本次分享内容为NDSS收录的一篇文章:《Local and Central Differential Privacy for Robustness and Privacy in Federated Learning》。这篇论文主要分析了LDP和CDP在联邦学习中对于隐私性以及鲁棒性的作用。围绕这篇论文的分享将分为以下4个部分:
-
动机与方法
-
背景知识
-
针对FL的攻击方法与防御方法
-
总结
一、动机与方法
1.动机:
现有防御手段只能针对隐私性以及鲁棒性两个维度中的一个进行保护,因此抛出两个问题:
-
是否能同时对上述两个维度进行保护?
-
如何衡量保护效果与模型可用性之间的trade-off?
2.方法及达到的效果:
总结了针对FL的两个维度,即鲁棒性和隐私性的现有攻击以及防御手段,分析了分析LDP和CDP对于FL中的鲁棒性和隐私性的保护效果,其可行性的Intuition在于:LDP 是sample-level,CDP是participant-level,能够不同程度的降低‘poisonous data or gradients’在训练中的影响,同时能够提供不同程度的隐私保护。此外,在实际的数据集上进行了大量的实验比较,验证了LDP和CDP的作用。
二.背景知识
1.联邦学习
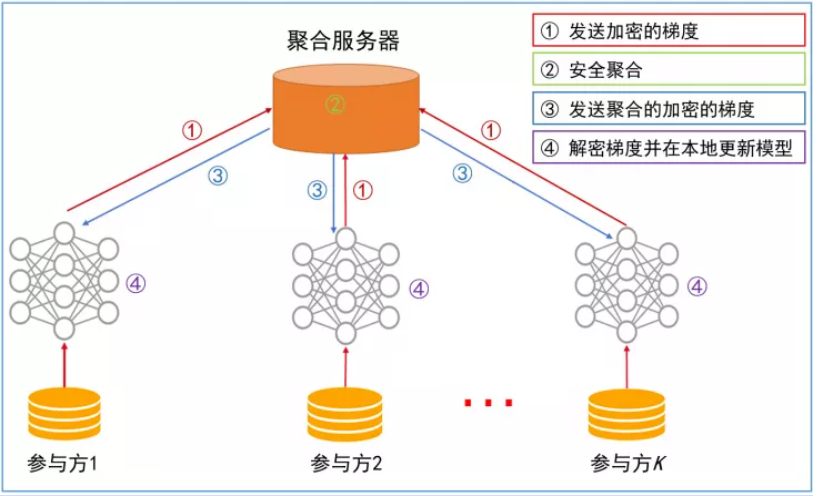
图片来源:https://air.tsinghua.edu.cn/info/1008/1312.htm
联邦学习最早由Google提出,主要的思想是各个数据方本地迭代训练模型,得到模型的梯度,再交由中心服务器进行梯度的聚合,并将聚合后的梯度发送给各个数据方。为了保护模型的梯度以及抵御恶意攻击,中心服务器会采用不同的聚合方法或者同态加密的技术,提高安全性以及鲁棒性。
2.差分隐私
差分隐私提供了一种方式来量化隐私泄露的程度,其标准定义为:

而用于机器学习领域,可以用于在发送或者聚合梯度是对包含隐私信息的梯度加噪:
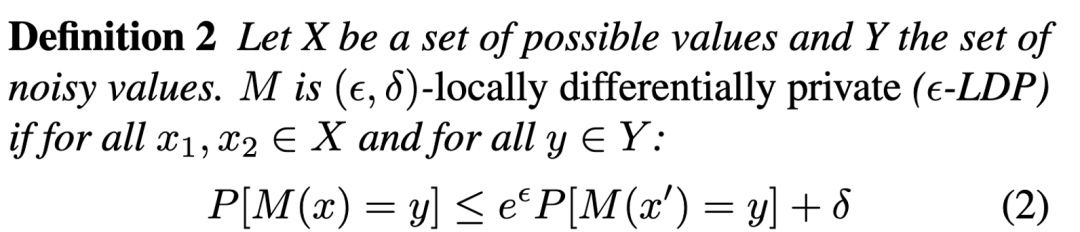
3.差分隐私+联邦学习
加噪的常见位置有:
-
Loss Function:修改模型的损失函数
-
Model:对训练好的模型参数加噪
-
Gradients:对模型训练过程中的梯度加噪
目前使用最多的为对梯度加噪,修改损失函数需要分析模型的收敛性,而对最终模型加噪可能会导致严重的精度损失。
加噪的常见方式有如下两种,基于DP-SGD [1]
- LDP:local differential privacy。即由各方本地对还未聚合的梯度加噪

- CDP:central differential privacy。即由中心服务器对聚合的梯度加噪

上述两种加噪方式都是在计算梯度的时候,根据梯度的二范数添加噪声。
三.针对FL的攻击方法与防御方法
鲁棒性(Robustness)
1.攻击方法
投毒攻击(注意,此种攻击假设的adversary只有client),有如下分类
-
Random: 构造一些随机样本/梯度,或者错分类的样本来降低最终模型的Acc
-
Target (Backdoor): 构造特定的样本/梯度,使得特定sample的分类结果为指定值
此篇文章针对的是Target,即Backdoor后门攻击。

后门攻击中 [2,3],模型参数使用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZmyxZvJk-1683356837955)(null)]表示,backdoored version 用 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nt9jBuQ0-1683356837842)(null)]表示,
在聚合时使用model-replacement的方式实现攻击:
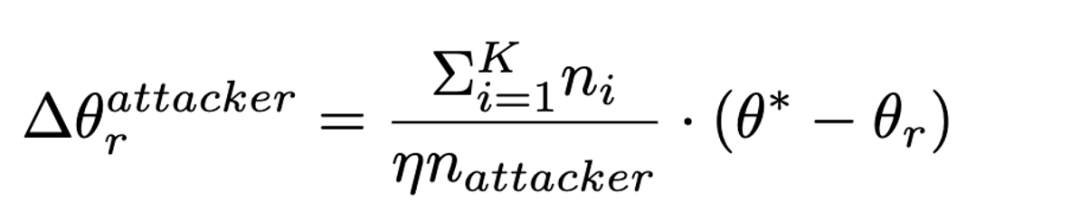
因此有:
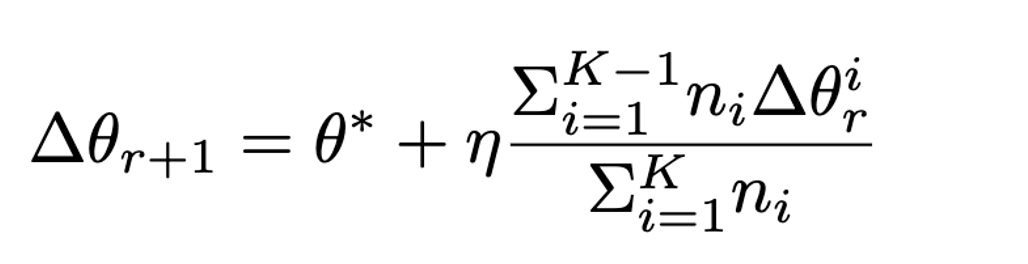
2.防御方法
-
Byzantine-robust 防御:Krum,Trimmed Mean…
-
这里没有分析对于Bzyzantine 相关的defense,claim是这些方案并没有提供privacy相关保护
-
Sun et al.[2] 提出Norm Bounding 和 Weak DP 来防御攻击
-
Norm Bounding:通过对梯度进行限制,减弱恶意攻击方的梯度对于模型训练的影响
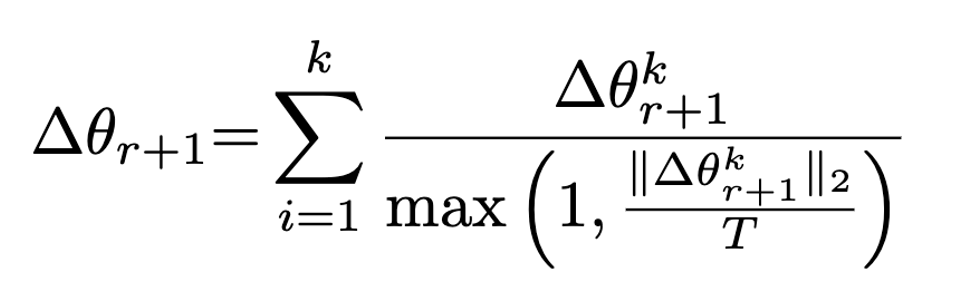
-
Weak DP:类似CDP,但是没有考虑Total Privacy Budget,即会导致添加的噪声过多,影响模型的可用性
-
Small noise, large privacy loss
3.实验结果
实验设置:选取两个数据集上的实验为例
-
EMNIST- 5-layer CNN. 2400 clients
-
CIFAR10 – ResNet18 100 clients
评估的metrics为Main Task Accuracy 以及 Backdoor Accuracy。前者代表了模型的可用性(越高说明可用性越好),后者代表了抵御攻击的能力(越低说明Backdoor成功的几率越小)。
Setting 1:使用[2]中的攻击方法,每轮迭代中只有一个攻击方
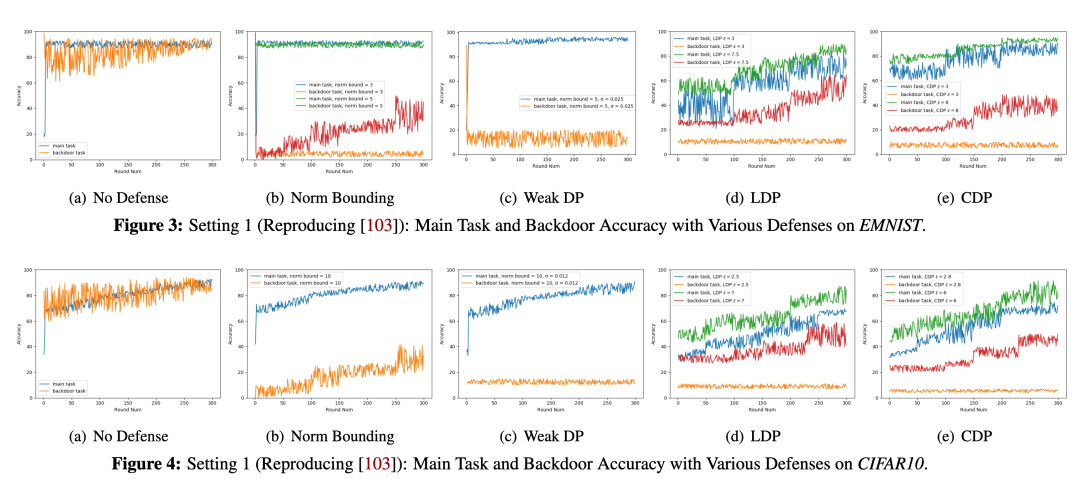
图三可以看到如果没有加任何防御手段,虽然Main Task Accuracy很高,但是相应的 Backdoor Accuracy也很高,说明后门攻击的效果很好。
Norm Bounding和Weak DP都能带来一定程度的抵御,但是Norm Bounding在训练多轮之后仍然会导致较高的Backdoor Accuracy。
LDP和CDP对于后门攻击的抵御效果显著,但是epsilon的增加会导致utility的下降,Main Task Accuracy对比Weak DP较低。
Setting 2: 增加每一轮迭代中攻击方的数量,并且攻击方可以选择是否按照协议执行LDP defense
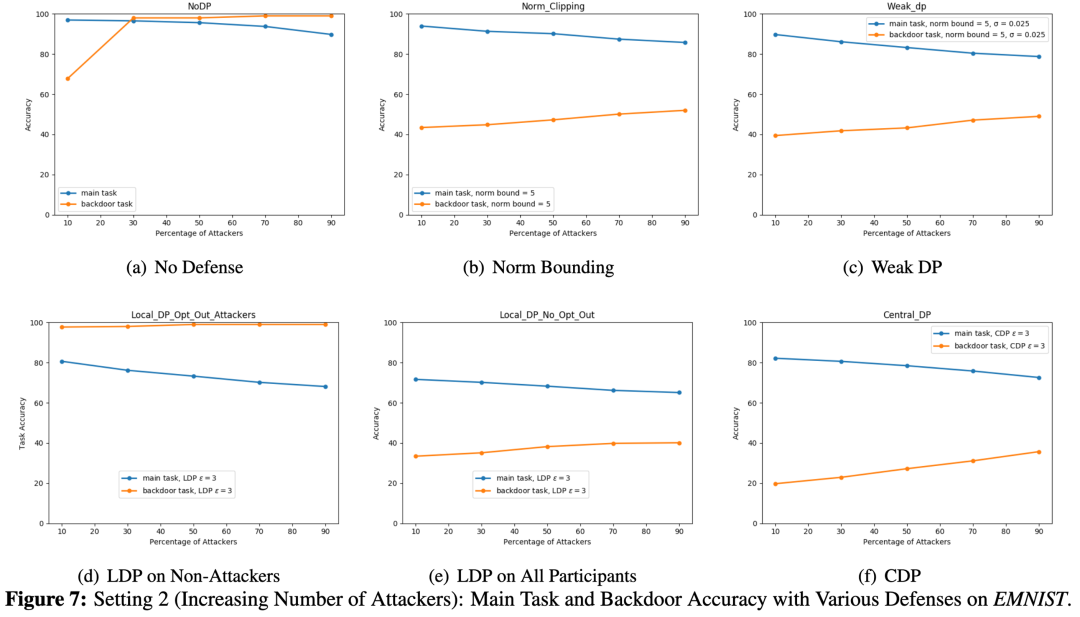
LDP和CDP相较Norm Bounding和Weak DP能够起到很好的防御效果,然而也导致utility下降。值得注意的是,LDP防御中只需要10%的攻击方不添加噪声,能够比没有defense起到更强的attack 效果。这是因为没有加DP的梯度对聚合的模型梯度有更大影响。
单从robustness上来看的话,LDP和CDP没有显著的优势。此外,CDP会对server有安全假设,而LDP对于攻击的防御很弱(假设client为攻击方)
隐私性(Privacy)
1.攻击方法
注意,此种攻击假设的adversary可以是client,也可以是server
- Membership Inference Attack [4]:
-
Gradient Ascent
-
Isolating
-
Isolating Gradient Ascent
- Property Inference Attack [5]:(需要有数据)
-
Passive:通过使用不同数据的梯度,根据梯度判断训练数据是否包含特定属性
-
Active:修改local model使得模型学习的数据表示和property相关
-
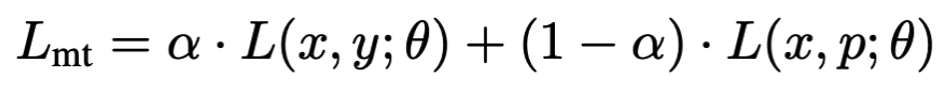
2.防御方法
-
Dropout
-
Gradient Sampling
不过这篇文章并没有针对现有的这些方案进行实验对比,仍然选择Norm Bounding 和Weak DP进行实验对比。
3.实验结果
Membership Inference Attack
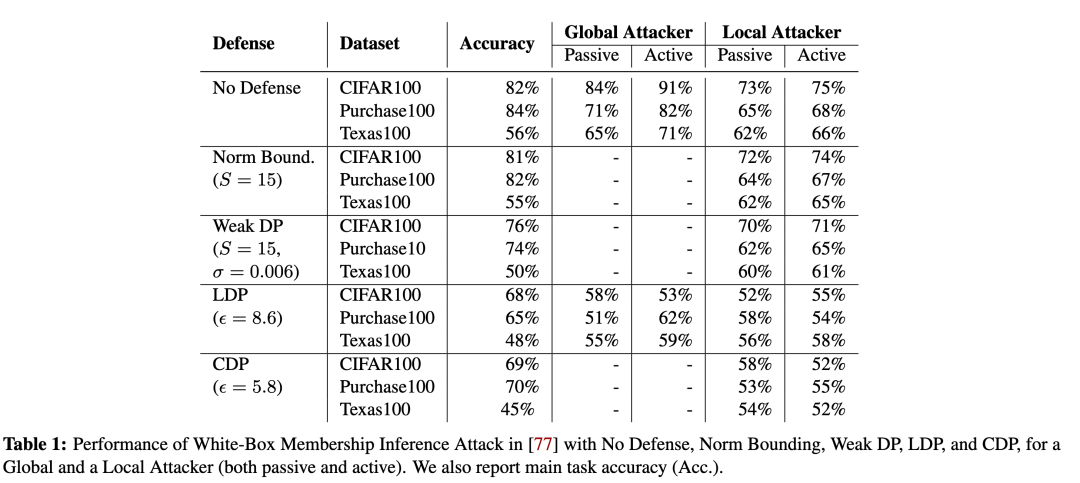
LDP和CDP能够显著抵御membership inference attack,而Norm Bounding 和 Weak DP的防御效果很弱。LDP和CDP的缺点在于,同样会导致更高的utility loss,模型Main Task Accuracy相比不加defense下降了十几个点。因此这是utility和privacy的一个trade-off。
Property Inference Attack
主要任务是性别分类,property inference的目的是判断种族
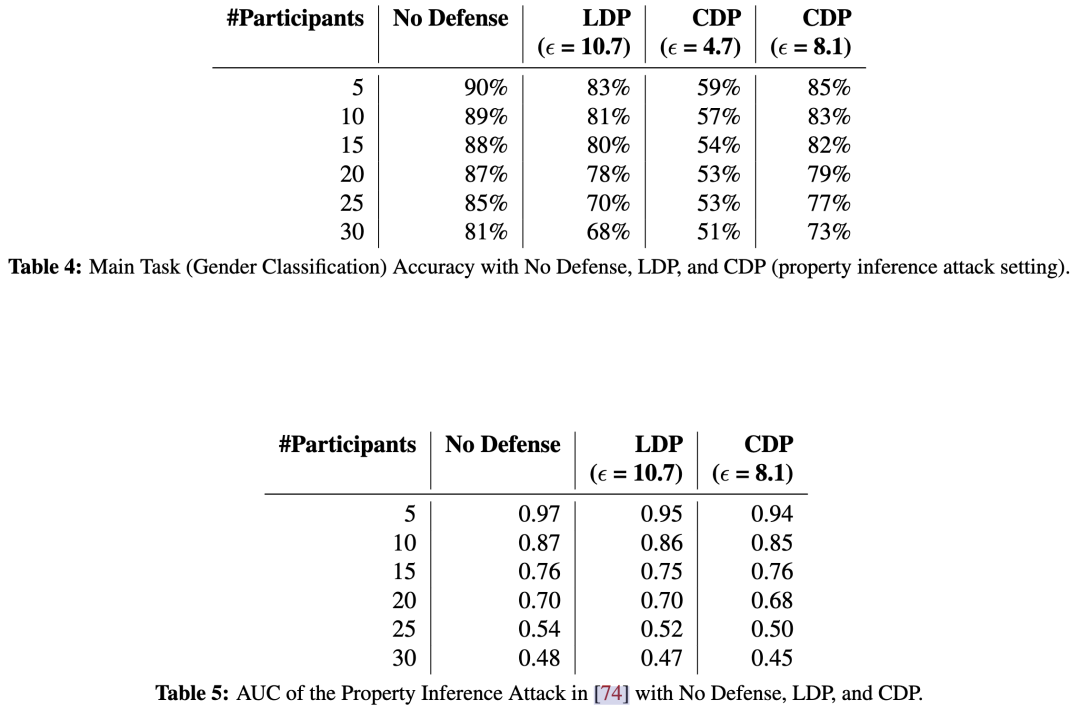
实验结果可以看到LDP和CDP均不能很好的抵御Property Inference Attack。
四.总结
相较现有的分别针对鲁棒性和隐私性的防御方法,LDP和CDP能够同时抵御这两类攻击。但是也存在utility和privacy的显著trade-off,并且不能低于property inference attack。未来需要考虑将LDP、CDP和现有的防御手段进行结合,在提高鲁棒性和隐私性的同时,减少可用性的损失。此外,作者指出需要设计出更加合理实际的方法来比较CDP和LDP所提供的隐私保护程度。
Ref
[1]: Deep Learning with Differential Privacy. CCS 2016
[2]: Can You Really Backdoor Federated Learning.
[3]: How To Backdoor Federated Learning.
[4]: Comprehensive privacy analysis of deep learning. S&P 2019
[5]: Exploiting unintended feature leakage in collaborative learning. S&P 2019