0. 简介
对于激光雷达数据而言,虽然与2D图像相比,可以提供精确的物体深度信息,但也存在数据量大的问题,不便于数据存储或传输。在拿到离线数据分析的时候会发现我们很难拿到较长一段时间的激光数据,这就给我们问题的重现增加了困难。而本文《R-PCC: A Baseline for Range Image-based Point Cloud Compression》就提出了一种基于距离图像的点云压缩方法R-PCC,该方法可以重建具有均匀或非均匀精度损失的点云。我们将原始大尺度点云分割成小而紧凑的区域,以实现空间冗余和显著区域分类。与其他基于体素或基于图像的压缩方法相比,该方法可以在重构点云中保留并对齐原始点云中的所有点。它还可以通过量化模块控制每个点的最大重构误差。在实验中,我们证明了我们更简单的基于FPS的分割方法可以获得比基于实例的分割方法(如DBSCAN)更好的性能。相对应的代码已经在Github上完成了开源。
1. 文章贡献
在本文中,我们提出了一种使用最远点采样(FPS)的基于区域的方法。在第IV-C节中,我们比较了基于实例和基于区域的分割方法的压缩比和重构质量,结果表明,语义和准确的分割不能提高整体压缩性能,而我们的统一压缩框架可以在2cm倒角距离误差的情况下实现30倍的压缩比。将大规模点云分割为小区域的另一个原因是,我们可以在不影响下游任务的情况下,通过在重要区域保持高压缩精度而降低不重要区域的压缩精度来减小压缩的比特流大小。下面是主要贡献:
- 我们评估了不同范围和分布与压缩比率之间的关系,结果表明,我们的最远点采样分割和点-平面混合建模方法比基于群集的压缩方法在效率和效果上更好。
- 我们为不同需求提出了一个统一和非统一的压缩框架。具有更多关键点的群集作为后续任务的显着区域保持高的重建质量。
- 我们将我们的压缩框架与其他最先进的算法进行比较,在重建质量和后续任务性能方面都取得了卓越的表现。我们的实时框架R-PCC是开源的,易于扩展到多个下游任务,并可以成为一个新的基于范围图像的点云压缩基准。
2. 点云压缩基础
点云数据很大要压缩。压缩点云的平台国际上有MPEG的基于几何的点云压缩(Geometry Point Cloud Compression,G-PCC) 和基于视频的点云压缩 (Video Point Cloud Compression, V-PCC) 两个平台;国内有AVS的AVS-PCC平台。V-PCC旨在为需要实时解码的应用提供低复杂度的解码能力,如虚拟/增强现实、沉浸式通信等。G-PCC可为自主驾驶、3D地图和其他利用激光雷达生成的点云(或类似内容)的应用程序的部署提供高效的无损和有损压缩。
V-PCC的整体框架如下图所示,类似于传统的三维视频,整体编码过程可分为四个步骤:补丁生成、几何/纹理图像生成、附加数据压缩和视频压缩。视频压缩过程可以采用已发布的视频编码标准H.265/HEVC、H.266/VVC进行压缩。
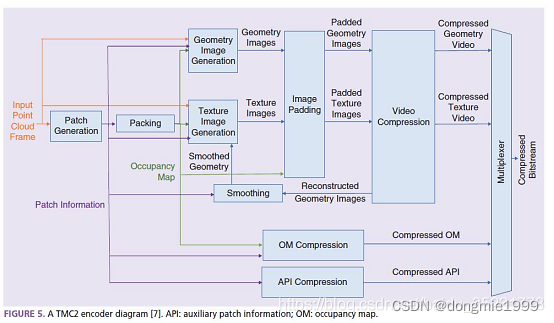
2.1 压缩方法分类
传统方法:先去除一部分冗余,再使用变换与量化将空间域的点云变换到频域并压缩变换系数,再经过熵编码进一步压缩比特流。优点:简单直观易理解、可控易debug;缺点:语义难建模,用户不友好
深度方法:通过卷积神经网络将点云数据编码为隐藏表示,再量化隐藏特征,基于学习熵模型和熵编码将上下文输入的情况下每个符号出现的概率压缩并产生比特流。优点:简单高效、数据驱动;缺点:不可解释、黑盒不可控、需要硬件支持(GPU/FPGA etc.)、因为门槛低所以难找工作
3. 系统总览
我们提出的统一或非统一点云压缩框架R-PCC如图1所示。我们的框架的解压部分使用与压缩框架相同的基本压缩器,以解压分割和建模信息数据(信息数据)和量化残差数据。信息数据可以像压缩框架一样预测粗略点云,而残差由反量化模块恢复。在非统一框架中,每个簇的精度对应于压缩中的量化模块。
我们提出的基于激光雷达采集范围图像的压缩框架如图1所示。该框架的解压部分使用与压缩框架中相同的基本压缩器,以解压分割和建模信息数据(info.data)和量化残差数据。info.data可以像压缩框架中一样预测粗略的点云,而残差则通过逆量化模块恢复。在非均匀框架中,每个聚类的准确度对应于压缩中的量化模块。
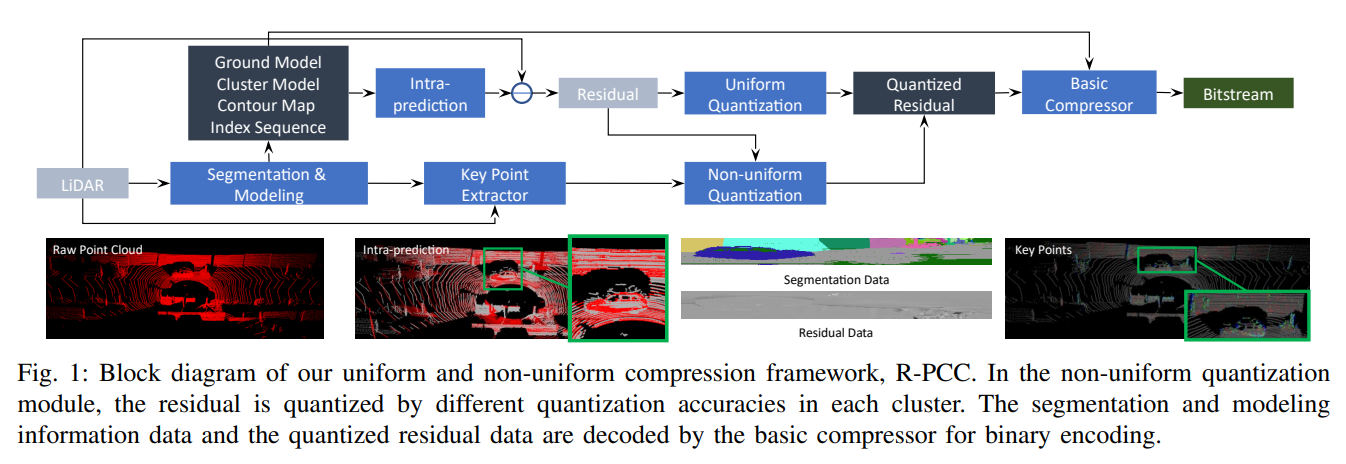
这样的误差损失包括两个部分:
- 从点云到范围图像的投影;
- 均匀或非均匀量化精度。
4. 距离图像
现在,大多数激光雷达的单帧点云可以从三维投影到二维。激光雷达具有不同的激光束(例如,Velodyne HDL-64E具有64束激光,而32E具有32束激光),所有激光束在方位角方向(水平视场)上都具有 360 ° 360° 360°的全旋转。这里我们以Velodyne HDL-64E为例。在高度方向(垂直视场),距离图像由64行组成,这些行的角度分布在最低角度 ϕ m i n ϕmin ϕmin和最高角度 ϕ m a x ϕmax ϕmax之间。每个扫描在距离图像中代表一个固定的角度。如果激光雷达具有 H H H束激光,水平角分辨率为 ρ ρ ρ,则激光雷达收集的距离图像的形状应为 [ H , W ] = [ H , ⌊ 360 / ρ ⌉ ] [H,W]=[H,\lfloor360/ρ\rceil] [H,W]=[H,⌊360/ρ⌉],其中 ⌊ ⌉ \lfloor \rceil ⌊⌉表示四舍五入操作。
我们可以将3D点 P = ( x , y , z ) P=(x,y,z) P=(x,y,z)投影到对应的2D像素 I = ( w , h , r ) I=(w,h,r) I=(w,h,r)上,其中 w w w和 h h h是垂直索引和水平索引, r r r是点到LiDAR原点的欧几里得距离。 p ( w , h , r ) p(w,h,r) p(w,h,r)的值按照计算。 r = x 2 + y 2 + z 2 r = \sqrt{x^2 + y^2 + z^2} r=x2+y2+z2, h = ⌊ θ / ρ ⌉ h = \lfloorθ/ρ\rceil h=⌊θ/ρ⌉,以及 w = ⌊ ( ϕ − ϕ m i n ) / σ ⌉ w = \lfloor(ϕ−ϕmin)/σ\rceil w=⌊(ϕ−ϕmin)/σ⌉,其中 θ = a r c t a n ( y / x ) θ=arctan(y/x) θ=arctan(y/x)和 ϕ = a r c t a n ( z / r ) ϕ=arctan(z/r) ϕ=arctan(z/r)分别是水平角和垂直角, ϕ m i n ϕ_{min} ϕmin是最小的垂直角, σ = W / ( ϕ m a x − ϕ m i n ) σ=W/(ϕ_{max}−ϕ_{min}) σ=W/(ϕmax−ϕmin)。
5. 压缩框架
地面提取模块: 地面点具有很强的规律性,因为地面点可以拟合到一个大平面上。我们使用像[8]中的RANSAC平面拟合方法来估计地面模型。
分割模块: 该模块将点云分割成几个更密集的点云子集。与[7]和[8]中的实例分割方法相比,我们选择FPS方法来找到每个聚类的中心作为基于区域的分割方法。聚类的数量等于FPS设置中采样点的数量。在Sec. IV-C中,我们将DBSCAN作为基线与我们的分割方法进行比较,结果表明我们的方法在压缩和效率方面表现更好。
模型模块: 在获得小点云集群之后,我们使用两种方法,点和平面,来建模每个集群中的点。点建模方法使用点深度的平均值,平面建模方法使用通过RANSAC估计的平面来表示每个集群中的点。当集群中的点数小于30或该集群中平面法向量和LiDAR扫描之间的最大角度大于 75 ° 75° 75°时,我们将选择点建模方法。对于集群中的点集 { P i = ( x i , y i , z i ) } i = 1 k \{P_i =(x_i,y_i,zi)\}^k_{i=1} {Pi=(xi,yi,zi)}i=1k,点模型: r = 1 k ∑ ∣ ∣ P i ∣ ∣ 2 r = \frac{1}{k}∑||Pi||^2 r=k1∑∣∣Pi∣∣2,平面模型 a x + b y + c y + d = 0 ax + by + cy + d = 0 ax+by+cy+d=0,其中 { r } \{r\} {r}和 { a , b , c , d } \{a,b,c,d\} {a,b,c,d}是模型参数。



