b站刘二大人《PyTorch深度学习实践》课程第七讲处理多维特征的输入笔记与代码:https://www.bilibili.com/video/BV1Y7411d7Ys?p=7&vd_source=b17f113d28933824d753a0915d5e3a90
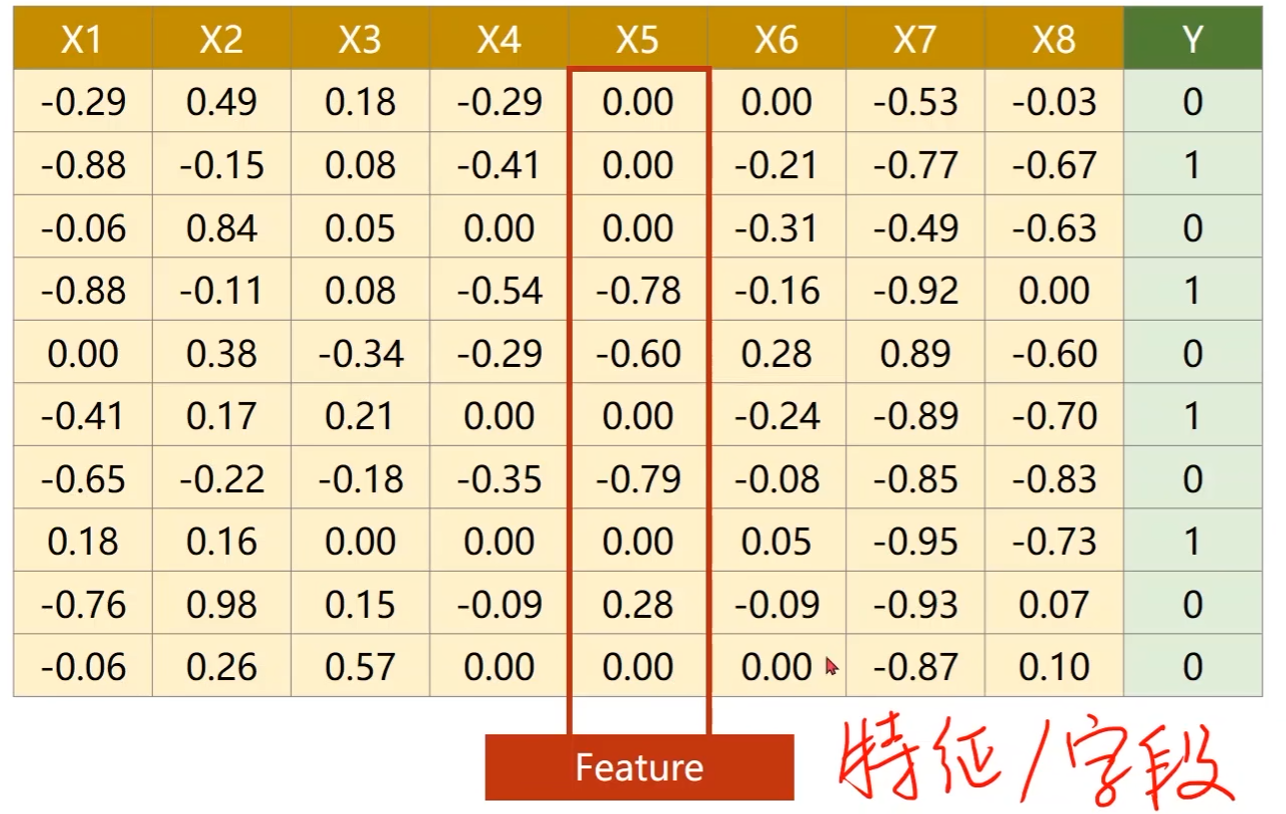
Diabetes Dataset
- 每一行是一个记录
- 每一列是一个特征,每个样本有8个特征
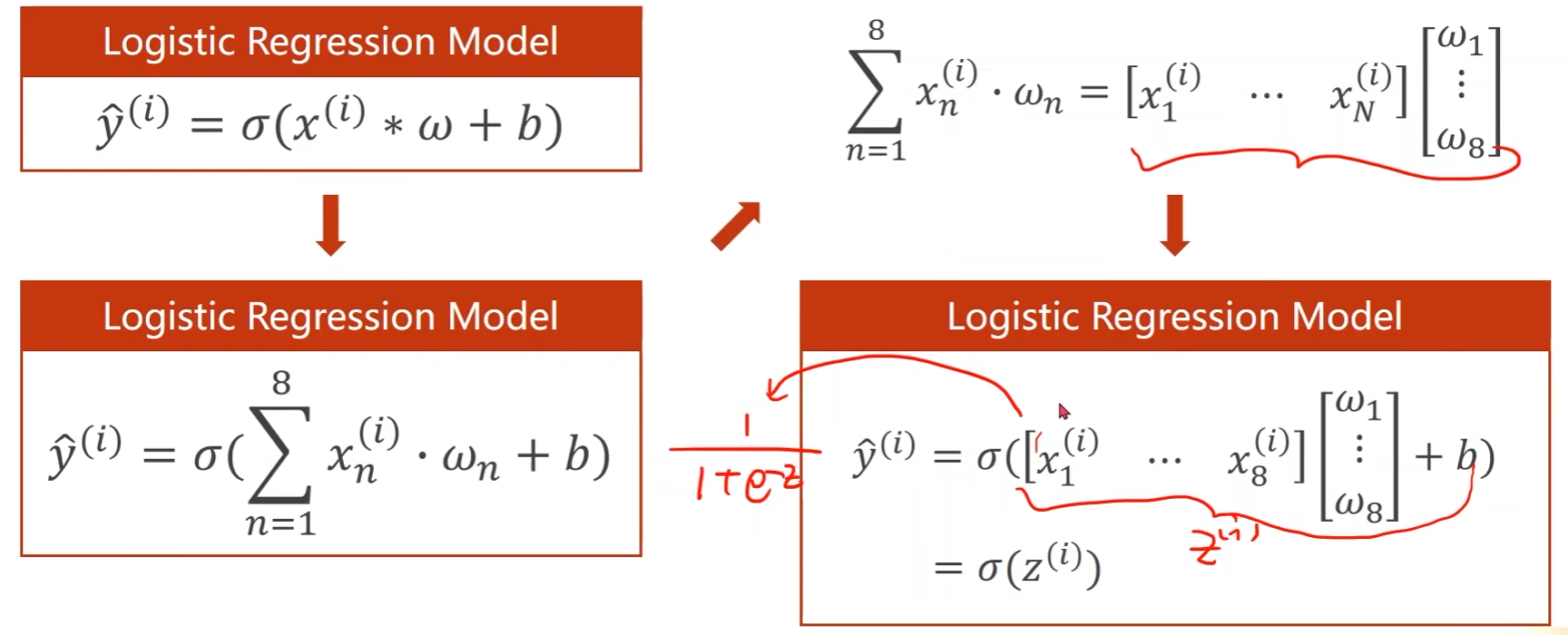
每个样本不再是一个特征,即模型输入变成了多维,那么就要将所有特征乘以相应的权重然后再累加起来
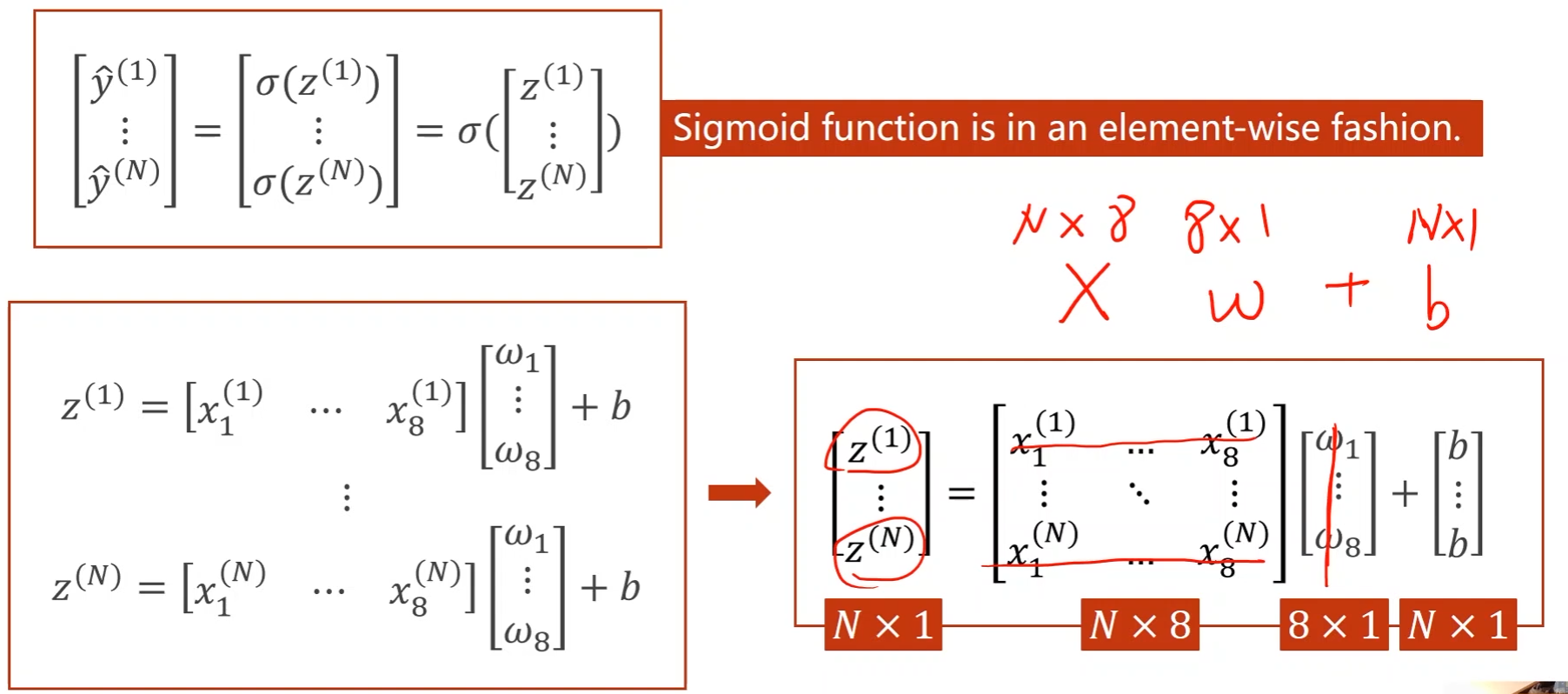
Mini-Batch(N samples):
-
向量化形式
- 可以用上并行计算

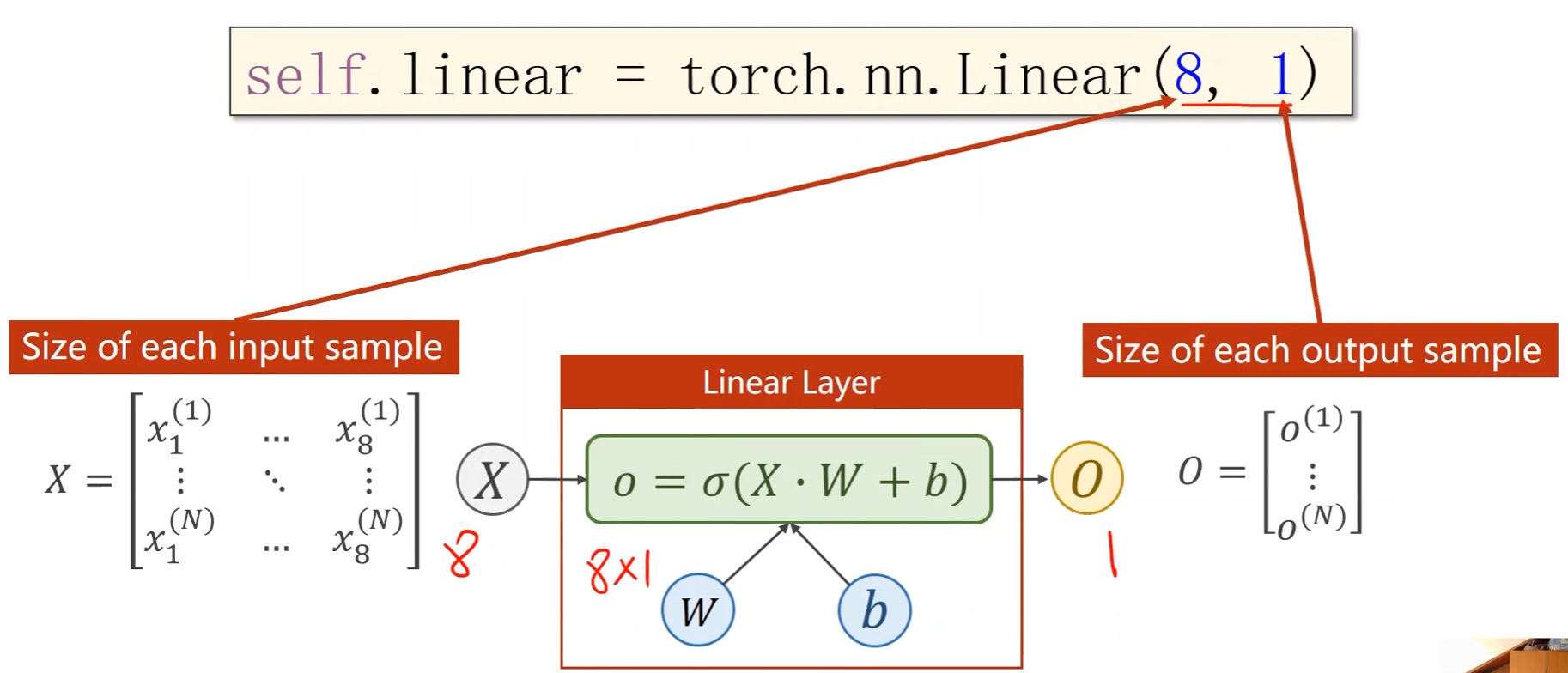
- Linear的第一个参数是输入特征数,第二个是输出特征数
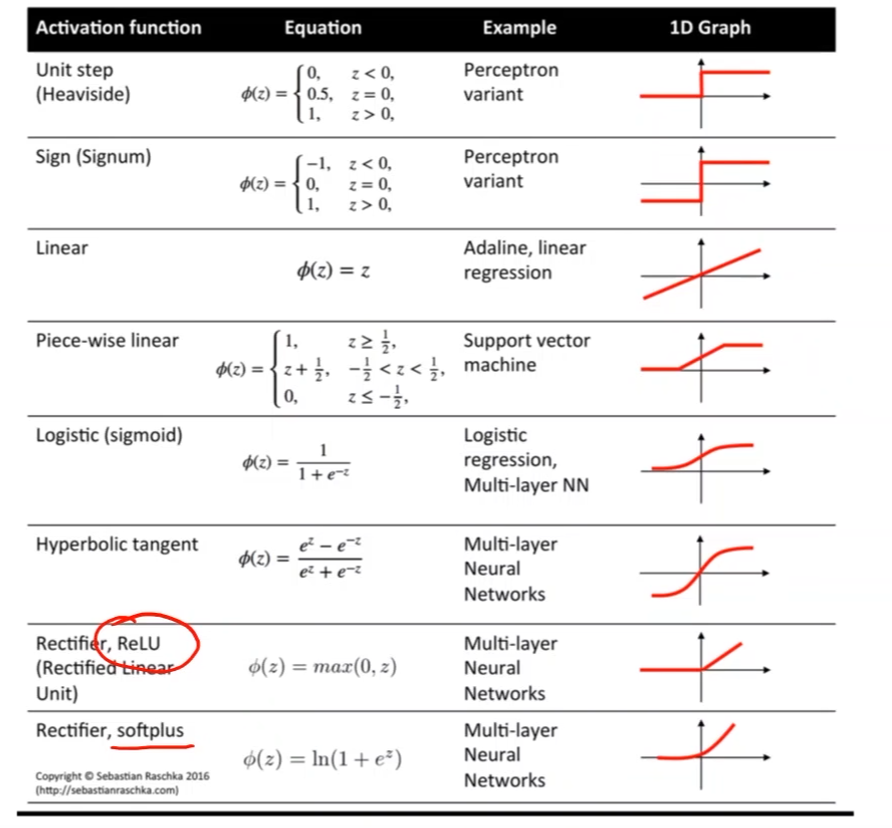
- 通过引入激活函数 σ \sigma σ,给线性变换增加非线性因子,这样就可以去拟合非线性变换
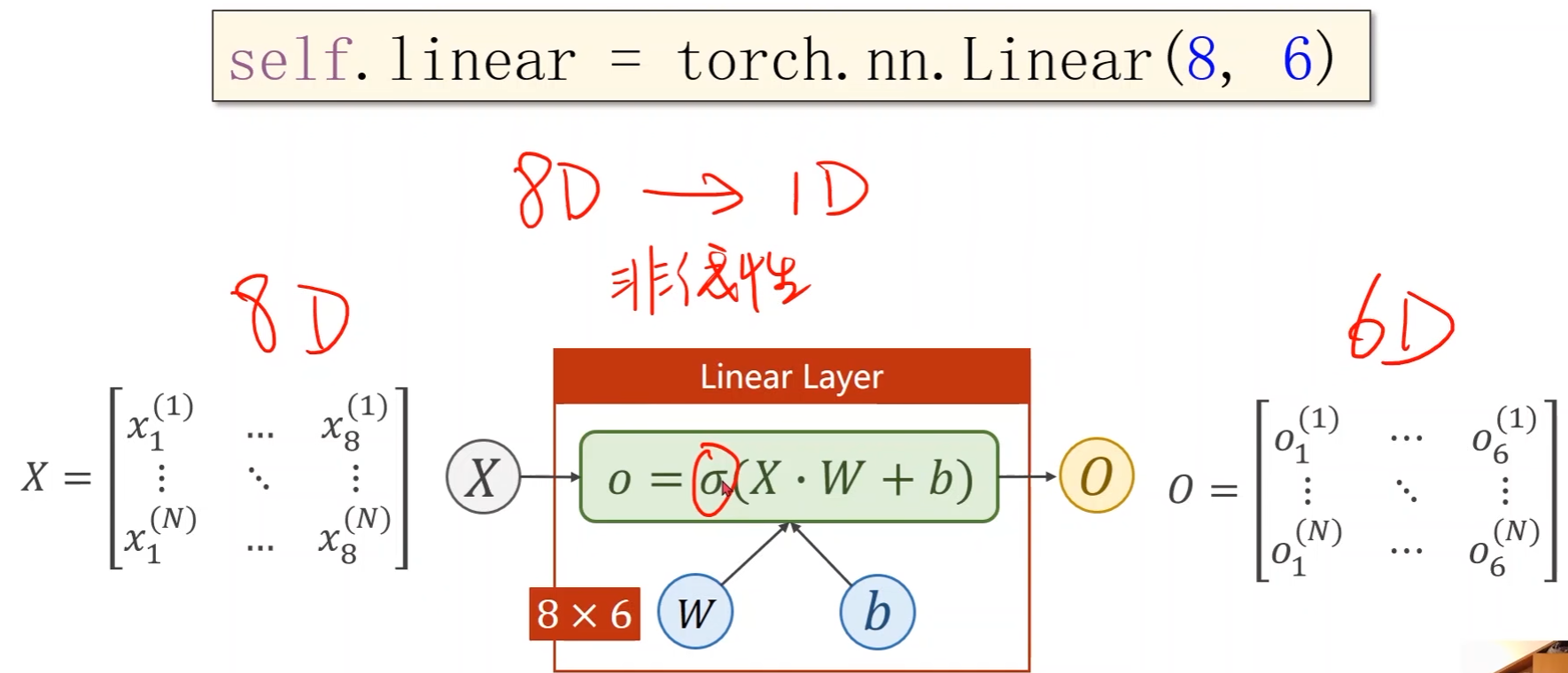
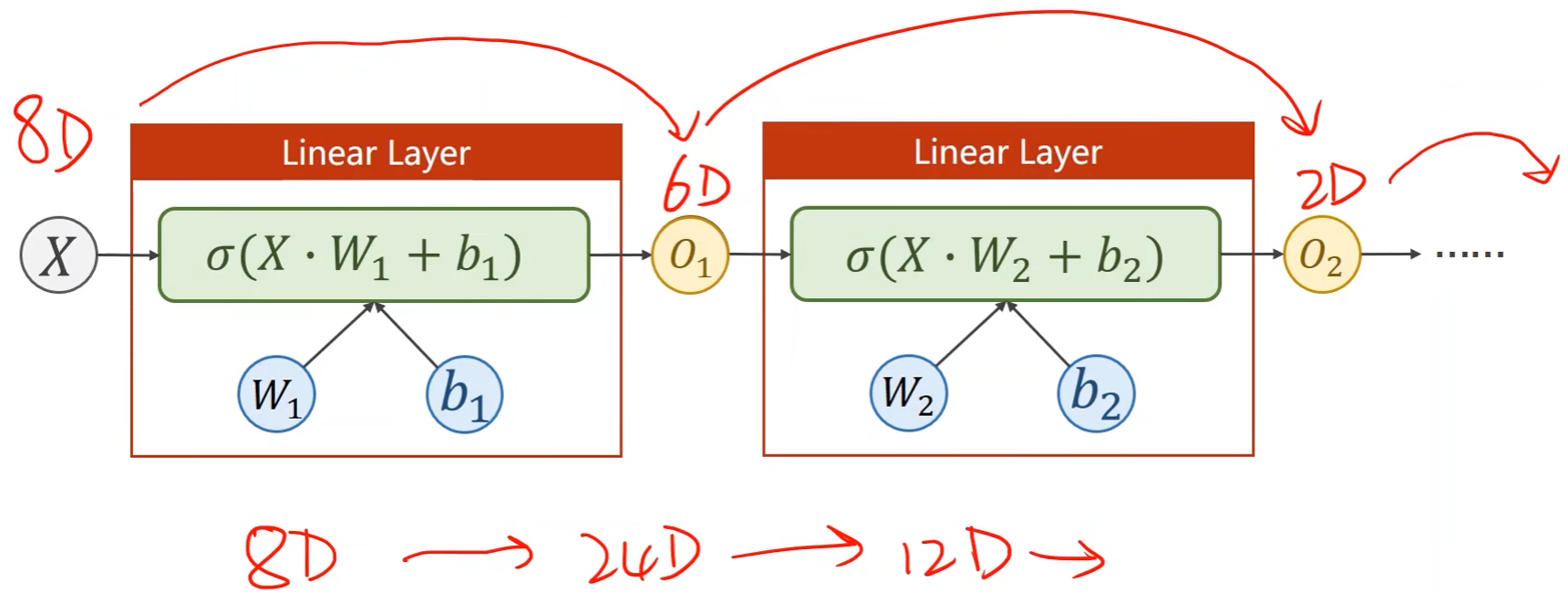
- 学习能力越强,有可能会把输入样本中噪声的规律也学到,而我们要学习的是数据本身真实数据的规律,因此关键的是模型的泛化能力
例子:Artificial Neural Network -> Diabetes Prediction
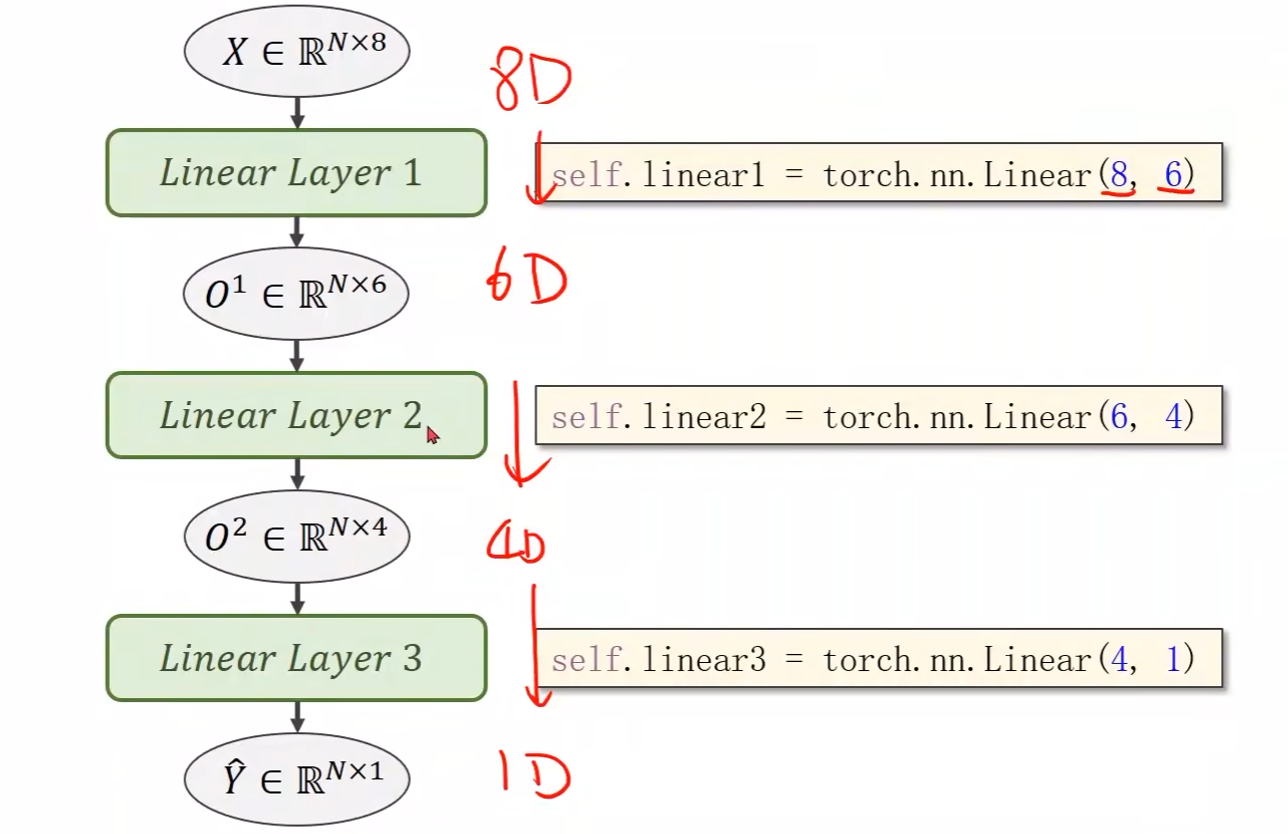
-
Prepare dataset:
import numpy as np import torchxy = np.loadtxt('dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32) # :表示所有行;:-1表示第一列开始,最后一列(-1)不要,最后一列是分类(这是输出) x_data = torch.from_numpy(xy[:, :-1]) # : 表示所有行;[-1]表示只要最后一列,加中括号意味着取出后是一个矩阵,不加则是向量 y_data = torch.from_numpy(xy[:, [-1]])数据集放到和源代码同一个存储目录下即可,代码目录是Liuer_lecturer,数据集放在Liuer_lecturer/dataset
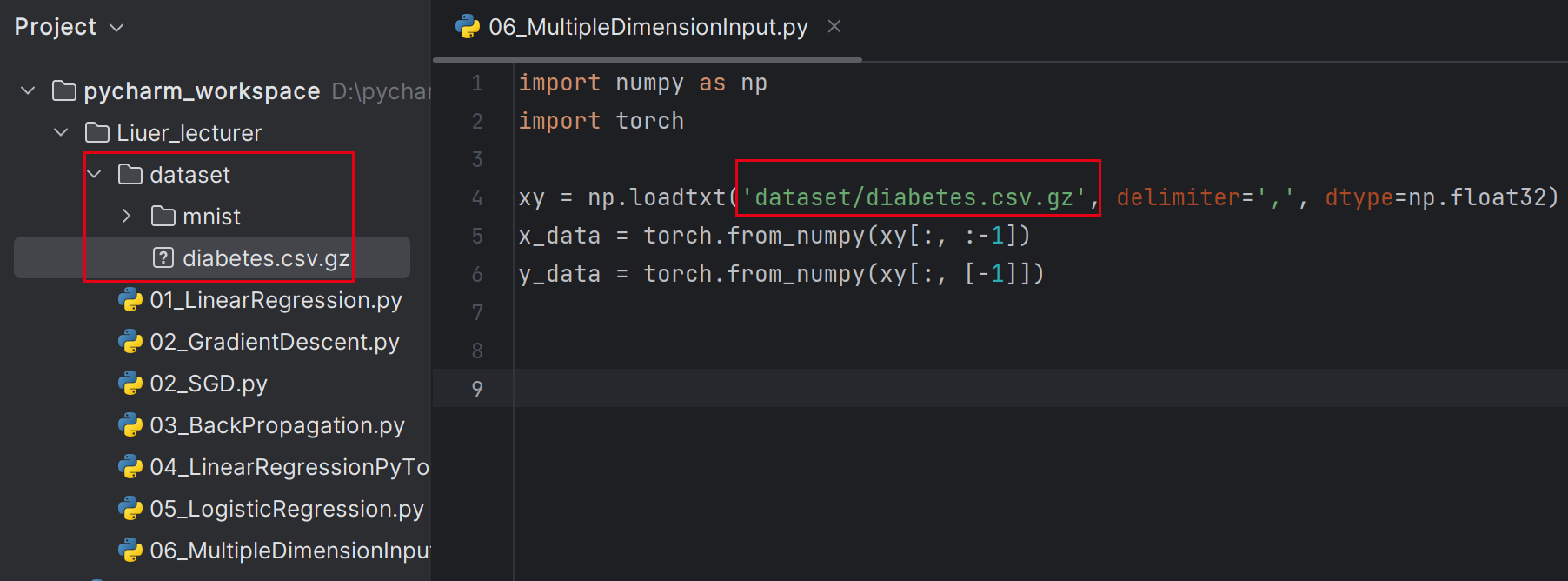
-
delimiter是分隔符;dtype是指定数据类型
- 用float32是因为常用的GPU(1080,2080等)中都只支持32位浮点数,因此在神经网络计算中通常使用32位浮点数
-
可以用print查看数据,如下是print(x_data)
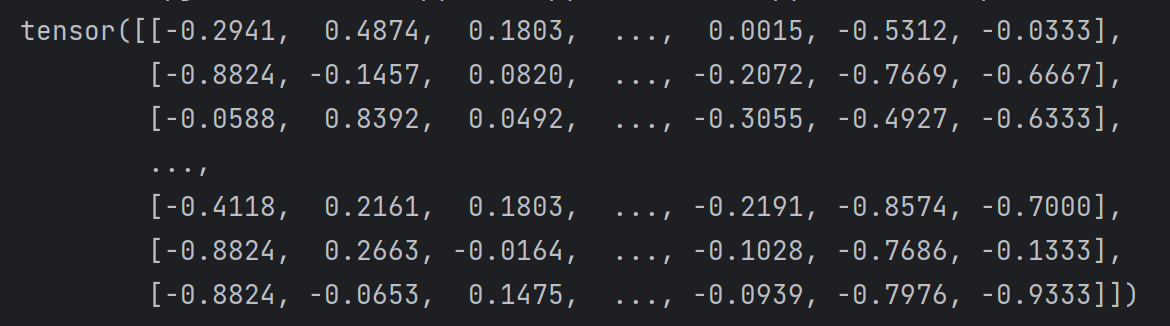
-
-
Design model using class:
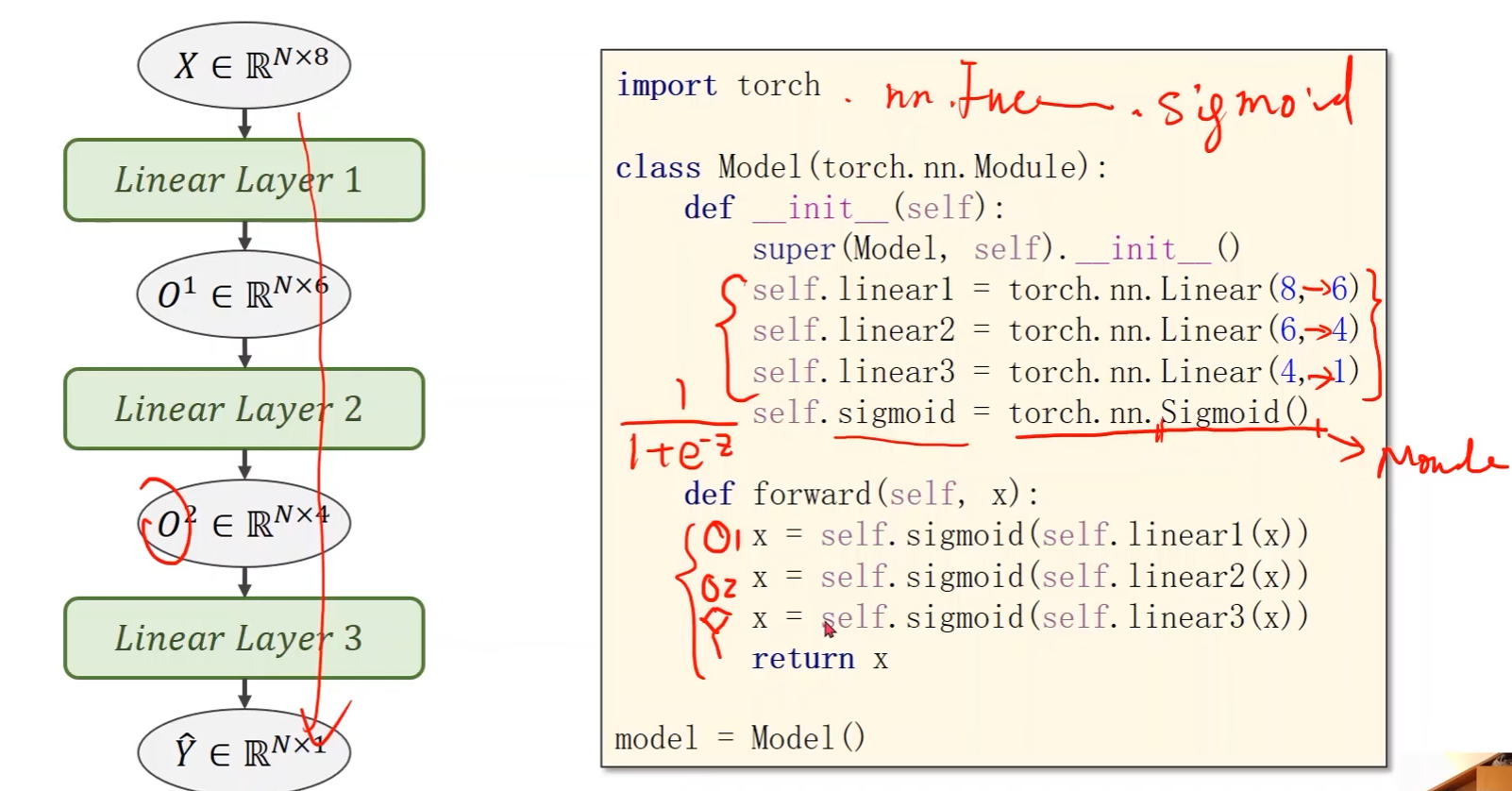
class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)# 激活函数# 之前的是调用torch.nn.Functional的sigmoid函数# 现在调用的是nn下的模块,把它当成一个层(运算模块)构建计算图self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model() -
Construct loss and optimizer:

# criterion = torch.nn.MSELoss(size_average=True) pytorch更新后被弃用了 criterion = torch.nn.BCELoss(reduction='mean') optimizer = torch.optim.SGD(model.parameters(), lr=0.01) -
Training cycle:

- 此处没做mini-batch,而是将全部数据放进去,mini-batch后续才讲
# 训练过程 for epoch in range(100):# 前馈y_pred = model(x_data) # 计算y_hatloss = criterion(y_pred, y_data) # 计算损失print(epoch, loss.item())# 反馈optimizer.zero_grad() # 在反向传播开始将上一轮的梯度归零loss.backward() # 反向传播(计算梯度)# 更新optimizer.step() # 更新权重w和偏置b
完整代码:
import torch
import numpy as np
import matplotlib.pyplot as plt# 建立数据集
xy = np.loadtxt('dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # :表示所有行;:-1表示第一列开始,最后一列(-1)不要,最后一列是分类(这是输出)
y_data = torch.from_numpy(xy[:, [-1]]) # : 表示所有行;[-1]表示只要最后一列,加中括号意味着取出后是一个矩阵,不加则是向量# 用于绘图
epoch_list = []
loss_list =[]# 定义模型
class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model()# criterion = torch.nn.MSELoss(size_average=True) pytorch更新后被弃用了
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练过程
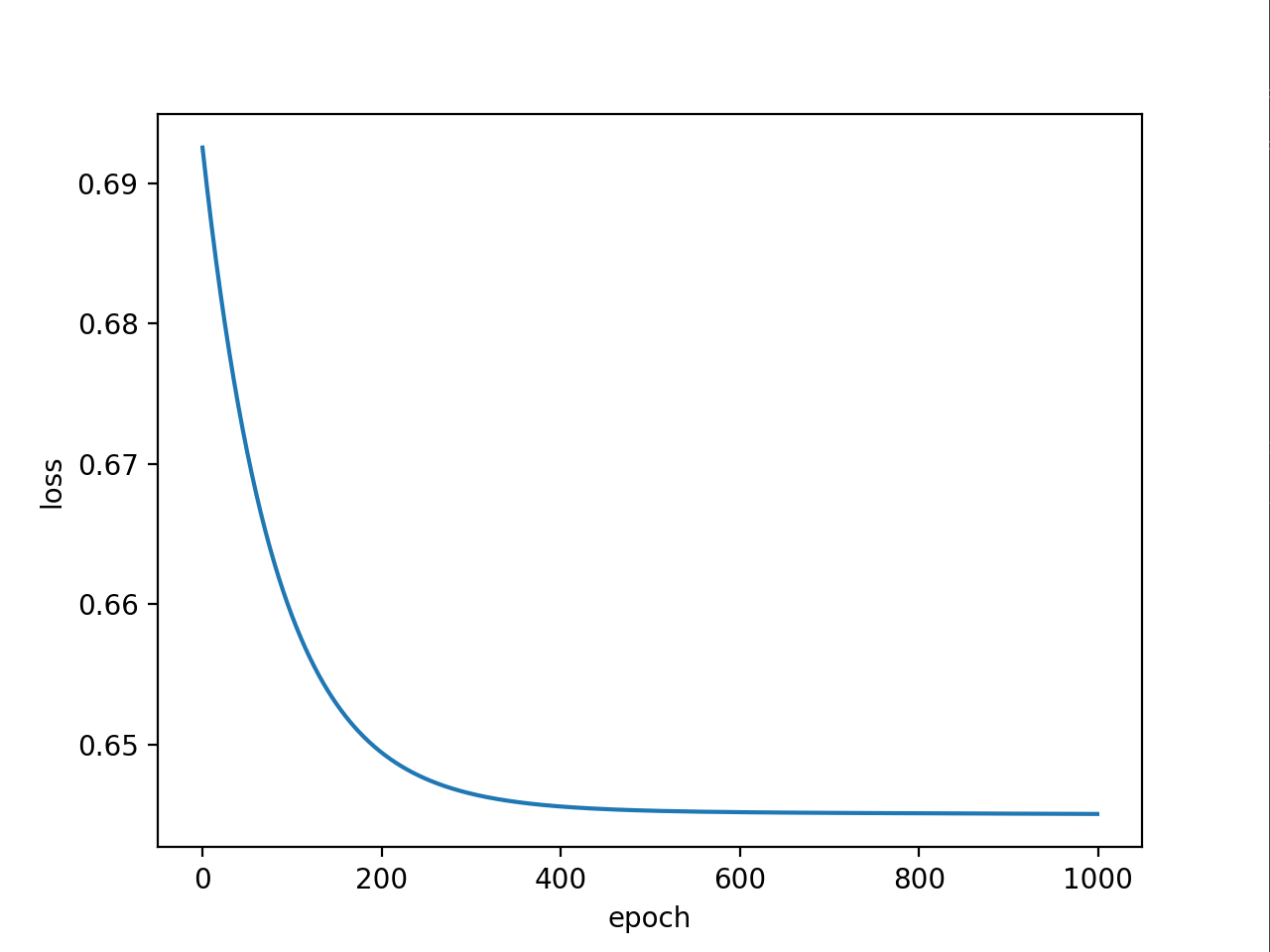
for epoch in range(1000):# 前馈y_pred = model(x_data) # 计算y_hatloss = criterion(y_pred, y_data) # 计算损失print(epoch, loss.item())epoch_list.append(epoch)loss_list.append(loss.item())# 反馈optimizer.zero_grad() # 在反向传播开始将上一轮的梯度归零loss.backward() # 反向传播(计算梯度)# 更新optimizer.step() # 更新权重w和偏置b# 绘制loss曲线
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()