搭建hadoop集群我们必须拥有自己的虚拟机,下列我会给大家奉上超详细的集群搭建以及我在搭建的时候碰到的问题以及对应解决办法,正所谓自己走过的错路是曲折的,也是防止大家做弯路,不仅浪费时间还心态爆炸,下面带走入hadoop集群搭建。
1.下载VMware
这里给大家提供一个下载Vmware虚拟机的网站:
VMware - Delivering a Digital Foundation For Businesses
- 进去之后点击产品-产品-更多产品-搜索work
- 对应的系统根据自己的电脑进行选择(下载后就是傻瓜式安装,不多做解释)
- VM密钥可在网上自行查找
2.下载Centos7系统
阿里云镜像下载地址:centos-7-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
环境的配置根据自己的电脑的配置进行选择(虚拟机最好分50g内存)
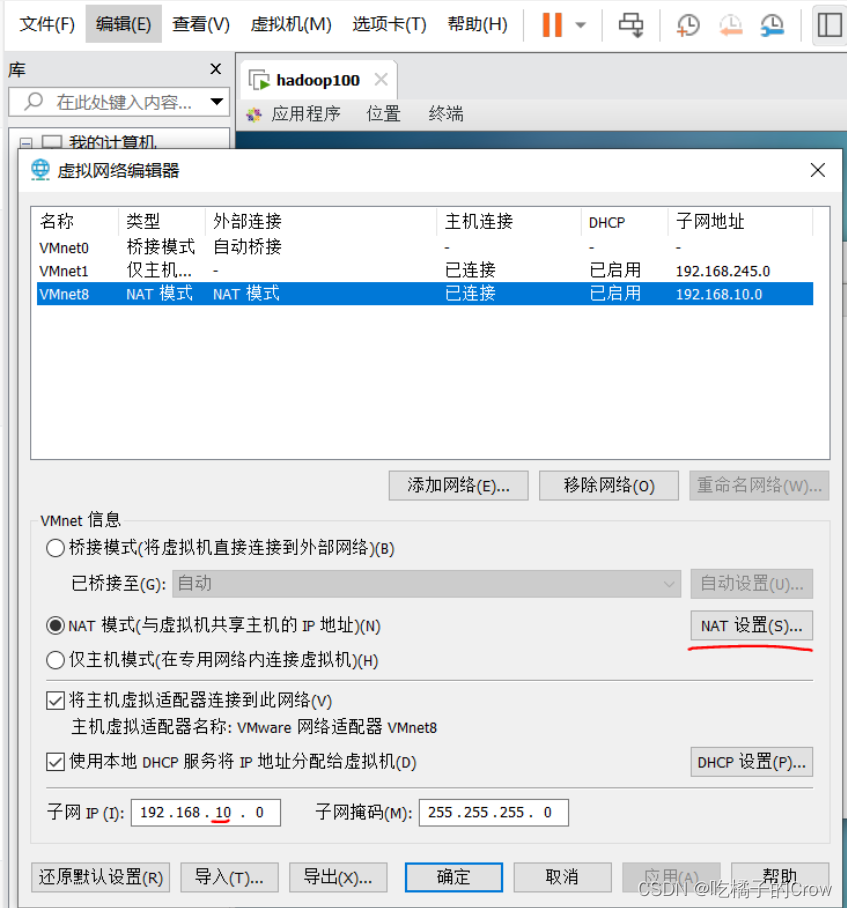
3.更改ip地址
一共有三处需要更改ip地址
一、改变VM中的ip地址
二、改变windows中的ip地址
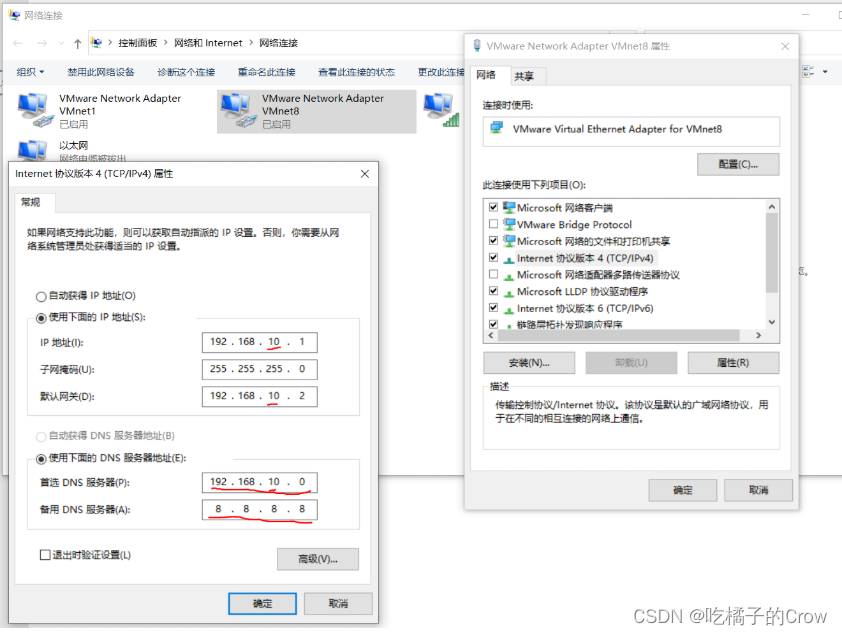
三、改变hadoop100ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33BOOTPROTO="static"
IPADDR=192.168.10.100
GATEWAY=192.168.10.2
DNS1=192.168.10.2
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
C:\Windows\System32\drivers\etc
将上述ip地址加入到hosts中
如果w10可能会出现无法在文件中进行添加,w10对权限这方面把控的比较严格,所以可以将文件复制一份在桌面上,然后在添加后在放进原文件夹中
4.关闭防火墙以及其他操作
1.yum install -y epel-release //类似于安装了一个仓库2.systemctl stop firewalld //关闭当前防火墙3.systemctl disable firewalld.service //关闭开机时的防火墙4.vim /etc/suduers
5.卸载虚拟机自带的jdk
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps6.下载、解压hadoop、jdk 配置linux中的环境
Hadoop镜像:Index of /apache/hadoop/common (tsinghua.edu.cn)
注意:hadoop版本最好下不易过高的,因为是在windows环境中如果运行hdfs等,所需要的hadoop.dll 不太好找,以至于心态崩溃。
jdk:百度云下载:
链接:百度网盘 请输入提取码 提取码:cbw4
下载后通过Xftp软件将jar包传到linux下的 /opt/software中,
vim /etc/profile.d/my_env.sh解压并安装jdk:
1.tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/2.cd /etc/profile.d/ 3.sudo vim my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin4.source /etc/profile解压并安装hadoop:
1.tar -zxvf hadoop-3.3.1.tar.gz -C /opt/module/ 2.2.cd /etc/profile.d/ 3.sudo vim my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.3.1export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin4.source /etc/profile
6.完全分布式运行模式
1.scp:可以实现服务器与服务器之间的数据拷贝
拷贝:
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件夹路径/名称 目的地用户@主机:目的地路径/名称同步:
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件夹路径/名称 目的地用户@主机:目的地路径/名称但是我们在这里为了方便写了一个shell脚本以便于虚拟机进行同步数据
#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ============ $host =============#3. 遍历所有目录,逐个发送for file in $@do #4. 判断文件是否存在if [ -e $file ]then #5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelse echo $file does not exists!fidone
done可以在~目录下创建一个bin的文件夹,以便于我们后期写的shell脚本的存储位置
创建一个文件写入脚本sxync,然后输入
chmod 999 sxync使得脚本生效
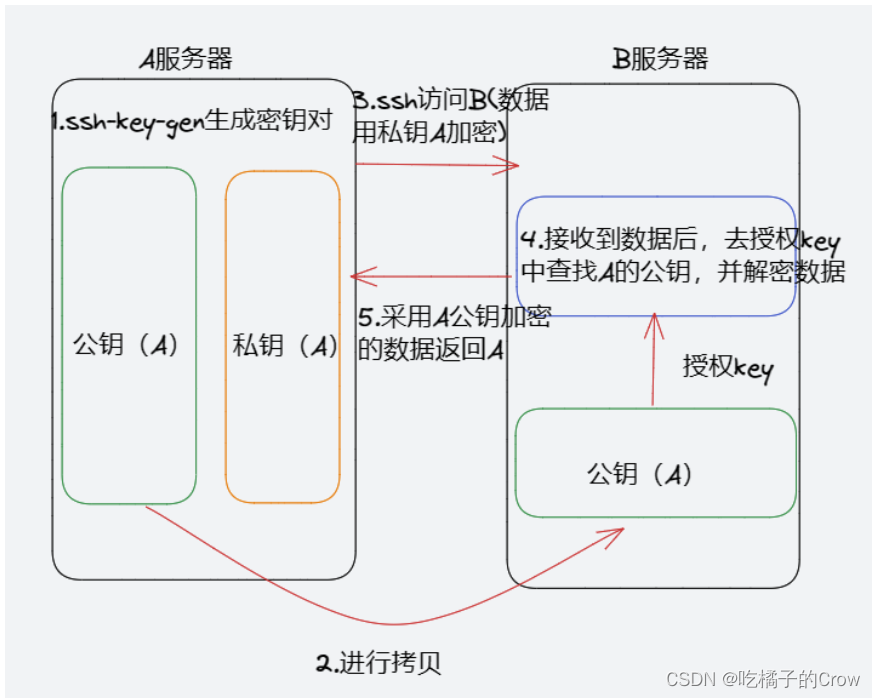
7.ssh无密登录
生成公钥和私钥:
[lzw@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh
[lzw@hadoop102 .ssh]$ ssh-keygen -t rsa
三次回车就会出现公钥(id_rsa)和私钥(id_rsa.pub)将公钥拷贝到要免登录的目标机器上:
[lzw@hadoop102 .ssh]$ ssh-copy-id hadoop102
[lzw@hadoop102 .ssh]$ ssh-copy-id hadoop103
[lzw@hadoop102 .ssh]$ ssh-copy-id hadoop104ssh无密登录的原理图奉上:
8.配置集群
1.核心配置文件
cd $HADOOP_HOME/etc/hadoopvim core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 lzw--><property><name>hadoop.http.staticuser.user</name><value>lzw</value></property>
</configuration>2.hdfs配置文件
vim hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property>
<!-- 2nn web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>3.Yarn配置文件
vim yarn-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value></property>
</configuration>4.MapReduce配置文件
vim mapred-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>将配置好的Hadoop文件分发给其他虚拟机
sxync /opt/module/hadoop-3.1.3/etc/hadoop/9.配置works
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers添加以下内容,注意在添加的时候千万不能出现空格、空行
hadoop102
hadoop103
hadoop104同步所有节点的配置文件
xsync /opt/module/hadoop-3.1.3/etc10.启动集群
进入到hadoop-3.1.3的目录下:
//对hdfs进行初始化
hdfs namenode -format//启动dfs
sbin/start-dfs.sh
//启动yarn
sbin/start-yarn.sh1.启动集群时如果碰到Attempting to operate on hdfs namenode as root错误:第一种方法:输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
第二种方法:
将start-dfs.sh,stop-dfs.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
将start-yarn.sh,stop-yarn.sh(在hadoop安装目录的sbin里)两个文件顶部添加以下参数
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
报错先暂停,然后再清理原数据,再进行初始化
2.ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.出现以上报错信息需要到 sbin 目录下 更改 start-yarn.sh 和 stop-yarn.sh 信息,在两个配置文件的第一行添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
制作不易,恳请关注!!!