RCNN系列、Fast-RCNN、Faster-RCNN、R-FCN检测模型对比
一.RCNN
问题一:速度
经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断。
问题二:训练集
经典的目标检测算法在区域中提取人工设定的特征(Haar,HOG)。本文则需要训练深度网络进行特征提取。可供使用的有两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
保证合并后形状规则。

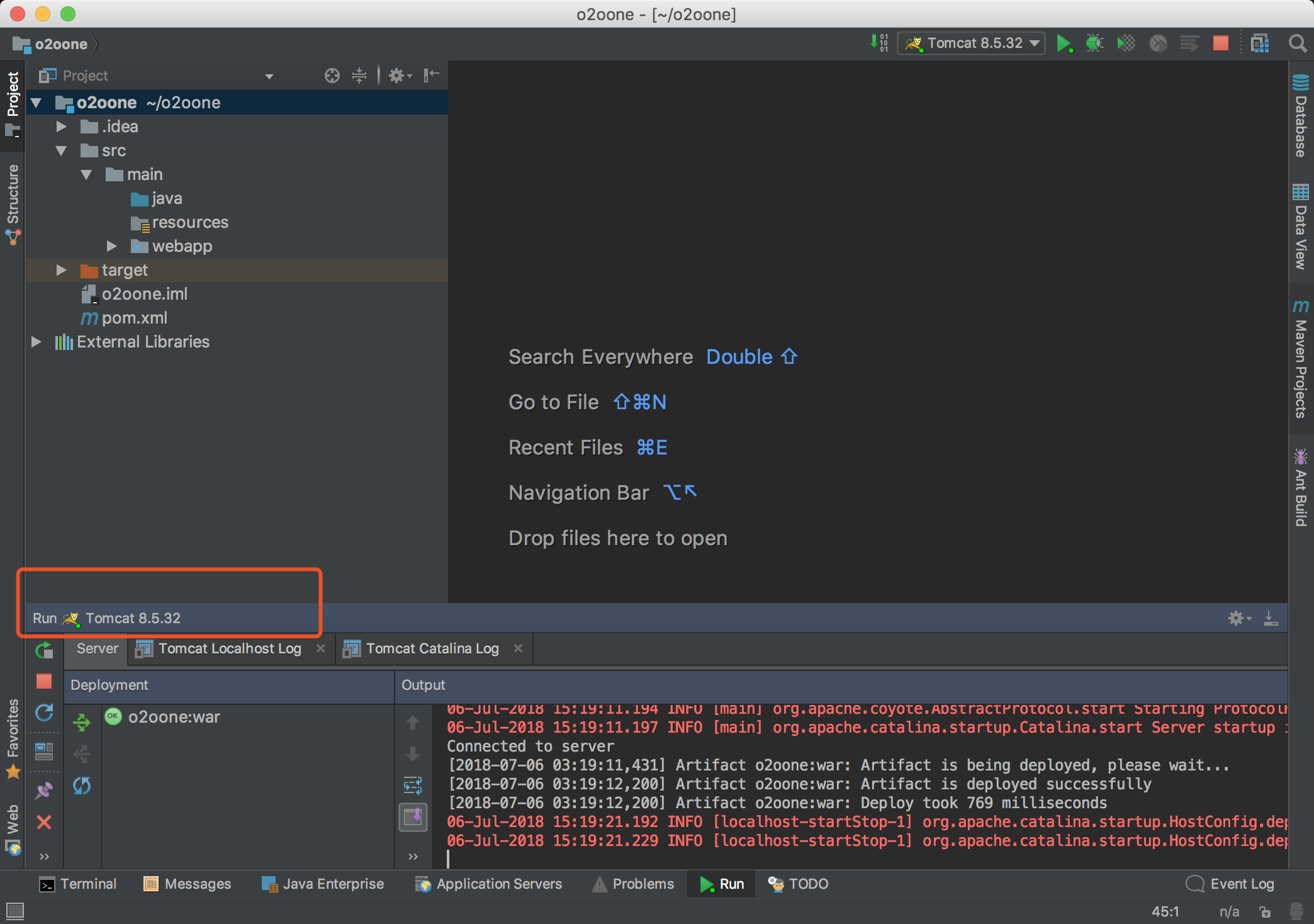
网络分为四个部分:区域划分、特征提取、区域分类、边框回归
区域划分:使用selective
search算法画出2k个左右候选框,送入CNN
特征提取:使用imagenet上训练好的模型,进行finetune
区域分类:从头训练一个SVM分类器,对CNN出来的特征向量进行分类
边框回归:使用线性回归,对边框坐标进行精修
优点:
ss算法比滑窗得到候选框高效一些;使用了神经网络的结构,准确率比传统检测提高了
缺点:
1、ss算法太耗时,每张图片都分成2k,并全部送入CNN,计算量很大,训练和inference时间长
2、四个模块基本是单独训练的,CNN使用预训练模型finetune、SVM重头训练、边框回归重头训练。微调困难,可能有些有利于边框回归的特征并没有被CNN保留
二.Fast-RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
相对RCNN,准确率和速度都提高了,具体做了以下改进:
1、依旧使用了selective search算法对原始图片进行候选区域划分,但送入CNN的是整张原始图片,相当于对一张图片只做一次特征提取,计算量明显降低
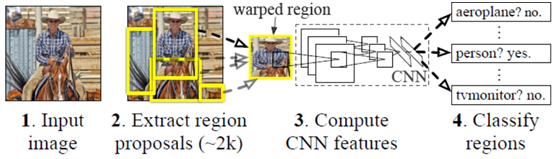
2、在原图上selective search算法画出的候选区域对应到CNN后面输出的feature map上,得到2k个左右的大小长宽比不一的候选区域,然后使用RoI pooling将这些候选区域resize到统一尺寸,继续后续的运算
3、将边框回归融入到卷积网络中,相当于CNN网络出来后,接上两个并行的全连接网络,一个用于分类,一个用于边框回归,变成多任务卷积网络训练。这一改进,相当于除了selective search外,剩余的属于端到端,网络一起训练可以更好的使对于分类和回归有利的特征被保留下来
4、分类器从SVM改为softmax,回归使用平滑L1损失。
缺点:因为有selective search,所以还是太慢了,一张图片inference需要3s左右,其中2s多耗费在ss上,且整个网络不是端到端。


三.Faster-RCNN
从RCNN到fast RCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成,特征提取,分类,位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
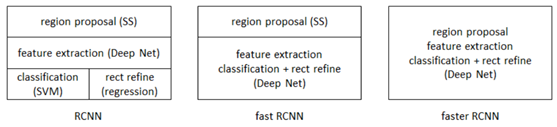
引入RPN,Faster-RCNN相当于Fast-RCNN+RPN,准确率和速度进一步提高,主要做了以下改进:
1、移除selective search算法,还是整张原始图片输入CNN进行特征提取,在CNN后面的卷积不再使用ss算法映射过来的候选区域,而是采用新的网络RPN,使用神经网络自动进行候选区域划分。
2、RPN通过生成锚点,以每个锚点为中心,画出9个不同长宽比的框,作为候选区域,然后对这些候选区域进行初步判断和筛选,看里面是否包含物体(与groundtruth对比IoU,大于0.7的为前景,小于0.3的为背景,中间的丢弃),若没有就删除,减少了不必要的计算。
3、有效的候选区域(置信度排序后选取大概前300个左右)进行RoI pooling后送入分类和边框回归网络。
优点:端到端网络,整体进行优化训练;使用神经网络自动生成的候选区域对结果更有利,比ss算法好;过滤了一些无效候选区,较少了冗余计算,提升了速度。
RPN训练:
1、加载预训练模型,训练RPN。
2、训练fast-rcnn,使用的候选区域是RPN的输出结果,然后进行后续的bb的回归和分类。
3、再训练RPN,但固定网络公共的参数,只更新RPN自己的参数。
4、根据RPN,对fast-rcnn进行微调训练。

四.R-FCN
一个base的conv网络如ResNet101, 一个RPN(Faster
RCNN来的),一个position sensitive的prediction层,最后的ROI pooling+投票的决策层。
分类需要特征具有平移不变性,检测则要求对目标的平移做出准确响应。现在的大部分CNN在分类上可以做的很好,但用在检测上效果不佳。SPP,Faster R-CNN类的方法在ROI pooling前都是卷积,是具备平移不变性的,但一旦插入ROI pooling之后,后面的网络结构就不再具备平移不变性了。因此,本文想提出来的position sensitive score map这个概念是能把目标的位置信息融合进ROI pooling。
对于region-based的检测方法,以Faster
R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast
RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI
pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。
在Faster-RCNN基础上,进一步提高了准确率,主要以下改进:
1、使用全卷积层代替CNN basenet里面的全连接层。
2、CNN得到的feature map在RoI pooling之后变成3x3大小,把groundtruth也变成3x3大小,对9宫格每个区域分别比较和投票。