英伟达开源了深度学习硬件架构:NVDLA。
包括完整的源代码:Verilog代码,C_Model代码,以及验证平台代码。
英伟达官网上也有详细的文档。
英伟达NVDLA官网:http://nvdla.org/primer.html
非常值得学习推敲。
感谢英伟达的分享
不得不吐槽一下,NVDLA的开源代码一看就知道是脚本生成的,造成重复代码非常多,非常不方便阅读。
比如输入的1024位的数据,竟然在接口上是按照8位一个byte为单位来生成的信号,也就是说明明用1个1024位的信号就行了,但是代码中用的是128个8位的数据。
吐血。。。。
作为芯片从业者,我更加关注NVDLA卷积核的实现方式。
不过,文档中并没有详细的说明。
众多分析博客,也更多的是系统层的应用,几乎没有分析内部硬件结构的文章。
于是,直接看代码,分析结构。
好记性不如烂笔头。
顺便将看代码的过程中学习到的东西,记录下来,以备后续查看。
1、NVDLA 硬件架构
NVDLA的SOC整体架构如下图1所示。图片来自英伟达官网。
根据配置的不同,可分为两种。

接下来,细看NVDLA的硬件核心。如下图所示。

NVDLA core的内部架构,与寒武纪的DianNao、谷歌的TPU,都比较像。
共同点,主要思路是:数据从memory来,回memory去。中间先进入乘法、加法逻辑,完成卷积的计算,然后是执行激活、pooling和BN等操作。
不同点,主要区别在于卷积核(Convolution CORE)内部:
(1)TPU采用高效整齐的脉动阵列(systolic array),
(2)DianNao共16个PE,每个PE采用16个乘法和15个加法逻辑形成一个完整的计算单元,或许会类似NVDLA,将乘法加法IP展开融合起来。
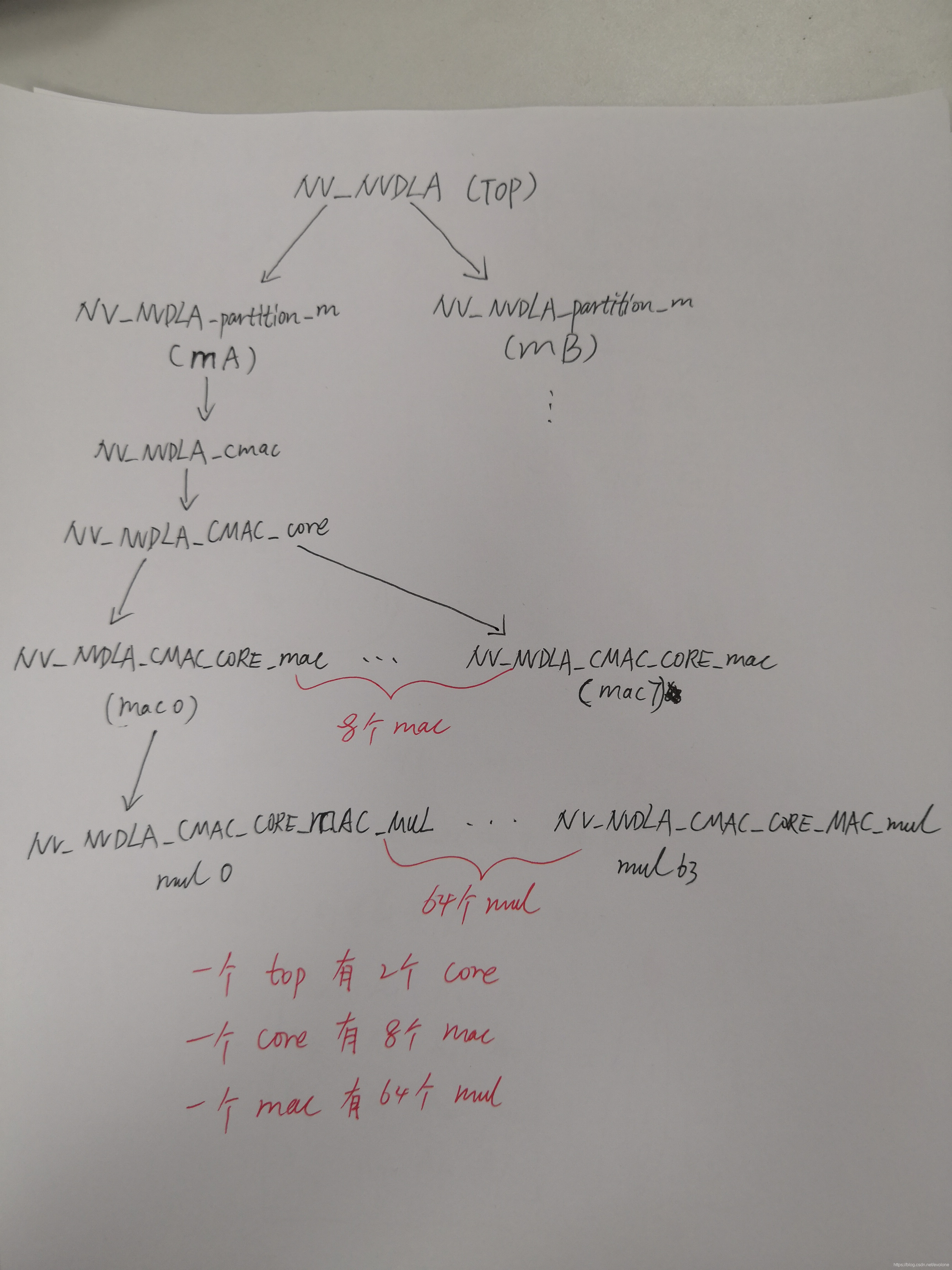
(3)NVDLA采用两个卷积核,每个核中有8个mac,每个mac中有64个mul,每个mul就是一个16位的乘法逻辑。
下面就细细分析NVDLA的卷积核。
2、卷积核
一个NVDLA有2个卷积核core。
一个卷积核Core,由8个mac 组成。
1个mac中包含64个mul,形成4个输出结果。可简单看作16个mul计算得到1个结果。
具体结构可见下图。
Core同时支持3种数据类型:int8,int16,fp16。
按照官方文档介绍,NVDLA的卷积核支持4种工作模式:
(1)Direct Convolution
这种直接卷积,类似寒武纪的DianNao架构。
(2)Image Input
针对第一层,输入是彩色图像,只有3个channel。
(3)Winograd
利用Winograd算法,采用其中的F(2x2,3x3)参数公式。以尽可能少的乘法器数量去计算得到卷积结果。
(4)Batching
一次性计算多个inference,重复利用权重参数,节省存储和带宽。
那么,一个core是如何同时支持以上的这些特性的呢?
细看代码发现,NVDLA的core内部,没有利用已有的乘法/加法/乘加计算IP,而是直接在代码中展开并重写了IP的内部逻辑。
core从顶层得到2个1024bit的数据,一个是weight,一个是data。
在core中分发成8份,发送给8个mac,每个mac的数据都是2个1024位的数据。
mac得到2个1024的原始数据,会将这些数据对应给到64个mul。每个mul的输入数据都是16位的。
如果是int8,没关系,16位的输入数据就代表的是两个8位的数据。
mac内部的64个mul结构如下图所示。
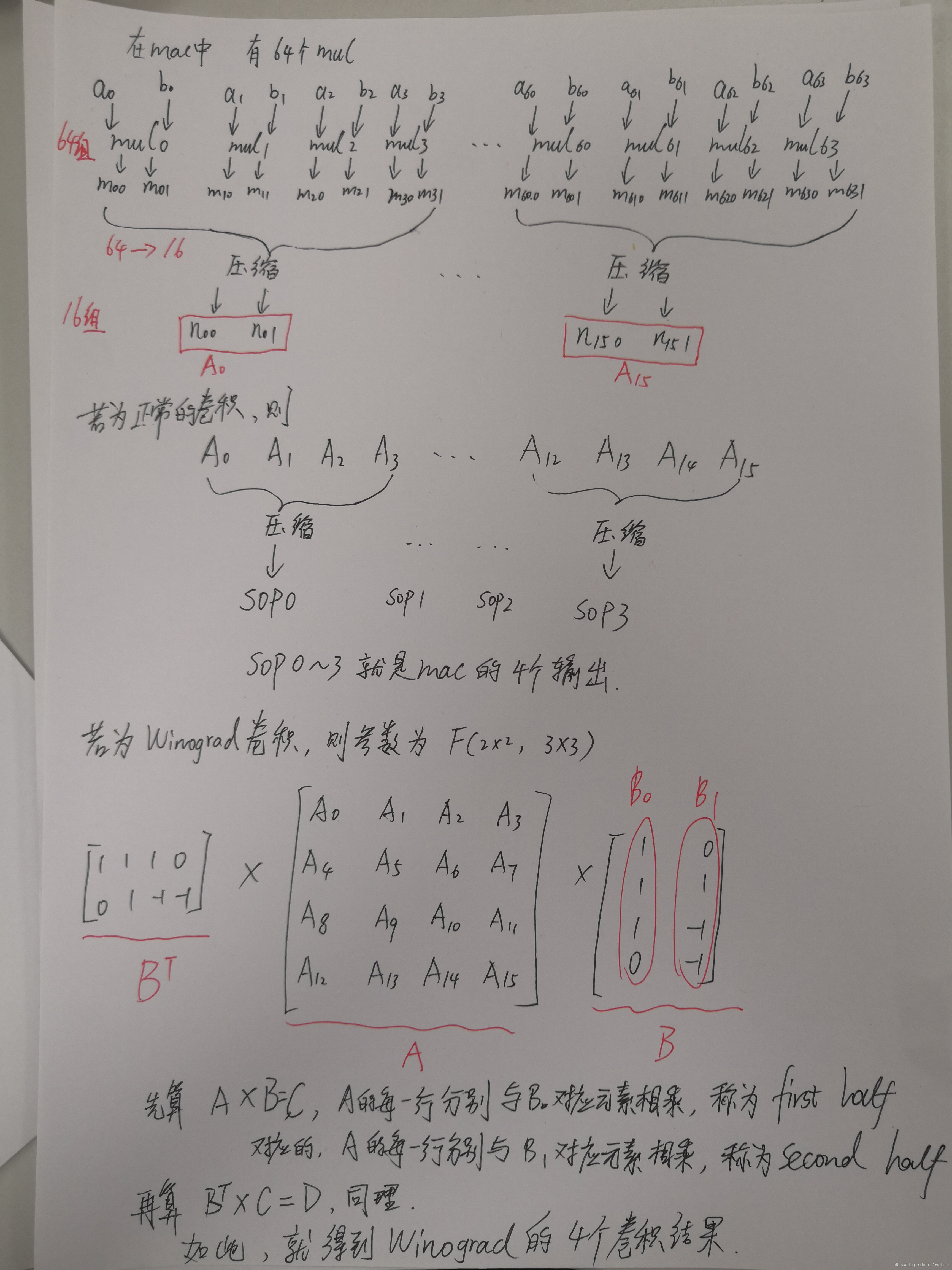
在mul中,首先取其中一个16位的数据,根据3位的boothcode算法,形成8个boothcode,然后分别编码另一个数据,形成8个部分和,再各自加上一个进位,共10个部分和,分成两组。
然后10组部分和经过两次的3-2CSA压缩后,形成2个部分和,输出。
这样,mac一次性得到了64组部分和。
然后按照一定顺序,继续利用3-2CSA算法,将64组部分和压缩成16组部分和,即64(128)->16(32).
到了这个地方,就到了一个分水岭。
普通正常的卷积计算,那么就选择走first half.(不是我故意写英文装逼,这个是代码中的原始注释,我直接套用了)
如果是winograd,那么就还需要走second half.
fp16的指数计算有专门的逻辑。
first half,继续按照3-2CSA压缩16组部分和,直到形成4组部分和(8个)。然后每两个相对应的部分和及符号位,三者相加,形成卷积结果。
second half,这里就要根据F(2x2,3x3)的特殊参数,对后8组部分和进行特殊处理的3-2CSA压缩,直到形成2组部分和为止。
然后这个时候,会有winograd逻辑信号去控制winograd的结果的生成。
这样,就形成了mac的4个输出。
NVDLA支持Winograd算法的F(2x2,3x3)形式。
但是,这个只是复用mac中的mul,实际来看,并不能完整发挥出每16个mac计算出4个神经元的理论性能。如果是理论上的,16个mul计算得到4个神经元,那么64个mul,就会计算得到16个神经元。但是一个mac实际只有4个输出数据。
所以,我猜测,所谓的支持Winograd,实际性能或许并不理想,或许只是单纯为了支持这种计算方式而已。
但是,因为只是静态地看代码,所以不清楚8个mac的输入数据之间有什么关系。
暂时只能分析到这里。