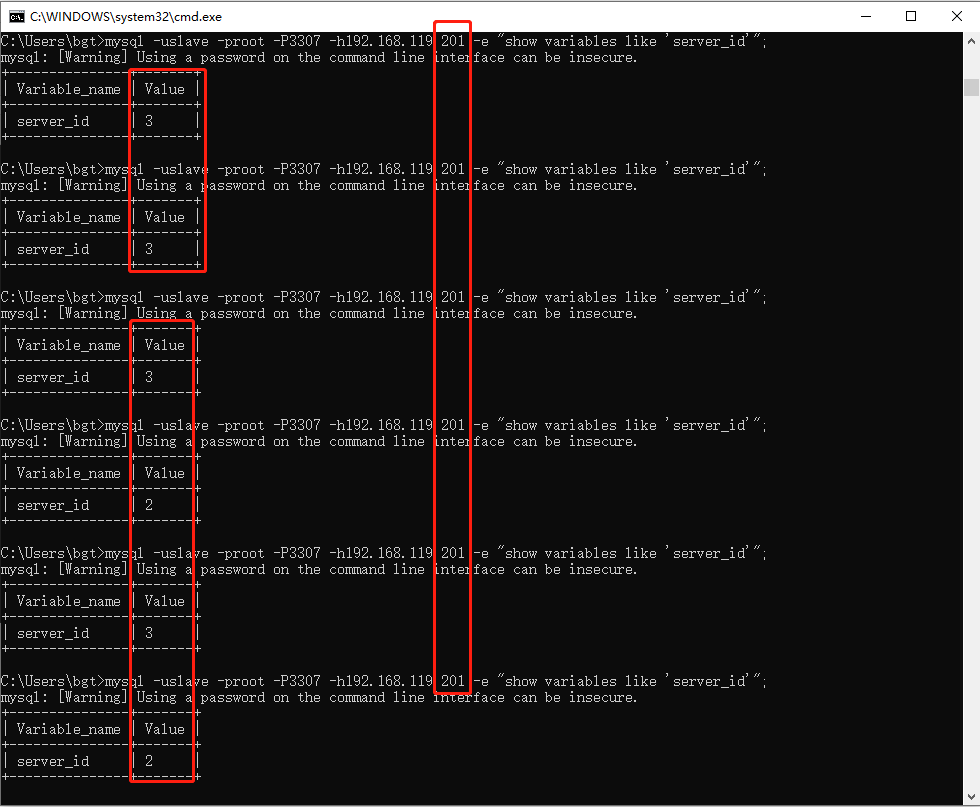
动动发财的小手,点个赞吧!
有效的沟通在所有数据驱动的项目中都至关重要。数据专业人员通常需要将他们的发现和见解传达给利益相关者,包括业务领导、技术团队和其他数据科学家。
虽然传达数据见解的传统方法(如 PowerPoint 演示文稿和静态报告)广受青睐,但创建它们通常很耗时。
更重要的是,这些服务要求人们离开舒适的 Jupyter Notebook——数据科学家大部分时间都花在那里。
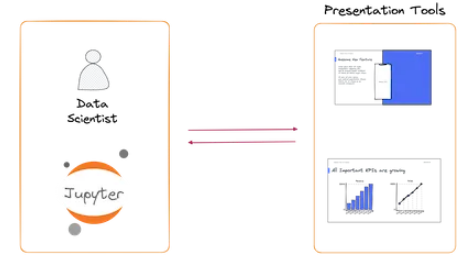
如果我们可以通过直接从 Jupyter Notebook 创建交互式和优雅的 Web 应用程序来与其他人分享我们的发现,那不是很好吗?
为此,Mercury 是一种开源工具,可简化 Jupyter Notebook 上 web 应用程序的创建。
因此,在本文[1]中,我将演示如何使用 Mercury 创建令人惊叹的 Web 应用程序并与他人共享。
开始使用 Mercury
Mercury 创建的 Web 应用程序主要由两件事驱动:
Jupyter Notebook:
这是您开发网络应用程序的地方。我们使用 Mercury 的输入和输出小部件启用交互性。
输入小部件允许用户提供输入并与应用程序交互。 Mercury 支持的一些输入小部件如下所示:
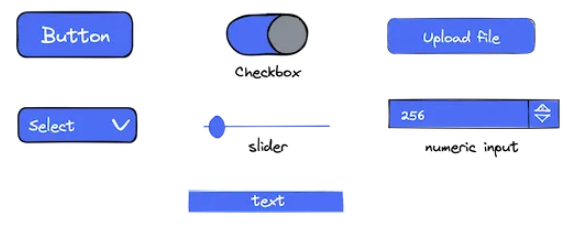
输出小部件用于呈现输出。这包括 Markdowns(带变量)、JSON 等。此外,Jupyter 单元格的输出也由 Mercury 呈现。
因此,如果您的应用程序创建绘图或打印 DataFrame 等,它们将出现在网络应用程序的输出面板中。
Mercury Server
服务器将 Jupyter Notebook 呈现为 Web 应用程序。
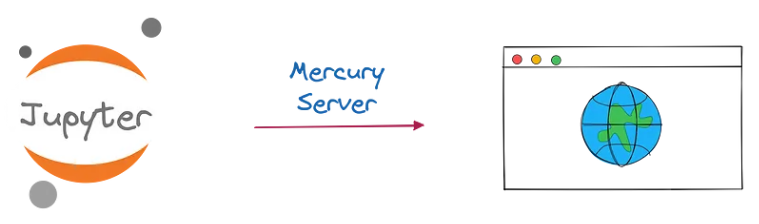
正如我们将看到的,渲染笔记本就像运行一个命令一样简单。您所要做的就是在笔记本中创建您的网络应用程序。
使用 Mercury 设置 Web 应用程序需要几个简单的步骤。
Install Mercury
首先,使用 pip 安装库:
pip install mercury
现在我们可以创建带有输入和输出小部件的 Web 应用程序。
使用 Mercury 开发 Web 应用程序
如上所述,使用 Mercury 创建的 Web 应用程序主要由其小部件提供支持。
导入库
要使用它们,我们首先导入库。重申一下,我们将在 Jupyter Notebook 上做所有事情。
## mercury_app.ipynb
import mercury as mr
此外,您可以根据需要导入任何其他库。对于这个博客,我将创建一个网络应用程序来分析一个自行创建的虚拟员工数据框。因此,我还将使用以下库:
## mercury_app.ipynb
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
sns.set()
配置应用程序
接下来,我们通过提供标题和描述来实例化 Mercury 应用程序。
## mercury_app.ipynb
app = mr.App(title="Employee Data Analysis",
description="Employee Report in Mercury")
使用小部件填充应用程序
接下来,让我们添加一些小部件以允许其用户与以下虚拟数据进行交互:
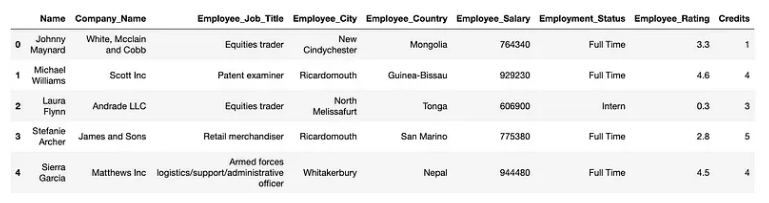
本质上,我们将执行以下操作:
-
添加一个小部件以上传 CSV 文件。 -
让用户根据 Company_Name 列中的条目过滤数据。这将是 MultiSelect 小部件。 -
此外,用户还可以使用滑块根据 Credits 过滤数据。
过滤数据后,我们将显示以下内容:
-
过滤后的 DataFrame 的维度。 -
Employee_Salary 和 Employee_Rating 的散点图。 -
显示 Employee_Status 列分布的条形图。
首先,我们添加文件上传小部件。
## mercury_app.ipynb
data_file = mr.File(label="Upload CSV")
可以使用 data_file 对象的文件路径属性访问文件名。因此,文件上传后,我们将使用 Pandas 读取它,如下所示:
## mercury_app.ipynb
emp_df = pd.read_csv(data_file.filepath)
现在,我们将添加另外两个小部件 — Company_Name 上的 MultiSelect 小部件和 Credits 列上的 Slider。
## mercury_app.ipynb
company = mr.MultiSelect(value=emp_df.Company_Name.unique(),
choices=emp_df.Company_Name.unique(),
label="Select Companies")
在这里,value 参数指的是初始值,choices 显示为可供选择的值列表,label 是显示在小部件旁边的自定义文本。
接下来,我们有 Slider 小部件。
## mercury_app.ipynb
credits_filter = mr.Slider(value=1,
min=emp_df.Credits.min(),
max=emp_df.Credits.max(),
label="Credits Filter", step=1)
这里,value 参数定义了初始值,min 和 max 指的是值的范围,label 和之前一样,是一个自定义文本。最后,step 定义滑块小部件的步长值。
这样,我们就完成了为交互添加的小部件。最后一步是根据小部件中的值创建绘图。
填充输出面板
首先,我们根据从小部件接收到的值过滤数据框。您可以使用 WidgetObj.value 属性访问它。
换句话说,要检索小部件的值,我们可以参考 company.value 属性。
## mercury_app.ipynb
new_df = emp_df[(emp_df.Company_Name.isin(company.value)) &
(emp_df.Credits>=int(credits_filter.value))]
接下来,使用 Markdown 输出小部件,我们打印过滤后的 DataFrame 的维度。
## mercury_app.ipynb
mr.Md(f"""The DataFrame has {new_df.shape[0]} rows
and {new_df.shape[1]} columns.""")
Mercury markdown 的一件很酷的事情是您还可以使用 f-strings,如上所示。
最后,我们创建绘图:
## mercury_app.ipynb
fig, ax = plt.subplots(1, 2, figsize = (16, 9))
sns.scatterplot(data = new_df, ax = ax[0],
x = "Employee_Rating", y = "Employee_Salary") ## scatter plot
sns.countplot(x = new_df.Employment_Status, ax = ax[1]) ## count plot
plt.show();
就是这样。现在我们的 Mercury 应用程序已准备就绪。
运行网络应用
要运行该应用程序,请在命令行中导航到您的应用程序的文件夹并运行以下命令:
mercury run
因此,我们看到以下内容:
正如预期的那样,我们有一个小部件来上传文件。让我们在这里上传虚拟数据集。
上传 CSV 文件后,我们会立即看到弹出的图表。
现在,我们可以使用输入小部件来分析数据。
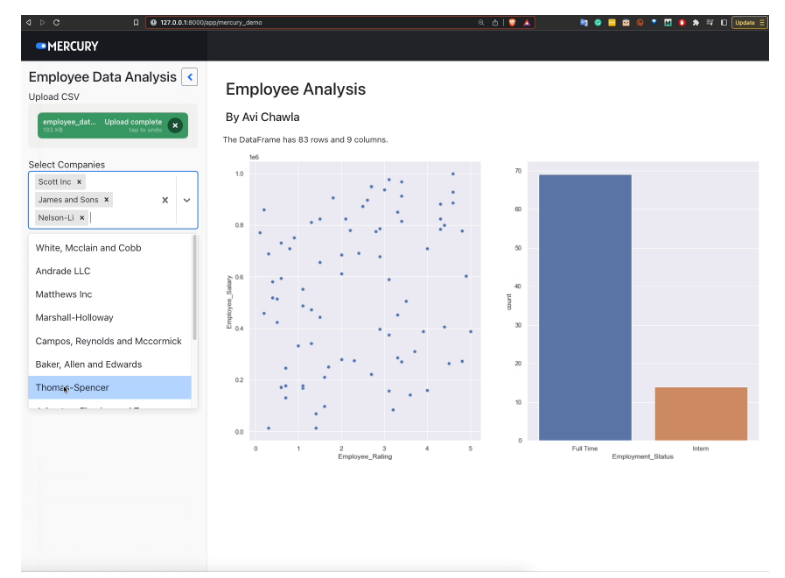
当我们更新过滤器时,图表和行数也会更新。这是通过 Mercury 服务器实现的,它保持笔记本和应用程序之间的持续交互。
事实上,如果我们更新 notebook,更改会立即反映出来。
总结
在本文中,我们学习了如何在舒适的 Jupyter Notebook 上使用 Mercury 构建一个简单的 Web 应用程序。
另外,您还可以使用 Mercury Cloud 在云上托管您的笔记本。只需上传笔记本,即可完成。
但是,如果您不希望专门在 Mercury Cloud 上托管您的 Web 应用程序,那么您也可以将它部署在任何带有 Docker 的服务器上。
Reference
Source: https://towardsdatascience.com/build-elegant-web-apps-right-from-jupyter-notebook-with-mercury-78d9ebcbbcaf
本文由 mdnice 多平台发布