目录
- 安装库
- xpath入门
- 怎么快速得到xpath路径
- xpath节点的关系
- xpath方法
- 小型实战
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
安装库
pip install lxml
xpath入门
怎么快速得到xpath路径
(相对路径)复制xpath->//*[@id="1"]/div/div[1]/h3/a[1]
(从根节点开始的绝对路径)复制完整的xpath->/html/body/div[2]/div[5]/div[1]/div[3]/div[1]/div/div[1]/h3/a[1]
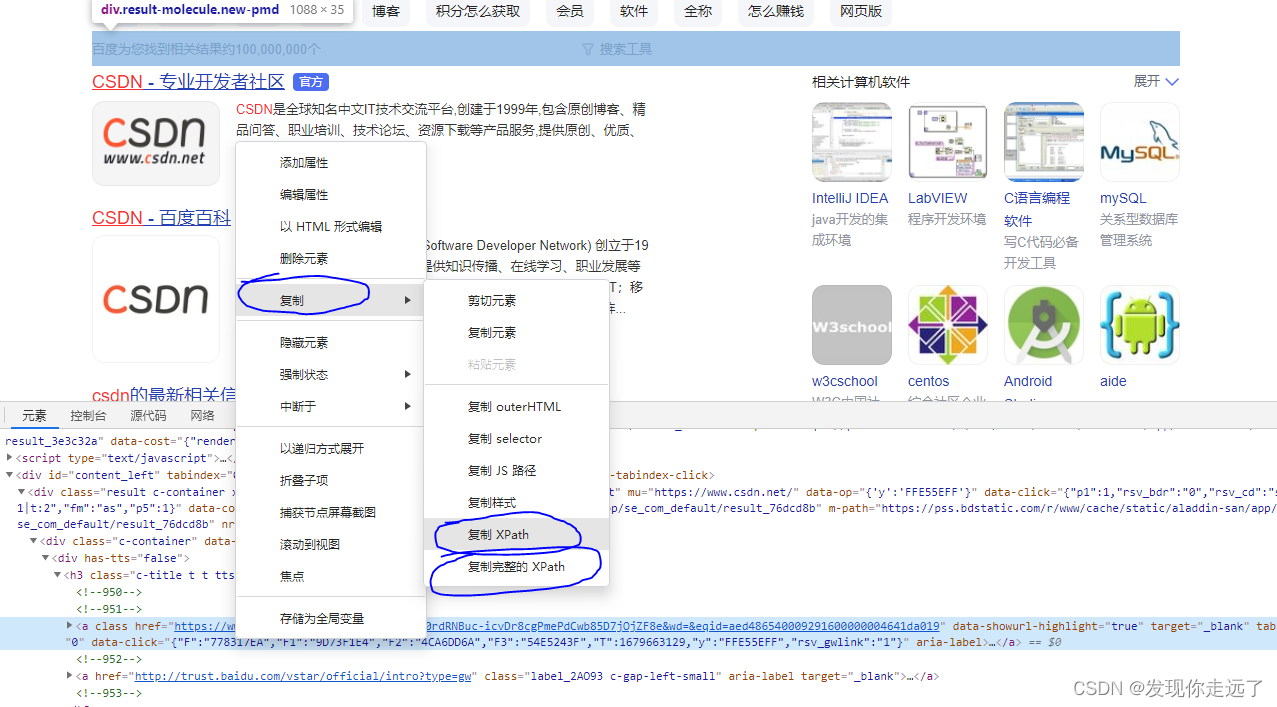
xpath节点的关系
<book><id>1</id><name>野花遍地香</name><price>1.23</price><author><nick>周大强</nick><nick>周芷若</nick></author>
</book>
在上述html代码中
- book, id, name, price…都被称为节点.
- Id, name, price, author被称为book的⼦节点
- book被称为id, name, price, author的⽗节点
- id, name, price,author被称为同胞节点
xpath方法
from lxml import etreexml = """
<book><id>1</id><name>野花遍地香</name><price>1.23</price><nick>臭豆腐</nick><author><nick id="10086">周大强</nick><nick id="10010">周芷若</nick><nick class="joy">周杰伦</nick><nick class="jolin">蔡依林</nick><div><nick>热热热热热1</nick></div><span><nick>热热热热热2</nick></span></author><partner><nick id="ppc">胖胖陈</nick><nick id="ppbc">胖胖不陈</nick></partner>
</book>
"""tree = etree.XML(xml)
# result = tree.xpath("/book") # /表示层级关系. 第一个/是根节点
# result = tree.xpath("/book/name")
# result = tree.xpath("/book/name/text()") # text() 拿文本
result = tree.xpath("/book/author//nick/text()") # // 所有的后代,无论是第几代后代
print(result)
result = tree.xpath("/book/author/*/nick/text()") # * 任意的节点. 通配符 这里区别与上一处是要求得到的是子代的子代
print(result)
result = tree.xpath("/book//nick/text()")
print(result)
小型实战
-
tree = etree.XML(xml)#如果是xml格式
-
tree = etree.parse(“b.html”)#如果是html格式,b.html的内容就是上面的xml的内容
-
xpath的顺序是从1开始数的, []表示索引
-
[@xxx=xxx] 属性的筛选
-
相对查找时在
./后面加上后续的路径
from lxml import etree
xml = """
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><title>Title</title></head><body><ul><li><a href="http://www.baidu.com">百度</a></li><li><a href="http://www.google.com">谷歌</a></li><li><a href="http://www.sogou.com">搜狗</a></li></ul><ol><li><a href="feiji">飞机</a></li><li><a href="dapao">大炮</a></li><li><a href="huoche">火车</a></li></ol><div class="job">李嘉诚</div><div class="common">胡辣汤</div></body>
</html>
"""tree = etree.XML(xml)#如果是xml格式
# tree = etree.parse("b.html")#如果是html格式,b.html的内容就是上面的xml的内容result = tree.xpath('/html')
result = tree.xpath("/html/body/ul/li/a/text()")
result = tree.xpath("/html/body/ul/li[1]/a/text()") # xpath的顺序是从1开始数的, []表示索引result = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") # [@xxx=xxx] 属性的筛选print(result)ol_li_list = tree.xpath("/html/body/ol/li")for li in ol_li_list:# 从每一个li中提取到文字信息result = li.xpath("./a/text()") # 在li中继续去寻找. 相对查找print(result)result2 = li.xpath("./a/@href") # 拿到属性值: @属性print(result2)print(tree.xpath("/html/body/ul/li/a/@href"))print(tree.xpath('/html/body/div[1]/text()'))
print(tree.xpath('/html/body/ol/li/a/text()'))

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』