聊聊Doris向量化执行引擎-过滤操作
Doris是开源的新一代极速MPP数据库,和StarRocks同源,采用全面向量化技术,充分利用CPU单核资源,将单核执行性能做到极致。本文,我们聊聊过滤操作是如何利用SIMD指令进行向量化操作。
过滤操作的SIMD向量化函数是_evaluate_vectorization_predicate:和StarRocks实现大致类似,但稍有不同:
SegmentIterator::_evaluate_vectorization_predicate
执行过程如下图所示:
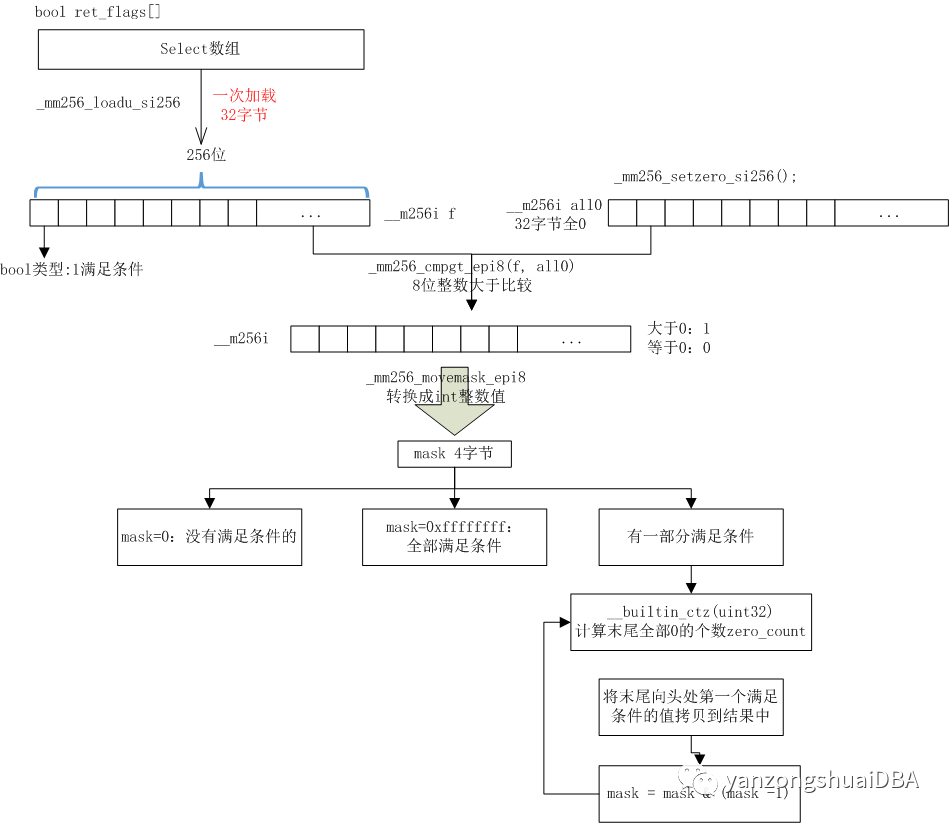
1、通过1个字节bool类型的ret_flags数组来表示是否满足过滤条件,1表示满足条件,0表示不满足
2、AVX2指令集环境下:通过_mm256_loadu_si256封装的指令函数加载256位长度值到寄存器,也就是32字节值f
3、_mm256_setzero_si256生成256位的0值all0
4、_mm256_cmpgt_epi8函数将f和all0每个字节进行并行比较,也就是32个字节并行比较,f中字节>all0中字节值时,对应结果位为1,否则为0
5、将第4步的值通过_mm256_movemask_epi8转换成int整数mask。比如10001111111111111,转换后为36863,其中ret_flags[0]为1,ret_flags[1]为0...
6、mask等于0,表示没有一个满足条件。
7、mask等于0xffffffff,表示全部满足条件,需要将32个数据的行号保存到数组sel_rowid_idx[]中
8、mask等于其他值时,表示有一部分值满足条件。这个时候需要特殊处理:
1)通过__builtin_ctzll(mask)计算mask中末尾0的个数bit_pos。比如:
11100000:有5个0
2)sel_rowid_idx[new_size++] = sel_pos + bit_pos;后导第一个满足条件的行号保存到sel_rowid_idx数组中
3)mask = mask & (mask - 1)跳过不满足的行,StarRocks实现方式:mask右移6位,即11,值3。
4)当然还需要处理尾数据,也就是SIMD对其后剩余的部分:按照标量处理方式处理
for (; sel_pos < sel_end; sel_pos++) {if (ret_flags[sel_pos]) {sel_rowid_idx[new_size++] = sel_pos;}
}5)返回1)步继续计算。
9、当然,上述涉及mask的计算,仅说明了AVX指令集下实现方式,同时还实现了SSE2指令集
inline uint32_t bytes32_mask_to_bits32_mask(const uint8_t* data) {
#ifdef __AVX2__auto zero32 = _mm256_setzero_si256();uint32_t mask = static_cast<uint32_t>(_mm256_movemask_epi8(_mm256_cmpgt_epi8(_mm256_loadu_si256(reinterpret_cast<const __m256i*>(data)), zero32)));
#elif defined(__SSE2__) || defined(__aarch64__)auto zero16 = _mm_setzero_si128();uint32_t mask =(static_cast<uint32_t>(_mm_movemask_epi8(_mm_cmpgt_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i*>(data)), zero16)))) |((static_cast<uint32_t>(_mm_movemask_epi8(_mm_cmpgt_epi8(_mm_loadu_si128(reinterpret_cast<const __m128i*>(data + 16)), zero16)))<< 16) &0xffff0000);
#elseuint32_t mask = 0;for (std::size_t i = 0; i < 32; ++i) {mask |= static_cast<uint32_t>(1 == *(data + i)) << i;}
#endifreturn mask;
}关键原理同样是将32字节的select数组,转变成32bit位的无符号整数来操作。





