MindSpore循环神经网络
一. 神经网络的组成
神经元模型:首先简单的了解以下构成神经网络的最基础单元:神经元。每个神经元与其它神经元相连,处于激活状态时,就会向相连的神经元发送相应信号。从而改变其它神经元的状态。如果某个神经元的信号超过某个阈值。那么将被激活,再接着发送给其它神经元。如图1所示:
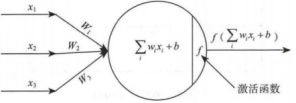
图1:神经元结构
神经网络的任何神经元都可以表述为上述的形式。该单元主要由输入变量、带权参数和激活函数组成。首先是x1,x2,x3带权重的输入变量,该变量的取值来自前面一层所有变量与权重的乘积,然后再求和,在数学上表示为下式:
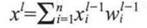
其中,x为自由的输入变量,xl为当前l层,这里的累加求和为前面一层所有变量与权重的乘积,n为神经元个数。在实践当中,神经网络的输入层由训练样本给定。隐含层和输出层的x取值由前一层计算得到。其中b为偏置参数。
激活函数:理想中的激活函数是如图2所示的跃迁函数,将输入值映射到O或1,很直观的1对应着神经元激活状态,0则表示神经元处于失活状态。然而由于跃迁函数不连续且非光滑(无法完美表达大脑神经网络的连续传递过程),实际常用Sigmoid函数作为激活函数。典型的Sigmoid函数如图3所示,把可能的数压缩进(0,1)输出值之间,又名挤压函数(squashing function)。
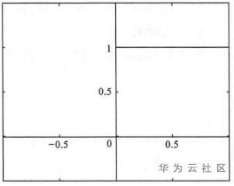
图2:跃迁函数图
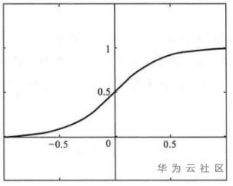
图3:sigmoid函数图
将许多这样的神经元按照一定的层次结构组织起来,就得到了人工神经网络。发现这个模型是由许多个函数不断嵌套而成。
感知机与多层网络:输入层接收外界的输入信号然后传递给输出层,输出层为逻辑单元,图4中的感知机有三个输入:x1、x2、x3。通常,可以根据数据的维度设置数量。这里是一种计算输出的规则,引入了权重(weight),w1,w2,…,wj等实数来表示各个输人对于输出的重要程度。
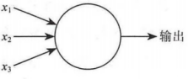
图4:多层感知机结构图
神经元的输出是0或者l,分别代表未激活与激活状态,由加权和的值是否小于或者大于某一个阈值(threshold value)决定。与权重一样,阈值也是一个实数,这是神经元的一个参数。使用更严密的代数形式来表示:
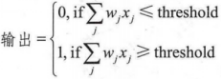
对于上面决策的式子,基本的思想就是:这是一个通过给每个维度数据赋予不同权重从而做出决策的机器,就可以判断出该事件可不可行。也需要通过调整权重和阈值的大小,得到不同的决策模型。
很显然,感知机不能完全模拟人类的决策系统。但是,一个由感知机构成的复杂网络能够做出更加精细的决策,可解释得通的。在图5所示这个网络中,第一层感知机,通过赋予输入的权重,做出三个非常简单的决策。第二层感知机呢?每一个第二层感知机通过赋予权重给来自第一层感知机的决策结果做出决策。通过这种方式,第二层感知机可以比第一层感知机做出更加复杂,更高层次抽象的决策。第三层感知机能够做出更加复杂的决策。通过这种方式,一个多层网络感知机可以做出更加精细的决策。
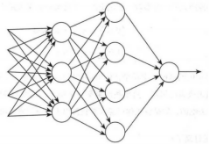
图5:多层感知机网络
图5网络最左边的是输入层神经元,用于接收外界输入信息,中间为隐藏层,对信号进行一定加工与转换,最右边为输出层神经元,最终结果由输出层神经元输出表示。因此,通常被称之为两层网络。一般情况下,只需要包含隐藏层,即可称为多层网络。神经网络的学习过程,就是根据训练数据来调整神经元之间的“权重”,以及每个功能神经元的阈值。
设计网络的输入层通常是非常直接的。例如,,要尝试识别一张输入图像是否有“1”。很自然的,,可以将图片像素的强度进行编码作为输入层。如果图像是64×64的灰度图.需4096=64×64个输入神经元。每个强度都取0-1之间适合的值。输出层只需要一个神经元,当输出值小于0.5,表示该图像不是“1”,反之,表示输出的图像是“1”。
相较于完全固定的输入层和输出层,隐含层的设计是个难题,特别是通过一些简单的经验来总结隐藏层的设计流程不一定总是可行的。讨论的神经网络,都是的前面一层作为后面一层的输入,这种经典的网络被称为前馈神经网络。这也就意味着网络中没有回路,信息总是向前传播,从不反馈。
二. 神经网络模型
神经网络就是由很多个单一的神经单元组合到一起,这里面的一个神经单元的输出就可以是另一个神经单元的输入,每一个神经元有着各自的功能,通过将这些功能各异的神经元有序组合,就可以构成结构不同、用途不同的神经网络。例如,图6就是一个简单的人工神经网络。
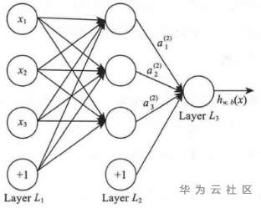
图6:神经网络图
对于图6神经网络图的解释,使用小圆圈来表示神经网络要接受的信号,标上的圆圈中的+1被称为偏置节点(bias)。神经网络最左层用于接受的外部的信息,称为输入层,最右层是经过神经网络处理后最终的输出,称为输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层用于变换计算,看不到具体计算过程,称为隐藏层,无法在训练样本集中观测到它们的值。同时也可以看到,以上神经网络的例子中有3个输入单元(维度为3,偏置单元不计在内),3个隐藏单元及一个输出单元。
在这里,用Lx来表示网络总共有几层,本例中很显然x=3,同时,将第1层记为L1,则L1为输入层,L3为输出层。本例的神经网络有训练参数(W,b),其中(W1,b1,W2,b2)其中W1是第l层第j单元与第l+1层的第i单元之间的连接参数,bi则为第l+1层的第i单元的偏置单元。偏置单元是没有输入的,因为它们总是输出+1。同时,,记第l层的节点数为si。
用ai表示第l层第i单元的激活值(输出值)。当l=1时,ai=x,也就是第i个输入值(输入值的第i个特征)。对于给定参数集合(W,b),,的神经网络就可以按照函数h从(x)来计算输出结果,则计算过程:
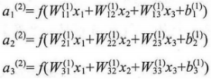
这里用zi来表示第l层第i单元的激活值(包含偏置单元)。这样就可以将激活函数f()扩展写为向量的形式来表示,则上面的等式可以更简洁地写为:
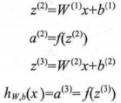
上式的计算过程被称为ANN的前向传播。先前使用a=x来表示输入层的激活值,依此类推给定第l层的激活值al之后,则第l+1层的激活值a就可以按照如下式子来计算:
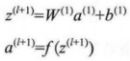
更直观的结构如图7所示:

图7:输入与输出
讨论了一种通用的人工神经网络结构,可以构建另种结构的神经网络(这里的结构指的是两个神经元的连接方式),即含有多个隐藏层的神经网络。例如有一个有nl层的神经网络,那么第1层为输入层,第n层是输出层,中间的每个层l与H+1层紧密相联。在这种构造下,很容易计算神经网络的输出值,,可以按照之前推出的式子,一步一步地进行前向传播,逐个单元地计算第L2层的每个激活值,依此类推,接着是第L3层的激活值,直到最后的第Ln层。这种联接图没有回路或者闭环,所以称这种神经网络为前馈网络。
除此之外,神经网络的输出单元还可以是多个。举个例子,图8的神经网络结构就有两层隐藏层:(L2和L3层),而输出层L4层包含两个输出单元。
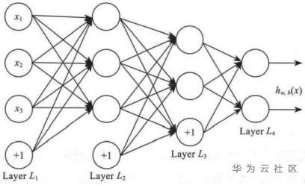
图8:神经网络连接图
要求解这样的神经网络,需要样本集(x,y)。如果想要预测的输出是有多个分类的,那么这种神经网络就比较适合,例如检测一张数字图片,就有两个输出。
三. 神经网络的反向传播
多层网络的学习拟合能力比单层网络要强大很多。所以想要训练多层网络,前面的简单感知机学习方法显然有些不足,需要拟合能力更加强大的算法。反向传播算法( Back Propagation,BP)是其中的经典方法,BP算法不仅可以用于多层前馈神经网络,可以用于其它类型神经网络,例如LSTM模型,通常所说的BP网络,一般是用BP算法训练的多层前馈网络。
可以先通过BP网络的走向图大致掌握以下反向传播算法的主要用处,从输入层开始,数据进入到网络中经过每一层的计算变化,最终得出实际输出。然后和期望输出做比较计算损失值,此时的损失值将按照反方向逐渐向前传播计算,通过梯度下降的方式优化网络中的参数,求取出符合要求的网络模型。如图9中所示:
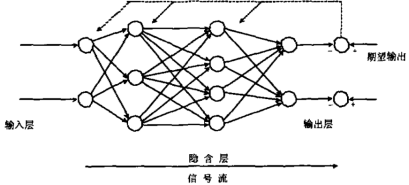
图9:BP网络结构图
接下来,将通过公式计算逐步的展示BP网络的基本结构。最开始要假设,有一个固定训练集合{(x1,y1),…,(xm,ym)},样本总数为m。利用批量梯度下降法来求解参数,也属于有监督学习方法。具体到每个样本(x,y),其代价函数为下式:
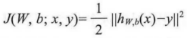
对于给定有m个样本的数据集,可以定义整体的代价函数为:
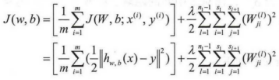
上式中的第一项J(w,b)是均方差项。第二项则是规则化项,用来约束解以达到结构风险最小化( Structural risk minimization,SRM),目的是防止模型出现过拟合( over fitting)。
BP算法的总体流程:首先对每个样本数据,进行前向传播计算,依次计算出每层每个单元的激活值。接着计算出第l层的每个节点i的“残差”值δ,该值直接体现了这个单元对最终的输出有多大的影响力。最后一层输出层则可以直接获得最终结果和输出结果的差值,,定义为δ(,而对于中间的隐藏层的残差,,则通过加权平均下层(l+1层)残差来计算。
BP算法的具体推导过程如下:
1)前馈网络传导的计算,逐层算出L2到最后一层的每层节点的激活值。
2)计算各节点的残差值,对于输出层,使用如下公式:
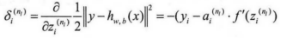
上式子中的推导过程如下:
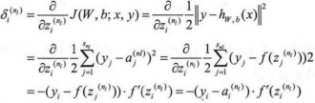
3)从最后一层依次向前推导到第2层,第l层的残差为:
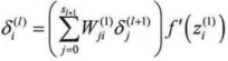
推导可得出:
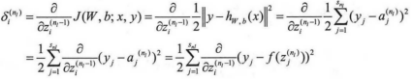
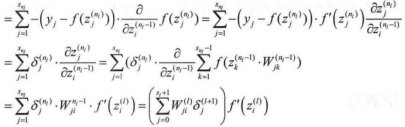
依照上面只需将nl替换为l就可以推导到中间层l与l=1的残差关系。可以更新所需的偏导数:
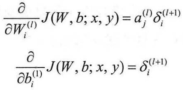
最后得出BP算法的描述:
在下面的伪代码中,ΔW0是一个与矩阵W维度相同的矩阵,△b0是一个与b0维度相同的向量。注意这里“ΔW”是一个矩阵。下面,实现批量梯度下降法中的一次迭代:
1)对于所有l,令△W0:=0,Δb0:=0(设置为全零矩阵或全零向量)。
2)对于i=1到m,
a)使用反向传播算法计算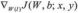
和 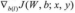
。
b)计算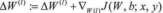
。
c)计算 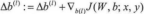
。
3)更新权重参数: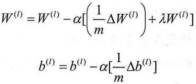
现在,可以重复梯度下降法的迭代步骤来减小代价函数J(w,b)的值,进而求解,的神经网络。
四.门控制循环单元
门控循环神经网络(gated recurrent neural network)的提出,为了更好地捕捉时间序列中时间步距离较大的依赖关系。通过可以学习的门来控制信息的流动。其中,门控循环单元(gated recurrent unit,GRU)是一种常用的门控循环神经网络。
下面将介绍门控循环单元的设计。引入了重置门(reset gate)和更新门(update gate)的概念,从而修改了循环神经网络中隐藏状态的计算方式。
门控循环单元中的重置门和更新门的输入均为当前时间步输入XtXt与上一时间步隐藏状态Ht−1,输出由激活函数为sigmoid函数的全连接层计算得到。
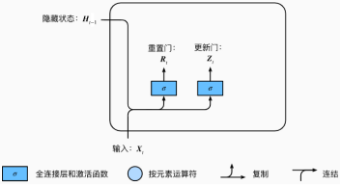
图10:门控制循环单元的重置门和更新门
具体来说,假设隐藏单元个数为h,给定时间步t的小批量输入Xt∈Rn×d(样本数为n,输入个数为d)和上一时间步隐藏状态Ht−1∈Rn×h。重置门Rt∈Rn×h和更新门Zt∈Rn×h的计算如下:
Rt=σ(XtWxr+Ht−1Whr+br),
Zt=σ(XtWxz+Ht−1Whz+bz),
其中Wxr,Wxz∈Rd×h和Whr,Whz∈Rh×h是权重参数,br,bz∈R1×h是偏差参数。
接下来,门控循环单元将计算候选隐藏状态来辅助稍后的隐藏状态计算。如图11所示,将当前时间步重置门的输出与上一时间步隐藏状态做按元素乘法(符号为⊙)。如果重置门中元素值接近0,那么意味着重置对应隐藏状态元素为0,即丢弃上一时间步的隐藏状态。如果元素值接近1,那么表示保留上一时间步的隐藏状态。然后,将按元素乘法的结果与当前时间步的输入连结,通过含激活函数tanh的全连接层计算出候选隐藏状态,
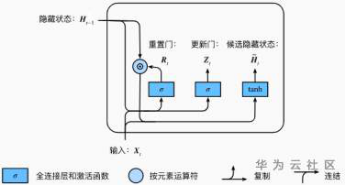
图11:门控制循环单元中候选隐藏状态的计算
具体来说,时间步t的候选隐藏状态H~t∈Rn×h的计算为:
H~t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
其中Wxh∈Rd×h和Whh∈Rh×h是权重参数,bh∈R1×h是偏差参数。从上面这个公式可以看出,重置门控制了上一时间步的隐藏状态如何流入当前时间步的候选隐藏状态。而上一时间步的隐藏状态可能包含了时间序列截至上一时间步的全部历史信息。因此,重置门可以用来丢弃与预测无关的历史信息。
最后,时间步t的隐藏状态Ht∈Rn×h的计算使用当前时间步的更新门Zt来对上一时间步的隐藏状态Ht−1和当前时间步的候选隐藏状态H~t做组合:
Ht=Zt⊙Ht−1+(1−Zt)⊙H~t.
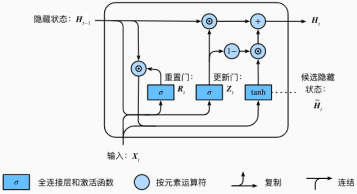
图12:门控制循环单元中隐藏状态的计算
值得注意的是,更新门可以控制隐藏状态应该如何被包含当前时间步信息的候选隐藏状态所更新,如图11所示。假设更新门在时间步t′到t(t′<t)之间一直近似1。那么,在时间步t′到t之间的输入信息几乎没有流入时间步t的隐藏状态Ht。实际上,这可以看作是较早时刻的隐藏状态Ht′−1一直通过时间保存并传递至当前时间步t。这个设计可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
对门控循环单元的设计稍作总结:重置门有助于捕捉时间序列里短期的依赖关系;更新门有助于捕捉时间序列里长期的依赖关系。
五.长短期记忆网络
门控制循环单元是为了解决循环神经网络短期记忆问题提出的解决方案,引入称作“门”的内部机制,可以调节信息流。在上次的内容分享中,简单解析了名称为GRU的门控制循环单元。因为“门”的机制,还可以在此基础上创新出性能更优的循环单元。本次分享的内容也是基于GRU循环单元的强化版:长短期记忆网络(long short-term memory,LSTM)门控制循环单元。

图13 :LSTM和GRU结构图
通过图13可以很明显的发现LSTM比GRU“门”的数量更多结构也更复杂。LSTM 中引入了3种类型的门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞。
输入门、遗忘门和输出门:此3种控制门与门控循环单元中的重置门和更新门功能相似。如图2所示,长短期记忆的门的输入均为当前时间步输入Xt与上一时间步隐藏状态Ht-1,输出由激活函数为sigmoid函数的全连接层计算得到。如此一来,由于sigmoid函数的特性,此3个门元素的输出值域均为[0, 1]。

图14:LSTM中的输入门、遗忘门和输出门
具体来说,假设隐藏单元个数为h,给定时间步t的小批量输入Xt ∈ Rn×d(样本数为n,输入个数为d)和上一时间步隐藏状态Ht−1 ∈ Rn×h。时间步t的输入门It ∈ Rn×h、遗忘门Ft ∈ Rn×h和输出门Ot ∈ Rn×h分别计算如下:
It = σ(XtWxi + Ht−1Whi + bi),
Ft = σ(XtWxf + Ht−1Whf + bf ),
Ot = σ(XtWxo + Ht−1Who + bo),
其中的Wxi,Wxf ,Wxo ∈ Rd×h和Whi,Whf ,Who ∈ Rh×h都属于权重参数,其余是bi, bf , bo ∈ R1×h是偏差参数。
候选记忆细胞:接下来便是记忆细胞的机制,长短期记忆需要计算候选记忆细胞C˜t。它的计算与上面介绍的3种门类似,但这里使用了值域在[-1, 1]的tanh函数作为激活函数,如图15所示。

图15:LSTM中的候选记忆细胞计算
时间步t的候选记忆细胞C˜t ∈ Rn×h的计算可以表示为:
C˜t = tanh(XtWxc + Ht−1Whc + bc),
上述表达式中的Wxc ∈ Rd×h和Whc ∈ Rh×h是权重参数,bc ∈ R1×h是偏差参数。
记忆细胞:,可以通过元素值域在[0, 1]的输入门、遗忘门和输出门来控制隐藏状态中信息的流动,这一般也是通过使用按元素乘法(符号为⊙)来实现的。当前时间步记忆细胞Ct ∈ Rn×h的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门来控制信息的流动:
Ct = Ft ⊙ Ct−1 + It ⊙ C˜t.
如图16所示,遗忘门控制上一时间步的记忆细胞Ct-1中的信息是否传递到当前时间步,而输入门则控制当前时间步的输⼊Xt通过候选记忆细胞C˜t如何流入当前时间步的记忆细胞。如果遗忘门一直近似1且输入门一直近似0,过去的记忆细胞将一直通过时间保存并传递至当前时间步。这个设计主要是针对循环神经网络中的梯度衰减问题,并且还可以更好地捕捉时间序列中时间步距离较大的依赖关系。

图16:LSTM忆中记忆细胞的计算。这⾥的⊙是按元素乘法
隐藏状态:有了记忆细胞以后,接下来,还可以通过输出门来控制从记忆细胞到隐藏状态Ht ∈ Rn×h的信息的流动:
Ht = Ot ⊙ tanh(Ct).
这里的tanh函数确保隐藏状态元素值在-1到1之间。需要注意的是,当输出门近似1时,记忆细胞信息将传递到隐藏状态供输出层使用;当输出门近似0时,记忆细胞信息只自己保留。图17展示了长短期记忆中隐藏状态的计算。

图17:LSTM忆中隐藏状态的计算。这⾥的⊙是按元素乘法
LSTM的输入门、遗忘门和输出门可以控制信息的流动。隐藏层输出包括隐藏状态和记忆细胞,只有隐藏状态会传递到输出层。长短期记忆可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
总结:
首先,从网络的基础单元神经元开始,不同的神经元组合就构成了各种功能不同的神经网络模型。BP网络就是一种具有自我更新参数能力,具有一定的容错性和抗干扰性。基本方法:学习过程由数据集信号的正向传播和误差的反向传播两个过程组成,通过两种传播不断优化模型。门控循环单元(GRU)的改进是引入了门的概念,从而也修改了循环神经网络中隐藏层重点计算方式。LSTM的核心是细胞的状态,以及其中的各种门结构。细胞状态充当传输通道,在序列链中进行着相关信息的传递。也可以抽象为网络的“记忆”。






