简介

在一本厚厚的书籍的前几页,通常会有几页目录。作用是让读者可以快速找到感兴趣的章节进行阅读。
目录之所以可以快速阅读,是因为它提前进行了结构化+有序处理。
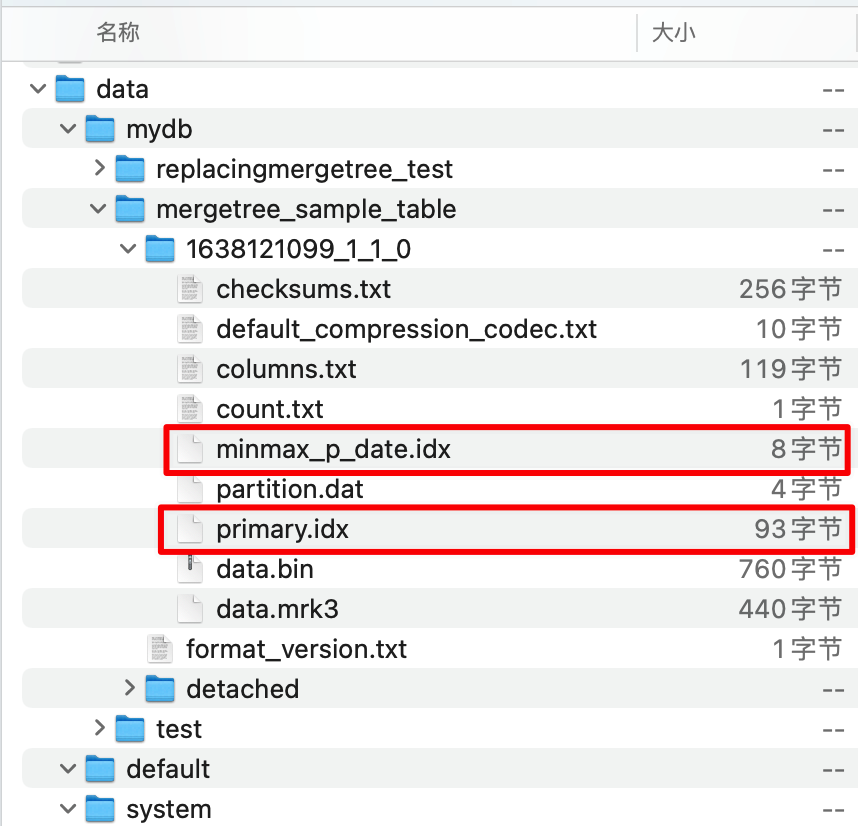
同样的道理,数据库的数据表的文件下面(以 ClickHouse 为例),通常也有索引文件(目录 primary.idx)加上数据文件(正文页 data.bin), 使得查询快速。
索引之所以能提升查询速度,在于它的结构化+有序。
查找数据结构进化史
线性查找:一个个找;实现简单;太慢
二分查找:有序;简单;要求是有序的,插入特别慢
HASH查找:查询快;占用空间;不太适合存储大规模数据
二叉查找树:插入和查询很快(log(n));无法存大规模数据,复杂度退化
平衡树:解决 BST 退化问题,树是平衡的;节点非常多的时候,依然树高很高
多路查找树:一个父亲多个孩子节点(度);节点过多树高不会特别深
多路平衡查找树:B-Tree
关于这些查找结果的演示推荐:
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
举个例子:
左边是数据表,一共有两列 (Col1, Col2) 七条记录,最左边的是数据证已录的物理地址( 0x 开头的 ):
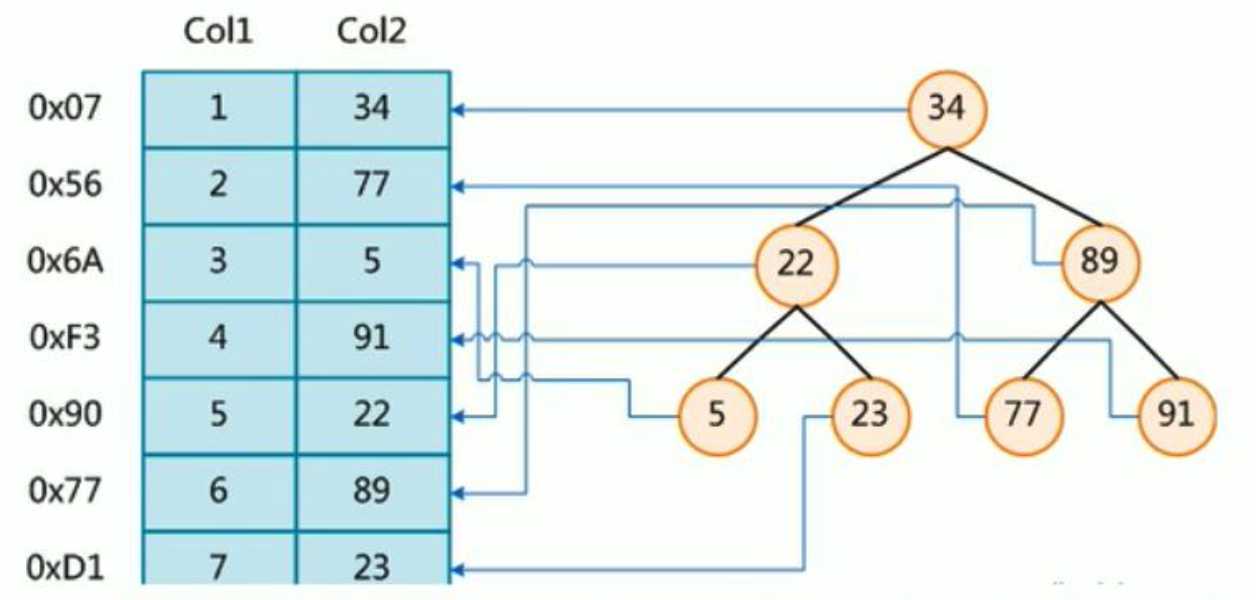
为了加快 Col2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取取到相应数据,从而快速的检索出符合条件的记录。
BST 二叉查找树
二叉查找树 , Binary Search Tree/BST/二元树,一种数据结构,支持多种动态集合操作,如 Search、Insert、Delete、Minimum 和 Maximum 等。
二叉树性质:
(1)若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
(2)若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
(3)任意节点的左、右子树也分别为二叉查找树。
B Tree
存储数据: 1,2,3,4,5,6,7,8,9,10
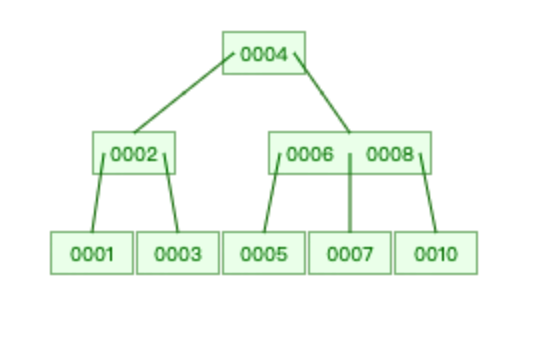
查找 6 :


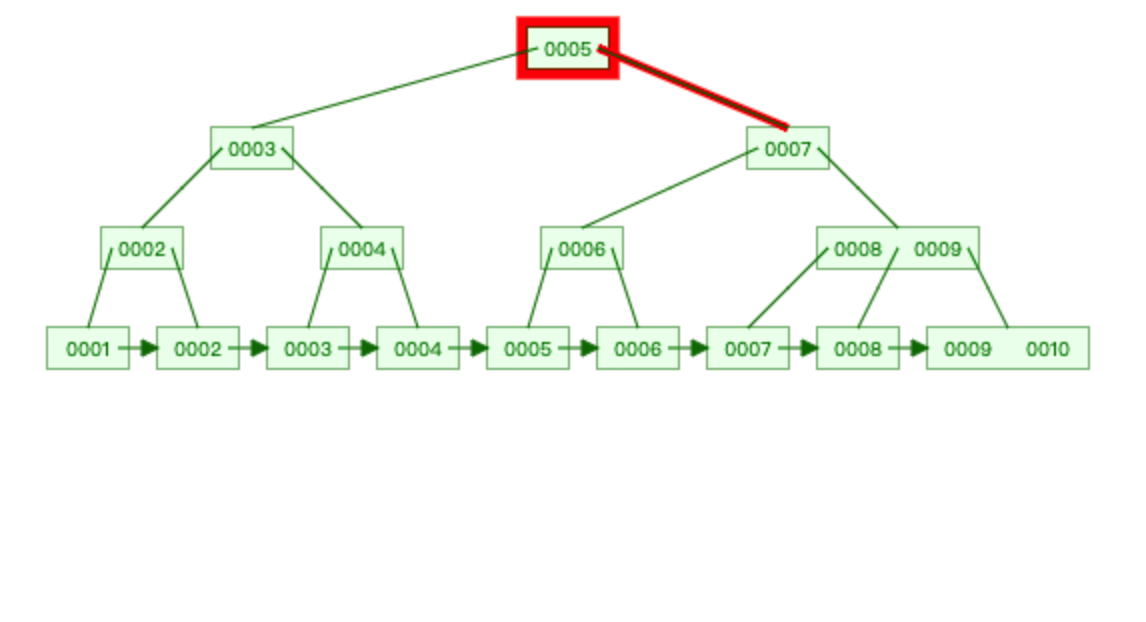
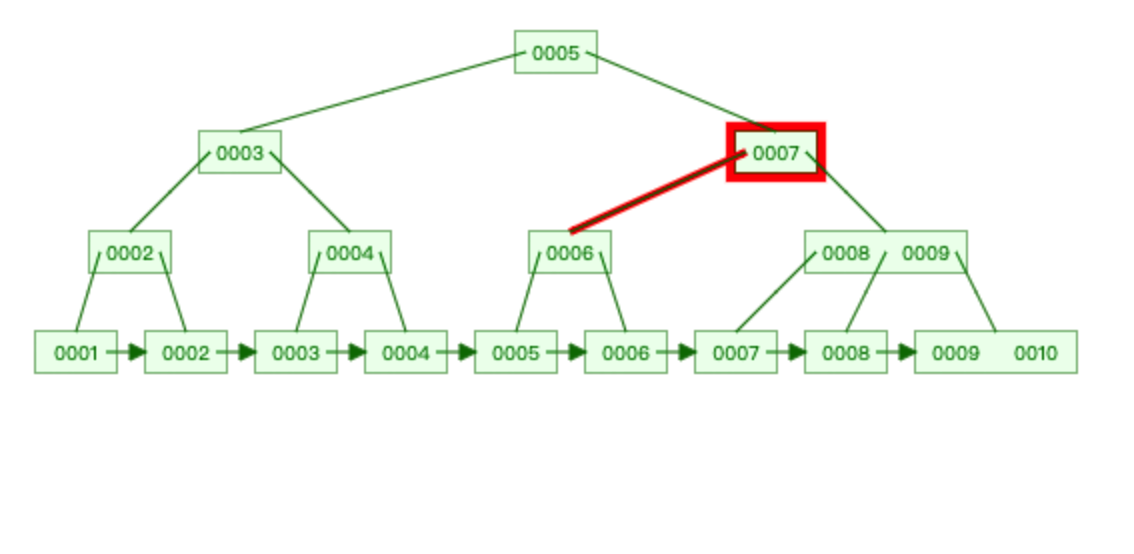
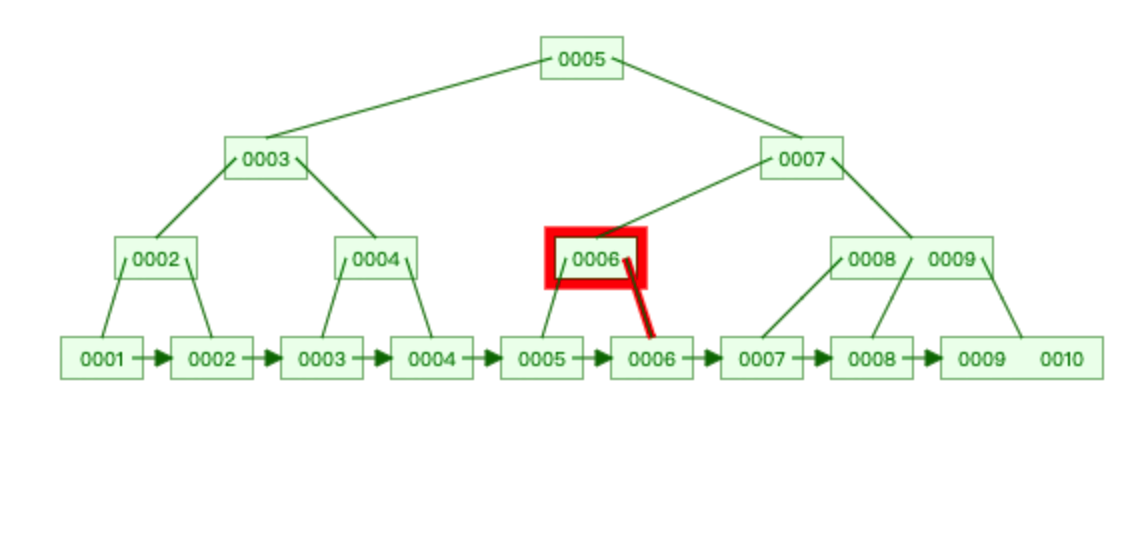
B+Tree
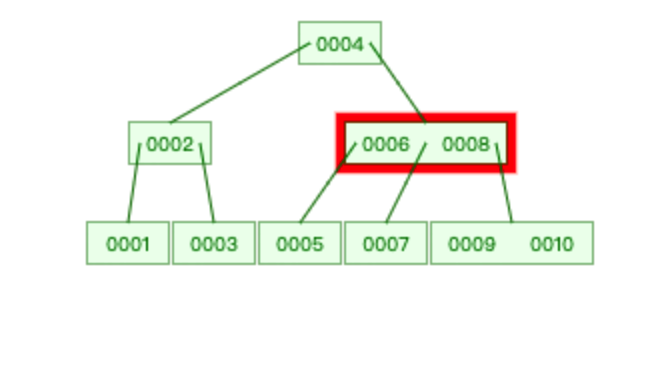
存储数据: 1,2,3,4,5,6,7,8,9,10
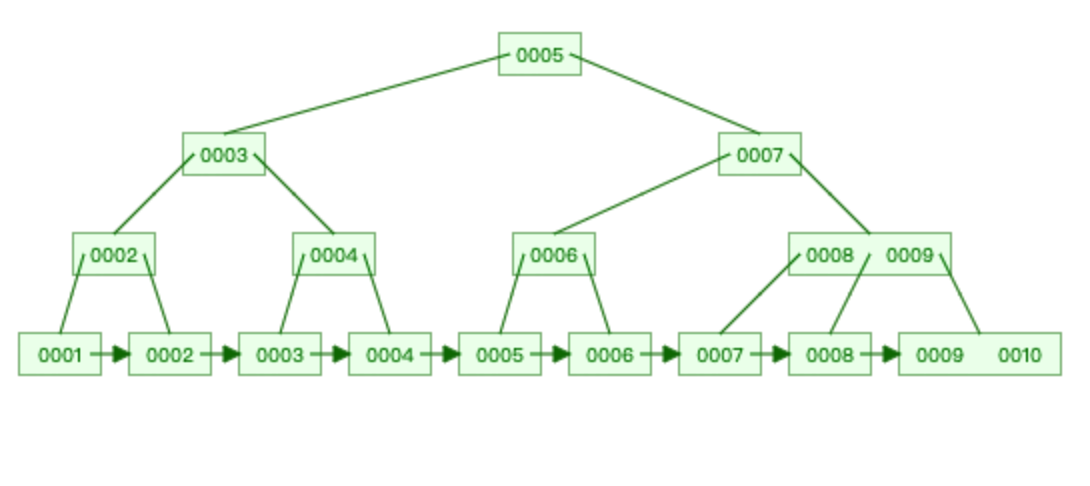
查找 6 :
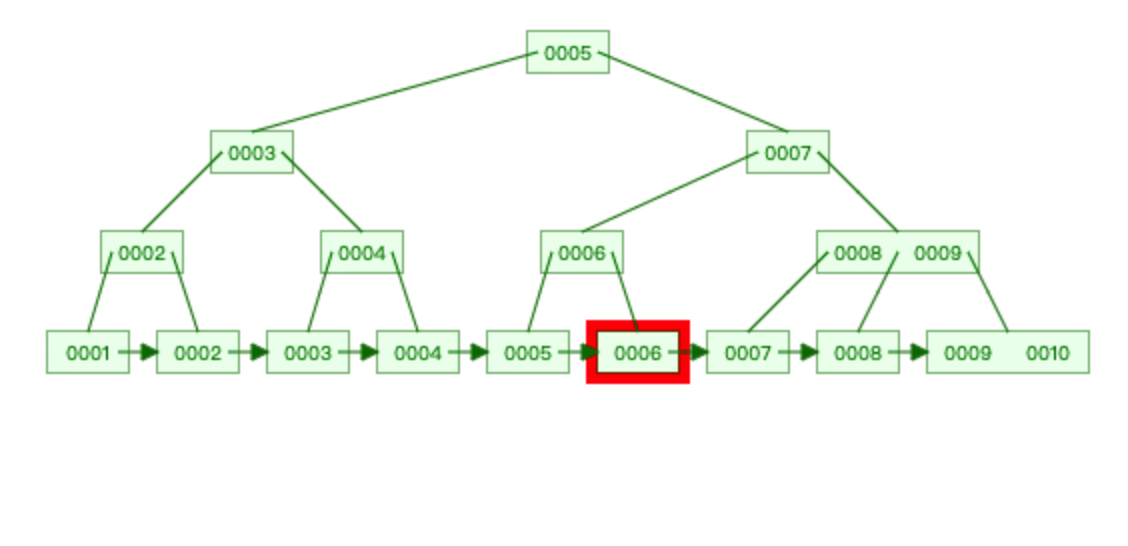
索引分类及使用
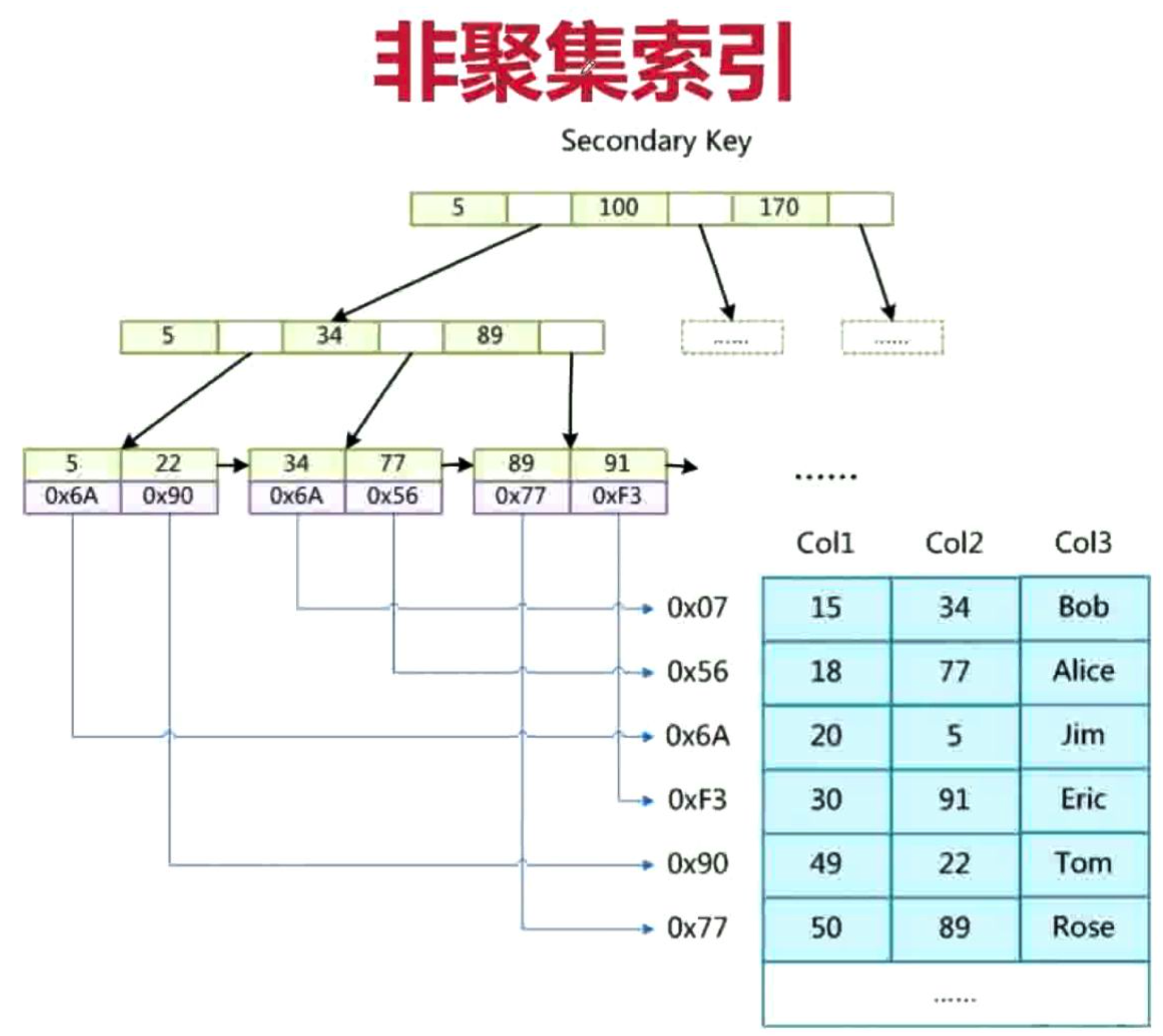
非聚簇索引

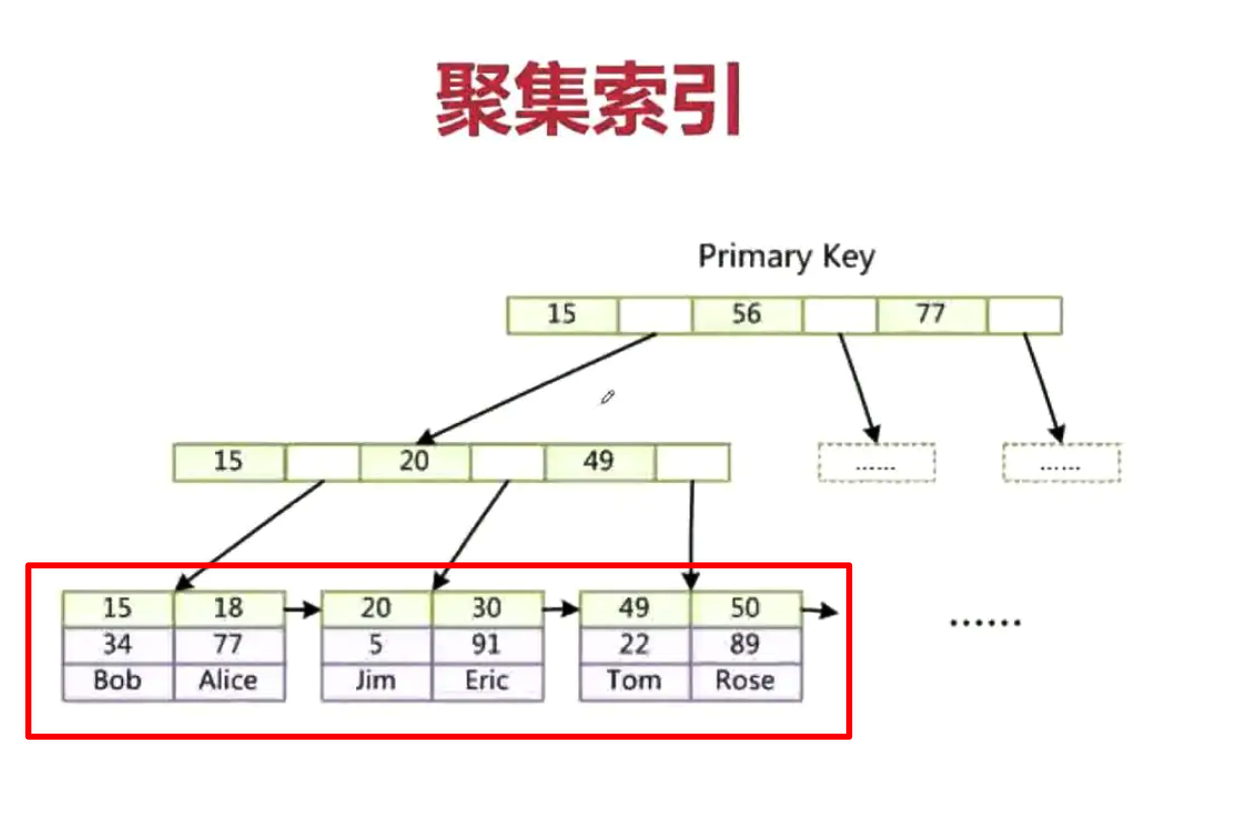
聚簇索引
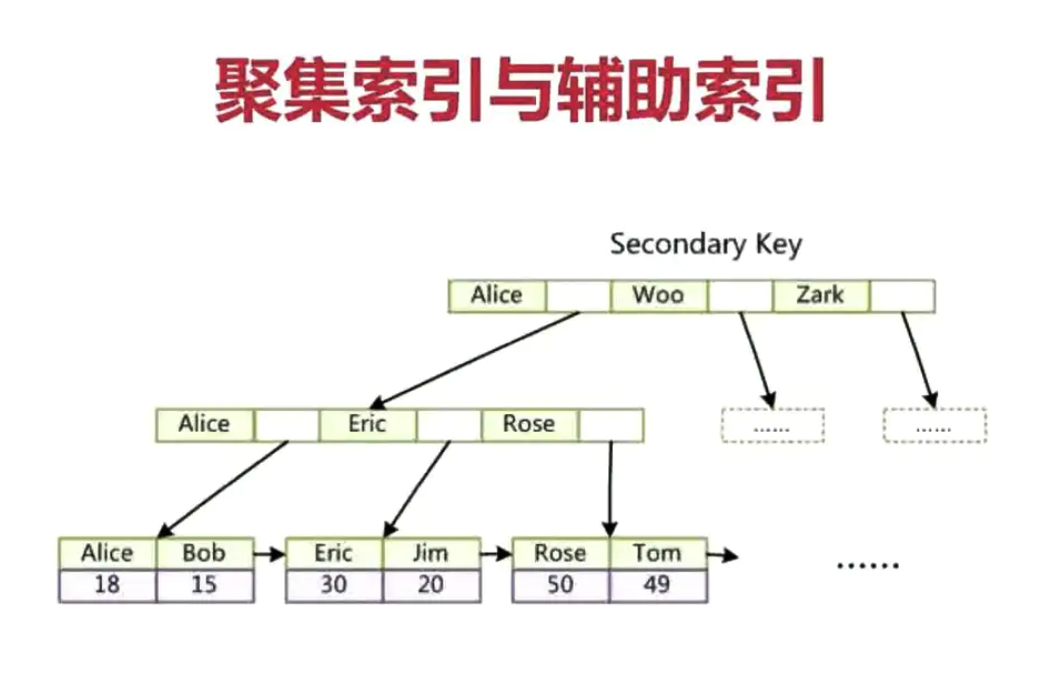
辅助索引(需要回表 )
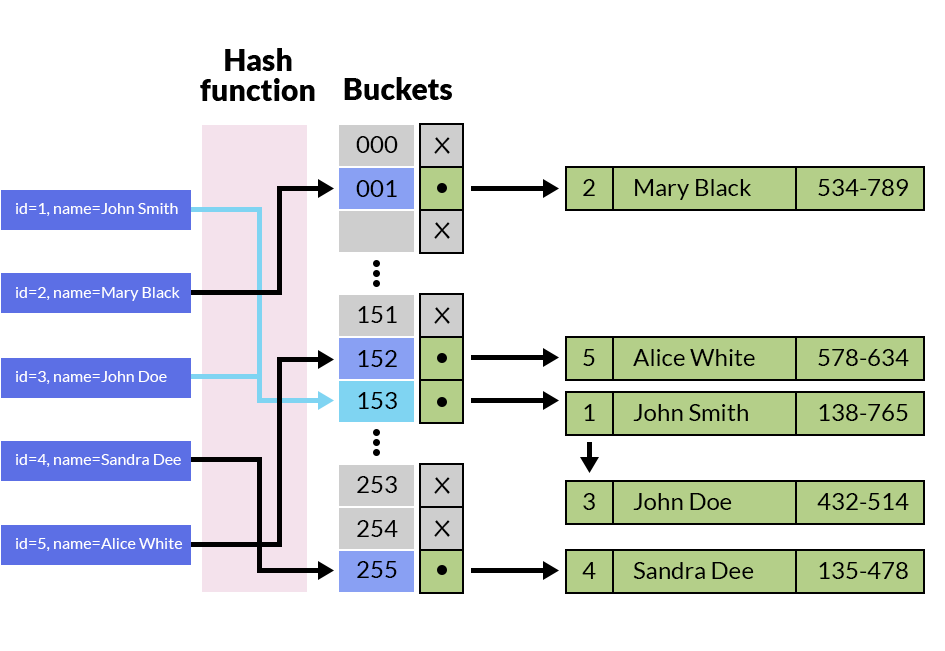
索引键 Hash 分桶映射原理
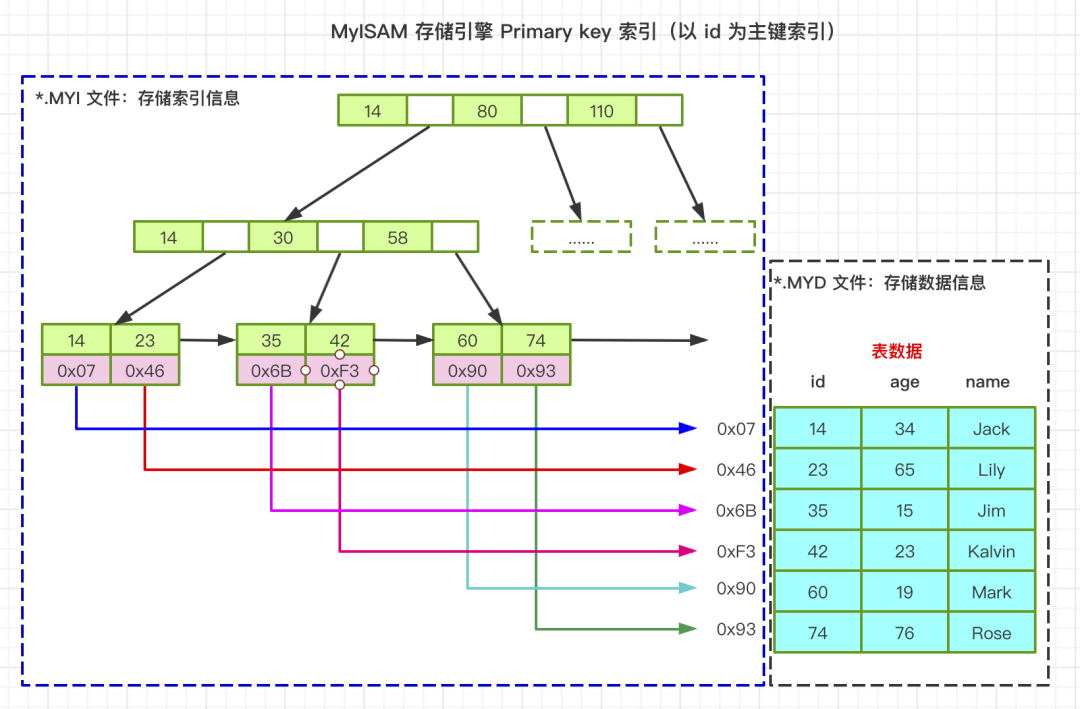
MyISAM 非聚集索引之主键索引
MyISAM 非聚集索引之辅助索引

数据表中以 age 为辅助索引或者叫次要索引,其实他们在MyISAM存储引擎中,在存储数据的结构上没有任何区别,只是主键索引要求key值唯一,而辅助索引中的key值可以重复,从上图中,可以看到,也是B+树的形式进行保存,索引是age列,而B+树的叶子节点中的data域,也是保存的记录的地址。
InnoDB 聚集索引之主键索引
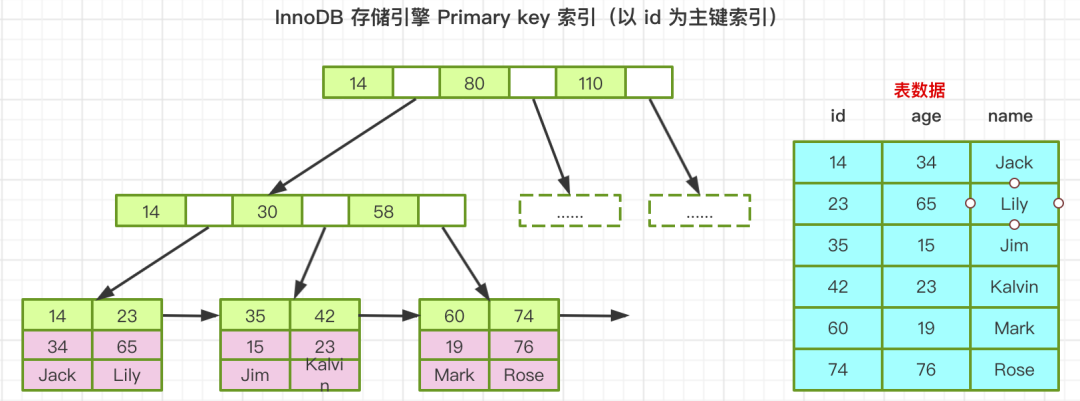
Innodb的数据表,必须要有一个可以唯一标识数据记录的列作为主键,如果创建表时,没有人为定义,InnoDB存储引擎会生成一个隐含字段作为主键,上图中我们心ID为主键,在B+树中的叶子节点中,其实他记录的是完整的行记录。因为InnoDB的数据文件本身就是按主键聚集的,也是为什么当没有主键时,InnoDB会自动的为表创建隐含主键。
InnoDB 聚集索引之辅助索引
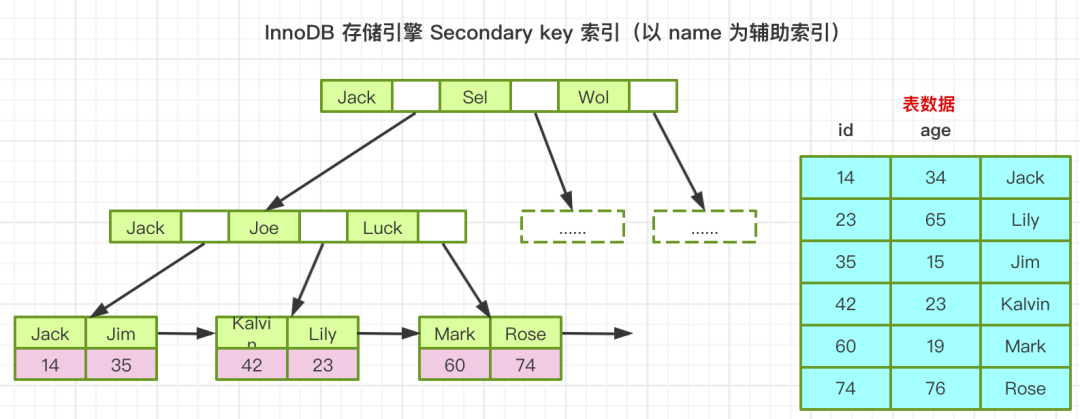
假这里定义了 name 为辅助索引,B+树的叶子节点中的data域,它存储的是相应记录的主键的值,而不是地址,换句话说,InnoDB的所有辅助索引都引用主键值作为data域,当它检索数据时,如果是select * from user where name='Mark'; 它会根据定义的索引B+树,进行二分查找,查找到Mark后,从数据域中读取到主键的地址,然后再回到主键索引,再次根据主键索引的B+树,进行二分查找,找到对应的主键所在的叶子节点,然后再取出所有的数据,这种操作叫做回表查询,需要进行检索两次:
非主键索引----> 从非主键索引的data域中获取主键ID---->再次检索主键索引的B+树---->从主键索引的叶子节点中获取到主键ID----->最终获取到数据;
如果是检索 select id,name form user where user='Mark'; 根据where条件中的name进行检索,由于name是非主键索引,按B+树进行二分查找,查找到Mark,然后再根据data域的主键ID,但这里要查询的数据是id和name,id正好是主键,在非主键索引中的叶子节点中的数据域中,保存的是主键ID,此时的查询称为覆盖索引查询。从而可以知道MySQL使用组合索引的话,可以更高效的检索数据。在实际工作中,可以根据检索的内容尽可能多的使用组合索引,形成覆盖索引,减少回表查询,减少IO次数,提高效率。
一颗B+树上面创建组合索引,省空间,更容易实现覆盖索引、组合索引,遵循最左前缀原则:
前缀索引
where name like a%可以用到索引,但如果where name like %a,索引失效;从左到右直到遇到范围查询检索时,当遇到
> 、 < 、 between 、 like这些条件时,索引失效。
例如建⽴组合索引 (a,b,c,d),where a=1 and b=1 and c>3 and d=1; 到 c>3 停⽌了, 所以d ⽤不到索引了。
如果还想使用 d 做索引怎么办?换个顺序建立索引,使用(a,b,d,c),再使用 where a=1 and b=1 and c>3 and d=1; 因为,查询优化器是根据 索引建立的顺序 进行索引的。
联合索引(组合索引、复合索引、组合排序键等): 涵盖多个列的索引
为了提高数据库效率,建索引是家常便饭;那么当查询条件为2个及以上时,我们是创建多个单列索引还是创建一个联合索引好呢?他们之间的区别是什么?哪个效率高呢?
数据库表中有 3列: a、b 和 c(按此顺序)
如果第一个过滤器是等式过滤器,而随后的列有 范围(<、<=、> 和 >=)表达式,查询可以使用复合索引。 以下过滤器示例使用了复合索引中的列:
WHERE a=1
WHERE a>=12 AND a<15
WHERE a=1 AND b < 5
WHERE a=1 AND b = 17 AND c >= 40以下过滤器示例不能使用该复合索引:
WHERE b=10
WHERE c=221
WHERE a>=12 AND b=15联合索引简介
一个三列索引(col1, col2,col3) 的数据结构示意图如下:

联合索引(col1, col2,col3)也是一棵B+Tree,其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1、col2、col3的顺序进行排序。
配图可能不太让人满意,因为col1都是不同的,也就是说在col1就已经能确定结果了。
更合适的图:col1表示的是年龄,col2表示的是姓氏,col3表示的是名字:

如图,联合索引(年龄, 姓氏,名字),叶节点上data域存储的是三个关键字的数据,且是按照年龄、姓氏、名字的顺序排列的。其中,对应地址指的是数据记录的地址。
执行过程分析
因此,如果执行的是:
select * from STUDENT where 姓氏='李' and 名字='安'或者
select * from STUDENT where 名字='安'那么当执行查询的时候,是无法使用这个联合索引的。
因为联合索引中是先根据年龄进行排序的。如果年龄没有先确定,直接对姓氏和名字进行查询的话,就相当于乱序查询一样,因此索引无法生效。
因此查询是全表查询。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='李'那么当执行查询的时候,索引是能生效的,从图中很直观的看出,age=1的是第一个叶子节点的前6条记录,在age=1的前提下,姓氏=’李’ 的是前3条。因此最终查询出来的是这三条,从而能获取到对应记录的地址。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='黄' and 名字='安'那么索引也是生效的。
而如果执行的是:
select * from STUDENT where 年龄=1 and 名字='安'那么,索引年龄部分能生效,名字部分不能生效。也就是说索引部分生效。
最左原则:联合索引的B+Tree是按照第一个关键字进行索引排列的:
order by col1,col2,col3联合索引的列顺序
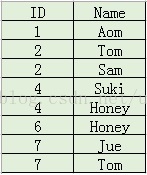
联合索引的列顺序是非常讲究的,以id列在前、name列在后为例。
建联合索引前的情况
建联合索引后的情况(先按 ID 排序 + 再按 Name 排序,排序键 order by ID, Name)
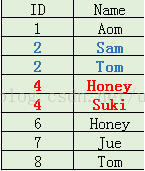
创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
多个单列索引在多条件查询时优化器会选择最优索引策略,可能只用一个索引,也可能将多个索引全用上! 但多个单列索引底层会建立多个B+索引树,比较占用空间,也会浪费一定搜索效率,故如果只有多条件联合查询时最好建联合索引!
联合索引的好处
1.避免回表
如在user的id列建有索引,
select id from user这个不用回表,直接从索引中读取id的值,而
select id,name from user中,不能返回除id列其他的值,所以必须要回表。如果建有了id和name列的联合索引,则可以避免回表。另外,建立了 id 和 name 的联合索引(id列在在前),则select id from user可以避免回表,而不用单独建立id列的单列索引。
2.两个单列查询返回行较多,同时查返回行较少,联合索引更高效。
如果
select * from user where id=2和
select * from user where name='tom'各自返回的行数比较多,而
select * from user where id=2 and name='tom'返回的行数比较少,那么这个时候使用联合索引更加高效。
最左前缀原则:
顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上,
注:如果第一个字段是范围查询需要单独建一个索引
注:在创建联合索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。这样的话扩展性较好,比如 userid 经常需要作为查询条件,而 mobile 不常常用,则需要把 userid 放在联合索引的第一位置,即最左边
组合索引核心原理
当组合索引的第一个索引列(通常称为先导列)没有出现在查询条件中时,一般情况下该索引无法被使用。组合索引最大的缺点就是当只为一部分索引列赋予了查询条件时,或者所使用的比较运算符大部分都是非“=”比较运算符时效率非常低下。
创建组合索引涉及两个非常重要的方面:
第一,基于什么样的列创建索引;
第二,按照什么样的顺序创建索引。
1.离散度和列序之间的关系
如果只是在“=”比较的情况下,离散度的好坏对列的组合顺序并没有什么大的影响。(对我们来说最重要的并不是离散度的好坏,而是是否使用了“=”比较的查询条件。)
2.等值比较对列的组合顺序的影响
问题的焦点就在于大量的等值比较运算符是否被连续使用。在实际工作中,多样化的数据读取需求使得很难为所有的列赋予等值比较,更为常见的是LIKE、BETWEEN、>、<等运算符。事实上,对执行速度影响最大的正是使用非等值比较的查询条件。在没有为组合索引的第一列赋予使用“=”比较查询条件时,即使为后面的列赋予了使用“=”查询条件也不会缩减数据的查询范围。
3.IN的垫脚石效果
从概念上看,BETWEEN 或者LIKE类似于“线段”的概念,IN类似于“点”的概念。由于线段是由无穷多个点构成的,如果无法将BETWEEN 或者LIKE转换为IN,也无法将线段概念的查询条件转换为“=”比较的查询条件。
该“点”就像垫脚石一样,有助于只读取需要的部分。
例:INDEX:COL1+COL2+COL3
WHERE COL1=’A’ and COL3=’333’如果没有为列COL2赋予查询条件,尽管为COL1赋予了“=”比较的查询条件,但是仍然扫描了满足COL1=’A’的整体范围。没有为COL2赋予查询条件与为COL2赋予LIKE’%’查询条件具有相同的效果。由于没有为COL3之前的COL2赋予“=”查询条件,COL3的查询条件只能起检验作用。
假设,当COL2的值只有1,2,3时,可以修改查询条件解决此问题:
WHERE COL1=’A’ and COL2 IN (1,2,3) and COL3=’333’在没有为C2赋予查询条件的情况下,由C1+C2所构成的索引和由C1+C2+C3所构成的索引不仅具有相同的查询范围,而且具有相同的执行结果。
但是由于在C1+C2的索引中没有使用列C3,所以当查询条件WHERE C1=’A’ and C3=’333’,为了检验满足C1=’A’的行是否满足C3=’333’就必须从表中读取数据。因此,像C3这样的列,虽然对缩减查询范围没有直接性的影响,但是对查询却起着非常重要的作用。
在为某个组合索引选定列时,首先应该考虑的是对直接缩减查询范围骑着重要作用的列;其次,对附加性列是否会有利于提高执行效率等相关问题进行全面分析。
在 MySQL 里,组合索引最大支持 16 个列。可以基于 B+ 树,也可以基于哈希,这篇主要讨论基于 B 树,并且索引顺序默认升序,基于 HASH 只有一种用法,就是所有列的都必须等值过滤。
使用组合索引的必备条件为:最左列必须存在于 SQL 语句过滤条件中!也就是说组合索引的第一个列(最左列)在过滤条件中必须存在,而且最好是等值过滤。
索引覆盖(Covering Index): 避免回表
SQL需要二级索引查询得到主键值,然后再根据主键值搜索主键索引,最后定位到完整的数据。这一过程叫 回表。
但是由于二级组合索引的叶子节点,包含索引键值和主键值 ( id ) ,若查询的字段 ( name ) 在二级索引的叶子节点中,则可直接返回结果,无需回表。例子:
select id,name from t_user where age=18;这种通过组合索引避免回表的优化技术也称为 索引覆盖(Covering Index)。
索引最左匹配原则
多列索引(联合索引)有最左匹配的原则,即最左优先:如果有一个 2 列的索引 (a, b),则已经对 (a)、(a, b) 上建立了索引;如果有一个 3 列索引 (a, b, c),则已经对 (a)、(a, b)、(a, b, c) 上建立了索引;
假设数据表 user (id,sex,price,name) 数据如下:
主键id sex(a) price(b) name(c)
(1) 1 1350 AAA安妮
(2) 2 6300 MMM盲僧
(3) 1 3150 NNN奈德丽
(4) 2 6300 CCC锤石
(5) 1 6300 LLL龙女
(6) 2 3150 EEE伊泽瑞尔
(7) 2 6300 III艾克
(8) 1 6300 BBB暴走萝莉
(9) 1 4800 FFF发条魔灵
(10) 2 3150 KKK卡牌大师
(11) 1 450 HHH寒冰射手
(12) 2 450 GGG盖伦
(13) 2 3150 OOO小提莫
(14) 2 3150 DDD刀锋之影
(15) 2 6300 JJJ疾风剑豪
(16) 2 450 JJJ剑圣当你在 user 表创建一个联合索引 abc_index:(sex,price,name)时,生成的索引文件逻辑上等同于下表内容(分级排序):
sex(a) price(b) name(c) 主键id
1 450 HHH寒冰射手 (11)
1 1350 AAA安妮 (1)
1 3150 NNN奈德丽 (3)
1 4800 FFF发条魔灵 (9)
1 6300 BBB暴走萝莉 (8)
1 6300 LLL龙女 (5)
2 450 GGG盖伦 (12)
2 450 JJJ剑圣 (16)
2 3150 DDD刀锋之影 (14)
2 3150 EEE伊泽瑞尔 (6)
2 3150 KKK卡牌大师 (10)
2 3150 OOO小提莫 (13)
2 6300 CCC锤石 (4)
2 6300 III艾克 (7)
2 6300 JJJ疾风剑豪 (15)
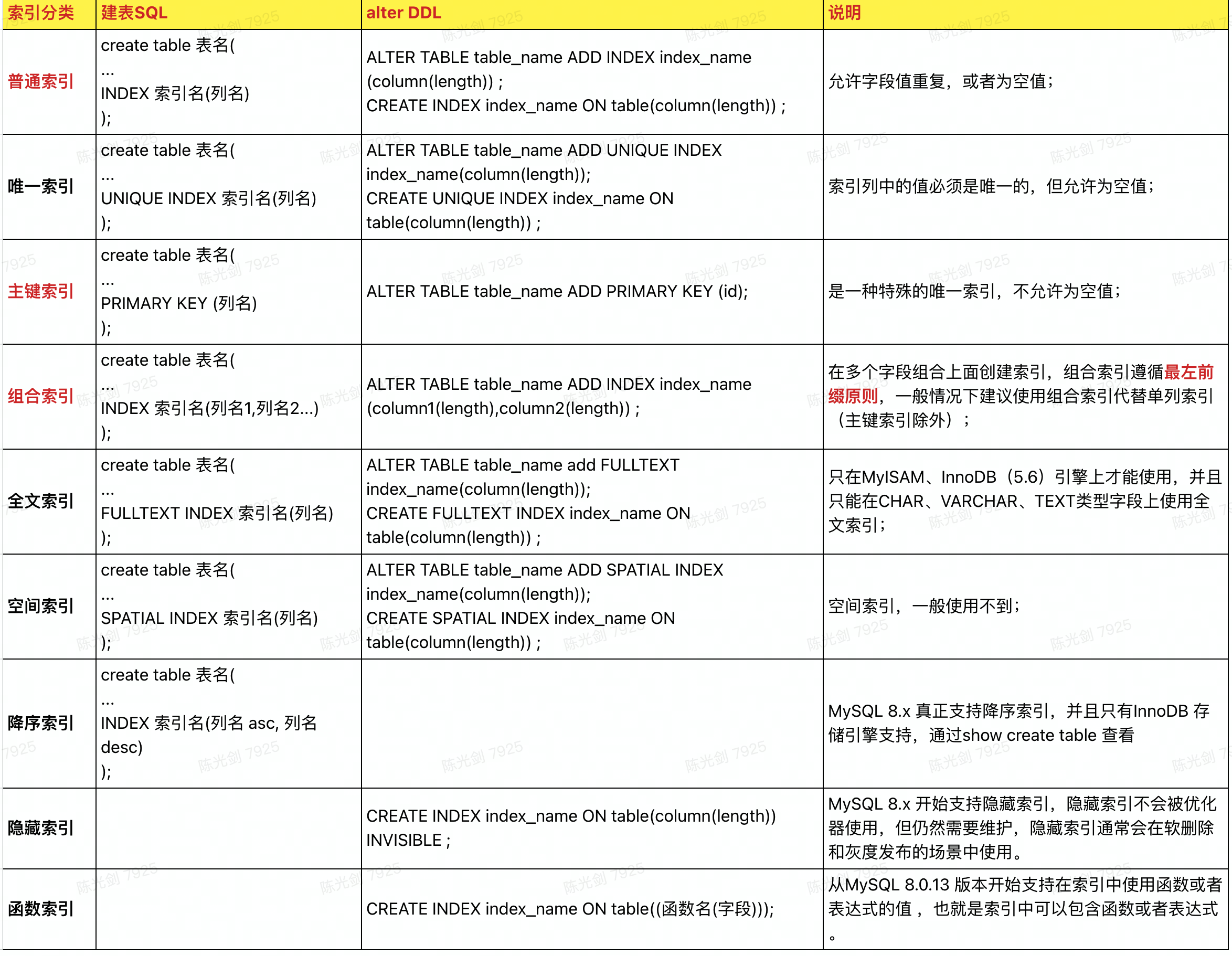
2 6300 MMM盲僧 (2)索引分类一览表:
索引执行计划
MySQL 提供了⼀个 EXPLAIN 命令, 它可以对 SELECT 语句的执⾏计划进⾏分析, 并输出 SELECT 执⾏的详细信息, 以供开发⼈员或DBA同学对性能进行优化。
explain字段详解:
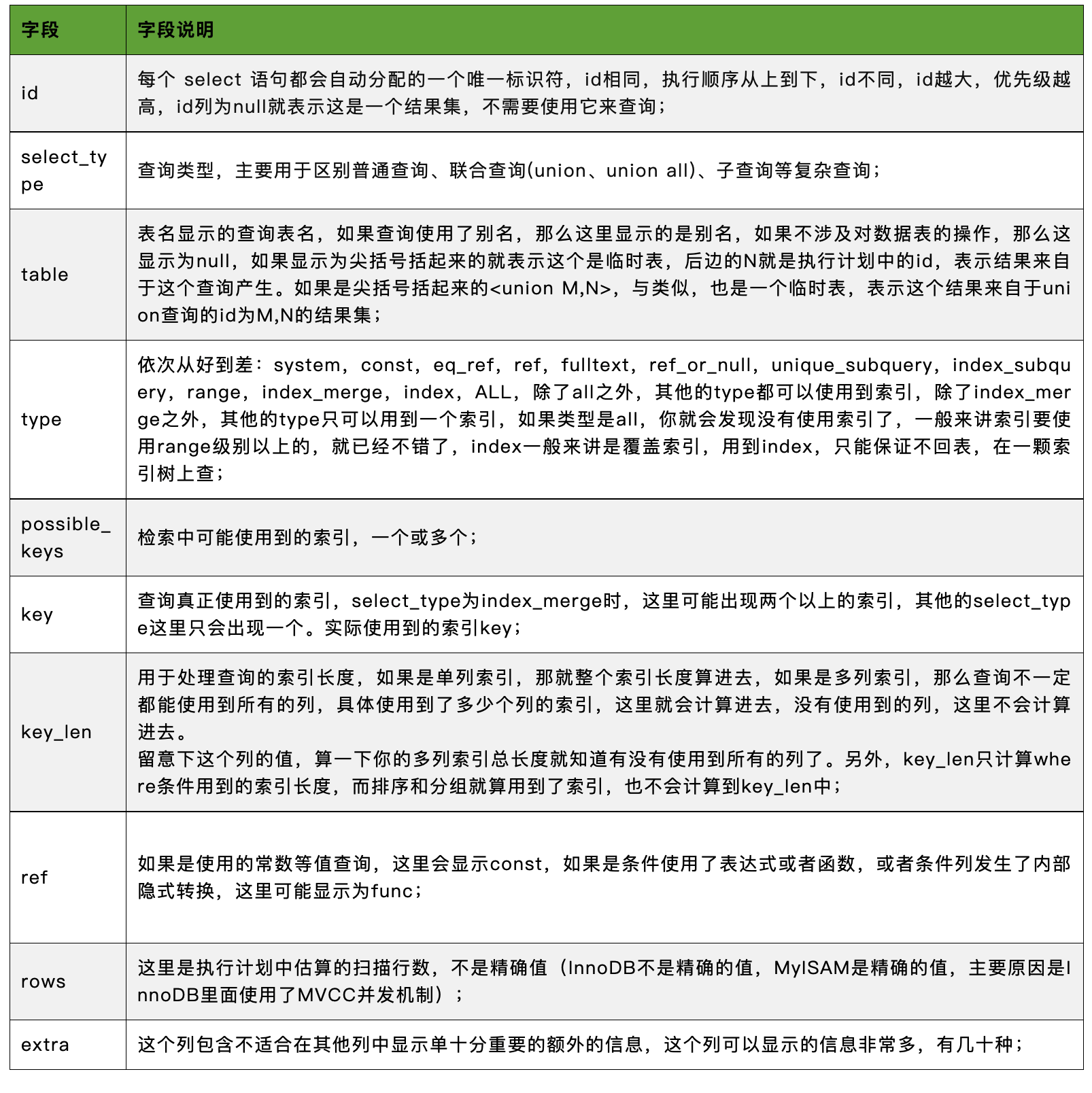
其中, type 的常见取值如下:

extra 常见取值如下:

如何优化查询性能?
慢查询通常是缺少索引,索引不合理或者业务代码实现所致。
1.slow_query_log_file 开启并且查询慢查询日志
2.通过 explain 排查索引问题
3.调整数据修改索引;业务代码层限制不合理访问
另外,如果在列上进行函数运算,将导致索引失效而进行全表扫描。
例如 :
select * from user where YEAR(birthday) < 1990查询条件中含有函数或表达式,索引失效,进行全表扫描。
可以改造成:
select * from users where birthday <’1990-01-01′参考资料
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://www.jianshu.com/p/0b1063421925
https://www.modb.pro/db/50686
https://blog.csdn.net/Abysscarry/article/details/80792876
https://blog.csdn.net/Edwingu/article/details/6680451
https://houbb.github.io/2019/01/02/db-index-07-combine-index
https://www.ibm.com/docs/zh/informix-servers/12.10?topic=use_composite_indexes
https://www.wuguangping.com/a/MySQL-lian-he-suo-yin-zui-zuo-pi-pei-yuan-ze.html
相关文章

触摸精灵 关于三剑豪手游的练级(练到10级) 制作 请大家帮忙一下!!谢谢大家了
MySQL的order by该如何避免“未命中索引“

Java岗大厂面试百日冲刺 - 日积月累,每日三题【Day7】 —— 数据库2(事务)

深夜小酌,50道经典SQL题,真香~
实战案例:使用Python制作疾风剑豪-亚索词云图
