本笔记内容为尚硅谷谷粒商城分布式锁Redisson-lock部分
目录
一、分布式锁与本地锁
二、分布式锁实现
使用 RedisTemplate 操作分布式锁
三、Redisson 完成分布式锁
1、简介
2、导入依赖
3、配置
4、使用
1.可重入锁
2.公平锁(Fair Lock)
3.读写锁(ReadWriteLock)
4.闭锁(CountDownLatch)
5.信号量(Semaphore)
6.缓存的数据一致性问题
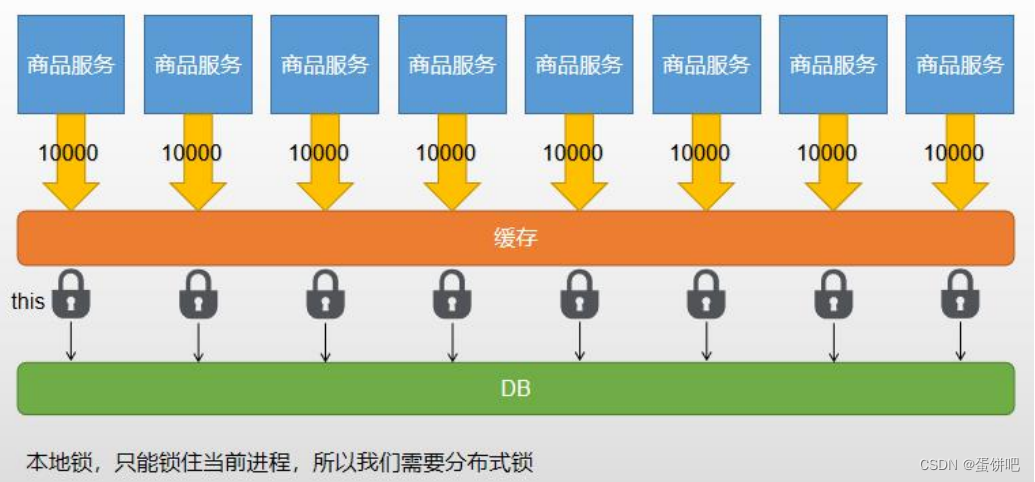
一、分布式锁与本地锁
二、分布式锁实现
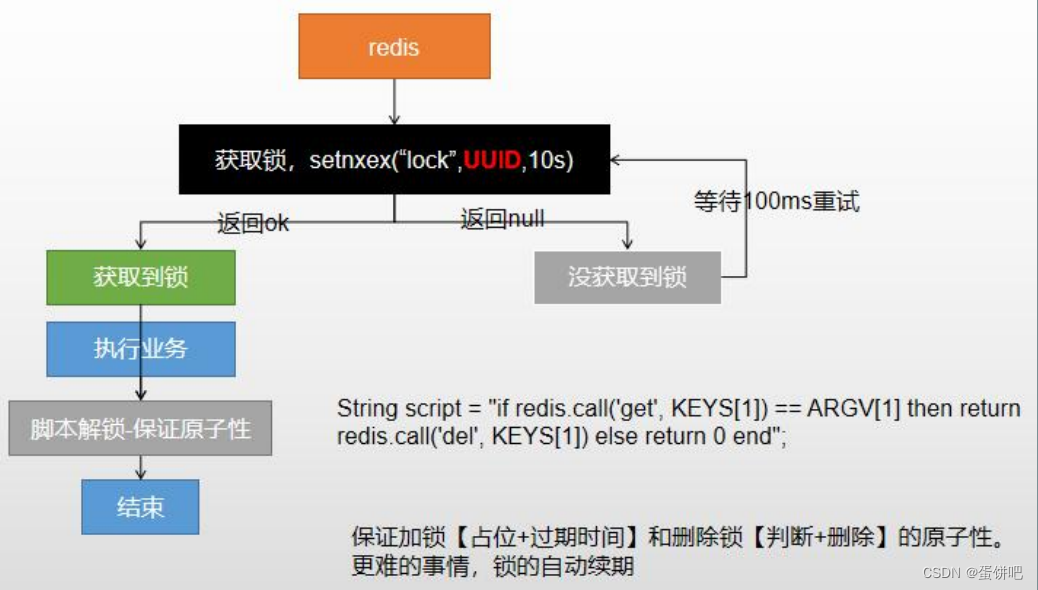
使用 RedisTemplate 操作分布式锁
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {//1 、占分布式锁。去 redis 占坑String uuid = UUID.randomUUID().toString();Boolean lock =redisTemplate.opsForValue().setIfAbsent("lock",uuid,300,TimeUnit.SECONDS);if(lock){System.out.println(" 获取分布式锁成功...");// 加锁成功 ... 执行业务//2 、设置过期时间,必须和加锁是同步的,原子的//redisTemplate.expire("lock",30,TimeUnit.SECONDS);Map<String, List<Catelog2Vo>> dataFromDb;try{dataFromDb = getDataFromDb();}finally {String script = "if redis.call('get', KEYS[1]) == ARGV[1] thenreturn redis.call('del', KEYS[1]) else return 0 end";// 删除锁Long lock1 = redisTemplate.execute(newDefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);}// 获取值对比 + 对比成功删除 = 原子操作 lua 脚本解锁// String lockValue = redisTemplate.opsForValue().get("lock");// if(uuid.equals(lockValue)){// // 删除我自己的锁// redisTemplate.delete("lock");// 删除锁// }return dataFromDb;}else {// 加锁失败 ... 重试。 synchronized ()// 休眠 100ms 重试System.out.println(" 获取分布式锁失败... 等待重试");try{Thread.sleep(200);}catch (Exception e){}return getCatalogJsonFromDbWithRedisLock();// 自旋的方式}
}三、Redisson 完成分布式锁
1、简介
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分的利用了 Redis 键值数据库提供的一系列优势, 基于 Java 实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。 使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
官方文档:目录 · redisson/redisson Wiki · GitHub
2、导入依赖
<!-- https://mvnrepository.com/artifact/org.redisson/redisson -->
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.0</version>
</dependency>
3、配置
@Configuration
public class MyRedissonConfig {/*** config.useSingleServer() 单节点模式* @Description 所有对Redisson操作都是通过RedissonClient对象* @Param destroyMethod = "shutdown" 销毁方法 服务停止销毁* @return org.redisson.api.RedissonClient*/@Bean(destroyMethod = "shutdown")RedissonClient redisson() throws IOException {//创建配置Config config = new Config();config.useSingleServer().setAddress("redis://192.168.88.130:6379");//创建实例return Redisson.create(config);}
}
4、使用
1.可重入锁

看门狗:锁的自动续期,如果业务时间超长,在业务运行期间自动给锁续上30s。
@AutowiredRedissonClient redisson;@ResponseBody@GetMapping("/hello")public String hello() {//获取一把锁 只要名字一样就是一把锁RLock lock = redisson.getLock("MY-LOCK");//lock.lock();//加锁 阻塞式等待 默认过期时间30s//锁自动续期 如果业务超长 运行期间自动续上新的30s 不用担心业务时间长锁自动过期被删除//加锁的业务只要运行完成就不会给当前锁续期 即使不手动解锁 默认30s删除lock.lock(10, TimeUnit.SECONDS);//10s自动解锁 自动解锁时间一定要大于业务执行时间//问题 lock.lock(10, TimeUnit.SECONDS); 锁时间到了以后不会自动续期//1.如果传了锁的超时时间 就发给reids执行脚本 进行占锁 默认超时时间就是我们指定的时间//2.如果没传锁的超时时间 就使用30*1000 LockWatchdogTimeout看门狗的默认时间//只要占锁成功 就会启动一个定时任务 (重新给锁设定过期时间 新的过期时间就是看门狗的默认时间)//定时任务时间 = internalLockLeaseTime(看门狗时间 )/ 3 10s//最佳实战 lock.lock(30, TimeUnit.SECONDS); 省掉了整个续期操作 自动解锁给长一点 手动解锁try {System.out.println("加锁成功 执行业务" + Thread.currentThread().getId());Thread.sleep(30000);} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();//解锁System.out.println("释放锁" + Thread.currentThread().getId());}return "hello";}
redisson默认就是可重入锁
2.公平锁(Fair Lock)
它保证了当多个Redisson客户端线程同时请求加锁时,优先分配给先发出请求的线程。所有请求线程会在一个队列中排队,当某个线程出现宕机时,Redisson会等待5秒后继续下一个线程,也就是说如果前面有5个线程都处于等待状态,那么后面的线程会等待至少25秒。
=========不设置过期时间 使用默认过期时间=========
RLock fairLock = redisson.getFairLock("anyLock");
// 最常见的使用方法
fairLock.lock();=========设置过期时间========
// 10秒钟以后自动解锁
// 无需调用unlock方法手动解锁
fairLock.lock(10, TimeUnit.SECONDS);// 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
boolean res = fairLock.tryLock(100, 10, TimeUnit.SECONDS);
...
fairLock.unlock();
3.读写锁(ReadWriteLock)
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
- 读数据加读锁,写数据加写锁
- 写锁和写锁之间、写锁和读锁之间是独占锁,读锁之间是共享锁
- 保证总是能读到最新数据。
/*** 保证一定能读的最新数据 * 修改期间 写锁是一个排他锁(互斥锁) 读锁是一个共享锁* 写锁没释放 读锁就必须等待* 读 + 读 相当于无锁 并发读只会在reids中记录好当前的读锁 都会同时加锁成功* 写 + 读 等待写锁释放* 写 + 写 阻塞方式* 读 + 写 有读锁 写也需要等待*/@ResponseBody@GetMapping("/read")public String read() {RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");String s = "";RLock rLock = lock.readLock();rLock.lock();try {System.out.println("读锁加锁成功 执行业务" + Thread.currentThread().getId());s = redisTemplate.opsForValue().get("writeValue");Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();} finally {rLock.unlock();//解锁System.out.println("读锁释放锁" + Thread.currentThread().getId());}return s;}@ResponseBody@GetMapping("/write")public String write() {RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");String s = "";RLock rLock = lock.writeLock();rLock.lock();try {System.out.println("写锁加锁成功 执行业务" + Thread.currentThread().getId());s = UUID.randomUUID().toString();Thread.sleep(30000);redisTemplate.opsForValue().set("writeValue", s);} catch (InterruptedException e) {e.printStackTrace();} finally {rLock.unlock();//解锁System.out.println("写锁释放锁" + Thread.currentThread().getId());}return s;}
4.闭锁(CountDownLatch)
/*** @Description 放假锁门 闭锁*/@ResponseBody@GetMapping("/lockDoor")public String lockDoor() throws InterruptedException {RCountDownLatch countDownLatch = redisson.getCountDownLatch("door");countDownLatch.trySetCount(5);countDownLatch.await();//等待闭锁都完成return "放假了";}@ResponseBody@GetMapping("/gogogo/{id}")public String gogogo(@PathVariable("id") Long id){RCountDownLatch countDownLatch = redisson.getCountDownLatch("door");countDownLatch.countDown();//计数减一return "ok"+id;}
5.信号量(Semaphore)
- 信号量被消耗的时候,信号量的 value 减少
- 信号量被补充的时候,信号量的 value 增加
- 当信号量不足时,消耗信号就会阻塞,直到信号量被补充
信号量也可以用作分布式限流
比如当前服务只能承受1w的并发请求,设置1w个信号量,让所有服务先获取信号量 能获取到证明有空闲线程来处理 否则等待
/*** @Description 模拟停车 限流 信号量*/@ResponseBody@GetMapping("/park")public String park() throws InterruptedException {RSemaphore park = redisson.getSemaphore("park");park.acquire();//获取一个信号量 获取一个值 阻塞式获取 一定要获取 park.tryAcquire();//有就获取 没有就算了return "ok";}@ResponseBody@GetMapping("/go")public String go(){RSemaphore park = redisson.getSemaphore("park");park.release();//释放一个信号量 释放一个值return "ok";}
6.缓存的数据一致性问题
如果缓存中已经存在数据,但是数据在数据库被修改,那么如何保证缓存的数据与数据库的数据有一致性?
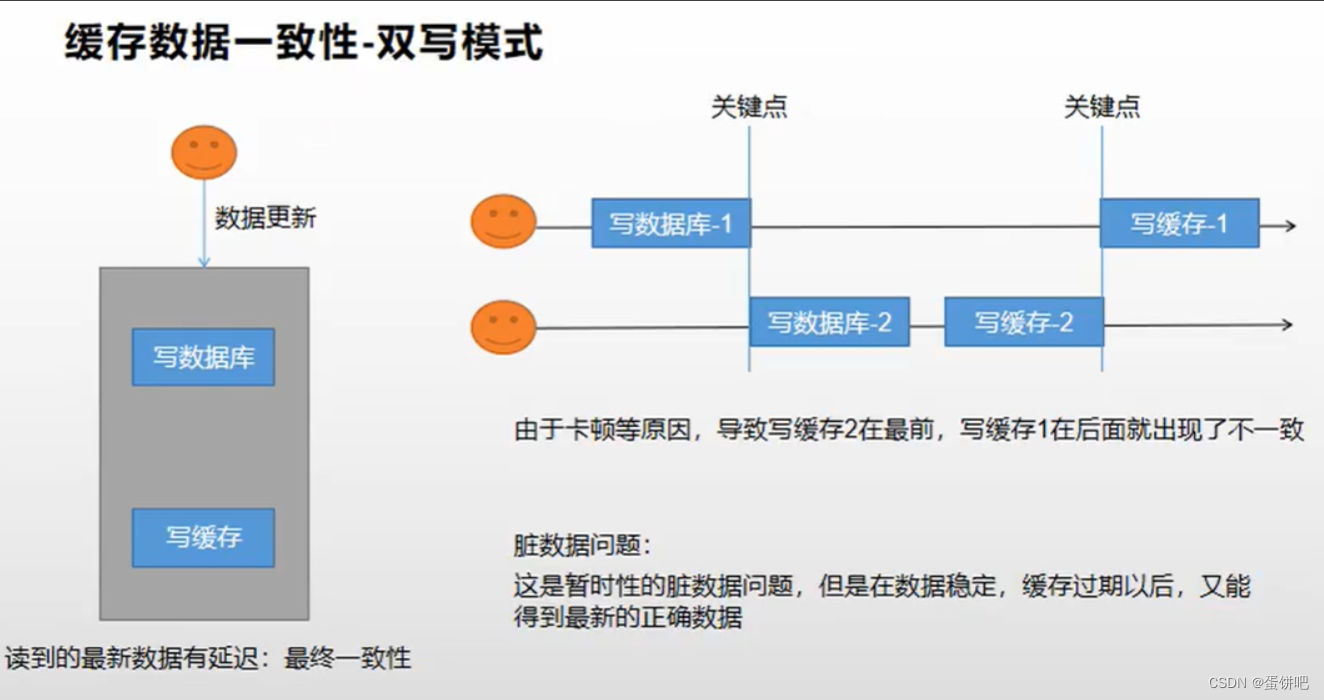
双写模式:
- 在数据更新时,同时更新缓存和数据库
- 缺点:先写数据库的一号线程可能由于卡顿等等,导致写缓存在二号线程之后,出现了脏数据的问题。
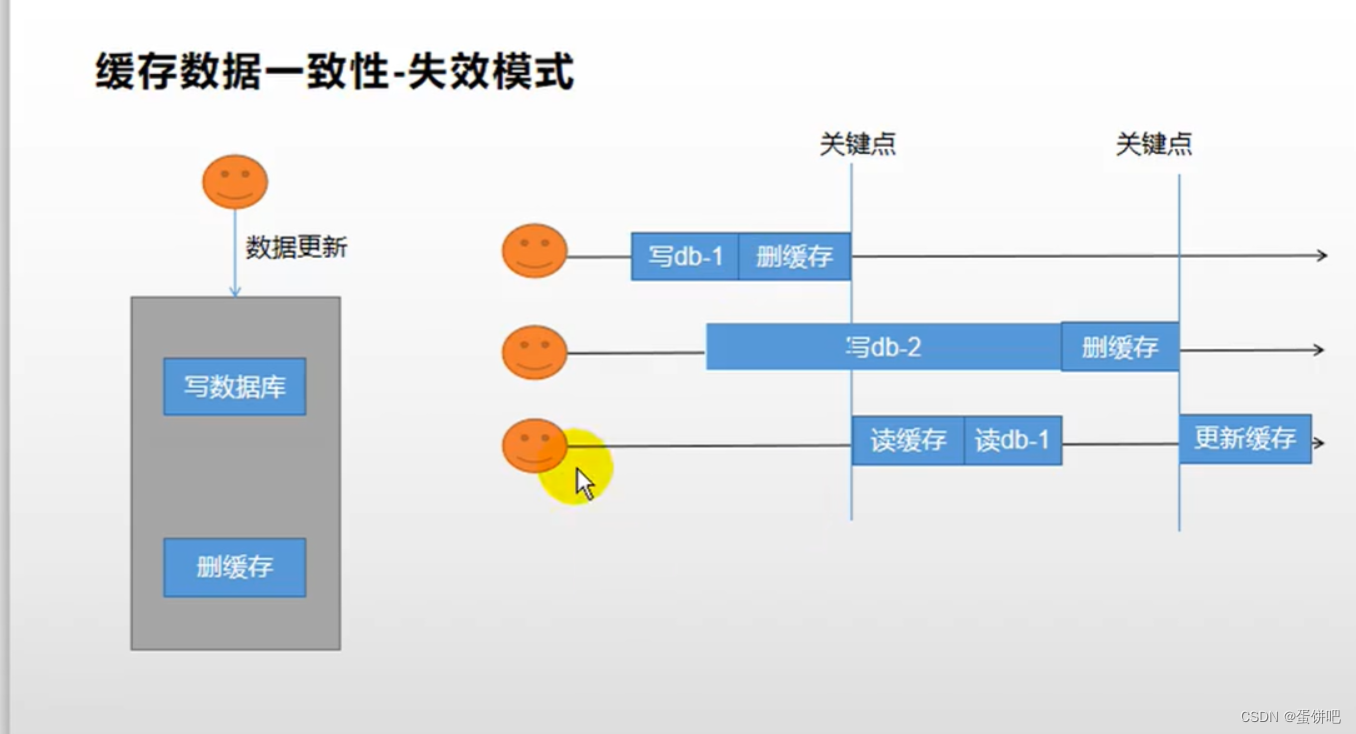
失效模式:
- 更新数据时,删除缓存
- 缺点:假设之前有一个线程修改数据,删除了缓存。紧接着在一号线程写数据库的过程中,二号线程读缓存,没有,读db,获取到的是一号线程修改数据库之前的db,紧接着在二号线程更新缓存之前,一号线程删除了缓存,导致缓存中的数据是二号线程修改之前的数据,产生了脏数据。
解决方法:

结束!