前言
在大数据应用中,现在发现依赖关系非常复杂,在上线之前很长测试,前一段时间在部署udf 出现了导致生产Hiveserver2
宕机问题,出现严重事故。现在就咨询研究一下。Maven虽然已经诞生多年,但仍然是当前最流行的Java系项目管理工具之一。在使用Maven的过程中,比较常见也相对难解决的问题就是依赖冲突,Gradle和sbt也同样存在此问题。本文先简述Maven中的依赖原则,然后通过两个例子讲述解决方法。
Maven依赖原则
Maven具有传递依赖(transitive dependency)的特性,即如果组件A依赖组件B,组件B依赖组件C,那么A就会自动产生对C的依赖,以此类推。这使我们不必再关心众多依赖背后的关系,只需要着眼于自己需要的组件,很方便。
但是,传递依赖会使得项目依赖空间逐渐扩展。当依赖非常多时,不可避免地会出现相同组件版本不同的情况。Maven内置了依赖仲裁(dependency mediation)机制来处理该问题,具体来说有以下两条。
最近依赖优先(nearest definition wins)
如果有如下的Maven依赖关系树:
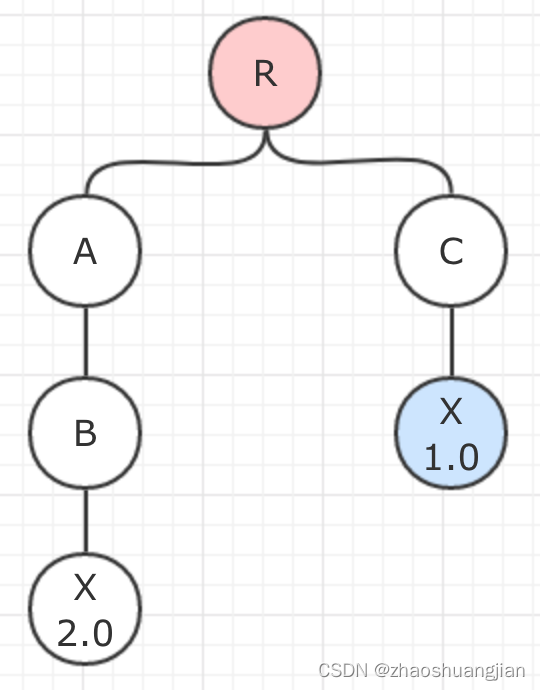
在这种情况下,根组件R传递依赖了两个版本不同的X。由于R→C→X这条路径比R→A→B→X要短,也就是说X 1.0比X 2.0距离R更近,所以会选择X 1.0作为依赖,X 2.0会被忽略。
最先声明优先(first declaration wins)
如果出现了下图这种情况:
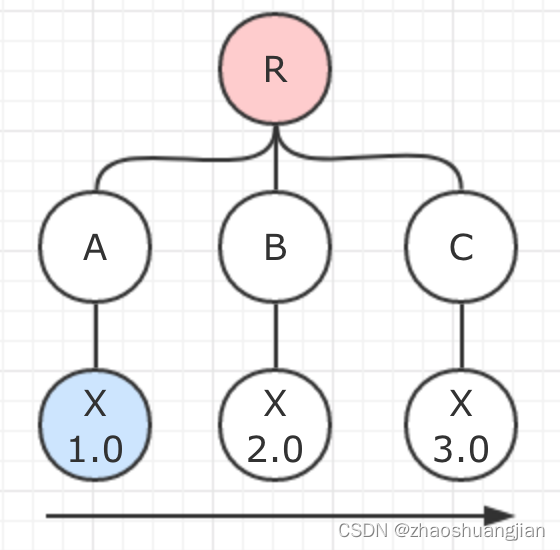
同一组件的不同版本深度相同的话,就会按声明的顺序判定。图中R的依赖声明顺序是A→B→C,所以会选择A所引用的X 1.0作为依赖。如果反过来的话,就会选择X 3.0。
Maven的依赖仲裁已经可以摆平大部分问题,但是有时由于组件兼容性不好,就需要自己解决冲突了。下面举两个来自我们日常的简化版例子。
例子一:应用Dependency插件和依赖原则
有一个与推荐系统相关的项目需要同时访问HBase集群和Codis集群,pom文件中有如下依赖(实际上我们对Codis和Jodis源码做了大量改动,但为了方便举例,这里用原版):
<properties><hbase.version>1.2.0</hbase.version><jodis.version>0.5.1</jodis.version>
</properties><dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>io.codis.jodis</groupId><artifactId>jodis</artifactId><version>${jodis.version}</version></dependency>
</dependencies>
然后普通地创建一个Codis连接池:
JedisResourcePool jedisResourcePool = RoundRobinJedisPool.create().curatorClient("10.10.99.130:2181,10.10.99.132:2181,10.10.99.133:2181,10.10.99.124:2181,10.10.99.125:2181", 10000).zkProxyDir("/jodis/bd-redis").build();
结果抛出找不到ZK构造方法的异常:

看起来好好的Maven工程抛出NoClassDefFoundError或者NoSuchMethodError,首先要考虑的就是Maven依赖冲突。我们用Maven Dependency插件来检查依赖,在工程目录下执行mvn dependency:tree命令打印依赖树,并加上-Dverbose参数输出详细的冲突信息,加上-Dincludes:org.apache.zookeeper过滤出与ZK相关的依赖,输出如下:
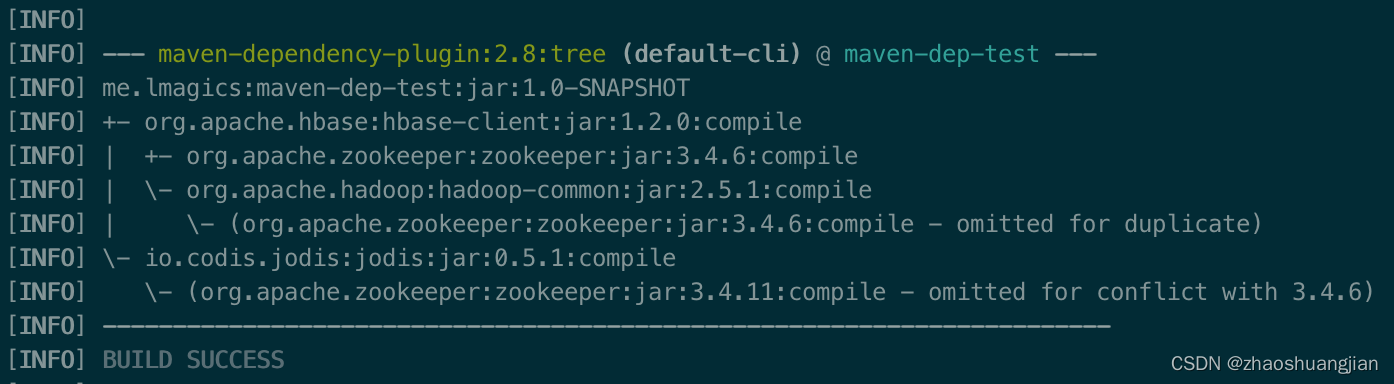
据上述依赖原则,生效的依赖是3.4.6版本的,但是Jodis中依赖的是较高版本3.4.11(被忽略了),其调用的ZK构造方法在低版本中并不存在,故抛出NoSuchMethodError。问题找到了,解决方法也有多种:
- 将两个依赖调换一下位置,让Jodis依赖的高版本ZK先声明。
- 在原pom中依赖列表的第一位添加ZK 3.4.11,这样它的路径就是最短的了。
- 将ZK 3.4.11写在标签下,它会强制让项目中所有ZK依赖都应用该版本。
- 排除掉hbase-client里的低版本依赖,即:
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency>
另外,也可以借助图形化工具来检查依赖,比如IntelliJ IDEA里的Maven Helper等,不再赘述。
下面来看另一种情况。
例子二:应用Shade插件
上述项目中会通过HBase连接做查询,简单描述如下:
Configuration conf = HBaseConfiguration.create();
conf.set("...", "...");
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("table"));
Get get = new Get(Bytes.toBytes("row_key"));
Result result = table.get(get);
该项目后来又需要用到Guava 20.0。添加依赖后,抛出如下异常:
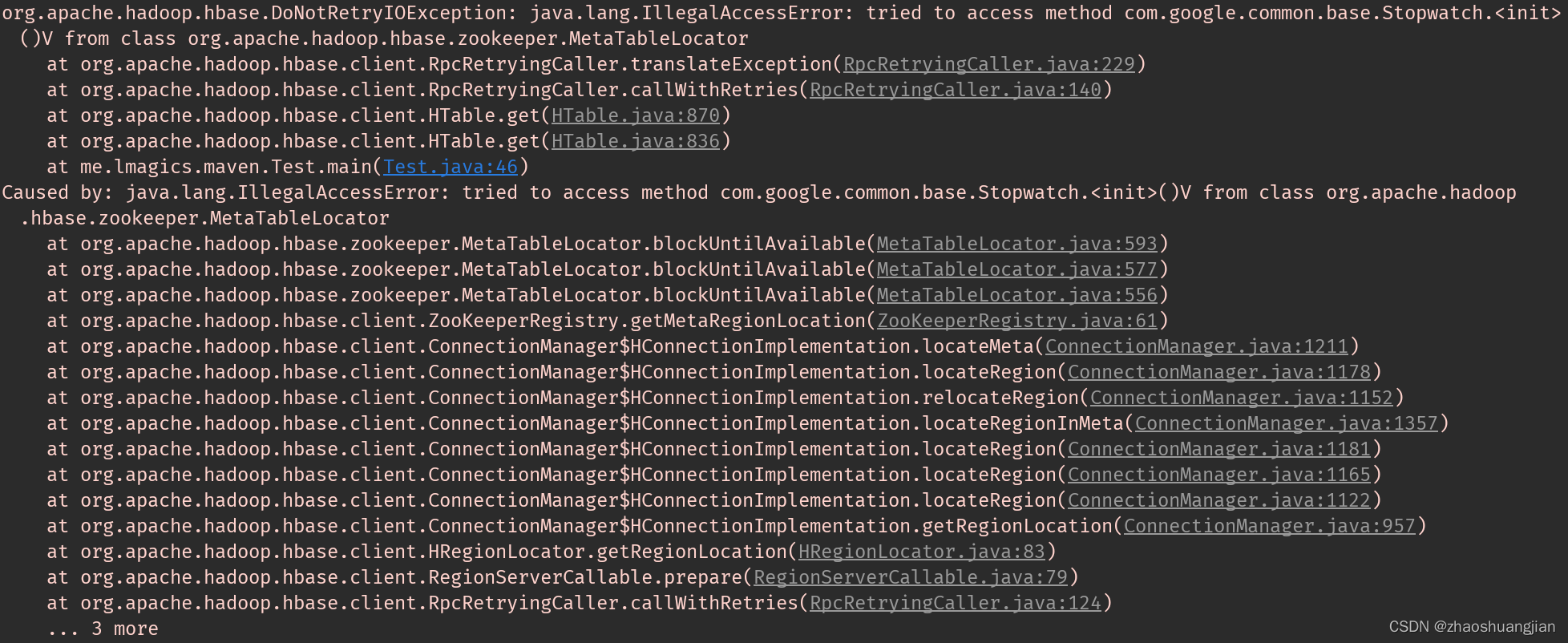
Stopwatch是Guava中的基础类,HBase的元数据表定位器MetaTableLocator中用到了它。用Dependency插件观察Guava相关的依赖:
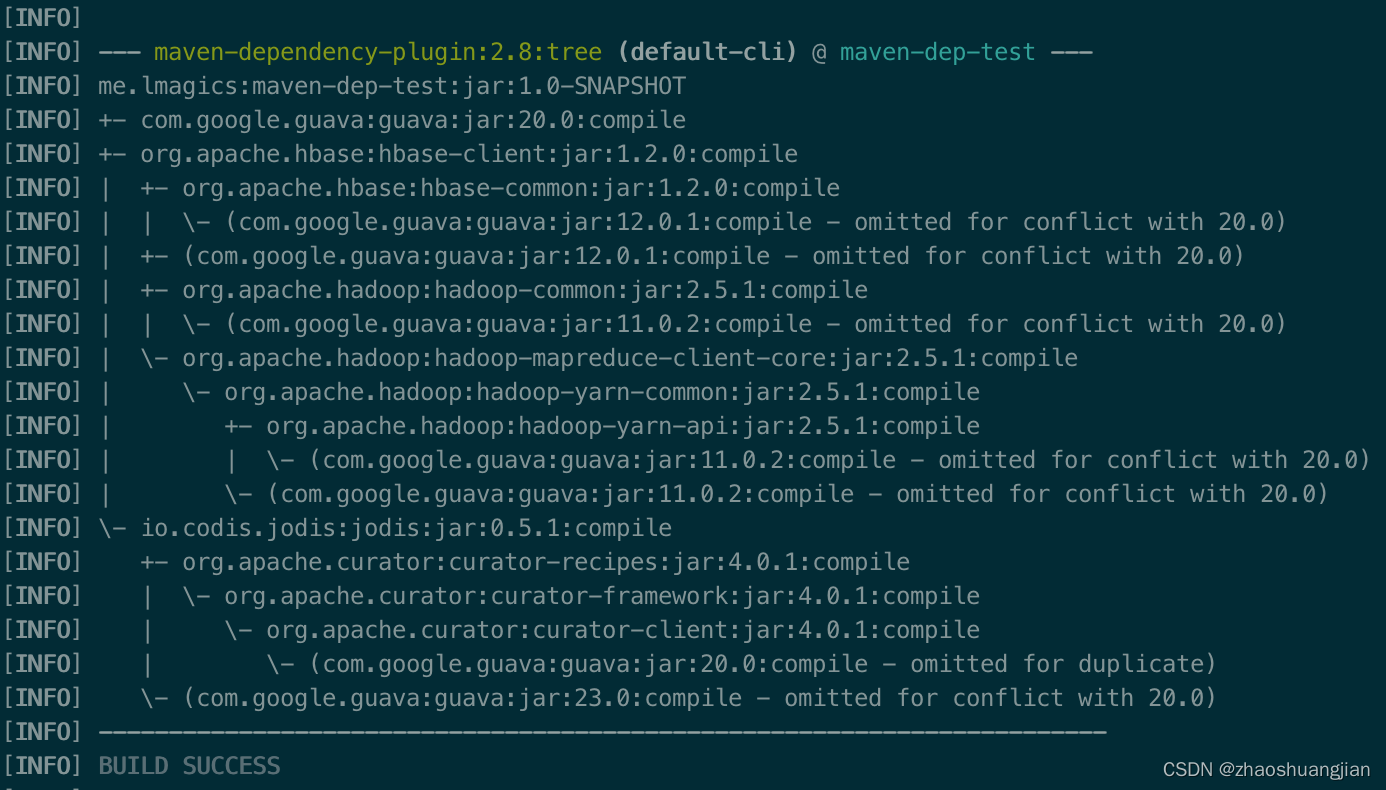
这个依赖树复杂些,出现了4个Guava版本,从低到高分别是11.0.2(Hadoop)、12.0.1(HBase)、20.0(实际应用的版本)和23.0(Jodis)。根据先验知识,Guava从16.0版本开始发生了很大变化,没有向前兼容,所以HBase的API会出现问题。由于我们必须使用高版本Guava,故不能通过例子一中的任何方法来解决冲突,这时就可以让Maven Shade插件上场了。
简单地讲,Shade插件负责将Maven项目及其依赖打成Uber JAR包,并且还能将依赖通过重命名等方式隐藏起来。我们就可以将高版本Guava(低版本也行,总之是冲突方之一)的依赖重命名,从而消除冲突。从上图中可以发现,Jodis已经引用了更高版本的Guava 23.0,我们可以直接Shade它,因为20.0和23.0是兼容的。
打开Jodis的pom文件,添加以下内容:
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.4.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><relocations><relocation><pattern>com.google.guava</pattern><shadedPattern>shaded.com.google.guava</shadedPattern></relocation><relocation><pattern>com.google.common</pattern><shadedPattern>shaded.com.google.common</shadedPattern></relocation></relocations></configuration></execution></executions>
</plugin>
重新构建之后,删去项目中原来的Guava引用,就可以直接导入Shade过的高版本Guava的类,冲突解除:
import shaded.com.google.common.hash.Funnels;
import shaded.com.google.common.hash.Hashing;
同理,如果不Shade Jodis,而去Shade HBase相关依赖的话,可以不必去修改HBase的源码。另外创建一个新的空Maven项目,在其pom文件中写入HBase相关的依赖,再打包即可。当实际引用时,就要在依赖里写自定义Shade包的GAV,而不是原依赖的GAV了。


![[pgrx开发postgresql数据库扩展]7.返回序列的函数编写(2)表序列](https://img-blog.csdnimg.cn/img_convert/c0f3c08d10ab46ada568f0a2994ac713.webp?x-oss-process=image/format,png)
