【数据结构】和栈一样简单的结构——队列
- 一、前言
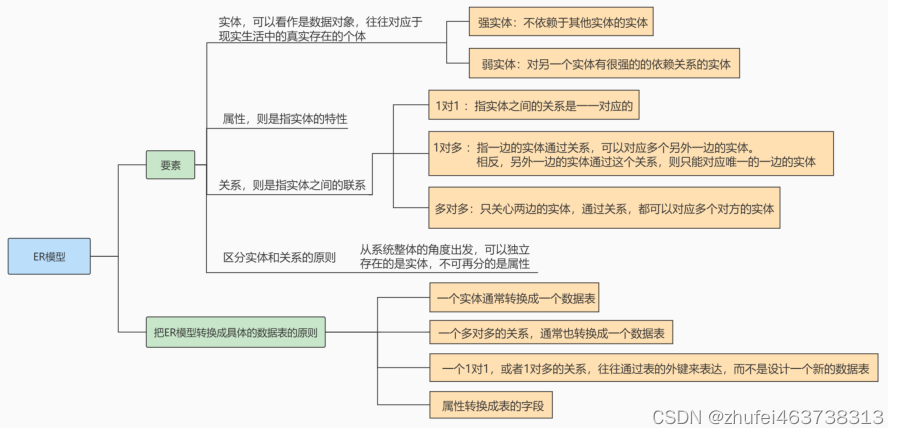
- 1、什么是队列?
- 2、使用什么结构实现?
- 二、目标
- 三、实现
- 1、初始化工作
- 2、入队
- 2.1、图解思路
- 2.2、代码实现
- 3、出队
- 3.1、图解思路
- 3.2、代码实现
- 4、打印队列(用于测试)
- 5、返回队头元素
- 6、返回队尾元素
- 7、返回队列中元素个数
- 8、判断队列是否为空
- 9、销毁队列
一、前言
1、什么是队列?
对于队列,百度百科上对它的简介是这样的:
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)线性表。
其实队列放到我们生活中也非常好理解,比如我们平时在食堂打饭或在超市里买东西付款的时候都需要排队。我们排的队肯定是后面来的人要排到队尾,前面的人先被服务到,也就是遵循了先进先出规则:

其实队列的实现也是和栈一样简单的,因为它的插入和删除也是规定死了的只能头删和尾插,所以我们主要要实现的也只是两个接口而已。
2、使用什么结构实现?
对于队列的实现主要使用的是两种结构,数组和链表:
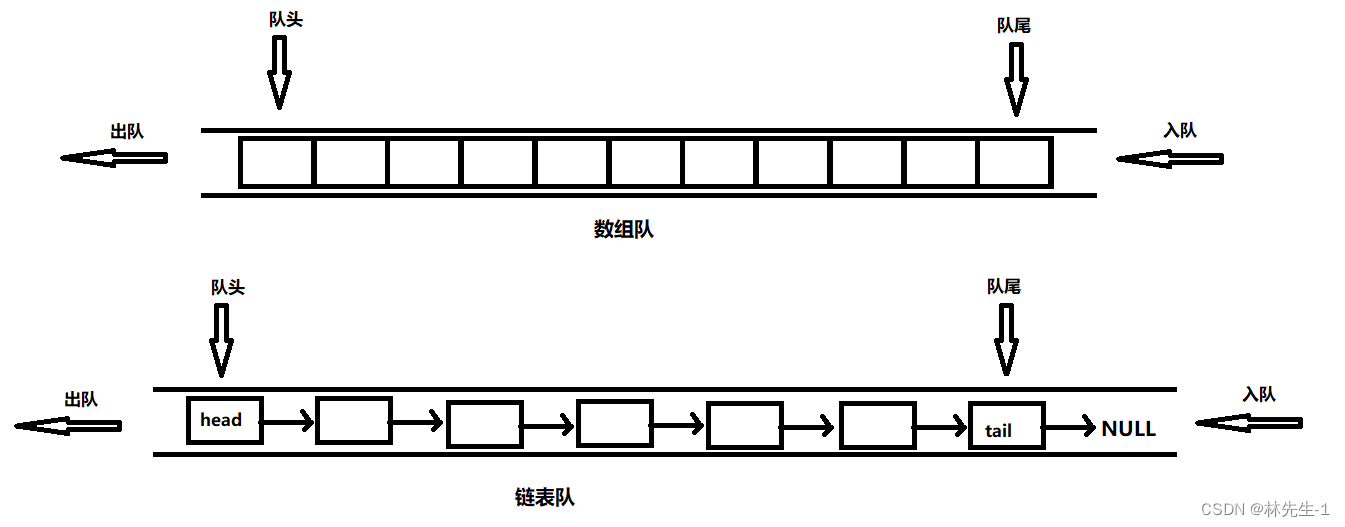
那么选择哪一种结构更加方便一点呢?这里能明确地告诉大家是使用链表实现更加简单。因为要是使用数组尾做队尾的话入队是挺方便的,但是出队的话就要将后面的元素全都向前移动一个位置,选用数组头做队尾则反过来出队也要移动数据。不管怎么样都是会有一端不太方便。
而使用链表来实现的话,我们可以定义两个指针head和tail分别记录链表的头和为,然后入队和出队就只需要执行头删和尾插即可,两个方法的复杂度都是O(1)。
所以我们就选用链表来实现队列。
二、目标
队列主要要实现的功能如下:
// 队列的入队
void QueuePush(Queue* pq, QDataType x);
// 队列的出队
void QueuePop(Queue* pq);
// 打印队列(用于测试)
void printQueue(Queue* pq);
// 返回队列的对头元素
QDataType QueueFront(Queue* pq);
// 返回队列的队尾元素
QDataType QueueBack(Queue* pq);
// 返回队列中的节点个数
int QueueSize(Queue* pq);
// 判断队列是否为空
bool QueueEmpty(Queue* pq);
// 销毁队列
void QueueDestroy(Queue* pq);
三、实现
1、初始化工作
老规矩,我们还是要先做好前期工作,将要用到的各种结构先定义一下:
// 重定义数据类型
typedef int QDataType;// 定义节点类型
typedef struct QueueNode {struct QueueNode* next;QDataType data;
} QueueNode;
因为我们在队列中定义了两个指针head和tail,所以为了方便我们就再定义一个队列的类型,将这两个指针放到一个类型里,方便操作和维护:
// 定义队列类型
typedef struct Queue {QueueNode* head;QueueNode* tail;
} Queue;
然后就是对队列进行初始化,我们先将head和tail置空:
// 队列的初始化
void QueueInit(Queue* pq) {assert(pq);pq->head = NULL;pq->tail = NULL;
}
2、入队
2.1、图解思路
因为我们选择的是使用单链表来实现队列,所以入队的操作就基本和单链表的尾插一样了。又因为我们记录了链表的尾,所以我们就不在需要在重头找尾了,直接创建一个新节点,然后将其连接在tail的后面即可:

而仅有的特殊情况就是当我们的队列为空时候,我们需要将入head指针和tail指针同时指向这个入队的新节点:

2.2、代码实现
// 队列的入队
void QueuePush(Queue* pq, QDataType x) {assert(pq);// 创建一个新节点QueueNode* newNode = (QueueNode*)malloc(sizeof(QueueNode));if (NULL == newNode) {perror("malloc fail!\n");exit(-1);}newNode->data = x;if (NULL == pq->head) {pq->head = newNode;pq->tail = newNode;pq->tail->next = NULL;}else {pq->tail->next = newNode;pq->tail = pq->tail->next;pq->tail->next = NULL;}
}
3、出队
3.1、图解思路
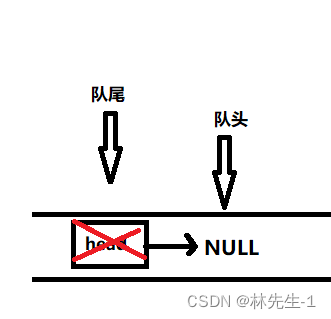
出队对应的就是单链表的头删,其操作和单链表的头删一样,我们先用一个next指针保存队头的下一个节点,然后再释放队头节点,最后再将head指向next即可:

然后还有一个特殊情况就是当出队出到队列为空的时候,根据上面的逻辑,头指针head是已经为空的了。但我们发现尾指针tail还没被处理,也就是说尾指针还指向这已被释放表的节点,这就会导致野指针了:
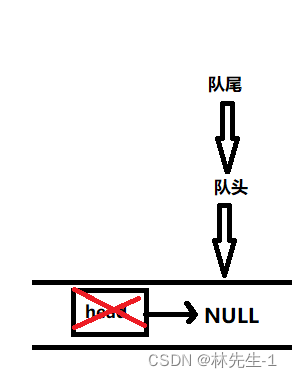
所以当我们把队列删空的时候也要将尾指针tail给置空:
3.2、代码实现
// 队列的出队
void QueuePop(Queue* pq) {assert(pq);assert(!QueueEmpty(pq));QueueNode* next = pq->head->next;free(pq->head);pq->head = next;// 如果对头为空了,我们也要把队尾也给置空,避免野指针if (NULL == pq->head) {pq->tail = NULL;}
}
4、打印队列(用于测试)
然后我们再写一个用于测试的打印函数,这其实就是在打印链表啦:
// 打印队列
void printQueue(Queue* pq) {assert(pq);QueueNode* cur = pq->head;while (cur) {printf("[%d]——", cur->data);cur = cur->next;}printf("NULL\n");
}
打印和测试效果如下:
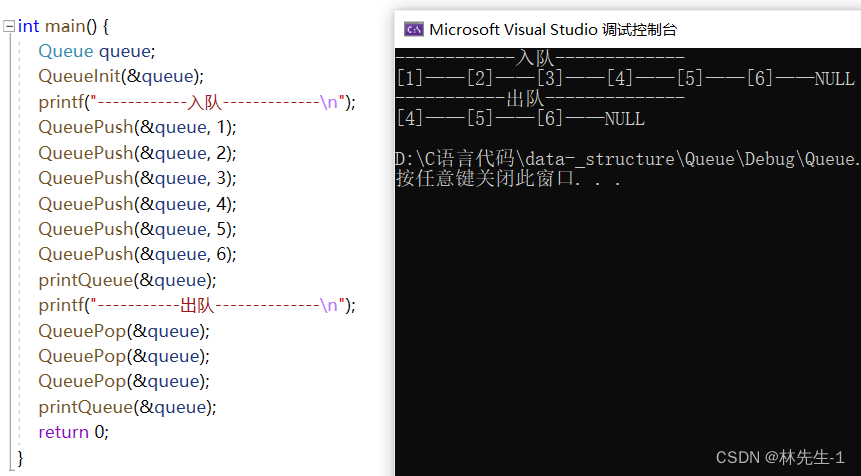
5、返回队头元素
这个其实就不用多说,如果队列不为空就直接返回即可:
// 返回队列的对头元素
QDataType QueueFront(Queue* pq) {assert(pq);assert(!QueueEmpty(pq));return pq->head->data;
}
6、返回队尾元素
这个也是一样:
// 返回队列的队尾元素
QDataType QueueBack(Queue* pq) {assert(pq);assert(!QueueEmpty(pq));return pq->tail->data;
}
7、返回队列中元素个数
对于队列中的元素个数,其实我们可以在定义队列类型的时候再额外定义一个size成员来记录当前队列中的元素个数,然后在我们执行入队和出队的时候相应的让size自加1或自减1。这样能省事不少:
// 定义队列类型
typedef struct Queue {QueueNode* head;QueueNode* tail;int size;
} Queue;
但是size这个属性好像在大多数情况下都用不到,所以若是单独再定义一个size好像有点怪怪的又好像有点多余,所以我们干脆就额外写一个函数来返回队列中的元素个数。
这个逻辑其实也很简单,就是遍历链表而已:
// 返回队列中的节点个数
int QueueSize(Queue* pq) {assert(pq);assert(!QueueEmpty(pq));QueueNode* cur = pq->head;int size = 0;while (cur) {size++;cur = cur->next;}return size;
}
8、判断队列是否为空
这个函数我们直接返回head是否等于空的判断结果即可:
// 判断队列是否为空
bool QueueEmpty(Queue* pq) {assert(pq);return pq->head == NULL;
}
9、销毁队列
销毁队列其实也就是销毁链表,这其实和销毁链表的逻辑是一样的,但我们最后还有注意也要讲head和tail给置空了:
// 销毁队列
void QueueDestroy(Queue* pq) {assert(pq);assert(!QueueEmpty(pq));QueueNode* cur = pq->head;QueueNode* next = cur->next;while (cur) {next = cur->next;free(cur);cur = next;}pq->head = NULL;pq->tail = NULL;
}