不同句子的这两个[CLS]标记非常有帮助。另一方面,[SEP]用于区分两个句子,它只用于分隔两个句子。在预训练之后,如果有人打算在序列分类任务上微调 BERT,例如情感分析,这是一个序列分类任务,他们将在[CLS]的输出嵌入之上使用分类器。还值得注意的是,所有 TL 模型都可以在微调期间冻结或释放;冻结意味着将模型中的所有权重和偏差视为常数并停止对其进行训练。在情感分析的例子中,只会训练分类器,如果模型被冻结,则不会训练。
概括
至此,我们现在来到了本章的结尾。您现在应该了解 NLP 方法和方法的演变,从 BoW 到 Transformers。我们研究了如何实现基于 BoW、RNN 和 CNN 的方法,并了解 Word2vec 是什么以及它如何帮助改进使用浅层 TL 的传统基于 DL 的方法。我们还研究了 Transformer 架构的基础,以 BERT 为例。在本章结束时,我们已经了解了 TL 以及 BERT 如何使用它。
至此,我们已经了解了继续下一章所必需的基本信息。我们了解了基于 Transformer 的架构背后的主要思想,以及如何使用这种架构来应用 TL。
在下一节中,我们将看到如何从头开始运行一个简单的 Transformer 示例。将给出有关安装步骤的相关信息,并详细研究使用数据集和基准。



