背景:
在流量存量时代,内容运营重要性不言而喻。在流量时代,内容可以不要过于多样化和差异化,只需要有足够多的人流量,按流量转化比率来看,1000个人有1%概率转化,素材不变只要增加足够多的流量那就一定会有收益。所以在流量时代,运营提出的打法就是“黑客增长”,所谓流量漏斗、如何引入更多用户进来是重点。但在流量的存量时代,用户流量已经不可能无法线性增长,已经不存在或者只有很少部分的用户是没有被覆盖的。那么如何提高用户访问次数、素材和用户匹配概率就是增长的路径;上面两个增长路径其实都会涉及到能够促达用户的素材质量和素材量。只有素材足够多足够个性才有可能有足够概率满足用户的喜好,如此才可能让用户的访问次数增加、让用户对素材的匹配概率增加。
用户素材消费量 = 用户数*用户访问次数*素材和用户匹配概率 素材和用户匹配概率 = 用户访问次数*素材数量*素材差异度概率*素材-用户喜欢概率
通过对运营增长的建模数据分析,我们可以看到在存量增长时代内容运营的重要性,内容运营中高质量内容的重要性,要有绝对数量的高质量内容一定基数的内容数量是必须的。为了支撑内容化运营,AIGC应该能够快速方便的构建出活动运营需要的物料,确保物料的种类多样些、每种物料有足够数量、有更多可促达用户的玩法手段,物料能够更自动化的构建、过审、上线、效果评估。
玩法多样化:
除了现在常规的静态图文运营,可以融合更多样化玩法,比如游戏互动、SVG动图展示、动效展示、动漫化讲述内容、基于code生成方式低代码可视化展示、活动页构建
运营自动化:
在内容生产过程,需要更少的运营人员参与,产出内容能够保证更好调性、更高过审率、能够更自动化的根据线上数据迭代素材产出
物料多样化:
根据人、货、场、时空、事件创作更多元粒度的物料
同类物料数量保证:
同一类的物料有更多条内容物料数据可供选择
创作产品化:
现在交互方式更多是通过线下和运营沟通方式来生成,不利于内容沉淀和能力沉淀。可以抽象出合适输入、输出,通过产品来收集用户需求产出用户投放素材。方便内容数据沉淀和能力迁移。
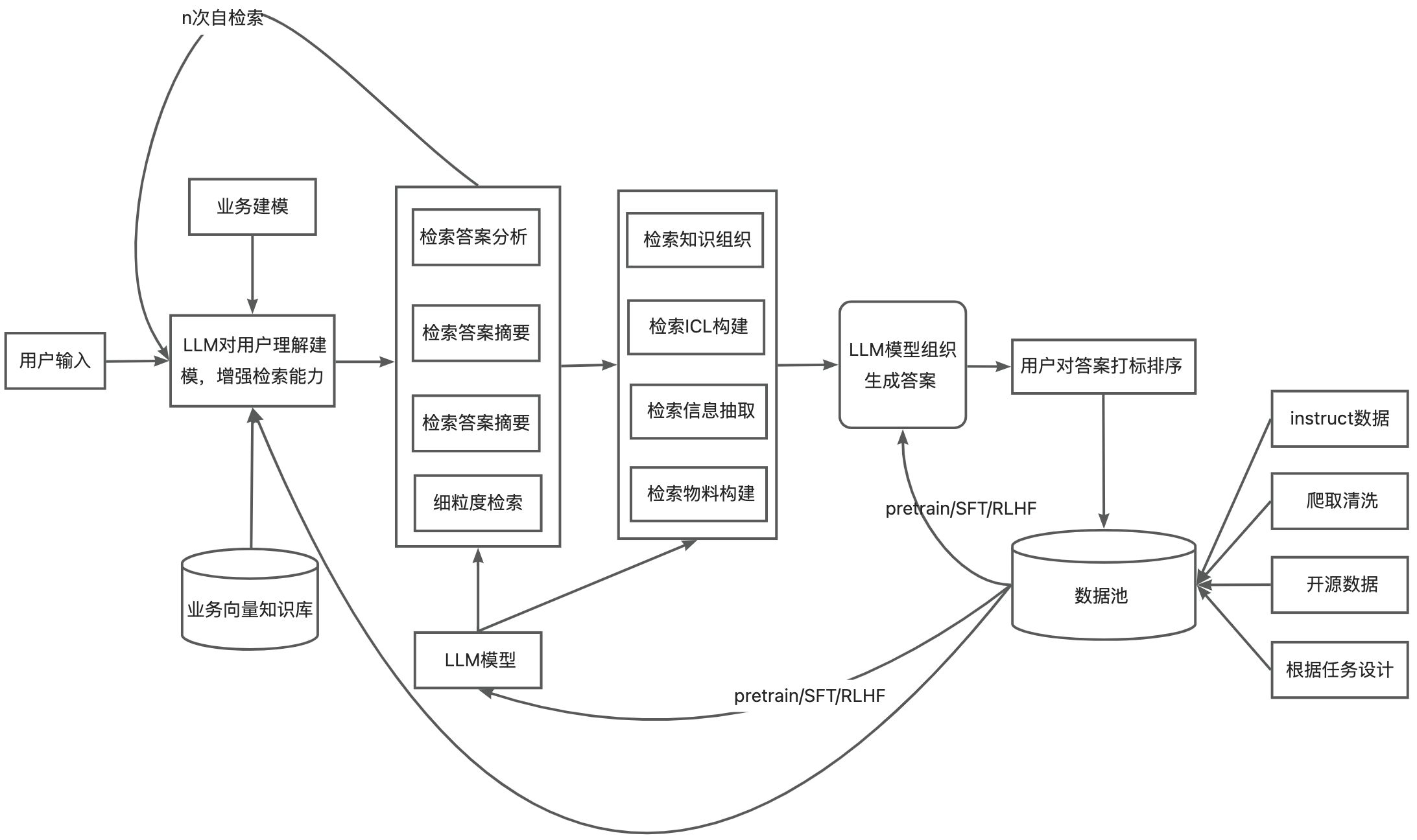
构建基于LLM大模型的内容生成系统
单个的LLM模型能力往往是不足以支撑在具体业务实现可控精准内容生成的。为了更好的产出物料,我们是必须要去围绕LLM的能力来构建一套系统更好的服务业务。对于这一套系统应该要具备一定的抽象和迁移能力,肯定不能够一个业务场景一套系统,一种交互方式。应该是一个产品形态一套交互方式就能适配各种的业务场景。
下面是我们对这套系统能力做的抽象:
理解输入:对用户多样化和差异化的输入做理解,根据用户输入理解选择合适的生成流程
业务建模:对不同的业务形态建模,构建业务知识框架,可以方便业务输入较少信息,自动化补齐业务没交代,实际必须知道的信息
流程选择:根据业务需求、用户输入,通过策略模型选出适配的物料生成流程
检索物料:用户信息输入往往会默认很多信息我们是知道的,这时候最好的方法就是通过用户输入把一些用户没告诉的默认领域信息补齐,减少沟通成本,提高对业务理解深度和准确性
组织物料:根据对用户输入理解,对领域知识补齐,召回更多更丰富信息后,需要对这些信息可能的搭配组合做筛选组织,生成多样化且符合业务逻辑的物料
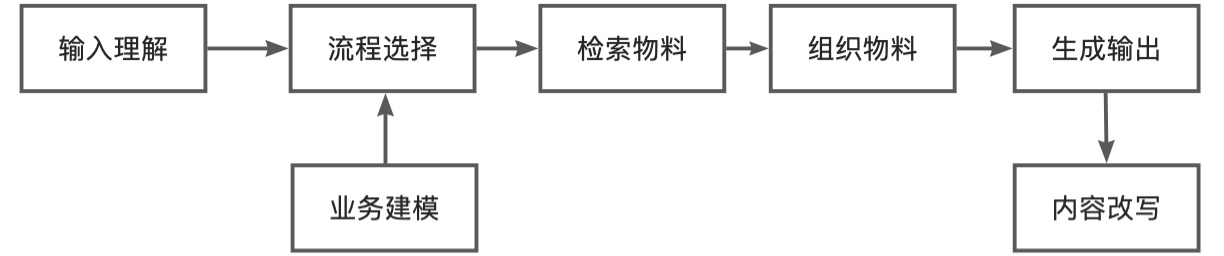
底下图,是对上面的抽象系统能力做的一个基于LLM模型构建的更具象化的事例。
文案生成类型
根据输入信息判断是什么类型的文案生成,不同类型的文案生成所需要的输入信息和处理的流程是不同的。
这部分的工作是需要抽象和总结出现在常用的几种文案差异。比如:
1.公域文案,要求比较严苛,只能在给定关键词基础上,做文案增删改增加多样性
2.给定产品描述,抽取总结关键卖点,给予卖点作为论点论据包装差异化人群场景文案
3.UGC、PGC约束更小的吸引力内容文案
文案生成的流程
根据不同文案生成的特点抽象出文案生成需要的流程链路。
根据输入信息补充数据(这个是流程差异化重点环节)
个环节数据补充
输入信息结构化组织
文案生成(prompt个性化)
文案改写(参考例子或者文案创作来改)
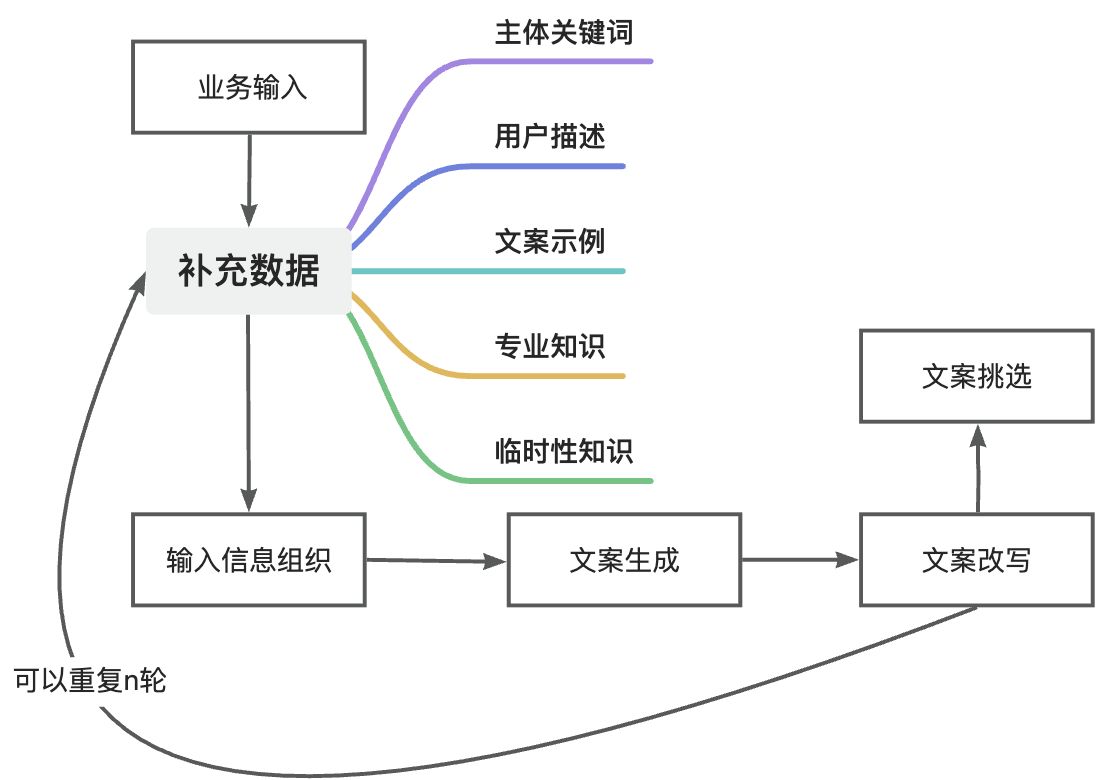
数据收集部分
生成需要什么信息
现在有什么信息
需要补什么信息
从哪补这些信息
为了补这些信息需要什么前置准备(数据库、知识库、临时数据输入)
数据组织部分
为了生成文案,需要的数据都收集齐了。接下来的任务就是该如何把这些信息组织起来,送入到我们文案生成的工序流程。
数据组织原则:这些数据是作为生成的参考还是作为生成的原料参与;如果是作为参考,参考什么如何让他们在生成中发挥参加的作用;如果是作为生产原料,那么这部分东西该如何参与生成,如何控制生成质量
数据组织结构:输入信息的如何组织一定是围绕要达成的目的来设计的,有什么输入要达成什么目的如何设计才能让llm生成复合要求的文案
数据组织参考:组织的参考是说,我们有没一些历史经验可以作为数据组织结构参考,或者说用户是否可以给我们一些文案,为什么这么设计文案好的一些说明
文案生成的工序
根据约束制定控制点(哪些词必须出现、哪些词必须能不能出现、文案调性、参考例子)
构建prompt生成文案
生成文案增删改修复流程
文案验收
构建更强大的LLM能力
大模型火之前专业模型其实已经能够很好的配合做很多很复杂的事情。如果只是从提高工作效率的角度来讲应该是发展模型的专业问题解决能力,往单一技能深度去做就好了,理论大的通用的能力模型应该是没有什么市场的。为什么这么说呢,直观讲我们要解决的事是把某一专业技能的事做好,而如果我的做法是去提高模型的各方面的通用能力,这似乎很不符合投资收益的要求。其实事实呢,也确实是大部分的企业就是在想怎么把模型单件事情的能力提高。而并未考虑如何提高模型综合能力,如何去实现所谓的AGI,只有一些科研实验室在做这件事。
但是其实我们静下心来看这件事,可以很明显的感知到所谓的专业技能的事需要专业技能就行。但是其实有哪些技能是完全专业的呢,所谓专业无外乎就是对某一件事提出了一个定制化的解决方案,但底层的能力其实都是通用的几种能力。也就是说某件事的专业与否,专业的只是为了解决这件事定制的方案和流程,而非底层能力的专业。如此你要提高某件所谓专业事的解决方案或者提高解决这件事的效率,方法无非有二:1.提高对这件事的认知,提出更妙的解决流程方案 2.提高底层的解决事情的能力,每个能力的提升上层流程就是这些能力组合。
其实如果反观大模型的技术迭代也是如此演进的,所谓数据样本不够提出自监督、无监督学习、所谓的迁移学习能力,所谓元学习,其实背后的思路都是底层能力事一样的,定制化的事解决事情的流程和方案。所以我们可以迁移学习(底层能力迁移),才可以自监督、无监督学习(数据自含结构,结构自带能力)。
上面用了一段的描述介绍了大模型出现的必然,也讲出我自己对大模型和专用模型的差异定义:专用模型只是对某件事专业流程和方案(把能力固化在解决方案);大模型其实就是把一些通用能力抽象出来需要模型同时具备这些能力,同时可以根据不同情况需要模型能够组合出解决问题流程方案适配具体事情,根据人类需要精调流程参数给出符合人类期望的答案。
也就是说大模型之大在于:
1.模型具备通用解决问题的各种能力
2.模型具备对具体事情适配解决流程方案能力
3.模型具备根据人类需要精调参数能力
4.大模型已经把能力分层了,并且可以有机组合
大模型设计:
上面只是介绍了一个宏观的大模型的几层能力架设,那么该如何让模型具备这些能力呢。又该如何设计这些能力,如何通过任务设计、数据收集和模型训练让模型这些能力可以逐步增强呢。
上面提到的三层能力,其实通过大模型的一些论文我们可以看到:通用能力就是通过pretrain来实现;根据事情适配出解决事情的方案流程,合理搭配各种能力是通过SFT来实现;具备人类需要精调能力事通过RLHF来实现。具体如何去构建任务、构建数据集、构建哥能力数据集比例训练模型,放在下面环节来介绍。
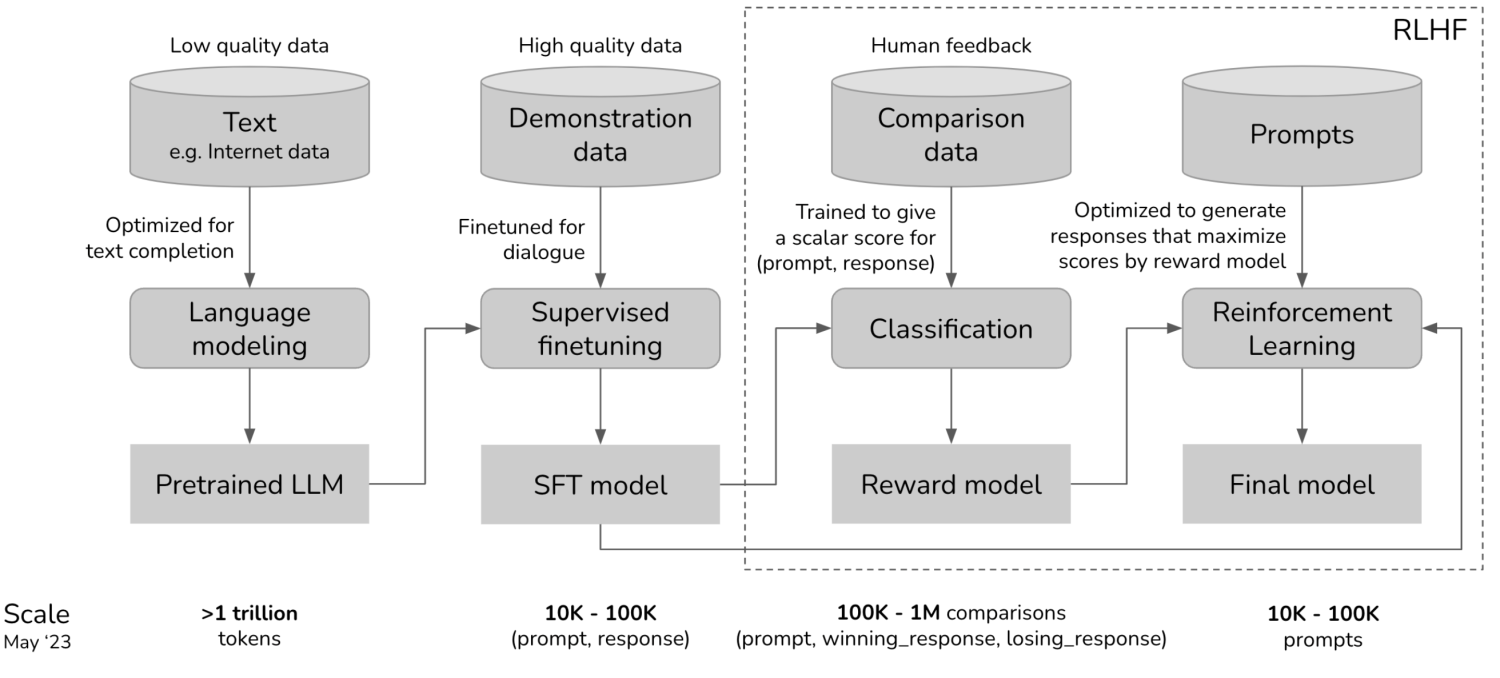
构建通用能力——pretrain model
考卷为什么要设计成:填空题、判断题、完形填空题、阅读理解、申论、概念理解、计算、推理。其实这对应的就是解决事务性问题需要具备的一些基本能力,所以如果要让模型更好的理解世界、有能力解决事情,应该也是需要具备这些能力的。
上面提到的一些能力很可能不是最细粒度的能力,甚至他们可能不一定是在一个粒度的能力。所以我们对上面的一些能力做抽象总结,提出了下面的6种能力,有了这六种能力,对这些能力组合理论上说可以解决人类生活中大部分问题。
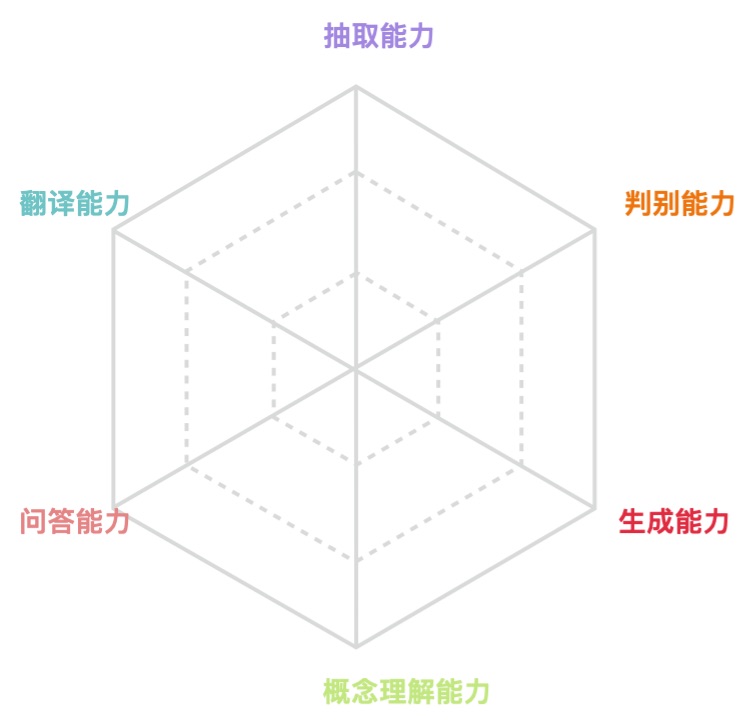
生成能力:少到多生成,生成、联想
抽取能力:多到少,摘要、观点抽取
判别能力:分类、NER
概念理解能力:定义、理解、常识概念
问答能力:这其实需要综合上面一些能力,阅读理解、填空
翻译能力:这其实需要综合上面能力
如何构建这些能力:
任务设计
根据input输入,包括能力类型、输入上下文、生成prompt,做前向文案生成,或者做任意位置文案生成
数据准备
"填空":{"input": "心理学领域的研究人员发现,做出重要决定的最好方法之一,比如选择一所大学或<mask_0>,都涉及到使用决策工作表。研究优化的心理学家将<mask_1>与理论理想决策进行比较,看看它们有多相似。工作表程序的支持者认为它会产生最优的,也就是说,最好的决策。虽然有<mask_2>可以接受,但它们在本质上都是相似的。","<ans>":{"<mask_0>":"","<mask_1>":"","<mask_2>":""}},
"文本生成": {"input": "今天天气很好,我和妈妈一起去公园,", "prompt": "往后写约100字", "<ans>": ""}
"翻译": {"input": "北京是中国的首都", "prompt": "中翻英", "<ans>": ""}
"问答": {"input": "NGC 6231是一个位于天蝎座的疏散星团,天球座标为赤经16时54分,赤纬-41度48分,视觉观测大小约45角分,亮度约2.6视星等,距地球5900光年。NGC 6231年龄约为三百二十万年,是一个非常年轻的星团,星团内的最亮星是5等的天蝎座 ζ1星。用双筒望远镜或小型望远镜就能看到个别的行星。NGC 6231在1654年被意大利天文学家乔瓦尼·巴蒂斯特·霍迪尔纳(Giovanni Battista Hodierna)以Luminosae的名字首次纪录在星表中,但是未见记载于夏尔·梅西耶的天体列表和威廉·赫歇尔的深空天体目录。这个天体在1678年被爱德蒙·哈雷(I.7)、1745年被夏西亚科斯(Jean-Phillippe Loys de Cheseaux)(9)、1751年被尼可拉·路易·拉卡伊(II.13)分别再次独立发现。", "question": "NGC 6231的经纬度是多少?", "<ans>": ""}
"评分预测": {"input":"之前多次聚餐都选择这里,有各种大小的包房同时能容纳很多人,环境好有特色还有表演,整体聚餐氛围一下被带动起来。现在由于炭火改成了电烤羊,口感真的不如从前,不过其他菜品都还是不错,烤羊剩下的拆骨肉最后还能再加工一下椒盐的也很好吃。","question":"评分是多少?(1-5)","<ans>":""},
"选择题": {"input": "父母都希望自己的孩子诚实、勇敢、有礼貌。要想让孩子成为这样的人,父母首先得从自己做起,要是连自己都做不到,又怎能要求孩子做到呢?", "options": {"<option_0>": "少提要求", "<option_1>": "降低标准", "<option_2>": "自己先做好", "<option_3>": "让孩子拿主意"}, "question": "教育孩子时,父母应该:", "<ans>": ""}
"生成":{"input":"中华文明源源流长","prompt": "往后续写100字","<ans>":""},
"生成":{"input":"中华文明源源流长","prompt": "改写文案","<ans>":""},
模型训练
收集大量数据。这是我们称之为数据混合的示例,该示例来自 Meta 发布的这篇论文,他们发布了这个 Llama 基础模型。
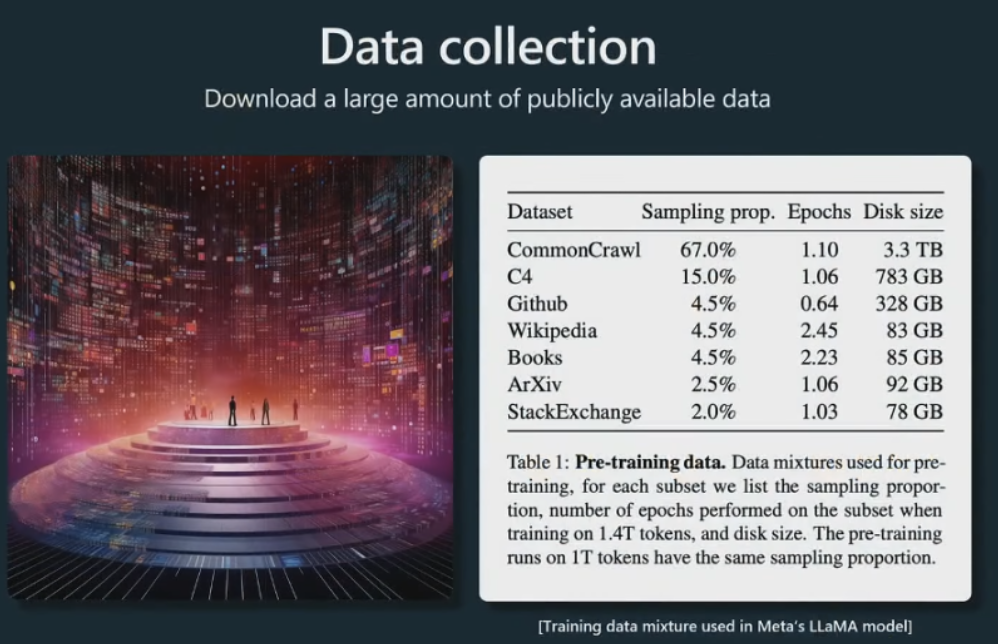
common crawl,然后还有一些高质量的数据集。例如,GitHub、维基百科、书籍、ArXiv论文存档、StackExchange问答网站等。这些都混合在一起,然后根据给定的比例进行采样,形成 GPT 神经网络的训练集。

实际训练这些数据之前,我们需要再经过一个预处理步骤,即标记化(tokenization)。标记化是文本片段和标记与整数之间的一种无损转换,这个阶段有许多算法。通常您可以使用诸如字节编码之类的东西,它迭代地合并小文本块并将它们分组为标记。然后这是将实际馈入Transformer的原始整数序列。
一般来说,我们将获取我们的标记并将它们放入数据批次中。

有这些数组将馈入Transformer,这些数组是 B,批量大小,这些都是按行堆叠的独立示例,B 乘以 T,T 是最大上下文长度。在我的这个图里,长度只有十个,实际工作里这可能是 2,000、4,000 等等。这些是非常长的行。
我们所做的是获取这些文档并将它们打包成行,然后用这些特殊的文本结束标记将它们分隔开,基本上是为了告诉Transformer新文档从哪里开始。
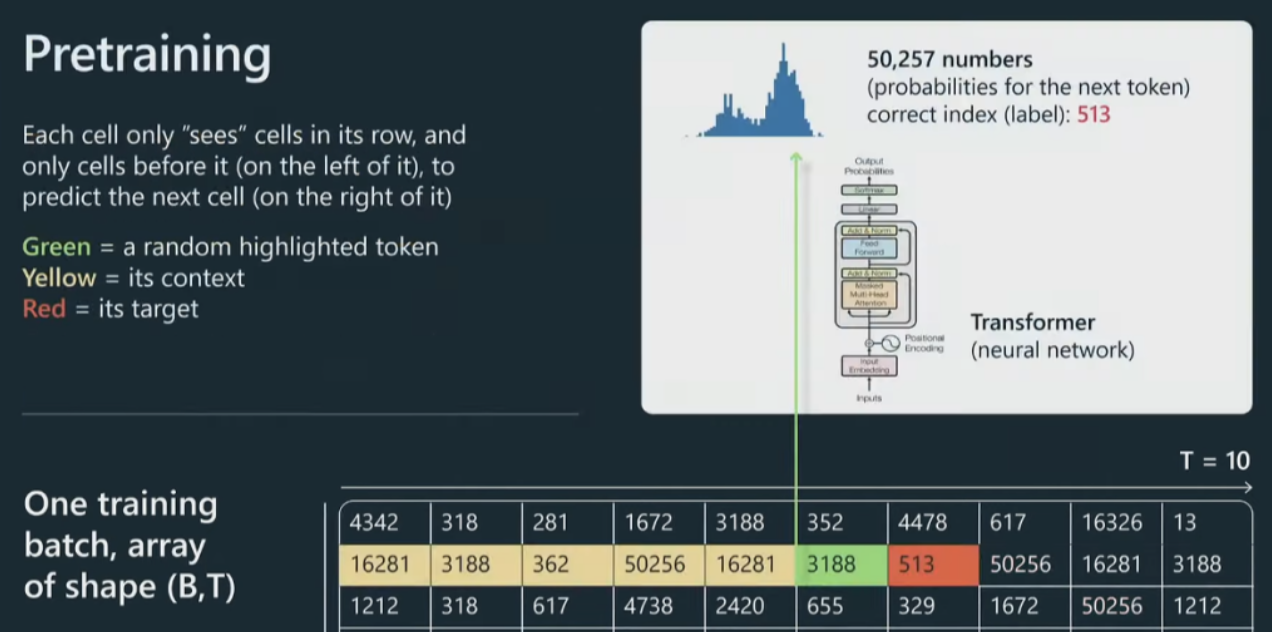
然后将它们扩展到这个输入中。现在,将把所有这些数字输入到 Transformer 中。在这我们只关注一个特定的单元格,但同样的事情会发生在这个图中的每个单元格上。
让我们看看绿色单元格。绿色单元会查看它之前的所有标记,所有标记都是黄色的,我们将把整个上下文输入到 Transformer 神经网络中,Transformer 将尝试预测 序列中的下一个标记,在本例中为红色。
对于我们的目的来说,Transformer只是一大堆神经网络的东西,通常有几百亿个参数,或者类似的东西。当然,当您调整这些参数时,您会得到这些单元格中的每一个单元格的预测分布略有不同。
例如,如果我们的词汇表大小是 50,257 个标记,那么我们将拥有那么多数字,因为我们需要为接下来发生的事情指定概率分布。基本上,我们有可能发生任何事情。
现在,在这个特定的例子中,对于这个特定的单元格,513 将是下一个标记,因此我们可以将其用作监督源来更新Transformer的权重。将同样的做法应用于并行中的每个单元格,并且不断交换批次,并且试图让Transformer对序列中接下来出现的标记做出正确的预测。
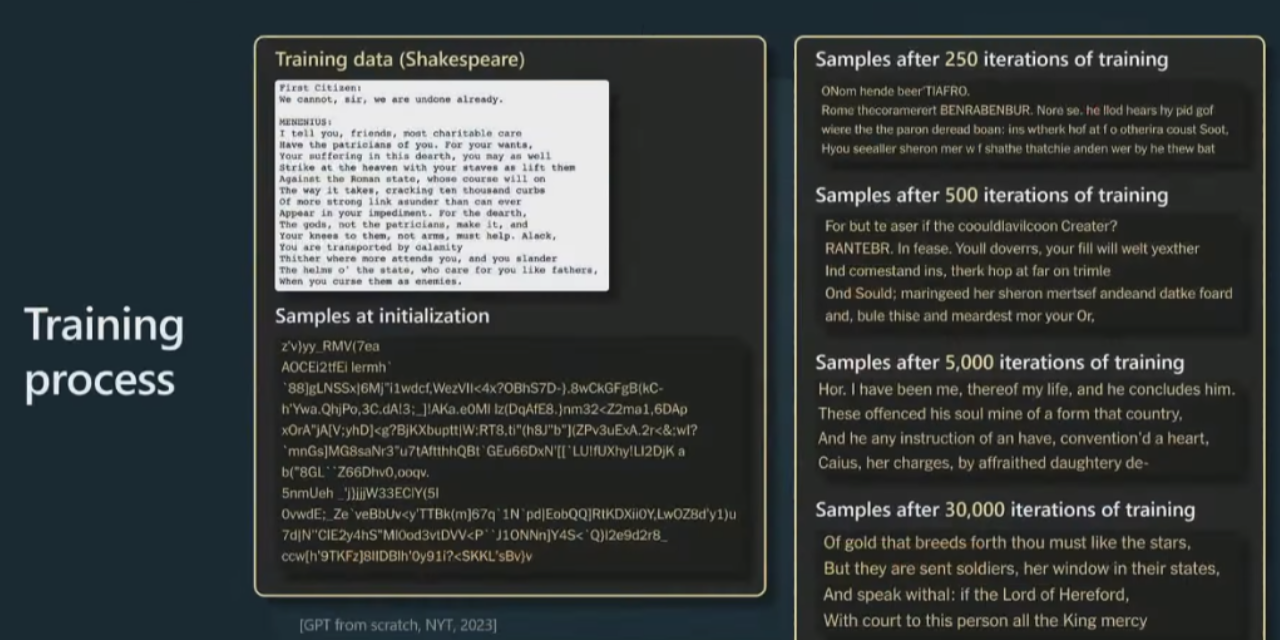
更具体地展示当您训练其中一个模型时的情况。一开始,在初始化时,GPT 以完全随机的权重开始,因此也将获得完全随机的输出。但是,随着时间的推移,当训练 GPT 的时间越来越长时,我们会从模型中获得越来越连贯和一致的样本。
当然,你从中抽样的方式是预测接下来会发生什么,你从那个分布中抽样,然后不断将其反馈到过程中,基本上就是对大序列进行抽样。到最后,你会看到 Transformer 已经学会了单词,以及在哪里放置空格,在哪里放置逗号等等。
随着时间的推移,模型正在做出越来越一致的预测。
训练一个月后,我们将如何处理这个模型?在这个领域,这些模型基本上在语言建模过程中学习了非常强大的通用表示,并且可以非常有效地微调它们以用于您可能感兴趣的任何下游任务 .(gpt2前做法)
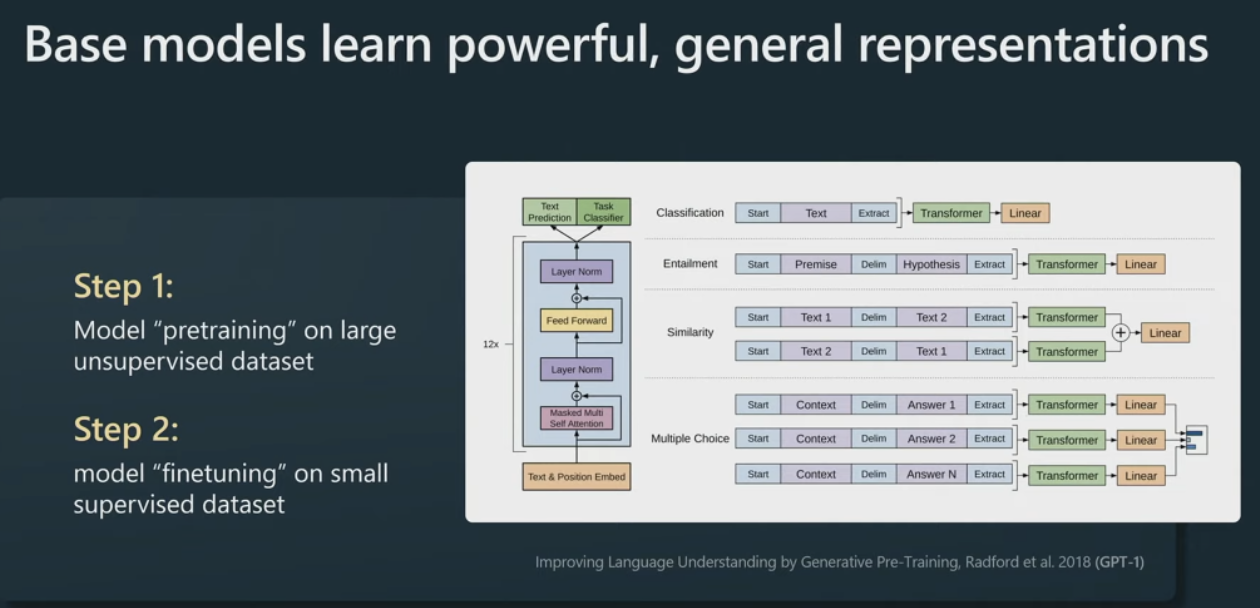
举个例子,如果对情感分类感兴趣,过去的方法是收集一堆正面和负面的信息,然后为此训练某种 NLP 模型,
但新方法是忽略情感分类,直接去进行大型语言模型预训练,训练大型Transformer,然后你可能只有几个例子,已经可以非常有效地为该任务微调你的模型。这在实践中非常有效。
这样做的原因基本上是 Transformer 被迫在语言建模任务中同时处理大量任务,因为就预测下一个标记而言,它被迫了解很多关于文本的结构和其中所有不同的概念。这就是 GPT-1。
在 GPT-2 后,人们注意到比微调更好的是,你可以非常有效地提示(prompt)这些模型。这些是语言模型,它们想要完成文档,所以你可以通过排列这些假文档来欺骗它们执行任务。
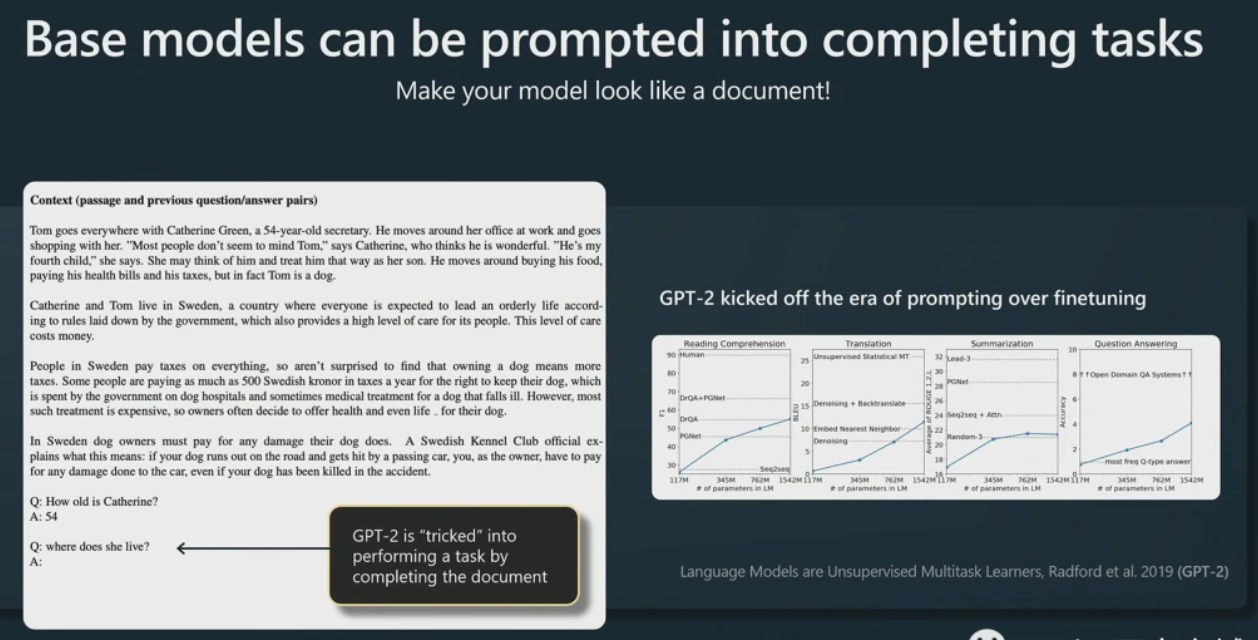
在这个例子中,例如,我们有一些段落,然后我们做 QA(问和答),QA,QA,几次提示,然后我们做 Q,然后,当 Transformer 试图完成文档时,它实际上是在回答我们的问题。
这就是一个提示工程(prompt engineering)基础模型的示例,通过提示工程让模型相信它正在模仿文档并让它执行特定的任务。
这开启了提示高于微调(prompt over finetuning)的时代。我们看到,即使没有对任何神经网络进行微调,它也可以在很多问题上非常有效。
构建能力组织能力——SFT
有了一个有各种通用能力于一身的通用大模型,接下来的工作就死如何让他去按人类的需求去做事了,或者说如何让模型理解人类的需求去做事。从预训练模型到听懂人话去做事,让模型产出结果看起来还是不错。这中间其实是有两个事情:1.理解人类意图,懂你输入的话是要他干嘛 2.能够整合他的基础能力给出结果;要实现这两种能力就需要SFT这个过程来实现。
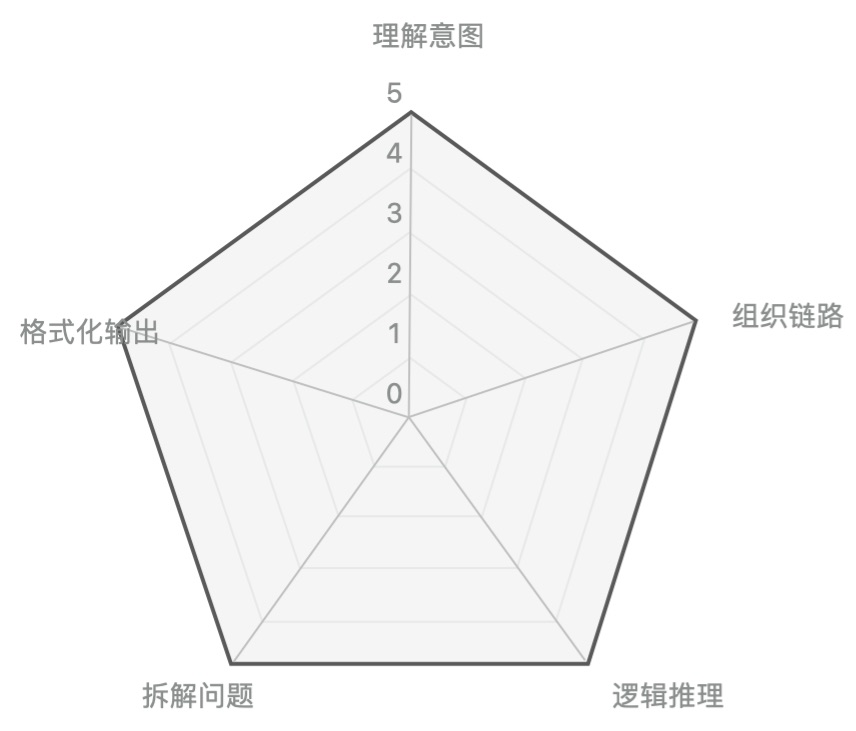
这个阶段需要模型具备能力:
1.意图理解能力:理解人类输入问题的意图
2.组织链路能力:根据问题组织各种能力生成结果
3.逻辑推理能力:根据上下文输入做问题推理能力
4.拆解问题能力:思维链,把一个复杂问题拆解成多个小问题流程
5.格式化输出能力,根据人类意图输出需要的结构
如何实现这些能力
任务设计
通过上下文、指令、输入构建结构化prompt,生成需要的输出结果
数据准备
{"instruct":"请基于给定的场景续写一段合理的对话。" ,
"input":"你是苏州人,但不怎么出去玩。你朋友来苏州找你,你准备带他逛逛“水乡古镇”,你希望客服给你推荐个消费水平“中等”的地方。然后你要问清楚这地方“是否地铁直达”、“特点”、“门票价格”这些信息。最后,你要感谢客服的帮助,然后说再见。" ,
"Ans":
"human: 你好,我是苏州人,但是不怎么出去玩,我朋友来苏州找我了,我准备带他逛逛水乡古镇,你能帮我推荐一下吗? gpt: 推荐您去周庄古镇。 human: 我希望这个地方消费水平适中的,这个是中等的吗? gpt: 这个不是,我又重新帮您找了一家山塘街。 human: 听这地方应该挺好玩,他们家特点是什么? gpt: 特点是欣赏苏州老城风貌,参观会馆等古迹,乘游船,拍摄美丽的夜景。 human: 听起来很不错,他们家门票是多少? gpt: 门票免费。 human: 还行,那他们家是否有地铁直达呢? gpt: 嗯嗯,可以地铁直达。 human: 谢谢你的帮助,再见! gpt: 再见。 "}
{"instruct":"math",
"input":"This math problem has got me stumped: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? Can you show me the way?" ,
"Ans":"Natalia sold 48/2 = 24 clips in May. Natalia sold 48+24 = 72 clips altogether in April and May."}
{"instruct":"1/7:1/7:1/14 = 2:2:1\n1/5*5600 = 1120\n2240-1120 = 1120 The final answer: (C)." ,
"input":"",
"Ans":"Question: Rs. 5600 is divided into three parts A, B and C. How much A is more than C if their ratio is 1/7:1/7:1/14?\nOptions:\n(A) 300\n(B) 992\n(C) 1120\n(D) 552\n(E) 312 Let's think first. Some random reasoning:"}
模型训练
在有监督的微调阶段,我们将收集少量但高质量的数据集。在这种情况下,我们要求人工承包商收集及时和理想响应形式的数据。我们收集很多这样的东西,通常是类似数万个这种数量。然后我们仍将对这些数据进行语言建模,因此算法上没有任何改变。
我们只是换出一个训练集。它曾经是互联网文档,那是一种量很大但质量不高的数据,我们换成用QA即时响应的数据。那是低数量但高质量的。我们还是做语言建模,然后,训练之后,我们得到一个SFT(Supervised Finetuning 监督微调)模型。你可以实际部署这些模型,它们是实际的助手,它们在一定程度上起作用。
为了支持大模型的高效微调,有下面几类的微调方式:
- 增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
- 选取一部分参数更新,如:BitFit。
- 引入重参数化,如:LoRA、AdaLoRA、QLoRA。
- 混合高效微调,如:MAM Adapter、UniPELT。
P-Tuning v2
该方法在每一个Transformer层都加入了prompt token作为输入,引入多任务学习,针对不同任务采用不同的提示长度。并且回归传统的分类标签范式,而不是映射器。
特点:
- 解决了Prompt Tuning无法在小模型上有效提升的问题。
- 移除了对模型效果改进较小的重参数化的编码器(如:Prefix Tuning中的MLP、P-Tuning中的LSTM)。
- 对于一些复杂的硬序列标记任务(即序列标注)取得了不错的效果。
LoRA
该方法通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
特点:
- 将BA加到W上可以消除推理延迟。
- 可以通过可插拔的形式切换到不同的任务。
- 设计的比较好,简单且效果好。
AdaLoRA
对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
QLoRA
使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
特点:
- 使用 QLoRA 微调模型,可以显著降低对于显存的要求。同时,模型训练的速度会慢于LoRA。
结合上面SFT手段特点,我们后续SFT会选用P-Tuningv2,Lora、Adaptor-lora做模型训练。
1.超参数的设置
2.监控模型训练,确保收敛
3.模型参数可视化确保模型没有过拟合
4.模型能力验证确保模型在实际任务的综合表现
构建适配人类能力——RLHF
SFT完的模型理论上已经能够完成大部分的工作了,那么为什么还有来一道RLHF的操作呢。其实很简单,SFT完的模型对一些精细的操作还是不符合人类预期的,也就是说还比较机械。那么对于一些更精细操作要怎么解决呢,比如幻写、又伤害的内容、种族内容,这些内容生成出来理论都是对的,只是不符合道德约束。最简单的解决方法就是学习人类的行为,看看人类是如何来处理这些内容的。这就是RLHF工序的原因,当然这只是RLHF的一种用法,后续是否会把这种能力直接用来在SFT过程、在pretrain过程,其实也未尝不可,只要有更高ROI。
如何实现这些能力
任务设计
通过模型生成答案,然后通过人类排序方式来准备数据,排序数据训练RM模型;训练好RM模型后用PPO方式来训练模型。
数据准备
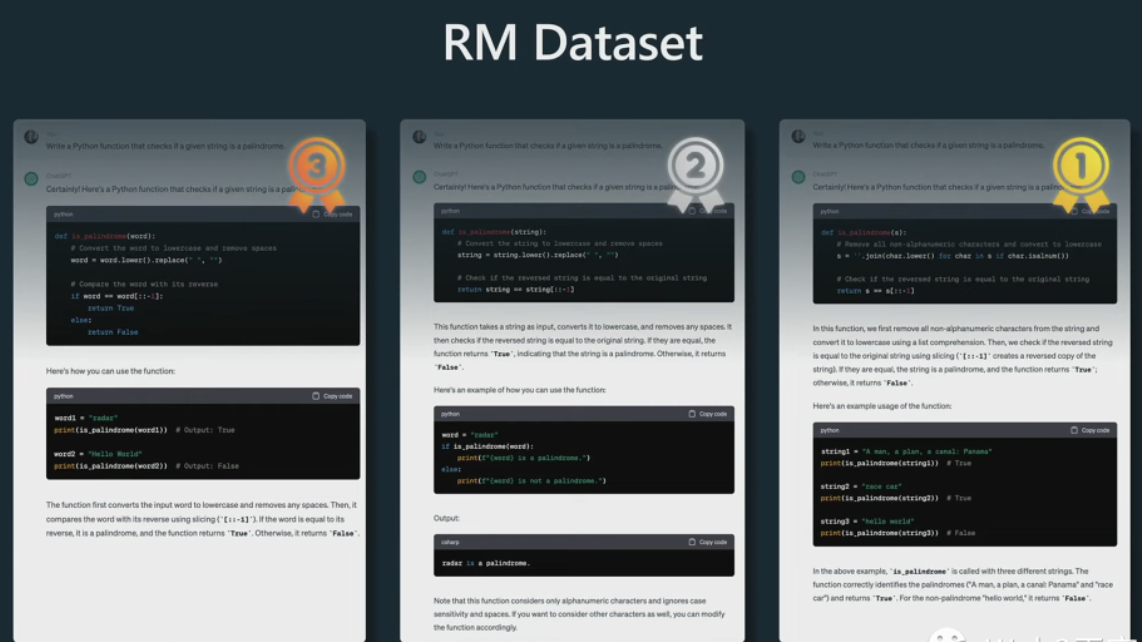
RM排序数据集的示例。
顶部是相同的提示,它要求助手编写一个程序或一个函数来检查给定的字符串是否为回文。然后我们做的是采用已经训练过的 SFT 模型,并创建多个补全。在这种情况下,我们有模型创建的三个补全。然后我们要求人们对这些补全进行排名。
模型训练
要比较其中的一些预测是非常困难的事情,而且这可能需要人们甚至几个小时来完成一个提示补全的比较。但假设我们决定,其中一个比其他的好得多,依此类推,我们对它们进行排名。然后,我们可以对这些补全之间的所有可能对,进行看起来非常像二元分类的东西(以进行排序)。
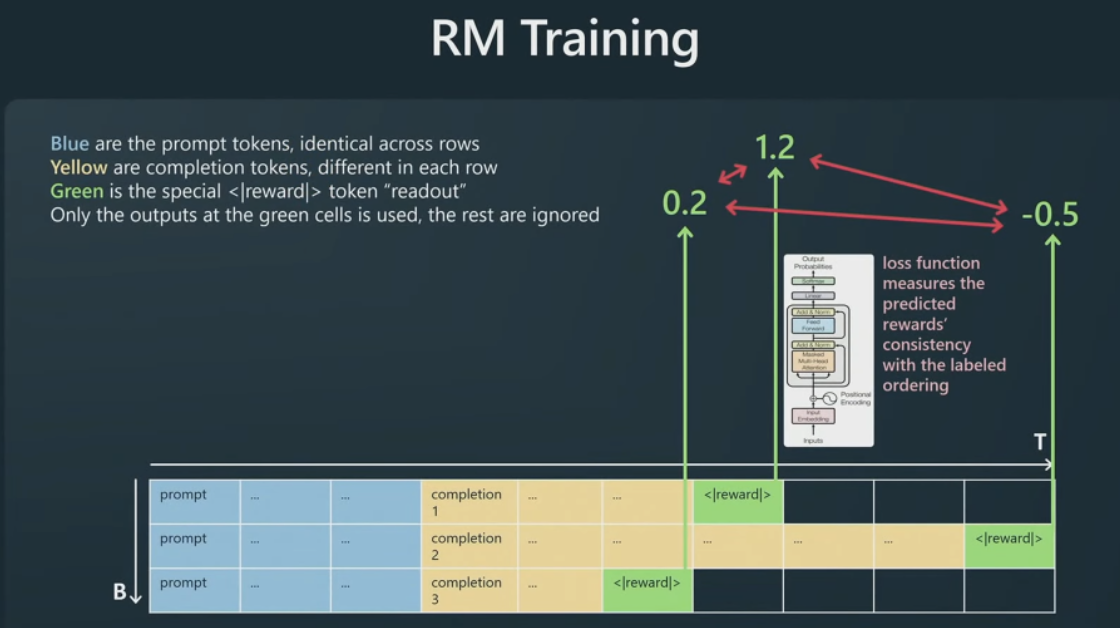
接着,要做的是将提示按行排列,这里所有三行的提示都是相同的,但补全方式不同,黄色标记来自 SFT 模型,我们在最后附加另一个特殊的奖励读出标记,基本上只在这个单一的绿色标记上监督Transformer。Transformer会根据提示的完成程度预测一些奖励。
Transformer对每个补全的质量进行了猜测,然后,一旦对每个补全进行了猜测,我们就有了模型对它们排名的基本事实,而我们实际上可以强制其中一些数字应该比其他数字高得多,我们将其制定为损失函数,并训练我们的模型,使得模型做出与来自人类承包商的比较事实数据相一致的奖励预测。
这就是我们训练奖励模型的方式。这使我们能够对提示的完成程度进行评分。
有了奖励模型,但我们还不能部署它。因为它本身作为助手不是很有用,但是它对于现在接下来的强化学习阶段非常有用。因为我们有一个奖励模型,所以我们可以对任何给定提示(prompt)的任意完成/补全(completion)质量进行评分。我们在强化学习期间所做的基本上是再次获得大量提示,然后针对奖励模型进行强化学习。
这就是它的样子:

我们接受一个提示,将其排成行,现在我们使用想要训练的模型,将该模型初始化为 SFT 模型,以创建一些黄色的补全。
然后,再追加奖励标记,按照已经固定不变的奖励模型读出奖励分数,现在这个奖励模型的评分不再变化。奖励模型告诉我们这些提示的每一次完成的质量。
我们现在基本上可以用(和前面)相同的语言建模损失函数,但我们目前正在对黄色标记进行训练,并且我们正在通过奖励模型指示的奖励来权衡语言建模目标。
例如,在第一行中,奖励模型表示这是一个相当高的完成度,因此我们碰巧在第一行采样的所有标记都将得到强化,它们将 获得更高的未来概率。相反,在第二行,奖励模型真的不喜欢这个完成,负 1.2,因此我们在第二行采样的每个标记在未来都会有更低的概率。
我们在很多提示、很多批次上一遍又一遍地这样做,基本上,我们得到一个在这里创建黄色标记的策略,让所有完成标记都会根据我们在前一阶段训练的奖励模型获得高分。
构架生态——工具、系统
经过上面3阶段多轮次的训练,理论上讲已经是一个很牛逼的通用大模型了。那么为什么还需要配置工具搭建系统,甚至组件组织呢。其实如果用人类社会来比喻就很好理解,个人能力很强,但如果任务复杂(时间、空间、时空耦合)那么人类的做法就是用工具,或者组件一个团队系统来功课。
对于大模型,这思路其实一样适用。具体的做法差异可以看下面概念图,这边不再展开叙述,后面会找时间单独写一篇文案来讲可以怎么做。