文章目录
- 页
- 区
- 获得页
- 获得填充为 0 的页
- 释放页
- kmalloc()
- gfp_mask 标志
- kfree()
- vmalloc()
- slab 层
- slab 层的设计
- slab 分配器的接口
- 在栈上的静态分配
- 单页内核栈
- 高端内存的映射
- 永久映射
- 临时映射
- 每个 CPU 的分配
- 新的每个 CPU 接口
页
struct page 结构表示系统中的物理页,位于:include/linux/mm_types.h

- flag:页的状态。
- _count:页的引用次数。值为 -1 表示当前内核没有引用这一页,该页可分配。内核调用 page_count() 进行检查。
- virtual:页的虚拟地址。
区
由于硬件存在缺陷而引起的内存寻址问题:
- 一些硬件只能用某些特定的内存地址来执行 DMA。
- 一些体系结构的内存物理寻址范围比虚拟寻址范围大得多。这样,就有一些内存不能永久地映射到内核空间上。
因为存在这些约束,因此 Linux 主要使用了 4 种分区:
- ZONE_DMA —— 这个区包含的页能用来执行 DMA 操作。
- ZONE_DMA32 —— 和 ZOME_DMA 类似,该区包含的页面可以用来执行 DMA 操作;而和 ZONE_DMA 不同之处在于,这些页面只能被 32 位设备访问。在某些体系结构中,该区比 ZONE_DMA 更大。
- ZONE_NORMAL —— 这个区包含的都是正常能映射的页。
- ZONE_HIGHEM —— 这个区包含“高端内存”,其中的页并不能永久地映射到内核地址空间。
区的实际使用和分布都与体系结构有关。

- Linux 把系统的页划分为区,形成不同的内存池,这样就可以根据用途进行分配了。
- 注意,区的划分没有任何物理意义,这只不过是内核为了管理页而采取的一种逻辑上的分组。
获得页
以页为单位分配内存,分配 2 o r d e r 2^{order} 2order 个物理页,位于:include/linux/gfp.h
alloc_pages(gfp_t gfp_mask, unsigned int order) {return alloc_pages_current(gfp_mask, order);
}
将给定的页转为它的逻辑地址:
- include/linux/mm.h
- mm/highmem.c
/*** page_address - get the mapped virtual address of a page* @page: &struct page to get the virtual address of** Returns the page's virtual address.*/
void *page_address(struct page *page) {unsigned long flags;void *ret;struct page_address_slot *pas;if (!PageHighMem(page))return lowmem_page_address(page);pas = page_slot(page);ret = NULL;spin_lock_irqsave(&pas->lock, flags);if (!list_empty(&pas->lh)) {struct page_address_map *pam;list_for_each_entry(pam, &pas->lh, list) {if (pam->page == page) {ret = pam->virtual;goto done;}}}
done:spin_unlock_irqrestore(&pas->lock, flags);return ret;
}
上面函数返回一个指针,指向给定物理页当前所在的逻辑地址。若用不到 struct page,可以用:
路径:mm/page_alloc.c
/** Common helper functions.*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;/** __get_free_pages() returns a 32-bit address, which cannot represent* a highmem page*/VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);page = alloc_pages(gfp_mask, order);if (!page)return 0;return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
获得填充为 0 的页
带有 zeroed 的函数,会将分配好的页都填充成 0。用户空间的页在返回之前,必须将分配的页填充为 0。

释放页
void __free_pages(struct page *page, unsigned int order)
{if (put_page_testzero(page)) {if (order == 0)free_hot_cold_page(page, 0);else__free_pages_ok(page, order);}
}EXPORT_SYMBOL(__free_pages);void free_pages(unsigned long addr, unsigned int order)
{if (addr != 0) {VM_BUG_ON(!virt_addr_valid((void *)addr));__free_pages(virt_to_page((void *)addr), order);}
}EXPORT_SYMBOL(free_pages);
记住,分配完内存后,必须检测是否分配成功,否则会出现大问题。
kmalloc()
以字节为单位申请一块连续的内核空间。
位于:
-
include/linux/slab.h
-
include/linux/slab_def.h
static __always_inline void *kmalloc(size_t size, gfp_t flags) { ... }
gfp_mask 标志
行为修饰符:
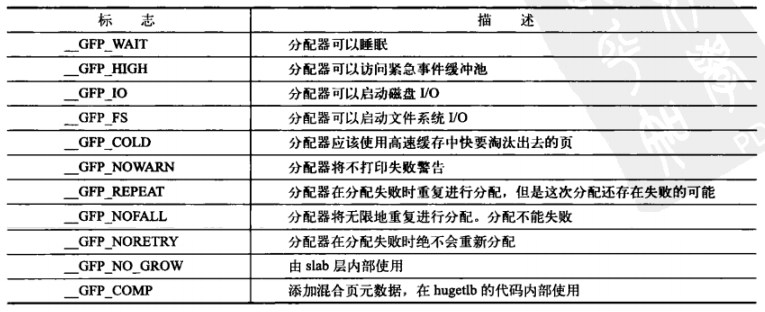
多个行为修饰符可以使用或运算符连接,如:
__GFP_WAIT | __GPT_IO | __GFP_FS
区修饰符:

指定从哪个区分配资源,若未指定任何标志,默认从 ZONE_DMA 或 ZONE_NORMAL 分配,优先从 ZONE_NORMAL 分配。
不能给 _get_free_pages() 或 kalloc() 指定 ZONE_HIGHMEM,因为这两个函数返回的都是逻辑地址,而不是 page 结构,这两个函数分配的内存当前有可能还没有映射到内核的虚拟地址空间,因此,也可能根本就没有逻辑地址。
类型标志:
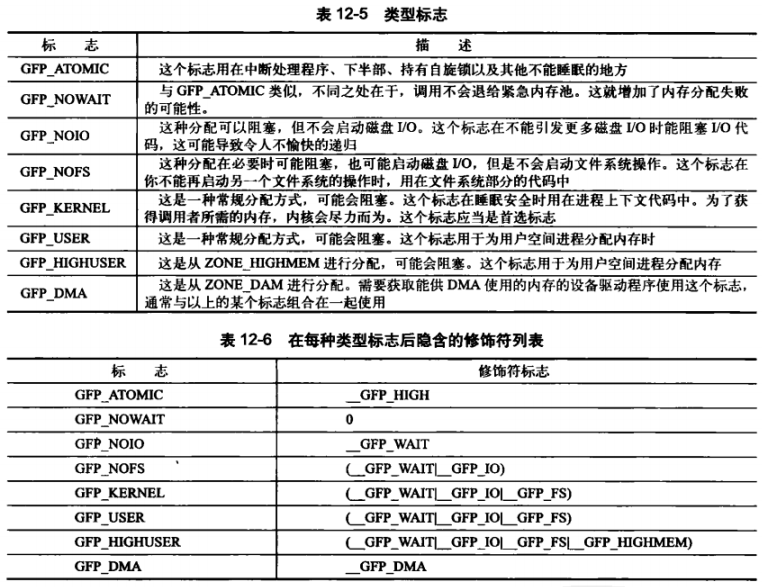
通常,要么用 GFP_KERNEL,要么是 GFP_ATOMIC。

kfree()
kmalloc() 所对应的内存释放函数 kfree()。
void kfree(const void *);
kfree() 只能释放由 kmalloc() 分配出来的内存资源。若想要释放的内存不是由 kmalloc() 申请的,或想要释放的内存早被释放了,再调用 kfree() 的话,就会导致很严重的后果。
和用户空间一样,申请和释放函数都是一对的。
vmalloc()
kmalloc() 确保页在物理地址上是连续的(虚拟地址自然也是连续的)。
vmalloc() 只确保页在虚拟地址是连续的。
硬件设备用到的任何内存区都必须是物理上连续的块,而不仅仅是虚拟地址连续上的块。应用程序所使用的内存块可以使用只有虚拟地址连续的内存块。
通过 vmalloc() 获得的页必须一个一个地进行映射(因为物理地址可以不连续),这就导致比直接内存映射大得多的 TLB 抖动。
对应释放:vfree()。
路径:
- include\linux\vmalloc.h
- mm\vmalloc.c
slab 层
空闲链表:便于数据的频繁分配和回收。当需要内存块时,就从空闲链表中取出一个,不用时就放回去,而不是释放它。
缺点:在内核中,空闲链表无法全局控制。当可用内存变得紧缺时,内核无法通知每个空闲链表,让其收缩缓存的大小以便释放出一些内存。
slab 层,即 slab 分配器来nibu缺陷。
slab 分配器在如下基本原则中寻求一种平衡:

slab 层的设计
一个高速缓存由多个 slab 组成,而一个 slab 由多个同类型对象。
slab 由一个或多个物理上连续的页组成。
slab 的三种状态:
- 满:没有空闲对象可分配。
- 部分满:有部分空闲对象可分配。
- 空:没有一个被分配的对象。
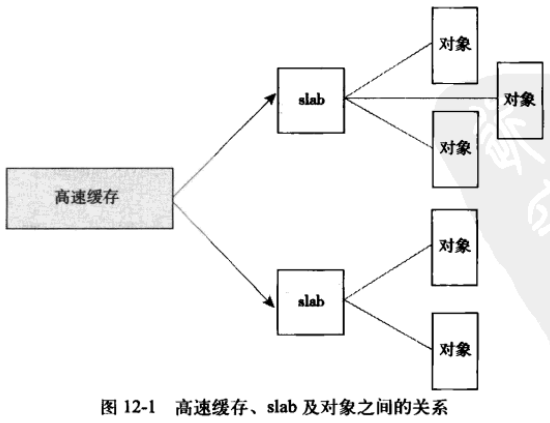
高速缓存的结构:
// include/linux/slab_def.h
struct kmem_cache {// ...struct kmem_list3 *nodelists[MAX_NUMNODES];// ...
}
// mm/slab.c
/** The slab lists for all objects.*/
struct kmem_list3 {struct list_head slabs_partial; /* partial list first, better asm code */struct list_head slabs_full;struct list_head slabs_free;// ...
}
slab 结构:
// mm/slab.c
/** struct slab** Manages the objs in a slab. Placed either at the beginning of mem allocated* for a slab, or allocated from an general cache.* Slabs are chained into three list: fully used, partial, fully free slabs.*/
struct slab {struct list_head list; // 三种状态的链表unsigned long colouroff; // slab 着色的偏移量void *s_mem; // 在 slab 中的第一个对象unsigned int inuse; // slab 中已分配的对象数kmem_bufctl_t free; // 第一个空闲对象unsigned short nodeid;
};
slab 描述符要么在 slab 之外另行分配,要么就放在 slab 自身开始的地方。
slab 分配器可以创建新的 slab,这通过 __get_free_pages() 低级内核页分配器进行。
// mm/slab.c
/** Interface to system's page allocator. No need to hold the cache-lock.** If we requested dmaable memory, we will get it. Even if we* did not request dmaable memory, we might get it, but that* would be relatively rare and ignorable.*/
static void *kmem_getpages(struct kmem_cache *cachep, gfp_t flags, int nodeid)
{struct page *page;int nr_pages;int i;#ifndef CONFIG_MMU/** Nommu uses slab's for process anonymous memory allocations, and thus* requires __GFP_COMP to properly refcount higher order allocations*/flags |= __GFP_COMP;
#endifflags |= cachep->gfpflags;if (cachep->flags & SLAB_RECLAIM_ACCOUNT)flags |= __GFP_RECLAIMABLE;page = alloc_pages_exact_node(nodeid, flags | __GFP_NOTRACK, cachep->gfporder);if (!page)return NULL;nr_pages = (1 << cachep->gfporder);if (cachep->flags & SLAB_RECLAIM_ACCOUNT)add_zone_page_state(page_zone(page),NR_SLAB_RECLAIMABLE, nr_pages);elseadd_zone_page_state(page_zone(page),NR_SLAB_UNRECLAIMABLE, nr_pages);for (i = 0; i < nr_pages; i++)__SetPageSlab(page + i);if (kmemcheck_enabled && !(cachep->flags & SLAB_NOTRACK)) {kmemcheck_alloc_shadow(page, cachep->gfporder, flags, nodeid);if (cachep->ctor)kmemcheck_mark_uninitialized_pages(page, nr_pages);elsekmemcheck_mark_unallocated_pages(page, nr_pages);}return page_address(page);
}
slab 层的管理就是在每个高速缓存的基础上,通过提供给整个内核一个简单的接口来完成的。通过接口就可以创建和撤销新的高速缓存,并在高速缓存内分配和释放对象。高速缓存及其内 slab 的复杂管理完全通过 slab 层的内部机制来处理。当你创建了一个高速缓存后,slab 层所起的作用就像一个专门的分配器,可以为具体的对象类型进行分配。
slab 分配器的接口
连续上了一个下午的讲座,头疼,不记了,艹!
在栈上的静态分配
单页内核栈
进程设置为单页内核栈的好处:
- 可以让每个进程减少内存消耗。
- 随着时间的推移,避免因为物理内存碎片化而造成给新进程分配两个未分配、连续的页变得困难。
中断栈:
- 中断栈为每个进程提供一个用于中断处理程序的栈。
- 这样中断处理程序就不用再和被中断的进程共享同一个内核栈了,它们可以使用自己的栈了。
高端内存的映射
在高端内存中的页不能永久映射到内核地址空间上。因此通过 alloc_pages() 以 __GFP_HIGHMEM 标志获得的页不可能有逻辑地址。
x86 的高端内存中的页被映射到 3GB~4GB。
永久映射
// linux/high.mem.h
// 将 page 映射到内核地址空间
void *kmap(struct page *page)
// 对应的解除映射
void kunmap(struct page *page)
- 高端或低端内存都可以使用。
- 若 page 对应低端那一页,返回该页虚拟地址。若是高端,则建立一个永久映射,返回物理地址。
- 该函数可休眠,因此只能用在进程上下文中。
临时映射
void *kmap_atomic(struct page *page, enum km_type type)
void *kunmap_atomic(struct page *kvaddr, enum km_type type)
- 该函数不可休眠。
- type 描述了临时映射的目的。
每个 CPU 的分配
- 支持 SMP 的现代操作系统使用每个 CPU 上的数据,对于给定的处理器其数据是唯一的。
- 一般来说,每个 CPU 的数据存放在一个数组中。数组中的每一项对应着系统上的一个处理器。
声明数据:
unsigned long my_percpu[NR_CPUS];
按照如下方式访问:
int cpu;
cpu = get_cpu(); // 获得当前处理器,并禁止内核抢占
my_percpu[cpu]++; // ...
printk("my_percpu on cpu=%d is %lu\n", cpu, my_percpu[cpu]);
put_cpu(); // 激活内核抢占
因为所操作的数据对当前处理器来说是唯一的。没有其它处理器可以访问到该数据,不存在并发访问的问题,因此当前处理器可以在不用锁的情况下安全访问它。
内核抢占引起的问题:
- 如果你的代码被其他处理器抢占被重新调度,那么这时 CPU 变量就会无效,因为它指向的是错误的处理器(通常,代码获得当前处理器后是不可休眠的)。
- 如果另一个任务抢占了你的代码,那么有可能在同一个处理器上发生并发访问 my_percpu 的情况,显然这属于一个竞争条件。
使用下面的方法来保护数据安全,就不需要自己手动禁止内核抢占:
- get_cpu():获得当前处理器号。该函数会禁止内核抢占。
- put_cpu():重新激活当前处理器号。
新的每个 CPU 接口
略…