一、什么是存储引擎
关系型数据库的数据是存在表里的,可以将表理解为由行和列组成的表格,类似于Excel的电子表格的形式,每个表格就是一个数据。
表是在存储数据的同时,还要组织数据的存储结构,而这些数据的组织结构就是由存储引擎决定的。
即存储引擎的作用就是规定了数据存储时的存储结构,业务直接决定了存储引擎的选择。因为不同的业务对数据的要求是不同的,比如查询、增删、外键、事务、索引等。
mysql查看支持存储引擎语句:show engines;
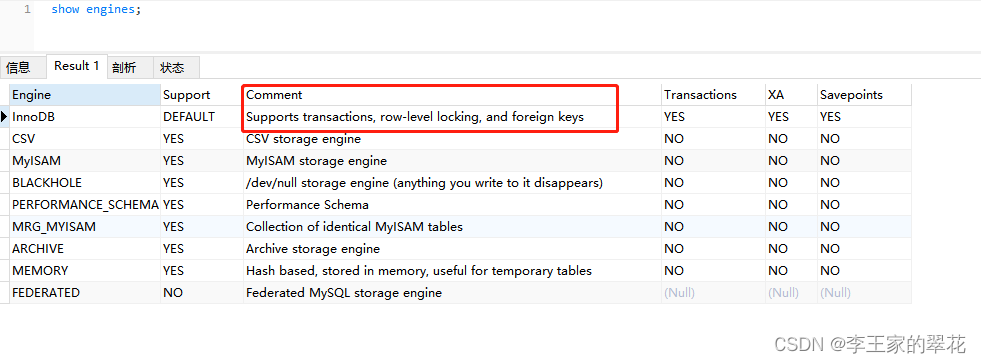
可以看出mysql默认支持的InnoDB索引,且支持事务、行级锁、外键。
存储引擎的使用级别是数据表。
切换存储引擎的sql语句如下:
alter table a engine = innodb;
二、存储引擎的选择
mysql比较常用的存储引擎有三个:
Innodb:行(记录)锁,事务(回滚),外键
Myisam:表锁,全文索引
Memory:内存存储引擎,速度快、数据容易丢失
1、Innodb
mysql的默认存储引擎,支持事务、外键。
场景:对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作。(普通业务、web)
2、Myisam
表锁,全文索引,访问速度快。
场景:应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高。(多读少写,对数据恢复要求不高,比如数据仓库)—MongoDB
3、Memory
将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。—Redis
一般情况下,默认使用Innodb,可以满足大多数场景。
尽量不要混合使用存储引擎,因为会有不可控的问题,比如:
事务:一个事务对两种存储引擎的表进行操作,如果这个事务出现了回滚,那么InnoDB存储引擎的表才可以进行回滚,MyISAM存储引擎表中的数据是无法回滚。这样就会带来一些数据逻辑上的问题。