目录
一、线性表的基本概念
(1)线性表的基本概念
(2)线性表的逻辑结构特征
(3)线性表的基本运算
二、线性表的顺序存储
(1)线性表顺序存储的类型定义
(2)线性表的基本运算在顺序表上的实现
(3)顺序表实现算法的分析
① 插入
② 删除
③ 定位(查找)
三、线性表的链接存储
(1)单链表的类型定义
① 单链表
② 单链表的一般图示法
③ 单链表的类型定义
④ 单链表的简单操作
(2)线性表的基本运算在单链表上的实现
① 初始化
② 求表长
③ 读表元素
④ 定位
⑤ 插入
⑥ 删除
四、其它运算在单链表上的实现
(1)建表
(2)删除重复结点
① 清除单链表中值为 x 的重复结点
② 清除单链表中所有重复结点
五、其它链表
(1)循环链表
(2)双向循环链表
① 双向循环链表
② 双向链表的结构体定义
③ 双向链表中结点的插入
④ 双向链表中结点的删除
六、顺序实现与连接实现的比较
(1)线性表与链表的优缺点
(2)时间性能的比较

一、线性表的基本概念
(1)线性表的基本概念
【概念】线性表是由 n(n≥0)个数据元素(结点)a1,a2,…,an 组成的有限序列。
【记法】数据元素的个数 n 定义为表的长度:
① n=0 时称为空表,记作:()或 (直接空格)② 非空的线性表(n>0),记作:L=(a1,a2,…,an)
- a1 称为起始结点,an 为终端结点。
- 对任意一对相邻结点 ai 和 ai+1( 1≤i<n ),ai 称为 ai+1 的直接前驱,ai+1 称为 ai 的直接后继。
③ 数据元素 ai(1≤i≤n)只是个抽象符号,其具体含义在不同情况下可以不同。【基本术语】
- 起始结点、终端结点、直接前驱、直接后继、线性表长度,空表
L=(a1,a2,…,an)【注意】
- 线性表中只有一个起始结点,一个终端结点
- 起始结点没有直接前驱,有一个直接后继
- 终端结点有一个直接前驱,没有直接后继
- 除此二结点外,每个结点都有且只有一个直接前驱和一个直接后继
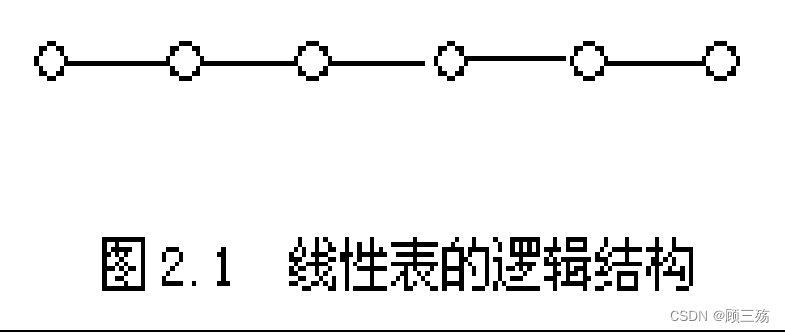
(2)线性表的逻辑结构特征
对于非空的线性表: 线性表中结点具有一对一的关系
- 有且仅有一个起始结点 a1,没有直接前驱,有且仅有一个直接后继 a2
- 有且仅有一个终端结点 an,没有直接后继,有且仅有一个直接前驱 an-1
- 其余的内部结点 ai(2≤i≤n-1)都有且仅有一个直接前驱 ai-1 和一个直接后继 ai+1
(3)线性表的基本运算
| 线性表的基本运算 | ||
| 初始化 | Initiate(L) | 建立一个空表 L=(),L 不含数据元素。 |
| 求表长度 | Length(L) | 返回线性表 L 的长度。 |
| 取表元 | Get(L,i) | 返回线性表第 i 个数据元素,当 i 不满足 1≤i≤Length(L) 时,返回一特殊值。 |
| 定位 | Locate(L,x) | 查找线性表中数据元素值等于 x 的结点序号,若有多个数据元素值与 x 相等,运算结果为这些结点中序号的最小值,若找不到该结点,则运算结果为 0。 |
| 插入 | Insert(L,x,i) | 在线性表 L 的第 i 个数据元素之前插入一个值为 x 的新数据元素,参数 i 的合法取值范围是 1≤i≤n+1 。 操作结束后线性表 L 由(a1,a2,…,ai-1, ai,ai+1,.…,an) 变为 (a1,a2,…,ai-1,x, ai,ai+1,.…,an),表长度加 1。 |
| 删除 | Delete(L,i) | 删除线性表 L 的第 i 个数据元素 ai,i 的有效取值范围是 1≤i≤n。 删除后线性表 L 由 (a1,a2,…,ai-1, ai,ai+1,.…,an)变为 (a1,a2,…,ai-1,ai+1,.…,an),表长度减 1。 |
二、线性表的顺序存储
(1)线性表顺序存储的类型定义
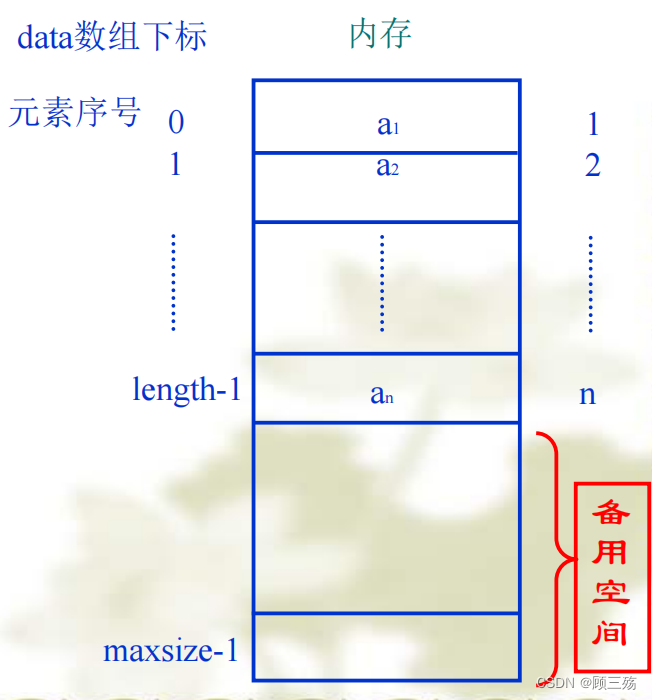
- 线性表顺序存储的方法是:将表中的结点依次存放在计算机内存中一组连续的存储单元中,数据元素在线性表中的邻接关系决定它们在存储空间中的存储位置,即逻辑结构中相邻的结点其存储位置也相邻。
- 用顺序存储实现的线性表称为顺序表。
- 一般使用数组来表示顺序表。
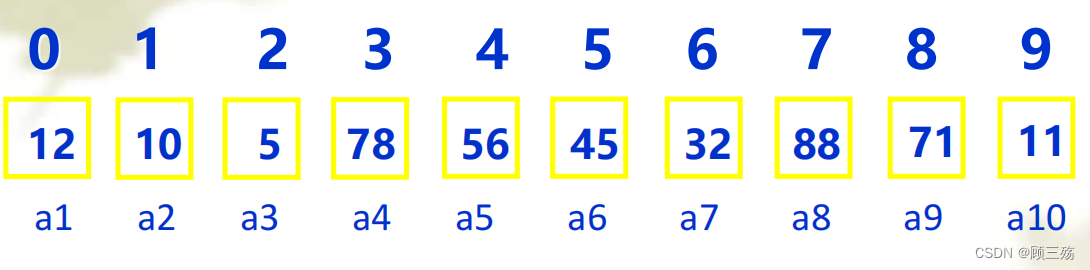
【示例】线性表的顺序存储结构
- 假定有一组数据,数据间有顺序:
- 此处数据间的顺序即表示数据间的逻辑关系即线性关系,这一组数据为线性表:
- 假设已知 a1 地址为 Loc(a1),每个数据占 c 个单元则计算 ai 地址:
Loc(ai) = Loc(a1) + c*(i-1)

【示例】顺序表的结构体定义
【示例代码】
//定义常量Maxsize并初始化为100 const int Maxsize = 100;//定义结构体Seqlist,包含一个数组和一个int类型的长度 typedef struct { DataType data[Maxsize]; //数组,用于存储数据int length; //当前数组中数据的个数 } Seqlist;Seqlist L; //定义一个Seqlist类型的变量L【代码详解】
- 代码定义了一个结构体 Seqlist,包含一个数组 data 和 int 类型的 length,用于存储数据和当前数组中数据的个数。
- 同时,定义了一个常量 Maxsize,并用 typedef 为 Seqlist 取了一个别名,方便以后使用。
- 最后,定义了一个 Seqlist 类型的变量 L。
- const int Maxsize = 7;
- 使用 const 关键字定义一个整型常量 Maxsize,表示顺序表中存储数据的数组最大长度为 7
- typedef struct
- 使用 struct 关键字定义一个结构体类型,名称为 DataType
- {
- 结构体定义开始的大括号
- int num;
- 结构体中的成员变量,表示学生的学号
- char name[8];
- 结构体中的成员变量,表示学生的姓名,姓名长度为 8 个字符
- char sex[2];
- 结构体中的成员变量,表示学生的性别,性别长度为 2 个字符
- int age;
- 结构体中的成员变量,表示学生的年龄
- int score;
- 结构体中的成员变量,表示学生的入学成绩
- } DataType;
- 结构体定义结束的大括号,并且紧接着定义了别名 DataType,表示结构体类型 DataType 的别名
- typedef struct
- 使用 struct 关键字定义一个结构体类型,名称为 seqList
- {
- 结构体定义开始的大括号
- DataType data[Maxsize];
- 结构体中的成员变量,表示存放数据的数组,最大长度为 Maxsize
- int length;
- 结构体中的成员变量,表示当前数组中数据的个数,也就是线性表的实际长度
- } seqList;
- 结构体定义结束的大括号,并且紧接着定义了别名 seqList,表示结构体类型 seqList 的别名
- seqList student;
- 定义一个顺序表变量 student,它是一个 seqList 类型的结构体变量,包含了一个数组 data 和一个 length 成员变量,可以用于存储多个学生的信息,即学号、姓名、性别、年龄和成绩等信息。
【图解】
【结论】
- 顺序表是用一维数组实现的线性表,数组下标可以看成是元素的相对地址
- 逻辑上相邻的元素,存储在物理位置也相邻的单元中
【特点】 顺序存储结构的特点:
- 线性表的逻辑结构与存储结构一致
- 可以对数据元素实现随机读取
【图解】
【表达式】
- 设线性表中所有结点的类型相同,则每个结点所占用存储空间大小亦相同。
- 假设表中每个结点占用 L 个存储单元,其中第一个单元的存储地址则是该结点的存储地址。
- 并设表中开始结点 a1 的存储地址是 d,那么结点 ai 的存储地址 LOC(ai):
LOC(ai)=d+(i-1)*L

(2)线性表的基本运算在顺序表上的实现
基本运算在顺序表上的实现:
- 插入
- 删除
- 定位
顺序表的优点:
- 无需为表示结点间的逻辑关系而增加额外存储空间
- 可以方便地随机存取表中的任一结点
顺序表的缺点:
- 插入和删除运算不方便,必须移动大量的结点
- 顺序表要求占用连续的空间,存储分配只能预先进行,因此当表长变化较大时,难以确定合适的存储规模
插入与删除分析结论:
- 顺序存储结构表示的线性表,在做插入或删除操作时,平均需要移动大约一半的数据元素。
- 当线性表的数据元素量较大,并且经常要对其做插入或删除操作时,这一点需要值得考虑。【说明】
- 根据上述定义,该顺序表的名称为 student ,表的最大长度为 7,表的实际长度值在student.length 中
(3)顺序表实现算法的分析
① 插入
- 线性表的插入运算是指在表的第 i(1≤i≤n+1)个位置上,插入一个新结点 x,使长度为 n 的线性表:
(a1,…,ai-1,ai,…an)
- 变成长度为 n+1 的线性表:
(a1,…,ai-1,x,ai,…an)① 当表空间已满,不可再做插入操作② 当插入位置为非法位置,不可做正常插入操作
顺序表插入操作过程:
- 将表中位置为 n ,n-1,…,i 上的结点,依次后移到位置 n+1,n,…,i+1 上,空出第 i 个位置
- 在该位置上插入新结点 x 。仅当插入位置 i=n+1 时,才无须移动结点,直接将 x 插入表的末尾
- 该顺序表长度加 1
- 下图为在位置 3 插入新结点 x=66 示意图:
【示意图】
【示例】在顺序表
L的第i个位置插入数据元素x:
- 插入前需要判断表是否已满以及插入位置是否合法
- 插入完成后需要将后面的元素向后移动一个位置,从而在顺序表中加入一个新的数据元素
【具体算法描述】
//在顺序表L的第i个位置插入元素x void InsertSeqlist(SeqList L, DataType x, int i) { //将元素x插入到顺序表L的第i个数据元素之前//检查表是否已经满if (L.length == Maxsize) exit("表已满");//检查插入位置i是否合法if (i < 1 || i > L.length+1)exit("位置错");//将i后面的每个元素都向后移一个位置for (j = L.length; j >= i; j--) //初始i=L.lengthL.data[j] = L.data[j - 1]; //依次后移//将x插入到下标为i-1的位置L.data[i - 1] = x;//表长度加1L.length++; }【代码详解】
- 该函数的作用是在顺序表 L 的第 i 个位置插入元素 x 。
- 函数中首先检查表是否已满,如已满则终止程序运行。
- 其次,检查插入位置 i 是否合法,如果 i 不在 1~L.length + 1 的范围内,则终止程序运行。
- 接下来将i后面的每个元素都向后移一个位置,为新元素 x 让出一个位置。
- 最后将 x 插入到下标为 i-1 的位置处,表长度加 1。
void InsertSeqlist(SeqList L, DataType x, int i)
- 函数名称:
InsertSeqlist- 返回值类型:无返回值,该函数的作用是直接修改顺序表
L- 参数类型:
SeqList L:顺序表变量DataType x:要插入的数据元素的值int i:要插入的数据元素在顺序表中的位置
if (L.length == Maxsize)
- 判断表是否已满
- 如果顺序表
L已经满了,那么就说明无法再插入新的元素,此时程序将会使用exit()系统函数结束运行,并输出"表已满"的错误信息
if (i < 1 || i > L.length+1)
- 判断插入数据元素的位置是否合法
- 如果内部参数
i的取值小于 1 或者大于L.length+1,那么就说明插入位置非法,此时程序将会使用exit()系统函数结束运行,并输出"位置错"的错误信息
for (j = L.length; j >= i; j--)
- 从最后一个数据元素开始,将第
i个元素位置后面的每个元素向后移动一个位置,腾出位置来插入新的数据元素j从顺序表L的最后一个元素开始循环,一直到位置i- 1,共需移动L.length - (i-1)个元素
L.data[j] = L.data[j - 1];
- 将顺序表中第
j-1个元素的值向右移动一个位置,即赋值给顺序表中第j个元素
L.data[i - 1] = x;
- 将要插入的通能元素
x插入到位置i-1上,完成在顺序表中的插入操作
L.length++;
- 由于顺序表中插入了一个数据元素,因此需要将顺序表中的元素个数
L.length加一,更新数据元素个数

插入算法的分析:
- 假设线性表中含有 n 个数据元素,在进行插入操作时,有 n+1 个位置可插入
- 在每个位置插入数据的概率是:1/(n+1)
- 在 i 位置插入时,要移动 n-i+1 个数据
- 假定在 n+1 个位置上插入元素的可能性均等,则平均移动元素的个数为:
- 平均时间复杂度 O(n) :

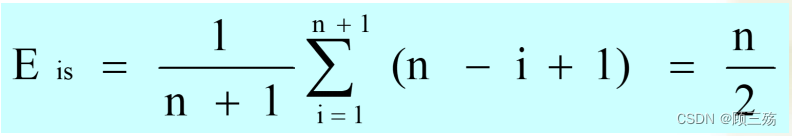
② 删除
- 线性表的删除运算是指将表的第 i 个结点删去,使长度为 n 的线性表:
(a1,…,ai-1,ai,ai+1,…,an)- 变成长度为n-1的线性表:
(a1,…,ai-1,ai+1,…,an)
- 当要删除元素的位置i不在表长范围内(即 i<1 或 i>L->length)时,为非法位置,不能做正常的删除操作
顺序表删除操作过程:
- 若 i=n,则只要删除终端结点,无须移动结点
- 该表长度减 1

【示例】在顺序表
L中删除第i个位置的数据元素:
- 首先需要判断该位置是否合法(注意,这里是从 1 开始计数)
- 如果位置合法,就将该位置后面的元素向左移动一个位置,从而将该位置的数据元素删除,并将顺序表的长度减一
- 如果位置非法,就会直接结束程序并输出错误信息
【具体算法描述】
//删除线性表L中的第i个数据结点 void DeleteSeqList(SeqList L, int i) {//检查位置是否合法if (i < 1 || i > L.length)exit("非法位置");//将i后面的每个元素向左移动一个位置for (j = i; j < L.length; j++) //第i个元素的下标为i-1L.data[j - 1] = L.data[j]; //依次左移//表长度减1L.length--; }【代码详解】
- 该函数的作用是删除线性表 L 中的第 i 个数据结点。
- 函数中首先检查位置是否合法,如果位置不合法,则终止程序运行。
- 将 i 后面的每个元素向左移动一个位置,为删除元素 x 让出一个位置。
- 最后将该元素删除,表长度减 1。
void DeleteSeqList(SeqList L, int i)
- 函数名称:
DeleteSeqList- 返回值类型:无返回值,该函数的作用是直接修改顺序表
L- 参数类型:
SeqList L:顺序表变量int i:要删除的元素在顺序表中的位置
if (i < 1 || i > L.length)
- 判断要删除的元素的位置是否合法
- 如果位置
i小于 1 或者i大于顺序表的长度L.length,那么就说明要删除的位置非法,此时程序将会使用exit()系统函数结束运行,并输出"非法位置"的错误信息
for (j = i; j < L.length; j++)
- 从要删除的元素位置
i开始,将其后面的每个元素向左移动一个位置,使删除i后的顺序表仍然保持连续存储结构j从i开始循环,一直到顺序表L的最后一个元素,共需移动L.length - i个元素
L.data[j - 1] = L.data[j];
- 将顺序表中第
j个元素的值向左移动一个位置,即赋值给顺序表中第j-1个元素
L.length--;
- 由于顺序表中删除了一个数据元素,因此需要将顺序表中的元素个数
L.length减一,更新数据元素个数
删除算法的分析:
- 假设线性表中含有 n 个数据元素,在进行删除操作时,有 n 位置可删除
- 在每个位置删除数据的概率是:1/n
- 在 i 位置删除时,要移动 n-i 个数据
- 假定在 n 个位置上删除元素的可能性均等,则平均移动元素的个数为:
- 在进行删除操作时,若假定删除每个元素的可能性均等,则平均移动元素的个数为:
- 平均时间复杂度 O(n):

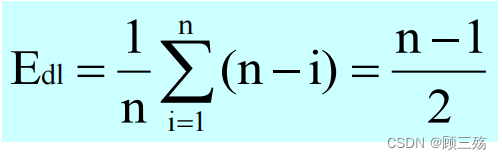
③ 定位(查找)
定位运算 LocateSeqlist(L,X) 的功能是求 L 中值等于 X 的结点序号的最小值,当不存在这种结点时结果为 0 。
【示例】在顺序表L中查找值为x的元素并返回其在顺序表中的位置:
- 首先设置查找起始位置为 0
- 然后通过循环在顺序表中查找值为
x的元素- 如果找到了就返回其位置,如果未找到则返回 0
【示意图】
【具体算法描述】从第一个元素 a1 起依次和 x 比较,直到找到一个与 x 相等的数据元素,则返回它在顺序表中的存储下标或序号;或者查遍整个表都没有找到与 x 相等的元素,返回 0:
//在顺序表L中查找值为x的元素 int LocateSeqlist(SeqList L, DataType x) {int i = 0;//在顺序表中查找值为x的结点while ((i < L.length) && (L.data[i] != x))i++;//若找到值为x的元素,返回元素的序号if (i < L.length)return i + 1;//未查找到值为x的元素,返回0else return 0; }【代码详解】
- 该函数的作用是在顺序表 L 中查找值为 x 的元素。
- 函数中通过 while 循环在顺序表L中查找值为 x 的元素,若找到值为 x 的元素,则返回该元素的序号。
- 若未查找到值为 x 的元素,则返回 0。
- 顺序表的求表长操作,直接输出 L.length 即可。
int LocateSeqlist(SeqList L, DataType x)
- 函数名称:
LocateSeqlist- 返回值类型:
int,返回值表示查找到的元素在顺序表中的位置- 参数类型:
SeqList L:顺序表变量DataType x:查找的元素值
int i = 0;
- 定义一个整数变量
i,表示当前顺序表中查找的位置
while ((i < L.length) && (L.data[i] != x))
- 循环查找顺序表中是否包含元素值为
x的元素
- 当
i小于顺序表的长度,并且当前位置i对应的元素值不为x时,继续查找,即在顺序表中查找到第一个值为x的元素
i++;
- 不断将当前查找位置加 1,继续往后查找,直到找到值为
x的元素
if (i < L.length)
- 如果当前查找位置
i小于顺序表的长度
return i + 1;
- 返回查找到的值为
x的元素在顺序表中的位置,位置从 1 开始计数
else
- 如果顺序表中未找到值为
x的元素
return 0;
- 返回 0,表示未查找到值为
x的元素
在分析线性表的顺序表实现算法时,一个重要指标就是数据元素的比较和移动的次数。1. 设表的长度 length=n,在插入算法中,元素的移动次数不仅与顺序表的长度 n 有关, 还与插入的位置 i 有关。
- 插入算法在最坏情况下,其时间复杂度为 O(n)。
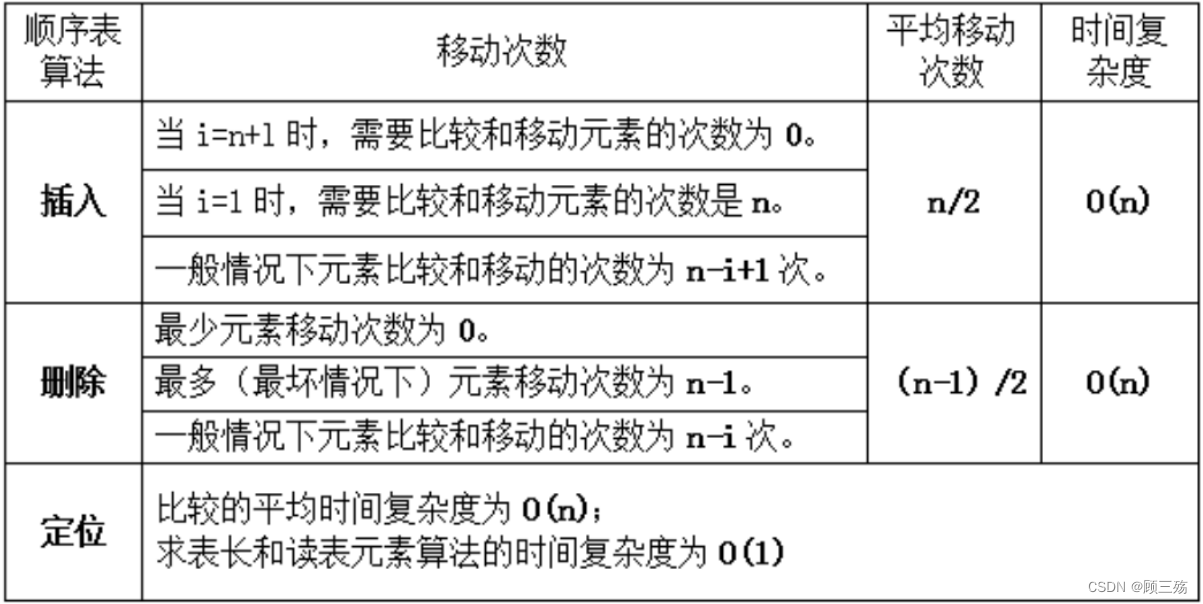
- 一般情况下元素比较和移动的次数为 n-i+1 次,插入算法的平均移动次数约为 n/2, 其时间复杂度是 O(n)。
2. 删除算法 DeleteSeqlist,可得:
- 其在最坏情况下元素移动次数为 n-1,时间复杂度为 O(n),元素平均移动次数约为(n-1)/2,时间复杂度为 O(n)。
3. 对于定位算法,需要扫描顺序表中的元素。
- 以参数 x 与表中结点值的比较为标准操作,平均时间复杂度为 O(n)。
- 求表长和读表元素算法的时间复杂度为 O(1),就阶数而言,己达到最低。
三、线性表的链接存储
链接方式存储的线性表简称为链表:
- Link List
链表的具体存储表示为:
- 用一组任意的存储单元来存放
- 链表中结点的逻辑次序和物理次序不一定相同。还必须存储指示其后继结点的地址信息
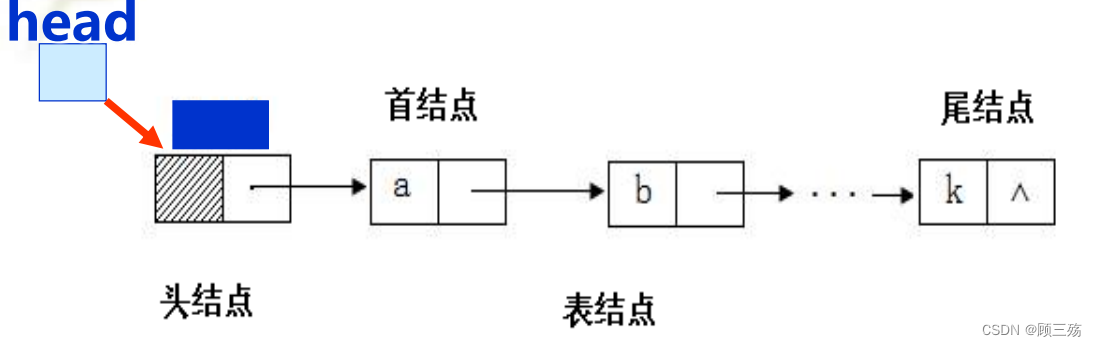
(1)单链表的类型定义
① 单链表
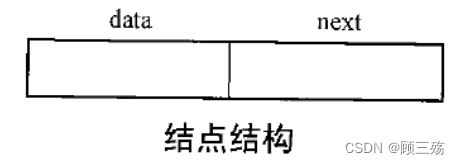
【示意图】
【说明】
- data 域:存放结点值的数据域
- next 域:存放结点的直接后继的地址(位置)的指针域(链域)
- 所有结点通过指针链接而组成单链表
- NULL 称为:空指针
- Head 称为:头指针变量,存放链表中第一个结点地址
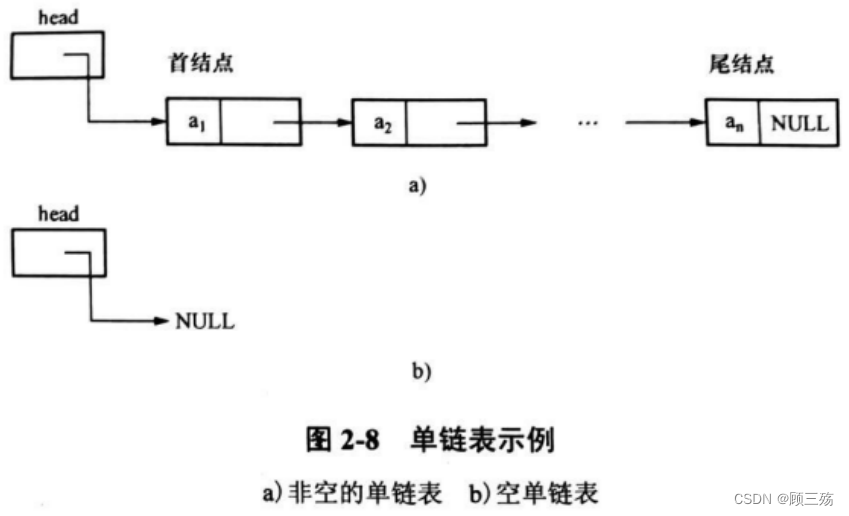
② 单链表的一般图示法
【说明】
- 由于我们常常只注重结点间的逻辑顺序,不关心每个结点的实际位置,可以用箭头来表示链域中的指针,单链表就可以表示为下图形式
- 加设头结点的作用:单链表中第一个结点内一般不存数据,称为头结点,利用头指针存放该结点地址
【示意图】
③ 单链表的类型定义
【示例】定义了一个链表节点的结构体类型
node,其中包含数据域data和指针域next,同时定义了两个别名Node和LinkList,方便后续程序的编写。【示意图】
【具体算法描述】
//定义链表节点结构体 typedef struct node { DataType data; //数据域struct node* next; //指向下一个节点的指针域 } Node, *LinkList;【代码详解】
- 该代码定义了一个链表的节点结构体。
- 每个节点包含一个数据域 data,存储节点的数据,和一个指向下一个节点的指针域 next。
- 同时使用 typedef 关键字定义了两个新的类型,一个是 Node,表示节点类型,另一个是LinkList,表示链表类型。
- LinkList 类型是一个指向 Node 类型的指针。
- 这个链表是单向链表,每个节点只包含一个指向下一个节点的指针。
typedef struct node
- 使用
struct关键字定义一个结构体类型node
{
- 结构体定义开始的大括号
DataType data;
- 结构体中的成员变量,表示节点的数据域
struct node* next;
- 结构体中的成员变量,表示节点的指针域,指向下一个节点
} Node, *LinkList;
- 结构体定义结束的大括号,并且紧接着定义了两个别名,
Node表示结构体类型node的别名,LinkList表示指向结构体类型node的指针的别名。因此,使用LinkList声明的指针就是指向链表头节点的指针。


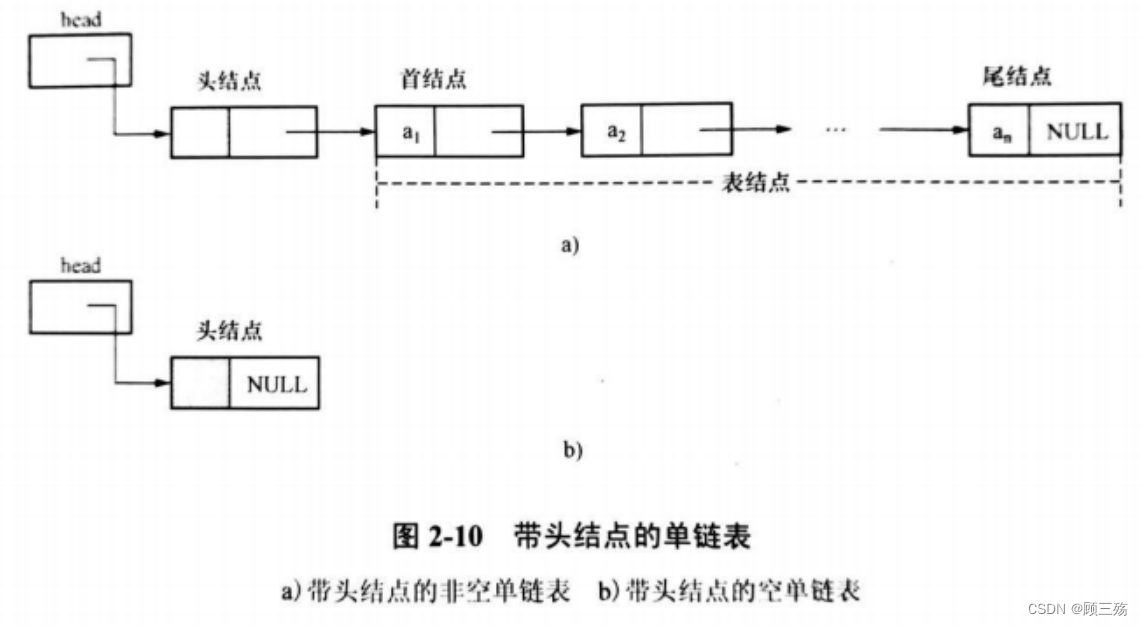
④ 单链表的简单操作
单链表特点:
- 起始节点又称为首结点,无前驱,故设头指针 head 指向开始结点。
- 链表由头指针唯一确定,单链表可以用头指针的名字来命名。头指针名是 head 的链表可称为表 head 。
- 终端结点又称尾结点,无后继,故终端结点的指针域为空,即 NULL
- 除头结点之外的结点为表结点
- 为运算操作方便,头结点中不存数据
【示意图】
【说明】
- head 是链表的头指针,所以是指针类型变量。
- head 内存放的是头结点的地址。
- 第一个元素结点:head->next

(2)线性表的基本运算在单链表上的实现
① 初始化
【示例】初始化一个空的单链表
- 通过动态分配内存空间,创建一个大小为
Node的头结点,将头结点的下一个节点指针域设置为空指针,最终返回头结点的指针,表示单链表中还没有任何数据
- 建立一个空的单链表 L,InitiateLinkList(L)
- 一个空的单链表是一个头指针和一个头结点构成的
- 假设已定义指针变量 t,令 t 指向一个头结点
- 并令头结点的 next 为 NULL
【注意】
- 产生头结点时由 malloc 函数产生一个新节点
【特别注意】malloc 函数的使用格式及作用
- 【格式】动态分配内存函数 malloc 函数格式如下:
(数据类型*)malloc(sizeof(数据类型))// 示例: int *p;p=(int *)malloc(sizeof(int))【具体算法描述】空表由一个头指针和一个头结点组成。算法描述如下:
//初始化一个空的单链表 LinkList InitiateLinkList() {LinkList head; //头指针head = malloc(sizeof(Node)); //动态构建一个节点,它是头节点head->next = NULL; //头节点的指针域为空return head; }【代码详解】
- 该函数的作用是初始化一个空的单链表。
- 函数中首先定义了一个头指针 head。
- 接着使用 malloc 函数动态分配一个头结点,并将头节点的指针域指向 NULL。
- 最后返回头指针 head。
LinkList InitiateLinkList()
- 函数名称:
InitiateLinkList- 返回值类型:
LinkList,即返回一个指向链表头结点的指针- 参数类型:无参数
LinkList head;
- 声明一个指向
Node类型的指针head,表示链表的头结点
head = malloc(sizeof(Node));
- 使用
malloc动态分配一个大小为Node的内存空间,返回该空间的地址给指针head
head->next = NULL;
- 将链表头节点的指针域设置为空指针,因为此时链表中除了头结点外还没有任何节点
return head;
- 返回头结点的指针
head,从而初始化一个空的单链表
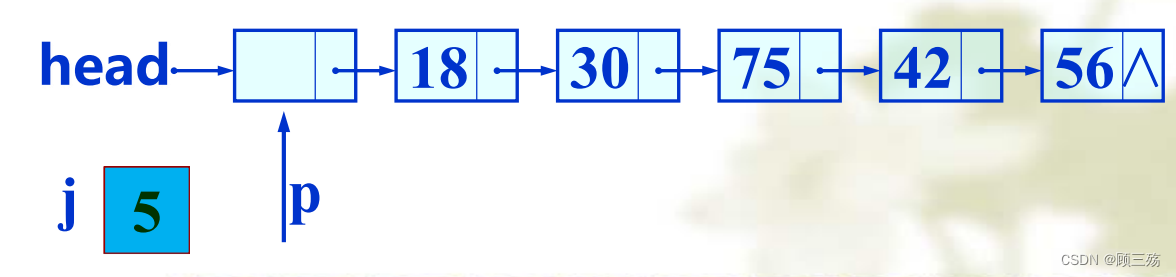
② 求表长
【示意图】
【说明】
【示意图】
【步骤】
- 令计数器 j 为 0
- 令 p 指向头结点
- 当下一个结点不空时,j 加 1,p 指向下一个结点
- j 的值即为链表中结点个数,即表长度
【示例】获取单链表
head的长度
- 定义一个指针
p,指向链表的头结点,通过遍历链表的方式获取链表的长度,最终将链表的长度作为函数的返回值【注意】
- p=p->next 的作用
【具体算法描述】空表由一个头指针和一个头结点组成。算法描述如下:
//获取单链表的长度 int lengthLinklist(LinkList head) { Node* p; //定义一个指针p,用于遍历链表p = head; //指向链表头节点int j = 0; //用于记录链表长度的计数器while (p->next != NULL) //当指针p没有指向链表尾节点时{ p = p->next; //指针p指向下一个节点j++; //链表长度加1}return j; //返回链表长度 }【代码详解】
- 该函数的作用是获取单链表的长度。
- 函数中定义了一个指针 p,用于遍历链表。
- 指针 p 从链表的头节点开始,循环遍历链表,直到链表的尾节点。
- 在遍历的过程中,计数器j用于记录链表的长度。
- 最后返回计数器j的值,即链表的长度。
int lengthLinklist(LinkList head)
- 函数名称:
lengthLinklist- 返回值类型:
int,即返回链表的长度- 参数类型:
LinkList head:指向链表头结点的指针(链表头结点不包含数据,其下一个节点才是链表的第一个节点)
Node* p;
- 声明指向
Node类型的指针p,用于遍历链表
p = head;
- 将指针
p指向链表头结点,开始从链表头开始遍历
int j = 0;
- 声明整型变量
j,用于记录链表长度的计数器
while (p->next != NULL)
- 当指针
p没有指向链表尾节点时(即p的下一个节点不为空)
p = p->next;
- 将指针
p指向下一个节点,即p指向链表中的下一个节点
j++;
- 链表长度计数器
j加 1,表示当前已经遍历到一个节点
return j;
- 遍历结束后返回链表的长度,即计数器
j的值
③ 读表元素
【示意图】
【步骤】查找第 i 个结点
- 令计数器 j 为 0
- 令 p 指向头结点
- 当下一个结点不空时,并且 j<i 时,j 加 1,p 指向下一个结点
- 如果 j 等于 i,则 p 所指结点为要找的第 i 结点;否则,链表中无第 i 结点

【示例】在链表中查找第
i个节点,并返回该节点的指针,如果没有找到,则返回空指针【具体算法描述】
// 获取链表中第 i 个节点的指针 Node* GetlinkList(LinkList head, int i) {Node* p;p = head->next; // 将 p 指向链表的第一个节点int c = 1; // 用 c 记录当前节点位置while ((c < i) && (p != NULL)) // 当前节点位置小于 i 且 p 不为空时{p = p->next; // 将 p 指向下一个节点c++; // 位置加一}if (i == c) // 如果当前节点位置等于 i,则返回当前节点的指针return p;elsereturn NULL; // 否则返回空指针 }【代码详解】
Node* GetlinkList(LinkList head, int i)
- 函数名称:
GetlinkList- 返回值类型:
Node*,即指向Node类型的指针- 参数类型:
LinkList head:指向链表头结点的指针(链表头结点不包含数据,其下一个节点才是链表的第一个节点)int i:要查找的节点在链表中的位置
Node* p;
- 声明一个指向
Node类型的指针p
p = head->next;
- 将指针
p指向链表head的下一个节点,即链表中的第一个节点
int c = 1;
- 定义变量
c,用于记录当前处理的节点在链表中的位置,初始化为 1,即第一个节点的位置
while ((c < i) && (p != NULL))
- 进入一个 While 循环
- 循环条件是:当前处理的节点在链表中的位置小于要查找的位置
i且当前指针p不为空- 当循环结束后,
p将指向目标节点或者为空
p = p->next;
- 在循环中,每次将指针
p指向下一个节点
c++;
- 在循环中,每次将变量
c加 1,表示当前指针p所指的节点在链表中的位置加 1
if (i == c)
- 判断当前节点在链表中的位置是否等于要查找的位置
i
return p;
- 如果当前节点在链表中的位置等于要查找的位置
i,则直接返回该节点的指针p
else
- 在不满足条件的情况下,返回空指针
NULL,表示没有找到目标节点
④ 定位
- 定位运算是对给定表元素的值,找出这个元素的位置。
- 对于单链表,给定一个结点的值,找出这个结点是单链表的第几个结点。
- 定位运算又称为按值查找。
具体步骤:
- 令 p 指向头结点
- 令 i=0
- 当下一个结点不空时,p 指向下一个结点,同时 i 的值加 1
- 直到 p 指向的结点的值为 x ,返回 i+1 的值
- 如果找不到结点值为 x 的话,返回值为 0
【说明】
- 线性表的定位运算,就是对给定表元素的值,找出这个元素的位置。
- 在单链表的实现中,则是给定一个结点的值,找出这个结点是单链表的第几个结点。
- 定位运算又称作按值查找。
- 在定位运算中,也需要从头至尾访问链表,直至找到需要的结点,返回其序号。
- 若未找到,返回 0 。
【示例】在链表
head中查找值等于x的第一个节点,并返回该节点的序号,如果不存在这样的节点,则返回 0【具体算法描述】
// 在链表中查找第一个与 x 相等的节点,返回节点的序号 // 如果不存在这样的节点,则返回 0 int LocateLinklist(LinkList head, DataType x) {Node *p = head; // 将工作指针 p 指向链表头结点p = p->next; // 将工作指针 p 指向链表的第一个节点int i = 0; // 初始化结点序号为 0while (p != NULL && p->data != x) // 当 p 非空且 p 所指向节点的数据域不为 x 时{i++; // 结点序号加一p = p->next; // 工作指针指向下一个节点}if (p != NULL) // 如果 p 不为空,说明找到了相应的节点return i + 1; // 返回节点的序号elsereturn 0; // 否则返回 0 }【代码详解】
int LocateLinklist(LinkList head, DataType x)
- 函数名称:
LocateLinklist- 返回值类型:
int,表示节点的序号,如果没有找到相应的节点则返回 0- 参数类型:
LinkList head:指向链表头结点的指针(链表头结点不包含数据,其下一个节点才是链表的第一个节点)DataType x:要查找的节点的值
Node *p = head;
- 声明一个指向
Node类型的指针p,并将其指向链表head
p = p->next;
- 将指针
p指向链表的第一个节点
int i = 0;
- 初始化节点序号为 0
while (p != NULL && p->data != x)
- 进入一个 While 循环
- 循环条件是:当前处理的节点的值不等于要查找的值
x,且当前指针p不为空- 当循环结束后,
p将指向目标节点或者为空
i++;
- 在循环中,每次将节点序号加 1,表示已经处理了一个节点
p = p->next;
- 在循环中,每次将指针
p指向下一个节点
if (p != NULL)
- 判断当前节点是否为空
return i + 1;
- 如果当前节点不为空,则返回当前节点的序号加 1
else
- 如果当前节点为空,则返回 0
⑤ 插入
插入运算是将值为 x 的新结点插入到表的第 i 个结点的位置上,即插入到 ai-1 与 ai 之间。具体步骤:
- 找到 ai-1 存储位置 p
- 生成一个数据域为 x 的新结点 *s
- 令结点 *p 的指针域指向新结点
- 新结点的指针域指向结点 ai
【示例】在链表
head中的第i个数据元素结点之前插入一个值为x的新结点。如果插入位置不存在,则输出错误信息并退出,否则将新结点插入到该位置【示意图】
【具体算法描述】
// 在链表 head 的第 i 个数据元素结点之前插入一个以 x 为值的新结点 void InsertLinklist(LinkList head, DataType x, int i) {Node *p, *q;if (i == 1)q = head;elseq = GetLinklist(head, i - 1); // 找到第 i-1 个数据元素结点if (q == NULL) // 第 i-1 个结点不存在exit("找不到插入的位置");else{p = malloc(sizeof(Node)); // 生成新结点p->data = x; // 新结点的数据赋值为 xp->next = q->next; // 新结点的链域指向*q的后继结点q->next = p; // 修改*q的链域} }【代码详解】
void InsertLinklist(LinkList head, DataType x, int i)
- 函数名称:
InsertLinklist- 返回值类型:
void,即不返回任何值- 参数类型:
LinkList head:指向链表头结点的指针(链表头结点不包含数据,其下一个节点才是链表的第一个节点)DataType x:要插入的节点的值int i:要插入的位置,即在第i个数据元素结点之前插入新节点
Node *p, *q;
- 声明指向
Node类型的指针,p指向新节点,q指向第i-1个数据元素结点
if (i == 1)
- 如果 i 等于 1,则新节点将插入头结点之后
q = head;
- 如果 i 等于 1,则直接将
q指向头结点
else
- 如果 i 大于 1,则需要找到第
i - 1个数据元素结点
q = GetLinklist(head, i - 1);
- 调用
GetLinklist函数,返回链表中第i - 1个数据元素结点的指针q
if (q == NULL)
- 如果
q为空指针,说明插入位置不存在
exit("找不到插入的位置");
- 输出错误信息并退出程序
else
- 如果
q不为空指针,则说明插入位置存在
p = malloc(sizeof(Node));
- 动态分配一个大小为
Node的内存空间,返回该空间的地址给指针p
p->data = x;
- 将新节点的数据域赋值为
x
p->next = q->next;
- 将新节点的链域指向第 i 个数据元素结点,即指向
q的后继结点
q->next = p;
- 将第
i-1个数据元素结点的链域指向新节点,使其成为新的第i个数据元素结点【注意】链接操作 p->next=q->next 和 q->next=p 两条语句的执行顺序不能颠倒,否则结点 *q 的链域值(即指向原表第i个结点的指针)将丢失。

⑥ 删除
【算法思路】 此算法描述删除第 i 个结点
- 找到第 i-1 个结点;若存在继续,否则结束;
- 删除第 i 个结点,并释放对应的内存,结束。
【算法步骤】删除运算是将表的第 i 个结点删去
- 找到 ai-1 的存储位置 p
- 令 p->next 指向 ai 的直接后继结点
- 释放结点 ai 的空间,将其归还给 "存储池"
【说明】在单链表中删除第 i 个结点的基本操作为:
- 找到线性表中第 i-1 个结点,修改其指向后继的指针
【示例】删除链表
head中的第i个结点:
- 如果该结点不存在,则输出错误信息并退出,否则将该结点从链表中移除并释放其所占用的内存空间
【示意图】
【具体算法描述】
// 删除表 head 的第 i 个结点 void DeleteLinklist(LinkList head, int i) {Node *q, *p;if (i == 1)q = head;elseq = GetLinklist(head, i - 1); // 先找待删结点的直接前驱if (q != NULL && q->next != NULL) // 若直接前驱存在且待删结点存在{p = q->next; // p 指向待删结点q->next = p->next; // 移出待删结点free(p); // 释放已移出结点 p 的空间}elseexit("找不到要删除的结点"); // 结点不存在 }【代码详解】
void DeleteLinklist(LinkList head, int i)
- 函数名称:
DeleteLinklist- 返回值类型:
void,即不返回任何值- 参数类型:
LinkList head:指向链表头结点的指针(链表头结点不包含数据,其下一个节点才是链表的第一个节点)int i:要删除的节点的位置,即删除第i个节点
Node *q, *p;
- 声明指向
Node类型的指针q和p,q指向待删结点的直接前驱,p指向待删结点
if (i == 1)
- 如果 i 等于 1,则要删除的节点为头结点,因此将
q指向头结点
q = head;
- 如果 i 等于 1,则将
q指向头结点
else
- 如果 i 大于 1,则需要找到待删结点的直接前驱
q = GetLinklist(head, i - 1);
- 调用
GetLinklist函数,返回链表中第i - 1个数据元素结点的指针q
if (q != NULL && q->next != NULL)
- 如果直接前驱结点
q不为空指针且待删结点存在
p = q->next;
- 将指针
p指向待删结点,即q的后继结点
q->next = p->next;
- 将指针
q的下一个节点指向待删结点的下一个节点,即将待删结点从链表中移出
free(p);
- 释放已移出结点
p的空间
else
- 如果结点不存在
exit("找不到要删除的结点");
- 输出错误信息并退出程序
【注意】free(p) 是必不可少的,因为当一个结点从链表移出后,如果不释放它的空间,它将变成一个无用的结点,它会一直占用着系统内存空间,其他程序将无法使用这块空间。
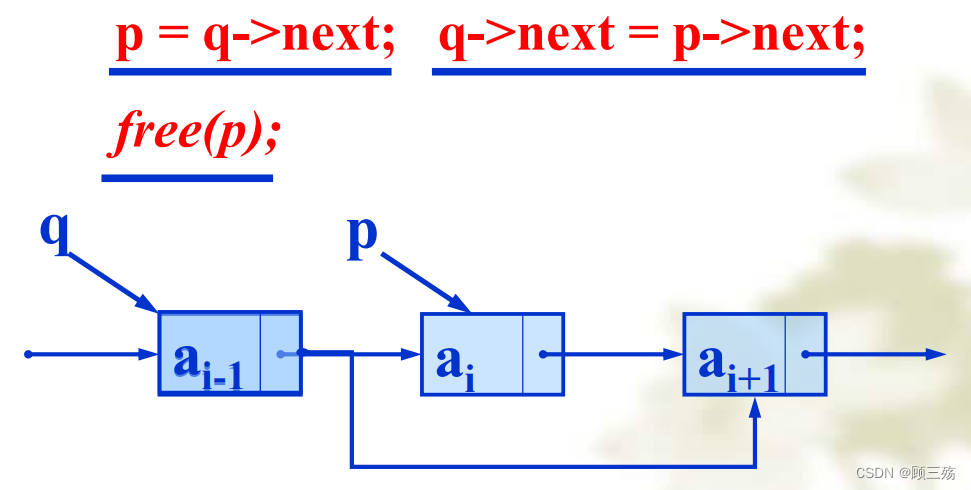
四、其它运算在单链表上的实现
(1)建表
这个过程分为三步:
- 首先建立带头结点的空表
- 其次建立一个新结点,然后将新结点链接到头结点之后,这个结点为尾结点(也是首结点)
- 复建立新结点和将新结点链接到表尾这两个步骤,直到线性表中所有元素链接到单链表中,这里用 int 代替 DataType
【方法一】 通过已实现的插入算法 InsertLinklist (LinkList head, int x, int i) 来实现,依次增大插入位置 i,使新的结点链入到链表中。
【示例】建立单链表的操作
【示例代码】
// 建立单链表 LinkList CreatLinklist() // 通过调用InitiateLinklist和Insertlinklist实现建表算法。假定0是输入结束标志 {// 创建头结点LinkList head;int x, i;head = InitiateLinklist(); // 建立空表:初始化链表,创建头结点// 循环插入结点i = 1; // 置插入位置初值scanf("%d", &x); // 读入第一个数据元素,x为整型while (x != 0) // 输入的不是结束标志时继续插入{InsertLinklist(head, x, i); // 将输入插入到head表尾:在链表的第i个位置插入值为x的结点i++; // 修改插入位置scanf("%d", &x); // 读下一元素}return head; // 返回创建好的单链表头结点指针 }【代码详解】
- 在函数内部,首先调用
InitiateLinklist函数建立一个空链表,并创建头结点head。- 然后通过循环读取数据元素并插入到单链表中,直到读取到结束标志 0 为止。
- 每次插入时,调用
InsertLinklist函数将数据元素插入到单链表的头部,并将插入位置i加 1,为下一个数据元素的插入做准备。- 最后,返回单链表头结点指针
head。
LinkList CreatLinklist()
- 函数名称:
CreatLinklist- 返回值类型:单链表的头结点指针,类型为
LinkList- 参数类型:无参数
LinkList head; int x, i;
- 定义
head、x和i三个变量,分别表示单链表的头结点指针、输入的数据元素和插入位置
head = InitiateLinklist();
- 调用
InitiateLinklist创建一个空链表,即初始化链表和创建头结点,并将头结点指针赋值给head
i = 1;
- 将插入位置初值设置为 1,表示将数据元素插入链表的第一个位置
scanf("%d", &x);
- 从标准输入中读取一个整型数据元素,存储在变量
x中
while (x != 0)
- 当读入的数据元素不为 0 时,循环执行以下操作:
InsertLinklist(head, x, i);
- 在单链表
head中的第i个位置插入一个值为x的新结点
i++;
- 将插入位置增加 1,为下一个数据元素的插入做准备
scanf("%d", &x);
- 从标准输入中读取下一个整型数据元素,存储在变量
x中
return head;
- 返回创建好的单链表头结点指针
head
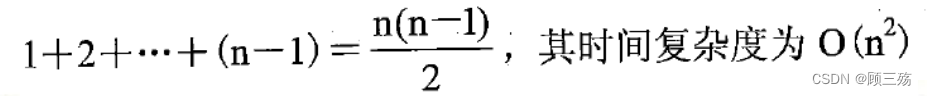
【方法二】方法一的算法由于每次插入都从表头开始查找,比较浪费时间:因为每次都是把新的结点链接到表尾,我们可以用一个指针指向尾结点,这样就为下一个新结点指明了插入位置
【示例 1】建立单链表的操作
【示意图】
【示例代码】函数名为
CreatLinklist2,返回值为单链表的头结点指针,类型为LinkList:// 建立单链表 LinkList CreatLinklist2() //q是一个LinkList类型的变量,用来指示链入位置 {// 创建头结点LinkList head;Node *q, *t;int x;head = (Node *)malloc(sizeof(Node)); // 创建头结点q = head; // 尾指针置初值,指向头结点scanf("%d", &x); // 读入第一个数据元素 xwhile (x != 0) // 输入的不是结束标志时继续插入{t = (Node *)malloc(sizeof(Node)); // 生成一个新结点t->data = x; // 给新节点赋值q->next = t; // 新节点t插入到链表中q = t; // 修改尾指针 q,指向新的尾结点scanf("%d", &x); // 读下一元素}q->next = NULL; // q指向尾结点,置尾结点标志return head; // 返回头结点指针 }【代码详解】
- 这段函数代码实现了建立单链表的操作。
- 在函数内部,一开始创建了单链表的头结点
head。- 在循环中,使用
malloc函数分配内存空间,为新的数据元素创建一个新的结点t,并将输入的数据元素赋值给新结点t的data成员。- 然后,将新结点
t插入到链表的末尾,并将尾指针q指向新的尾结点t。- 当遇到结束标志时,将尾结点
q的next指针设置成NULL,表示链表已经结束,最后返回单链表的头结点指针head,表示创建成功的单链表。
LinkList CreateLinklist2()
- 函数名称:
CreateLinklist2- 返回值类型:单链表的头结点指针,类型为
LinkList- 参数类型:无参数
LinkList head; Node *q, *t; int x;
- 定义
head、q和t三个变量,分别表示单链表的头结点指针、尾结点指针和新创建的结点指针;定义x表示输入的数据元素
head = (Node *)malloc(sizeof(Node));
- 使用
malloc函数分配内存空间,分配的内存大小为Node结构体的大小,将分配到的内存地址赋值给头结点指针head
q = head;
- 将尾指针
q的初始值设为头结点head
scanf("%d", &x);
- 从标准输入流中读取一个整型数据元素,存储在变量
x中
while (x != 0)
- 只要输入的数据元素不是结束标志,就执行以下操作:
t = (Node *)malloc(sizeof(Node));
- 创建一个新的结点
t,使用malloc函数分配内存空间
t->data = x;
- 赋值新结点
t的data成员,将其设置成输入的数据元素的值x
q->next = t;
- 将新结点
t插入到链表中,即将新结点t放在原尾结点q后面,将q指向新结点t
q = t;
- 将尾指针
q指向新的尾结点t
scanf("%d", &x);
- 从标准输入流中读取下一个整型数据元素,存储在变量
x中
q->next = NULL;
- 尾结点
q的next指针设置为NULL,表示链表结束
return head;
- 返回单链表的头结点指针
head,即创建成功的单链表
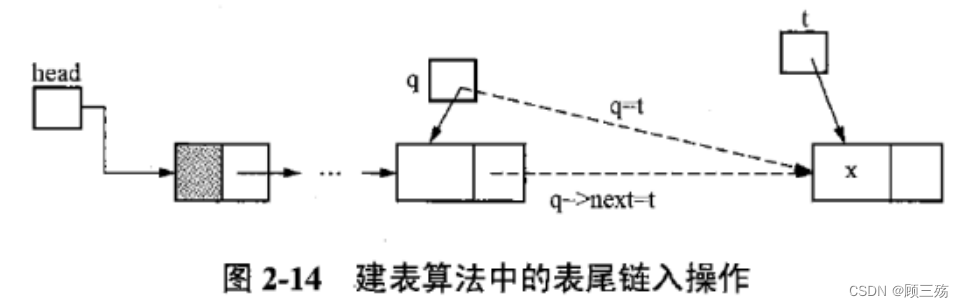
【方法二】方法一的算法由于每次插入都从表头开始查找,比较浪费时间:因为每次都是把新的结点链接到表尾,我们可以用一个指针指向尾结点,这样就为下一个新结点指明了插入位置
【示例 2】建立单链表的操作
【示意图】
【示例代码】
// 建立单链表 LinkList CreatLinklist3() {// 创建头结点LinkList head; // 定义头结点Node *p; // 定义一个指向Node类型的指针,用于遍历链表int x; // 定义一个节点的数据head = malloc(sizeof(Node)); // 创建头结点,动态分配内存空间head->next = NULL; // 头结点的next指针指向NULLscanf("%d", &x); //读入节点的数据while (x) // x=0 时结束输入:如果节点数据不为0,就一直循环插入节点{p = malloc(sizeof(Node)); // 动态分配内存空间,创建新节点p->data = x; // 给节点赋值p->next = head->next; // 前插:插入到链表的第一个结点处head->next = p; // 让头结点的next指针指向新插入的结点,从而将新节点加入到链表中scanf("%d", &x); // 读入节点数据}return head; // 返回链表头结点 }【代码详解】
- 这个函数用于创建一个单链表,函数开头声明了一个LinkList类型的返回值,意味着这个函数返回的是链表的头结点,每个节点包含一个数据和一个指向下一个节点的指针。
- 这个函数先创建头结点,然后不断读入新节点数据,直到读入的数据为0为止。
- 在读入新节点数据时,程序创建一个新的节点并为其赋值,然后把它加入到链表的第一个位置。
- 这里使用的是头插法,即让新的节点指向原来的第一个节点,然后让头节点指向新节点。
- 最后返回头节点。
1. 定义头结点
LinkList head; // 定义头结点
- 首先定义了一个 LinkList 类型的头结点,LinkList 类型在函数声明时被定义为:
typedef struct Node *LinkList;- 而 Node 结构体的定义如下:
struct Node {int data; // 存储节点数据Node *next; // 存储指向下一个节点的指针 };2. 动态分配内存空间,创建头结点
- 使用 malloc 函数分配内存空间给头结点
head = malloc(sizeof(Node)); // 创建头结点,动态分配内存空间3. 头结点初始化
- 将头结点的 next 指针指向 NULL
head->next = NULL; // 头结点的next指针指向NULL4. 读入节点的数据,创建节点并插入链表
- 先读入节点的数据,如果节点数据不为0,就一直循环插入节点。首先动态分配内存空间,创建一个新的节点,并为其赋值。然后将新创建的节点插入到原链表的第一个位置,也就是让新节点的 next 指针指向原来的第一个节点,然后让头节点的 next 指针指向新节点。这里使用了前插法,所以每次新节点插入到链表中的位置都是原来的第一个位置。
scanf("%d", &x); // 读入节点的数据 while (x) { // x=0 时结束输入, 如果节点数据不为0,就一直循环插入节点p = malloc(sizeof(Node)); // 动态分配内存空间,创建新节点p->data = x; // 给节点赋值p->next = head->next; // 前插:插入到链表的第一个结点处head->next = p; // 让头结点的next指针指向新插入的结点,从而将新节点加入到链表中scanf("%d", &x); // 读入节点数据 }5. 返回链表头结点
- 最后返回链表的头结点
return head; // 返回链表头结点【注意】
- 在这段代码中使用了 malloc 函数动态分配内存空间,分配的内存需要在最后释放
- 在 C++ 中不推荐使用 malloc 分配内存,而是建议使用 new 操作符,可以避免一些内存管理的问题。
- 此外,建议在代码中加入释放节点垃圾内存的语句,防止内存泄漏的问题。

(2)删除重复结点
① 清除单链表中值为 x 的重复结点
【分析】清除单链表中值为 x 的重复结点
【步骤】
- 找到值为 x 的第一个结点位置,p 指向该结点
- 从 p 所指结点开始向后查找,若存在值为x的结点,令 q 指向 x 结点前一个执行删除操作,继续查找直到链表末尾
② 清除单链表中所有重复结点
【逐步求精法分析】
【整体步骤】
- 当未到达链表末尾时(ai 不是终端结点时)
- 删除 ai+1 到 an 结点中值为 ai 的结点
- i++
i=1 While(ai不是终端结点) { 删除 ai+1 到 an 结点中值为 ai 的结点i++ }
【进一步细化分析】
【进一步细化步骤】
- 当未到达链表末尾时(ai 不是终端结点时)
- 删除 ai+1 到 an 结点中值为 ai 的结点
- j=i
while (j<n) { if(aj==ai) 删除 ajj++ } i++
【示例】删除单链表中多余的重复结点的函数
- 函数接收一个链表的头结点指针,删除所有多余的结点,并确保每个节点的值是唯一的
【示意图】
【示例代码】
// 删除表head中多余的重复结点 void PurgeLinklist(LinkList head) { Node *p, *q, *r; // 定义三个指向 Node 类型的指针,其中 p 为当前工作指针,q 为当前需要检查的指针,r 为需要删除的结点指针q = head->next; // 初始化为当前第一个结点:q指示当前检查结点的位置,置其初值指向首结点while (q != NULL) // 当前检查结点*q不是尾结点时,寻找并删除它的重复结点:当当前检查指针 q 不为空时,继续循环{p = q; // 工作指针*p指向当前检查指针*qwhile (p->next != NULL) // 当工作指针*p的后继结点存在时:将其数据域与*q数据域比较{ if (p->next->data == q->data) // 若工作指针的下一个指针*(p->next)的数值等于当前检查指针*p的数值:若*(p->next)是*q的重复结点{r = p->next; // 删除 r 指向待删节点p->next = r->next; // 移出结点* (p->next),p->next指向原来* (p->next)的后继结点free(r); // 释放待删节点的内存空间}else {p = p->next; // 否则,让工作指针*p指向下一个结点,继续检查}}q = q->next; // 更新检查结点:更新当前检查指针*p} }【代码详解】
- 这段代码是一个用于删除单链表中多余的重复结点的函数
- 其基本实现思路是,以单链表中每个节点为基准,循环遍历整个链表,将每个节点与它后面的所有节点数据进行比较,当遇到相同数据的节点时,删除后面的那个节点
- 函数接收一个链表的头结点指针,删除所有多余的结点,并确保每个节点的值是唯一的
1. 定义三个指向 Node 类型的指针
- 其中,p 为当前的工作指针,q 为当前需要检查的指针,r 为需要删除的结点指针
Node *p, *q, *r; // 定义三个指向 Node 类型的指针,其中 p 为当前工作指针,q 为当前需要检查的指针,r 为需要删除的结点指针2. 初始化检查指针
- 将应检查的指针 q 置为当前待检查的第一个普通结点
q = head->next; // 初始化为当前第一个结点3. 外层循环
- 进入外层 while 循环,当当前检查指针 q 不为空时,继续循环,直到检查完整个链表
while (q != NULL) // 当当前检查指针 q 不为空时,继续循环4. 内层循环
- 进入内层 while 循环,当工作指针的后继结点存在时,将其数据域与当前待检查指针 q 的数据域比较。若 p 的后继结点是 q 的重复结点,就将 r 指向待删结点, 移出结点 (p->next),然后释放待删结点的内存空间。否则,让 p 指向下一个结点
while (p->next != NULL) // 当工作指针的后继结点存在时5. 更新待检查指针
- 更新当前需要检查的指针 q
q = q->next; // 更新当前检查指针 q6. 物理释放内存空间
- 在删除多余结点后,当程序已经不需要这些内存空间时,需要及时将这些空间释放,以免造成内存泄漏
free(r); // 释放待删节点的内存空间【注意】
- 本函数建议使用标准库提供的容器和算法来实现

五、其它链表
(1)循环链表
【说明】
- 普通链表的终端结点的 next 值为 NULL
- 循环链表的终端结点的 next 指向 头结点
- 在循环链表中,从任一结点出发能够扫描整个链表
【示意图】
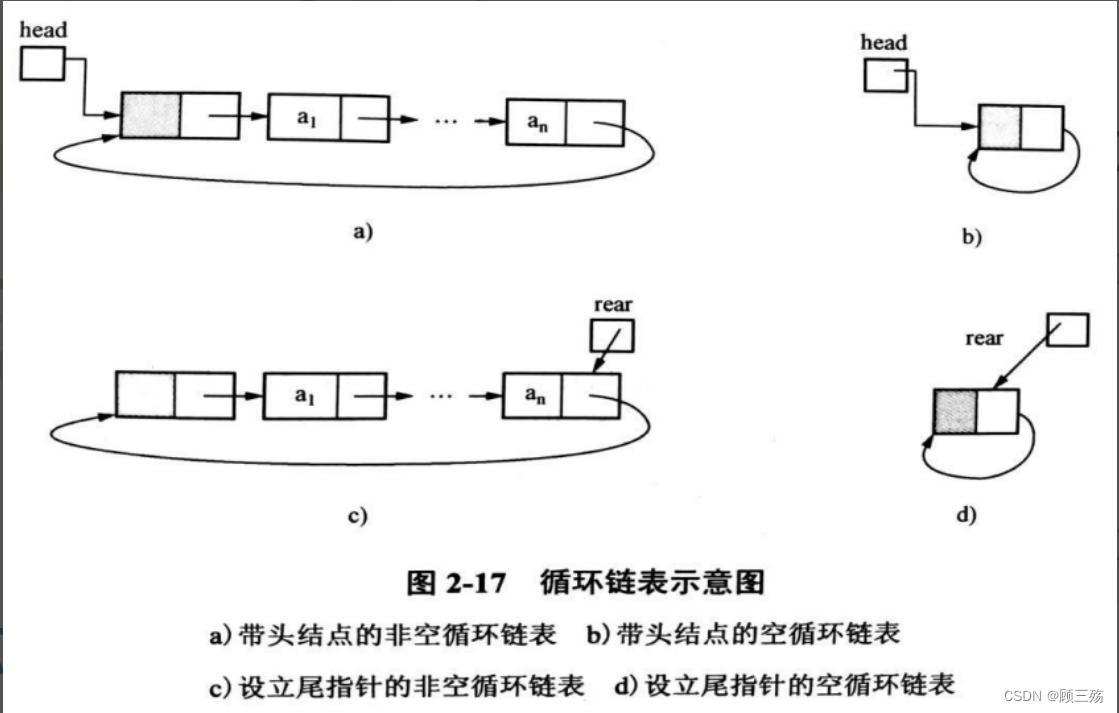
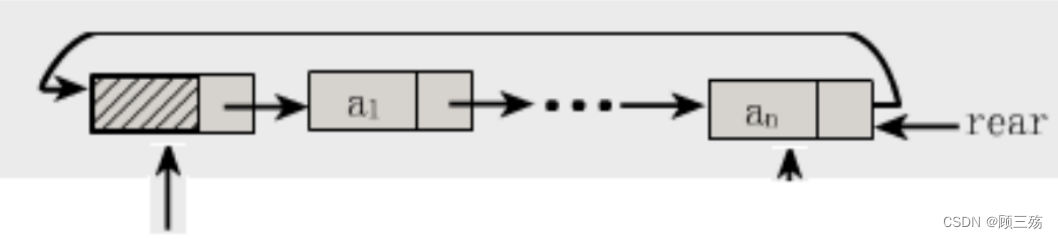
找到 普通链表 / 循环链表 的 尾结点 的办法:
- 在循环链表中附设一个 rear 指针指向尾结点适用于经常适用头尾结点的链表操作中
(2)双向循环链表
① 双向循环链表
【说明】 在链表中设置两个指针域:
- 一个指向后继结点
- 一个指向前驱结点
- 这样的链表叫做双向链表
【示意图】

② 双向链表的结构体定义
【定义】双向链表的结构体定义:
struct dbnode // 定义一个双向链表的结点结构体 { DataType data; // 数据域struct dbnode *prior, *next; // 双向指针域 }; typedef struct dbnode *dbpointer; // 定义一个指向 dbnode 的指针类型 dbpointer typedef dbpointer Dlinklist; // 定义一个指向 dbnode 的指针类型 Dlinklist
- 这段代码中,定义了一个结构体 dbnode,表示一个双向链表的结点。它包含了数据域 data 和两个指针域 prior 和 next。prior 指向当前节点的前驱结点,next 指向当前节点的后继结点。
- 其次,定义一个指向 dbnode 结构体的指针类型 dbpointer,用来指向 dbnode 结构体类型的变量。
- 最后,用 typedef 将 dbpointer 重新命名为 Dlinklist,表示 Dlinklist 是指向 dbnode 的指针类型。
【结点】双向链表的结点:
- 双向循环链表适合应用在需要经常查找结点的前驱和后继的场合
- 找前驱和后继的复杂度均为:O(1)
【示例】 假设双向链表中 p 指向某节点
- 则有 p->prior->next 与 p->next->prior 相等

③ 双向链表中结点的插入
【说明】在 p 所指结点的后面插入一个新结点 *t,需要修改 4 个指针:
- t->prior = p;
- t->next = p->next;
- p->next->prior = t;
【示意图】

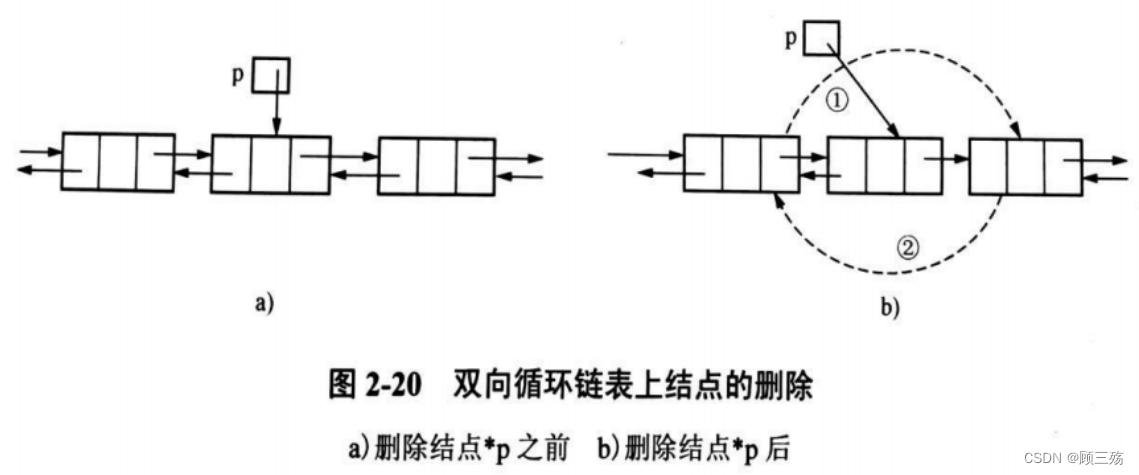
④ 双向链表中结点的删除
【说明】设 p 指向待删结点,删除 *p 可通过下述语句完成:
- p->next->prior = p->prior; // p 后继结点的前链指向 p 的前驱结点
- free(p); // 释放 *p 的空间
【示意图】
六、顺序实现与连接实现的比较
(1)线性表与链表的优缺点
- 单链表的每个结点包括数据域与指针域,指针域需要占用额外空间
- 从整体考虑,顺序表要预分配存储空间,如果预先分配得过大,将造成浪费,若分配得过小,又将发生上溢;单链表不需要预先分配空间,只要内存空间没有耗尽,单链表中的结点个数就没有限制
(2)时间性能的比较
| 顺序表 | 链表 | ||
| 读表元 | O(1) | 读表元 | O(n) |
| 定位(找x) | O(n) | 定位(找x) | O(n) |
| 插入 | O(n) | 插入 | O(n) |
| 删除 | O(n) | 删除 | O(n) |