🌞欢迎来到深度学习的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
6.1 参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化 (optimization )。为了找到最优参数,我们将参数的梯度(导数)作为了线索。 使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,从而逐渐靠 近最优参数,这个过程称为随机梯度下降法 (stochastic gradient descent ), 简称SGD 。 SGD 是一个简单的方法,不过比起胡乱地搜索参数空间,也算是“聪明”的方法。但是,根据不同的问题,也存在比 SGD 更加聪明的方法。6.1.1 探险家的故事
6.1.2 SGD
6.1.4 Momentum
6.1.5 AdaGrad
在关于学习率的有效技巧中,有一种被称为 学习率衰减 ( learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多” 学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。 逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。 而AdaGrad 进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。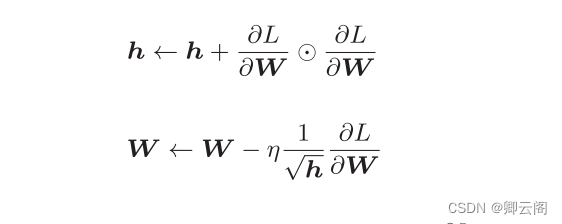
6.1.6 Adam
6.2 权重的初始值
6.2.1 可以将权重初始值设为0吗
后面我们会介绍抑制过拟合、提高泛化能力的技巧——权值衰减( weight decay)。简单地说,权值衰减就是一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。
6.3 Batch Normalization
Batch Norm ,顾名思义,以进行学习时的 mini-batch 为单位,按 minibatch进行正规化。具体而言,就是进行使数据分布的均值为 0 、方差为 1 的正规化。
6.4 正则化
6.4.2 权值衰减权值衰减 是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。6.4.3 Dropout
Dropout 是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。
0基础入门---第六章---与学习相关的技巧
news/2024/12/5 5:18:45/


相关文章
从0到1搭建Springboot整合Quartz定时任务框架(保姆级教学+Gitee源码)
前言:最近学习了目前主流的若依框架,这是一个非常优秀的开源项目,故此我这边把它的源码全部剖析了一遍,简化了它的框架,我会通过这篇博客详细讲解我是如何进行推敲和从0到1搭建这个项目的流程。 目录
一、Quartz简介 …

免费的电子书下载网站
免费的电子书下载网站
免费电子书网站
1.台大图书馆 http://ebooks.lib.ntu.edu.tw/Home/ListBooks 台湾大学图书馆,目前有244996本书籍,内外公开取用电子书资源,人文社科类的比较多一些。 2.epubw https://epubw.com/ 每日更新优质电子书&…
IT书籍电子书下载网站
终于转正了,要好好学习工作~~~
推荐一个IT书籍电子书下载网站:https://itbook.download/
挺好的网站,里面分门别类,语言类,计算机基础类,算法类,
很多经典…
推荐几个著名的电子书免费下载网站!
北极星书库 http://www.ebook007.com/ 资料全,内容多,免费电子书下载 。学术名著名家作品集现代文学当代文学外国文学古典名著武侠言情电脑教程编程技巧等等。 公益电子书 http://www.gy16.com/ 免费电子书下载,成功励志经济管理语音视频eboo…

推荐几个免费的电子书下载网站——网盘版
推荐几个免费的电子书下载网站——网盘版
1:虫部落 搜素引擎的集合版 链接: link.
图片:
2.大圣盘,类似于大力盘,怀疑它们的引擎是一个,搜索结果可能内它丰富 链接:link 图片: 3.罗马盘&am…