之前学习了视图集里运用序列化器进行序列化和反序列化操作,定义序列化器类,需要继承Serializer基类或者Serializer的子类;
这次我们将学习如何自定义校验器、如何进行单字段或者多字段校验,最后初步使用模型序列化器
一、自定义校验器
比如定义一个校验项目名称字段是否包含“项目”的函数:
def is_contain_project_word(value):if "项目" not in value:raise serializers.ValidationError("项目名称里必须包含'项目'")
- 在定义字段属性时候,有时候会用到校验器validators参数;
- validators参数只能为列表或者元素,列表或者元组中的每一个元素,为一个约束条件
- 可以使用UniqueValidator来指定唯一约束条件,第一个参数为查询集对象,message关键字参数可以指定具体的报错信息
- 如果校验不通过,必须得返回一个serializers.ValidationError对象,并且可以指定具体的报错提示信息
将自定义的校验函数添加到校验器列表中:
class ProjectSerializer(serializers.Serializer):id = serializers.IntegerField(label="id主键", help_text="id主键", read_only=True)name = serializers.CharField(label="接口名称", help_text="接口名称", max_length=10, min_length=5,validators=[UniqueValidator(ProjectsModel.objects.all(), message="项目名称不可重复!"),is_contain_project_word])二、单字段校验
除了上面的自定义校验器可以进行单字段校验外,我们还可以在序列化器类中使用validate_作为前缀,然后加上字段名称定义的方法 对单字段进行校验
def validate_name(self, value):if not value.endswith("项目"):return serializers.ValidationError("项目名称必须以'项目'结尾!")return value上面是针对name字段进行校验,验证是否以“项目”结尾
- 如果校验通过,则必须返回校验通过后的值(例如上面的return value),如果不返回则后面接收到的值为None,会产生异常并报错
- 如果校验不通过,则调用serializers.ValidationError,返回自定义的报错信息(例如上面的"项目名称必须以'项目'结尾!")
三、多字段校验
- 可以在validate方法中,对多个字段进行校验
- 第二个参数为上面校验通过之后的数据(字典类型)
- 必须得返回校验通过之后的值
def validate(self, attrs):project_leaders=attrs.get('leaders')project_name=attrs.get('name')if '花生' not in project_leaders or len(project_name) <= len(project_leaders):raise serializers.ValidationError('项目负责人名称必须得包含“花生”并且项目名称的长度要超过项目负责人名称')return attrs序列化器serializers.py
def is_container_project_word(value):if '项目' not in value:raise serializers.ValidationError('项目名称中必须得包含“项目”')# class ValidateProject:
# def __call__(self, *args, **kwargs):
# passclass ProjectSerializer(serializers.Serializer):name = serializers.CharField(label='项目名称', help_text='项目名称', min_length=5, max_length=10, write_only=True,validators=[UniqueValidator(Projects.objects.all(), message='项目名不能重复'),is_container_project_word],error_messages={'min_length': '项目名称不能少于5位','max_length': '项目名称不能超过10位', 'required': '项目名称为必传参数'})leader = serializers.CharField(label='项目负责人', help_text='项目负责人',min_length=5, max_length=8)desc = serializers.CharField(label='简要描述', help_text='简要描述', allow_blank=True, allow_null=True,default='')# token = serializers.CharField(read_only=True)def validate_name(self, value):if not value.endswith('项目'):raise serializers.ValidationError('项目名称必须得以“项目”结尾')return valuedef validate(self, attrs):leader_name = attrs.get('leader')project_name = attrs.get('name')if '花生' not in leader_name or len(project_name) <= len(leader_name):raise serializers.ValidationError('项目负责人名称必须得包含“花生”并且项目名称的长度要超过项目负责人名称')return attrsdef create(self, validated_data):pro = Projects.objects.create(**validated_data)return prodef update(self, instance, validated_data):instance.name = validated_data.get('name')instance.leader = validated_data.get('leader')instance.desc = validated_data.get('desc')instance.save()instance.token = 'shisdhisfhishfisfh'return instance四、优化(视图集与模型类序列化器)
因为视图集里面很多操作都是重复的,比如序列化与反序列化操作;序列化器里的字段和对应的参数也需要重复设置,无形中增加了代码量
所以这次将对序列化器和视图集进行一次优化升级,缩减代码量
4.1优化的视图集views.py
class ProjectDetailView(View):def get_object(self, pk):ret = {"msg": "参数异常","code": 0}# 数据校验(校验项目id是否存在)try:return Projects.objects.get(pk=pk)except Exception:raise Http404def get(self, request, pk):pro = self.get_object(pk)serializer_obj = ProjectSerializer(instance=pro)return JsonResponse(serializer_obj.data, json_dumps_params={"ensure_ascii": False})def put(self, request, pk):ret = {"msg": "参数异常","code": 0}pro = self.get_object(pk)json_data = request.body.decode('utf-8')try:python_data = json.loads(json_data)except json.JSONDecodeError:return JsonResponse(ret, status=400, json_dumps_params={"ensure_ascii": False})# a.在创建序列化器对象时,如果同时给instance与data传参,那么序列化器对象调用save()方法时,会自动调用update()方法serializer_obj1 = ProjectSerializer(instance=pro, data=python_data)try:serializer_obj1.is_valid(raise_exception=True)except:ret.update(serializer_obj1.errors)return JsonResponse(ret, status=400, json_dumps_params={"ensure_ascii": False})# 更新数据# a.如果给save传递参数,会自动将参数合并到validated_data中# b.如果传递重复参数,那么会将之前的前端传递的参数覆盖#serializer_obj1.save(age=18, name='唯一Love')serializer_obj1.save()return JsonResponse(serializer_obj1.data, json_dumps_params={"ensure_ascii": False})def delete(self, request, pk):ret = {"msg": "参数异常","code": 0}pro = self.get_object(pk)pro.delete()# 返回数据return JsonResponse(None, safe=False, status=204)class ProjectView(View):def get(self, request):# 获取所有的项目数据qs = Projects.objects.all()serializer_obj = ProjectSerializer(instance=qs, many=True)return JsonResponse(serializer_obj.data, json_dumps_params={"ensure_ascii": False})def post(self, request):ret = {"msg": "参数异常","code": 0}# 获取json格式的字符串数据json_data = request.body.decode('utf-8')try:python_data = json.loads(json_data)except json.JSONDecodeError:return JsonResponse(ret, status=400, json_dumps_params={"ensure_ascii": False})# b.在创建序列化器对象时,如果只给data传参,那么序列化器对象调用save()方法时,会自动调用create()方法serializer_obj1 = ProjectSerializer(data=python_data)try:serializer_obj1.is_valid(raise_exception=True)except:ret.update(serializer_obj1.errors)return JsonResponse(ret, status=400, json_dumps_params={"ensure_ascii": False})serializer_obj1.save()return JsonResponse(serializer_obj1.data, json_dumps_params={"ensure_ascii": False})上面代码中,反序列化输入与序列化输出
- 序列化输出
- 将模型类对象传递给instance,会返回一个序列化器类对象,
- 例如:serializer_obj = ProjectSerializer(instance=pro)
- 如果传递的是查询集对象,那么需要添加many=True
- 例如:serializer_obj = ProjectSerializer(instance=pro,many=True)
- 可以使用序列化器对象的data属性,获取序列化之后的数据(字典或者嵌套字典的列表)
- 例如:
def get(self, request, pk):pro=self.get_object(pk)serializer_obj=ProjectModelSerializer(instance=pro)return JsonResponse(serializer_obj.data,json_dumps_params={"ensure_ascii": False})- 反序列化输入
- 将字典类型或者(嵌套字典的列表)传递给data参数,会返回一个序列化器类对象
- 必须先调用序列化器类对象.is_valid()方法,才会开始校验参数,检验成功会返回True,否则返回False
- 可以使用序列化器类对象.errors属性,获取报错信息(字典类型)
- 可以使用序列化器类对象.validated_data属性,获取校验通过之后的数据
- 创建数据,返回模型类对象
- 模型类对象在调用save()方法时,会自动调用create()方法
- 如果序列化器对象调用save()方法时传递关键字参数进去,那么在自动调用create()方法时,自动合并到validated_data中
- 如果不调用save()方法,则不会调用create方法和update方法,输出时候是以validated_data里的数据进行输出的(适用于查询操作)
4.2优化序列化器类
之前是序列化器类,这次优化使用成模型序列化器类
- 可以继承ModelSerializer类或者ModelSerializer的子类,来创建模型序列化器类
- 来通过指定的模型类,来自动生成序列化器字段以及相关校验规则
class ProjectModelSerializer(serializers.ModelSerializer):# a.必须得在Meta内部类中使用model属性指定,参考的模型类# b.可以使用fields属性来指定哪些模型类中的字段,需要自动生成序列化器字段class Meta:model = Projects# c.指定所有的字段# fields = '__all__'# d.可以将需要自动生成序列化器字段的模型类字段添加到元组中fields = ('name', 'leader','tester')def validate_name(self, value):if not value.endswith("项目"):return serializers.ValidationError("项目名称必须以'项目'结尾!")return value# 如果不返回value,结果则为Nonedef validate(self, attrs):project_leaders = attrs.get('leaders')project_name = attrs.get('name')if '花生' not in project_leaders or len(project_name) <= len(project_leaders):raise serializers.ValidationError('项目负责人名称必须得包含“花生”并且项目名称的长度要超过项目负责人名称')return attrsdef create(self, validated_data):return ProjectsModel.objects.create(**validated_data)def update(self, instance, validated_data):# 修改老数据,传入新数据给对应字段instance.name = validated_data.get("name")instance.leader = validated_data.get("leader")instance.desc = validated_data.get("desc")instance.programmer = validated_data.get("programmer")instance.tester = validated_data.get("tester")instance.publish_app = validated_data.get("publish_app")instance.save()return instance所以上面的views.py文件内的代码还可以优化:将创建序列化器对象时调用 ProjectSerializer替换成 ProjectModelSerializer
debug跑通截图:
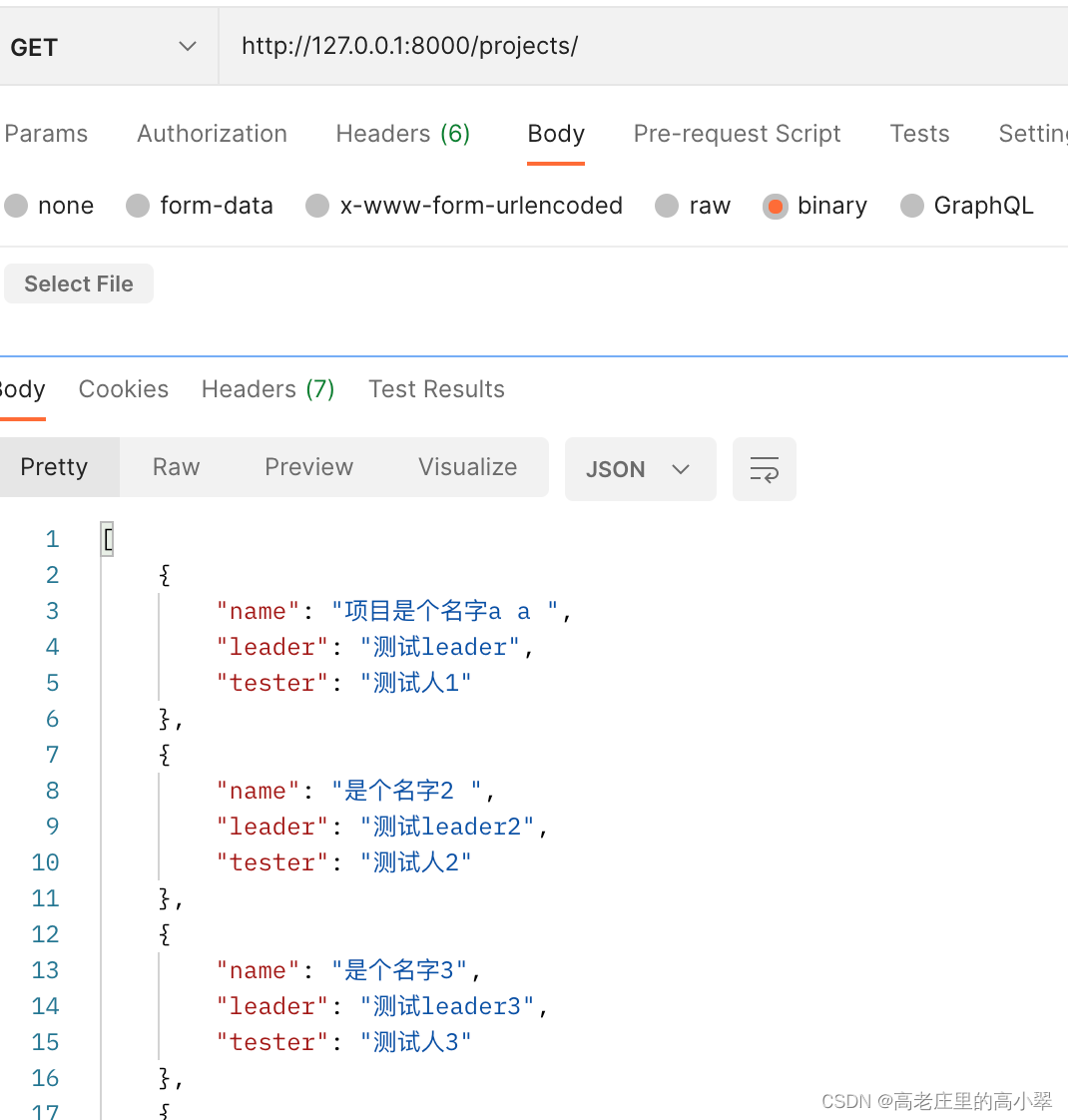

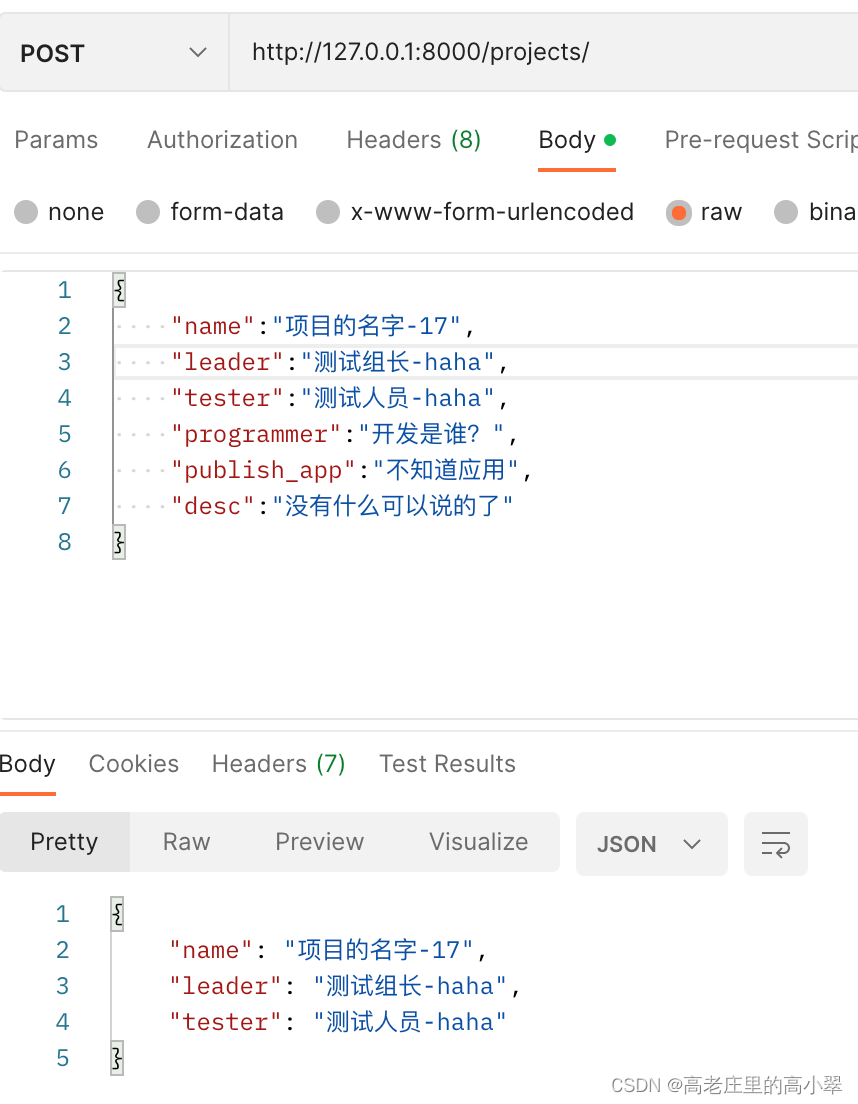
这个时候初步实现了视图集和序列化器的优化,后面还会继续针对模型序列化器类进行优化