数据挖掘实战 —— 泰坦尼克号
- 一、数据指导
- 二、数据源
- 三、理解数据
- 3.1 导包
- 3.2 读取数据
- 3.3 属性介绍
- 四、 填充缺失数据
- 4.1 处理age属性
- 五、分析描述数据
- 5.1 幸存比例
- 5.2 幸存男女比例
- 5.3 幸存年龄比例
- 5.4 身份地位幸存比例
- 5.5 家庭人数幸存比例
- 5.6 特征相关
一、数据指导
# 一、目的:根据已有数据预测未知旅客生死;
# 二、数据准备:数据获取,载入train.csv;
# 三、数据清洗:补齐或抛弃缺失值,数据类型变化;
# 四、数据分析:1 描述性分析:画图,直观分析;2 探索性分析,机器学习模型;
二、数据源
在kaggle上下载数据包:https://www.kaggle.com/c/titanic

把数据源下载下来。
三、理解数据
3.1 导包
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsfrom IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all" # 显示所有结果
plt.style.use('fivethirtyeight') #制定画图风格
warnings.filterwarnings('ignore') #将警告过滤掉
plt.rcParams['font.sans-serif'] = ['SimHei']
%matplotlib inline
3.2 读取数据
data = pd.read_csv("D:/test/train.csv")
# data.head(3)
data.tail()
data.shape # train的条数有891条,有12个column

3.3 属性介绍
PassengerId: 乘客ID;
Survived: 是否幸存,0代表遇难,1代表还活着;
Pclass: 船舱等级:1 好,2 中等,3 低等;
Name: 姓名;
Sex: 性别;
Age: 年龄;
SibSp: 兄弟姐妹及配偶个数;
Parch:父母或子女个数;
Ticket: 乘客的船票号;
Fare: 乘客的船票价;
Cabin: 乘客所在的仓位(位置);
Embarked:乘客登船口岸。
# 查看数据的具体字段
data.info()

四、 填充缺失数据
# 统计缺失值
data.isnull().sum()
# 数据描述
data.describe()

我们发现,年龄的缺失值最多,因此我们要填充数据。
# .loc[:,:] 中括号里面逗号前面的表示行,逗号后面的表示列。
data1 = data.loc[:,['PassengerId','Survived','Pclass','Sex','Age','SibSp','Parch','Fare']]
data1.head()
4.1 处理age属性
- 简单粗暴方法:
# 取 age 的中位数填充数据方法
age_median = data1['Age'].median() # 中位数
print("中位数:",age_median)
# 空值使用bool值来查看(这里只是查看,False代表有值)
data1['Age'].isnull().head()# 将age的空值使用中位数代替
data1.loc[data1['Age'].isnull(),'Age'] = age_median
# 统计缺失值
data1.isnull().sum()

- 深入方法: 在姓名属性中,我们可以发现 Mr,Mrs 先生,女士的称谓,隐性的表现年龄。
data['Initial']=0
for i in data:data['Initial']=data.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(data.Initial,data.Sex) #用性别核对姓名首字母
pd.crosstab(data.Initial,data.Sex).T # 转置

# 转化为:Master、Miss、Mr、Mrs、Other 属性
data['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr'],inplace=True)
data.groupby('Initial')['Age'].mean() # 求平均# 统计缺失值
data.Age.isnull().sum()# 安装平均数值对age进行填充
data.loc[(data.Age.isnull())&(data.Initial=='Master'),'Age']=5
data.loc[(data.Age.isnull())&(data.Initial=='Miss'),'Age']=22
data.loc[(data.Age.isnull())&(data.Initial=='Mr'),'Age']=33
data.loc[(data.Age.isnull())&(data.Initial=='Mrs'),'Age']=36
data.loc[(data.Age.isnull())&(data.Initial=='Other'),'Age']=46
data.Age.isnull().any() # 显示填充后信息
data.Age.isnull().sum()

五、分析描述数据
5.1 幸存比例
f,ax = plt.subplots(1,2,figsize=(18,8))
Survived_count = data['Survived'].value_counts()sns.countplot('Survived',data=data,ax=ax[0])
ax[0].set_title('幸存比例条形图')
ax[0].set_xlabel('幸存')
ax[0].set_ylabel('数量')explode = [0,0.1]
plt.pie(Survived_count,explode=explode,autopct='%1.1f%%',shadow=True)
ax[1].set_title('幸存比例饼图')# plt.savefig(r"C:\Users\Desktop\幸存比例.png",dpi=400)
plt.show()

5.2 幸存男女比例
# 对性别进行分组,并计数幸存人数
data.groupby(['Sex','Survived'])['Survived'].count()

f,ax = plt.subplots(1,2,figsize=(18,8))
data['Sex'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('男女比例饼图')Sex_count = data['Sex'].value_counts()
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('男女幸存比例条形图')
ax[1].set_xlabel('男 女')
ax[1].set_ylabel('数 量')# plt.savefig(r"C:\Users\Desktop\男女比例幸存.png",dpi=500)
plt.show()

- 可以发现,在饼图男女比例大约是6.5:3.5,男性死亡人数远高于女性。
- 在条形图,男性死亡(蓝条)人数远高于生存(红条)人数;女性则是反过来。
5.3 幸存年龄比例
f,ax=plt.subplots(1,2,figsize=(20,10))
x1=list(range(0,85,5)) # 年龄间隔
data[data['Survived']==0].Age.plot.hist(ax=ax[0],bins=20,edgecolor='black',color='red')
ax[0].set_title('Survived= 0,死亡')
ax[0].set_xticks(x1)
ax[0].set_xlabel('年 龄')
ax[0].set_ylabel('数 量')data[data['Survived']==1].Age.plot.hist(ax=ax[1],bins=20,edgecolor='black',color='green')
ax[1].set_title('Survived= 1,幸存')
ax[1].set_xticks(x1)
ax[1].set_xlabel('年 龄')
ax[1].set_ylabel('数 量')
# plt.savefig(r"C:\Users\Desktop\年龄幸存图.png",dpi=500)
plt.show()

- 可以发现在25-40岁年龄段是死亡人数最多的,幼童和老人死亡较少,综上符合老人、妇女、儿童性命优先策略。
5.4 身份地位幸存比例
# 对船舱等级分组,并计数幸存人数
# 设船舱等级越高则身份地位越高
data.groupby(['Pclass','Survived'])['Survived'].count()

f,ax = plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().plot.pie(explode=[0,0.05,0.05],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('船舱等级比例饼图')Pclass_count = data['Pclass'].value_counts()
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('身份地位幸存比例条形图')
ax[1].set_xlabel('船舱等级==身份地位')
ax[1].set_ylabel('数 量')# plt.savefig(r"C:\Users\Desktop\身份地位幸存者图.png",dpi=500)
plt.show()

- 可以发现船舱等级越高,则幸存比例越大,隐性显示身份地位越高越受到重视,所以金钱和地位很重要。
# 船舱等级和性别对结果的影响
pd.crosstab([data.Sex,data.Survived],data.Pclass,margins=True)# 在船舱等级下的男女幸存比例
sns.factorplot('Pclass','Survived',hue='Sex',data=data)
plt.title("身份地位幸存者图")
plt.xlabel("船舱等级")
plt.ylabel("幸存比例")
# plt.savefig(r"C:\Users\Desktop\身份地位幸存者图.png",dpi=500)
plt.show()


可以很容易地推断,总体上来看,女性优先,且地位高的女性着重救援,例如,pclass1女性生存是95-96%,这是非常之高的幸存比例了。
5.5 家庭人数幸存比例
# sibsip 兄弟姐妹的数量
pd.crosstab([data.SibSp],data.Survived).Tf,ax=plt.subplots(1,2,figsize=(20,8))
sns.barplot('SibSp','Survived',data=data,ax=ax[0])
ax[0].set_title('家庭人数比例条形图')
ax[0].set_xlabel('家庭人数')
ax[0].set_ylabel('比 例')sns.factorplot('SibSp','Survived',data=data,ax=ax[1])
ax[1].set_title('家庭人数比例折线图')
ax[1].set_xlabel('家庭人数')
ax[1].set_ylabel('比 例')
plt.close(2)
# plt.savefig(r"C:\Users\Desktop\家庭人数比例图.png",dpi=500)
plt.show()

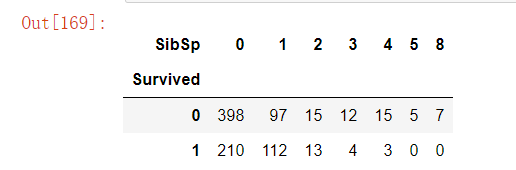
可以发现单身的约有35%的存活率,如果有兄弟姐妹的存活率会相应减少。但是令人惊讶的是,5-8名成员家庭的存活率为0%。这是什么原因呢?真是令人疑惑呢…
5.6 特征相关
sns.heatmap(data.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(10,8)
# plt.savefig(r"C:\Users\Desktop\特征相关图.png",dpi=500)
plt.show()

参考来自
https://www.cnblogs.com/bigbigbird/p/12960460.html