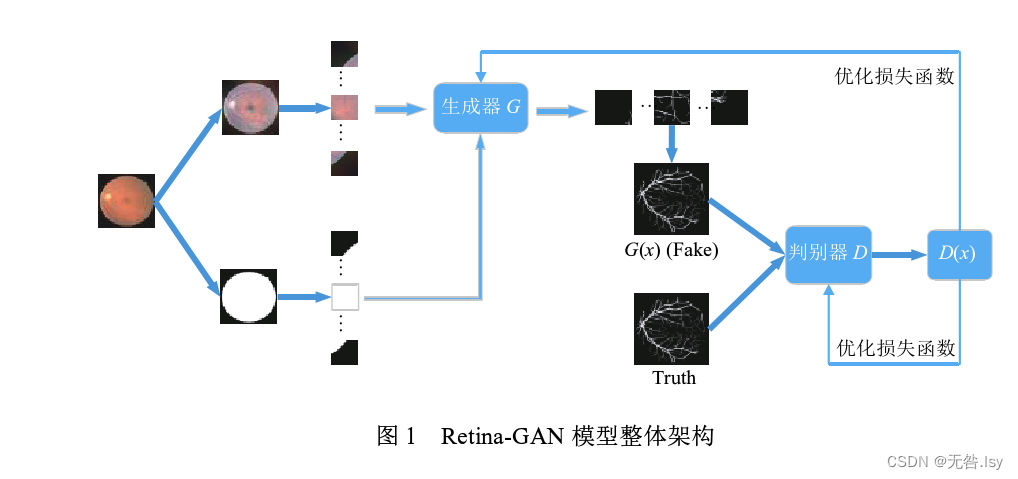
摘 要
随着图像处理技术迅猛发展,人们能够更好治疗某些疾病以及预后恢复情况的及时监控,从而使得诊疗水平得到极大的改善。 图像计算机系统的建立,可以对眼底很多组织进行定量,测量和检测,在正常和异常间做出明确鉴别,使系统的研究逐渐向标准化发展。医学图像处理是图像处理领域中的重点与难点问题之一。随着数字图像处理技术的快速发展,借助电子计算机等辅助手段,医学图像的提取方法以及图像质量都得到极大的提高。眼底视网膜图像使人体唯一可以非创伤直接观察的较深层微血管,对视网膜血管的分析研究有助于疾病的精确诊断。然而,由于视网膜血管图像的灰度分布不均匀,目标血管与图像背景的对比度低,再加上图像噪声的污染,使视网膜血管的自动分割非常困难。所以,通过建立眼底视网膜图像的计算机辅助分析系统,对眼底视网膜组织进行定量分析与定性检测,对临床眼科学的病理诊断具有非常重要的意义。
关键词 图像处理技术;血管分割;图像标配;图像连接
引言
视觉作为人类最高级感知器官,能够感知电磁波谱以内的视觉波段。图像是人类进行感知世界的视觉基础,图像信息技术的存储和分析对于人类科技发展具有重要意义。自世界第一台计算机1946年问世以来,计算机辅助操作系统应用范畴已从传统的数值计算扩展到现代社会各个领域。随着计算机科学技术的迅速发展,利用计算机进行图像处理已经成为研究重点,并逐步形成了完整的科学体系。医学图像处理作为数字图像处理的重要分支,从发展初期就占据了医学研究领域的主体地位。自1895年伦琴发现X射线后,医学图像成像技术(如计算机断层扫描技术、核磁共振成像技术等)为临床诊断提供了丰富的数据资源。通过对人体组织以及内部器官的二维或三维成像,可以有助于医生进行精确诊断及治疗。目前,医学成像分析已经成为现代医学检查、诊断以及虚拟治疗等方面的重要手段。
上世纪70年代,图像处理技术被引入到眼科学领域。通过借助计算机图形分析技术,对眼科疾病进行定量分析与诊断。眼底视网膜血管图像是人体唯一可以非创伤观察的较深层微血管,其血管真径,弯曲程度和颜色等结构变化可以反映人体高血压、糖尿病以及动脉粥样硬化等临床病理特征。常见的眼底视网膜疾病主要包括以下五种:1、血管和血管系统的病变;2、视网膜炎症;3、视网膜脱离;4、视网膜变性及营养不良;5、视网膜肿瘤。其中,基于血管和血管系统病变引起的糖尿病性眼底病变是造成人类失明的重要原因。在视力损伤前,对患者定期进行视网膜疾病筛查,能够及时发现病变,对糖尿病性视网膜疾病的治疗具有重要意义。
因此,将视网膜图像处理与计算机处理技术相结合,建立眼底视网膜图像的计算机研究系统,对眼底视网膜血管进行定量检测,有助于医生进行临床病理诊断,具体优势如下:1、进行眼底视网膜疾病辅助诊断:由于眼底照相系统拍摄角度以及范围比较大,所以能够对眼底视网膜以及视神经等疾病的病理性变化进行辅助研究和诊断;2、患者眼底视网膜疾病筛检:通过使用数字化眼底照相机,医生能够及时得到眼底视网膜彩色图片,可以方便快速的实现眼底视网膜疾病的监测,提高了早期查出率;3、建立眼底视网膜图像的动态变化图谱,通过采集不同时期患者眼底视网膜图像分析,并比较视网膜血管直径以及走向等不同特征,可以对疾病的发展行掌控。此外,通过对眼底视网膜数据库的探索,也为我国眼科学的精确诊断提供了良好的经济效益以及应用前景。
但是由于眼底视网膜血管图像获取比较模糊,造成目标血管与背景的对比度相对较低,特别是医学成像时受噪声污染,使得视网膜图像的分析诊断相对困难。由于视网膜血管的宽度变化范围较大,而且血管走向复杂,使得人工视网膜血管分割相对困难,通过计算机辅助操作系统建立视网膜分析诊断平台,不仅可以改善图像质量,而且能够进行视网膜血管的自动分割,有助于临床诊断水平的显著提高。
目前,已有很多方法提出对视网膜血管的自动分割。本文提出了新的眼底,视网膜图像自动分割算法,通过对眼底视网膜图像处理,对分割原理进行定性和定量分析,可以提高临床诊断的效率和精度。此外,对眼数据库,视网膜图形的探索也为我国眼科学诊断水平提供了良好的应用前景以及经济收益。
1.研究现状
1.1 国内外研究现状
对于视网膜图像的研究,国内外学者主要从视网膜图像血管分割、视网膜血管宽度测量视网膜图像连接技术这三个方面来展开。
视网膜图像血管分割的研究现状
通过利用数字图像分割技术对视网膜血管图像进行分割,这是诊断高血压、心脑血管病等疾病面临的首要难题。其主要是原因:视网膜位于眼球的最内层,呈球状凹面形,在临床诊断中所得到的往往是局部图像,而且获取到的图像常常表现出光照不均匀现象,于是很难用一般的直方图技术直接对血管图像进行分割。目前国外已有许多研究学者针对视网膜图像的特点提出了很多种分割方法,这些方法主要可以分为两大类:一类属于有规则的分割法,主要包括:局部自适应阈值法、血管追踪方法、基于数学形态学的方法、匹配滤波法等方法;另一类属于有监督的方法,包括:基于神经网络的方法、基于脊的血管分割法。不过由于目前国内在这一领域中的研究较晚,因此研究水平和进展也较为落后,分割结果也令人不太满意,与实际应用的要求还有较大差距,主要还是表现在血管提取精度低等方面,因此还需要根据实际应用中存在的问题和不足来对血管图像分割方法作进一步的研究。
视网膜血管宽度测量的研究现状
由于血管管径本身非常的细小,对血管管径的变化很难做出比较精确的判断,所以目前对血管宽度的测量还没有形成很成熟的方法。现有的一些方法通常由于人为的主观误差较大,很难在技术上从根本解决和排除一些量化操作所带来的主观误差。近年来,随着图形图像处理技术的引入和发展,到目前为止,出现了一些结合式屏幕显示技术,但是这种技术也很难完全排除人的主观因素,效果不是很理想,于是在临床上就迫切需要一种客观性极强的视网膜血管宽度的测量方法。
视网膜图像连接技术的研究现状
医学图像连接工作是要把多张互相对应的组织结构图像结合在一起,而这些待融合的图像往往来自于不同的图像采集设备,它们的型号、分辨率、成像角度和成像方位等等往往是不同的,所以这些图像中的相应组织都会有比较大的差异,在进行图像融合之前必须先对这些取自不同设备的图像进行配准变换处理,才能有效的实现准确的连接,所以图像连接的效果和质量,在很大程度上将依赖于图像配准工作的精度。因此,医学图像连接和融合技术的核心和关键就是图像的配准技术。近几年来,随着对图像配准技术的更深入的研究,在国内外已经出现了不少配准方法,主要可分为基于外部特征的图像配准和基于内部特征的图像配准方法。
国内外一些学者针对视网膜图像的特点提出基于图像特征的方法,如PeliE等和Park等的基于特征的序列相似检测法。其中 Becker等提出的方法是首先识别视网膜血管的分支和交叉点,然后进行自动拼接和目标跟踪,提取出交叉点,应用分层匹配方法精炼特征点对,对应的基干体素相似性的配准方法具有计算量大和受唤声干扰影响大的缺点。
1.2 研究内容
研究工作主要在视网膜血管的分割,血管网络的连接和配准等关键技术展开。
视网膜血管的分割:视网膜血管处在不均匀的背景和变化的对比度的环境之中。随着血管由耜到细的变化,血管与背景的灰度对比不断减弱。到血管末梢处,灰度对比已经变得很不明显。特别是如果考虑视网膜病变,情况会更加复杂。若直接采用图像分割中常用的阈值分割方法对血管进行分割,目标提取二值化的效果会很差。因此,血管提取算法一般都需要利用血管的某些先验知识和典型特征,包括血管的连通性和外形特征。
血管网络的连接与配准:在视网膜病变处、血管交叉处、血管末梢等位置,往往会产生误检的伪血管和漏检的断裂血管。应该以血管的中心线、方向、直径和灰度的空间连续性作为追踪依据,连接断裂的血管,去除伪目标,形成互联互通的血管网络。视网膜图像匹配进行的是多个图像之间的对齐比较,反映了不同间状态下视网膜变化的趋势,使得医生更加容易的辨别病情发展的趋势。血管网络交叉点(分叉点)可以作为控制点(特征点),它们的管径粗细或交叉角度等信息提供了视网膜图像匹配成功与否的重要判断依据。但是同时应该注意到这种方法的效果很大程度上取决于图像视网膜血管处理(分割与特征提取)的精度,因此也可以考虑使用图像的其它统计特性作为配准的依据。
2.研究基础
2.1 视网膜图像增强方法
2.1.1 数学形态学理论基础
集合论是数学中最为基础的学科,同时也是数学形态学的数学基础,并且数学形态学所用的语言同样也是集合论,很自然地数学形态学的就具备了完善的数学基础。所以数学形态学可以广泛应用于图像处理和分析技术,同时这也对一些形态滤波器的分析和设计打下了坚实的基础。它的作用在于不仅能够大大减少图像的数据,自然就能相对的减少数据处理量,从而提高处理的速度,同时它还能维持它们原有的一些重要的形态特征,并且可以剔除一些不大相关的结构,这样也就缩小数据量。所以数学形态学算法大大缩减了图像数据处理量并且大大提高了图像处理分析的速度,通常它采用并行实现的结构原理,这也就实现了形态学处理和分析算法的并行。
数学形态学主要有膨胀、腐蚀、开和闭这四种最基本的运算,而这四种运算是由一组形态学中的代数运算组成。它们在灰度图像和二值图像中各有不同的特点。所以可以用它们对图像进行处理和分析,主要包括了以下方面的图像处理:图像的分割、边缘检测、图像的增强和恢复、特征提取和图像的滤波等等。同样的,可以通过这四种最基本的运算来推导和组合成一些其他的比较实用的数学形态学算法。
数学形态学中最重要的一个信息即为“探针”,通常它是一个结构元素,并且主要负责收集图像的信息,当探针在图像中不停的移动时,它就可以考察图像中哪些部分存在着一些联系,从而就可以从整体上了解整幅图像的总体结构特征。而作为探针,可直接携带图像的一些重要信息如形态、大小等,甚至还可以加入灰度和色度信息来进行探测,这样便能更好的研究图像的结构特点。下面分别介绍形态学中几种最基本的运算,即为:腐蚀、膨胀、开和闭运算。
腐蚀和膨胀
一般而言,都是对灰度图进行运算的。设f为一幅图像(这里为灰度图像,彩色图像可
以通过空间转换为灰度图像),N代表结构元素,ε代表腐蚀,δ代表膨胀,那么

公式(2.1)
表示结构元素N对图像f的腐蚀运算。
而膨胀运算δN (N为结构元素)则被定义为

公式(2.2)
其中v为取极大值,N.(x) 为结构元的邻域。
开运算和闭运算
在形态学中,通过腐蚀和膨胀的迭代运算就形成了开和闭运算。开运算是先腐蚀后膨胀的结果,将它记为x﹐相反的,闭运算则是先膨胀,然后再对其进行腐蚀的结果,记为N,它们的数学表达式分别表示为公式(2.3)和公式(2.4)。


由公式(2.1)和公式(2.2)可知,膨胀运算是选取结构元素中所包含的区域的极大值,它能将图像中一些断裂的部分连接起来,还能将物体所能接触到的所有点都合并到物体中来;而腐蚀运算的作用则恰好相反,它能剔除图像中的一些“小毛刺状”,同时还能保留图像的基本形状不变。开运算和闭运算则将腐蚀和膨胀运算结合起来,经过开运算之后,能够平滑物体的边界,除去孤立的小点、小物体,同时还没有改变图像的面积;而闭运算则可以填充物体内部的小空间,平滑边界的作用。一般而言,对于选取的结构元素的不同,得到处理结果会存在差异,因此可以通过定义不同的结构元素来处理图像,使图像更加清晰。
视网膜图像去噪
结构元素的选取
结构元素是形态学算法的关键,不同结构元素的选择导致运算对不同几何信息分析和处理,因此对结构元素的分析是算法中重要的一部分。形态学运算只是采用具有一定形态的结构元素去提取图像中的对应形态。因此该算法选取结构元素时直接采用灰度值为0的区域,即:
N(x)=0,x∈D_N 公式(2.5)
D为结构元素的定义域。由于视网膜血管的特殊性,即为线性特点,这就使得对图像进行去噪可以采用线性这一类特殊的结构元素,由于几种特殊情况会使图像发生一些细微的变化,比如说所选取的结构元素与视网膜血管发生正交的话,如果再对图像进行某些形态学的操作的话,可能会剔除部分的视网膜血管,或者是视网膜血管比所选取的结构元素还短的话,同样可能出现类似的问题;而选取的结构元素与视网膜血管相平行的话,这时候视网膜血管不会发生改变。由于视网膜血管的直径大小不一样,为了能够满足最大的视网膜血管的要求,这里令最大的血管直径大小与所选取的结构元素的长度相同。基于上述几种特殊的情况,考虑使用相同大小的线性结构元素,然后再对图像在多个方向上做形态学运算,最后取极值。
对图像进行去噪
在各个方向上用所选取的结构元素对图像进行形态学操作(开运算),之后取各个方向上的极值(这里为最大值)来作为运算后原图像的灰度值,最后再利用原图像对运算后的图像进行重建。此图像即为所要得到的平滑图像。计算步骤如下(在这里我们选取的是12个方向,每个方向相差15°):


式中,C为邻域半径,d为运算次数,可根据实际的情况而定。
卷积神经网络的典型用途是分类任务,其中输出到图像是单个类别标签。 然而,在许多视觉任务中,尤其是在生物医学图像处理中,期望的输出应该包括定位,即:应该将类别标签分配给每个像素。 此外,在生物医学任务中,千量级的训练图像通常难以训练。 因此,Ciresan等人 在滑动窗口设置中训练网络,通过提供围绕该像素的局部区域(补丁)作为输入来预测每个像素的类别标签。
首先,这个网络可以局部化。
其次,补丁方面的训练数据远大于训练图像的数量。
由此产生的网络大幅度赢得了ISBI 2012的EM segmentation challenge。
显然,Ciresan等人的策略 有两个缺点。
第一,它非常慢。
因为网络必须分别为每个补丁运行,并且由于补丁重叠而导致大量冗余。
其次,需要在局部准确性 和 获取整体上下文信息之间取舍。
较大的补丁需要更多的最大池化层来降低局部准确性,而较小的补丁则使网络只能看到很少的上下文。 最近的方法提出了一个分类器输出,它考虑了来自多个层的特征。 良好的本地化和上下文的使用是可能的同时。
在这篇文章中,就建立了一个更加优雅的框架,通常被称为“全卷积网络”(FCN)。随后修改并拓展了这个框架,使其可以仅使用少量训练图片就可以工作,获得更高的分割准确率。网络架构如下图所示:
图1. FCN的网络架构

对FCN中的重要修改是:
上采样部分有大量的特征通道,它们允许网络将上下文信息传播到更高分辨率的层。
使得网络架构中扩张路径与收缩路径基本对称,并产生u形结构。
没有任何完全连接的层,分割图仅包含像素,对于该像素,输入图像中的完整上下文是可用的。
该策略允许通过重叠拼贴策略对任意大的图像进行无缝分割。 为了预测图像的边界区域中的像素,通过镜像输入图像来推断丢失的上下文。 这种平铺策略对于将网络应用于大图像很重要,否则分辨率将受到GPU内存的限制。
图 2 平铺策略

许多细胞分割任务中的另一个挑战是分离相同类别的触摸物体。为此提出使用加权损失:触摸单元之间的分离背景标签在损失函数中获得大的权重。
3.数据预处理
3.1 网络架构
网络架构如图1所示:它由一条收缩路径(左侧)和一条扩展路径(右侧)组成。
【收缩路径】
收缩路径是典型的卷积网络架构。它的架构是一种重复结构,每次重复中都有2个卷积层和一个pooling层,卷积层中卷积核大小均为3x3,激活函数使用ReLU,两个卷积层之后是一个2x2的步长为2的最大池化层。每一次下采样后我们都把特征通道的数量加倍。
【扩张路径】
扩展路径中的每一步包括对特征映射先进行上采样,然后进行2x2卷积(“上卷积”)。该特征映射将特征通道的数量减半,与收缩路径中相应裁剪的特征拼接起来,以及两个3x3卷积,每个卷积都有一个ReLU。由于每个卷积中边界像素的丢失,裁剪是必要的。在最后一层,使用1x1卷积来将每个64通道特征图映射到特定深度的结果。
【卷积层总数】
网络总共有23个卷积层。
3.2 训练
论文中采用随机梯度下降法(SGD)训练。由于没有使用0填补的卷积,输出图像比输入小一个恒定的边界宽度。 为了最大限度地降低开销并最大限度地利用GPU内存,我们倾向于在较大批量的情况下使用较大的输入切片,从而将批量减少为单个图像。 因此,我们使用高动量(0.99),以便大量先前看到的训练样本确定当前优化步骤中的更新。
损失函数使用逐像素的 softmax 函数和交叉熵损失函数的结合
Softmax函数:

a_k(x)表示在feature maps中的的channel=k的feature map像素位置为x的激活值。K表示总类别数,pk(x)表示似然函数。
交叉熵函数:

其中l是每个像素的真实标签,w是权重地图,表示训练中某些像素更加重要。
为了使某些像素点更加重要,我们在公式中引入了w(x)。我们对每一张标注图像预计算了一个权重图,来补偿训练集中每类像素的不同频率,使网络更注重学习相互接触的细胞之间的小的分割边界。我们使用形态学操作计算分割边界。权重图计算公式如下:
其中w_c是权重地图来平衡类像素的频率。d1表示最近单元边界的距离。d2表示到第二最近单元的边界的距离。文中设置w_0=10,σ≈5pixels。
训练需要标注对应的mask,就是类别的区域标记。
图 3

网络中权重的初始化:在具有许多卷积层和通过网络的不同路径的深层网络中,权重的良好初始化非常重要。 否则,网络的某些部分可能会过度激活,而其他部分则无法提供。 理想情况下,应调整初始权值,使网络中的每个特征映射具有近似单位差异。 对于具有我们的体系结构(交替卷积和ReLU层)的网络,这可以通过从具有标准偏差(2/N)^0.5的高斯分布中绘制初始权重来实现,其中N为每个神经元的输入节点数量。例如3x3的64通道的卷积层N=3x3x64=576。
3.3 数据增加
在只有少量样本的情况下,要想尽可能的让网络获得不变性和鲁棒性,数据增强是必不可少的。在显微图像的情况下,我们主要需要移位和旋转不变性以及对变形和灰度值变化的鲁棒性。论文中使用随机位移矢量在粗糙的3x3网格上产生平滑形变。 位移是从10像素标准偏差的高斯分布中采样的。然后使用双三次插值计算每个像素的位移。在压缩路径末端的退出层执行进一步的隐式数据增强。
最后论文的实验部分,我们这里直接在DRIVE数据库上做实验。
4.视网膜血管分割实验
4.1 实验任务
实验任务:使用U-Net神经网络提取纹理血管。
为什么要做这个,有什么实际意义?
临床实验中我们要能够更好的对眼部血管等进行检测、分类等操作,我们首先要做的就是对眼底图像中的血管进行分割,保证最大限度的分割出眼部的血管。从而方便后续对血管部分的操作。
4.2 数据集
实验数据集为:DRIVE数据集。
数据集下载地址:
http://www.isi.uu.nl/Research/Databases/DRIVE/
【数据集识别】
数据集分为训练集与测试集,而每个都分为如下目录:
图 4 部分数据集目录

1st_manual目录下的数据集为:手工分好的血管图像,如下图所示:
图 4-1

images目录下的数据集为眼底图像,如下图所示:
图 4-2

mask目录下的数据集为眼部轮廓图像,如下图所示:
图 4-3

从上面可以看出数据集非常少,总共只有20幅图片,为此我们需要做预处理增大数据集。
【U-Net网络优势】
在上述U-net论文中提到U-Net网络可以针对很少的数据集来进行语义分割,比如我们这个眼球血管分割就是用了20张图片来训练就可以达到很好的效果。而且我们这种眼球血管,或者指静脉,指纹之类的提取特征或者血管静脉在U-net网络里就是一个二分类问题。而本文用的U-net网络来实现这个二分类就只需要二十张图片来作为数据集。
参 考 文 献
[1] 何明一,Gonzalez,阮秋琦 等译. 《数字图像处理》 (matlab版),电子工业出版社,2008.
[2] 张一虎,卞正中,等. 基于互信息的视网膜眼底图像标准方法. 西安理工大学学报,2002,18(1):164-170.
[3] 杨晖曲,秀杰. 图像分割方法综述.电脑开发与应用,2005,18(3)21-23.
[4] Sonha M,HlaVac V, Boyle R著,艾海舟等译.数字图像处理、分析和机器视觉(第一版).北京邮电出版社.
[5] 王新城.高级图像处理技术【M】.北京中国科学出版社,2001.
欢迎大家加我微信交流讨论(请备注csdn上添加)