CUDA 11功能清单
基于NVIDIA Ampere GPU架构的新型NVIDIA A100 GPU在加速计算方面实现了最大的飞跃。A100 GPU具有革命性的硬件功能,CUDA 11与A100一起发布。

CUDA 11能够利用新的硬件功能来加速HPC,基因组学,5G,渲染,深度学习,数据分析,数据科学,机器人技术以及更多不同的工作负载。
CUDA 11包含了所有功能-从平台系统软件到入门和开发GPU加速的应用程序所需的一切。本文概述了此版本中的主要软件功能:
• 支持NVIDIA Ampere GPU架构,包括新的NVIDIA A100 GPU,用于加速扩展和扩展AI和HPC数据中心;具有NVSwitch结构的多GPU系统,例如DGX A100和HGX A100。
• 多实例GPU(MIG)分区功能特别有利于云服务提供商(CSP)改善GPU利用率。
• 新的第三代Tensor内核可加快对不同数据类型(包括TF32和Bfloat16)的混合精度矩阵操作。
• 任务图,异步数据移动,细粒度同步和L2缓存驻留控制的编程和API。
• CUDA库中针对线性代数,FFT和矩阵乘法的性能优化。
• Nsight产品工具系列的更新,用于跟踪,分析和调试CUDA应用程序。
• 全面支持所有主要的CPU体系结构,包括x86_64,Arm64服务器和POWER体系结构。
本文不能完全代表CUDA 11中可用的所有功能。在本文的末尾,有指向GTC Digital会议的链接,这些链接提供了对CUDA新功能的更深入研究。
CUDA和NVIDIA Ampere微架构GPU
NVIDIA Ampere GPU微架构采用台积电7nm N7制造工艺制造,包括更多的流多处理器(SM),更大,更快的内存,以及与第三代NVLink互连的带宽,以提供巨大的计算吞吐量。
A100的40 GB(5站点)高速HBM2内存的带宽为1.6 TB /秒,比V100快1.7倍以上。A100上的40 MB L2缓存几乎是Tesla V100的7倍,并提供了2倍的L2缓存读取带宽。CUDA 11在A100上提供了新的专用L2缓存管理和驻留控制API。A100中的SM包含更大,更快的L1高速缓存和共享内存单元(每个SM 192 KB)的组合,提供的容量是Volta V100 GPU的1.5倍。
A100配备了专用的硬件单元,包括第三代Tensor内核,更多的视频解码器(NVDEC)单元,JPEG解码器和光流加速器。所有这些都由各种CUDA库使用,以加速HPC和AI应用程序。
接下来将讨论NVIDIA A100中引入的主要创新,以及CUDA 11如何充分利用这些功能。无论是管理集群的平台DevOps工程师,还是编写GPU加速应用程序的软件开发人员,CUDA 11都能为每个人提供一些功能。有关NVIDIA Ampere GPU微体系结构的更多信息,请参阅深度NVIDIA Ampere Architecture。
多实例GPU
MIG功能可以将单个A100 GPU物理上划分为多个GPU。使多个客户端(例如VM,容器或进程)能够同时运行,同时在这些程序之间提供错误隔离和高级服务质量(QoS)。

Figure 1. New MIG feature in A100.
A100 is the first GPU that can either scale up to a full GPU with NVLink or scale out with MIG for many users by lowering the per-GPU instance cost. MIG enables several use cases to improve GPU utilization. This could be for CSPs to rent separate GPU instances, running multiple inference workloads on the GPU, hosting multiple Jupyter notebook sessions for model exploration, or resource sharing of the GPU among multiple internal users in an organization (single-tenant, multi-user).
MIG is transparent to CUDA and existing CUDA programs can run under MIG unchanged to minimize programming effort. CUDA 11 enables configuration and management of MIG instances on Linux operating systems using the NVIDIA Management Library (NVML) or its command-line interface nvidia-smi (nvidia-smi mig subcommands).
Using the NVIDIA Container Toolkit and A100 with MIG enabled, you can also run GPU containers with Docker (using the --gpus option starting with Docker 19.03) or scale out with the Kubernetes container platform using the NVIDIA device plugin.
The following command shows MIG management using nvidia-smi:
A100是第一款可以通过NVLink扩展到完整GPU或通过MIG扩展许多用户的GPU,降低了每个GPU实例的成本。MIG支持多种用例,以提高GPU利用率。这可能是CSP可以租用单独的GPU实例,在GPU上运行多个推理工作负载,托管多个Jupyter笔记notebook会话以进行模型探索,或者在组织中的多个内部用户(单租户,多用户)之间共享GPU的资源。 。
MIG对CUDA是透明的,并且现有的CUDA程序可以在MIG下运行,而无需更改,以最大程度地减少编程工作。CUDA 11使用NVIDIA管理库(NVML)或其命令行界面nvidia-smi(nvidia-smimig子命令)在Linux操作系统上配置和管理MIG实例。
使用启用了MIG的NVIDIA Container Toolkit和A100,可以在Docker上运行GPU容器(使用–gpus从Docker 19.03开始的选项),或者使用NVIDIA设备插件通过Kubernetes容器平台进行横向扩展。
以下命令显示使用以下命令进行MIG管理nvidia-smi:
List gpu instance profiles:
nvidia-smi mig -i 0 –lgip
系统软件平台支持
为了在企业数据中心中使用,NVIDIA A100引入了新的内存错误恢复功能,这些功能可以提高弹性并避免影响正在运行的CUDA应用程序。先前架构上无法纠正的ECC错误会影响GPU上所有正在运行的工作负载,从而需要重置GPU。
在A100上,影响仅限于遇到错误并已终止的应用程序,而其它正在运行的CUDA工作负载则不受影响。GPU不再需要重置即可恢复。NVIDIA驱动程序执行动态页面黑名单,以将页面标记为不可用,以便当前和新应用程序都不会访问受影响的内存区域。
重置GPU后,作为常规GPU / VM服务窗口的一部分,A100配备了一种称为行重新映射的新硬件机制,该机制用备用单元替换内存中退化的单元,并避免在物理内存地址空间中造成任何漏洞。
带有CUDA 11的NVIDIA驱动程序现在报告与带内(使用NVML / nvidia-smi)和带外(使用系统BMC)行重新映射有关的各种度量。A100包括新的带外功能,包括更多可用的GPU和NVSwitch遥测,控制以及改进的GPU和BMC之间的总线传输数据速率。
为了提高DGX A100和HGX A100等多GPU系统的弹性和高可用性,该系统软件支持禁用发生故障的GPU或NVSwitch节点的能力,而不是像上一代系统那样禁用整个baseboard。
CUDA 11是第一个添加对Arm服务器的生产支持的版本。通过将Arm的高能效CPU架构与CUDA相结合,Arm生态系统将从GPU加速的计算中受益,适用于各种用例:从边缘,云和游戏到为超级计算机提供动力。CUDA 11支持Marvell的高性能基于ThunderX2的服务器,并与Arm和生态系统中的其他硬件和软件合作伙伴紧密合作,以快速实现对GPU的支持。
第三代多精度Tensor核心
NVIDIA A100中每个SM的四个大型Tensor核心(总共432个Tensor核心)为所有数据类型提供了更快的矩阵乘法累加(MMA)操作:Binary,INT4,INT8,FP16,Bfloat16,TF32和FP64。
可以通过不同的深度学习框架,CUTLASS提供的CUDA C ++模板抽象或CUDA库(例如cuBLAS,cuSOLVER,cuTENSOR或TensorRT)访问Tensor Core 。
CUDA C ++使用warp级矩阵(WMMA)API使Tensor Core可用。这种可移植的API抽象提供了专门的矩阵加载,矩阵乘法和累加以及矩阵存储操作,以有效地使用CUDA C ++程序中的Tensor Core。nvcuda::wmma名称空间中提供了WMMA的所有功能和数据类型。可以使用mma_syncPTX指令直接访问Tensor Cores for A100(即具有计算能力compute_80及更高版本的设备)。
CUDA 11增加了对新输入数据类型格式的支持:Bfloat16,TF32和FP64。Bfloat16是另一种FP16格式,但与FP32数值范围匹配的精度降低。使用导致较低的带宽和存储要求,从而提高吞吐量。Bfloat16__nv_bfloat16通过WMMA在cuda_bf16.h中作为新的CUDA C ++数据类型公开,并受各种CUDA数学库支持。
TF32是一种特殊的浮点格式,旨在与Tensor Core一起使用。TF32包含一个8位指数(与FP32相同),10位尾数(与FP16相同的精度)和一个符号位。这是默认的数学模式,可在进行DL训练时获得FP32之上的加速,而无需对模型进行任何更改。最后,A100为MMA操作带来了双精度(FP64)支持,WMMA接口也支持该功能。

Figure 2. Table of supported data types, configurations, and performance for matrix operations.
编程NVIDIA Ampere架构GPU
为了改善GPU的可编程性并利用NVIDIA A100 GPU的硬件计算功能,CUDA 11包括用于内存管理,任务图加速,新指令和线程通信构造的新API操作。这里介绍了其中的一些新操作以及如何能够利用A100和NVIDIA Ampere微体系结构。
内存管理
最大化GPU内核性能的优化策略之一是最小化数据传输。如果内存驻留在全局内存中,则将数据读取到L2高速缓存或共享内存中的等待时间可能需要数百个处理器周期。
例如,在GV100上,共享内存提供的带宽比全局内存快17倍,比L2快3倍。因此,某些具有生产者-消费者范例的算法可能会观察到在内核之间将数据,持久存储在L2中时的性能优势,从而获得更高的带宽和性能。
在A100上,CUDA 11提供API操作以预留一部分40 MB的L2缓存,持久保存对全局内存的数据访问。持久性访问优先使用了L2缓存的此预留部分,而对全局存储器的常规访问或流式访问,仅在L2的这一部分通过持久访问而未使用时才可以使用。
可以将L2持久性设置为在CUDA流或CUDA图形内核节点中使用。当预留L2缓存区域时,需要考虑一些注意事项。例如,在具有不同访问策略窗口的同时,在不同流中同时执行的多个CUDA内核共享L2预留缓存。下面的代码示例显示为持久性预留L2缓存比率。
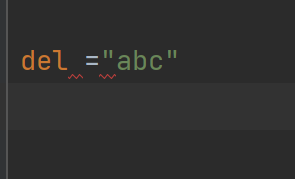
cudaGetDeviceProperties( &prop, device_id);
// Set aside 50% of L2 cache for persisting accesses
size_t size = min( int(prop.l2CacheSize * 0.50) , prop.persistingL2CacheMaxSize );
cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size);
// Stream level attributes data structure
cudaStreamAttrValue attr ;
attr.accessPolicyWindow.base_ptr = /* beginning of range in global memory */ ;
attr.accessPolicyWindow.num_bytes = /* number of bytes in range */ ;
// hitRatio causes the hardware to select the memory window to designate as persistent in the area set-aside in L2
attr.accessPolicyWindow.hitRatio = /* Hint for cache hit ratio */
// Type of access property on cache hit
attr.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;
// Type of access property on cache miss
attr.accessPolicyWindow.missProp = cudaAccessPropertyStreaming;
cudaStreamSetAttribute(stream,cudaStreamAttributeAccessPolicyWindow,&attr);
将虚拟内存管理API业务已经扩展到支持固定GPU内存压缩到L2减少DRAM带宽。这对于深度学习训练和推理用例可能很重要。使用创建共享内存句柄cuMemCreate时,会向API操作提供分配提示。
算法(例如3D模板或卷积)的有效实现涉及内存复制和计算控制流模式,其中数据从全局内存传输到线程块的共享内存中,然后使用该共享内存进行计算。全局到共享内存的副本被扩展为从全局内存到寄存器的读取,然后是对共享内存的写操作。
CUDA 11可以利用新的异步副本(async-copy)范例。实际上与通过计算将数据从全局复制到共享内存重叠,并且避免了使用中间寄存器或L1高速缓存。异步复制有很多好处:控制流不再遍历内存管道两次,并且不使用中间寄存器可以减少寄存器压力,从而增加内核占用率。在A100上,异步复制操作是硬件加速的。
以下代码示例显示了使用异步复制的简单示例。生成的代码虽然性能更高,但是可以通过流水线处理多批异步复制操作来进一步优化。这种额外的流水线操作可以消除代码中的同步点之一。
异步复制作为CUDA 11中的一项实验功能提供,并使用协作组集合公开。在CUDA C ++编程指南包括使用异步拷贝用多级流水线和在A100硬件加速屏障操作的更先进的实施例。
//Without async-copy
using namespace nvcuda::experimental;
shared extern int smem[];
// algorithm loop iteration
while ( … ) {
__syncthreads();
// load element into shared mem
for ( i = … ) {
// uses intermediate register
// {int tmp=g[i]; smem[i]=tmp;}
smem[i] = gldata[i];
}
//With async-copy
using namespace nvcuda::experimental;
shared extern int smem[];
pipeline pipe;
// algorithm loop iteration
while ( … ) {
__syncthreads();
// load element into shared mem
for ( i = … ) {
// initiate async memory copy
memcpy_async(smem[i],
gldata[i],
pipe);
}
// wait for async-copy to complete
pipe.commit_and_wait();
__syncthreads();
/* compute on smem[] */
}
任务图加速
CUDA 10中引入的CUDA图形代表了一种使用CUDA提交工作的新模型。图由一系列操作组成,例如内存副本和内核启动,通过依赖关系进行连接并与其执行分开定义。
图启用了一次定义一次运行重复执行流程。可以减少累积的启动开销并提高应用程序的整体性能。对于深度学习应用程序尤其如此,因为深度学习应用程序可能会启动多个具有减小的任务大小和运行时间的内核,或者可能具有任务之间的复杂依赖性。
从A100开始,GPU提供了任务图硬件加速功能,以预取网格启动描述符,指令和常量。与以前的GPU(例如V100)相比,可以在A100上使用CUDA图形来改善内核启动延迟。
CUDA Graph API操作现在具有轻量级机制,可以支持对实例化图进行就地更新,而无需重建图。在图的重复实例化期间,节点参数(例如内核参数)通常会发生变化,而图拓扑保持不变。图形API操作提供了一种用于更新整个图形的机制,其中可以为拓扑相同的cudaGraph_t对象提供更新的节点参数,或者为各个节点进行显式更新。
此外,CUDA图现在支持协作内核启动(cuLaunchCooperativeKernel),包括与CUDA流奇偶校验的流捕获。
线程集合
以下是CUDA 9中引入的CUDA 11对协作组的增强。协作组是一种集体编程模式,旨在能够明确表示线程可以进行通信的粒度。这将在CUDA中启用协作并行性的新模式。
在CUDA 11中,合作组集体展示了新的A100硬件功能,并添加了一些API增强功能。有关更改的完整列表的更多信息,请参见《CUDA C ++编程指南》。
A100引入了一条新的reduce指令,该指令对每个线程提供的数据进行操作。这是使用协作组的新集合,提供了可移植的抽象,也可以在较旧的体系结构上使用。reduce操作支持算术(例如加)和逻辑(例如AND)操作。以下代码示例显示了reduce集合。
// Simple Reduction Sum
#include <cooperative_groups/reduce.h>
…
const int threadId = cta.thread_rank();
int val = A[threadId];
// reduce across tiled partition
reduceArr[threadId] = cg::reduce(tile, val, cg::plus());
// synchronize partition
cg::sync(cta);
// accumulate sum using a leader and return sum
合作组提供labeled_partition了将父组划分为一维子组(在其中合并线程)的集体操作()。这对于试图通过条件语句的基本块跟踪活动线程的控制流特别有用。
例如,可以使用labeled_partition原子添加操作并在其中使用一个warp级别组(不限于2的幂)来形成多个分区。labeled_partitionAPI操作评估条件,标签,并分配具有用于标签到同一组的值相同的线程。
以下代码示例显示了自定义线程分区:
// Get current active threads (that is, coalesced_threads())
cg::coalesced_group active = cg::coalesced_threads();
// Match threads with the same label using match_any()
int bucket = active.match_any(value);
cg::coalesced_group subgroup = cg::labeled_partition(active, bucket);
// Choose a leader for each partition (for example, thread_rank = 0)
//
if (subgroup.thread_rank() == 0) {
threadId = atomicAdd(&addr[bucket], subgroup.size());
}
// Now use shfl to transfer the result back to all threads in partition
return (subgroup.shfl(threadId, 0));
CUDA C ++语言和编译器改进
CUDA 11还是第一个正式将CUB纳入CUDA Toolkit的版本。CUB是受支持的CUDA C ++核心库之一。
nvcc for CUDA 11的主要功能之一是对链接时间优化(LTO)的支持,以提高单独编译的性能。LTO使用–dlink-time-opt或-dlto选项在编译期间存储中间代码,然后在链接时执行更高级别的优化,例如跨文件内联代码。
CUDA 11中的nvcc增加了对ISO C ++ 17的支持,并支持了跨PGI,gcc,clang,Arm和Microsoft Visual Studio的新主机编译器。如果要试验尚不支持的主机编译器,则nvcc–allow-unsupported-compiler在编译构建工作流程中会支持一个新标志。nvcc添加了其他新功能,其中包括:
• 改进的lambda支持
• 依赖文件生成增强(-MD,-MMD选项)
• 传递给主机编译器的选项

Figure 4. Platform support in CUDA 11.
CUDA库
CUDA 11中的库通过在线性代数,信号处理,基本数学运算和图像处理中使用最新最先进的A100硬件功能超越熟悉的嵌入式API,从而不断突破性能和开发人员生产力的界限。
在线性代数库中,将看到Tensor Core加速度,了解A100上所有可用的精度,包括FP16,Bfloat16,TF32和FP64。这包括cuBLAS中的BLAS3操作,cuSOLVER中的分解和密集线性求解器,以及cuTENSOR中的张量收缩。
除了提高精度范围外,还消除了对矩阵尺寸和Tensor Core加速度对齐的限制。为了获得适当的精度,加速度现在是自动的,不需要用户选择。当在A100上带有MIG的GPU实例上运行时,cuBLAS的启发式方法会自动适应资源。

Figure 6. Mixed-precision matrix multiply on A100 with cuBLAS.
CUTLASS是高性能GEMM的CUDA C ++模板抽象,支持A100提供的所有各种精度模式。借助CUDA 11,CUTLASS现在与cuBLAS达到了95%以上的性能均等性。可以编写自己的自定义CUDA内核,以便在NVIDIA GPU中对Tensor Core进行编程。
cuFFT利用了A100中较大的共享内存大小,从而在批量较大时为单精度FFT提供了更好的性能。最后,在多GPU A100系统上,与V100相比,cuFFT可以扩展并提供每个GPU 2倍的性能。
nvJPEG是用于JPEG解码的GPU加速库。结合数据增强和图像加载库NVIDIA DALI,可以加速对图像分类模型(尤其是计算机视觉)的深度学习训练。这些库加快了深度学习工作流程的图像解码和数据增强阶段。
A100包含5核硬件JPEG解码引擎,nvJPEG利用硬件后端对JPEG图像进行批处理。专用硬件模块进行JPEG加速可缓解CPU瓶颈,并提高GPU利用率。
nvjpegDecode对于给定的图像,硬件自动选择硬件解码器,或者使用nvjpegCreateExinit函数明确选择硬件后端。nvJPEG提供基线JPEG解码和各种颜色转换格式(例如YUV 420、422和444)的加速。
图8显示,与仅使用CPU的处理相比,这将使图像解码速度提高18倍。如果使用DALI,则可以直接从此硬件加速中受益,因为nvJPEG是抽象的。

Figure 9. nvJPEG Speedup vs. CPU.
(Batch 128 with Intel Platinum 8168 @2GHz 3.7GHz Turbo HT on; with TurboJPEG)
CUDA数学库中的功能比单个帖子中涵盖的功能还要多。
开发工具
CUDA 11继续在现有的开发人员工具组合中添加丰富的功能。包括用于Visual Studio的熟悉的插件,以及用于Visual Studio的NVIDIA Nsight集成,以及具有Nsight Eclipse插件版的Eclipse。它还包括独立的工具,例如用于内核概要分析的Nsight Compute和用于系统范围的性能分析的Nsight系统。CUDA支持的所有三种CPU体系结构现在都支持Nsight Compute和Nsight系统:x86,POWER和Arm64。
One of the key features of Nsight Compute for CUDA 11 is the ability to generate the Roofline model of the application. A Roofline model is a visually intuitive method for you to understand kernel characteristics by combining floating-point performance, arithmetic intensity, and memory bandwidth into a two-dimensional plot.
Nsight Compute for CUDA 11的主要功能之一是能够生成应用程序的Roofline模型。Roofline模型是一种视觉直观的方法,通过将浮点性能,算术强度和内存带宽组合成二维图,可以了解内核特性。
通过查看Roofline模型,可以快速确定内核是受计算限制还是受内存限制。还可以了解进一步优化的潜在方向,例如,靠近车顶线的内核可以最佳地利用计算资源。
有关更多信息,请参见Roofline性能模型。

Figure 11. A Roofline model in Nsight Compute.
CUDA 11包括Compute Sanitizer,这是下一代的功能正确性检查工具,可对越界内存访问和竞争条件提供运行时检查。Compute Sanitizer旨在替代该cuda-memcheck工具。
以下代码示例显示了Compute Sanitizer检查内存访问的示例。
//Out-of-bounds Array Access
global void oobAccess(int* in, int* out)
{
int bid = blockIdx.x;
int tid = threadIdx.x;
if (bid == 4)
{out[tid] = in[dMem[tid]];
}
}
int main()
{
…
// Array of 8 elements, where element 4 causes the OOB
std::array<int, Size> hMem = {0, 1, 2, 10, 4, 5, 6, 7};
cudaMemcpy(d_mem, hMem.data(), size, cudaMemcpyHostToDevice);
oobAccess<<<10, Size>>>(d_in, d_out);
cudaDeviceSynchronize();
...
$ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no basic
========= COMPUTE-SANITIZER
Device: Tesla T4
========= Invalid global read of size 4 bytes
========= at 0x480 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Memcheck/basic/basic.cu:40:oobAccess(int*,int*)
========= by thread (3,0,0) in block (4,0,0)
========= Address 0x7f551f200028 is out of bounds
以下代码示例显示了用于竞争条件检查的Compute Sanitizer示例。
//Contrived Race Condition Example
global void Basic()
{
shared volatile int i;
i = threadIdx.x;
}
int main()
{
Basic<<<1,2>>>();
cudaDeviceSynchronize();
…
$ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no --tool racecheck --racecheck-report hazard raceBasic
========= COMPUTE-SANITIZER
========= ERROR: Potential WAW hazard detected at shared 0x0 in block (0,0,0) :
========= Write Thread (0,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Write Thread (1,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Current Value : 0, Incoming Value : 1
========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings)
最后,即使CUDA 11不再支持在macOS上运行应用程序,仍将开发工具提供给macOS主机上的用户使用:
• 使用远程目标调试 cuda-gdb
• NVIDIA Visual Profiler
• Nsight Eclipse插件
• Nsight系列工具,用于远程分析或跟踪
Summary
CUDA 11提供了一个基础开发环境,用于为NVIDIA Ampere GPU架构和基于NVIDIA A100构建的强大服务器平台构建应用程序,以用于本地(DGX A100)和云(HGX A100)的AI,数据分析和HPC工作负载部署。

Figure 12. Different ways to get CUDA 11.
CUDA 11现在可用。与往常一样,可以通过多种方式获得CUDA 11:下载本地安装程序软件包,使用软件包管理器进行安装或从各个注册表中获取容器。对于企业部署,CUDA 11还包括使用模块化流的RHEL 8驱动程序包装改进,以提高稳定性并减少安装时间。