计算字节数
在 Go 语言中,可以使用 unsafe.Sizeof 计算出一个数据类型实例需要占用的字节数。
package mainimport ("fmt""unsafe"
)type Args struct {num1 intnum2 int
}type Flag struct {num1 int16num2 int32
}func main() {fmt.Println(unsafe.Sizeof(Args{}))fmt.Println(unsafe.Sizeof(Flag{}))
}
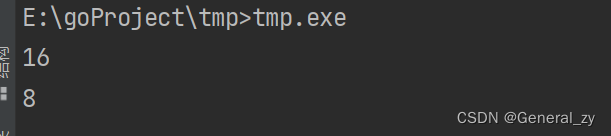
- Args 由 2 个 int 类型的字段构成,在 64位机器上,一个 int 占 8 字节,因此存储一个 Args 实例需要 16 字节。
- Flag 由一个 int32 和 一个 int16 的字段构成,成员变量占据的字节数为 4+2 = 6,但是 unsafe.Sizeof 返回的结果为 8 字节,多出来的 2 字节是内存对齐的结果。
因此,一个结构体实例所占据的空间等于各字段占据空间之和,再加上内存对齐的空间大小。
内存对齐
-
CPU 只从对齐的地址开始加载数据
-
CPU 读取块的大小是固定的,通常为 B 的 2 的整数幂次
-
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU ,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。
-
这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。
-
CPU 始终以字长访问内存,如果不进行内存对齐,很可能增加 CPU 访问内存的次数。
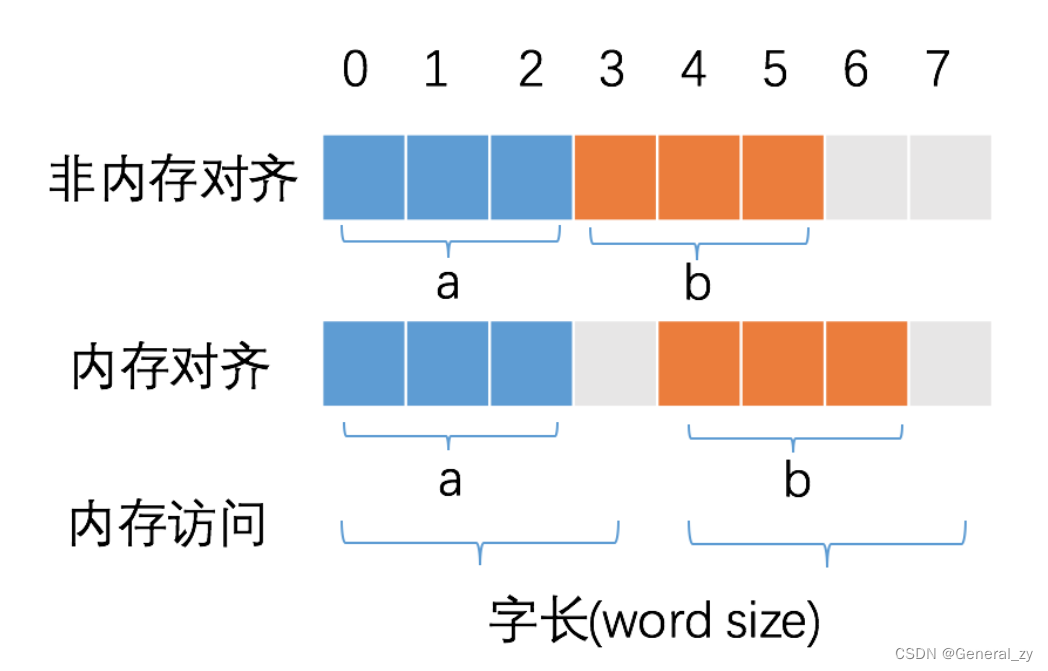
6. 变量 a、b 各占据 3 字节的空间,内存对齐后,a、b 占据 4 字节空间,CPU 读取 b 变量的值只需要进行一次内存访问。
7. 如果不进行内存对齐,CPU 读取 b 变量的值需要进行 2 次内存访问。第一次访问得到 b 变量的第 1 个字节,第二次访问得到 b 变量的后两个字节。
结论:内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
对齐系数
unsafe 标准库提供了 Alignof 方法,可以返回一个类型的对齐值,也可以叫做对齐系数或者对齐倍数。
unsafe.Alignof(Args{}) // 8
unsafe.Alignof(Flag{}) // 4- 对于任意类型的变量 x ,unsafe.Alignof(x) 至少为 1。
- 对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的 unsafe.Alignof(x.f),unsafe.Alignof(x) 等于其中的最大值。
- 对于 array 数组类型的变量 x,unsafe.Alignof(x) 等于构成数组的元素类型的对齐倍数。
- 没有任何字段的空 struct{} 和没有任何元素的 array 占据的内存空间大小为 0,不同的大小为 0 的变量可能指向同一块地址。
struct 内存对齐
type demo1 struct {a int8b int16c int32
}type demo2 struct {a int8c int32b int16
}func main() {fmt.Println(unsafe.Sizeof(demo1{})) // 8fmt.Println(unsafe.Sizeof(demo2{})) // 12
}
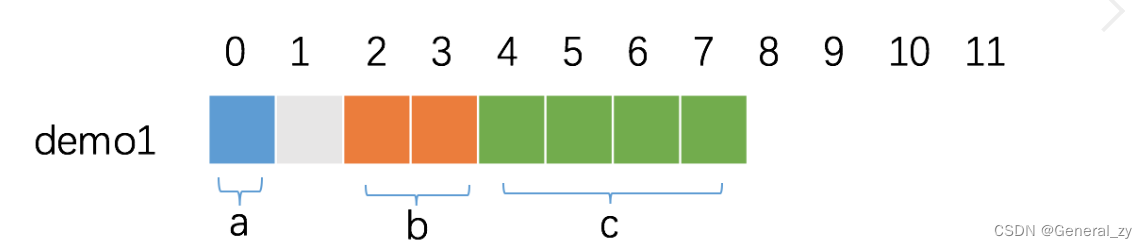
demo1:
- a 是第一个字段,默认是已经对齐的,从第 0 个位置开始占据 1 字节。
- b 是第二个字段,对齐倍数为 2,因此,必须空出 1 个字节,偏移量才是 2 的倍数,从第 2 个位置开始占据 2 字节。
- c 是第三个字段,对齐倍数为 4,此时,内存已经是对齐的,从第 4 个位置开始占据 4 字节即可。
因此 demo1 的内存占用为 8 字节。
demo2:
- a 是第一个字段,默认是已经对齐的,从第 0 个位置开始占据 1 字节。
- c 是第二个字段,对齐倍数为 4,因此,必须空出 3 个字节,偏移量才是 4 的倍数,从第 4 个位置开始占据 4 字节。
- b 是第三个字段,对齐倍数为 2,从第 8 个位置开始占据 2 字节,但最大对齐倍数为4,需要填充2个字节
demo2 的对齐倍数由 c 的对齐倍数决定,也是 4,因此,demo2 的内存占用为 12 字节。

空结构体
空 struct{} 大小为 0,作为其他 struct 的字段时,一般不需要内存对齐。
但是有一种情况除外:即当 struct{} 作为结构体最后一个字段时,需要内存对齐。