Steam游戏的爬取与分析
本文爬取了steam冒险类游戏中热销产品中的7500个游戏进行统计分析
1、首先要先知道网页链接的组成形式:

2、其次查看我们想要爬取的信息区域:
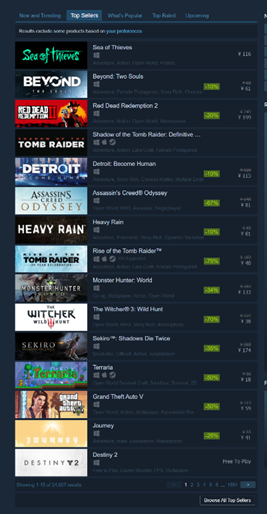
3、开始分析:
(1)、url的分析:
我们发现冒险类游戏的url:https://store.steampowered.com/tags/zh-cn/冒险当点击+页数的时候:


可以发现url尾部增加了: #p=1&tab=TopSellers
url变成了:https://store.steampowered.com/tags/zh-cn/冒险#p=1&tab=TopSellers
因此可以知道P代表页码,tab代表冒险类游戏中的游戏发布类型,此时url的组成已明了
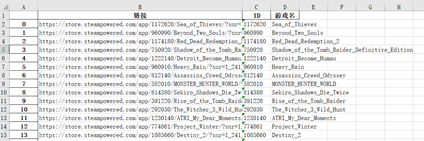
(2)、爬取游戏的网址、名字、编号:
1、首先先分析第一个游戏,我们发现游戏的链接信息中包含其名字、编号信息,所以我们可以通过获取其链接来提取其编号和名字信息。
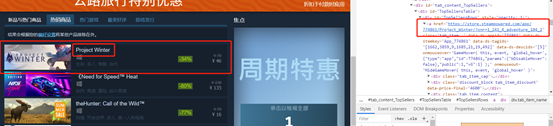
其次爬取翻页信息

但是从返回的网页信息中并没有发现其翻页数据

2、通过经验判断此处应该为js实现,但是js代码区经过了隐藏,所以不好下手,但是通过观察我们发现,通过搜索class=” paged_items_paging_controls”此处有五个结果,我们分析其中一个,发现他的命名方式和游戏的发布类型有相似之处,且告诉了每一页有15个数据,总共有936个数据,所以我们返回观察。
刚好页数就为936/15+1=63


3、开始爬取数据,在爬取数据的时候发现每次爬取的信息都永远是第一页的内容:说明此处steam平台动了小心思,我们接着通过抓包工具来进行分析。
当我们点击第二页的时候发现请求链接是,顺便点击第三页发现:
https://store.steampowered.com/contenthub/querypaginated/tags/NewReleases/render/?query=&start=15&count=15&cc=CN&l=schinese&v=4&tag=%E5%86%92%E9%99%A9
https://store.steampowered.com/contenthub/querypaginated/tags/NewReleases/render/?query=&start=30&count=15&cc=CN&l=schinese&v=4&tag=%E5%86%92%E9%99%A9
每次更改页数变化的是start的值,刚好是15的倍数,通过之前的分析,很容易知道这是翻页。 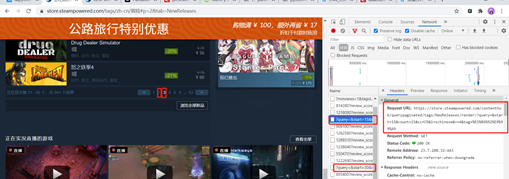
通过访问该链接,返回了一个字符串数据:

其中刚好有我们需要的链接消息,所以我们便可用正则匹配将我们需要的信息给提取出来。因此爬取模块代码:
import requests
import urllib
from selenium import webdriver
from bs4 import BeautifulSoup
from lxml import etree
import re
import random
import pandas as pd
from tqdm import tqdmheaders = [{'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'},{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'},{'User-Agent': 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'},{'User-Agent': 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0'},{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
]class steam_init(object):def __init__(self,name,announce):self.url = "https://store.steampowered.com/tags/zh-cn/" + nameself.headers = random.choice(headers)self.announce = announce#self.driver = webdriver.Chrome(executable_path='C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')def get_page(self):response = requests.get(self.url, self.headers)str = '<span id="' +self.announce + "_total" +'">(.*?)</span>'com = re.compile(str)result = re.findall(com, response.text)[0]result = re.sub(r',','',result)max_page = int( int( result ) / 15 ) + 1page_num = input("输入想要爬取的页数,当前商品列最大的页数为{}: ".format(max_page))return int(page_num)class steam_spider_request():def __init__(self,name,announce,page):self.headers = random.choice(headers)self.name = nameself.announce = announceself.page = pagedef get_spider(self):srclist = []IDlist = []namelist = []for page in tqdm(range(self.page)):url = 'https://store.steampowered.com/contenthub/querypaginated/tags/{0}/render/?query=&start={1}&count=15&cc=CN&l=schinese&v=4&tag={2}' \.format(self.announce, page * 15, self.name)html = requests.get(url, self.headers).textcom = re.compile('https://store.steampowered.com/app/(.*?)/(.*?)/')com1 = re.compile('href="(.*?)"')result = re.sub(r'\\', '', html)result = re.findall(com1, result)for dat in result:srclist.append(str(dat))IDlist.append(re.findall(com, str(dat))[0][0])namelist.append(re.findall(com, str(dat))[0][1])#print('已完成{}页的内容'.format(page))return srclist,IDlist,namelistdef save(self):srclist, IDlist, namelist = self.get_spider()df = pd.DataFrame(list(zip(srclist, IDlist, namelist)),columns=['链接', 'ID', '游戏名'])return dfif __name__ == '__main__':#rep_thread = ['rep1','rep2','rep3','rep4'] #处理线程num = ['NewReleases','TopSellers','ConcurrentUsers','TopRated','ComingSoon']game_type = input('输入想要爬取的游戏类型,例如:动作,射击…… ')game_type = urllib.parse.quote(game_type)game_anno = int(input('输入查询的货列编号:新品与热门商品1、热销商品2、热门游戏3、最受好评4、即将发行5 '))#获取最大页数,返回想要爬取的页数0steam = steam_init(game_type, num[game_anno-1])page = steam.get_page()#爬取规定页数的游戏基本信息path1 = 'first.xlsx'spider = steam_spider_request(game_type, num[game_anno-1],page)#spider.get_spider(page)save = spider.save()save.to_excel(path1)爬取信息:
(3)、通过访问游戏链接,获取游戏中的数据:
通过first.xlsx中爬取的链接信息,通过pandas中的apply方法来进行迭代访问。
首先先分析网页需要爬取的信息:

通过查看网页源码可以发现需要的信息都存在所以,此处就不需要分析太多直接通过xpath方法直接获取,并将获取的游戏信息保存到second.xlsx中。例如我们爬取好评率,通过xpath的方法:
所以第二部分代码:
def get_type(html):str = ' 'final_cost = html.xpath('//div[@class="glance_tags popular_tags"]/a')for i in final_cost[0:6]: #输出前6个标签str = str + i.text + ' 'return strdef clear(str):com = re.sub(r'\t|\r\n','',str)return comdef getdetail(x):#原价 现价 近评 全评 好评率 评价人数 游戏描述 游戏类型 发布时间 开发商original_cost ,final_cost,now_evaluate, all_evaluate, rate, people, des, type, time, deve= ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ',' ',' 'header = random.choice(headers)global counttry:html = requests.get(x['链接'], headers = header, timeout=10).textxml = etree.HTML(html)except:print('服务器1没响应,正在重新请求')try:html = requests.get(x['链接'], headers = header, timeout=10).textxml = etree.HTML(html)except:print('服务器2没响应,正在重新请求')try:html = requests.get(x['链接'], headers=header, timeout=10).textxml = etree.HTML(html)except:print('服务器没响应,直接进入下一个')#html = requests.get(x['链接'], headers=header, timeout=10).texttry:try:original_cost = xml.xpath('//div[@class="discount_prices"]/div[1]')[0].textfinal_cost = xml.xpath('//div[@class="discount_prices"]/div[2]')[0].textexcept:original_cost = xml.xpath('//div[@class="game_purchase_price price"]')[0].textoriginal_cost = clear(original_cost)final_cost = xml.xpath('//div[@class="game_purchase_price price"]')[0].textfinal_cost = clear(final_cost)try:now_evaluate = xml.xpath('//div[@class="summary column"]/span[1]')[0].textall_evaluate = xml.xpath('//div[@class="summary column"]/span[1]')[1].textrate = xml.xpath('//div[@class="user_reviews_summary_row"]/@data-tooltip-html')[0][:4]people = clear(xml.xpath('//div[@class="summary column"]/span[2]')[0].text)[1:-1]except:now_evaluate = "None"all_evaluate = xml.xpath('//div[@class="summary column"]/span[1]')[0].textrate = xml.xpath('//div[@class="user_reviews_summary_row"]/@data-tooltip-html')[0][:4]people = clear(xml.xpath('//div[@class="summary column"]/span[2]')[0].text)[1:-1]des = clear(xml.xpath('//div[@class="game_description_snippet"]')[0].text)type = get_type(xml)time = xml.xpath('//div[@class="date"]')[0].textdeve = xml.xpath('//div[@class="dev_row"]/div[2]/a[1]')[0].textexcept:print('第{}个游戏未完成检索'.format(count))count += 1return original_cost ,final_cost,now_evaluate, all_evaluate, rate, people, des, type, time, devedef info(path):df = pd.read_excel('./first.xlsx')df['详细'] = df.apply(lambda x: getdetail(x), axis=1)df['原价'] = df.apply(lambda x:x['详细'][0], axis=1)df['现价'] = df.apply(lambda x:x['详细'][1], axis=1)df['最近评价'] = df.apply(lambda x:x['详细'][2], axis=1)df['全部评价'] = df.apply(lambda x:x['详细'][3], axis=1)df['好评率'] = df.apply(lambda x:x['详细'][4], axis=1)df['评价人数'] = df.apply(lambda x:x['详细'][5], axis=1)df['游戏描述'] = df.apply(lambda x:x['详细'][6], axis=1)df['类型'] = df.apply(lambda x:x['详细'][7], axis=1)df['发行时间'] = df.apply(lambda x:x['详细'][8], axis=1)df['开发商'] = df.apply(lambda x:x['详细'][9], axis=1)df = df.drop('Unnamed: 0', axis=1) #删掉没用的数据df.to_excel(path)df.info()print('---检索完成---')if __name__ == '__main__':# 根据基本信息,爬取相应游戏的特有信息path2 = 'second.xlsx'info(path2)
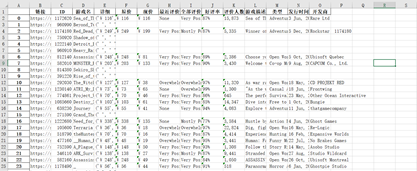
结果可以看到(注:虽然每个每个游戏的爬取方法都一致,但是存在有些游戏访问不到,可能由于是外网的原因,所以一些游戏访问的不到):
(4)、数据处理,由于使用的数据需要将其转化为一定的格式
价格的处理:由于有些游戏有打折,所以已现价为价格基础:
注:在实际爬取的过程中,大多数游戏有价格,但是有少部分游戏是 ‘免费游玩’,‘Free’甚至有一些是‘demo’,所以将这少部分同一转化为0元。通过爬取到的游戏价格我们发现在价格数字面前都存在‘¥’,所以我们通过鉴别第一个符号是否为‘¥’便可以完成价格的处理,最后用to_numeric()方法将其转化为int型
def deal_price(x):price = ' 'if(x['现价'][:1] != '¥' or x['现价'] == ' '):price = '0'else:price = re.sub(r'¥| |,','',x['现价'])return pricedf['price'] = df.apply(lambda x:deal_price(x), axis=1)
df['price'] = pd.to_numeric(df['price'])
好评率的处理:
注:每个游戏都存在评价,但是有些游戏的人数评价数量较少,所以被steam特殊处理为‘Need more user reviews to generate a scor’,其余的只需将最后的‘%’处理便可。
def deal_rate(x):rate = ' 'if(x['好评率'] == 'Need' or x['好评率'] == ' '):rate = '0'else:rate = re.sub(r'%| |o','',x['好评率'])return rate
df['好评率'] = df.apply(lambda x:deal_rate(x), axis=1)
df['好评率'] = pd.to_numeric(df['好评率'])
评价人数的处理:
注:此处和好评率的注意事项一致。
def deal_num(x):num = ' 'if x['评价人数'] == ' Need more user reviews to generate a scor' or x['评价人数'] == ' ':num = '0'else:num = re.sub(',','',x['评价人数'])return numdf['评价人数'] = df.apply(lambda x:deal_num(x), axis=1)
df['评价人数'] = pd.to_numeric(df['评价人数'])
游戏发布日期的处理:
注:目标需把爬取的日期需要将其转化为datatime格式,其次爬取的时间有极少部分只有年加月,所以同一将其日等于爬取月的一号。
def deal_year(x):mon = {'Jan':'1','Feb':'2','Mar':'3','Apr':'4','May':'5','Jun':'6','Jul':'7','Aug':'8','Sep':'9','Oct':'10','Nov':'11','Dec':'12'}year, month, day= ' ',' ',' 'if x['发行时间'] == ' ':year = '2000/1/1'else:year = x['发行时间'][-4:]if(x['发行时间'][0] >= '0'and x['发行时间'][0] <= '9' ):day = re.sub(' ', '', x['发行时间'][:2])month = mon[re.sub(r' |,', '', x['发行时间'][2:6])]else:day = '1'month = mon[x['发行时间'][:3]]year = year + '/' + month + '/' + dayreturn year
df['year'] = df.apply(lambda x:deal_year(x), axis=1)
接着打开保存的文件second_deal.xlsx先将日期的那一列全选(利用Ctrl+Shift+鼠标左键双击)

接着 点击数据->分列->下一步->下一步->日期->完成

最后通过info查看转换结果:

(5)、分析模块:
通过matplotlib库来进行分析:
分析:逐年游戏的好评度情况:
def show_first(df): #点图plt.rcParams['font.sans-serif'] = ['SimHei'] #设置字体为SimHei显示中文plt.rcParams['axes.unicode_minus'] = False #设置正常显示字符Y = df['price'] # 每一个点的Y值X = df['year']# 每一个点的X值plt.style.use('seaborn')#画布风格plt.rcParams['font.sans-serif']=['Microsoft YaHei']#字体plt.figure(figsize=(20, 5))#大小#这里散点大小是热销排行的倒数,也就是说越热销的游戏,圆点也就越大#颜色取决于好评率高低,colorbar也就是cmap选择'RdYlBu'风格plt.scatter(X,Y, s=15000/(df.index+200), c=df['好评率'], alpha=.9,cmap=plt.get_cmap('RdYlBu'))plt.colorbar().set_label('好评率',fontsize=20)'''#局部放大datenow = datetime.datetime(2021, 1, 1)dstart = datetime.datetime(2010, 1, 1)plt.xlim(dstart, datenow)plt.ylim(0, 500)'''plt.xlabel('年份',fontsize=20)plt.ylabel('价格',fontsize=20)plt.title('逐年该类型游戏的好评度情况')plt.show()
分析:每年的游戏的平均价格和好评度的曲线图:
def show_second(df): #曲线图 --统计的是每一年整年的游戏plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文plt.rcParams['axes.unicode_minus'] = False # 设置正常显示字符df_price = df.groupby('year')['price'].mean().to_frame().reset_index().sort_values(by='year') # 按年分组,求平均价格df_rate = df.groupby('year')['好评率'].mean().to_frame().reset_index().sort_values(by='year') # 按年分组,求平均好评率plt.figure(figsize=(20, 5))plt.plot(df_rate['year'], df_rate['好评率'], c='g', label='平均好评率%')plt.plot(df_price['year'], df_price['price'], c='c', label='平均价格')plt.xlabel('年份', fontsize=20)plt.legend()plt.title('年份与价格、好评率')datenow = datetime.datetime(2021, 1, 1)dstart = datetime.datetime(1980, 1, 1)plt.xlim(dstart, datenow)plt.ylim(0, 100)plt.show()
4、实验结果
本实验爬取了steam冒险游戏中的7500个游戏:
实验操作流程:
1、先运行steam.py获取first.xlsx第一张表:

2、运行specific_infomation.py获取second.xlsx第二张表:
3、运行deal_data.py获取second_deal.xlsx第三张表:
4、运行deal_show_info.py得到分析的游戏结果:
结果展示:




局部放大后:



可以发现随着年份的增加游戏的整体数量开始上升、其次整体质量十分优良,价格普遍都在100元以下,这也说明人人都可以消费得起。





