笔试题有三份,分别考python、SQL、java和计算机网络Linux命令等基础知识。
python部分
1、选择题
第1题,下列选项中,python不支持的数据类型有(B)
python中没有字符类型,只有字符串类型string
A、int B、char C 、float D、dictionary
第2题,下列Python语句正确的是(D)
考简单的python语句是否有错。按照语法就可以了
A. min = x if x < y else y B. max = x > y ? x : y
C. if(x > y) print x D. while True :pass (while后面加分号,pass语句空语句,不做任何事情)
2、简答题
一、a = 1,b = 2 。不用中间变量交换a和b的值(同理,交换列表也一样)
a,b = b,a
二、s ="ajldjlajfdljfddd",去重并从小到大排序输出 "adfjl"
方法1
# 由于数据类型set本身具有无序,唯一值的特性,可以用内置函数set对字符串和列表进行去重
s ="ajldjlajfdljfddd"
s1 = set(s) #去重
s2 = list(s1) #转为列表
s2.sort() #排序,注意没有返回值
s3 = ''.join(s2) #列表转字符串
print(s3) #输出方法2
s ="ajldjlajfdljfddd"
s1 = set(s) #去重
s2 = list(s1) #转为列表
s3 = sorted(s2) #排序
s4 = ''.join(s3) #列表转字符串
print(s4) #输出方法3,一行代码搞掂,熟悉的话应该很容易写。
s ="ajldjlajfdljfddd"
s1 =''.join(sorted(list(set(s))))
print(s1)三、用至少三种方法从字符串"hello boy<[www.doiido.com]>byebye"中提取字符串'www.doiido.com'
①使用切片法截取字符串。切片语法:[起始:结束:步长],步长默认为1,可为负数,切片区间左闭右开
str = "hello boy<[www.doiido.com]>byebye"
print(str[11:25:1]) #第一个w第11位,最后m第24位,注意切片区间左闭右开输出:
www.doiido.com②使用split函数。
语法:str.split(str="", num=string.count(str))[n]
参数:str默认为空格
num为分割次数
[n]表示取第n个分片,可不写则不取,下标同样从零开始
返回值:分割后的字符串列表(列表元素=分割次数num+1)
思路:
1. 网址在[]里面,用第一个 [ 将字符串分隔成列表 str.split("[")
['hello boy<', 'www.doiido.com]>byebye']2. 再取列表里的索引为1的元素 str.split("[")[1]
www.doiido.com]>byebye3. 再用分隔符]将列表分隔开 str.split("[")[1].split("]")
['www.doiido.com', '>byebye']4. 再取第一个元素 str.split("[")[1].split("]")[0]
www.doiido.com代码:
str = "hello boy<[www.doiido.com]>byebye"
print(str.split("[")[1].split("]")[0])#是先输出[后的内容 以及]前的内容,下标从0开始输出:
www.doiido.com③使用replace函数
语法:str.replace(old, new[, max])
参数
1.old -- 这是要进行更换的旧子串。
2.new -- 这是新的子串,将取代旧的子字符串。
3.max -- 如果这个可选参数max值给出,就只替代max个,除max个外若还有old值,也不替代。
返回值:把新的子串取代旧的子串后,形成的新的字符串。
注意:并不返回原字符串里,请赋给一个新的string。
思路:
1. 网址在w之前的字符串用空格替换掉 str.replace('hello boy<[','')
www.doiido.com]>byebye2. 网址在m后面的字符串用空格替换掉 str1.replace(']>byebye','')
www.doiido.com代码:
str = "hello boy<[www.doiido.com]>byebye"
str1 = str.replace('hello boy<[','')#删除网址之前的字符串
print(str1.replace(']>byebye',''))#删除网址之后的字符串输出:
www.doiido.com④目前到这里。。。可能还有其他的函数楼主还没想到
四、读取testA.txt的内容,去掉文件中的空格,写入到testB.txt中。
语法:
1、打开文件或者新建一个文件(不指定访问方式,默认只读方式打开文件)
2、读/写数据
3、关闭文件
代码:
f1 = open('testA.txt','w') #新建testA.txt
f1.write('I am Quality Testing Engineer')#往testA.txt写数据
f1.close()#关闭文件
f2 = open('testA.txt','r')#读模式
content = f2.read()#读testA.txt数据
str = content.replace(" ","")#把数据中的空格全部去掉
f3 = open('testB.txt','w')#新建testB.txt
f3.write(str)#往testB.txt写数据
f2.close()#关闭文件
f3.close()#关闭文件
看看运行后py文件目录下的结果:
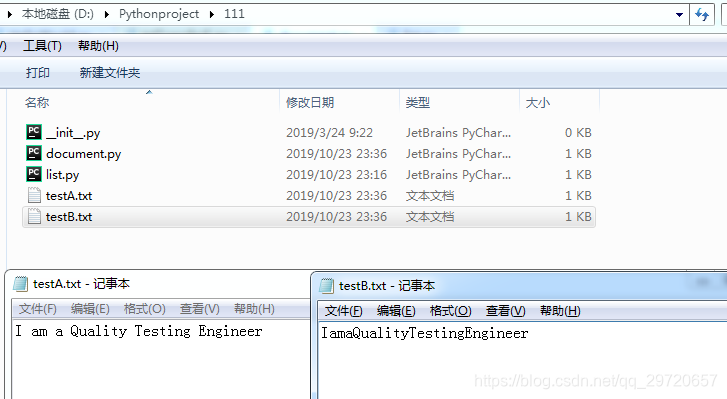
成功。注意读之前一定要关闭文件,否则读取会失败。可以删除f1.close()这一行代码试一试(运行后testB.txt内容为空)。
五、阅读下面的代码,写出A0,A1至An的值。
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5))) #先zip返回对象,再dict转字典
A1 = range(10) #即range(0,10,1)
A2 = [i for i in A1 if i in A0] #即[i for i in range(10) if i in A0],A0与A1交集
A3 = [A0[s] for s in A0] #即[A0[s] for s in A0.keys()],A0[s]字典知道键通过下标取值
A4 = [i for i in A1 if i in A3] #即 既满足A1,又满足A3,A1和A3交集
A5 = {i:i*i for i in A1} #即{i:i*i for i in range(10)},字典键值对
A6 = [[i,i*i] for i in A1] #即[[i:i*i] for i in range(10)],列表元素又是列表
print('A0:',A0)
print('A1:',A1)
print('A2:',A2)
print('A3:',A3)
print('A4:',A4)
print('A5:',A5)
print('A6:',A6)话不多说,马上看看结果
A0: {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
A1: range(0, 10)
A2: []
A3: [1, 2, 3, 4, 5]
A4: [1, 2, 3, 4, 5]
A5: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6: [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]分析:考察列表推导式,详情见Python 列表推导式
A0:zip函数作用,dict函数作用。#先zip返回对象,再dict转字典
A1:range函数作用。#即range(0,10,1)
A2:for if 用法。#即[i for i in range(10) if i in A0],A0与A1交集
A3:取字典元素,for 用法。#即[A0[s] for s in A0.keys()],A0[s]字典知道键通过下标取值
A4:同A2。#即 既满足A1,又满足A3,A1和A3交集
A5:for 输出字典元素。#即{i:i*i for i in range(10)},字典键值对
A6:for 输出列表元素。#即[[i:i*i] for i in range(10)],列表元素又是列表
后面对这些函数单独研究。
SQL部分
请移步:学生各门课程成绩统计SQL语句大全(面试题)