什么是GPU
GPU(Graphics Processing Unit)代表图形处理单元。该术语通常与图形卡或视频卡等术语互换使用。从技术上讲,GPU 是第三方显卡或主板上的主要图形处理芯片。
GPU 与 CPU不同。CPU 是中央处理器,它是计算机的主要大脑。GPU 专用于执行在计算机上渲染图像、视频和动画所需的密集计算。
GPU 对于需要大量处理能力的高分辨率视频游戏尤为重要。
GPU作用
GPU 的工作方式与 CPU 类似——它以极快的速度执行计算。GPU 的主要工作是进行与图形相关的计算,以便 CPU 可以继续处理其他所有事情。
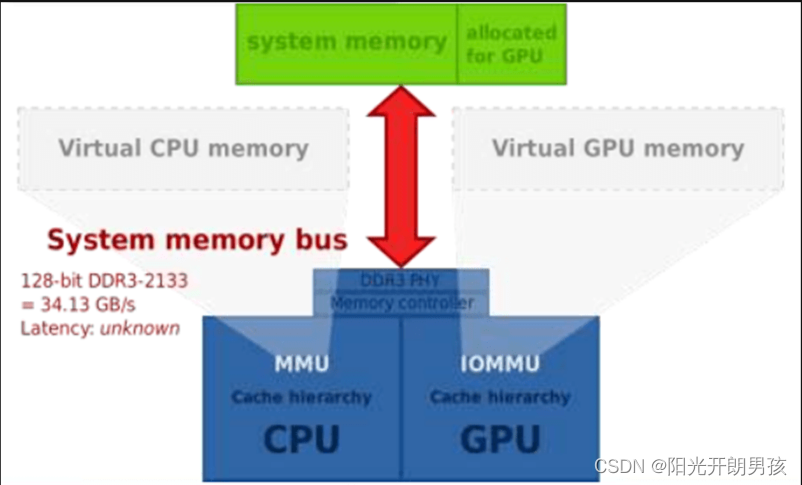
由于它是一个独立的芯片,它可以与 CPU 同时执行计算,从而为其他任务腾出处理能力。独立GPU一般封装在独立的显卡电路板上,拥有独立显存,而集成GPU常和CPU共用一个Die,共享系统内存。
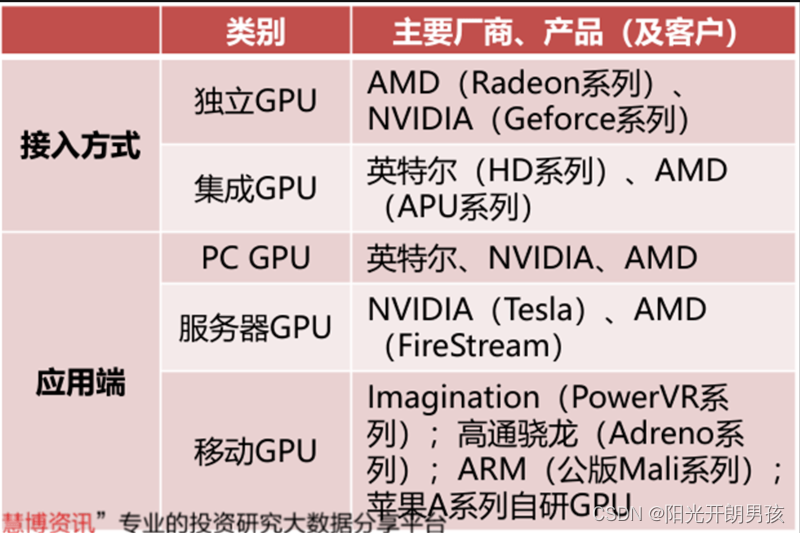
可以在计算机中找到两种主要类型的 GPU —集成 GPU(集显) 和离散 GPU(独显)。
集成GPU
集成 GPU内置于计算机主板中,而不是单独显卡的一部分。它甚至可以集成到 CPU 本身中。
集成 GPU 常见于笔记本电脑中,其中外形尺寸通常优先于可升级性。由于大多数笔记本电脑并非为升级而设计,因此在购买笔记本电脑时确保您的 GPU 足以满足您的需求非常重要。
如果您打算将笔记本电脑用于游戏,许多游戏都会有推荐的规格,包括处理能力和图形的最低规格。如果您正在寻找一款游戏笔记本电脑,则值得查找您喜欢玩的游戏类型的系统要求,以确保您选择的笔记本电脑的 CPU 和 GPU 都能胜任工作。
离散GPU
GPU 的另一种主要类型是离散 GPU。这是一个独立的图形处理器——通常采用可移动图形卡的形式。
即使您的计算机具有集成 GPU,您也可以安装更强大的显卡并将其用于图形密集型任务(例如游戏或视频渲染),而不是使用功能较弱的集成显卡。离散 GPU 的美妙之处在于,如果您发现需要更多图形处理能力,您可以继续升级。您需要做的就是用更强大的显卡更换显卡,以立即提高计算机的图形性能。
离散 GPU 的一个缺点是它们往往会消耗更多功率并产生更多热量。一些笔记本电脑同时具有独立显卡和集成显卡,但使用集成 GPU 来节省能源。然后,当需要更强大的图形性能时,这些设备会切换到独立 GPU。
在 Windows 上查找 GPU 信息
使用键盘快捷键Windows+R打开“运行”窗口。在窗口中输入dxdiag并按Enter。
DirectX 诊断工具打开后,单击“显示” 选项卡。
在这里,您可以看到您正在使用的显卡的名称和制造商等信息。
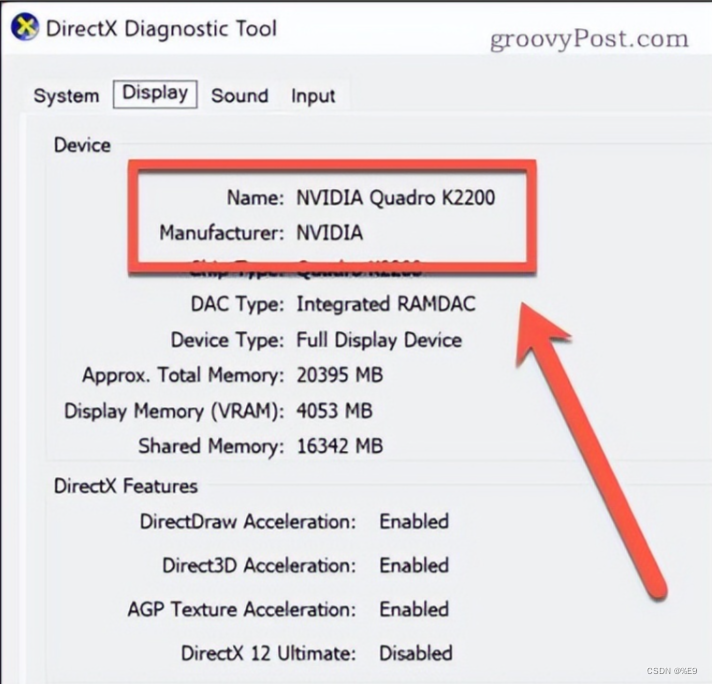
GPU 的其他用途
GPU 主要设计用于执行显示高质量图形所需的数字运算。然而,它们的能力也使它们成为许多其他用途的理想选择。
在渲染高质量视频时,GPU 对于减轻 CPU 的一些负载非常有用。它们也非常适合用于机器学习项目,例如Folding@Home,它使用您的 GPU 和 CPU 能力来帮助发现以前未知的医学进步。
然而,GPU 最近最著名的用途之一是加密货币的挖掘。GPU 的计算能力使其非常适合解决挖掘某些类型的加密货币(如比特币)所需的复杂数学方程。
这样做的一个缺点是 GPU 通常需求量很大,这可能导致库存短缺和价格上涨。
GPU内部结构
GPU通常包括图形显存控制器、压缩单元、BIOS、图形和计算整列、总线接口、电源管理单元、视频管理单元、显示界面。
GPU的出现使计算机减少了对CPU的依赖,并解放了部分原本CPU的工作。在3D图形处理时,GPU采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。

GPU的微架构(Micro Architecture)是一种给定的指令集和图形函数集合在处理器中执行的方法。
图形函数主要用于绘制各种图形所需要的运算。当前和像素、光影处理、3D坐标变换等相关运算由GPU硬件加速来实现。相同的指令集和图形函数集合可以在不同的微架构中执行,但实施的目的和效果可能不同。
优秀的微架构对GPU性能和效能的提升发挥着至关重要的作用,GPU体系是GPU微架构和图形API的集合。
以目前最新的英伟达安培微架构为例,GPU微架构的运算部份由流处理器(Stream Processor,SP)、纹理单元(Texture mapping unit, TMU)、张量单元(Tensor Core)、光线追踪单元(RT Cores)、光栅化处理单元(ROPs)组成。这些运算单元中,张量单元,光线追踪单元由NVIDIA在伏特/图灵微架构引入。
除了上述运算单元外,GPU的微架构还包含L0/L1操作缓存、Warp调度器、分配单元(Dispatch Unit)、寄存器堆(register file)、特殊功能单元(Special function unit,SFU)、存取单元、显卡互联单元(NV Link)、PCIe总线接口、L2缓存、二代高位宽显存(HBM2)等接口。
英伟达安培内核
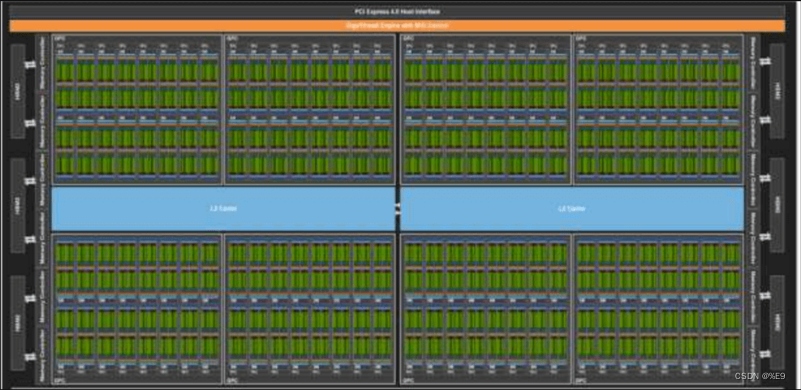
英伟达安培内核“SM”单元

GPU的流处理器单元是NVIDIA对其统一架构GPU内通用标量着色器的命名。SP单元是全新的全能渲染单元,是继Pixel Pipelines(像素管线)和Vertex Pipelines(顶点管线)之后新一代的显卡渲染技术指标。SP单元既可以完成VS(Vertex Shader,顶点着色器)运算,也可以完成PS(Pixel Shader,像素着色器)运算,而且可以根据需要组成任意VS/PS比例,从而给开发者更广阔的发挥空间。
流处理器单元首次出现于DirectX 10时代的G80核心的Nvidia GeForce 8800GTX显卡,是显卡发展史上一次重大的革新。之后AMD/ATI的显卡也引入了这一概念,但是流处理器在横向和纵向都不可类比,大量的流处理器是GPU性能强劲的必要非充分条件。
纹理映射单元(TMU)作为GPU的部件,它能够对二进制图像旋转、缩放、扭曲,然后将其作为纹理放置到给定3D模型的任意平面,这个过程称为纹理映射。纹理映射单元不可简单跨平台横向比较,大量的纹理映射单元是GPU性能强劲的必要非充分条件。
光栅化处理单元(ROPs)主要负责游戏中的光线和反射运算,兼顾AA、高分辨率、烟雾、火焰等效果。游戏里的抗锯齿和光影效果越厉害,对ROPs的性能要求就越高,否则可能导致帧数的急剧下降。NVIDIA的ROPs单元是和流处理器进行捆绑的,二者同比例增减。在AMD GPU中,ROPs单元和流处理器单元没有直接捆绑关系。
英伟达RTX 3080 GPU-Z参数

消费GPU的实时光线追踪在2018年由英伟达的“图灵”GPU首次引入,光追单元(RT Cores)在此过程中发挥着决定性的作用。图灵GPU的光追单元支持边界体积层次加速,实时阴影、环境光、照明和反射,光追单元和光栅单元可以协同工作,进一步提高帧数和阴影的真实感。
光追单元在英伟达的RTX光线追踪技术、微软DXR API、英伟达Optix API和Vulkan光追API的支持下可以充分发挥性能。拥有68个光追单元的RTX2080Ti在光线处理性能上较无光追单元的GTX1080Ti强10倍。
张量单元(Tensor Core)在2017年由英伟达的“伏特”GPU中被首次引入。张量单元主要用于实时深度学习,服务于人工智能,大型矩阵运算和深度学习超级采样(DLSS),可以带来惊人的游戏和专业图像显示,同时提供基于云系统的快速人工智能。
英伟达RTX2080Ti张量单元算力

英伟达图灵GPU光追单元运作流程

英伟达图灵GPU张量单元提供多精度AI

GPU的API(Application Programming Interface)应用程序接口发挥着连接应用程序和显卡驱动的桥梁作用。不过随着系统优化的深入,API也可以直接统筹管理高级语言、显卡驱动和底层汇编语言。
3D API能够让编程人员所设计的3D软件只需调动其API内的程序,让API自动和硬件的驱动程序沟通,启动3D芯片内强大的3D图形处理功能,从而大幅地提高3D程序的设计效率。同样的,GPU厂家也可以根据API标准来设计GPU芯片,以达到在API调用硬件资源时的最优化,获得更好的性能。3D API可以实现不同厂家的硬件、软件最大范围兼容。如果没有API,那么开发人员必须对不同的硬件进行一对一的编码,这样会带来大量的软件适配问题和编码成本。
目前GPU API可以分为2大阵营和若干其他类。2大阵营分别是微软的DirectX标准和KhronosGroup标准,其他类包括苹果的Metal API、AMD的Mantle(地幔)API、英特尔的One API等。
微软DirectX和Khronos Group API组合对比

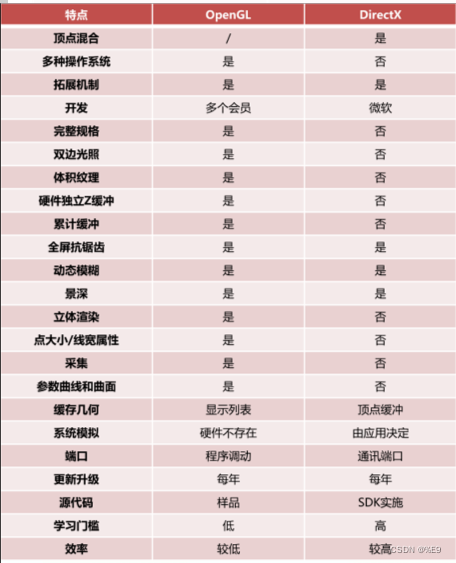
DirectX是Direct eXtension的简称,作为一种API,是由微软公司创建的多媒体编程接口。DirectX可以让以Windows为平台的游戏或多媒体程序获得更高的执行效率,加强3D图形和声音效果,并提供设计人员一个共同的硬件驱动标准,让游戏开发者不必为每一品牌的硬件来写不同的驱动程序,也降低用户安装及设置硬件的复杂度。DirectX已被广泛使用于Windows操作系统和Xbox主机的电子游戏开发。
OpenGL是Open Graphics Library的简称,是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API),相比DirectX更加开放。这个接口由近350个不同的函数组成,用来绘制从简单的二维图形到复杂的三维景象。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发。
正是由于OpenGL的开放,所以它可以被运行在Windows、MacOS、Linux、安卓、iOS等多个操作系统上,学习门槛也比DirectX更低。但是,效率低是OpenGL的主要缺点。
DirectX和OpenGL特点对比
Metal是Apple在2014年创建的接近底层的,低开销的硬件加速3D图形和计算着色器API。Metal在iOS 8中首次亮相。Metal在一个API中结合了类似于OpenGL和OpenCL的功能。它旨在通过为iOS,iPadOS,macOS和tvOS上的应用程序提供对GPU硬件的底层访问来提高性能。相较于OpenGL ES,Metal减少了10倍的代码拥挤,提供了更好的解决方案,并将会在苹果设备中取代OpenGL。Metal也支持英特尔HD和IRIS系列GPU、AMD的GCN和RDNA GPU、NVIDIA GPU。Metal也是可以使用Swift或Objective-C编程语言调用的面向对象的API。GPU的全部操作是通过Metal着色语言控制的。
2017年,苹果推出了Metal的升级版Metal2,兼容前代Metal硬件,支持iOS11,MacOS和tvOS11。Metal2可以在Xcode中更有效地进行配置和调试,加快机器学习速度,降低CPU工作量,在MacOS上支持VR,充分发挥A11 GPU的特性。
Vulkan是一种低开销,跨平台的3D图像和计算API。Vulkan面向跨所有平台的高性能实时3D图形应用程序,如视频游戏和交互式媒体。与OpenGL,Direct3D 11和Metal相比,Vulkan旨在提供更高的性能和更平衡的CPU/GPU用法。除了较低的CPU使用外,Vulkan还旨在使开发人员更好地在多核CPU中分配工作。
Vulkan源自并基于AMD的Mantle API组件,最初的版本被称为OpenGL的下一代。最新的Vulkan1.2发布于2020年1月15日,该版本整合了23个额外经常被使用的Vulkan拓展。
OpenGL和Vulkan对比

软件生态方面,GPU无法单独工作,必须由CPU进行控制调用才能工作,而CPU在处理大量类型一致的数据时,则可调用GPU进行并行计算。所以,GPU的生态和CPU的生态是高度相关的。
近年来,在摩尔定律演进的放缓和GPU在通用计算领域的高速发展的此消彼长之下,通用图形处理器(GPGPU)逐渐“反客为主”,利用GPU来计算原本由CPU处理的通用计算任务。
目前,各个GPU厂商的GPGPU的实现方法不尽相同,如NVIDIA使用的CUDA(compute unified device architecture)技术、原ATI的ATI Stream技术、Open CL联盟、微软的DirectCompute技术。这些技术可以让GPU在媒体编码加速、视频补帧与画面优化、人工智能与深度学习、科研领域、超级计算机等方面发挥异构加速的优势。以上4种技术中,只有OpenCL支持跨平台和开放标注的特性,还可以使用专门的可编程电路来加速计算,业界支持非常广泛。
DirectX和OpenGL生态对比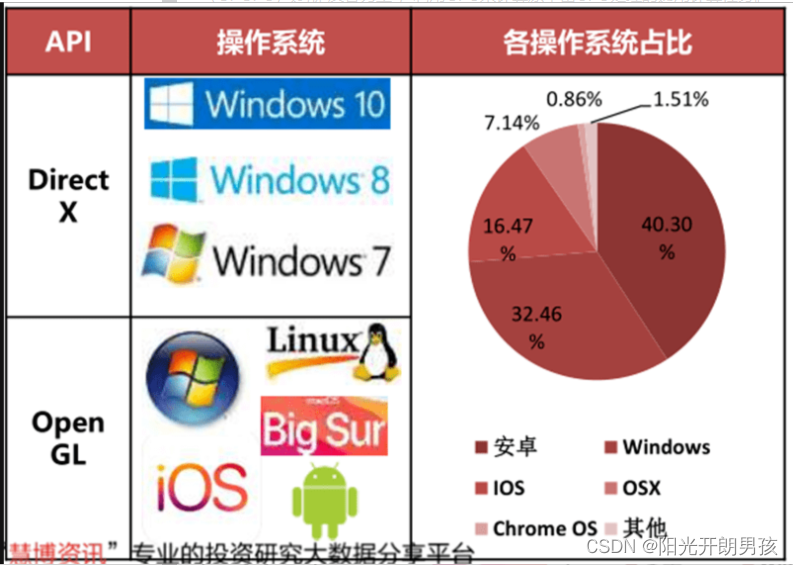
OpenCL联盟生态

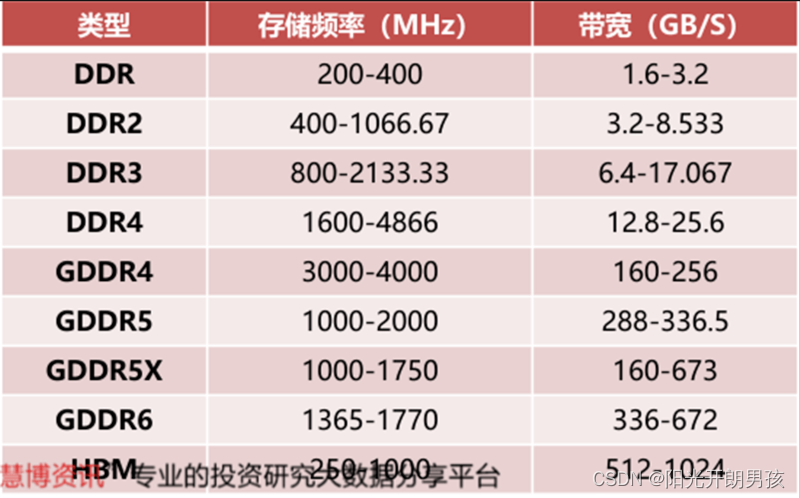
GPU显存是用来存储显卡芯片处理过或者即将提取的渲染数据,是GPU正常运作不可或缺的核心部件之一。GPU的显存可以分为独立显存和集成显存两种。目前,独立显存主要采用GDDR3、GDDR5、GDDR5X、GDDR6,而集成显存主要采用DDR3、DDR4。服务器GPU偏好使用Chiplet形式的HBM显存,最大化吞吐量。
集成显存受制于64位操作系统的限制,即便组成2通道甚至4通道,与独立显存的带宽仍有相当差距。通常这也造成了独立GPU的性能强于集成GPU。
显存的主要分类
独立显存的工作方式

独立显存的工作方式