从英雄联盟皮肤网站的网页源代码中获取不到英雄的皮肤地址 通过selenium可以轻松获取想要的内容
源码展示
from selenium import webdriver
from time import sleep
from pyquery import PyQuery as pq
import os,requests
from config import *
import pymongo
from selenium.common.exceptions import NoSuchElementExceptionbrowser = webdriver.Chrome()client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]def get_hero_url():browser.get("http://lol.qq.com/web201310/info-heros.shtml")html = browser.page_sourcedoc = pq(html)#通过PyQuery解析出来的网页 用css选择器获取li标签内容 并返回一个生成器items = doc('#jSearchHeroDiv.imgtextlist li').items()#通过循环获取生成器下的内容for item in items:data ={'hero_url':'http://lol.qq.com/web201310/'+item.find('a').attr('href'),'hero_name':item.find('p').text()}#print(len(data['hero_url']))# 在网页加载的时候可能会因为网络的问题 图片会加载不出来 然后css选择器就获取不到相应的内容#从未抛出异常 抛出异常后让网页重新加载一次try:get_hero_skin(data['hero_url'])except NoSuchElementException:print('出现异常再次请求网页')get_hero_skin(data['hero_url'])def get_hero_skin(url):browser.get(url)sleep(1)#只有点击第二个皮肤的时候所有的皮肤才会在网页的代码中显示出来 #所以这里设置了个自动点击的功能才能获取到英雄的所有皮肤#否则只能获取到一个默认皮肤skin = browser.find_element_by_css_selector('#skinNAV > li:nth-child(2)')skin.click()html = browser.page_sourcedoc = pq(html)items = doc('.defail-skin #skinBG li').items()for item in items:data ={'title':item.find('img').attr('alt'),'image':item.find('img').attr('src')}#print(data)save_to_mongo(data)download_image(data['image'],data['title'])def download_image(image_url,title):if not os.path.exists('images'):os.mkdir('images')response = requests.get(image_url)if response.status_code == 200:#每个英雄的第一个都是默认皮肤所以在保存到本地时候会将#之前的默认皮肤覆盖 所以文件中一个最后一个默认皮肤的图片 # 这里可以自己简单修改下 file_path = 'images/{}.jpg'.format(title)if not os.path.exists(file_path):print("正在获取%s的信息" % (title))# 图片以二进制格式保存with open(file_path, 'wb')as f:# content获取图片内存f.write(response.content)else:print("已经保存该图片")def save_to_mongo(data):try:#保存到mongodb数据库下的每一个数据都会有自己的id #所以数据库中的每个英雄的默认皮肤不会受到影响if db[MONGO_TABLE].insert(data):print("存储到数据库成功",data)except Exception:print('存储到数据库错误',data)get_hero_url()browser.close()
存储到MongoDB数据库需要一个配置文件
MONGO_URL = 'localhost'
MONGO_DB = 'lolskin'
MONGO_TABLE = 'allHeroSkin'
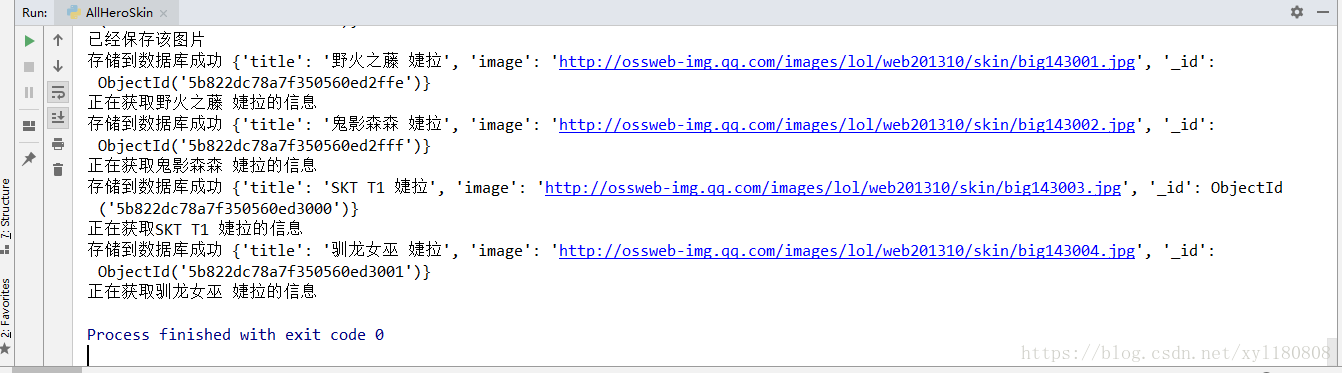
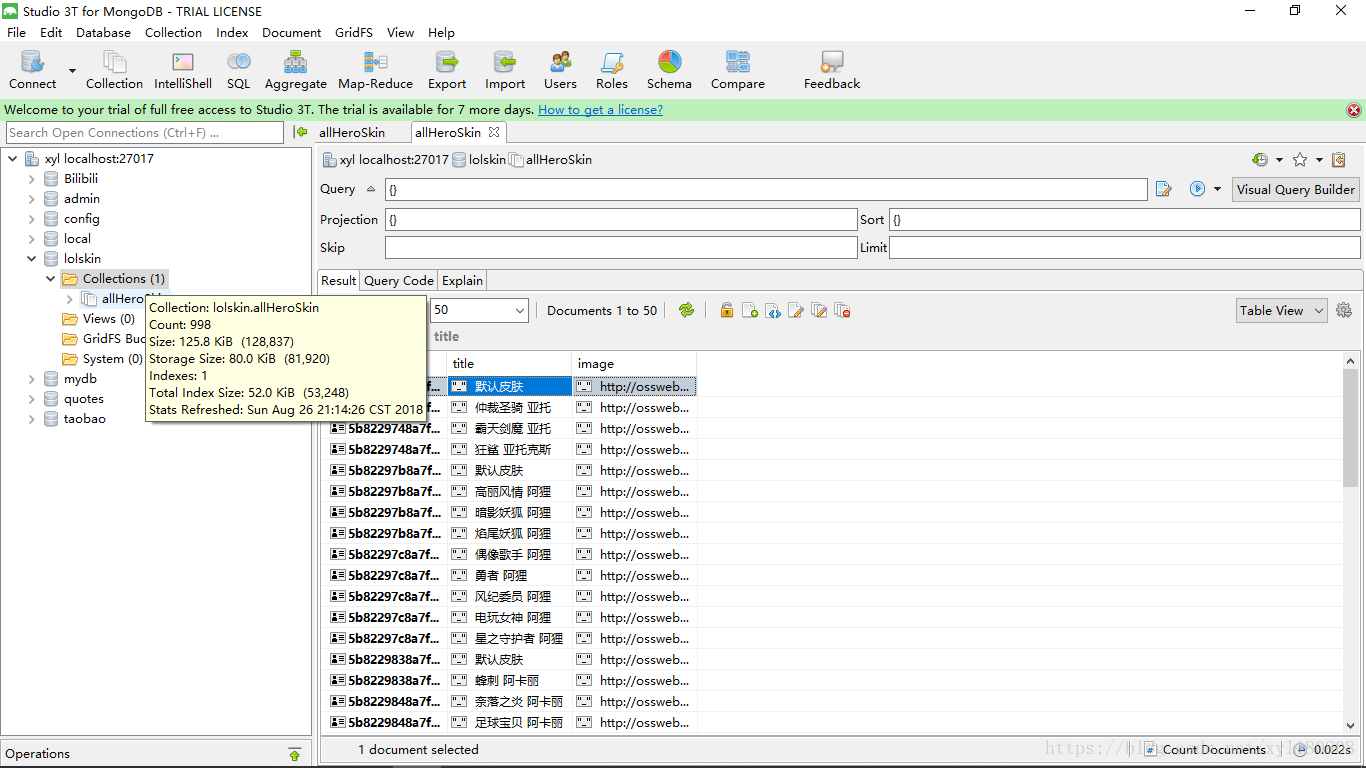
小结
selenium确实很容易将所有的皮肤爬取下来 但是效率太低 用进程池或者多线程是不是效率可以提高了 希望大佬可以提提建议