一、 开源玄铁C910简介
玄铁C910是由平头哥设计并开源的高性能CPU,基于开源的RISC-V指令集,主要面向对性能要求严格的边缘计算领域,如边缘服务器、边缘计算卡、高端机器视觉、高端视频监控、自动驾驶、移动智能终端、5G 基站等。
玄铁C910主要特点如下:
同构多核架构,支持双核;(开源版本为双核,预留四核接口)
• 支持各个核心独立下电以及cluster 下电;
• 支持1 个AXI4.0 Master 接口,128 比特的总线宽度;
• 两级cache结构,哈佛结构L1cache(Icache、Dcache)和共享的L2cache;
• L1cache支持MESI 的一致性协议,L2cache支持MOESI 的一致性协议;
• 支持RISC-V私有中断控制器CLINT 和平台级中断控制器PLIC;
• 支持自定义且接口兼容RISC-V 的多核调试框架;
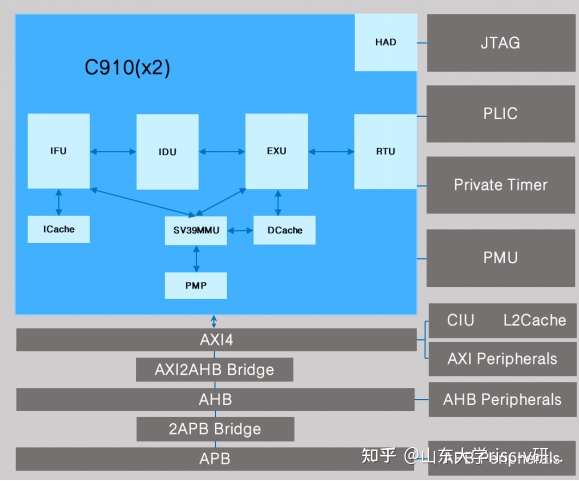
图1:SOC架构图
二、 模块简介
1、 IFU
• IFU为玄铁C910中的取指模块,包括三级流水线IF、IP、IB。IFU中主要完成指令从icache中取指、分支预测、预译码以及发送给IDU的功能。包括L0BTB, BTB(Branch Target Buffer, 分支目标缓冲器)、BHT(Branch History Table, 分支历史表)、Lbuf(Loop Buffer,短循环加速器)、IndBTB(Indirect BTB, 间接跳转目标缓冲器)、 RAS(Return Address Stack, 返回地址堆栈)等功能部件。
2、IDU
• IDU为玄铁C910中的译码模块,包括四级流水线ID、IR、IS、RF。IDU主要完成指令的译码、预派遣、寄存器重命名、指令派遣等功能。在IDU中RISC-V指令会被译码成微操作,在完成寄存器重命名后,派遣到七条发射管道中。
3、IU
• IU为玄铁C910中的执行模块,主要分为ALU、BJU、MUL、DIV四个部分,分别处理算数运算、跳转运算、乘法运算、除法运算等。各执行模块流水级长度不同,ALU为单周期,其他单元为多周期。IU负责将IDU的RF级发射的指令执行完毕,并完成指令的complete判断。
4、LSU
• LSU为玄铁C910中load/store单元,主要负责数据存储/加载。Load/store分别有一条流水线,支持load、store 指令双发射、全乱序执行。访存流水线分为AG(Address generation)、DC(Data cache)、DA(Data align)、WB(Write back)四个流水级,LSU中主要包括数据预取单元,从dcache中存取数据以及维护多核数据状态等。
5、RTU
• RTU是玄铁C910中负责指令退休单元,主要为ROB和指令retire的逻辑以及物理寄存器堆、异常寄存器堆等。玄铁C910支持指令快速退休机制,将指令的退休划分为complete、retire两个过程。
6、MMU
• MMU是玄铁C910中负责内存管理的单元,主要完成内存地址的虚实转换,RISC-V SV39标准。MMU中包括两级TLB(Translation Look-aside Buffer),用于缓存最近使用过的页表。
7、BIU
• BIU是玄铁C910的核内总线,支持AMBA4.0 AXI协议,有8个通道。不同单元通过各种事务类型访问总线。对于多核数据一致性,玄铁C910通过 snoop方式维护。
8、CIU
• CIU是玄铁C910核外负责处理多核数据一致性的单元,负责处理器核心和L2cache之间数据存取。L2cache大小可配置,大小128KB/256KB/512KB/1MB,为16路组相连结构,cacheline大小为64Byte。内存与Cache的组之间采用直接映射,而组内采用全相联映射。L2cache data 每一路4个bank,每行的64byte=512位,index为13位,每个bank1个index,索引具体在哪一行里,每128位为一个bank,通过gwen写使能。
三、 主要研究方向
基于玄铁C910的三译码八执行的微架构,对内部微架构进行修改,主要涉及内容如下:

1. 玄铁C910取值模块从ICACHE中取指为128的取指宽度,最多支持每周期取出4条RISC-V(32bit)指令,
当流水线中出现4条指令全部有效的情况时,指令会暂存到指令buffer中,再从buffer中pop出三条指令,优化后可以减少buffer表项数,提高IFU-IDU的效率。
2.三组译码器设计,每周期最多可以译码出4条uop
对于split_long类型的指令,只有原子指令集一种,而原子指令集每条指令可以分解出1~5条微操作,扩展成5uop可以在单周期内处理完原子指令。扩展成四译码5uop的设计可以扩充数据流宽度。
3.现有架构为八路执行,七个发射队列,每个指令发射队列有8/12个表项,表项利用率偏低
每个队列为两写入一写出端口,单周期写入更多指令可以提高表项利用率。 增加指令发射的数量可以提高执行级的利用效率,提高CPU的IPC,达到性能提升的效果。
4. 玄铁C910为4uop重命名的结构,有64个ROB表项,表项利用率低
ROB表项的利用率一定程度上体现了CPU的乱序能力。
根据测试结果,玄铁C910中ROB表项占用率在高负载测试环境下也最多占用20~30个表项。例如INTEL的12代CORE I7 ,包括500多个ROB表项,而玄铁C910中含有64个ROB表项,原有设计中64个表项利用率偏低。ROB的表项的读写占用面积和时序都很大,因此提高ROB表项的利用率可以更好的发挥CPU性能。提高指令重命名数量后,指令的乱序发射能力会提高,更多的指令会进入执行级中。加入指令快速退休机制后,可以更快的完成指令的complete和retire。对增加的一条uop扩展指令fold机制,可以占用更少的ROB表项。
四、 专栏后期规划
本专栏主要记录山东大学周莉教授课题组对开源玄铁C910的代码理解和架构分析,以及架构修改等内容。后续文章将介绍我们对流水线各模块具体介绍及分析,以及修改架构内容等。