Prometheus的功能、架构、组件、配置
1 介绍
1.1 简介
Promethues是一套开源系统监控及报警框架,启发于Google的borgmon, 由SoundCoud员工于2012年创建,并于2015年正式发布,2016年正式加入Cloud Native Computing Fundation
1.2 监控目的
趋势分析:对监控指标进行持续收集和统计,进行趋势分析。
利用磁盘空间增长率判断何时进行磁盘扩容。
对照分析:对不同版本系统运行资源使用情况或性能数据进行跟踪和对比。
告警:即使发现故障,快速响应问题,避免对业务产生较大影响。
故障分析与定位:分析和排查问题,找到问题根源。
数据可视化:通过仪表盘等对系统运行状态,资源使用,服务状态等进行直观显示。
1.3 特点
多维数据模型:使用metric名和键值对来区分的时间序列数据。
灵活强大的查询语言支持:PromQL。可对metrics进行数学运算、逻辑运算等操作。
单节点部署,不依赖于分布式存储。
数据采集其于HTTP协议,使用Pull模式获取数据。
扫描目标与告警管理支持静态配置与动态服务发现。
可使用使用PushGateway推送时间序列数据至Prometheus Server。
内置Dashboard用于基本功能查看和管理。
1.4 组件
Prometheus Server:数据采集和存储时序数据
对数据进行告警分析
client libaries:提供应用程序数据收集功能
push gateway:支持短期jobs,由jobs推送数据到push gateway,再由gateway暴露给Prometheus Server
Exporters:暴露第三方服务采集数据,非侵入式
Alertmanger:对Prometheus server产生告警进行去重、分组、发送等功能
1.5 架构

流程:Prometheus通过Service discovery发现采集目标
使用HTTP请求获取采集目标指标数据,并进行持久化存储
定时运行本地规则进行数据聚合产生新的时序数据或告警
将告警发送于alarmmanager,由alarmmanager进行分组、去重等功能后发送告警通知或恢复通知
可调用Prometheus Server提供的HTTP API获取采集数据用于可视化
1.6 使用场景:
Prometheus可以记录任何纯数据的时序数据
常用于以机器为中心的监控、面向高度动态的服务体系架构监控
不适合100%准确性的要求,如请求计费
2 部署安装
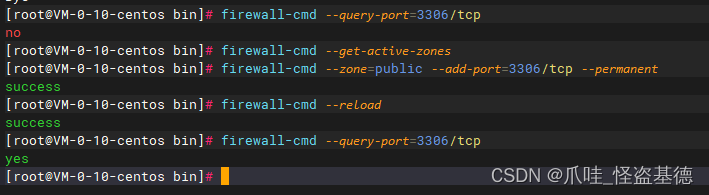
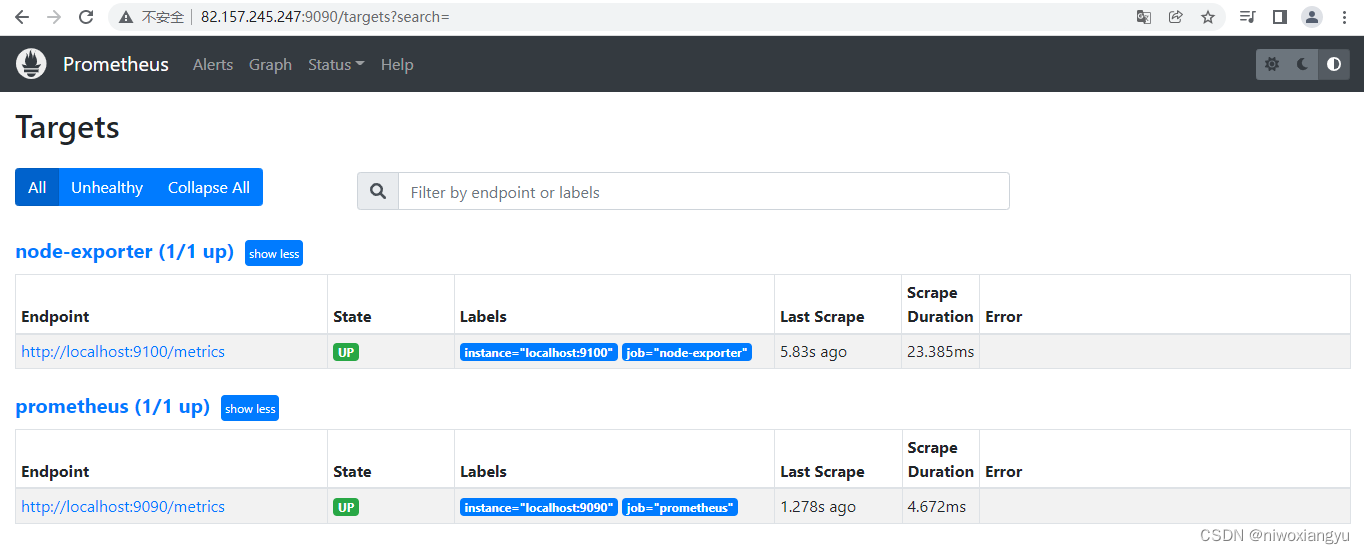
搭建组件Prometheus Server、Alertmanger、node_exporter、mysqld_exporter
安装 进程监控 systemd supervisord
Prometheus的环境搭建与使用
3 基本概念
3.1 数据模型:
Prometheus也会为查询结果生成临时的时间序列
每个时间序列由度量指标名称和他的标签键值对集合唯一确定
格式: <metric name>{label name> = <lable value>, ...} samples [millisecond]
指标名称: 格式[a-zA-Z_:][a-zA-Z0-9_:] *
标签名: [a-zA-Z_][a-zA-Z0-9_] *
标签值: 任意格式的Unicode值
采样数据: float64格式
3.2 指标类型
Prometheus client库提供4种核心的度是类型,Prometheus Server并不使用类型信息
Counter:计数类
使用在累计指标单调递增或单调递减情况下,只能在目标重启后自动归零
例如--服务请求处理数量
已完成任务数量
错误数量
Guage: 测量类
使用可增可减的数据情况下
例如--当前内存便用情况
并发请求数量
Histogram:直方图类
使用统计指标信息在不同区间内(桶)的统计数量
例如--延迟时间、响应大小
包含各桶的统计数量,总的统计信息以及总的统计数量:<basename> _bucket{le=""}
<basename>_sum
<basename>_count
Summary:摘要类
类似于直方图,在客户端对百分位进行统计
例如--延迟时间、响应大小
包含各桶的百分位信息,总的统计信息以及总的统计数量:<basename>{quantile=""}
<basename>_sum
<basename>_count
3.3 作业与实例
实例: instance
指数据采集的端点
作业: job
指具有相同目的的实例集合
Prometheus在采集数据时自动在时序数据中添加作业和实例标签名及值: job
instance
针对每个实例Prometheus生成采集指标:up--是否在线
scrape_ duration_seconds--采集持续事件
scrape_samples_post_metric_relabeling--重置label样本数量
scrape_samples_scraped--暴露的样本数量
scrape_series_added--近似的新增时间序列数量
4 配置
命令行参数--启动后不可修改
配置文件: 通过命令行参数--config.file指定,默认就是prometheus.yml
可修改并通过信号或API进行重新加载: kill -s SIGHUP $PID
api /-/reload 需要通过命令行参数--web.enable-lifecycle开启
全局配置
规则文件: 公共配置

说明
groups 配置规则组
name 规则组名称
interval 规则运行时间间隔
rules 规则列表
记录:用于对时序数据进行计算生成新的时序数据进行存储

说明 record 新时序数据库指标名
expr
promql表达式
用于查询时序数据
labels 标签
告警 用于产生告警
示例
采集列表
规则文件检查
重新加载配置
告警指标
5 PromQL
Prometheus提供PromQL功能用于时序数据的查询和统计
表达式数据类型:
及时向量--针对每个查询结果集单项中只包含一组时序数据和样本值
范围向量--针对每个查询结果集单项中包含多组时序数据和样本值
标量--浮点型数据
字符串--字符里数据
及时向量查询
范围向量查询
偏移量
子查询
运算
函数
6 HTTPAPI
查询:
及时向量查询
范围向量查询
指标查询
查询标签
查询标签值
查询采集目标
查询规则
查询告警
查询深集目标元数据
查询元数据
查询告警管理器
查询配置信息
查询命今行配置
查询运行时信息
查询编译信息
查询TSDB状态
管理员:命令行参数通过--web.enable-admin-api启动
快照 路径 /api/v1/admin/tsdb/snapshot
请求方式 POST PUT
查询参数 skip head 跳过头数据
删除时序 路径 /api/v1/admin/tsdb/delete series
请求方式 Post PUT
查询参数 match[]
start
end
说明 数据并未真正从硬盘删除,后续在压缩时进行清理
清理磁盘数据
生命周期管理: 命令行参数通过--web.enable-lifecycle启动
健康状态 路径 /-/healthy
请求方式 GET
准备状态 路径 /-/ready
请求方式 GET
重新加戟配置 路径 /-/reload
请求方式 PUT Post
退出 路径 /-/quit
请求方式 PUT POST
7 联合模式
8 告警管理
Prometheus的主要代码解读和服务发现与控制
针对服务发现的功能
告警的功能
exporter采集数据