个人主页:平行线也会相交💪
欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创
收录于专栏【C++之路】💌
本专栏旨在记录C++的学习路线,望对大家有所帮助🙇
希望我们一起努力、成长,共同进步。🍓

目录
- 一、构造函数
- 1.1构造函数的重载
- 1.2自动生成构造函数
- 1.3构造函数的调用
- 1.4三个默认构造函数(无参、全缺省、编译器自动生成)只能存在一个
- 小结
- 二、析构函数
我们知道类包含成员变量和成员函数,当一个类中既没有成员函数也没有成员变量时,我们把这个类称之为空类。就比如说下面这个空类:
class Date{};
虽然说Date这个类中啥都没有,即被我们称之为空类,相当于我们在这个类中啥都没写,但是编译器会生成6个默认成员函数。
默认成员函数:即用户没有显式实现,但编译器会自动生成的成员函数就被称为默认成员函数。
具体是哪六个成员函数呢?请看:

一、构造函数
构造函数是个比较特殊的成员函数,需要注意:构造函数不是真的然我们手把手的去写一个函数出来,构造函数的任务不是开辟空间创建对象,而是对对象进行初始化。
构造函数特征:
1.函数名与类名相同。
2.没有返回值(不需要写void)。
3.对象实例化时编译器会自动调用其对应的构造函数。
4.构造函数可以重载。
5.如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,但是如果用户显式定义了构造函数则编译器将不再生成。
6.如果我们不自己实现构造函数的话,编译器生就会成默认构造函数,但是编译器调用默认构造函数之后依旧会出现随机值的问题。故实际上这里编译器生成的默认构造函数并没有起作用。
7.无参的构造函数和全缺省的构造函数都被称为默认构造函数,并且二者中只能有一个,如果我们既没有写无参的构造函数也没有写全缺省的构造函数,那么编译器就会自动生成默认构造函数。总之,无参的构造函数、全缺省的构造函数、编译器自动生成的构造函数都被称为默认构造函数,而且这三者中只能存在其中一个。
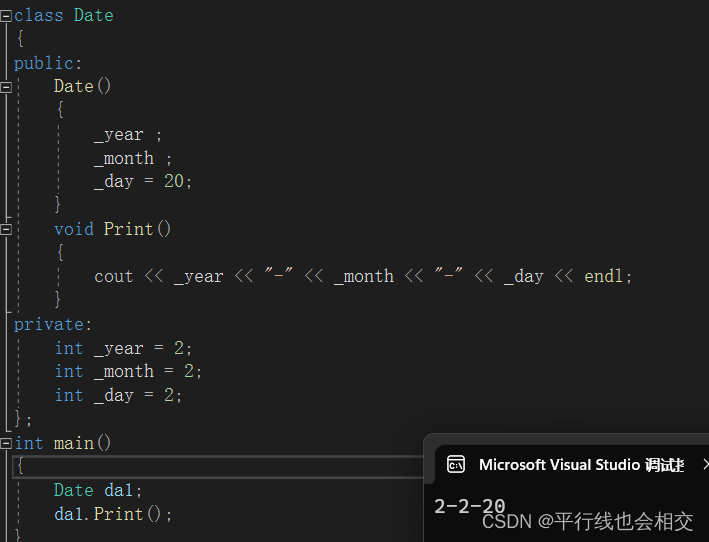
举个构造函数的例子,请看:
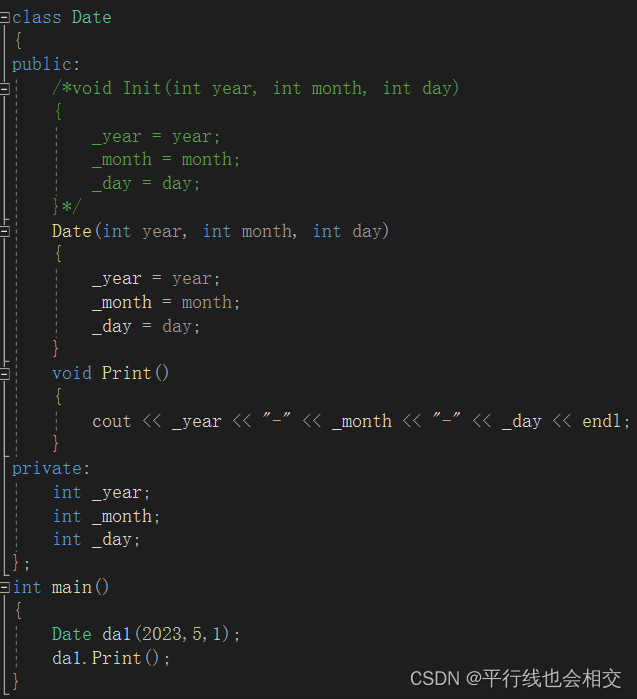
上述代码我们并没有调用初始化的函数,但是我们依然可以对类Date中的成员函数进行初始化。打印结果如下:
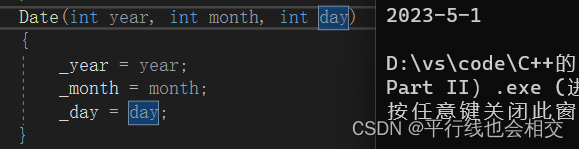
//这就是一个构造函数
Date(int year, int month, int day)
{_year = year;_month = month;_day = day;
}
当对象实例化时,编译器会自动调用该构造函数,即Date da1(2023,5,1);。
1.1构造函数的重载
我们已经知道构造函数的特性之一就是构造函数支持重载。我们已经知道构造函数可以对对象进行初始化操作,然而初始化的方式也有很多种,这也就是构造函数支持重载的原因。
举个例子,比如说数据结构中的栈,初始化时我一上来就上压入n个数据,我们应该怎样做呢?请看:
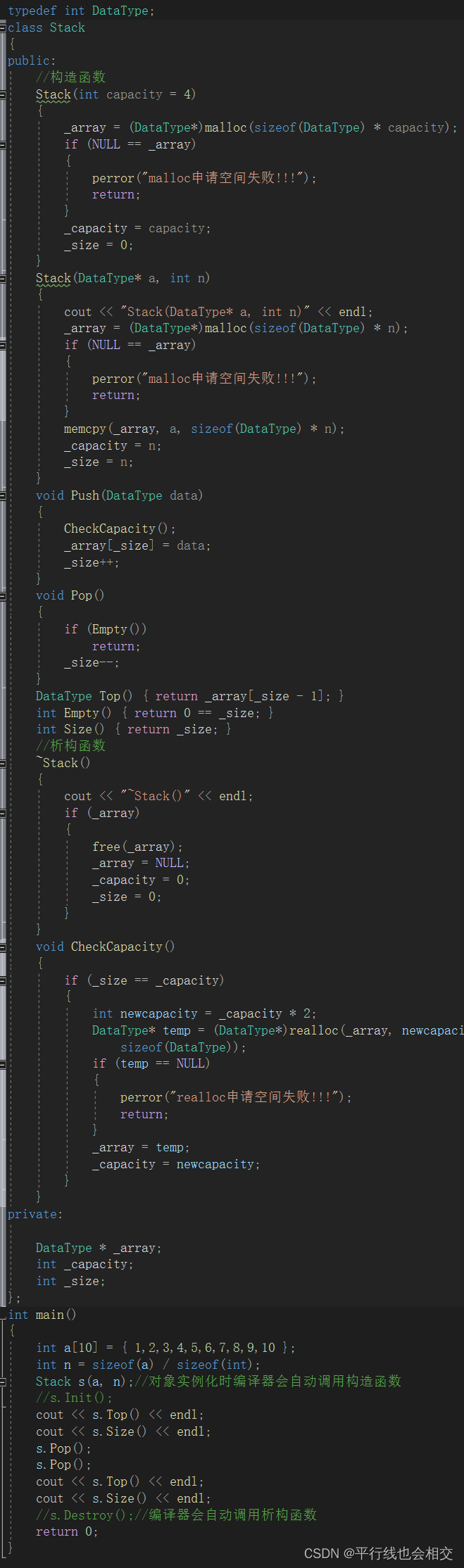
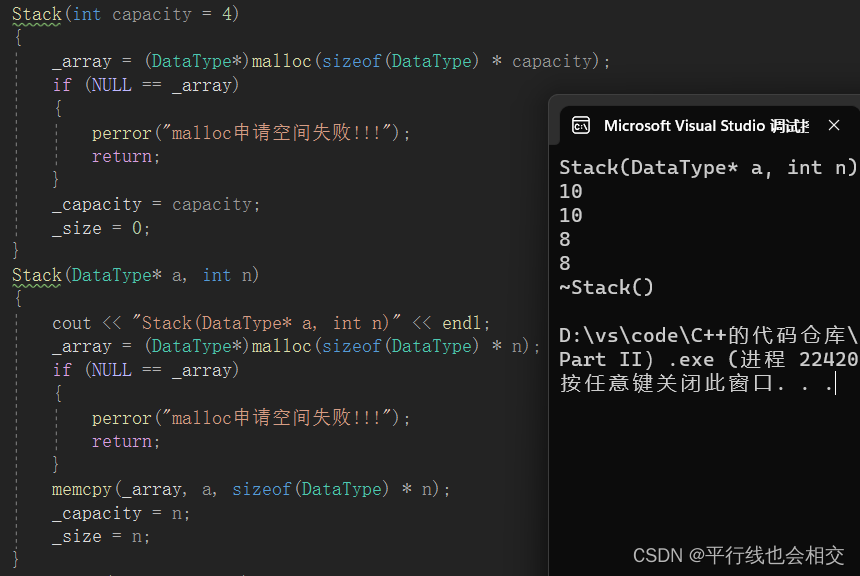
上述代码的构造函数的重载如下:
//构造函数Stack(int capacity = 4){_array = (DataType*)malloc(sizeof(DataType) * capacity);if (NULL == _array){perror("malloc申请空间失败!!!");return;}_capacity = capacity;_size = 0;}Stack(DataType* a, int n){cout << "Stack(DataType* a, int n)" << endl;_array = (DataType*)malloc(sizeof(DataType) * n);if (NULL == _array){perror("malloc申请空间失败!!!");return;}memcpy(_array, a, sizeof(DataType) * n);_capacity = n;_size = n;}
1.2自动生成构造函数
如果类中没有显式定义构造函数,则C++编译器会自动生成一个无参的默认构造函数,但是如果用户显式定义了构造函数则编译器将不再生成。
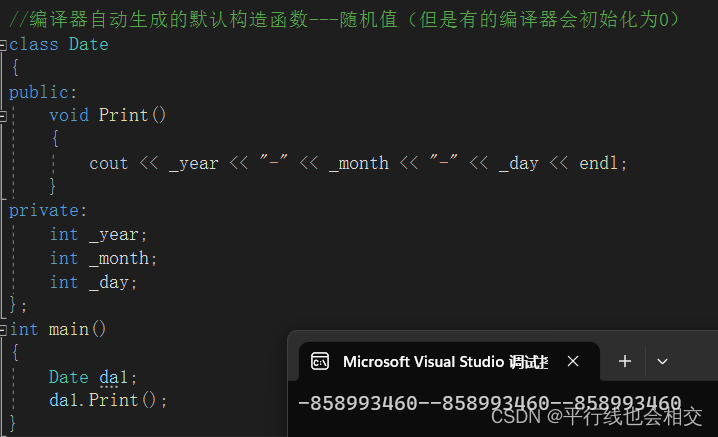
上述类中我们并没有显式的定义构造函数,此时C++就会生成一个无参的默认构造函数,来看运行结果:

请看,一般而言我们认为应该初始化为0,但是这里结果看起来想随机值,所以一些友友认为可能编译器啥也没干,其实并不是。C++的标准并没有说一定要初始化成0,但是有些编译器会初始化成0(这就是编译器自己的原因了,即个性化)。
1.C++中分为内置类型(或叫基本类型),即语言本身定义的基础类型,如int/char/double/指针等等。
2.与内置类型相对应的就是自定义类型,即用struct/class等等定义的类型。
注意:我们如果不写构造函数则编译器就会生成默认构造函数,该默认构造函数对内置类型不做初始化处理,而自定义类型就会调用它的默认构造函数。
请看举例:
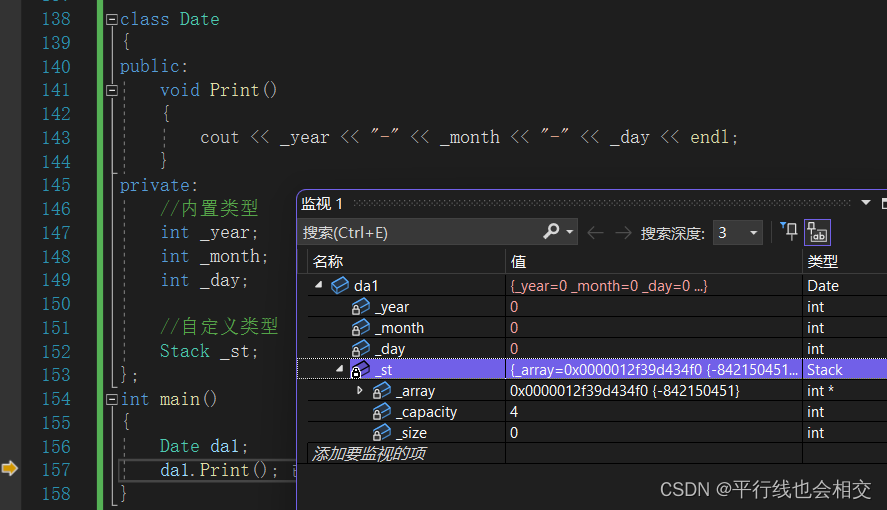
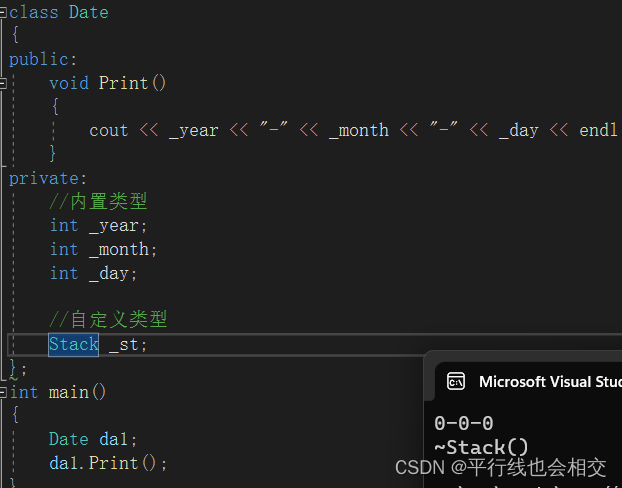
如果我将自定义类型_st省略后,再来看调试结果,请看:
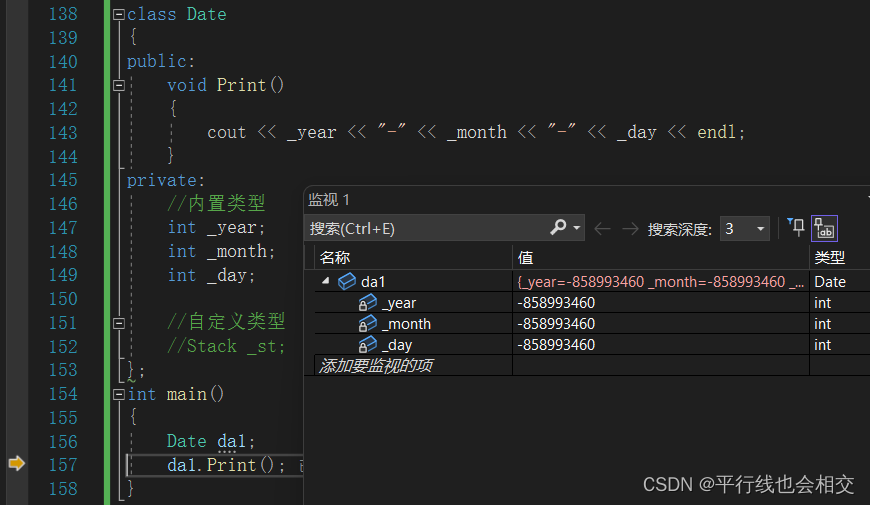

这算是vs2022的一个小bug吧,不同的编译器会有不同的表现,按理来说加上自定义类型_st后,编译器不应该对三个内置类型的变量进行处理,但是vs2022这里的确对这三个内置类型进行了特殊的处理(即初始化成了0)并不是所有的编译器都会对这三个内置类型进行处理,这里注意就好。但是有一点是确定的,自定义类型_st编译器必须要进行处理,因为我们的祖师爷本贾尼规定了自定义类型会调用它的默认构造函数进行处理。
再次强调,祖师爷本贾尼规定了编译器可以不对内置类型进行处理,但是编译器一定要对自定义类型进行处理,即自定义类型会调用它的默认构造函数进行处理。我们最好认为编译器不会对内置类型进行处理。
举个例子: 编译器生成默认的构造函数会对自定类型成员_t调用的它的默认成员函数。请看:

类中若有内置类型,理论上编译器不会生成默认构造函数,所以如果有内置类型,我们就需要自己去写构造函数,切记不要让编译器自己生成默认构造函数,否则可能就会存在随机值的风险(有的编译器会对内置类型处理,有的编译器就不会对内置类型进行处理)。
那什么情况下:编译器会自己生成默认构造函数呢?
1.一般情况下,有内置类型成员就需要我们自己写构造函数,不能用编译器自己生成的。
2.如果全部都是自定义类型成员,可以考虑让编译器自己生成默认构造函数。
举个让编译器自己生成默认构造函数的例子:leetcode232.用栈实现队列

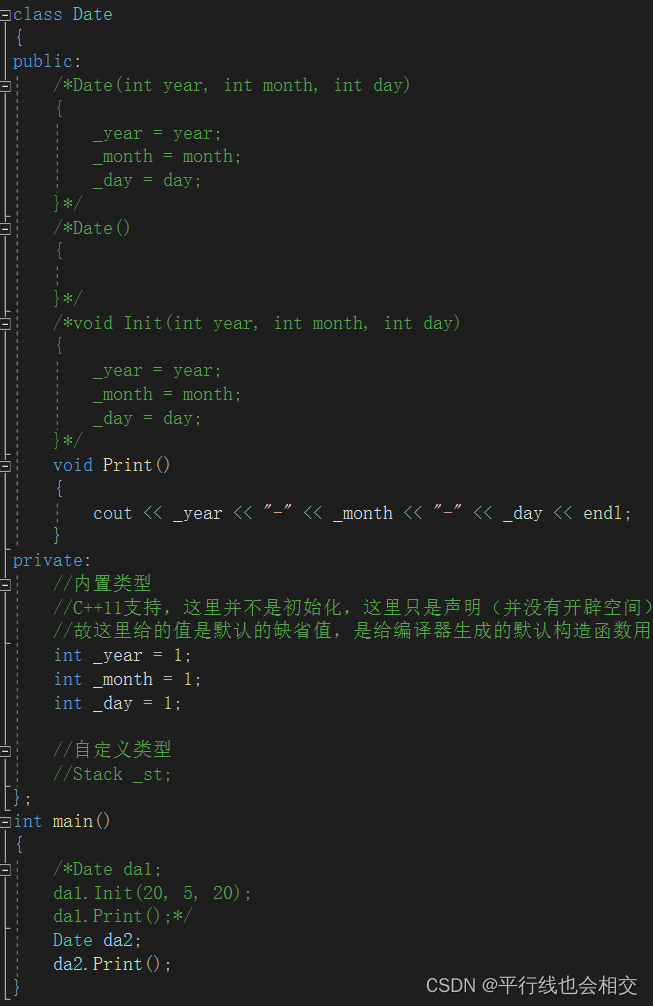
现在再来看下一个问题:C++11觉得内置类型不做处理而自定义类型会进行处理这里不是很好。所以C++11标准对这里进行了一些弥补:在成员进行声明的时候可以给缺省值。
请看举例:

1.3构造函数的调用
构造函数本身就已经很特殊了,而构造函数的调用和构造函数本身一样依然是特殊的,哈哈!!!
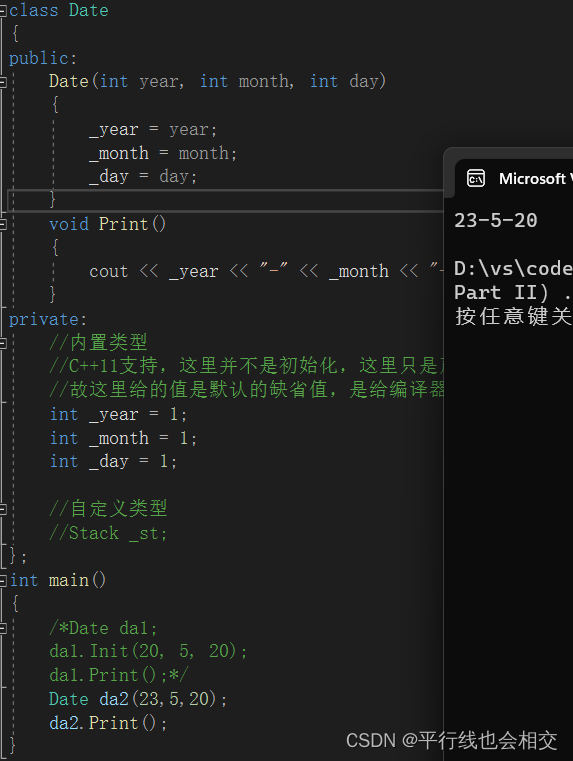
一般函数的调用是这样的:函数名+参数列表,即
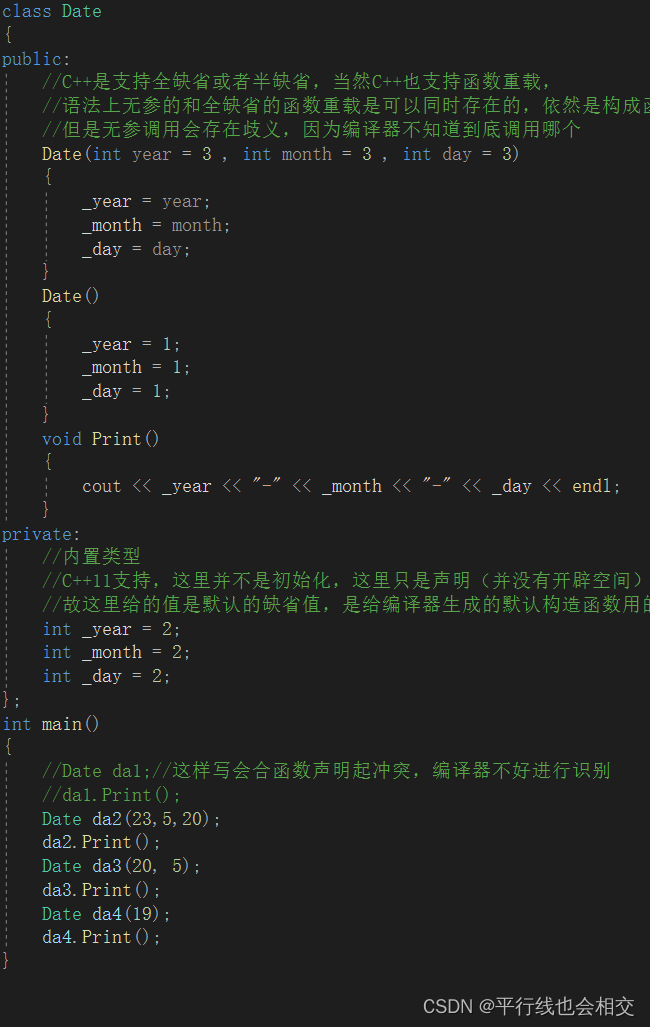
da1.Print();。 构造函数的调用是这样的:对象+参数列表,即Date da2(23,5,20);。但是我们不可以这样写:Date da3();没参数的时候这样写是错误的,因为这样写的化就会和函数声明有点冲突,仔细看Date da3();,按照函数声明来理解的话:Date是返回值类型,而且无参,这样的话就会导致编译器不好识别,所以这里一定要注意:Date da3();这种写法是错误的。
语法上无参的和全缺省的函数重载是可以同时存在的,依然是构成函数重载。但是编译器调用的时候会存在歧义。即符合构成函数重载,但是无参调用会出现歧义,故是不能同时存在的。

所以构造函数构成重载时无参调用存在歧义。
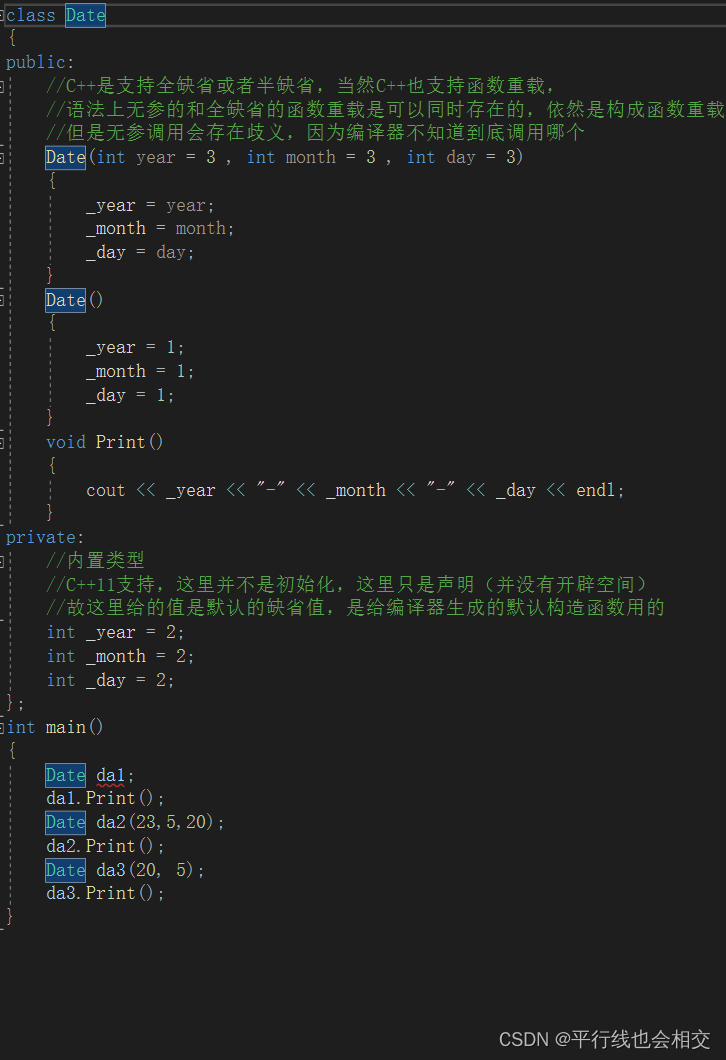
1.4三个默认构造函数(无参、全缺省、编译器自动生成)只能存在一个
下面是构造函数的特征7:
无参的构造函数和全缺省的构造函数都被称为默认构造函数,并且二者中只能有一个,如果我们既没有写无参的构造函数也没有写全缺省的构造函数,那么编译器就会自动生成默认构造函数。总之,无参的构造函数、全缺省的构造函数、编译器自动生成的构造函数都被称为默认构造函数,而且这三者中只能存在其中一个。
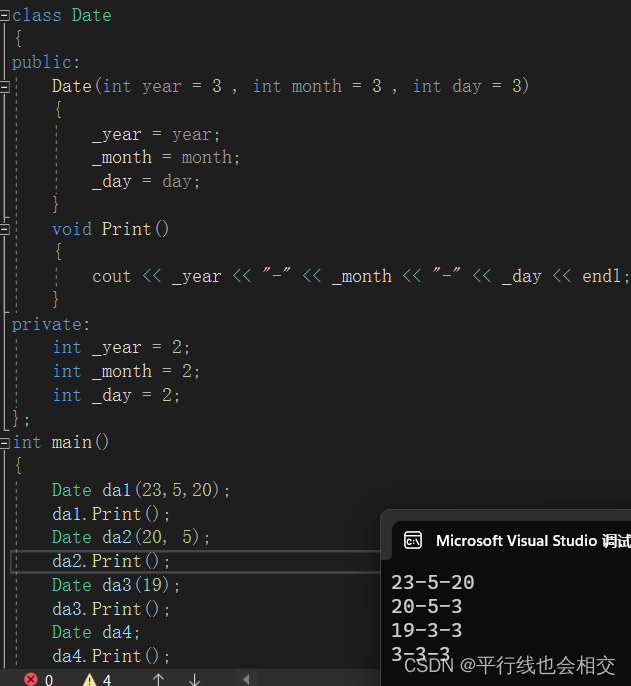
我们对这个三个默认构造函数一一进行对比,请看:
-
只存在全缺省的默认构造函数
同时注意下面这两种写法的对比:
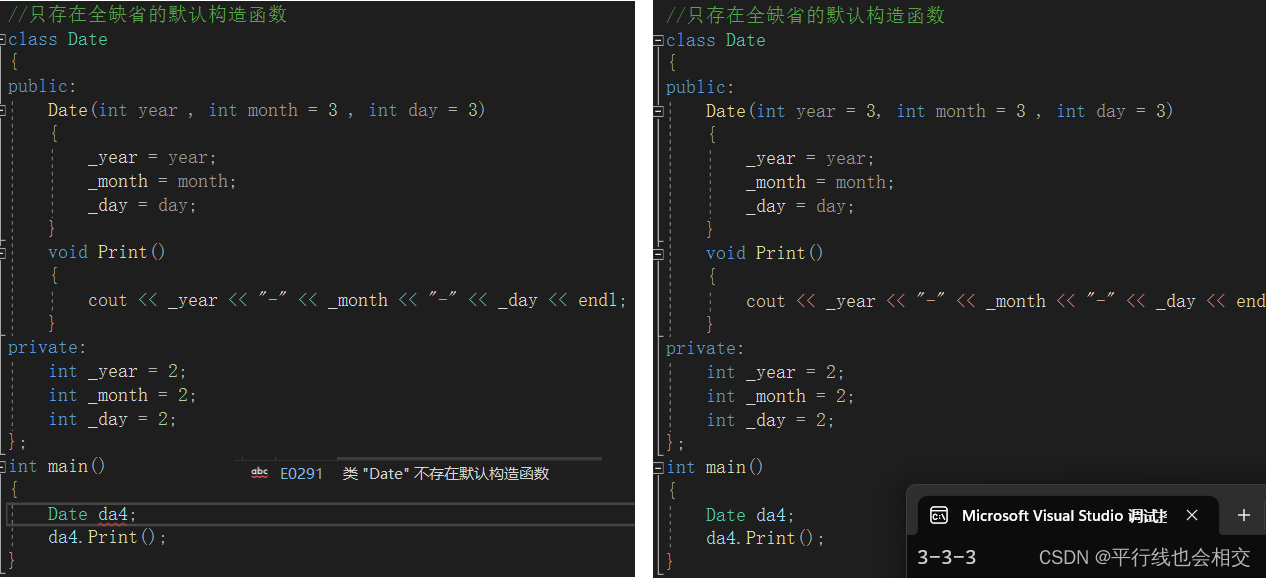
左图中既然是半缺省,所以我们必须要传一个参数,由于左图中并没有传参,所以就报错了;而右图中由于是全缺省,所以我们当然可以不传参数。
对于左图的修改请看:
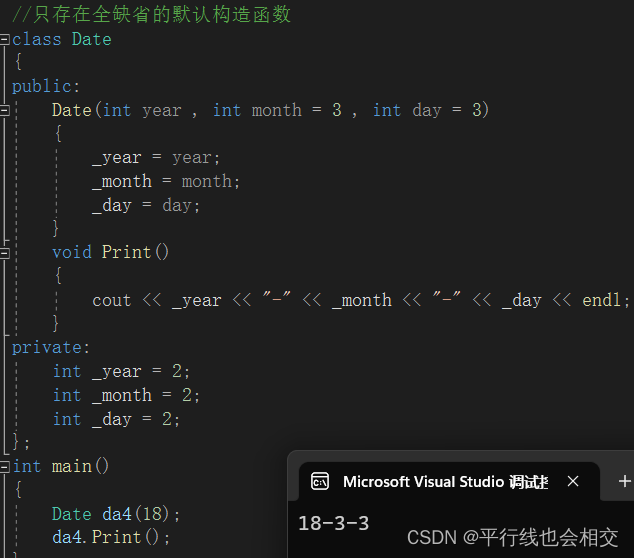
-
只存在无参的默认构造函数
-
编译器生成默认构造函数(随机值)
小结
1.构造函数可以构成重载,但是注意构造函数无参调用时会存在歧义。所以我们一般留一个全缺省的构造函数,因为全缺省的完全可以替代函数无参的。三种默认构造函数中有且只能有一个。
2.编译器对内置类型不做处理(有些编译器会对此进行处理,但这是少数,故C++11为了弥补这里的不足,可以给内置类型成员缺省值),对自定义类型会去调用它的默认构造。
3.不要依赖编译器的默认构造函数(不同的编译器会有不同的表现)。
什么情况下不需要我们去写构造函数呢?
情况一:内置类型成员都有缺省值且初始化符合我们的要求。
情况二:全是自定义类型,且这些自定义类型都已经定义了其所对应的默认构造,这种情况下编译器一般只能去调用那个无参的默认构造函数。那倘若那个默认构造并不是无参的而是带参的话就需要用到初始化列表的内容了,后面在给大家推出吧。
下面是情况一的举例:
class TreeNode
{TreeNode* _left;TreeNode* _right;int _val;
};
class Tree
{
private:TreeNode* _root = nullptr;
};
int main()
{Tree t1;return 0;
}
注意看上述代码:我们给内置类型成员_root了一个缺省值,此时我们就不需要写默认构造函数了。
再来看看情况二:
struct TreeNode
{TreeNode* _left;TreeNode* _right;int _val;TreeNode(int val = 0){_left = nullptr;_right = nullptr;_val = val;}
};
class Tree
{
private:TreeNode* _root = nullptr;//这里给了缺省值
};
int main()
{Tree t1;TreeNode n1(1);TreeNode n2(2);
}
下面来看一下不用写默认构造函数的经典场景:
//编译器对自定义类型会去调用它的默认构造函数
class MyQueue
{Stack _pushst;Stack _popst;
};int main()
{MyQueue q;return 0;
}
假设这里我们我们知道一开始就要插入几个数据的话,及想让Stack中的capacity变为我们想要的一个值,就需要用到初始化列表的内容。
二、析构函数
析构函数:析构函数与构造函数的功能相反,析构函数并不是完成对对象本身的销毁,局部对象销毁工作是由编译器来完成的,而对象在销毁时会自动调用析构函数,完成对象中资源的清理工作。相当于我们在数据结构中学习的Destroy函数。
析构函数特征:
1.析构函数名是在类名前加上字符~.
2.无参数也没有返回值类型。
3.一个类只能有一个析构函数。若我们没有显式定义析构函数,则系统会自动生成默认的析构函数(内置类型不做处理,自定义类型的话系统会去调用它的默认析构函数)。同时析构函数不可以重载。
4.对象生命周期结束时,C++编译系统会自动调用析构函数。
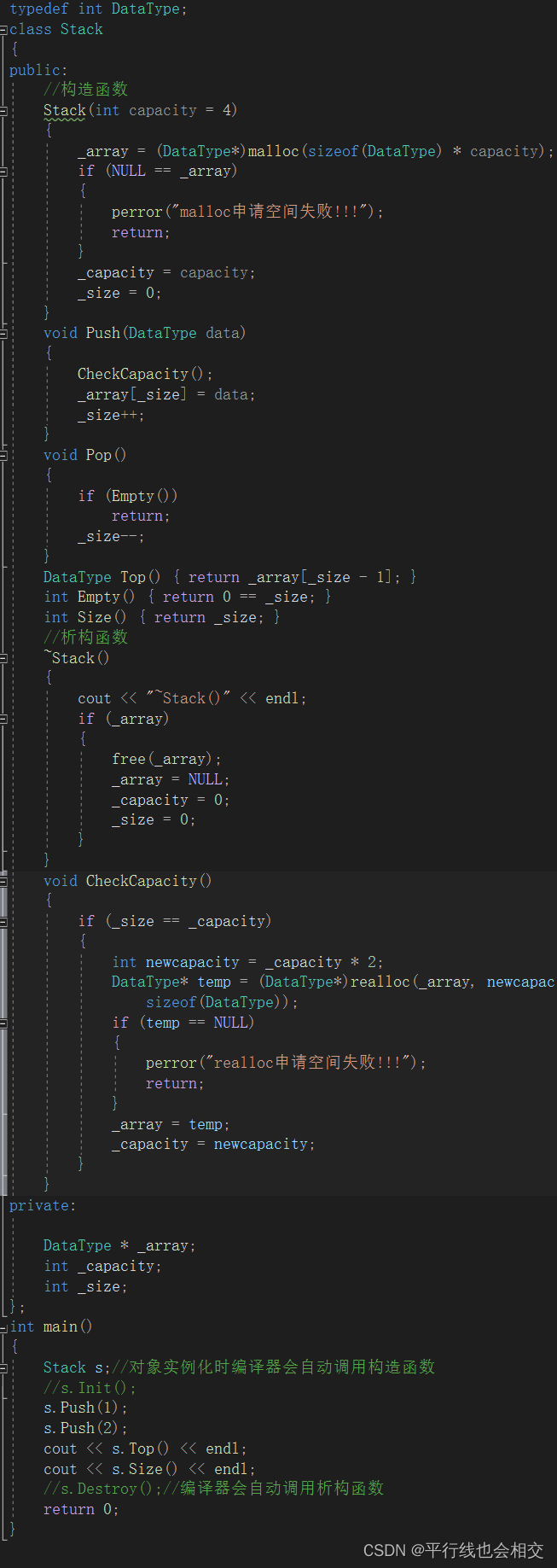

上述代码中构造函数和析构函数如下:
//构造函数
Stack(int capacity = 4){_array = (DataType*)malloc(sizeof(DataType) * capacity);if (NULL == _array){perror("malloc申请空间失败!!!");return;}_capacity = capacity;_size = 0;}
//析构函数
~Stack()
{cout << "~Stack()" << endl;if (_array){free(_array);_array = nullptr;_capacity = 0;_size = 0;}
}
有了构造函数和析构函数,我们就可以简化我们的初始化和清理工作,我们也不需要担心会忘记对象的初始化和对象中资源的清理工作了。
1.一般如果有动态申请资源,就需要显式写析构函数释放资源。(最典型的就是栈了)
2.如果没有动态申请的资源,不需要写析构函数。
3.需要释放资源的成员都是自定义类型,不需要写析构函数。
4.灵活一点,特殊情况特殊对待。😀
下面来看一下不需要写析构函数的:
//根本不需要我们写析构,因为没有动态申请的空间需要我们销毁
class Date
{
private:int _year;int _month;int _day;
};//下面也不需要我们写析构函数,对于自定义类型,编译器会去自动调用它的构造和析构函数
class MyQueue
{
private:Stack _pushst;Stack _popst;
};
好了,以上就是对C++中构造函数和析构函数的解释,大家一定一定要学好这里,因为这里对于C++而言真的是太太太重要了。
就到这里啦,下次见各位。