图片来源:网络
作者
XksA
来源
CSDN
如需转载,请联系原作者授权
前言 ▍
这是一篇技术文,但又不是一篇技术文,今天分享的是,当笔者获取了微信小程序英文取名的3500多个微信用户昵称、年龄段后,分析得到下面结果。
Let's get it
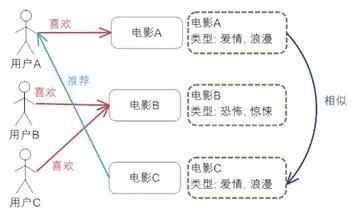
1.基本信息获取
访问英文取名的用户基本信息接口,获取英文取名用户微信名(Nick names)、访问次数(Count)、总数据集(Response data),并将微信名存入文件。
# 获取所有用户数量和相关信息
def get_json():
# 获取入口
search_url = '英文取名用户接口,欢迎扫码使用英文取名,生成一个最适合你的英文名'
# 发送http请求,获取请求页面
search_response = requests.get(search_url)
# 设置编码
search_response.encoding = 'UTF-8'
# 将页面转变成json代码格式
search_json = search_response.json()
# 获取我们需要的数据,是列表格式
our_data = search_json['ResponseData']
list_len = len(our_data)
print('总用户数有:' + str(list_len))
user_visit_numbers = 0
data_research = 0
NickName = []
for x in our_data:
user_numbers = x['Count'] + user_visit_numbers
if x['NickName'] == '':
data_research += 1
NickName.append(x['NickName'])
print("微信名获取失败量:"+str(data_research))
print(NickName)
name = ['微信名称']
file_test = pd.DataFrame(columns=name, data=NickName)
file_test.to_csv(r'I:/data.csv', encoding='utf-8',index=False)
print('总访问量:' + str(user_visit_numbers))运行结果:
总用户数有:3549
微信名获取失败量:0
总访问量:45732.读取所有微信名,数据分类
(1)读取微信名
# 读取文件,取出微信名
def get_name():
NickName = []
with open('I:/data.csv','r',encoding='utf8') as file :
i = 0
for line in file:
if i == 0: # 去除表头
i = 1
continue
line = line.strip() # 去除换行符
NickName.append(line)
return NickName(2)数据分为以下六大类
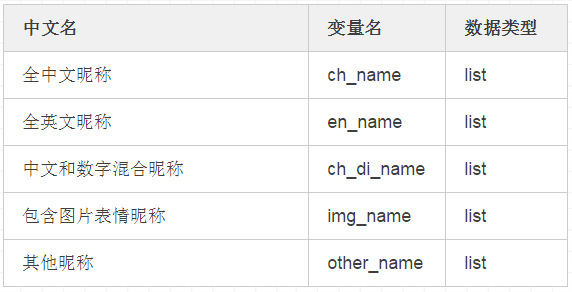
# ch :Chinese
ch_name_number = 0
ch_name = []
# en :English
en_name_number = 0
en_name = []
# di : digtal
di_name_number = 0
di_name = []
# img : image
img_name_number = 0
img_name = []
# ch_di : Chinese and digtal
ch_di_name = []
# other : other
oth_name_number = 0
oth_name = []
(3)数据分类判断
# 昵称全中文判断
def is_all_ch(keyword):
for c in keyword:
# 包含常见中文字符
if not ('\u4e00' <= c <= '\u9fa5'):
return False
return True
# 昵称全英文判断
def is_all_en(keyword):
# 不能全部为空格或者首位为空格
if all(ord(c) == 32 for c in keyword) or keyword[0] == ' ':
return False
# 允许空格和英文并存(例如:Xist A)
if not all(65 < ord(c) < 128 or ord(c) == 32 for c in keyword):
return False
return True
# 昵称全数字判断
def is_all_di(keyword):
for uchar in keyword:
if not (uchar >= '\u0030' and uchar <= u'\u0039'):
return False
return True
# 昵称包含表情图判断
def have_img(keyword):
# 下面是大部分图片的一个unicode编码集
# 详情查看:https://en.wikipedia.org/wiki/Emoji
img_re = re.compile(u'['
u'\U0001F300-\U0001F64F'
u'\U0001F680-\U0001F6FF'
u'\u2600-\u2B55]+',
re.UNICODE)
if img_re.findall(keyword) :
return True
return False
# 中文+数字昵称判断
def is_ch_di(keyword):
for c in keyword:
if not ('\u4e00' <= c <= '\u9fa5') and not (c >= '\u0030' and c <= u'\u0039'):
return False
return True
(4)数据归类计算各类数量
list_name = get_name()
print("总共有:"+str(len(list_name))+"个微信名")
for i in range(len(list_name)):
result = classification_name(list_name[i])
if result == 'ch': # 中文
ch_name_number +=1
ch_name.append(list_name[i])
if result == 'en': # 英文
en_name_number +=1
en_name.append(list_name[i])
if result == 'di': # 数字
di_name_number +=1
di_name.append(list_name[i])
if result == 'img': # 含表情
img_name_number +=1
img_name.append(list_name[i])
if result == 'ch_di': # 中文和数字
ch_di_name_number +=1
ch_di_name.append(list_name[i])
if result == 'other': # 其他
oth_name_number +=1
oth_name.append(list_name[i])
print("纯中文昵称个数:"+ str(ch_name_number))
# print(ch_name)
print("纯英文昵称个数:"+ str(en_name_number))
#print(en_name)
print("纯数字昵称个数:"+ str(di_name_number))
# print(di_name)
print("包含表情图昵称个数:"+ str(img_name_number))
# print(img_name)
print("中文和数字混合昵称个数:"+ str(ch_di_name_number))
print(ch_di_name)
print("其他昵称个数:"+ str(oth_name_number))
# print(oth_name)运行结果:
总共有:3549个微信名
纯中文昵称个数:1514
纯英文昵称个数:569
纯数字昵称个数:9
包含表情图昵称个数:400
中文和数字混合昵称个数:19
其他昵称个数:10383.获取用户画(只获取用户年龄段)
访问英文取名用户画像接口,获取近30天活跃用户和新用户的年龄段。
# 获取用户年龄段
def get_data():
# 获取token,并处理
t = get_token().strip('"')
# 然后将处理后的token值和其他参数作为post方式的参数值,调用用户画像api
post_user_api = " https://api.weixin.qq.com/datacube/getweanalysisappiduserportrait?access_token="
post_user_url = post_user_api + t
# 访问获取概况数据 (近一个月的数据情况)
data = json.dumps({
"begin_date" : "2018-07-21",
"end_date" : "2018-08-19"})
# 获取信息
user_portrait_data = get_info(post_user_url, data)
# 时间段
ref_date = user_portrait_data['ref_date']
# 新用户
visit_uv_new = user_portrait_data['visit_uv_new']
活跃用户
visit_uv = user_portrait_data['visit_uv']
# 年龄段
print(ref_date )
print((visit_uv_new['ages']))
print((visit_uv['ages']))
运行结果:
# id : 为年龄段序号 name :年龄段名称 value : 该年龄段人数
20180721-20180819
[{'id': 0, 'name': '未知', 'value': 6}, {'id': 1, 'name': '17岁以下', 'value': 18}, {'id': 2, 'name': '18-24岁', 'value': 118}, {'id': 3, 'name': '25-29岁', 'value': 75}, {'id': 4, 'name': '30-39岁', 'value': 81}, {'id': 5, 'name': '40-49岁', 'value': 14}, {'id': 6, 'name': '50岁以上', 'value': 7}]
[{'id': 0, 'name': '未知', 'value': 6}, {'id': 1, 'name': '17岁以下', 'value': 20}, {'id': 2, 'name': '18-24岁', 'value': 147}, {'id': 3, 'name': '25-29岁', 'value': 88}, {'id': 4, 'name': '30-39岁', 'value': 95}, {'id': 5, 'name': '40-49岁', 'value': 20}, {'id': 6, 'name': '50岁以上', 'value': 10}]
来点有趣的:数据清洗、分析
1.微信名称类型数据可视化分析
核心代码:
# 1.微信名分类:玫瑰饼图
from pyecharts import Pie
# 数据获取自上面代码
attr = ["纯中文昵称", "纯英文昵称", "纯数字昵称", "包含表情图昵称", "中文和数字混合昵称", "其他昵称"]
v1 = [1514, 569, 9, 400, 19, 1038]
pie = Pie("微信名分类饼图", title_pos='center', width=900)
pie.add(
"占比",
attr,
v1,
center=[50, 50],
is_random=True,
radius=[30, 75],
rosetype="area",
is_legend_show=False,
is_label_show=True,
)
pie.render("render_01.html")
运行效果:
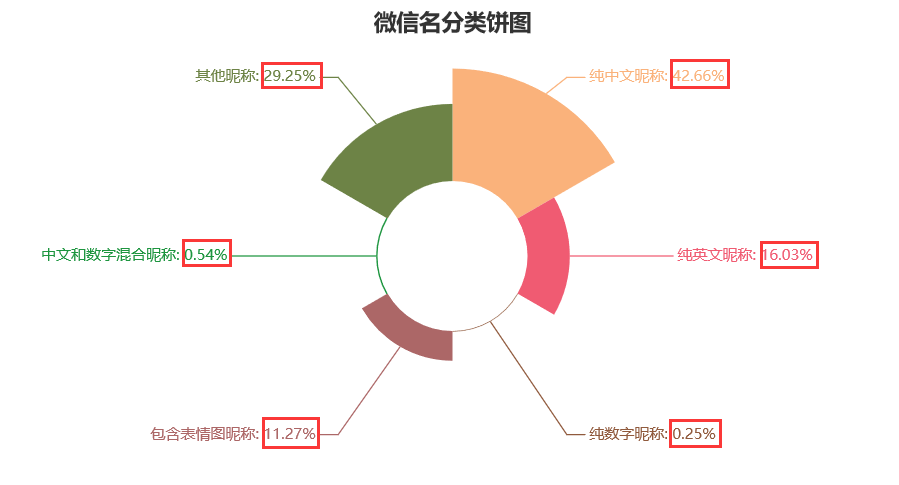
微信昵称类别玫瑰饼图
从中可以看出,微信昵称为全中文的占比最多,占有42.66%,其次为其他昵称(中英文混合、字符等类型),占有29.25%。
再比较大的类,就是纯英文昵称,占有16.03%,以及包含表情包昵称的,占有11.27%,纯数字昵称和中文数字混合昵称,相对占比较少。
我们常见的中文和数字混合昵称,最多的就是机构名/姓名+联系方式,一些营销号比较常用。
相较而言,大多数人还是喜欢,用纯中文来作昵称,既体现一种文化情怀,又简明扼要地介绍了自己 ,比如我的微信名就是老表,这是我初中时候的一个绰号,朋友们一说老表,不一定是在说亲戚,有可能在说我,哈哈哈。
2.微信用户年龄段可视化分析
核心代码:
# 2.用户年龄段:玫瑰饼图
from pyecharts import Pie
# 数据获取自上面代码
attr = ["未知", "17岁以下", "18-24岁", "25-29岁", "30-39岁", "40-49岁","50岁以上"]
v1 = [12, 38, 265, 163, 176, 34,17]
pie = Pie("微信用户年龄段饼图", title_pos='center', width=900)
pie.add(
"占比",
attr,
v1,
center=[50, 50],
is_random=True,
radius=[30, 75],
rosetype="area",
is_legend_show=False,
is_label_show=True,
)
pie.render("render_02.html")
运行效果:
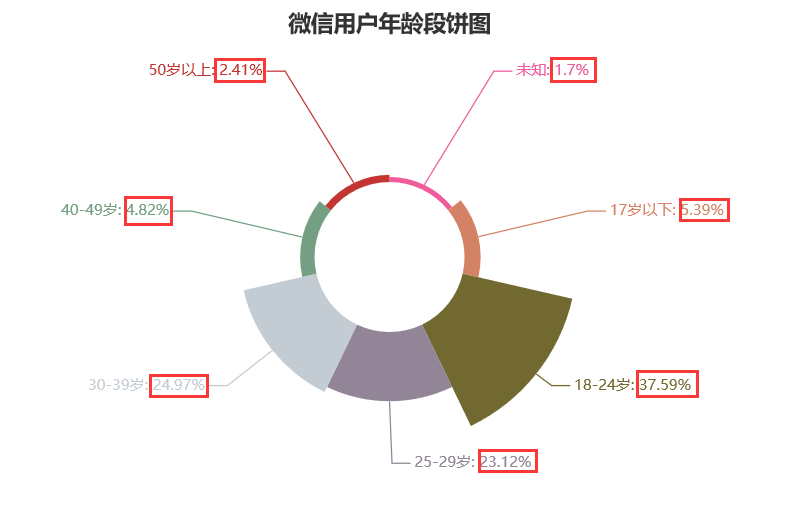
用户年龄段分布玫瑰饼图
从中可以看出,年龄段中,18-24岁的95-00后占比最多,达到37.59%,接下来是30-39岁的80-90后,占比达到24.97%,紧随其后的为25-29岁的90-95后,占比达23.12%,其他年龄段可大概分为两类:偏儿童类和偏老人类,一共占比10.21%。
我个人觉得,这类人群少的原因是:小孩、老人玩微信的少,更不用说微信小程序了,对于小孩来说,微信的作用就是玩游戏(登录账号),对于老人来说,微信主要用来聊天,已经是比较复杂的了,小程序使用可能对老人来说就更复杂了,也缺少必要性。
3.词云分析微信名称哪些词语、表情包更受欢迎?
(1)继续使用pyecharts生成词云图
核心代码:
# 清洗数据,生成词云图
def split_word(test_str):
test_str = re.sub('[,,。. \r\n]', '', test_str)
# jieba 词语
segment = jieba.lcut(test_str)
words_df = pd.DataFrame({'segment': segment})
# quoting=3 表示stopwords.txt里的内容全部不引用
stopwords = pd.read_csv(r"H:\PyCoding\ Analysis_wx_name\stopwords.txt", index_col=False, quoting=3, sep="\t", names=['stopword'], encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
test = words_stat.head(200).values
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("微信昵称", codes, counts, word_size_range=[20, 100])
wordcloud.render('render_03.html')
运行效果:

pyecharts词云图
4.使用Wordcloud+matplotlib,生成高级一点的词云图:
核心代码:
# 下下期好好讲一下matplotlib绘图可视化,挺有意思的
# 调用get_name函数获取全部微信名
text = get_name()
# 调用jiebaclearText函数,清洗数据(该函数和上面切词思想一样)
text1=jiebaclearText(text)
#产生词云图
bg = plt.imread(r"G:\small_pig.jpg")
#生成词云
wc=WordCloud(
background_color="wathet", #设置背景为白色,默认为黑色
mask=bg, # 设置词云内容范围(除指定图片白色区域的其他区域都将覆盖词云内容)
margin=10, #设置图片的边缘
max_font_size=70, #显示的最大的字体大小
random_state=20, #为每个单词返回一个PIL颜色
font_path='G:\simkai.ttf' #中文处理,用系统自带的字体
# 可以在这里下载这个字体:http://www.font5.com.cn/font_download.php?id=534&part=1245067666
).generate(text1)
#为图片设置字体
my_font=fm.FontProperties(fname='G:\simkai.ttf')
# 图片背景
bg_color = ImageColorGenerator(bg)
# 开始画图
plt.imshow(wc.recolor(color_func=bg_color))
# 为云图去掉坐标轴
plt.axis("off")
# 保存云图
wc.to_file("render_04.png")
5.词云轮廓原图:

这是您的专属社会人
运行效果:

wordcloud词云图
由于第二种方法无法解析表情图,所以没有表情出现,除此之外,这两种方法显示的词云图内容,几乎大同小异。
通过词云图,我们一眼看出,大家使用最多的,除开中文后,就是表情图了,你的微信朋友圈里,是否也有这样的大红嘴唇,我的好像有,哈哈哈~
当我们单纯来看词云中的中文时,发现像太阳、阳光、微笑、可爱、开心、爱、未来等比较积极向上的词语,还是比较受大家喜欢的,也体现出大家的内心的积极、乐观,当然还有像丽丽、徐、陈等这样的姓名部分,在昵称中大家也使用得比较多,但也不缺乏有像悲伤、凉这样比较冷色的词语。
通过昵称进行情绪分析(大胆猜想)
1.微信昵称为全中文
微信昵称为全中文,可以分为两大类:自己的真名和其他昵称。
直接用自己的姓名,当微信昵称的人,性格大多是直来直往的那种,待人比较坦诚。
他们的微信,一般用于熟人社交和日常办公,平时不会随便加不熟的人,就算用真名,也不怕泄露个人信息,来个不恰当的比喻:不做亏心事,不怕鬼敲门,哈哈哈。
为其他昵称的人,大多有自己的看法,也许昵称是自己对未来的一种期望,也许昵称是自己对生活的一种态度,或者是一些无厘头的话语,炫酷的话语。(猜测)

2.微信昵称为全英文
出于个人喜好或工作需求,有些人会给自己取一个容易记的、叫着顺口的英文名,比如Tom、Abby、Jason,并常常在自我介绍的时候,让大家可以用英文名字称呼自己。
对他们而言,英文名就相当于自己的第二个名字,用它做微信名,和用本名没什么太大的区别。
也有的人会刻意避开,那些常见的英文名,取一些更小众的,他们更在意提高自己的“逼格”,喜欢标新立异,追求时尚和前卫。(猜测)

3.微信昵称带有表情符号
有很多女生,会在微信名称里加上各种表情符号,从上面分析的词云图中,可以看出,一个大红唇大家使用最多,其他的可能是一个爱心、一朵玫瑰、一颗星星、又或是系统自带的emoji表情。
她们可能觉得,这是一种特别的装饰,能让自己的名字,和别人有明显的区别。
这样的女生,大多有细腻的小心思、浪漫的生活情调,和一颗蓬勃的少女心。(猜测)

4.微信昵称带有职业性质
一般来说,会主动在自己微信名前面,带一个字母“A”的,大多都是整天在朋友圈里发广告的微商或代购。
比较正式一点的,用的都是“公司名+姓名”的形式,这一类人基本都是销售员或房产中介……或者就是真正的大佬啦~
还有一些人,会根据自己不同的工作阶段,不定时更换名字后缀的。
认识一个在某地产公司做人力的朋友,为了能好好享受假期,她会把微信名改成“ΧΧΧ休假中”,以便提醒那些在节假日,还私信她询问工作的人。
也有一些人反着来,为了显示自己特别积极,直接把微信名改成“ΧΧΧ加班中”……emmm主要是改给老板看的吧。(猜想)

5.微信昵称带偶像名
不用说,这一类都是典型的追星族,而且大多都是女生,比如吴亦凡夫人、蔡徐坤秘密女友、胡歌的小娇妻……不出意外,她们的头像,一般就是她们的爱豆本人。
她们平时会在微博,给偶像打Call,朋友圈也会发很多相关推荐,如果有人夸自己的爱豆,她们会觉得遇到了知音;相反地,如果有人说她们爱豆的坏话,她们会马上拉黑……
切记,在追星的人面前,不要轻易抬杠,不要对她的爱豆指手画脚……(猜想)

6.微信昵称是四字词
仔细观察长辈们的微信名,就会发现他们,特别喜欢用四字词作昵称。
这些四字词最大的共同点,就是都传递着一种岁月静好的氛围:“人生如茶”“花自芬芳”“上善若水”“人心依旧”“云淡风轻”……
年轻人用独特的微信名标记自己,年长点的叔叔阿姨,只是想纯粹地寄托一种生活理想。(猜想)

都说名字是人的第二张脸。微信名取得好,往往会给人留下更好的印象。你的微信名,有什么特别的含义吗?留言区里聊一聊。
完
投稿啦!!!
精彩继续
CSDN作为国内专业的云计算服务平台,目前提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、机器学习、智能算法等相关云计算观点、技术、平台、实践、云产业咨询等服务。CSDN 公众号也一直坚持「与千万技术人共成长」的理念,深度解读行业内热门技术与场景应用,致力于让所有开发者保持敏锐的技术嗅觉、对行业趋势与技术获得更广阔的认知。
文章题材
首先你需要关注我们的公众号“CSDN云计算”,这样你会更准确了解我们需要的文章风格;
侧重于云计算领域相关的文章,可以是技术、运维、趋势等方面的务实内容;
原创,要求文章有鲜明观点和看法。
投稿须知
稿费:根据原创性、实用性和时效性等方面进行审核,通过的文章会发布在本微信平台。一经采用,我们将支付作者酬劳。酬劳可能不多,这代表的是一个心意,更多是因为爱好,是有识之士抒发胸怀的一种方式;
字数要求:稿件字数以2K-8K为宜,少于2K或多于8K都会一定程度降低阅读愉悦感;
投稿邮箱:lijy@csdn.net。或者添加微信表明来意,微信号:tangguoyemeng。请备注投稿+姓名+公司职位。
如果咱们的合作稳定又愉快,还可以签订合同长期合作哦!